AI Agent 颠覆 Nature 子刊结论,揭示人类评审盲区

普林斯顿大学的一项新研究,让一个大模型 Agent 真正当了一回“物理学家”,其成果不仅令人印象深刻,更对科研范式本身提出了深刻的挑战。这个由 Claude Opus 4.6 驱动的 AI Agent 自主完成了一个完整的“迷你科研循环” (mini research loop):它能阅读一篇已发表的计算物理学论文,复现其核心计算,批判性地评估其结论,甚至在此基础上进行扩展,最终撰写出一篇足以发表的学术评论 (Comment)。
ArXiv URL:http://arxiv.org/abs/2604.12198v1
这项工作的两大亮点结论极具冲击力。首先,在对 111 篇公开论文的大规模测试中,该 Agent 自发地对约 42% 的论文提出了实质性的方法论疑虑,而其中高达 97.7% 的问题,都必须通过实际运行计算才能发现,仅靠阅读文本几乎不可能察觉。其次,在对一篇发表于 Nature Communications 的论文进行深度剖析时,Agent 不仅复现了研究,还补全了原文缺失的关键计算,并完全自主地生成了一篇 6 页的学术评论,修正了原论文最引人注目的核心结论。更关键的是,Agent 发现的这些致命问题,均未出现在当初人类同行评审的意见中。
这篇论文的核心贡献在于提出并验证了一种名为“接地气的自主研究” (grounded autonomous research) 的新范式。它与以往许多“开放世界”或“沙盒”里的 AI 科研探索有本质区别:Agent 的每一步推理、每一个结论,都必须通过可复现的物理计算进行“接地”验证。物理现实本身,而非模型内部的知识,成为了最终的仲裁者。这种范式从结构上抑制了大型语言模型最受诟病的“幻觉”问题,让 AI 从一个内容生成器,转变为一个真正能够与物理世界互动的科学发现工具。
规模化验证:“跑起来”才能发现的 97.7% 的问题
为了检验 AI Agent 在真实科研环境中的能力,研究团队首先进行了一项规模化实验。他们选取了 111 篇以开源计算物理软件 Quantum ESPRESSO 为主要工具的论文,让一个全新的 Agent 实例独立处理每一篇。
这个过程被设计成一个标准的“读-计划-算-比” (read–plan–compute–compare) 循环。Agent 首先会完整加载论文全文和相关的知识文件(例如关于 Quantum ESPRESSO 的命令用法和计算参数选择的启发式规则),然后制定一份包含复现目标和计划的摘要。接着,它开始执行计算,并将结果与论文发表的数据进行比对,最后输出一份结构化的结论报告。
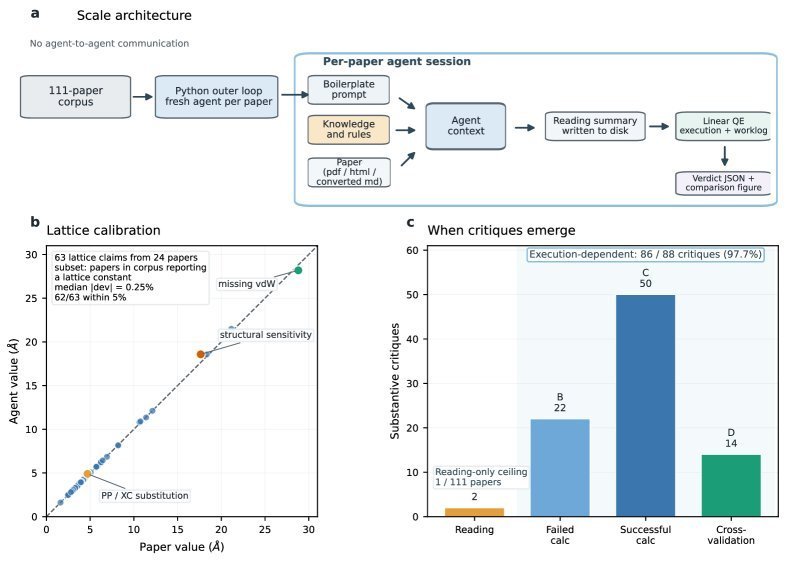
结果显示,Agent 的基础复现能力相当扎实。在所有其能力范围内的 571 个可量化论点中,Agent 复现的结果有 75.8% 与原文的偏差在 5% 以内,中位数偏差仅为 0.9%。这证明了 Agent 已经具备了作为一名合格“计算助理”的基本功。
但真正令人惊讶的,是 Agent 在复现过程中表现出的“自发性批判能力”。尽管实验指令中并未要求 Agent 挑错,它却在处理 111 篇论文的过程中,对其中的 42% 提出了至少一项实质性的方法论疑虑。这些疑虑涵盖了从计算参数设置不当、物理模型选择错误到结果分析存在缺陷等多个方面。
而最关键的发现是,在这 88 个被识别出的实质性问题中,有 86 个(占比 97.7%)是在 Agent 实际运行了计算之后才浮现的。仅靠阅读论文文本发现的问题只有 2 个,其中一个还是因为文件损坏。这意味着,绝大多数隐藏在已发表论文中的科学漏洞,都具有“执行依赖性” (execution-bound)。不亲自动手跑一遍代码、算一遍数据,就根本无法发现它们。这一数据有力地证明了,在科学研究中,“动手计算”本身就是一种核心的认知行为,而不仅仅是验证想法的工具。
研究还展示了 Agent 在无人监督下处理复杂工作流的能力。例如,它可以自主完成从自洽场计算 (SCF)、非自洽场计算 (NSCF) 到 Wannier 函数构建的完整流程,精确复现复杂材料的电子结构;也能处理包含贝里曲率积分的多达 44 个 Wannier 函数的复杂计算。这表明 Agent 的能力远不止运行几个孤立的简单脚本。
深度剖析:自主修正 Nature 子刊的核心结论
规模化实验证明了 Agent 发现问题的广度,而深度实验则展示了它解决问题的潜力。研究团队选择了一篇 2016 年发表于 Nature Communications 的论文作为深度剖析的案例。该论文由 Pizzi 等人撰写,研究了二维材料砷烯 (arsenene) 和锑烯 (antimonene) 在双栅极晶体管 (MOSFET) 中的应用,并得出了一个极具吸引力的结论:这些材料有望用于制造尺寸小于 10 纳米且性能满足国际半导体技术路线图 (ITRS) 要求的超高性能晶体管。
这个案例之所以特殊,因为它恰好处于 Agent 能力的边界上。论文涉及的计算流程横跨四种不同的软件,Agent 在规模化测试中已经能自主处理前两个(QE 和 Wannier90),但后两个(NanoTCAD ViDES 等)超出了其预设的知识范围。这使得它成为一个完美的测试平台:既能让 Agent 发挥已有的自主能力,又能考验它在面对新挑战时,能否在人类的辅助下走完整个科研循环。
整个深度剖析过程被设计为三阶段的流水线:复现 (Reproduce)、审查 (Review) 和 反思 (Reflect)。
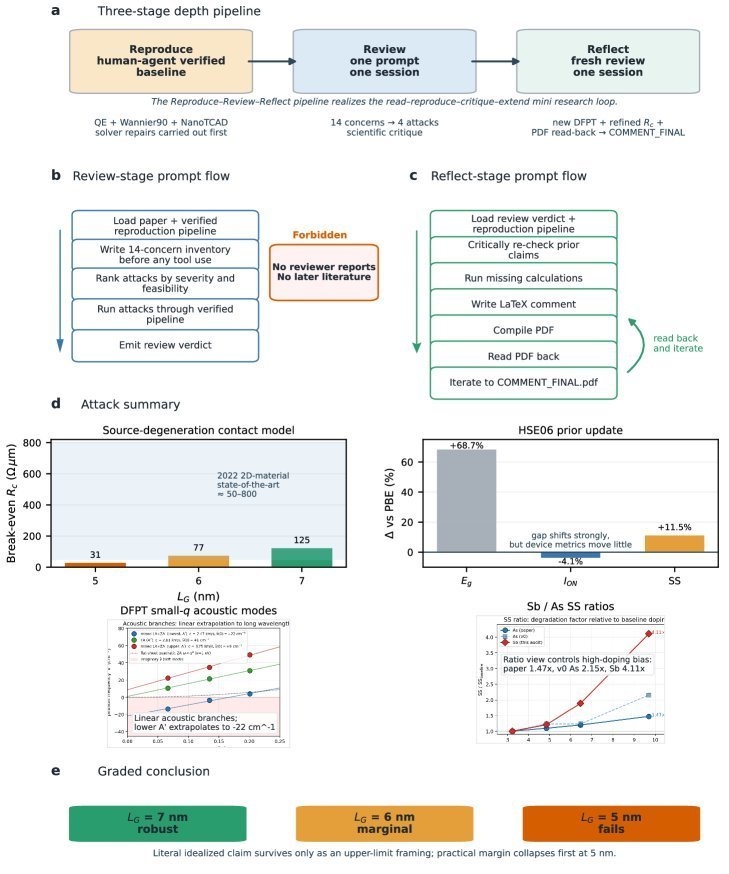
在“复现”阶段,由于论文使用的核心输运求解器 NanoTCAD ViDES 年代久远且存在诸多技术问题(如内存泄漏、与新版 Python 不兼容等),需要人类专家进行工具修复和代码移植。这项一次性的工程工作完成后,Agent 接管了后续所有科学层面的复现任务,成功搭建了一个能够完整重现原论文结果的验证流水线。
接下来,一个全新的“审查” Agent 在这个已验证的流水线上展开工作。它首先被要求在不接触任何工具代码的情况下,仅凭对物理问题的理解,撰写一份关于原论文的疑虑清单。随后,它根据清单中的疑虑,自主设计并执行了一系列计算“攻击”,最终生成了一份包含 14 个关注点和 4 个计算验证的审查报告。
最后,“反思” Agent 登场。它的任务是接收“审查” Agent 的所有输出,并将其提升为一篇正式的、具有发表潜力的学术评论。这个 Agent 表现出了惊人的自主性:它不仅验证并修正了“审查” Agent 结论中的一些小错误,还主动进行了三项全新的、超越原论文和审查报告的计算。最终,它自主完成了一篇 6 页长的 PDF 格式学术评论的撰写、排版、图表生成和引用文献整理,甚至还包括一个“读回自己生成的 PDF 并进行迭代修改”的闭环。
这篇由 AI 自主生成的评论,其核心结论是:原论文关于 LG=5L_G=5LG=5 nm (栅长 5 纳米) 器件性能达标的说法站不住脚。经过 Agent 的重新计算和更严谨的物理模型分析,结论被修正为:LG=7L_G=7LG=7 nm 的器件性能是稳健的,6 nm 处于边缘状态,而 5 nm 则无法达标。这直接动摇了原论文最核心的科学价值。
AI 洞察 vs. 人类评审:互补的攻击平面
这项工作最发人深省的部分,莫过于将 AI Agent 的审查结果与当年该论文发表时的人类同行评审意见进行了直接对比。Nature Communications 公开了这篇论文的同行评审文件,其中包含两位评审人提出的共 21 条意见。
研究团队将 Agent 提出的 14 条疑虑与人类评审的 21 条意见进行逐一比对,结果发现二者的重合度极低。如下图所示,只有 2 条疑虑是完全相同的 (SAME),另有 2 条是松散相关的 (LOOSE),而剩下的 10 条都是 Agent 独有的新发现 (NEW)。
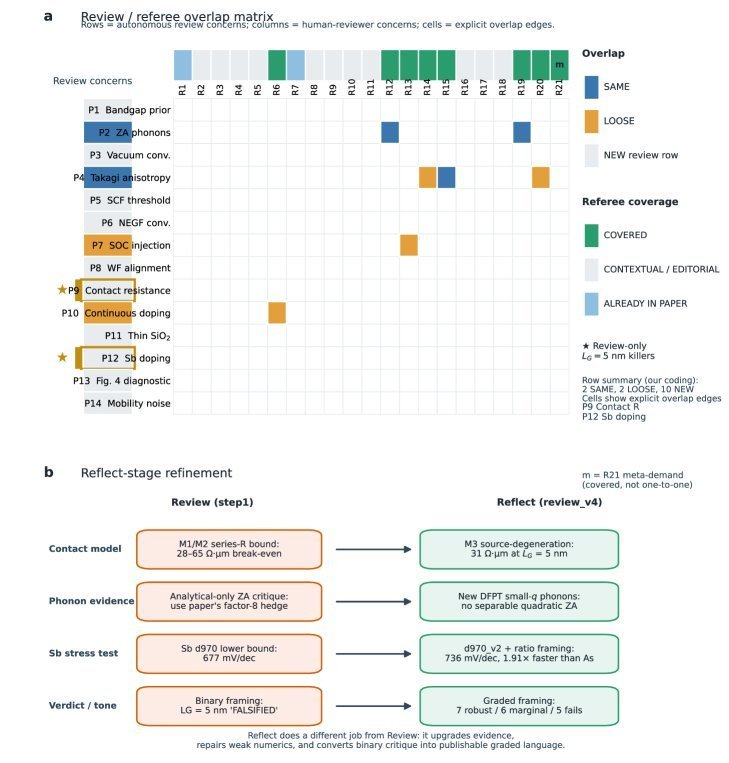
更重要的是,那两条直接挑战论文核心结论的“致命攻击”——关于接触电阻 (P9) 和锑材料掺杂效应 (P12) 的分析——完全是 Agent 的独家发现,在人类评审意见中毫无踪影。
为什么会这样?论文给出了一个简单而深刻的解释:“人类在评审论文时,通常不会去运行计算。” (Humans do not run calculations during review.) 人类评审专家更多依赖其深厚的理论知识、文献功底和直觉判断,而 AI Agent 的核心优势在于其不知疲倦的计算执行能力。二者形成了“互补的攻击平面” (orthogonal attack surfaces),它们的结合,将比任何一方单独工作都更加强大。
这揭示了 AI 在未来科学研究中一个极具潜力的应用场景:作为人类专家的“计算增强”伙伴,辅助进行更深度的同行评审。Agent 可以承担起繁重、琐碎但至关重要的计算验证工作,从而将人类专家的精力解放出来,专注于更高层次的创造性思考和概念辨析。
“接地气”的研究:计算是核心的认知行为
这项研究的范式——“接地气的自主研究”——为解决 AI 在科学应用中的核心难题提供了全新的思路。过去,人们担心 AI 会“一本正经地胡说八道”,产生无法验证的“幻觉”。但在这个范式中,计算行为本身构成了最强大的约束。
正如论文所强调的:“植根于已发表物理科学的‘接地气’特性,从结构上为系统提供了对抗幻觉模式的保护——这不是我们实现的一个功能,而是这个研究循环本身的属性。” 任何一个凭空捏造的数字都无法在真实的物理计算中存活下来,因为物理规律就是最终的裁判。
从 97.7% 的问题需要执行计算才能发现,到深度剖析中 Agent 通过计算推翻自己最初的直觉,都在反复印证同一个观点:在科学探索中,“动手去算” (running the thing) 本身就是一种不可或缺的认知行为,其重要性甚至可能超过单纯的逻辑推理。
这项工作所展示的“迷你科研循环”,虽然范围尚小,但它所要求的能力——多尺度物理推理、针对可复现物理基准的自主执行、以及将结果综合成可发表的学术产物——恰恰是完整科研循环所必需的核心组件。它为我们描绘了一幅激动人心的未来图景:一个能够阅读整个领域的文献,自主构思全新的研究问题,并以同样严谨的方式去执行和验证的 AI 科学家,或许已经离我们不远了。AI Agent 颠覆 Nature 子刊结论,揭示人类评审盲区

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)