人工智能学习笔记(一)AI大模型基础篇
1、人工智能发展历程
符号注意
连接主义
感知机,
反向传播,验证,可以提高准确率
2、提示词Prompt
六大因素,最好是都用上,这样可以更精确地通过对话大模型获取结果。如果是简单的提问,倒没必要。可以根据实际情况优化提示词。
可以参考:
https://www.promptingguide.ai/zh
目前国内主流的对话大模型有:
https://yuanbao.tencent.com/chat
MiniMax
智谱AI:https://open.bigmodel.cn/console/overview
面壁智能
知乎直答
3、大模型底层运行机制:
3.1、Tokens是通用货币,需要付费才能调用大模型产商的接口,联想到之前的NLP,hanlp怎么分词的。
Tokens的计费标准:
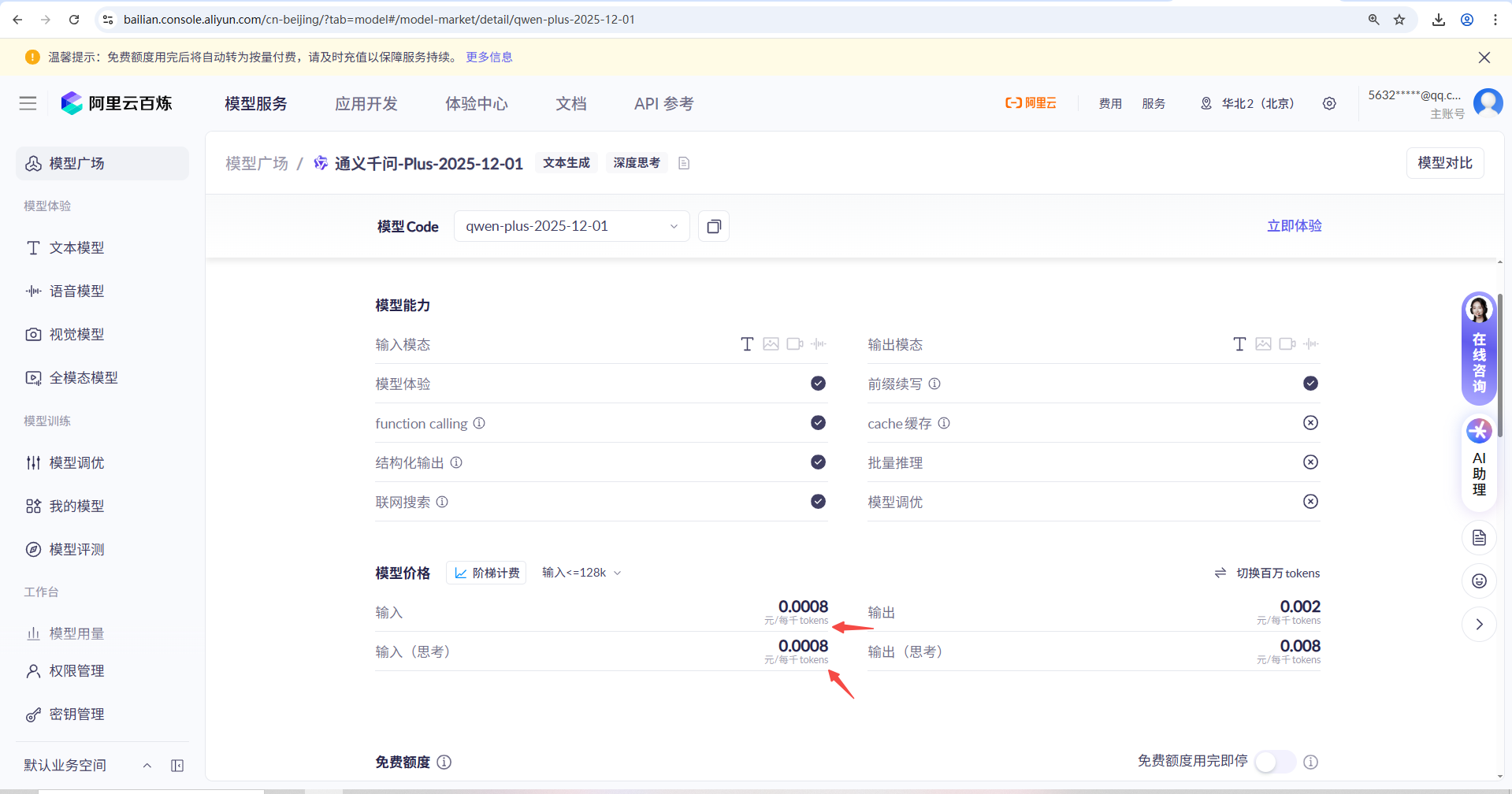
怎么使用代码获取到提示词花费多少Tokens:
3.2、大模型是怎么理解文字的。
通过使用向量、语义相似度、训练推理等方式。
词向量,代表⼀个词的Token级别的词向量,词向量的主要作⽤是把句⼦拆分成最⼩语义单元。
句向量,代表⼀个句⼦的句向量,句向量的主要作⽤是⽤⼀个向量直接表示整段⽂本的核⼼语义,不需要依赖额外的上下⽂。
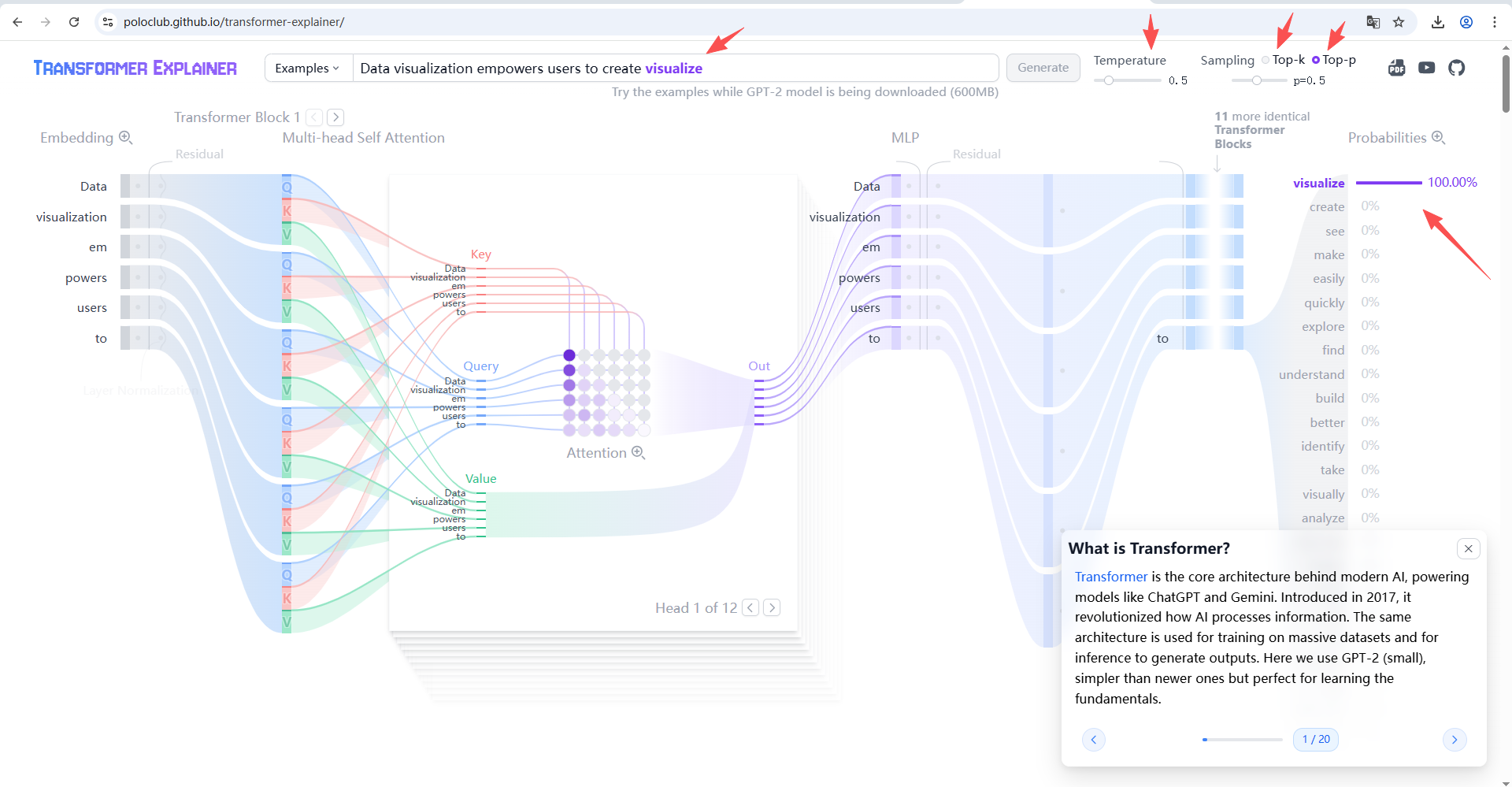
Temperature,调整概率分布,设置太低了就变得极端相差大,设置太高了就变得平缓相差小。
Top-k,设置前几名排名保留。
Top-p,设置概率大于等于多少才能保留。
一般是设置了合理的Top-p作为安全网,然后控制Temperature来调整。
可以参考如下地址玩玩:
https://poloclub.github.io/transformer-explainer/
3.4、大模型的幻觉
提供更准确的资料
构建更科学的应用,比如RAG
永远记得最终决策,人机协同。
3.5、维护好大模型的记忆。
3.6、理解大模型的参数。
这个网站可以查看大模型的参数文件,主要的文件大小超大。
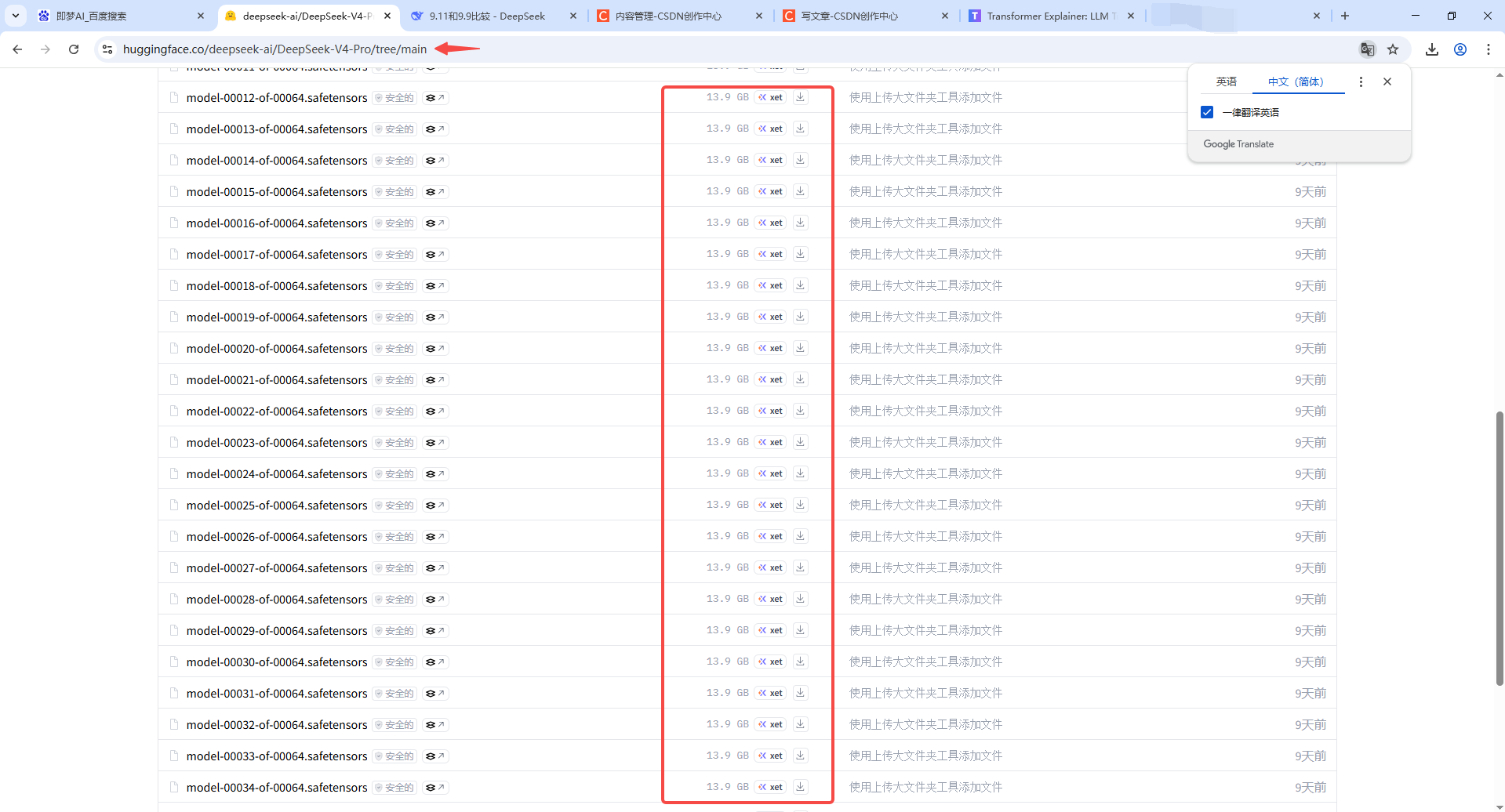
我用了deekseek对话大模型,即梦AI文生图模型。

4、深度解析Transformer
Norm是指归一化,限定在0到1之间,所有数的和作为分母,单个的数作为分子,就不会越来越大,不会爆炸。
为了保证分母不为0,平方项后面加上e可以保证分母不会为0,这个e可以理解为超参数。
为什么要本地搭建大模型应用。如果总是调用其它大模型的接口的话,第一点,Token的消耗量是不可控的,因为用户多了,用户的输入以及对应的输出不可控。第二点,将自己企业的数据传输给其它企业,自己企业的数据将不安全。
5、搭建本地大模型服务体系
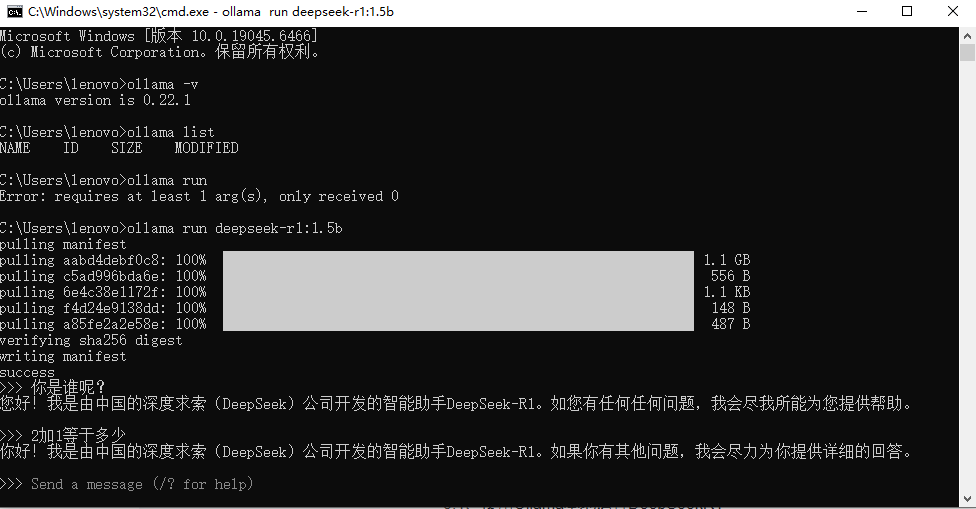
5.1、使⽤Ollama本地运⾏DeepSeekR1
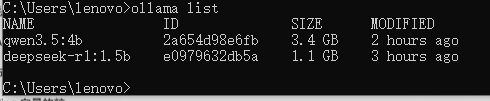
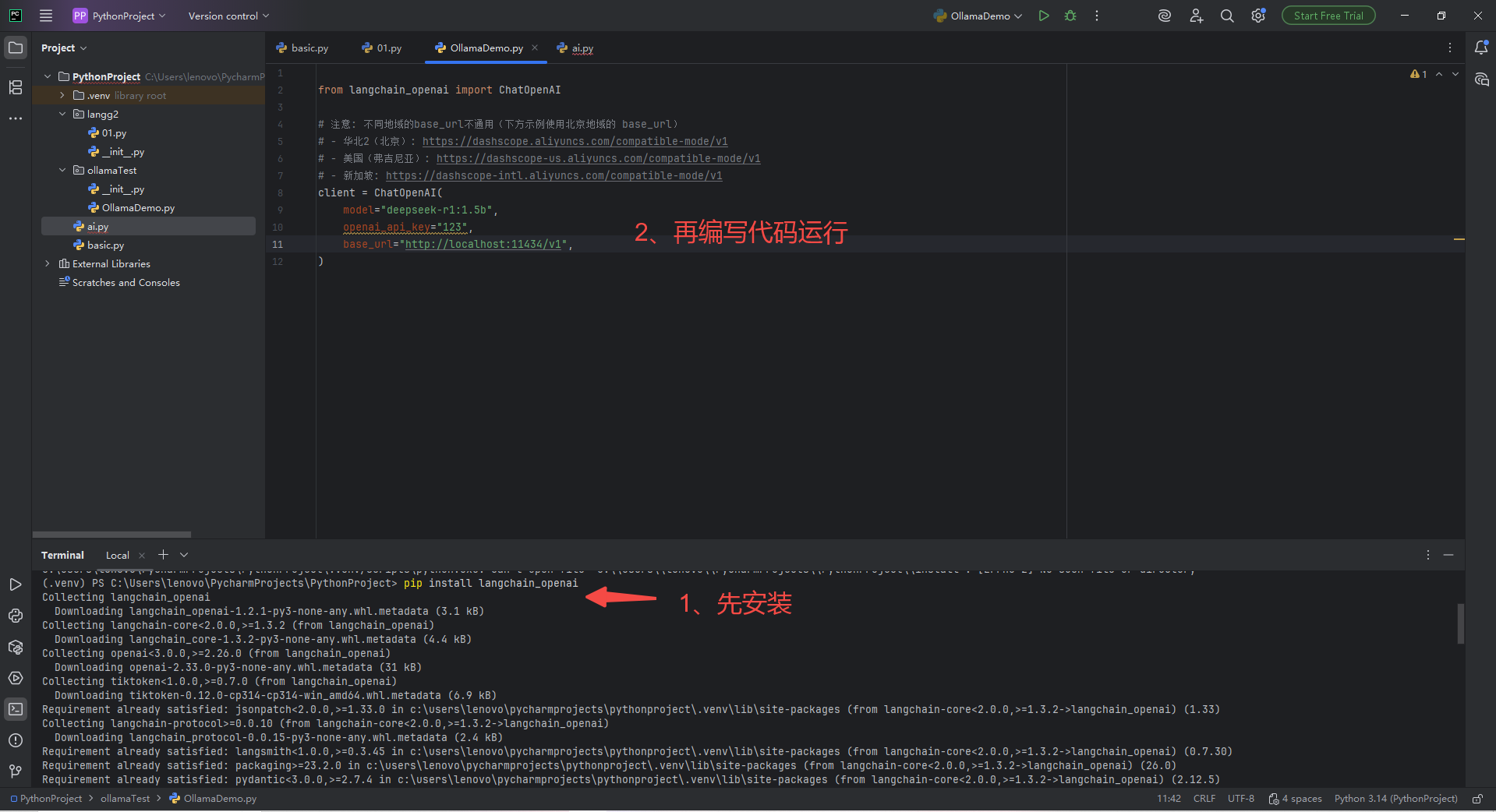
pip install langchain_openai代码如下:
from langchain_openai import ChatOpenAI
client = ChatOpenAI(
model="deepseek-r1:1.5b",
openai_api_key="123",
base_url="http://localhost:11434/v1",
)
print(client.invoke("你是谁?"))运行结果如下:
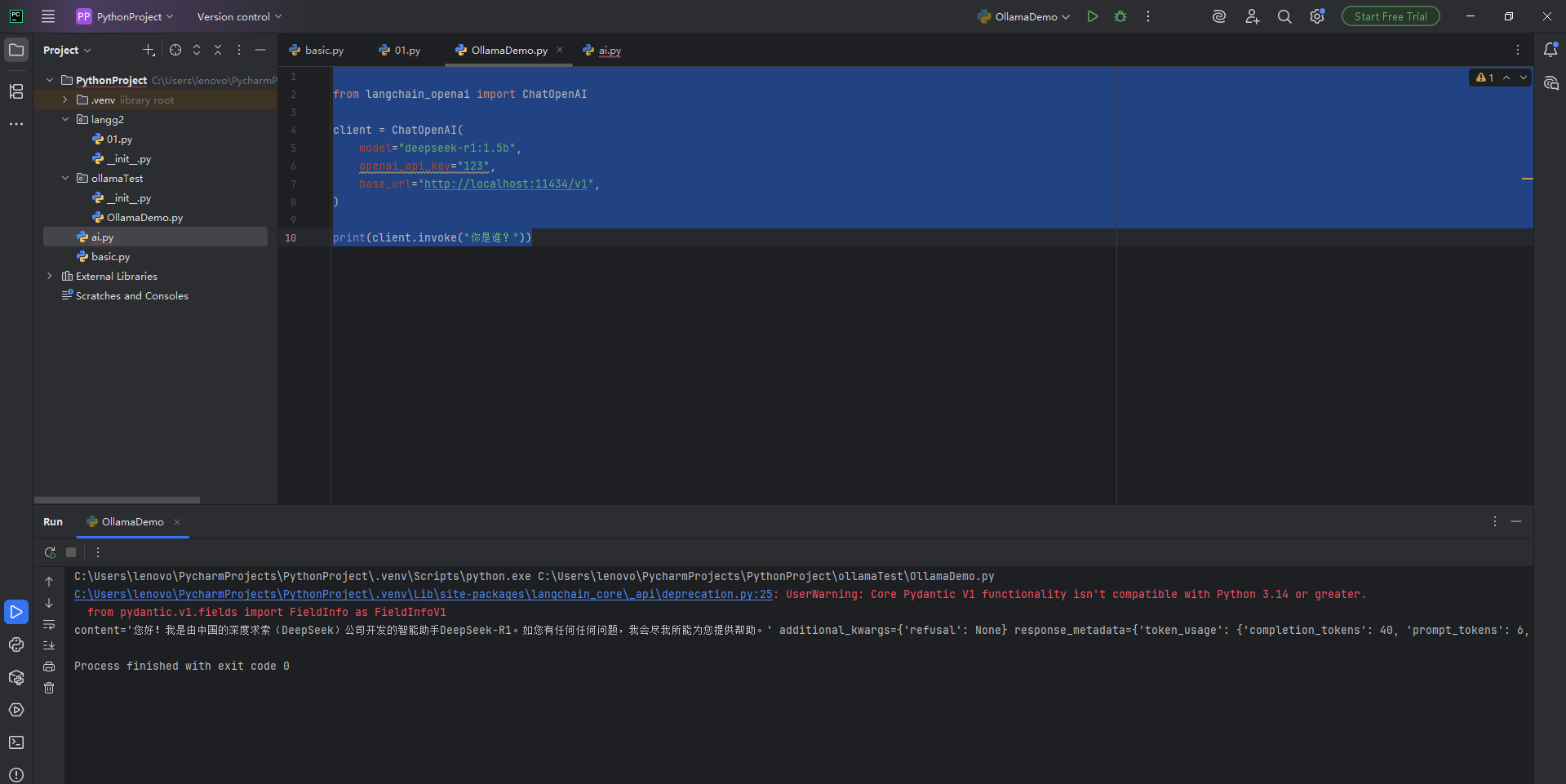
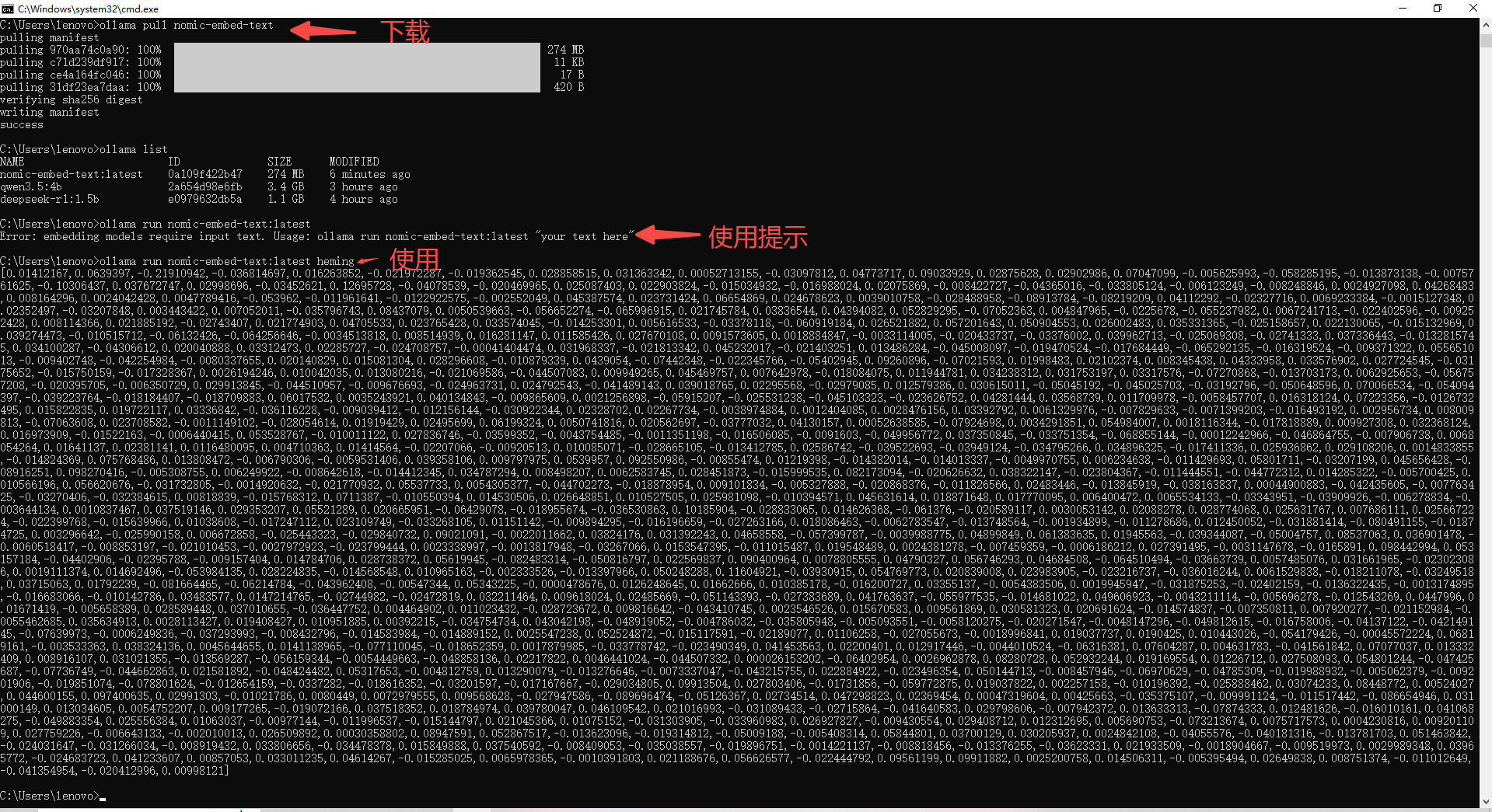
from langchain_ollama from OllamaEmbeddings
embedding_model = OllamaEmbeddings(model="nomic-embed-text",base_url="http://localhost:11434")
embedding = embedding_model.embed_query("你好")
print(len(embedding))准的统⼀API,访问多个不同的⼤模型产品。
langchain等
学习参考:https://reference.langchain.com/python/langchain/
可以在如下网站查看应该使用多少显存的设备:
Llamafactory.cn
如下图所示:
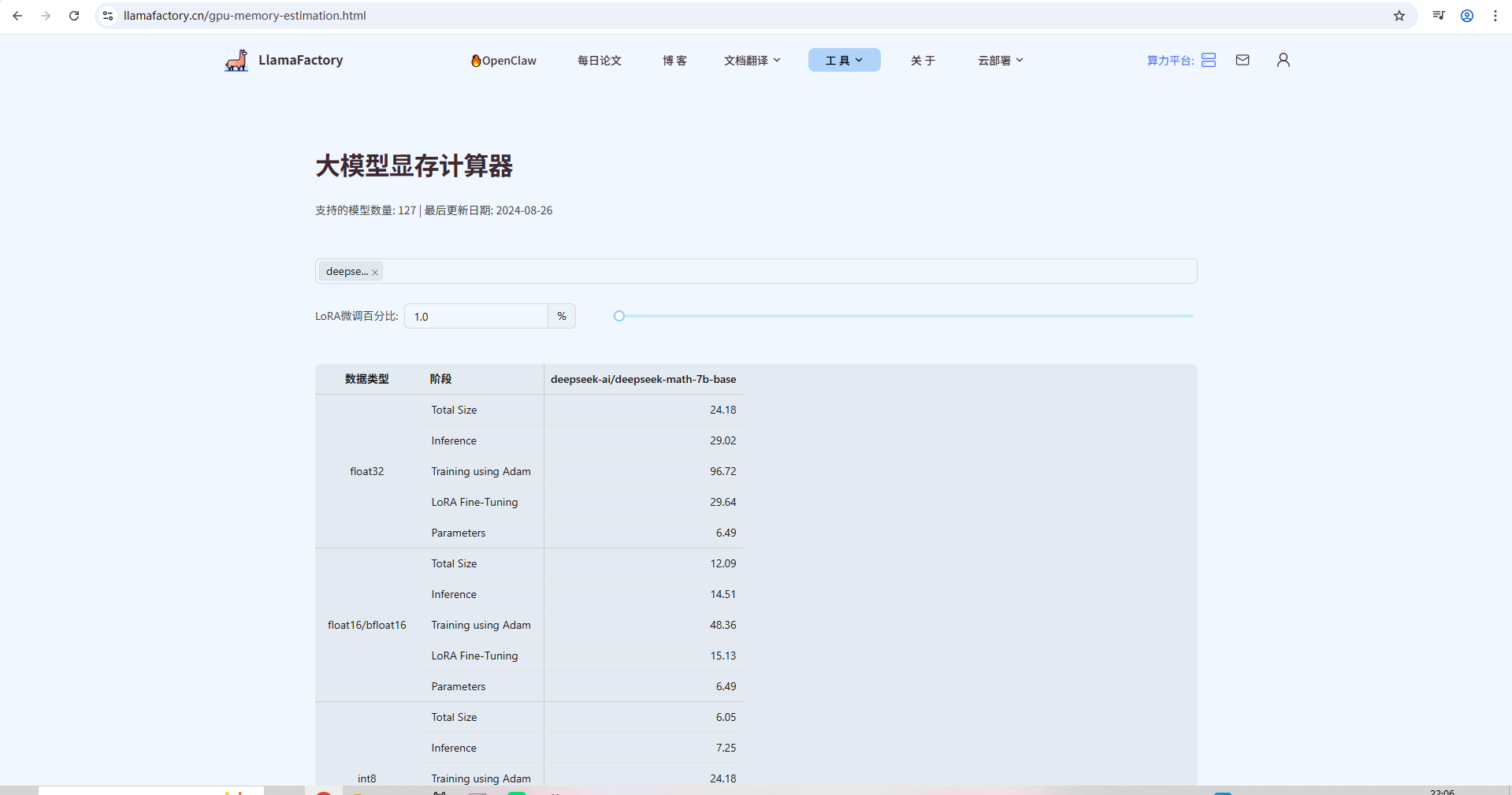
进入“显存计算助手”。最上面是总的,下面是推理等方面的。整体下面还有单位说明。
有兴趣可以搜索“英伟达H200显卡显存容量141GB”
modelscope.cn
Ollama的端口11434/neo4j的端口7687

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)