基于 YOLOv8 的大米杂质检测系统
本项目围绕粮食质检场景,完整实现了从数据集构建、模型训练调优到桌面端系统集成的全流程。核心算法采用 YOLOv8s 目标检测模型,针对大米中常见的五类杂质进行实时识别与定位,最终以 PyQt6 桌面应用的形式完成系统交付。
数据集介绍
类别说明
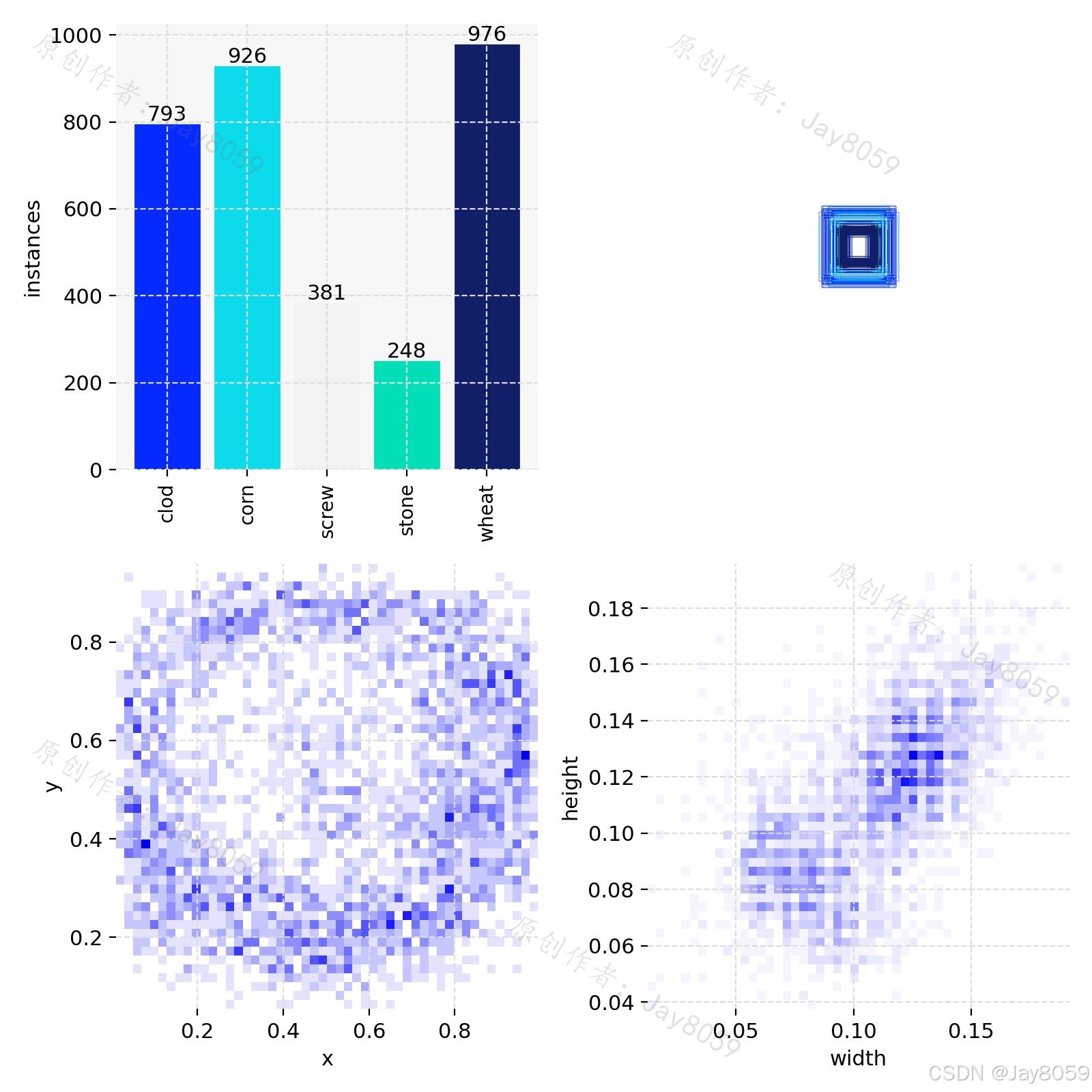
数据集共包含五类目标,均为大米在生产、运输或存储过程中可能混入的杂质或干扰物。
| 类别标识 | 中文名称 | 描述 |
|---|---|---|
| clod | 土块 | 泥土板结形成的不规则颗粒,颜色偏深,边缘粗糙 |
| corn | 玉米粒 | 外形饱满,颜色偏黄,与大米粒大小接近,混入后较难肉眼分辨 |
| screw | 螺丝 | 金属异物,形态规则,属于机械污染类杂质 |
| stone | 石子 | 大小不一的碎石颗粒,颜色多为灰白,硬度高 |
| wheat | 小麦 | 非大米谷物,呈椭圆纺锤形,颜色淡黄 |
数据规模与划分
原始数据共 1007 张 JPEG 图片,每张图片对应一个 YOLO 格式标注文件(.txt),记录各目标的类别编号与归一化包围框坐标。数据集按照 8:2 的比例随机划分,固定随机种子为 42 以保证可复现性,最终得到训练集 806 张、验证集 201 张。
划分后的目录结构符合 ultralytics 的 YOLO 数据集规范,由 src/dataset.py 自动完成文件整理,并生成 dataset.yaml 作为训练配置入口。若目标目录已存在且非空,程序会跳过重复划分,直接复用已有结构。
深度学习开发过程
一、数据集的构建与处理
原始图片统一存放在 data/JPEGImages/,标注文件存放在 data/labels/,类别列表记录在 data/labels/classes.txt。src/dataset.py 负责扫描所有有效的图片-标注对,过滤掉没有对应标注的图片,随机打乱后按比例划分,并复制到 train_result/dataset/ 下的标准 YOLO 目录结构中。
二、模型训练与调优
训练入口为 train.py,模型选用 YOLOv8s,在 ImageNet 预训练权重基础上进行迁移学习。训练过程中启用了多种数据增强策略以提升模型泛化能力,包括随机色调/饱和度/亮度扰动、随机旋转、随机翻转、Mosaic 拼图以及 Mixup 混合增强,有效缓解了样本多样性不足的问题。
训练采用早停机制,当验证集 mAP 连续 30 个 epoch 没有提升时自动终止,避免过拟合并节省计算资源。每隔 10 个 epoch 自动保存一次中间权重,最终 best.pt 和 last.pt 分别保存精度最高和最后一轮的模型。
三、系统集成与功能开发
训练完成后,src/visualizer.py 读取 results.csv 生成七张单指标曲线图和一张总览图,直观呈现收敛过程。桌面端系统以 app.py 为入口,PyQt6 构建多页面界面,SQLite 存储用户账号与检测历史,YOLOv8 推理封装在 ui/utils/detector.py 中,通过 QThread 实现异步检测,保证界面流畅不卡顿。
训练配置与超参数
| 参数 | 值 | 说明 |
|---|---|---|
| 基础模型 | yolov8s.pt | small 版本,精度与速度的平衡点 |
| 最大轮次 | 100 | 配合早停使用 |
| 输入尺寸 | 640×640 | YOLOv8 默认推荐分辨率 |
| 批大小 | 16 | 适配 12GB 显存的 3060 |
| 初始学习率 | 0.01 | 余弦退火调度 |
| 学习率衰减 | 0.01(乘数) | 最终 lr = lr0 × lrf |
| 动量 | 0.937 | SGD 动量 |
| 权重衰减 | 0.0005 | L2 正则 |
| 预热轮次 | 3 | 防止早期梯度爆炸 |
| 早停耐心 | 30 | 连续 30 轮无提升则停止 |
| Box Loss 权重 | 7.5 | 定位精度优先 |
| Cls Loss 权重 | 0.5 | |
| DFL Loss 权重 | 1.5 | |
| Mosaic 增强 | 1.0 | 全程启用 |
| Mixup 增强 | 0.1 | 低比例混合 |
| 随机旋转 | ±5° | |
| 随机缩放 | 0.5 | |
| 水平翻转 | 0.5 | |
| 垂直翻转 | 0.1 |
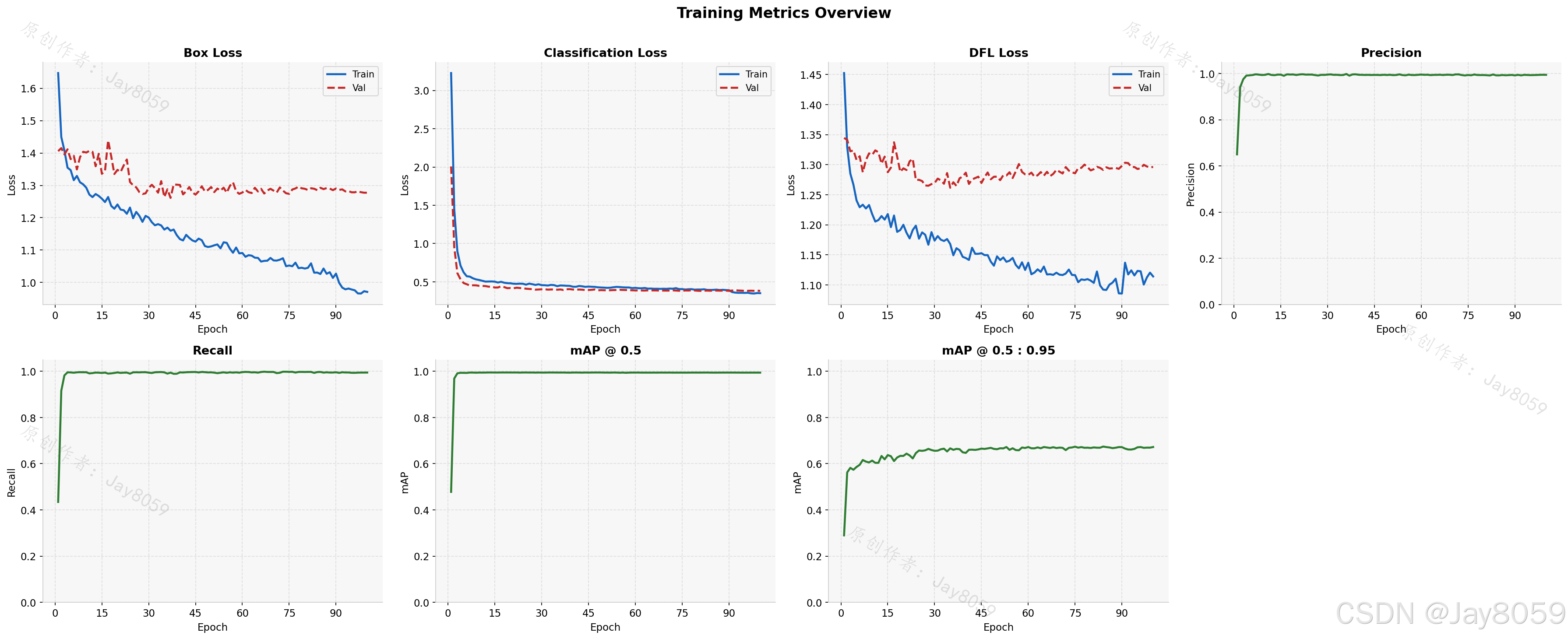
训练指标与实验结果
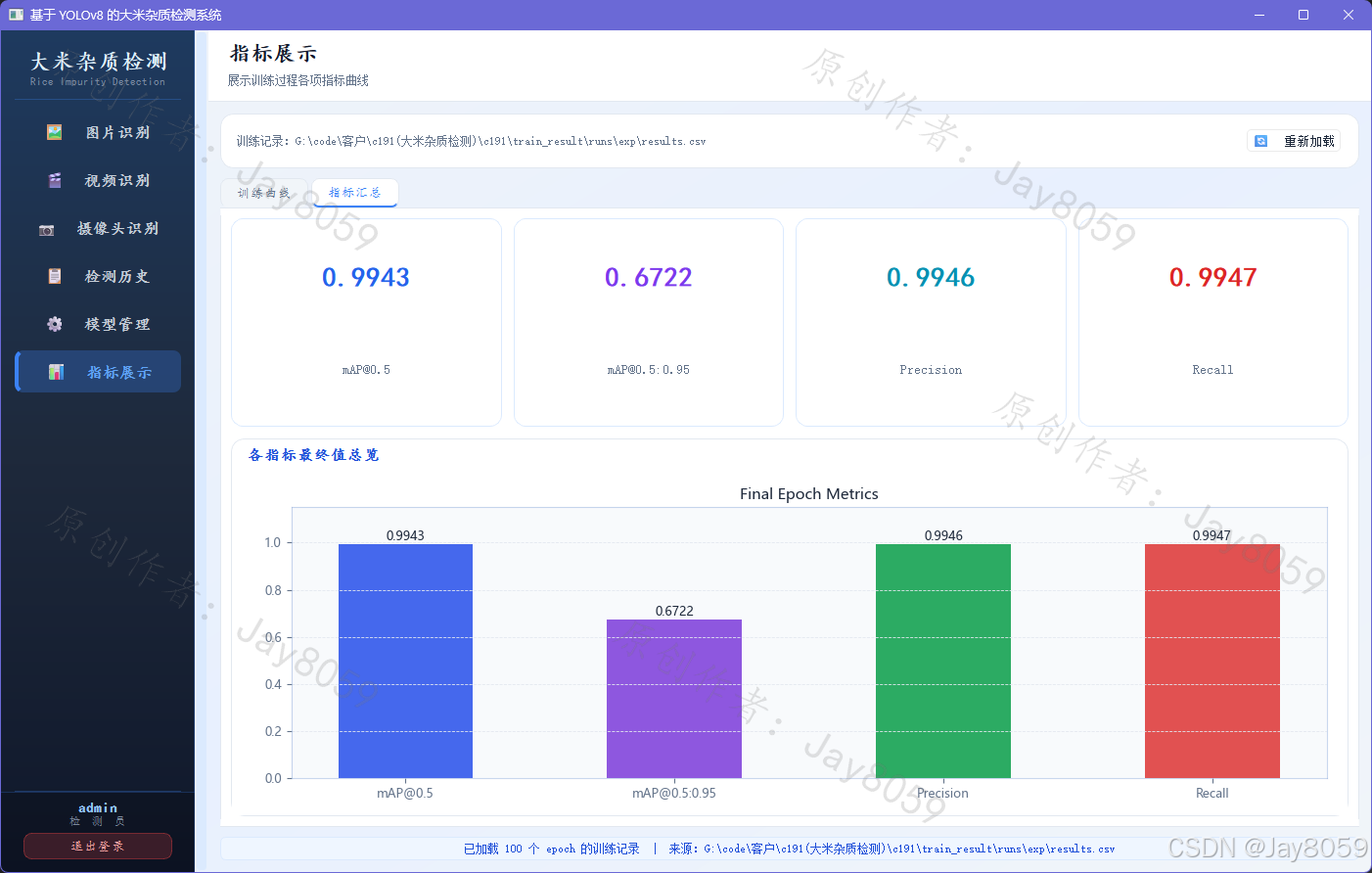
训练共运行 100 个 epoch,全程未触发早停,说明模型在此数据集上仍有收益空间。最终 epoch 在验证集上的核心指标如下:
| 指标 | 最终值 |
|---|---|
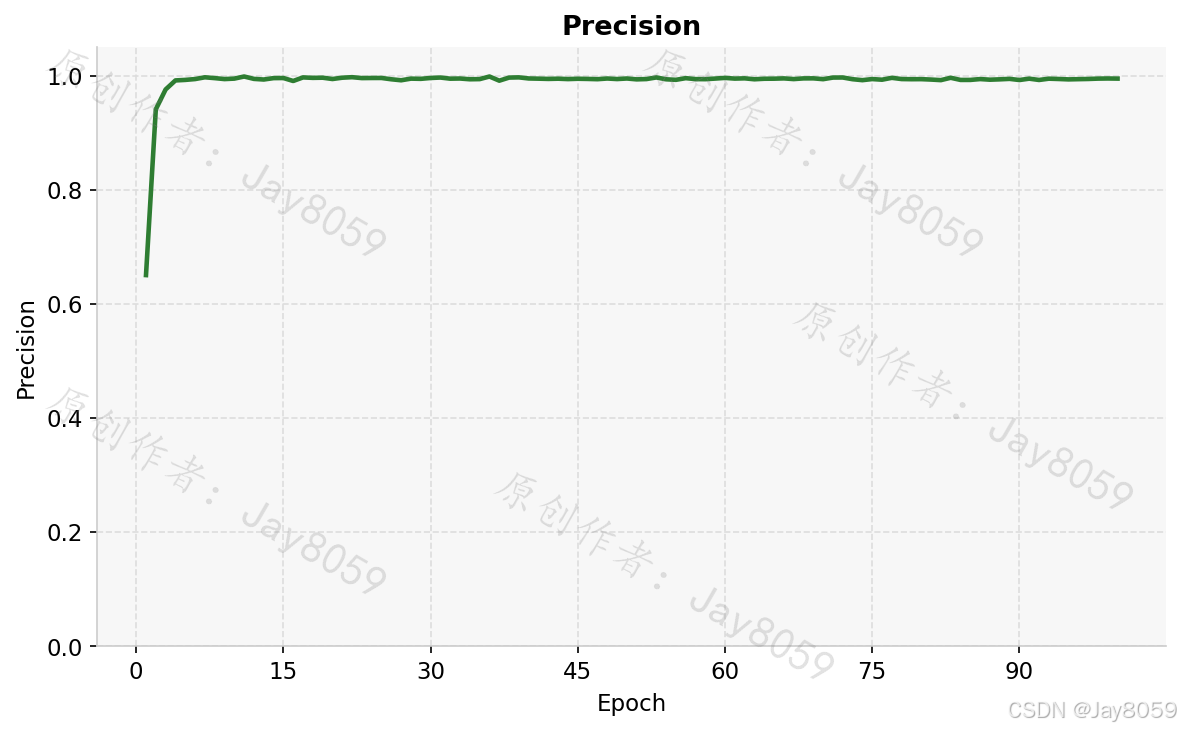
| Precision | 0.9946 |
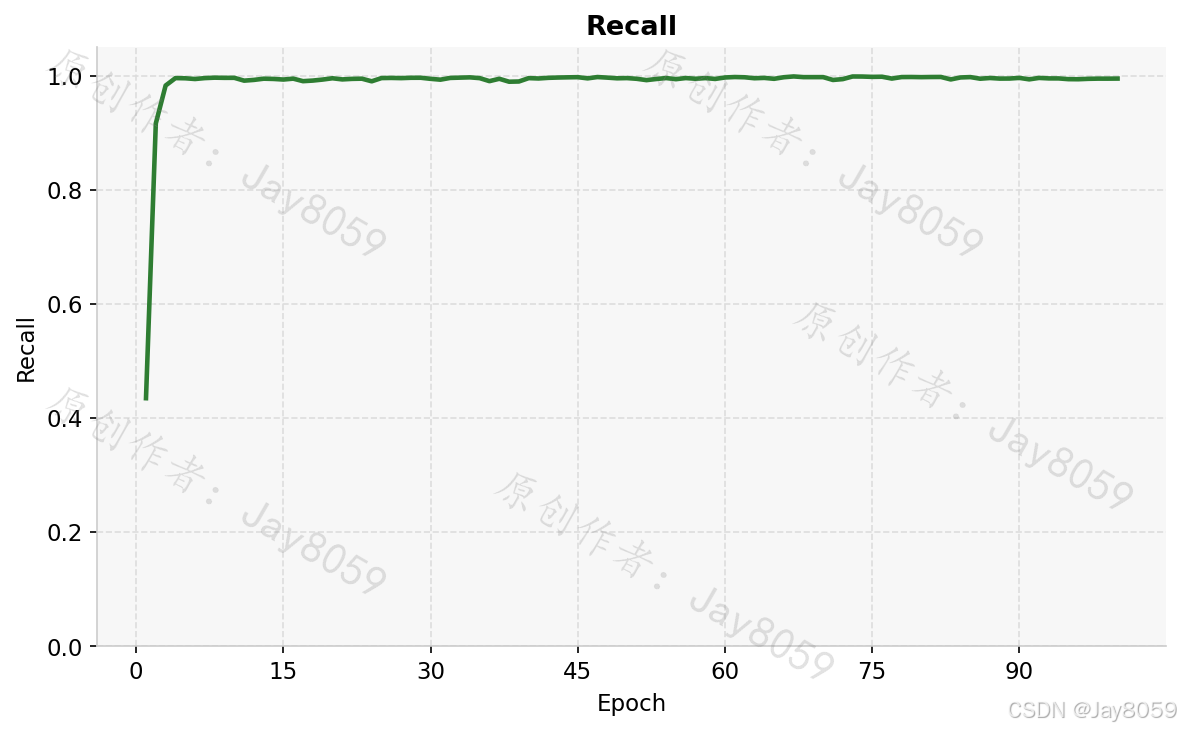
| Recall | 0.9947 |
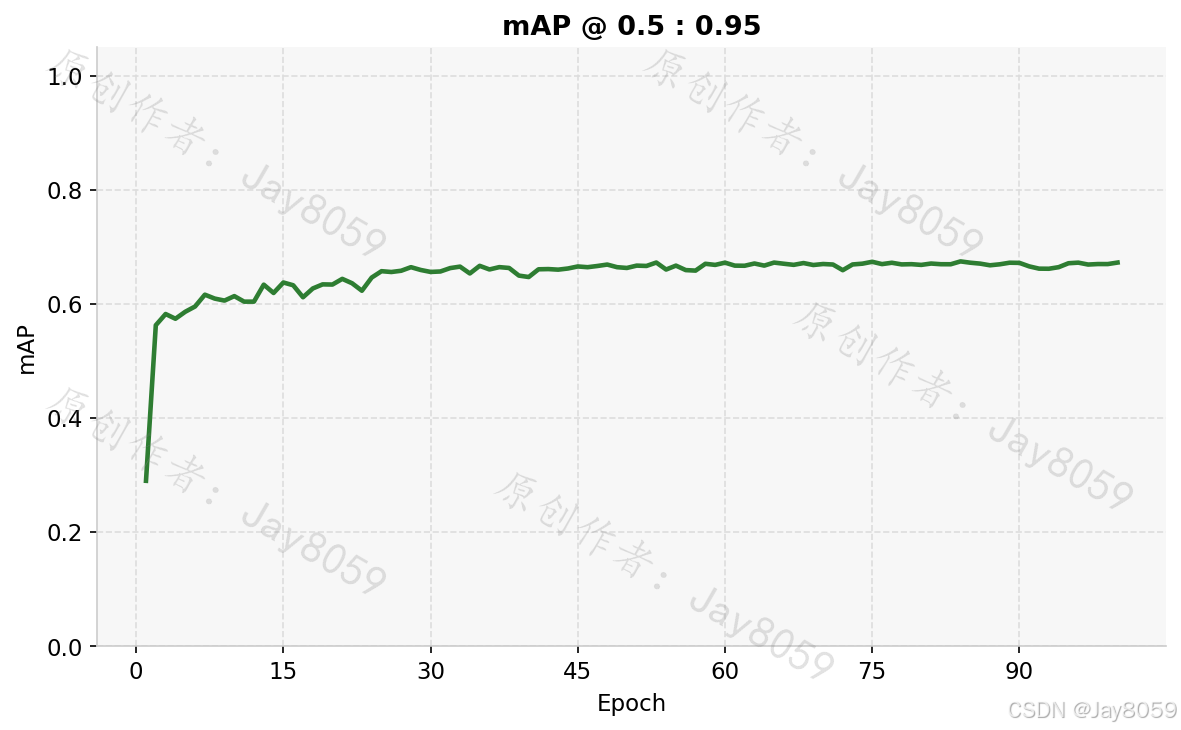
| mAP@0.5 | 0.9943 |
| mAP@0.5:0.95 | 0.6722 |
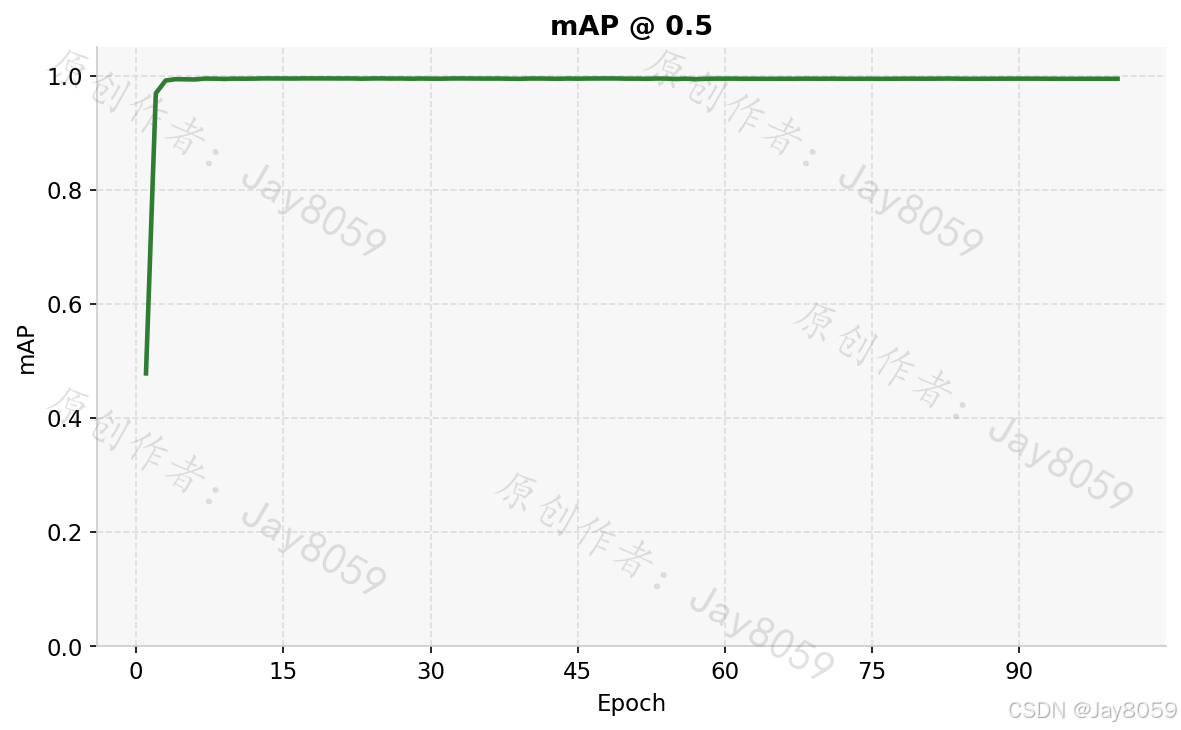
Precision 和 Recall 均接近 0.995,mAP@0.5 同样超过 0.994,说明模型在 IoU=0.5 阈值下对五类杂质的识别近乎完整;mAP@0.5:0.95 约为 0.672,反映了在更严格的定位精度要求下模型仍保持较高水平。
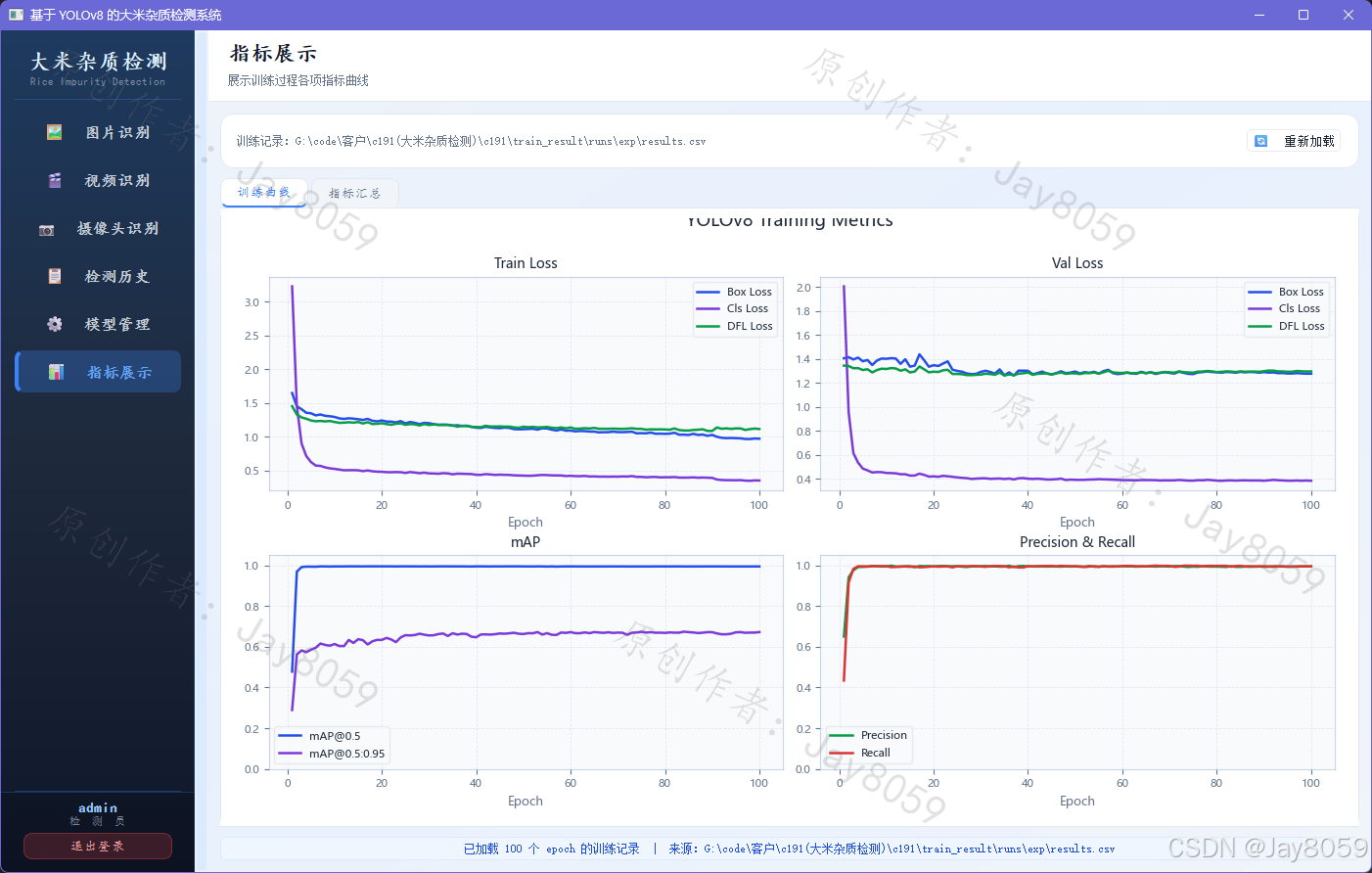
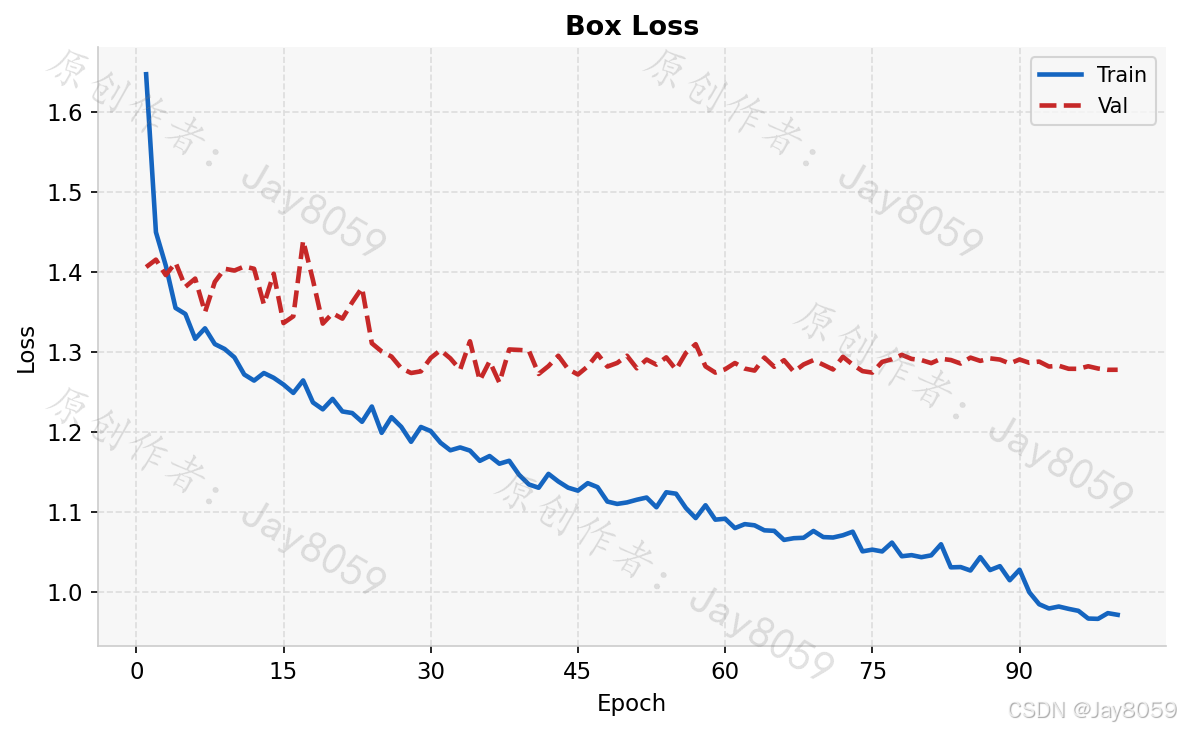
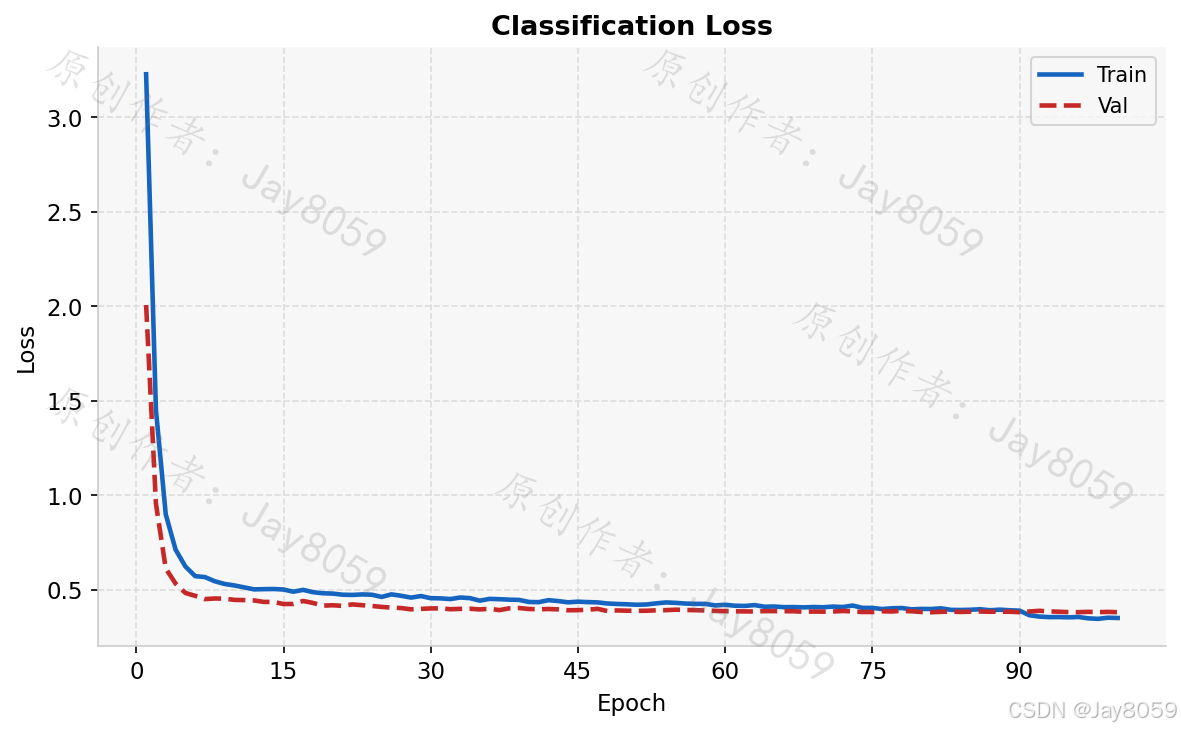
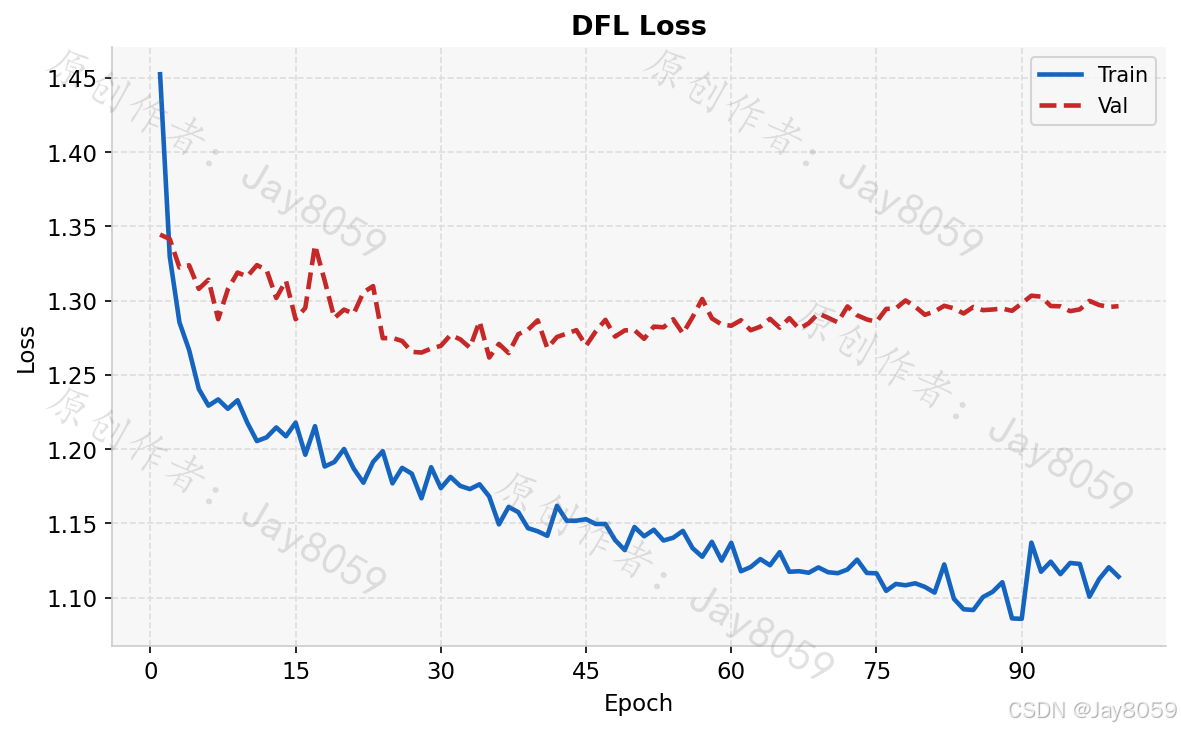
整体训练曲线呈现良好的收敛态势:训练损失(Box/Cls/DFL)在前 20 个 epoch 快速下降,此后平稳趋近;验证损失与训练损失走势基本一致,没有出现明显的过拟合分叉,表明数据增强策略和正则化配置合理。
可视化图表说明
训练结束后,src/visualizer.py 会在 train_result/charts/ 下自动生成以下图表:
box_loss.png 展示包围框回归损失(训练集与验证集)随 epoch 的变化,用于判断定位能力是否充分学习。cls_loss.png 对应分类损失,下降越平滑说明类别区分越稳定。dfl_loss.png 为 Distribution Focal Loss,是 YOLOv8 特有的边框分布损失,辅助模型学习更精细的坐标分布。
precision.png 和 recall.png 分别展示精确率和召回率的 epoch 曲线,两者均接近 1.0 且上升平稳,说明模型几乎没有漏检和误检。map50.png 对应 IoU=0.5 时的 mAP,map50_95.png 对应从 IoU=0.5 到 0.95 每隔 0.05 取平均的综合 mAP,后者要求更严格的定位精度,通常比 mAP@0.5 低 20~30 个百分点属于正常现象。
summary.png 是总览图,将全部指标的最终值以柱状图汇总呈现,方便一眼评估整体效果。
此外,系统【指标展示】页面会直接在 UI 内嵌入训练曲线与汇总图表,无需单独打开图片文件查看。
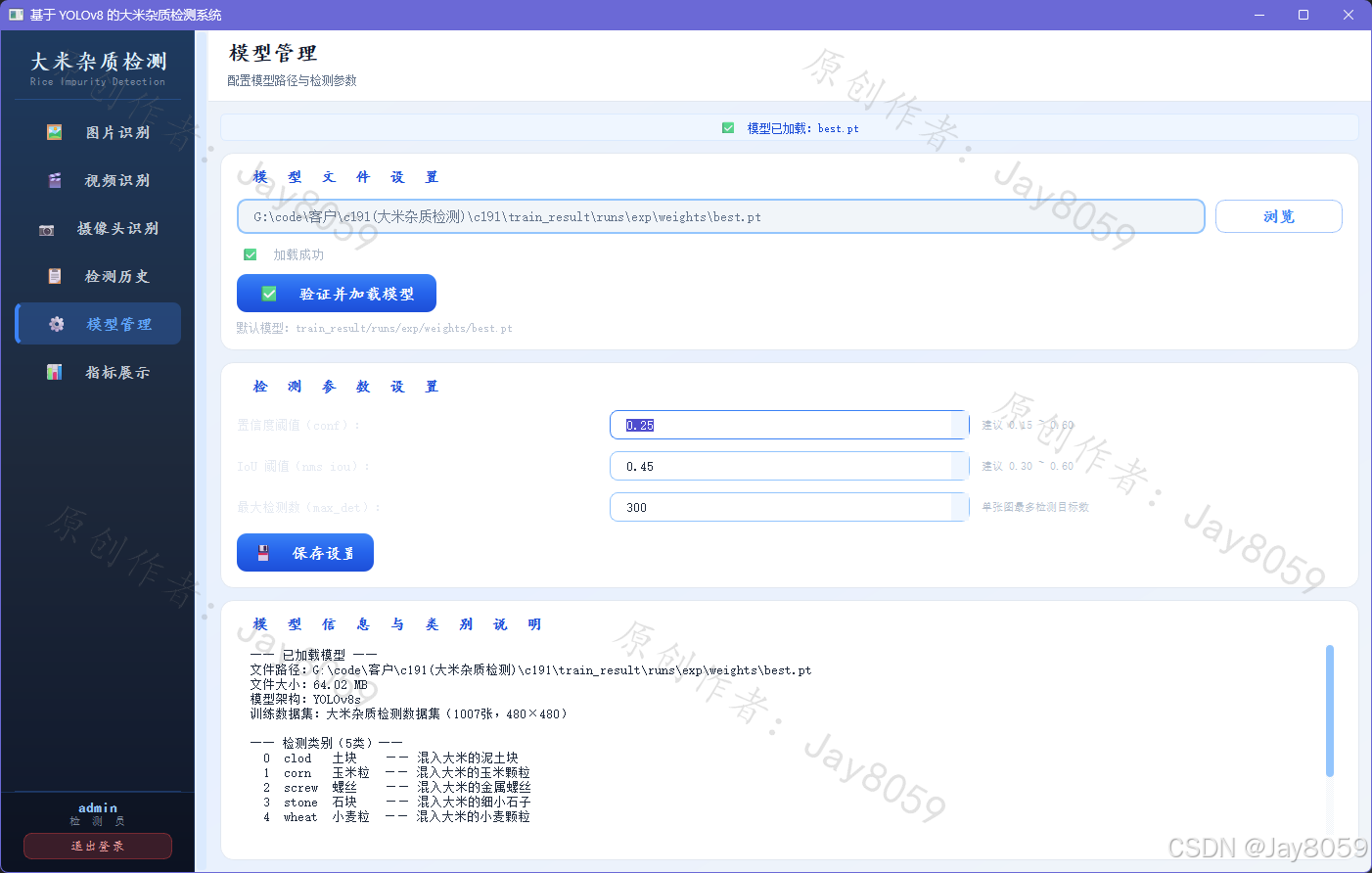
系统功能模块
系统登录界面支持账号注册与登录,首次运行会自动初始化 SQLite 数据库并创建默认账号(admin / admin123)。登录成功后进入主界面,左侧为导航侧栏,右侧为功能区,共六个页面:
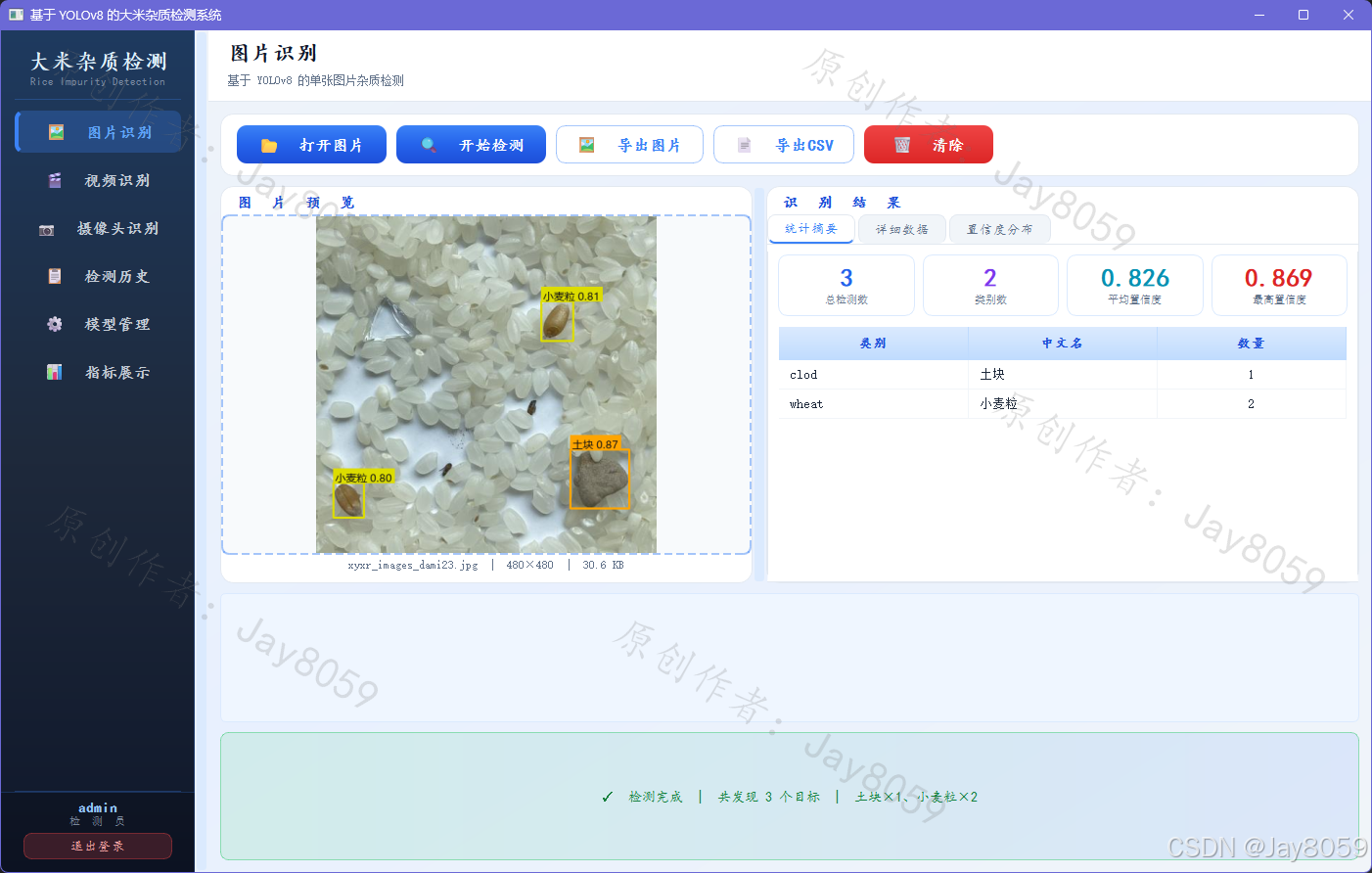
图片识别页支持本地图片的打开与检测,检测完成后在预览区域叠加标注框,同时以统计摘要(目标总数、类别数、平均/最高置信度)、逐目标详细数据表和置信度分布直方图三个 Tab 展示结果,支持导出带标注图片和 CSV 明细文件。
视频识别页逐帧处理视频文件,用户可设置每 N 帧检测一次以平衡速度与精度,实时显示当前帧目标信息和本次运行的累计统计,处理完毕自动保存至历史记录。
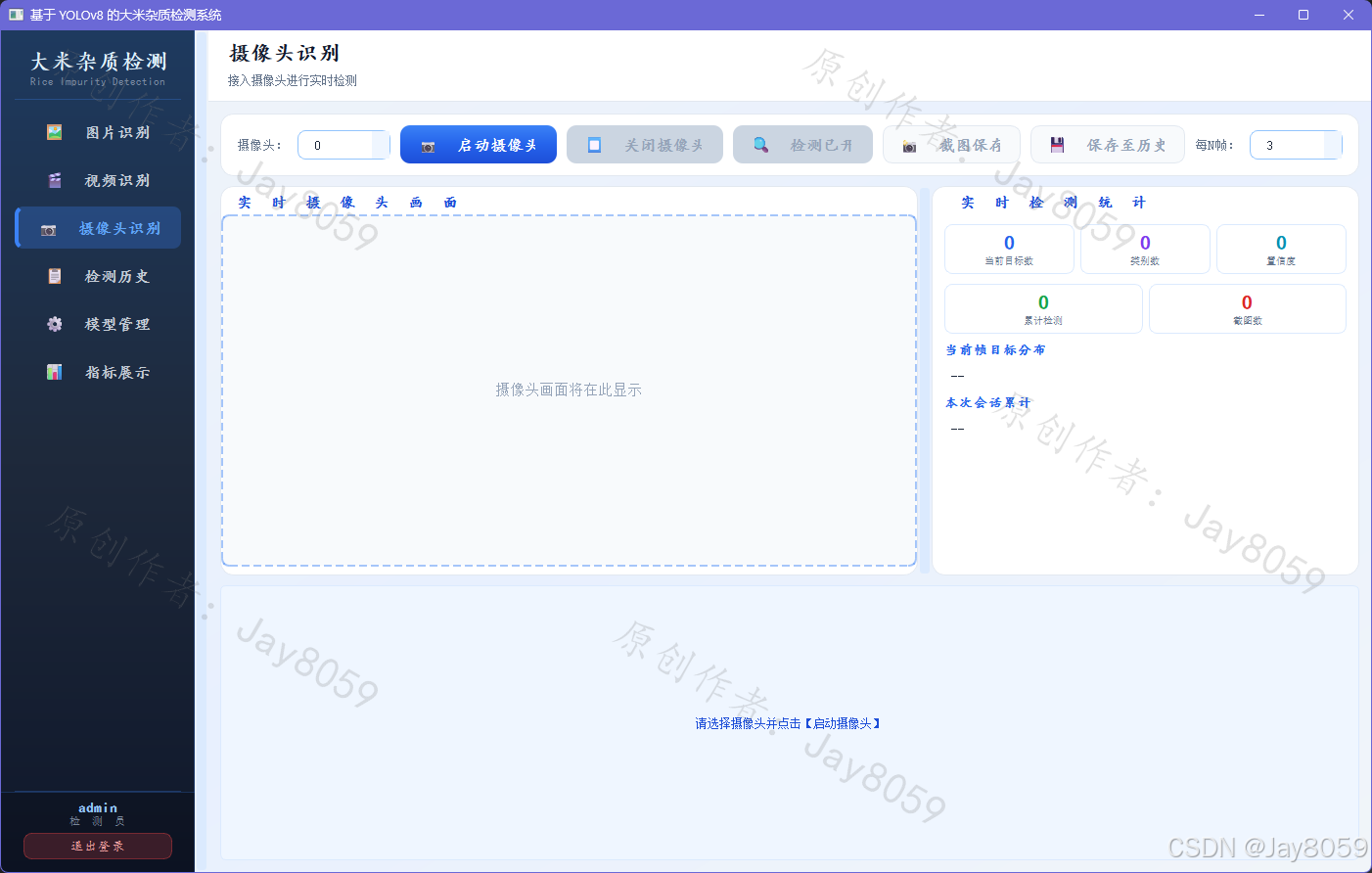
摄像头识别页接入本地摄像头进行实时推流检测,支持随时截图保存、手动开关检测以及将本次会话记录存入历史。
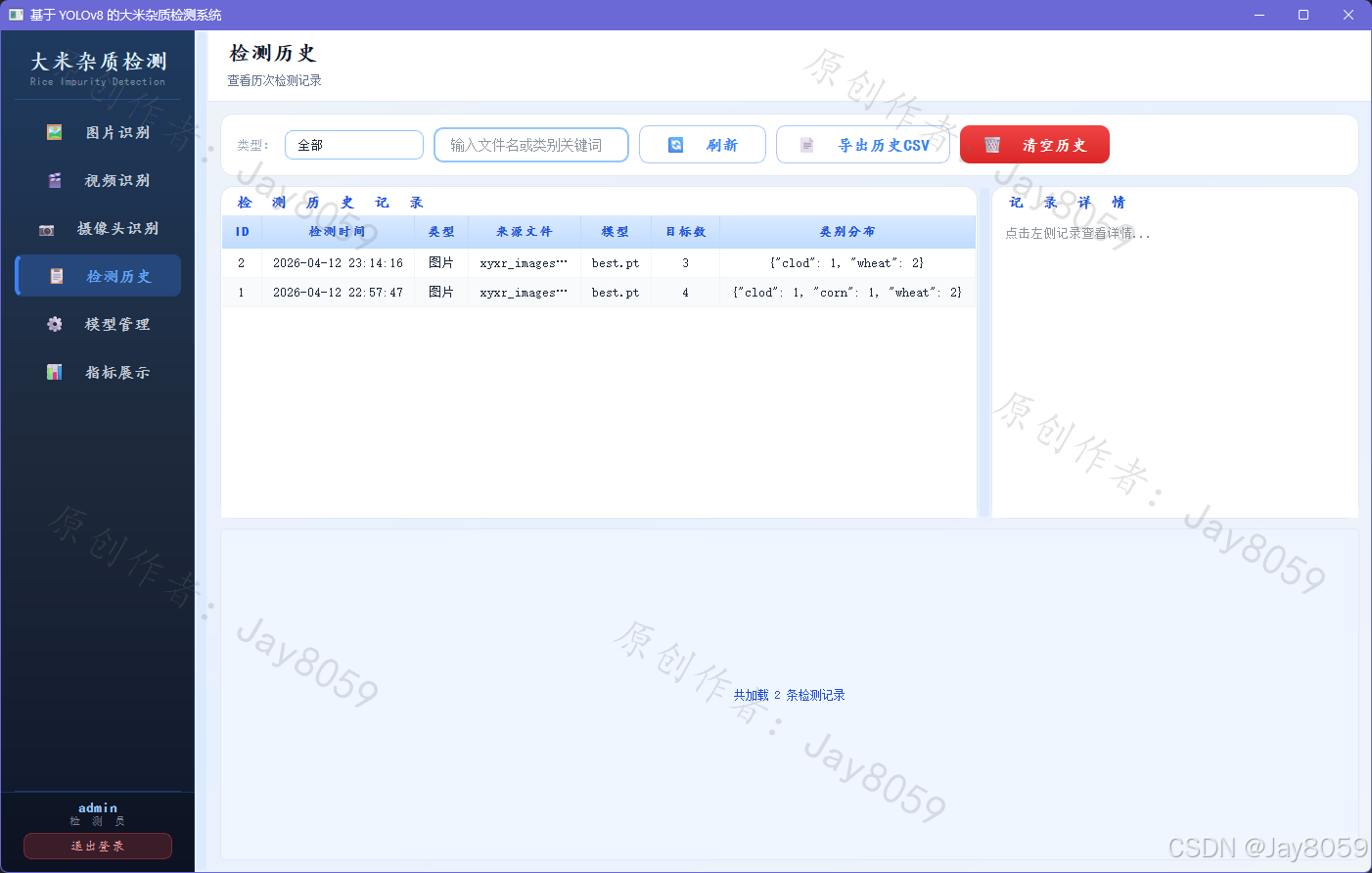
历史记录页以表格形式展示所有图片/视频/摄像头检测记录,支持按类型筛选,可随时清空历史。
指标展示页嵌入训练曲线图(训练/验证损失、mAP、Precision & Recall)和最终指标汇总柱状图,点击【重新加载】可刷新最新训练结果。
模型管理页显示当前加载模型的路径、类别数、类别列表等元信息,支持手动切换模型权重文件,置信度阈值和 IoU 阈值均可实时调整。
技术栈
| 方向 | 组件 |
|---|---|
| 目标检测 | YOLOv8(ultralytics) |
| 深度学习框架 | PyTorch |
| 图像处理 | OpenCV、Pillow |
| UI 框架 | PyQt6 |
| 图表可视化 | Matplotlib |
| 数据处理 | Pandas、NumPy |
| 数据存储 | SQLite(Python 内置 sqlite3) |
| 配置解析 | PyYAML |
| 运行环境 | Python 3.9、CUDA、Windows |
项目结构
c191/ ├── app.py # 桌面端入口 ├── train.py # 训练流程入口 ├── yolov8s.pt # YOLOv8s 预训练权重 │ ├── data/ # 原始数据集 │ ├── JPEGImages/ # 全部原始图片(1007 张) │ ├── labels/ # YOLO 格式标注文件 │ │ └── classes.txt # 类别列表 │ └── README.md # 数据集说明文档 │ ├── src/ # 训练相关模块 │ ├── dataset.py # 数据集划分与 YAML 生成 │ ├── trainer.py # YOLOv8 训练封装 │ └── visualizer.py # 训练指标可视化 │ ├── ui/ # 桌面应用模块 │ ├── login_window.py # 登录/注册窗口 │ ├── main_window.py # 主窗口框架与导航 │ ├── pages/ # 各功能页面 │ │ ├── image_page.py # 图片识别 │ │ ├── video_page.py # 视频识别 │ │ ├── camera_page.py # 摄像头实时检测 │ │ ├── history_page.py # 历史记录 │ │ ├── metrics_page.py # 训练指标展示 │ │ └── model_page.py # 模型管理 │ └── utils/ # 公共工具 │ ├── detector.py # YOLOv8 推理封装 │ ├── workers.py # QThread 异步工作线程 │ ├── database.py # SQLite 数据库操作 │ └── styles.py # QSS 样式生成 │ └── train_result/ # 训练产物(自动生成) ├── dataset/ # 划分后的数据集 + dataset.yaml ├── runs/exp/ # 训练日志、权重、内置图表 │ ├── weights/ │ │ ├── best.pt # 最优权重 │ │ └── last.pt # 最后一轮权重 │ └── results.csv # 逐 epoch 训练记录 └── charts/ # 自定义可视化图表(7 张 + 1 张总览)
启动说明
环境安装
Python 版本要求 3.9,CUDA 版本需与 PyTorch 匹配(推荐 CUDA 11.8 或 12.x)。依赖项均列在 requirements.txt,在对应虚拟环境中执行安装即可。
pip install -r requirements.txt
如需 GPU 加速,建议单独先安装对应版本的 torch 和 torchvision,再安装其余依赖。
训练(可选)
如需重新训练,直接运行:
python train.py
程序会依次完成数据集准备、模型训练和可视化图表生成,所有产物自动保存至 train_result/。训练参数可在 train.py 顶部的 TRAIN_CFG 字典中修改。
若只需要基于已有 results.csv 重新生成图表:
python src/visualizer.py
启动桌面应用
python app.py
系统默认加载 train_result/runs/exp/weights/best.pt 作为检测权重。首次启动会自动建库,默认账号为 admin,密码 admin123。进入系统后可在【模型管理】页面切换为其他权重文件。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)