AREAL: A Large-Scale Asynchronous ReinforcementLearning System for Language Reasoning
Abstract
强化学习(RL)已成为训练大语言模型(LLM)的一种流行范式,尤其在推理任务方面表现突出。面向 LLM 的高效强化学习需要大规模并行化,对高效训练系统提出了迫切的需求。现有的大多数大规模 LLM 强化学习系统都是同步式的,在批处理设置下交替执行生成与训练,每个训练批次中的 rollout 都由同一个(或最新的)模型生成。这种方式虽然能够稳定强化学习训练,但存在严重的系统级低效问题。在模型更新之前,生成阶段必须等到批次中最长的输出完成,从而导致 GPU 利用率【GPU underutilization】不足。我们提出了 AReaL,一个将生成与训练彻底解耦【generation from training】的全异步【asynchronous】强化学习系统。AReaL 中的 rollout 工作进程持续不断地生成新输出而无需等待,训练工作进程则在每收集到一批数据时立即更新模型。AReaL 还集成了一系列系统级优化,从而显著提升了 GPU 利用率。为稳定强化学习训练,AReaL 通过平衡 rollout 工作进程与训练工作进程之间的负载来控制数据陈旧度,并采用了一种针对陈旧度增强的 PPO 变体,以更好地处理过时的训练样本。在数学与代码推理基准上的大量实验表明,与使用相同 GPU 数量的同步系统相比,AReaL 实现了最高 2.77 倍的训练加速,并取得了相当甚至更优的最终性能。AReaL 的代码已开源,地址为 https://github.com/inclusionAI/AReaL/。
1 Introduction
强化学习(RL)已成为一种新的扩展范式,通过赋予大语言模型(LLM)思考能力来增强其性能 [52]。给定一个提示词,RL 允许 LLM 在输出最终答案之前先生成思考 token,从而实现测试时扩展 [29, 47]。这些具备思考能力的 LLM 被称为大型推理模型(Large Reasoning Models,LRM),已被证明在具有挑战性的推理问题上表现出尤为强大的能力,例如数学 [9, 5, 20]、编程 [3, 14, 15]、逻辑谜题 [22, 34] 以及智能体任务 [23, 57]。高效的 RL 训练通常需要大规模并行化来生成大批量的 rollout 以进行充分探索,这是获得最优模型性能的关键。例如,PPO [42] 和 GRPO [43] 等主流 RL 算法通常需要包含数千条输出的有效训练批次 [60, 61, 53]。此外,LRM 针对每个输入提示词可能生成数万个思考 token [6],这进一步对在大规模上运行 RL 训练的高效训练系统提出了迫切需求。
因此,现有的大多数大规模 RL 系统都采用完全同步的设计方式 [27, 11, 45, 44],严格地在 LLM 生成与训练之间交替进行,从而确保 LLM 始终基于最新的输出进行训练,以获得最佳的实际性能。在这种同步设计中,生成步骤必须等待批次中最长的输出完成。由于 LRM 的输出长度参差不齐,同步式 RL 系统会面临严重的训练效率低下问题。最近,也有一些工作开始尝试探索并行的生成与训练 [30, 24, 49]。这些工作使用由先前模型版本生成的输出来更新当前模型。为了获得最佳性能,用于 rollout 生成的模型版本通常被限制为仅落后一到两个训练步。然而,所有这些系统仍遵循批处理式生成的设定,即同一训练批次内的所有样本均来自同一模型版本。因此,生成阶段的系统效率低下问题仍未得到解决。为了从根本上解决系统设计中的这些问题,我们开发了 AReaL,这是一个面向 LRM 的全异步 RL 训练系统,能够将生成与训练彻底解耦,同时不损害最终性能。
AReaL 以流式方式运行 LLM 生成,每个 rollout 工作进程持续不断地生成新输出而无需等待,从而实现较高的 GPU 利用率。与此同时,AReaL 中的训练工作进程一旦从 rollout 工作进程获取到训练批次,便并行地执行模型更新。模型更新完成后,我们会同步每个 rollout 工作进程中的模型权重。在这种异步设计下,AReaL 的每个训练批次中可能包含由不同模型版本生成的样本。为此,AReaL 引入了一种改进版的 PPO 算法目标,使其能够利用由更早模型版本生成的样本,而不会出现性能下降。AReaL 还执行数据过滤流程,以确保每个训练样本的陈旧度【staleness】都得到良好控制。
此外,AReaL 还引入了多项系统级优化,包括可中断的 rollout 工作进程【interruptible rollout workers】、面向变长输出的动态批处理【dynamic batching for variable-length outputs】以及并行奖励服务【parallel reward service】,这些进一步提升了整体训练吞吐量。我们在具有挑战性的数学推理与代码生成任务上对 AReaL 进行了评估,所使用的模型规模最大达到 32B 参数。
与最先进的同步系统相比,AReaL 实现了最高 2.57 倍的训练吞吐量,并在最多 512 块 GPU 上展现出线性的扩展效率。更重要的是,这种加速还伴随着上述任务上解题准确率的提升,这表明 AReaL 在显著提高效率的同时,并未牺牲模型性能(反而有所增强)。
2 Related Work
RL for LLMs
面向 LLM 的强化学习。强化学习(RL)已成为提升大语言模型(LLM)推理能力的主流范式 [31, 32]。现有的 RL 方法通常聚焦于具有明确定义奖励函数的任务,包括数学推理 [9]、编程 [14, 15]、科学问题求解 [39, 36] 以及工具使用 [57]。在训练过程中,模型通过逐步延长思维链轨迹的长度来学习推理 [52, 6]。近期的开源项目已经证明,通过更小的蒸馏模型也能在提升模型能力方面取得显著成功 [24, 25]。
我们的工作建立在这一研究方向之上,与基于偏好的 RLHF [33] 以及试图在不进行任务特定微调的情况下从预训练模型中获取推理能力的零样本推理方法 [60, 61, 12] 有所区别。
Asynchronous RL
异步强化学习。解耦式异步 RL 架构 [21, 8, 26] 结合相应的算法创新 [7, 16],已在游戏应用中取得了显著成功 [2, 51]。尽管类似的异步方法已被用于 LLM 训练,但这些方法通常聚焦于短上下文场景 [30, 1, 40](例如 RLHF),或者仅实现一两步的生成-训练重叠 [24, 48]。
我们的工作对上述研究进行了扩展,并在数据陈旧度与训练速度之间提供了更为灵活的权衡,详见第 5 节。与同期专注于最大化系统级效率的工作 [64] 不同,我们采用了算法与系统协同设计的方法,既提供了一个表达力丰富的系统,也提供了一种切实可行的算法实现。
我们的可中断生成技术【interruptible generation technique】在概念上类似于同步 RL 系统中的部分 rollout 技术 [17]。与设定固定长度预算的方式不同,AReaL 通过缓冲机制在保持训练批次大小一致的同时动态中断生成,从而保留了 PPO 的稳定性。与现有方法 [40, 30] 相比,我们在异步设置下的算法创新能够容忍更高的数据陈旧度,并且与可中断生成保持兼容。
LLM Training and Inference
LLM 的训练与推理。我们的工作聚焦于稠密 Transformer 模型 [50]。RL 训练主要包含生成(推理)和训练两个阶段[generation (inference) and training phases]。生成阶段涉及自回归解码,需要高效的 KV 缓存管理 [63, 18] 以及经过优化的解码内核 [58]。
训练阶段则需要对数据并行[orchestration of data]、张量并行[tensor]和流水线并行[pipeline parallelism]策略进行精心编排 [38, 46, 62]。传统的同步系统在同一硬件资源上顺序执行生成与训练,但二者所需的最优并行化策略并不相同。近期的工作提出了上下文切换 [19, 17] 或权重重分片 [45, 27] 等技术来解决这种不匹配问题。AReaL 通过将生成与训练解耦,超越了同步 RL 系统的局限,从而彻底消除了关键训练路径上的重分片开销。
3 Background
3.1 Preliminaries about RL Training
RL Formulation and PPO
强化学习问题建模与 PPO。我们在马尔可夫决策过程(Markov Decision Process,MDP)框架 [37] 下建模我们的问题,该框架由元组 定义。其中,S 表示状态空间,A 表示动作空间,P 表示状态转移模型【transition model】,r : S × A → R 表示奖励函数,
表示折扣因子,H 表示时间步长(horizon)。
LRM 实现了一个参数化策略 : S → A,其中每个动作
∈ A 对应词表中的一个文本 token。状态
∈ S 由问题
和此前已生成的回答 token (a1, ..,
) 组成,状态转移是确定性的,即
= concat(
,
)。
给定问题分布 D,我们优化以下目标函数:
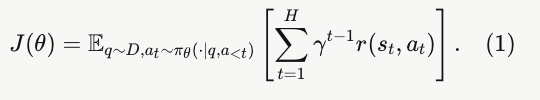
遵循常见做法 [6, 25],我们使用基于规则的奖励函数,该函数仅在最后一个动作上给出非零反馈以指示答案的正确性,并设 = 1。
我们使用近端策略优化算法(PPO)[42] 来优化该目标:
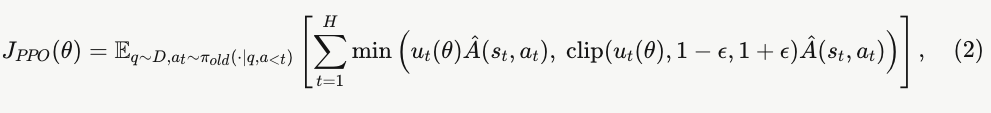
其中![]() 表示重要性采样比【the importance ratio】,
表示重要性采样比【the importance ratio】,![]() 表示估计的优势函数【estimated advantage】 [41]。遵循 RL 中的标准做法 [42, 33],我们将全局批次划分为多个小批次(minibatch),以进行顺序的参数更新。(脚注:这与梯度累积不同,梯度累积是在多个小批次上执行单次参数更新。)
表示估计的优势函数【estimated advantage】 [41]。遵循 RL 中的标准做法 [42, 33],我们将全局批次划分为多个小批次(minibatch),以进行顺序的参数更新。(脚注:这与梯度累积不同,梯度累积是在多个小批次上执行单次参数更新。)
Distributed Systems for LRM Training
面向 LRM 训练的分布式系统。我们的工作专注于在监督微调(SFT)之后增强 LRM 的推理能力,这与那些直接在预训练基础模型上激励推理能力的方法 [6] 有所不同。经过 SFT 的 LRM 会生成较长的推理序列(例如 32K tokens),通常需要较大的全局批次规模(例如每个批次包含 128 个提示词,每个提示词对应 16 条回答)来稳定 RL 训练 [6, 25, 24, 60, 61]。
在同步式 RL 系统中,两个阶段被迭代地执行:生成(rollout)【generation (rollout】阶段与训练【training】阶段。生成阶段使用最新的模型参数为训练批次中的每个查询生成多条推理轨迹。训练阶段则基于生成的轨迹更新模型参数。这两个阶段在同一组 GPU 上迭代地执行。
3.2 Motivation for Asynchronous RL System
我们识别出同步式 RL 系统中存在两个本质性的局限:Inference devices are underutilized. 推理设备利用率不足。如图 1(左)所示,生成阶段必须等待最长的序列完成后,训练才能开始。这导致各 GPU 之间的解码长度参差不齐,从而使 GPU 的计算资源未能得到充分利用。

Figure 1: Execution timeline of a synchronous (left) and a one-step overlap (right) RL system showing underutilized inference devices.
Scalability is poor in synchronous RL systems. 同步式 RL 系统的可扩展性较差。同步式系统将生成任务分摊到所有设备上,从而降低了每块 GPU 上的解码批次大小。这会将解码过程推入受内存 IO 带宽限制的状态 [4, 28],此时增加更多设备也无法提升吞吐量。
4 System Architecture
第 3.2 节中所识别出的局限促使我们设计了一个能够在不同 GPU 集群上将生成与训练彻底解耦的系统。该系统应当具备硬件高效性、可扩展性,并且能够灵活支持自定义的 RL 工作流。我们在 AReaL 中实现了上述设计原则——这是一个专门为高效大规模 LRM 训练而设计的异步 RL 系统。
4.1 System Overview
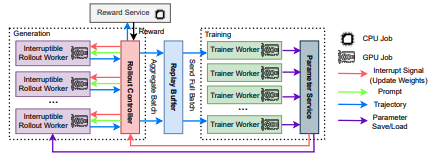
Figure 2: The AREAL architecture featuring asynchronous generation and training components.
图 2 展示了 AReaL 的系统架构与数据流。该系统由 4 个核心组件构成:可中断 Rollout 工作进程【Interruptible Rollout Worker】处理两种类型的请求:(1)generate 请求根据给定的提示词生成回答;(2)update_weights 请求会中断所有正在进行的生成任务,并加载新版本的模型参数【parameter saveload】。
中断发生时,rollout 工作进程会丢弃由旧权重计算得到的 KV 缓存,并使用新权重重新计算。随后,rollout 工作进程会继续解码尚未完成的序列,直至下一次中断或终止。我们强调,这种中断与运行中的权重更新会导致轨迹由不同模型版本生成的片段拼接而成。这引入了一项新的算法挑战,我们将在第 5 节加以解决。
奖励服务(Reward Service) 用于评估模型生成回答的准确性。例如,在编程任务中,该服务会从回答中提取代码并执行单元测试以验证其正确性。训练工作进程(Trainer Workers) 持续地从回放缓冲区【replay buffer】中采样【sample】,不断累积数据直至达到配置的训练批次大小。然后它们执行 PPO 更新,并将得到的新参数存储到分布式存储【distributed storage】中。
采样"在这里的真实含义
中文里"采样"这个词容易误导,让人想到"采样 → 学习 → 采样 → 学习"这种边采边学的循环。但这里的"采样"就是字面意思:从一个数据池里取数据,相当于 PyTorch DataLoader 里
dataset[i]那种取数据,不涉及任何模型更新。英文原文 "sample from the replay buffer" 中的 sample 是动词"取样",不是"采样训练"。换成更直白的中文翻译应该是:"trainer worker 从 replay buffer 里不停地取数据"。
二、那 trainer worker 在干什么?
它就是在凑齐一个 batch,凑齐之前不做任何模型更新。流程是这样:
while True: while len(buffer_local) < batch_size: # 凑 batch 阶段 traj = replay_buffer.get() # 从 buffer 拿一条轨迹(不更新模型) buffer_local.append(traj) batch = collate(buffer_local) # 拼成一个 batch do_ppo_update(batch) # 这一刻才真正做 PPO 更新 save_weights_to_storage() # 把新参数存起来 buffer_local.clear() # 清空,开始下一轮所以"采样累积数据 → 达到 batch size → 执行 PPO 更新"是一个完整的训练步。在凑 batch 的过程中,trainer worker 就是个搬运工:把 rollout 那边塞进 buffer 的轨迹一条条搬到自己这边,搬够数量了就开始训练。
为保证数据的新鲜度,回放缓冲区中的数据只会被使用一次。Rollout 控制器(Rollout Controller) 在 rollout 工作进程【rollout workers】、奖励服务【reward service】以及模型工作进程【the model workers】之间扮演着关键桥梁的角色。
在训练过程中,它从数据集中读取数据,并调用 rollout 工作进程【rollout worker】的 generate 请求。收到的回答随后被发送至奖励服务【reward service】以获取相应的奖励。轨迹【trajectory】连同奖励【reward】一起被存入回放缓冲区【replay buffer】,等待训练工作进程进行训练。模型工作进程【model worker】更新参数完成后,控制器会调用 rollout 工作进程的 update_weight。

Figure 3: Illustration of generation management in AREAL. Vertical lines show the ready time for the next step training. Blue crosses show the interrupted requests when new parameters arrive.
我们在图 3 中展示了生成与训练的管理流程。这种异步流水线确保了生成资源和训练资源都能持续地被充分利用。
4.2 Algorithmic Challenges
尽管异步式系统设计通过提升设备利用率带来了显著的加速,但它也引入了一些需要从算法层面加以应对的技术挑战。
Data Staleness 数据陈旧度
由于 AReaL 的异步特性,每个训练批次中都会包含来自多个先前策略版本的数据。先前关于异步 RL 训练系统的研究已经表明,这种陈旧度会在 RLHF [30] 和游戏环境 [2] 中削弱学习性能。数据陈旧度会导致训练数据与最新模型之间出现分布差异。在面向 LRM 的异步 RL 训练中,由于解码时间被显著拉长,这一问题在长轨迹上可能变得更加严重。
Inconsistent Policy Versions 策略版本不一致
正如第 4.1 节中所讨论的,生成的轨迹中可能包含由不同策略版本产生的片段。这种不一致从根本上违反了公式 (2) 中标准 PPO 的建模假设——该公式假定所有动作均由同一个策略 π_old 生成。在接下来的章节中,我们将详细介绍为克服这些挑战所提出的技术创新,同时保留异步系统所带来的效率优势。
5 Addressing the Algorithmic Challenges in AREAL
5.1 Staleness-Aware Training
为避免在陈旧度过高的数据上训练所导致的性能下降,我们引入了一个超参数 ,用于表示陈旧度感知训练中每个训练批次所允许的最大陈旧度。
特别地,当 η = 0 时,我们的系统退化为同步 RL——此时所有训练样本均由当前策略生成。我们在系统中通过动态控制发送给生成服务器【generation servers】的生成请求吞吐量来实现陈旧度控制。
给定当前策略版本 、已生成轨迹的总数
以及每个训练步的训练批次大小 B,我们在每次提交新的生成请求时强制执行以下约束:

一、代码里的 η =
max_head_offpolicyness在
areal/api/cli_args.py里:max_head_offpolicyness: int = field( default=0, metadata={ "help": "Maximum off-policyness for the head. " "If the current version is more than this many versions behind, " "the request will not be accepted.", }, )关键信息:
项 值 类型 int(整数,不是浮点数)默认值 0(默认退化为同步 RL)单位 "version" = 训练步(每次 PPO update 增 1)
论文里实际用的值
实验 η 取值 出处 数学任务 8 7.1 节 "η = 8 for math" 编程任务 4 7.1 节 "η = 4 for coding" 消融实验 0, 1, 2, 4, 8, 16, ∞ 表 2 也就是说论文的主实验里 η 至少是 4,最大用到 16,甚至测过 ∞——它绝对不是 0-1 的比例,而是个可以很大的整数。
代码里怎么实现这个约束?
areal/infra/staleness_manager.py里的get_capacity函数:def get_capacity(self) -> int: # ofp 就是 η ofp = self.max_staleness sample_cnt = self.rollout_stat.accepted + self.rollout_stat.running consumer_bs = max(1, self.consumer_batch_size) staleness_capacity = (ofp + current_version + 1) * consumer_bs - sample_cnt capacity = min(concurrency_capacity, staleness_capacity) return capacity把它和论文公式 (3) 对照:

变形一下:

代码里的
staleness_capacity = (η + i + 1) × B − N_r就是这个约束的剩余配额:
- 配额 > 0:还能再放新生成请求进来
- 配额 ≤ 0:必须等 trainer 消费掉一些样本(i 增长)才能继续
这就是论文说的"rate-limiting protocol"——通过这个配额机制反向限制 rollout 的速度,迫使它不要跑得太超前。
此外,我们在组建训练批次时会优先选用数据缓冲区中较早的轨迹。在系统实现层面,rollout 控制器会同时跟踪已生成的样本数 Nr (这肯定是从global_step=0开始的样本计数)以及来自参数服务器的策略版本 i。它会拒绝可能违反陈旧度约束的新生成请求。值得注意的是,这种限流协议在实践中是一种简单而有效的设计选择。然而,当 η 设置得过小时,一旦有部分极长轨迹正在生成,整体的生成吞吐量便可能被拖慢。因此,从经验上我们建议采用较大的陈旧度控制参数 η,以获得最佳的系统吞吐量。这一系统层面的实践也促使我们设计一种增强的算法,使其能够有效利用更陈旧的数据进行 RL 训练。
5.2 Decoupled PPO Objective
我们采用了一种解耦的 PPO 目标函数 [10],将行为策略【behavior policy,这是生成rollout时候的策略】与近端策略【the proximal policy】解耦开来。行为策略 π_behav 表示用于采样轨迹的策略,而近端策略 π_prox 则是一个较新的目标策略,用于对 π_θ(最新的模型参数) 的更新进行正则化约束。通过对采样得到的轨迹应用重要性采样,我们推导出一个适用于异步 RL 训练的解耦 PPO 目标函数:

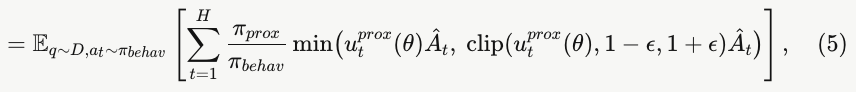
其中![]() 是相对于近端策略的重要性比。为简洁起见,我们省略了状态-动作相关的下标项。
是相对于近端策略的重要性比。为简洁起见,我们省略了状态-动作相关的下标项。
公式5这里进行了一个变换,把
作为一个因子提出来,这样括号里的advantage前面的系数就相同了。
公式 (5) 中的异步 PPO 目标函数与公式 (2) 中的标准 PPO 目标函数之间的主要区别,在于用于约束模型更新的近端策略 π_prox。在异步 PPO 训练中,若直接将行为策略当作近端策略使用,会将最新的策略 π_θ 拉向较旧、质量较低的策略,从而拖慢模型的改进进程。通过采用一个较新的策略作为近端策略,模型更新便发生在围绕高质量近端策略 π_prox 所构成的信任域内,从而稳定了训练过程。公式 (5) 中的解耦 PPO 目标函数还带来一个自然的好处:它放宽了"同一训练批次中的所有数据都必须由单一策略生成"这一要求。当将可中断生成与策略更新结合使用时,这一性质对保持算法正确性至关重要。
我们断言:一条轨迹中存在不一致策略版本的情况,在数学上等价于由单一行为策略 π_behav 进行采样。(证明见附录 D。)
【Proposition 1】命题 1。 对于任意由策略序列 (, ...,
) 生成的序列 (
,
, ...,
),其中
负责生成 token (
...,
),且 1 =
< ··· <
,存在一个行为策略 π_behav,使得这种被中断生成的过程在效果上等价于完全从 π_behav 中采样。
Practical Remark 实践说明 虽然 Hilton 等人 [10] 通过维护参数的指数滑动平均来构造 π_prox,但这种方法对 LRM 而言开销过于昂贵。因此,我们直接采用每次模型更新步骤前的参数作为 π_prox。
D Proof of Proposition 1
命题 1。 对于任意由策略序列 (π_θ, ..., π_{θ+k}) 生成的序列 (q, a₁, ..., a_H),其中 π_{θ+i} 负责生成 token (a_{ti}, ..., a_{t_{i+1}}),且 1 = t₀ < ··· < t_{k+1} = H,存在一个行为策略 π_behav,使得这种被中断生成的过程在效果上等价于完全从 π_behav 中采样。
Proof. 证明。
对于问题 q,令 S_t(q) 表示在策略序列下第 t 步所遇到的状态。由于当 i ≠ j 时 ,我们可以构造:
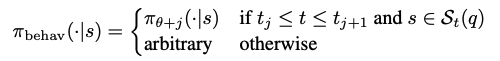
一、先讲清楚命题在说什么
回顾场景:在 AReaL 的可中断生成里,一条轨迹的不同 token 段是由不同模型版本生成的。
举个具体例子,一条轨迹有 100 个 token:
- token 1-30 由策略 π_θ(比如版本 5)生成
- 然后发生权重更新,模型变成 π_{θ+1}(版本 6)
- token 31-70 由 π_{θ+1} 生成
- 又发生权重更新,模型变成 π_{θ+2}(版本 7)
- token 71-100 由 π_{θ+2} 生成
这违反了标准 PPO 的假设——PPO 的公式 (2) 假设整条轨迹由同一个策略 π_old 生成。
命题 1 说:尽管这条轨迹是由 3 个不同版本拼出来的,但在数学上,我们可以构造一个"虚拟"的单一策略 π_behav,使得"从这个 π_behav 整条采样出来的概率"= "实际由 3 个版本拼接生成的概率"。
只要这个 π_behav 存在,我们就可以假装这条轨迹是从 π_behav 整条采样得来的,标准 PPO 的数学框架就能继续套用,5.2 节的解耦 PPO 目标就有了正当性。
二、构造 π_behav 的核心思路
我们需要定义一个策略 π_behav(·|s)——也就是"在任何状态 s 下,下一个 token 的概率分布是什么"。
关键观察:
每个状态 s(也就是"问题 + 已生成的前缀")在这条轨迹里只会出现一次。
为什么?因为状态是确定性递增的(s_{t+1} = concat(s_t, a_t),每加一个 token 状态就变一次),所以任意两个时刻 t_i ≠ t_j 对应的状态一定不同。
这就是证明里那一句:
"Since S_{ti}(q) ∩ S_{tj}(q) = ∅ for i ≠ j"
意思是不同时刻的状态集合互不相交。
三、构造方法
既然每个状态在轨迹里只出现一次,我们就可以"看菜下饭"——针对轨迹经过的每个状态,让 π_behav 在那个状态上的概率分布等于当时实际用来生成那个 token 的策略。
正式构造:
πbehav(⋅∣s)={πθ+j(⋅∣s)如果 tj≤t≤tj+1 且 s∈St(q)任意其他情况任意如果 tj≤t≤tj+1 且 s∈St(q)其他情况
逐字翻译:
- 第一种情况:当状态 s 是"轨迹在第 t 步遇到的那个状态",且这个 t 落在策略 π_{θ+j} 负责的区间 [t_j, t_{j+1}] 内时,π_behav 在这个状态上的行为就完全照抄 π_{θ+j} 的行为
- 第二种情况:对于轨迹没经过的所有其他状态,π_behav 在那里的概率分布随便定,反正不会影响这条轨迹的概率

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)