深入解析企业级上下文窗口管理架构:构建安全、高效、可扩展的AI问答系统
·
在构建企业级AI问答系统时,上下文窗口管理能力是核心之一。它决定了系统如何有效利用历史对话、关键信息和知识库内容,以生成准确、合规且符合企业需求的回答。本文将基于之前的示例代码,深入解析企业级上下文窗口管理架构的设计思路、关键技术及实现细节,帮助读者理解其背后的逻辑与价值。
一、企业级上下文管理的核心挑战
企业环境下的上下文管理面临以下关键挑战:
- 数据量与效率:企业知识库庞大,对话历史可能冗长,如何高效存储和检索上下文?
- 安全与合规:需确保敏感信息不被泄露,访问权限严格控制,操作可审计。
- 语义连贯性:在限制窗口长度的同时,如何避免关键语义丢失,保证回答质量?
- 动态性:上下文需随对话动态更新,区分短期与长期信息的重要性。
二、分层上下文管理架构设计
企业级上下文窗口管理通常采用分层架构,结合不同策略管理不同类型的数据。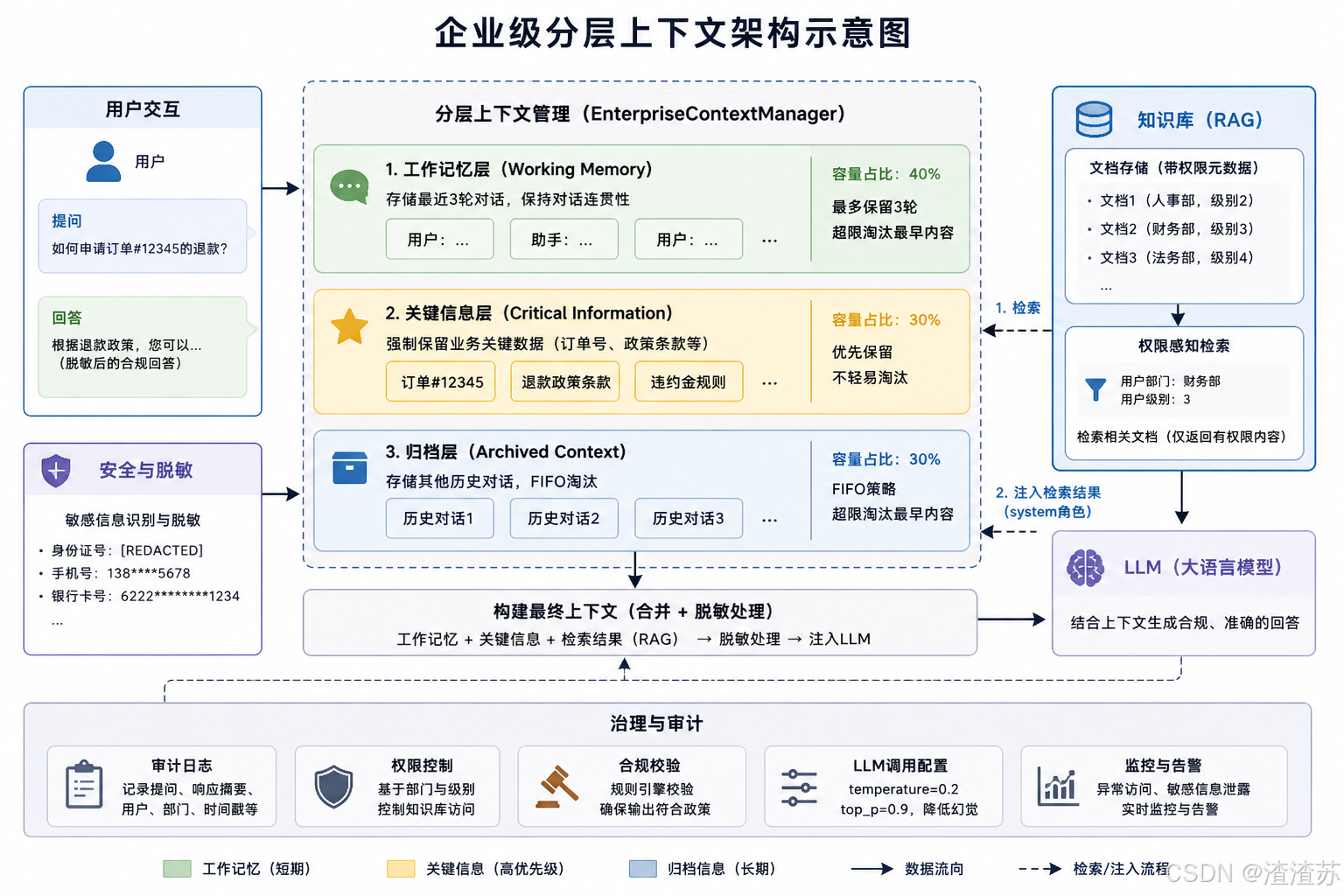
核心设计如下:
1. 分层结构:工作记忆、关键信息、归档层
class EnterpriseContextManager:
def __init__(self, max_tokens):
self.layers = {
"working": {"content": [], "max_tokens": max_tokens * 0.4}, # 短期对话
"critical": {"content": [], "max_tokens": max_tokens * 0.3}, # 关键业务信息(如订单号、政策条款)
"archived": {"content": [], "max_tokens": max_tokens * 0.3} # 历史对话归档
}
- 工作记忆层:存储最近3轮对话,用于保持对话连贯性。
- 关键信息层:强制保留业务关键数据(如通过正则匹配
订单#、退款等关键词),确保高优先级信息不丢失。 - 归档层:存储其他历史内容,采用FIFO(先进先出)淘汰策略,动态控制长度。
2. 动态压缩与智能注入
- 通过
add_message()方法智能分类信息:
def add_message(self, role, content, is_critical=False):
if is_critical or re.search(r"订单#\d+|退款|违约", content):
target = "critical"
elif len(self.layers["working"]["content"]) < 3:
target = "working"
else:
target = "archived"
# 动态压缩(超限时淘汰最早内容)
while layer["content"] and ...:
layer["content"].pop(0)
layer["content"].append((role, content))
- 关键信息强制进入
critical层,避免被误删。 - 工作记忆层仅保留最新对话,归档层则按FIFO淘汰,平衡长度与语义。
3. 安全增强:敏感信息脱敏
构建上下文时,通过正则过滤敏感字段(如身份证号):
def build_context(self):
full_context = "\n".join(context)
return re.sub(r"身份证号:\s*\w+", "身份证号: [REDACTED]", full_context)
确保输出到LLM或最终响应时,敏感数据已被脱敏,符合企业安全规范。
三、权限感知与知识库协同(RAG)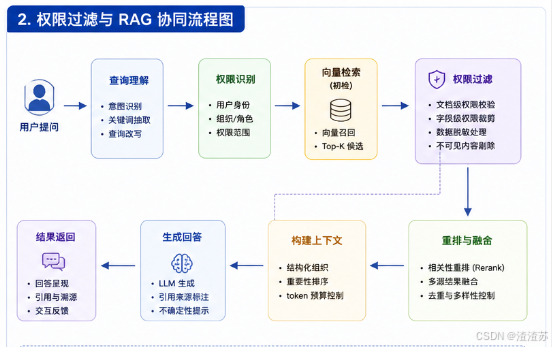
企业级上下文管理需与知识库紧密协同,通过**检索增强生成(RAG)**提升回答质量,同时控制权限:
1. 权限控制的知识库
class KnowledgeBase:
def add_document(self, text, dept, level):
self.texts.append((text, {"dept": dept, "level": level}))
def retrieve(self, query, user_dept, user_level):
results = []
for i in indices[0]:
if meta["dept"] == user_dept and user_level >= meta["level"]:
results.append(text)
return results
- 文档存储时绑定部门与保密级别元数据。
- 检索时仅返回用户有权访问的内容(部门匹配且权限≥文档级别)。
2. 上下文与RAG的协同流程
- 用户提问后,知识库基于权限检索相关文档。
- 检索结果作为关键信息注入上下文(标记为
system角色)。 - LLM生成回答时,结合上下文中的工作记忆、RAG结果和关键信息,确保回答合规且准确。
四、企业级治理与审计
- 审计日志记录:完整记录用户提问、系统响应摘要、访问部门及时间戳等元数据,支持后续合规审查与问题追溯,满足GDPR等数据治理要求。
- LLM调用配置:采用低随机性参数(
temperature=0.2)与高top_p值,约束生成内容的多样性,确保回答聚焦业务事实,有效抑制“幻觉”现象。 - 响应生成策略:集成规则引擎,在LLM生成前预校验关键信息(如合同条款、价格策略),确保输出内容符合企业政策与合规标准,提升回答的确定性与可信度。
五、关键技术实现与优化方向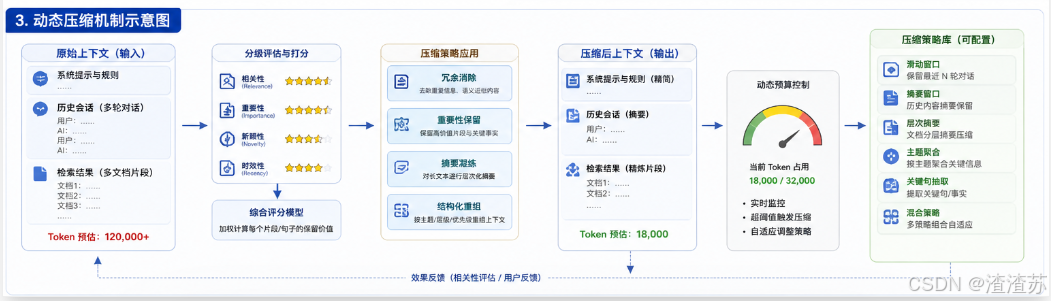
- 智能压缩策略:采用FIFO与重要性加权结合的淘汰机制,优先保留高价值语义片段,避免简单截断导致的上下文断裂。
- 向量数据库扩展:Demo中使用轻量级FAISS,生产环境可平滑迁移至Milvus或Pinecone,支持亿级向量的高效检索与动态更新。
- 长期记忆优化:探索神经压缩技术(如Neural Zip)对归档层内容进行语义级压缩,在保留关键信息的同时显著降低存储开销。
- 未来演进方向:包括自适应记忆分层(基于访问频率动态调整)、多模态上下文融合(支持图像、表格等)、以及分布式上下文管理架构,以支撑跨地域、高并发的企业级部署。
- 未来方向:自适应记忆策略(基于使用频率动态调整分层)、多模态记忆(融合文本、图像等)、分布式存储支持跨地域部署。
六、总结
企业级上下文窗口管理架构通过分层策略、权限控制、动态压缩和安全机制,解决了数据量、安全性、语义连贯性及合规性等核心挑战。它将短期对话、关键信息与知识库协同,构建出既能高效响应又能保障企业数据安全的AI问答系统。未来,随着技术的演进,自适应策略与多模态支持将进一步提升系统的智能与灵活性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)