SDD(规范驱动开发)
SDD(规范驱动开发)分享会 — 完整讲稿
分享主题:Specification-Driven Development(规范驱动开发) 目标听众:初学AI的程序员
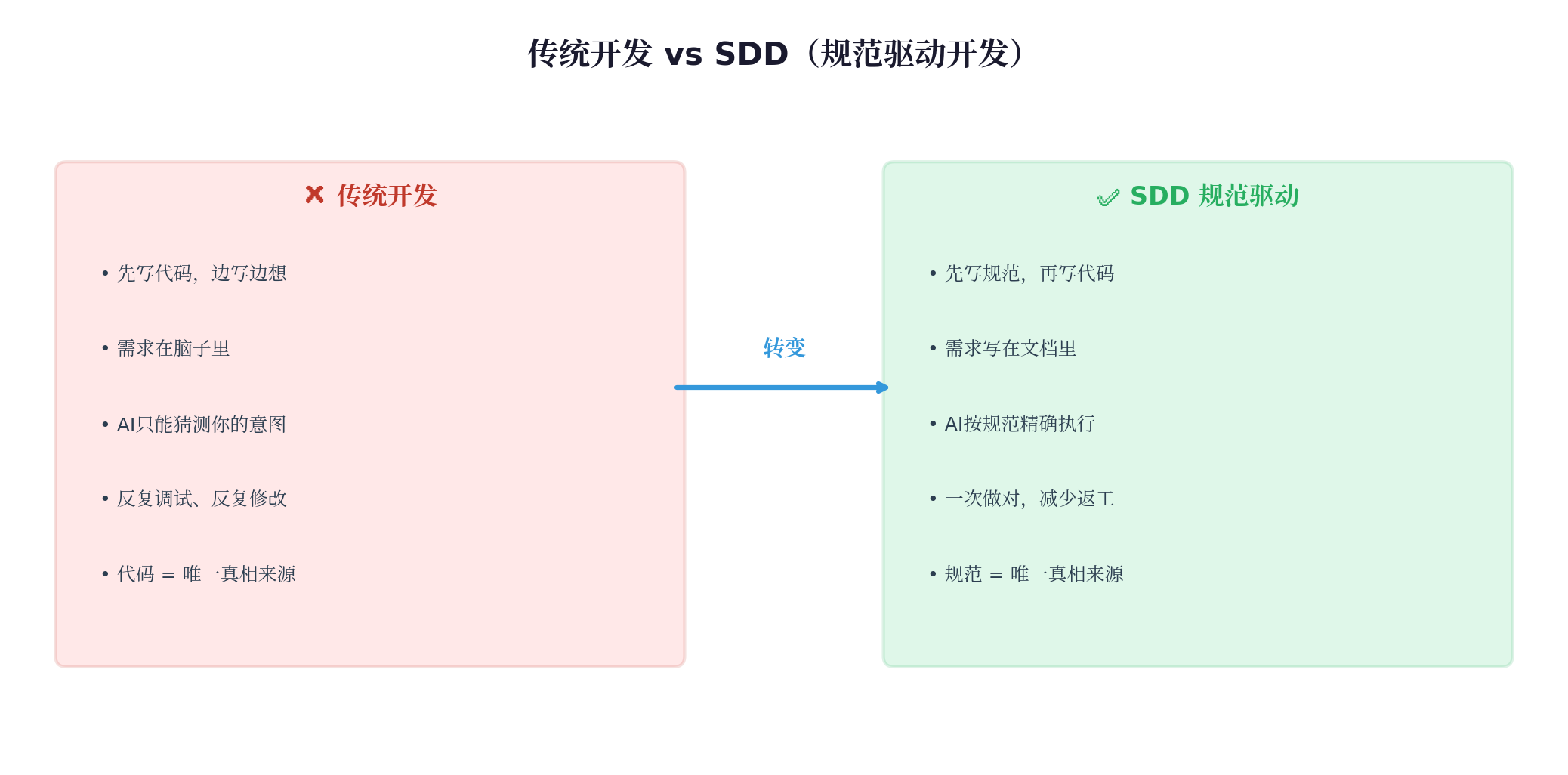
开场:为什么需要SDD?
痛点引入(问题 1)
问大家:"你们有没有遇到过这种情况?让AI写个功能,它生成了代码,但和你想的完全不一样,然后你花2小时调试修改..."
这就是 "Vibe Coding"(凭感觉编码) 的问题——没有明确规范,AI只能猜测你的意图。
一个小故事
想象你去餐厅点菜:
-
传统方式:"给我来份好吃的" → 厨师自由发挥 → 可能不是你想要的
-
SDD方式:"我要一份宫保鸡丁,微辣,不要花生,配米饭" → 厨师精确执行
SDD的核心理念:
"代码是规范的实现细节,而不是反过来。规范声明意图,代码实现它。"
第一部分:SDD是什么?
SDD的定义
SDD = Specification-Driven Development(规范驱动开发)
在AI编程时代,SDD意味着:
在让AI写代码之前,先写清楚"做什么"和"怎么做"的规范文档。
三种严格程度
| 级别 | 名称 | 特点 | 适用场景 |
|---|---|---|---|
| 轻度 | Code-First | 想到哪写到哪 | 小脚本、实验 |
| 中度 | Spec-First | 先写规范再写代码 | ⭐ 初学者建议 |
| 重度 | Spec-as-Source | 规范直接生成代码 | 大型项目、未来趋势 |
互动问题 2:"大家觉得日常写代码,更接近哪个级别?"
第二部分:SDD四步工作流⭐核心内容
这是SDD的标准流程,每个阶段产出一份文档,指导下个阶段: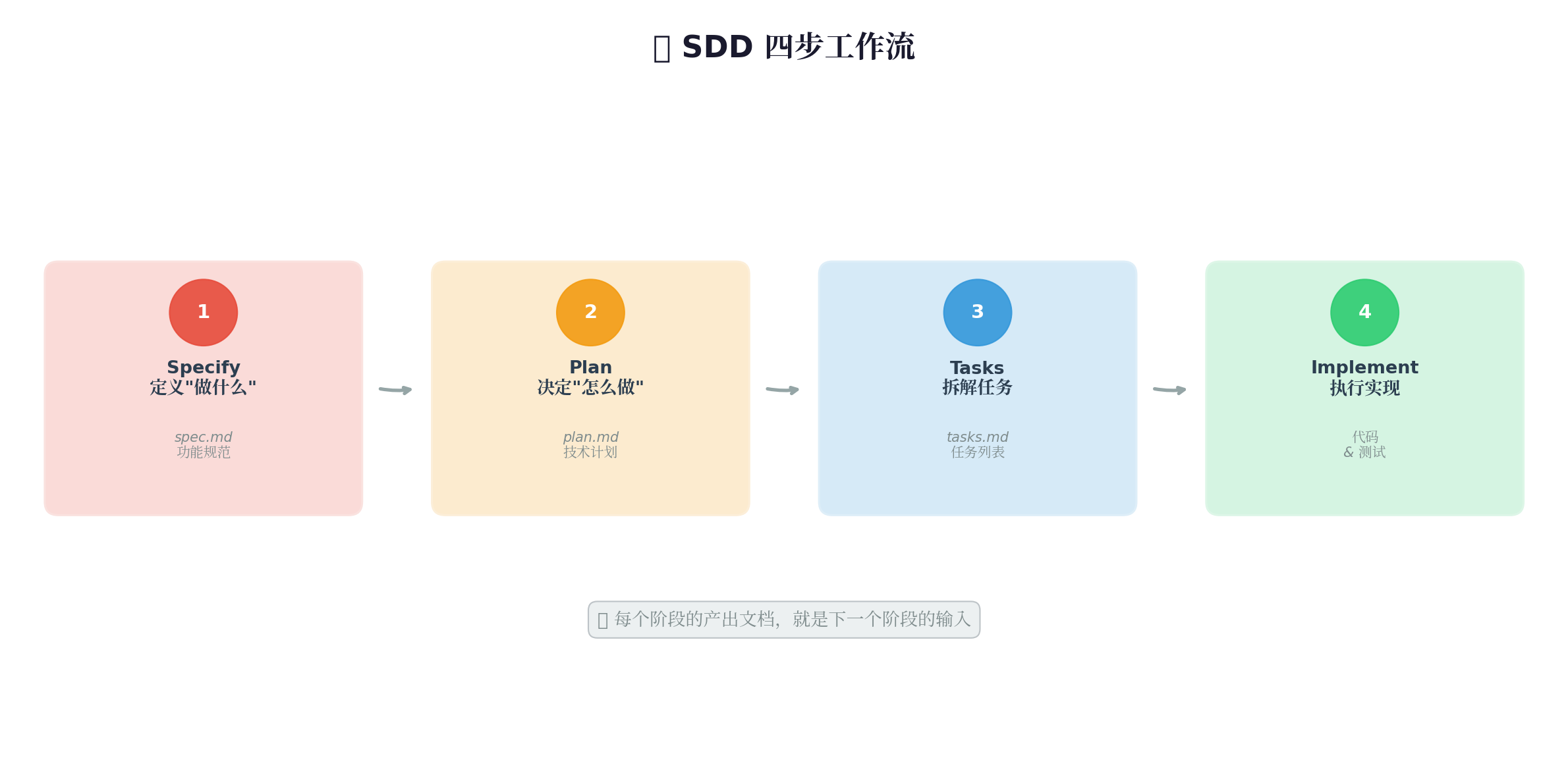
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ Specify │───▶│ Plan │───▶│ Tasks │───▶│Implement│ │ 定义做什么 │ │ 决定怎么做 │ │ 拆解任务 │ │ 执行实现 │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │ │ │ │ ▼ ▼ ▼ ▼ spec.md plan.md tasks.md 代码
实战示例:开发一个"用户登录功能"
Phase 1: Specify(规范定义)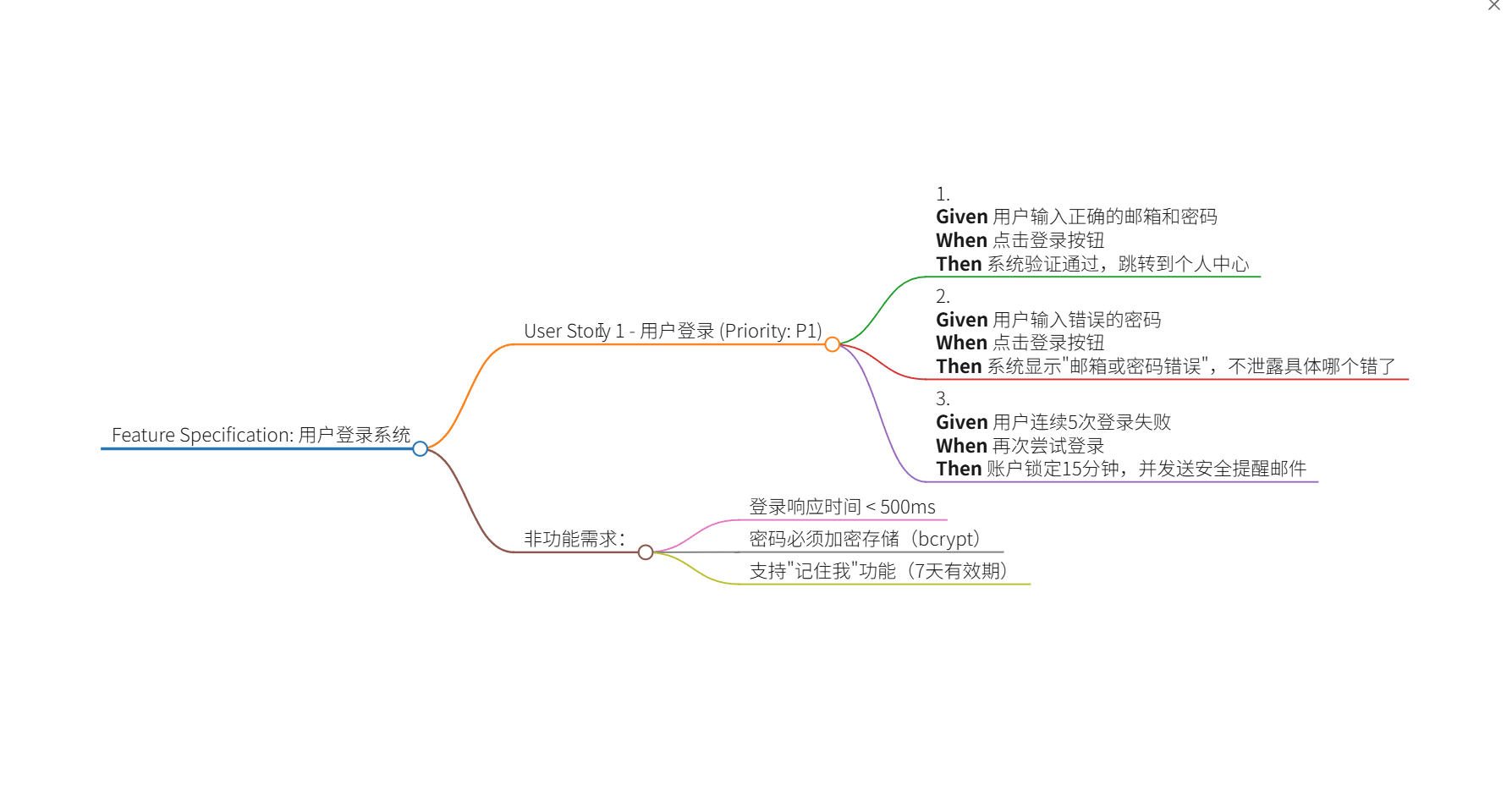
原则:只写"做什么",不写"怎么做"
# Feature Specification: 用户登录系统
**Feature Branch**: 001-user-login
**Status**: Draft
### User Story 1 - 用户登录 (Priority: P1)
作为用户,我需要使用邮箱和密码登录,
以便访问我的个人中心。
**验收标准 (Acceptance Criteria)**:
1. **Given** 用户输入正确的邮箱和密码
**When** 点击登录按钮
**Then** 系统验证通过,跳转到个人中心
2. **Given** 用户输入错误的密码
**When** 点击登录按钮
**Then** 系统显示"邮箱或密码错误",不泄露具体哪个错了
3. **Given** 用户连续5次登录失败
**When** 再次尝试登录
**Then** 账户锁定15分钟,并发送安全提醒邮件
### 非功能需求:
- 登录响应时间 < 500ms
- 密码必须加密存储(bcrypt)
- 支持"记住我"功能(7天有效期)Given/When/Then 语法解析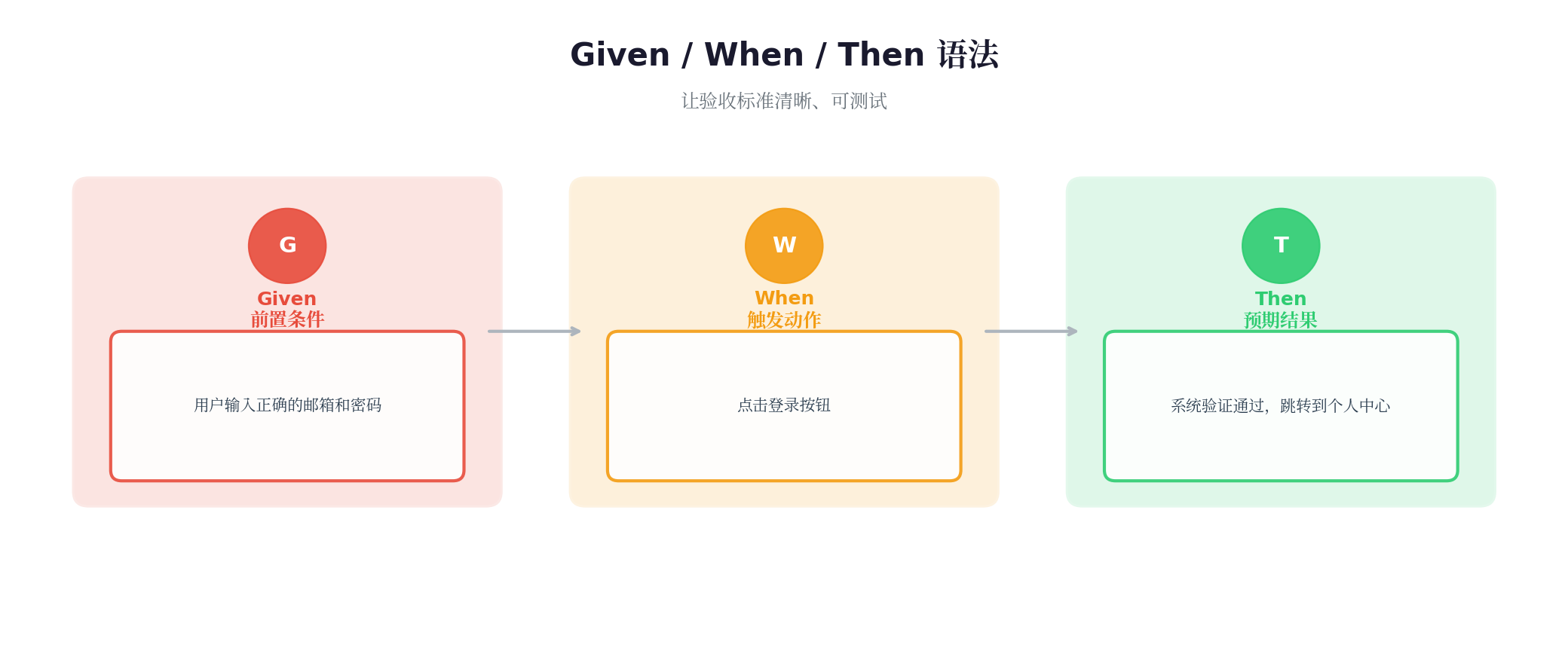
为什么用这个格式?
-
每个场景都是可测试的
-
非技术人员也能看懂
-
AI能精确理解每个条件
互动问题 3:"如果不用GWT格式,直接说'登录功能要做好',AI会怎么理解?"
Phase 2: Plan(技术规划)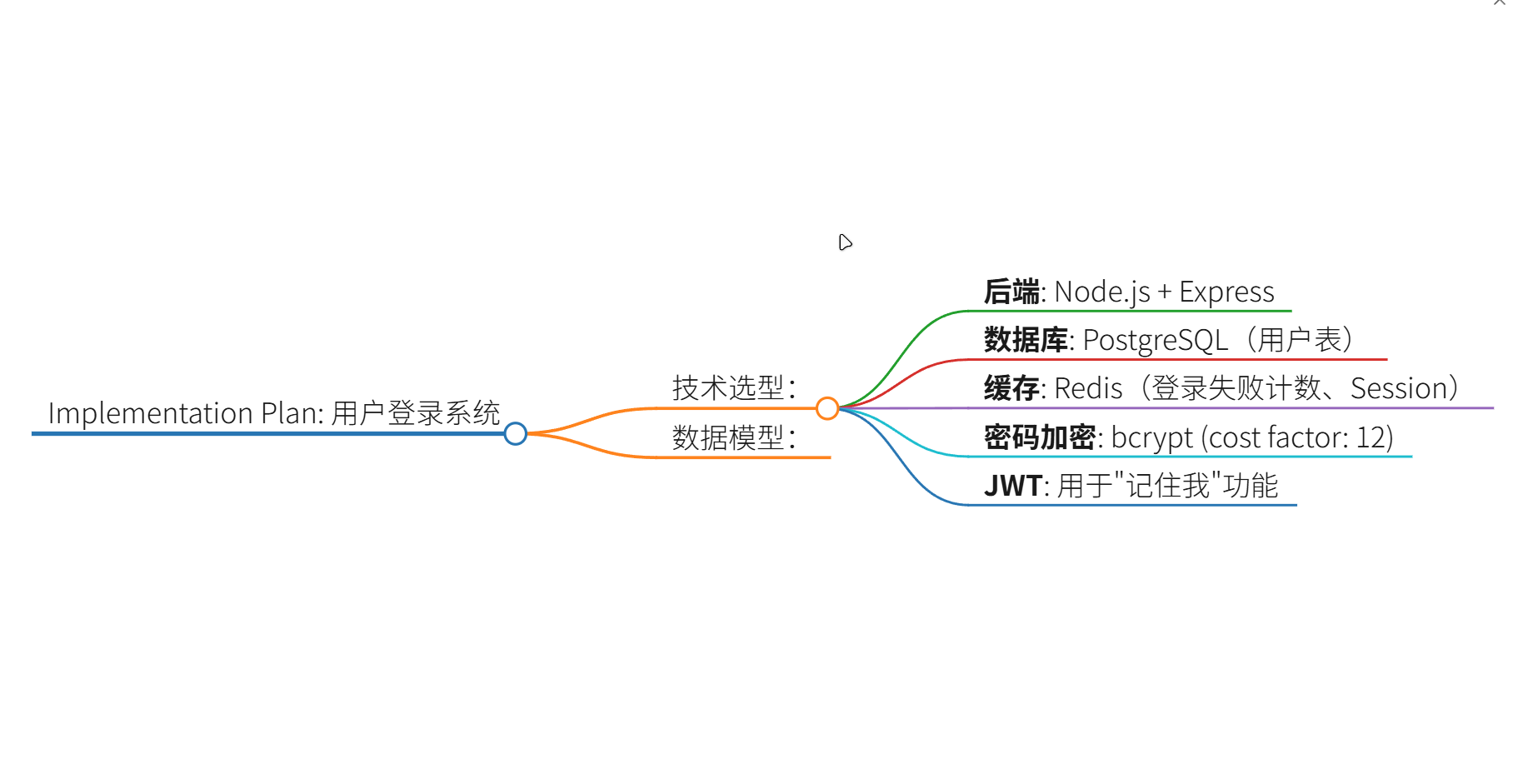
原则:现在才决定技术方案
# Implementation Plan: 用户登录系统
### 技术选型:
- **后端**: Node.js + Express
- **数据库**: PostgreSQL(用户表)
- **缓存**: Redis(登录失败计数、Session)
- **密码加密**: bcrypt (cost factor: 12)
- **JWT**: 用于"记住我"功能
### 数据模型:
User 表:
id: UUID (PK)
email: VARCHAR(255), UNIQUE, NOT NULL
password_hash: VARCHAR(255), NOT NULL
failed_login_attempts: INT, DEFAULT 0
locked_until: TIMESTAMP, NULLABLE
created_at: TIMESTAMP
### API 设计:
POST /api/auth/loginRequest: { email, password, rememberMe? }Response: { token, user: { id, email } }Errors: 401 (认证失败), 423 (账户锁定)
互动问题 4:"大家觉得,如果不写Plan,直接让AI写代码,可能会出什么问题?"(提示:可能选错技术栈、数据库设计不合理、API不统一...)
Phase 3: Tasks(任务拆解)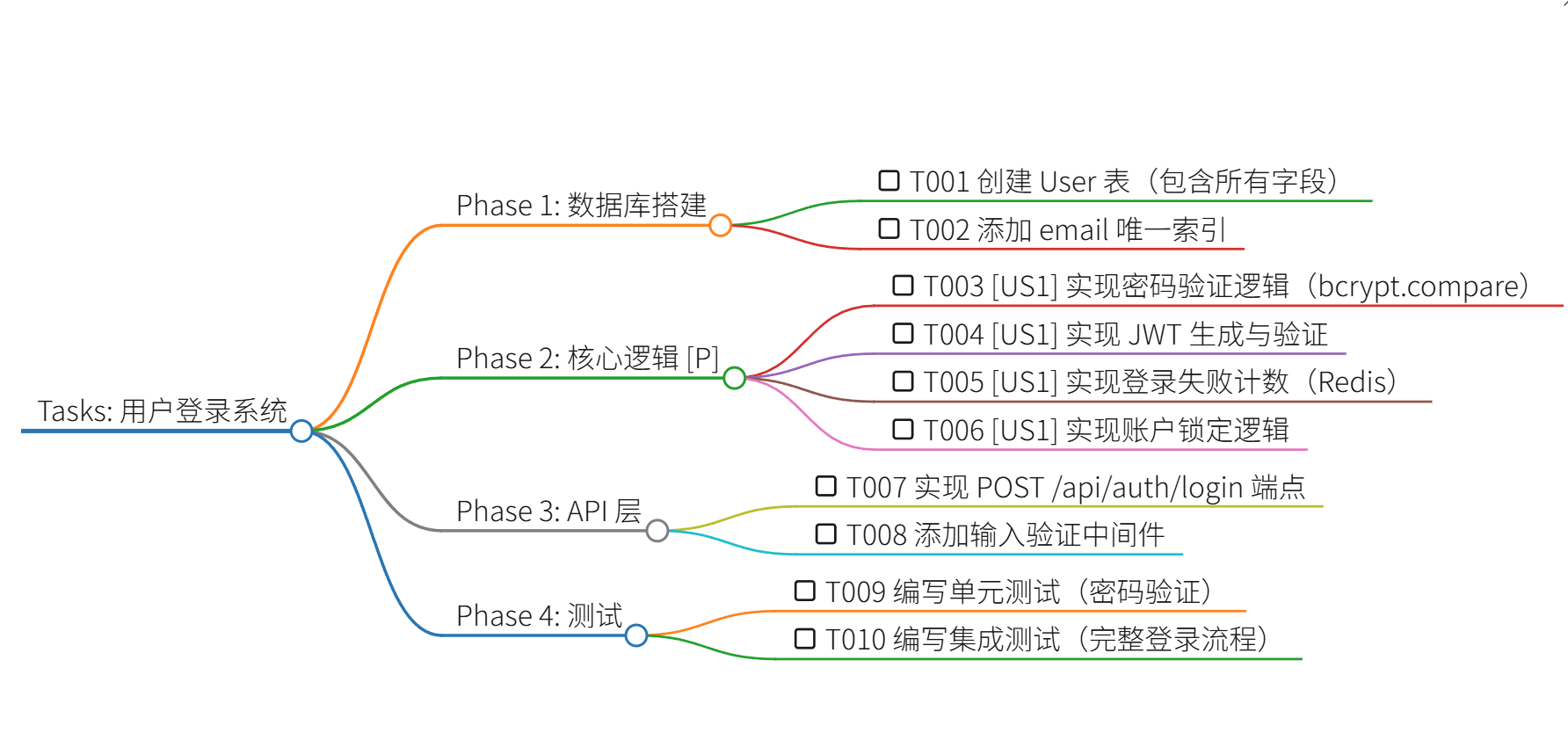
# Tasks: 用户登录系统
### Phase 1: 数据库搭建
- [ ] T001 创建 User 表(包含所有字段)
- [ ] T002 添加 email 唯一索引
### Phase 2: 核心逻辑 [P]
- [ ] T003 [US1] 实现密码验证逻辑(bcrypt.compare)
- [ ] T004 [US1] 实现 JWT 生成与验证
- [ ] T005 [US1] 实现登录失败计数(Redis)
- [ ] T006 [US1] 实现账户锁定逻辑
### Phase 3: API 层
- [ ] T007 实现 POST /api/auth/login 端点
- [ ] T008 添加输入验证中间件
### Phase 4: 测试
- [ ] T009 编写单元测试(密码验证)
- [ ] T010 编写集成测试(完整登录流程)[P] = 可并行执行的任务
Phase 4: Implement(实现)
现在才把规范交给AI:
请根据以下规范实现用户登录功能:
1. 规范文件:specs/001-user-login/spec.md
2. 技术计划:specs/001-user-login/plan.md
3. 任务列表:specs/001-user-login/tasks.md
请按任务列表顺序实现,确保所有验收标准通过测试。结果:AI不再猜测,而是精确执行!
互动问题 5:"对比一下,直接说'帮我写个登录功能' vs 给AI完整的规范文档,效果会有什么不同?"
第三部分:SDD项目结构
一个规范的SDD项目长什么样?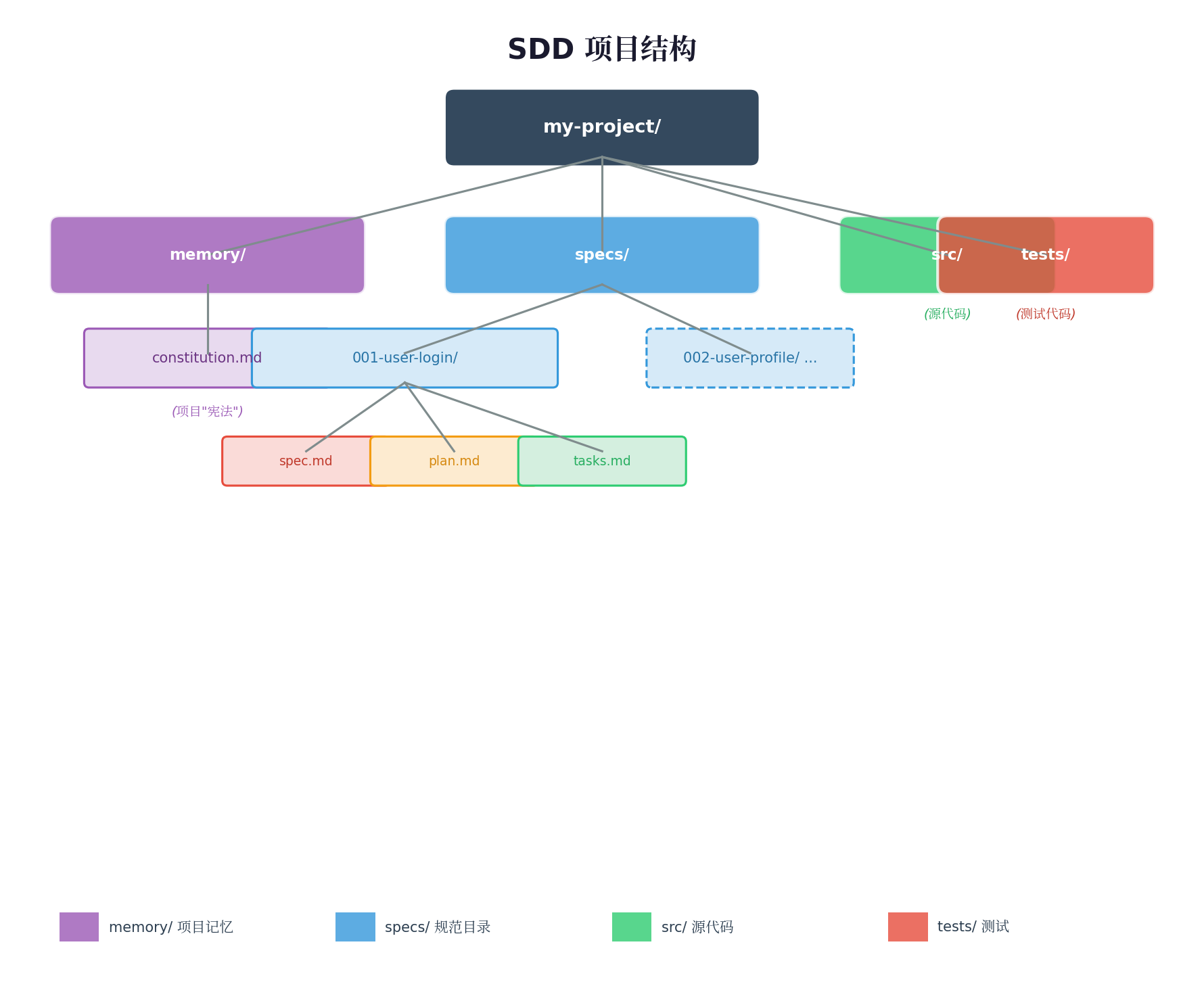
my-project/
├── memory/
│ └── constitution.md ← 项目"宪法"(核心原则)
├── specs/ ← 所有规范存放处
│ ├── 001-user-login/
│ │ ├── spec.md ← 功能规范(做什么)
│ │ ├── plan.md ← 技术计划(怎么做)
│ │ ├── tasks.md ← 任务列表
│ │ ├── data-model.md ← 数据模型
│ │ ├── contracts/ ← API契约(OpenAPI等)
│ │ └── research.md ← 技术调研
│ └── 002-user-profile/
│ └── ...
├── src/ ← 源代码
└── tests/ ← 测试代码Constitution(项目宪法)示例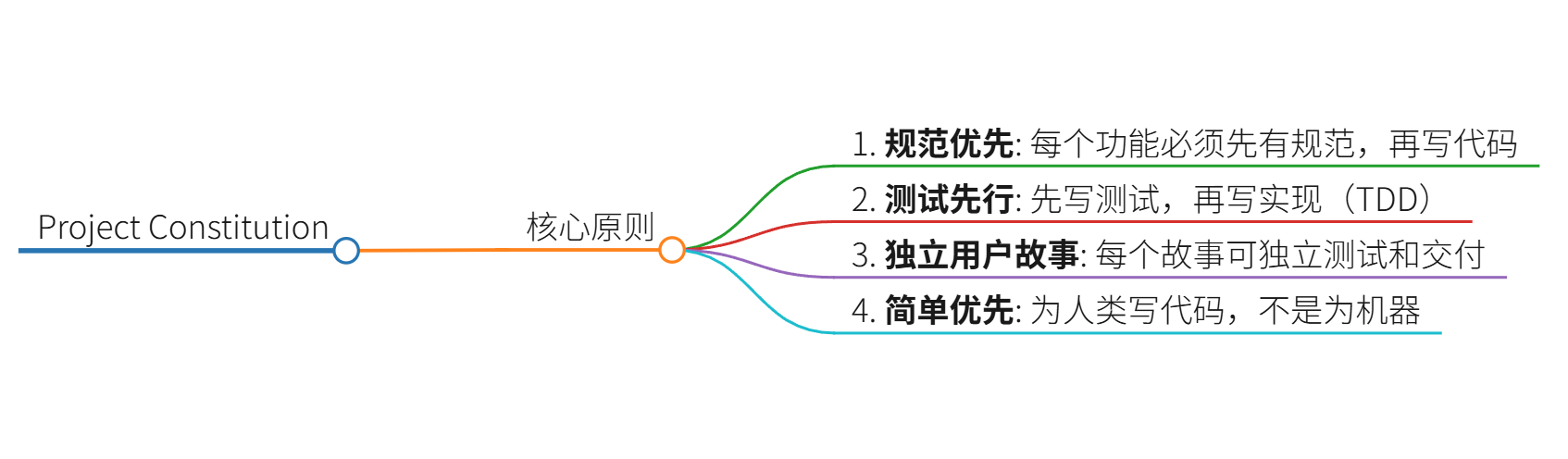
# Project Constitution ### 核心原则 1. **规范优先**: 每个功能必须先有规范,再写代码 2. **测试先行**: 先写测试,再写实现(TDD) 3. **独立用户故事**: 每个故事可独立测试和交付 4. **简单优先**: 为人类写代码,不是为机器
互动问题 6:"大家觉得'项目宪法'这个概念有用吗?它解决了什么问题?"(提示:团队一致性、AI上下文保持一致、新人 onboarding)
补充:SDD 不是"写三个文档"
SDD = 一套"用规范驱动开发"的方法论
SDD ≠ 三个文档
一句话版
SDD = 用 spec 定义问题,用 plan 决策方案,用 tasks 驱动执行,用代码验证结果
spec / plan / tasks 是什么关系?
你可以把它理解成一条"信息压缩链":
spec(意图) ↓ plan(决策) ↓ tasks(执行步骤) ↓ code(最终产物)
👉 每一步都在做一件事:
| 阶段 | 本质 | 解决什么问题 |
|---|---|---|
| spec | 定义"做什么" | 防止 AI 理解错需求 |
| plan | 决定"怎么做" | 防止技术选型混乱 |
| tasks | 拆解"具体干啥" | 防止实现过程失控 |
| code | 执行 | 最终交付 |
开发时要写三个文档吗?
不需要! 而且如果你每次都写三个文档,大概率会把自己拖慢。
更现实一点讲:
👉 SDD 不是让你"多写文档",而是让你"在该清晰的时候变清晰"。
四种场景
| 场景 | 复杂度 | 写什么 | 目的 |
|---|---|---|---|
| 🟢 直接干 | 低 | 不写 | 快 |
| 🟡 写个 spec | 中 | spec | 不跑偏 |
| 🔴 spec + plan | 高 | spec + plan | 不返工 |
| ⚫ 完整 SDD | 很高 | spec + plan + tasks | 可协作 |
🟢 场景1:不用写(直接干)
比如:
-
加个按钮
-
改个样式
-
写个小工具
👉 做法:直接一句话 + AI
帮我加一个登录按钮,点击后跳转到 /login
🟡 场景2:写一个 spec 就够了(最常见 ⭐)
比如:
-
登录功能
-
表单系统
-
简单业务逻辑
👉 做法:写一个简化版 spec(甚至不用单独文件)
功能:用户登录 场景: 1. 正确登录 → 进入首页 2. 密码错误 → 提示错误 3. 连续失败5次 → 锁定账户
👉 然后直接让 AI 实现
🔴 场景3:spec + plan(推荐你重点用的)
比如:
-
有后端 + 数据库
-
有安全/性能要求
-
需要长期维护
👉 做法:
-
spec:定义需求
-
plan:定技术方案
👉 这一步是性价比最高的
⚫ 场景4:spec + plan + tasks(完整 SDD)
比如:
-
团队项目
-
多人协作
-
复杂系统(权限 / 支付 / AI Agent)
👉 才需要:
-
tasks(拆任务)
-
并行开发
-
流程管理
默认策略
80% 场景:spec + plan 就够了
⚠️ 很多人会踩的坑(重点提醒)
❌ 坑1:形式主义
写了一堆 spec.md / plan.md / tasks.md,但:
-
AI 没用这些
-
自己也不看
那就是:
❌ "写文档式SDD" —— 没任何价值
❌ 坑2:所有项目都上 full SDD
👉 结果:写文档比写代码还久,开发体验极差
❌ 坑3:该写的时候不写
比如:权限系统、支付流程
👉 直接让AI写
结果:
💥 重写三次 + 逻辑混乱
✅ 正确姿势
在该清晰的时候变清晰,在该快的时候直接干
第四部分:什么时候用SDD?(5分钟)
不是每个任务都需要规范!
| 写规范 | 跳过规范 |
|---|---|
| 跨多个AI会话的工作 | 探索性/实验性代码 |
| 涉及多个服务或仓库 | 一个提示就能出结果的 |
| 错误代价高(支付、安全) | 5分钟内能审查完的 |
| 需要合规审计 | 用完就扔的原型 |
| 需要认真审查的组件逻辑 | 机械性、低风险的改动 |
| 多人协作开发 | 个人小脚本 |
判断标准:
"如果AI理解错了我会很烦,那就写规范。如果我能用一句话快速修正,那就跳过。"
互动问题 7:"大家来投票:以下场景要不要写规范?"
A. 写一个计算BMI的小工具
B. 实现支付接口
C. 给页面加个按钮
D. 设计用户权限系统
第五部分:AI时代的SDD最佳实践
多智能体协作模式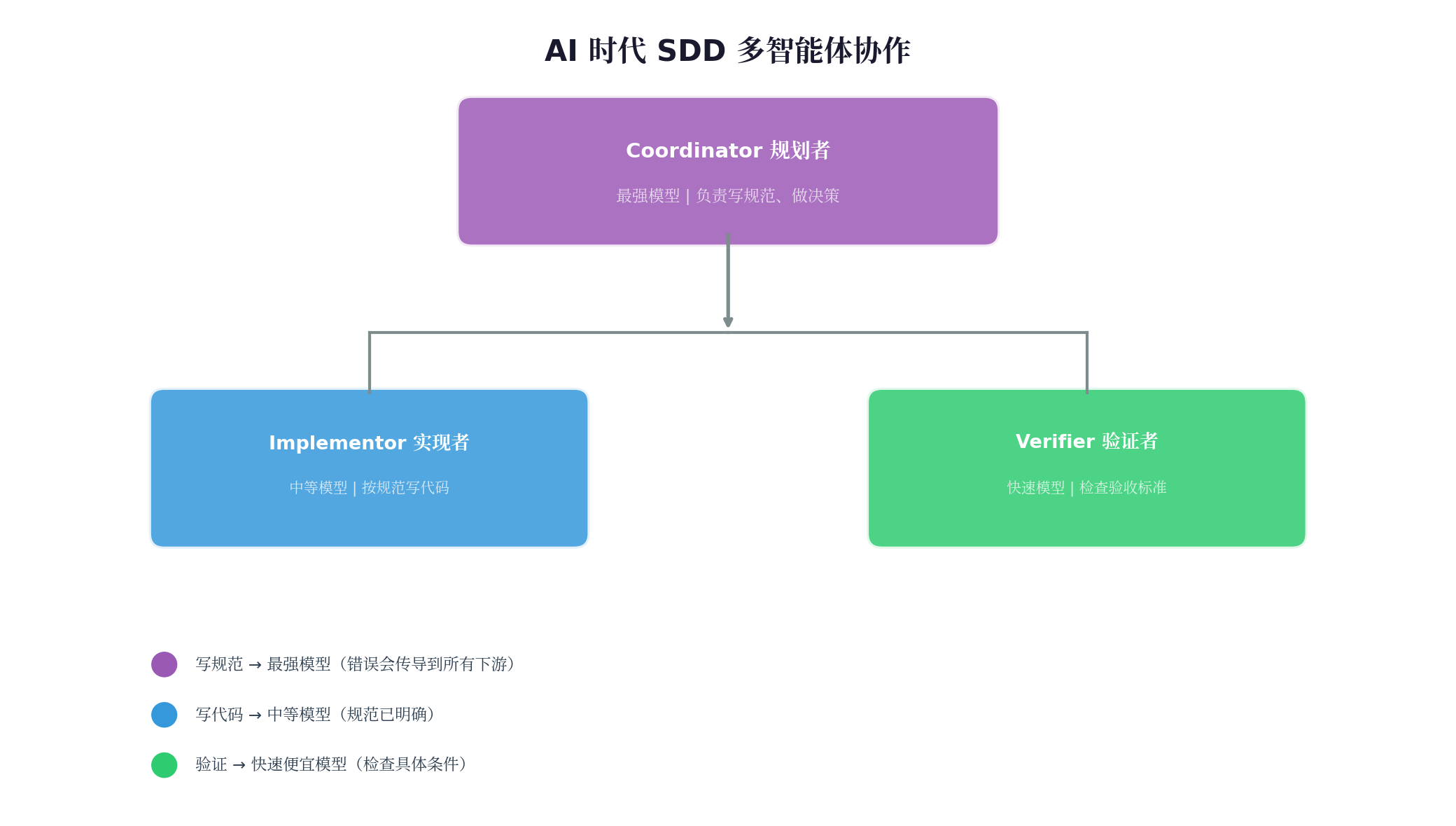
┌─────────────┐ │ Coordinator │ ← 最强模型(写规范) │ 规划者 │ └──────┬──────┘ │ ┌───┴───┐ ▼ ▼ ┌──────┐ ┌──────┐ │Implementor│ │Verifier│ │ 实现者 │ │ 验证者 │ └─────────┘ └─────────┘
资源分配原则:
-
写规范:用最强的模型(错误会传导到所有下游)
-
写代码:中等模型即可(规范已明确)
-
验证:快速便宜模型(检查具体条件)
互动问题 8:"为什么写规范要用最强的模型,而不是随便一个模型?"(提示:规范错了,后面全错;规范对了,实现可以降级)
结尾:快速开始
今天就能用的最小SDD流程:
-
创建规范文件
spec.md-
描述功能 + 用户故事 + 验收标准
-
-
创建计划文件
plan.md-
技术选型 + 数据模型 + API设计
-
-
让AI按规范实现
-
把两个文件作为上下文输入
-
进阶工具(可选):
-
GitHub SpecKit:CLI工具,自动化SDD流程
-
/specify、/plan、/tasks命令一键生成文档
总结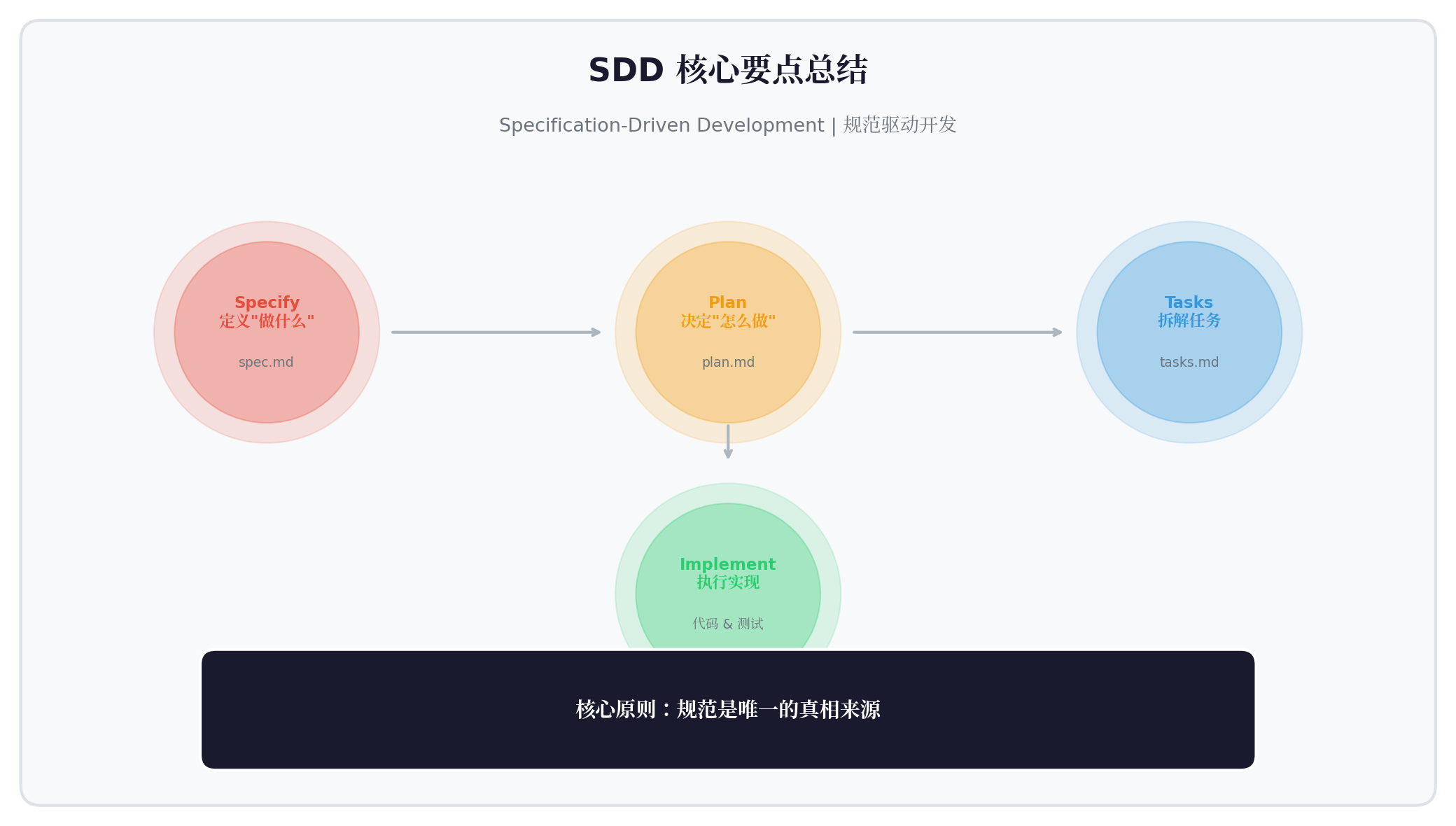
┌─────────────────────────────────────────┐ │ SDD = 用规范驾驭AI,而不是被AI牵着走 │ │ │ │ 1. Specify → 明确"做什么" │ │ 2. Plan → 决定"怎么做" │ │ 3. Tasks → 拆解可执行任务 │ │ 4. Implement→ AI精确执行 │ │ │ │ 核心原则:规范是唯一的真相来源 │ └─────────────────────────────────────────┘
Q & A
最后互动:"大家有什么问题?或者想分享自己用AI编程时遇到的坑?"
附录:参考资料
分享结束,感谢聆听!
附录:互动问题参考答案(演讲者用)
问题1:开场 — "有没有遇到过AI写错功能的情况?"
参考答案:"我相信大家都经历过。问题不在于AI不够聪明,而在于我们给它的指令太模糊。就像你去餐厅只说'来份好吃的',厨师很难猜到你想要宫保鸡丁。SDD就是解决这个问题——先把需求说清楚,再让AI动手。"
问题2:SDD定义 — "日常写代码更接近哪个级别?"
参考答案:"我猜大部分同学都在'代码优先'这一端——想到哪写到哪,让AI自由发挥。这没问题,小脚本、实验性代码完全可以这样。但如果是一个需要维护的功能、团队协作的项目,或者错误代价高的场景(比如涉及支付),我们就需要往右移动——先写规范。
今天我们要学的,就是如何从'代码优先'平滑过渡到'规范优先'。"
问题3:Specify阶段 — "不用GWT格式,AI会怎么理解?"
参考答案:"AI可能会:
做一个简单的表单提交
加上图形验证码
支持手机号登录
用Session还是JWT?它随便选一个
密码错误时告诉用户'密码错了'(泄露了邮箱存在的信息,安全隐患!)
每一个猜测都可能错。而用GWT格式,我们把所有条件、动作、结果都写死了,AI没有猜测空间,只能按规范执行。"
问题4:Plan阶段 — "不写Plan直接写代码,可能会出什么问题?"
参考答案:"可能出现的问题:
问题 后果 AI选了不熟悉的ORM 团队维护困难 数据库字段命名不统一 后续扩展混乱 API路径风格不一致 前端对接麻烦 没考虑高并发 上线后性能瓶颈 密码明文存储 安全事故 Plan阶段就是'技术拍板'阶段。在这个阶段把技术选型、数据模型、API设计定下来,AI在实现时就不会走偏。"
问题5:Implement阶段 — "给规范 vs 直接说需求,效果差异?"
参考答案:
直接说需求:'帮我写个登录功能'
AI输出:一个基础表单,可能缺少错误处理、安全考虑
你需要:反复修改、补充细节、调试2小时
给规范:spec.md + plan.md + tasks.md
AI输出:按验收标准逐条实现,包含所有边界情况
你需要:检查是否满足规范,微调即可
时间对比:直接说需求可能花2小时,给规范可能只花20分钟写文档 + 10分钟检查 = 效率提升4倍。前期多花10分钟写规范,后期节省2小时调试。"
问题6:项目结构 — "项目宪法有用吗?解决什么问题?"
参考答案:"非常有用,它解决两个核心问题:
1. 团队一致性
新成员加入,读一遍constitution.md就知道项目规则
不会出现'有人写测试有人不写'的混乱
2. AI上下文保持一致
每次新开AI会话,把constitution.md作为系统提示词
AI始终遵循同一套规则,不会这次用JWT、下次用Session
项目宪法 = 项目的'操作系统',所有规范都基于它。"
问题7:何时用SDD — "以下场景要不要写规范?(投票)"
参考答案:
场景 答案 理由 A. 写一个计算BMI的小工具 不用 一个提示就能完成,5分钟搞定 B. 实现支付接口 必须写 错误代价极高,涉及资金安全 C. 给页面加个按钮 不用 机械性改动,低风险 D. 设计用户权限系统 必须写 涉及多角色、多权限,逻辑复杂,容易遗漏 总结判断标准:记住一句话——如果AI理解错了你会很烦,那就写规范。如果一句话就能修正,那就跳过。"
问题8:最佳实践 — "为什么写规范要用最强模型?"
参考答案:"因为规范是源头,错误会传导到所有下游。
规范(最强模型)→ 计划 → 任务 → 实现(中等模型)→ 验证(快速模型) ↑_________________________________________________________↓ 如果规范错了,后面全错!类比:
规范 = 建筑蓝图 → 错了整栋楼要推倒
实现 = 工人砌砖 → 按蓝图做,用普通工人就行
验证 = 质量检查 → 快速扫一遍,用实习生也行
资源分配原则:把最贵的算力用在最需要智慧的地方——写规范。"

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)