大模型训练与量化
一、模型量化实战
这节课程内容主要围绕大模型量化技术展开,从理论基础到主流算法原理,再到使用 llmcompressor 进行实战部署。
1、核心概念与量化价值
1. 量化的本质
-
用较少的信息表示数据,在尽量不损失性能的前提下降低资源开销。
-
利用神经网络的参数冗余性(大量参数可被删除或降精度而不显著影响准确率),将高精度权重转为低精度整数。
2. 量化的主要收益
-
降低显存占用:FP16 → INT8 减半,FP16 → INT4 仅为原来 1/4。
-
提升推理速度:内存带宽压力降低,在大模型这种“内存受限”场景下,更快地加载权重即意味着更快的 Token 生成速度。
2、精度与显存估算
1. 常见数值精度与字节占用
| 精度 | 类型 | 每参数字节数 |
|---|---|---|
| FP32 | 单精度浮点 | 4 Bytes |
| FP16/BF16 | 半精度浮点 | 2 Bytes |
| INT8 | 8 位整数 | 1 Byte |
| INT4 | 4 位整数 | 0.5 Byte (4 bit) |
2. 显存估算公式
权重显存占用 ≈ 模型参数量 × 每参数字节数( 1 GB≈109 Bytes)
-
以 7B 模型为例:
-
FP16/BF16:≈ 14 GB
-
INT8:≈ 7 GB
-
INT4:≈ 3.5 GB
-
实际总显存还需加上:
KV Cache:上下文缓存,与序列长度(Context Length)成正比,上下文越长,占用越大。
激活值:中间层计算结果,与 Batch Size 和序列长度相关。
PyTorch/CUDA 框架开销:PyTorch / CUDA context 本身会占用一定开销。
通常比纯权重估算值高 20%–30%。例如加载 7B 的 INT4 模型(3.5GB 权重),推荐显存至少 6GB 起步。
3、三大主流量化技术(Transforms 集成)
GPTQ 和 AWQ 主要面向推理部署与加速,它们属于 PTQ(Post-Training Quantization)算法,生成的模型通常以量化后的检查点形式保存,加载后显存占用低且推理速度快。bitsandbytes 则既常用于 8bit/4bit 推理,也是诸如 QLoRA 在内的一系列低显存微调方案的核心依赖,尤其擅长让大模型在单卡上完成 4-bit 训练。
1. GPTQ(训练后量化,PTQ)
-
目标:最小化量化前后激活值的平方误差:
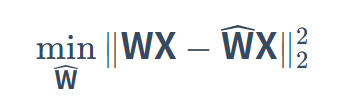
W 为原始权重矩阵,X 为输入激活值矩阵,W^ 为量化后的权重矩阵。
-
关键机制:
-
二阶信息补偿:利用海森矩阵(H=2XX⊤)的逆来更新剩余权重,补偿当前权重量化误差。
-
任意顺序与延迟批量更新:GPTQ 发现大模型不需要像 OBQ 那样进行昂贵的“贪心排序”,只需按顺序量化即可。引入了 Lazy Batch-Updates(延迟批量更新) 策略,将计算密集型的更新操作分块执行(如 128 列为一组),大大提升了 GPU 利用率。
-
Cholesky 分解:解决大规模下海森矩阵求逆的数值不稳定问题。
-
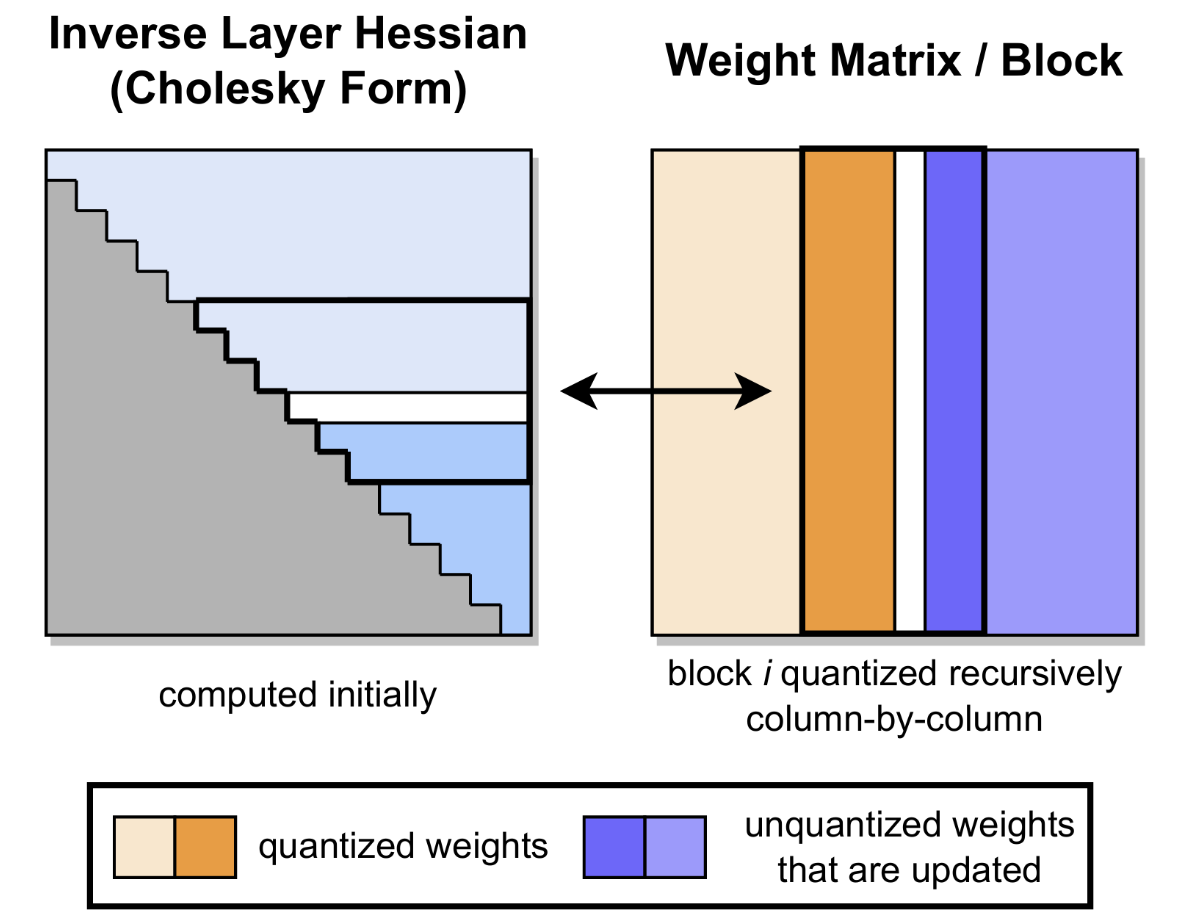
加粗的列块(Block)表示当前正在处理的列。左侧灰色部分是利用 Cholesky 分解预先计算好的逆 Hessian 信息。在处理当前块(橙色部分)时,算法会递归地逐列量化(中间白色列),并将量化误差利用预计算的 Hessian 信息“推”给后续未量化的权重(右侧蓝色部分)进行更新补偿,从而最大程度保留模型精度。
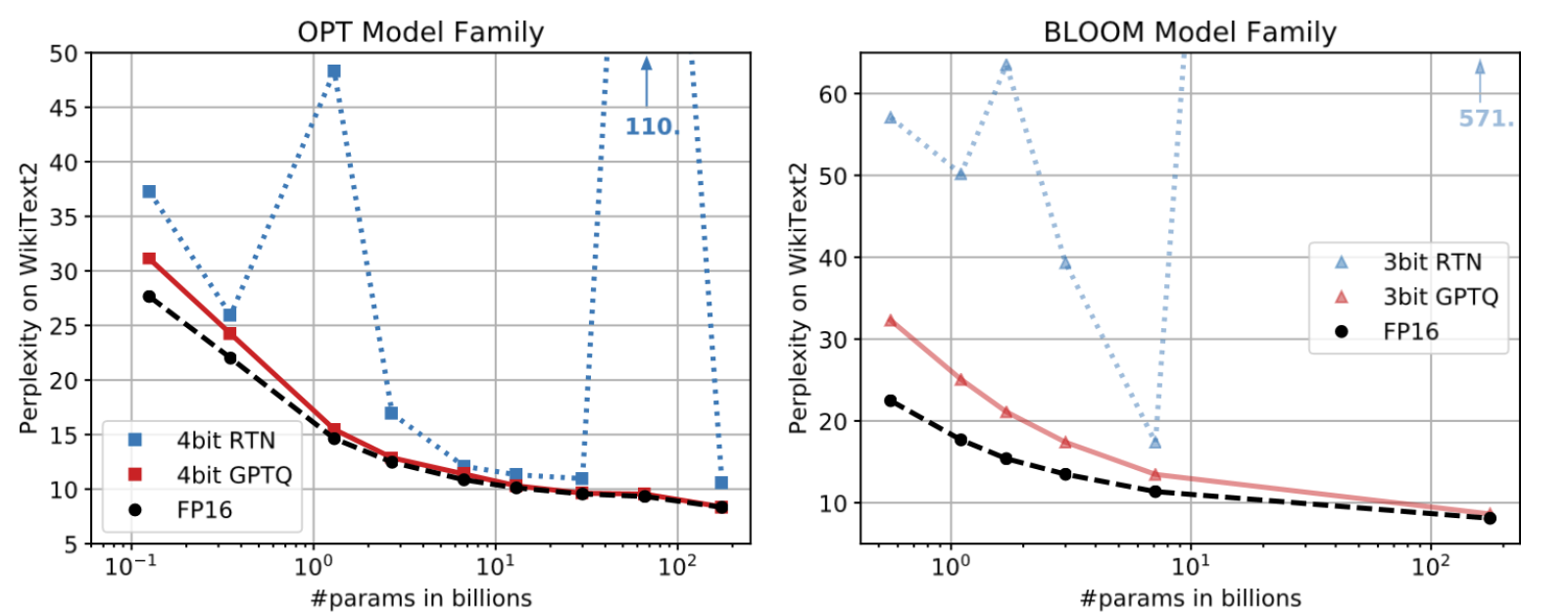
在 OPT 模型家族中,随着参数量增加(横轴向右),传统 RTN 方法(蓝线)的困惑度(PPL)急剧上升,意味着模型“崩了”;而 GPTQ(红线)则紧贴全精度基线(黑虚线),展现了极强的鲁棒性。
特点:GPTQ 能以极快的速度(如 1750 亿参数仅需 4 小时)完成量化。一次量化,模型越大相对精度损失越小,配合 ExLlama 等专用内核推理速度可达 FP16 的 3-4 倍。
2. AWQ(激活感知权重量化)
-
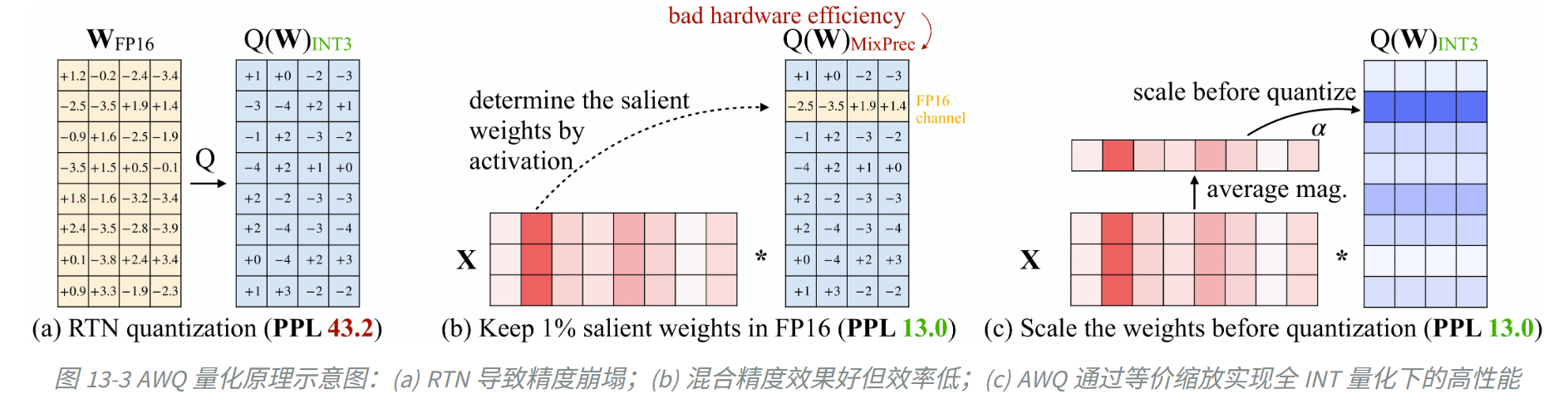
核心发现:权重的“重要性”取决于其对应激活值的幅度,而非权重本身的大小。更符合直觉且高效的量化思路,特别适合端侧部署。
-
仅保留 1% 的“显著权重”(即对应激活值较大的通道)为 FP16 精度,就能极大恢复模型性能。有趣的是,如果按权重本身的 L2 范数来选这 1%,效果和随机选差不多;但如果按激活值幅值来选,效果立竿见影。
-
为了工程落地,AWQ 并没有真正把这 1% 的权重存成 FP16(混合精度会拖累推理速度),而是采用了一种精妙的数学等价变换。
-
-
方法:通过数学等价变换,将重要权重通道乘以缩放因子 s,并将对应输入除以 s,保持线性层输出(如:y=wx)不变,使得整体计算在数学上保持等价,但被放大的权重在量化时的相对误差更小。
-
优化目标:当权重被放大后,其数值范围变大,相对量化误差(Relative Quantization Error)就会变小。AWQ 的优化目标是找到一组最优的缩放因子 s,使得量化误差最小:
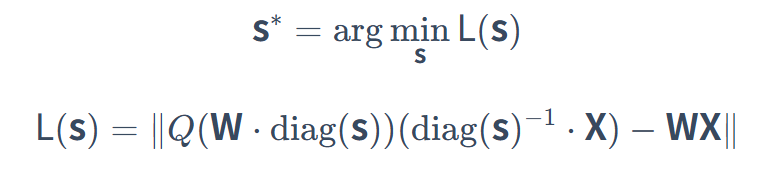
-
特点:无需混合精度,全 INT 量化即可达到接近 FP16 的效果;对端侧设备友好,配合 TinyChat 推理框架,作者展示了在高配 Jetson Orin 上以小 batch 形式运行 Llama-2-70B 的可能性;在树莓派等资源更受限的设备上,理论上也可以以 INT4 形式跑 7B 模型,但整体更偏 Demo/实验性质,速度和体验都会受到一定限制。
3. BitsAndBytes (BNB)
-
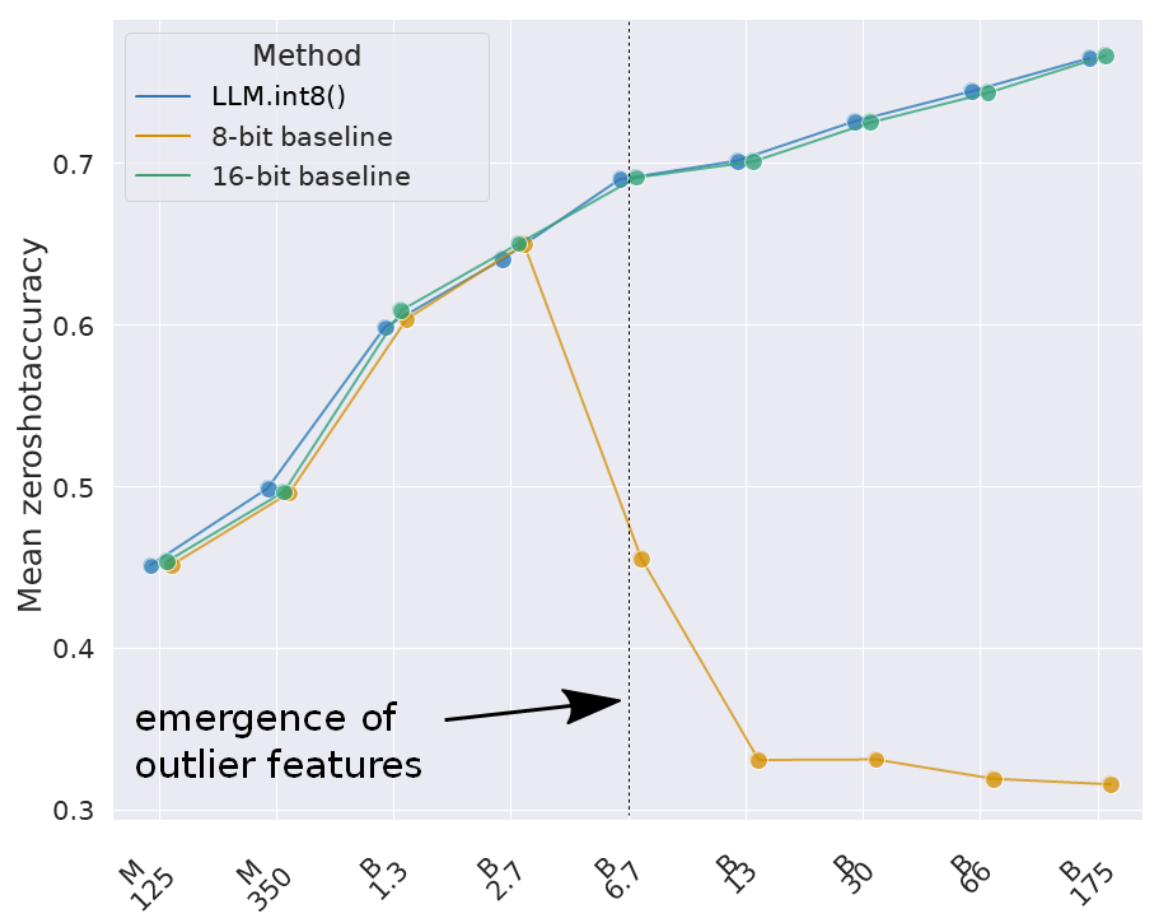
解决“离群值”问题:当参数规模超过 6.7B 时,Transformer 层中会出现极少量数值极大的离群特征(约占 0.1%),传统 8-bit 量化会直接导致性能崩塌,而 LLM.int8()(蓝线)则保持了与 16-bit 基线一致的性能。
-
bnb 是底层库,LLM.int8() 是它的 8-bit 量化方法,QLoRA 是基于 bnb 4-bit 量化的高效微调技术。
-
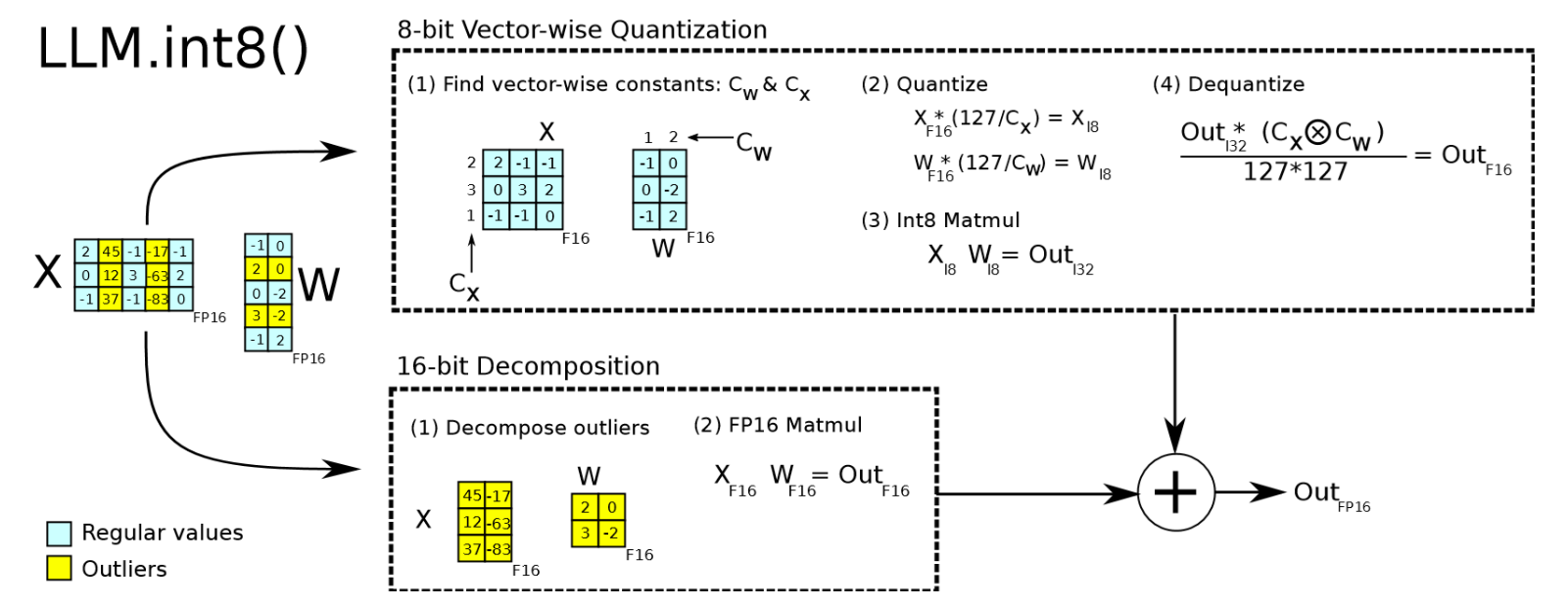
LLM.int8()
-
主要原理是混合精度分解:
-
99.9% 常规值:向量级 8-bit 量化做矩阵乘法。
-
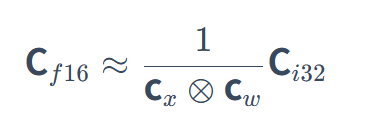
-
Cf16 是近似的 FP16 输出结果,Ci32 是 INT8 矩阵乘法得到的 INT32 结果,cx和 cw分别是输入 X 和权重 W 的量化缩放因子(Scaling Factors)。
-
-
0.1% 离群维度:保持 FP16 高精度计算。
-
最终结果合并,达到 FP16 性能的同时享受 INT8 显存节省。
-
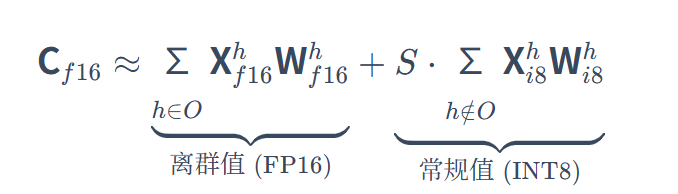
-
h 代表特征维度,O 是离群特征维度的集合,S 是去归一化项(对应上面的缩放因子乘积)。为了便于理解,这里对缩放因子 cx、cw 和 S 的张量维度及广播方式做了简化,实际工程实现中会针对 batch/head/channel 等维度分别维护缩放因子。
-
-
-
-
QLoRA 支持:引入NormalFloat4 (NF4) 数据类型,这是一种专门为正态分布权重量身定制的 4-bit 类型,信噪比高于标准 INT4。如今,通过
BitsAndBytesConfig,我们可以轻松调用这些技术,在单张消费级显卡上不仅能加载大模型,还能进行高效的微调。
4、实战工具与流程(llmcompressor)
1. LLM Compressor 简介
-
统一 API 支持 GPTQ、AWQ、SmoothQuant、SparseGPT 等多种压缩算法。
-
与 Hugging Face 和 vLLM 深度集成,输出可直接被 vLLM 加载部署。
-
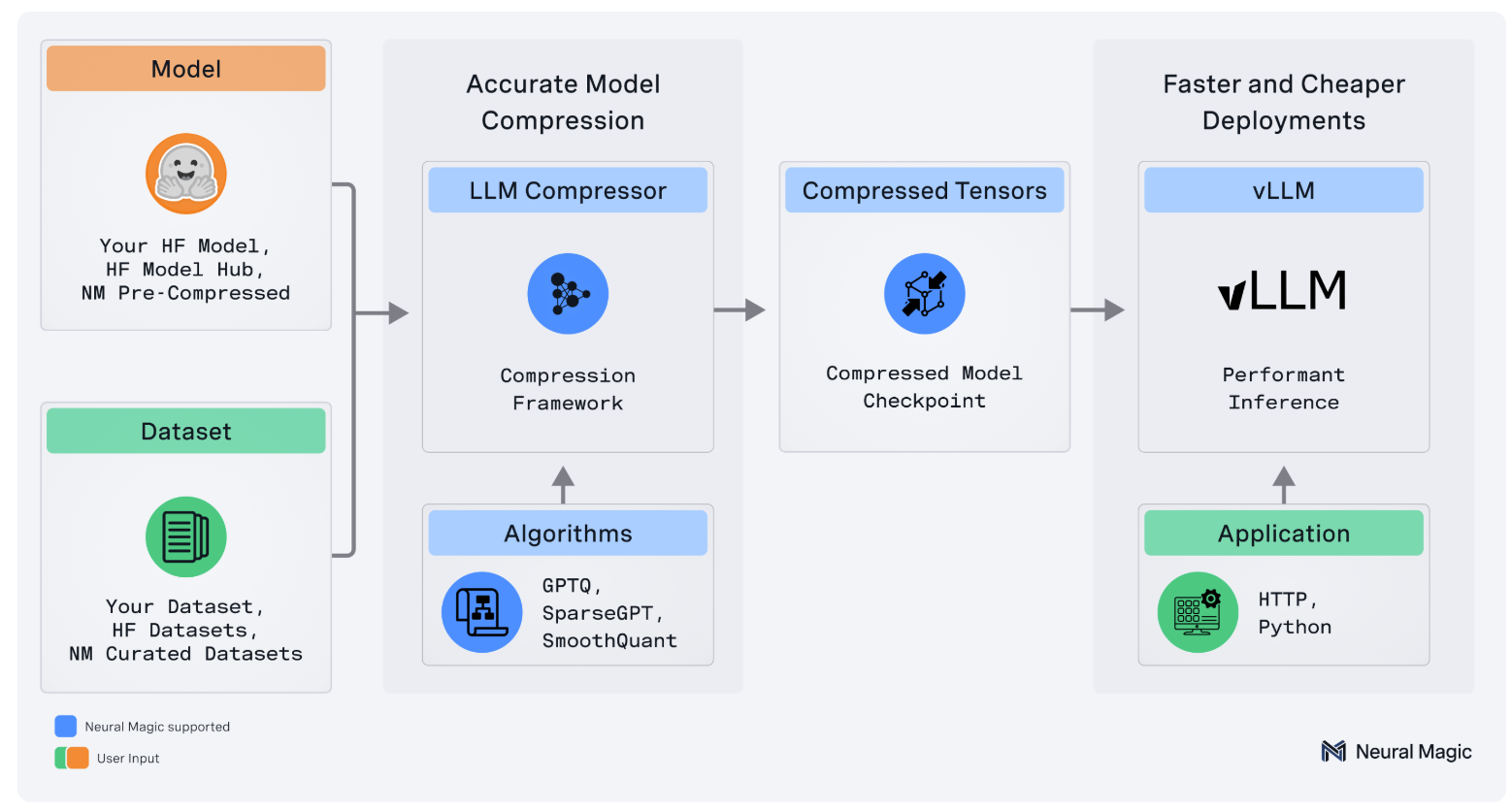
LLM Compressor 的工作流程:首先输入准备好的 Hugging Face 模型和(可选的)校准数据集;接着在压缩阶段,使用
llmcompressor库应用量化算法(如 GPTQ、AWQ 等);随后输出压缩后的模型检查点(Compressed Model Checkpoint);最后在部署阶段,将压缩模型直接加载到 vLLM 中进行高效推理,最终服务于上层应用。
2. GPTQ 量化实战步骤
-
定义策略(
GPTQModifier):# 量化后模型输出目录 gptq_out_dir = "models/qwen2.5-1.5b-instruct-gptq-llmc" # 定义 GPTQ 量化策略 gptq_recipe = [ GPTQModifier( scheme="W4A16", # 权重 4bit,激活保持 16bit targets="Linear", # 只量化线性层 ignore=["lm_head"], # 保持输出头的高精度,避免性能损失 ), ]scheme="W4A16":W4 代表权重(Weights)被量化为 4-bit 整数,将模型体积压缩为原来的 1/4;A16 代表激活值(Activations)在计算时保持 16-bit 浮点精度(FP16/BF16)。这种组合既降低了显存占用,又利用了 GPU 的 INT4 Tensor Core 进行加速,同时保持了较高的计算精度。targets="Linear":指定量化仅应用于线性层(Linear Layers)。Transformer 模型的大部分参数都集中在这些全连接层中。ignore=["lm_head"]:这是一个必须注意的细节。模型的输出头(LM Head)负责将高维特征映射回词表空间,对数值精度极其敏感。对其进行 4-bit 量化往往会导致输出乱码或逻辑崩坏,所以通常将其排除在量化范围之外。
-
执行 One-Shot 量化(
oneshot):oneshot( model=base_model_id, dataset="open_platypus", # 使用公开数据集进行校准 recipe=gptq_recipe, # 传入定义好的量化策略 output_dir=gptq_out_dir, max_seq_length=2048, num_calibration_samples=128, # 128个样本通常足够计算准确的统计信息 )-
llmcompressor提供的oneshot函数将加载模型、应用算法并保存结果,全流程一气呵成。 -
输出为压缩后的模型检查点。
-
在这个过程中,校准(Calibration) 是不可或缺的一环。与微调不同,GPTQ 是一种 Post-Training Quantization (PTQ) 方法,它不需要全量训练,但需要少量的真实数据来“观察”模型的激活值分布。
dataset="open_platypus":GPTQ 依赖于计算海森矩阵来判断权重的重要性。我们需要输入一些具有代表性的文本数据。当前选用的open_platypus是一个高质量的指令微调数据集,涵盖了逻辑推理、代码生成等多种任务,能够很好地代表真实场景的输入分布,防止量化后的模型在特定领域能力退化。num_calibration_samples=128:通常情况下,128 到 512 个样本就足以计算出准确的统计信息。过多的样本不仅增加耗时,边际收益也递减。
-
-
加载与验证:量化后输出的层类型变为
CompressedLinear,说明原本庞大的 FP16 线性层已经被成功替换为支持压缩张量计算的专用层。同时,quantization_config中清晰地记录了量化策略:weights部分显示num_bits: 4和group_size: 128,确认模型已按照 W4A16 的分组量化策略进行了压缩。推理测试确认生成内容逻辑清晰,能力保持完好。
3. AWQ 量化实战要点
-
使用
AWQModifier,参数配置与 GPTQ 类似,主要区别在于使用AWQModifier。oneshot基本除了名称其他基本相同。
from llmcompressor.modifiers.awq import AWQModifier
awq_out_dir = "models/qwen2.5-1.5b-instruct-awq-llmc"
awq_recipe = [
AWQModifier(
scheme="W4A16",
targets="Linear",
ignore=["lm_head"],
),
]-
在 AWQ 量化时,日志中出现的 SmoothQuant 或 Smoothing 阶段,是
llmcompressor在实现 AWQ 时对平滑/缩放步骤采用的内部命名,算法本身依然是 AWQ(与 SmoothQuant 论文中的方法不同)。这个过程本质上是在执行一次网格搜索(Grid Search),所以我们会发现 AWQ 的量化过程比 GPTQ 要慢很多。 -
因为 GPTQ 的核心计算(海森矩阵求逆)是确定性的数学解析过程,计算量相对固定;而 AWQ 需要针对每一层,在校准数据上反复尝试不同的缩放因子 ss,来找到让量化误差最小的最优解。这个迭代搜索的过程自然比单次矩阵运算更耗时。
-
大模型中常存在极少数数值巨大的激活值(尖峰),如果不加处理直接量化,会带来巨大的精度损失。AWQ 的 Smoothing 过程相当于将这些“尖峰”的压力平滑地分摊到了权重上,从而在不增加推理计算量的前提下,显著降低了量化噪声。
-
优势:对激活值离群点更鲁棒,在 vLLM 中可获得更好的原生加速支持。。量化完成后,可以使用与 GPTQ 相同的方式加载和测试模型。
核心要点总结:量化是通过降低数值精度来压缩大模型的关键手段,GPTQ 基于二阶信息进行误差补偿,AWQ 利用激活值幅度进行缩放保护,BitsAndBytes 则通过混合精度有效应对离群值。实战中通过 llmcompressor 可快速完成 W4A16 量化,显著降低显存并保持模型性能。
二、DeepSpeed 分布式训练框架
1、DeepSpeed 概述
-
定位:微软开源的 PyTorch 分布式训练与推理优化库,侧重于系统与算力优化。Hugging Face 更偏向“模型与数据”的生态(
transformers、datasets等),而 DeepSpeed 更偏向“系统与算力”的生态(显存优化、并行策略、通信调度等)。 -
核心目标:从零预训练、全量微调甚至训练万亿参数模型,用更少显存训练更大模型、更快训练、更稳扩展。
-
主要子模块:
-
DeepSpeed Training(核心):含 ZeRO、Offload、Infinity、3D 并行等。
-
DeepSpeed Inference / Compression:推理加速、量化、剪枝、KV Cache 优化。
-
DeepSpeed-MoE:面向混合专家模型的高效路由与通信。
-
DeepSpeed-Chat / RLHF:大规模 RLHF 训练流水线。
-
DeepSpeed for Science:将系统能力扩展到科学计算。
-
2、训练面临的三大挑战与显存分析
1. 三大挑战
-
显存不足:万亿参数模型所需的状态远超单卡显存。
-
加速比不理想:单纯堆 GPU 会遇通信瓶颈,难以线性加速。
-
硬件异构:GPU 显存、CPU 内存、NVMe SSD 等资源需协同利用。
围绕这三个问题,DeepSpeed 提出了以 ZeRO(Zero Redundancy Optimizer) 为核心的一系列技术(ZeRO、ZeRO-Offload、ZeRO-Infinity),再叠加数据并行、模型并行、流水线并行构成完整的 3D 并行框架。
2. 全量训练显存开销估算(以 7B 模型 + Adam 为例)
前面我们已经学会了如何估算推理阶段的显存开销,知道“只加载权重并做前向传播”大概需要多少显存。这里我们换一个视角,聚焦在训练相对于推理多出来的那一部分显存。
假设我们想要对一个 7B 模型(约 70 亿参数)进行全量预训练或微调,并采用常见的 Adam 优化器和混合精度训练策略。
-
参数(FP16/BF16):7×10⁹ × 2 Bytes ≈ 14 GB
-
梯度(FP16):反向传播中同样以 16-bit 精度存储 ≈ 14 GB
-
优化器状态(Adam,FP32):
-
每个参数:master weights (4) + m (4) + v (4) = 12 Bytes
-
总:7×10⁹ × 12 ≈ 84 GB
-
-
模型状态合计:14 + 14 + 84 = 112 GB(不含激活、临时张量、碎片)
-
每参数平均开销:2(参数) + 2(梯度) + 12(优化器) = 16 Bytes/参数
在经典数据并行 + Adam 的设定下,每个可训练参数平均需要约 16 Bytes 显存(不含激活)。这就是 DeepSpeed 想要“动刀”的地方。如果我们能把这 16 Bytes 中的冗余复制部分打散分摊到多张卡上,每张卡就不需要承担完整的 16 Bytes 开销,从而在固定总 GPU 数量下训练更大的模型。
3、ZeRO(Zero Redundancy Optimizer)核心思路
-
什么是冗余:传统数据并行(DP)每张 GPU 都存完整模型副本,模型状态被重复存储 N 次。
-
ZeRO 的本质:将优化器状态(OS)、梯度(G)、参数(P)在所有 GPU 间分片存储,消除冗余。
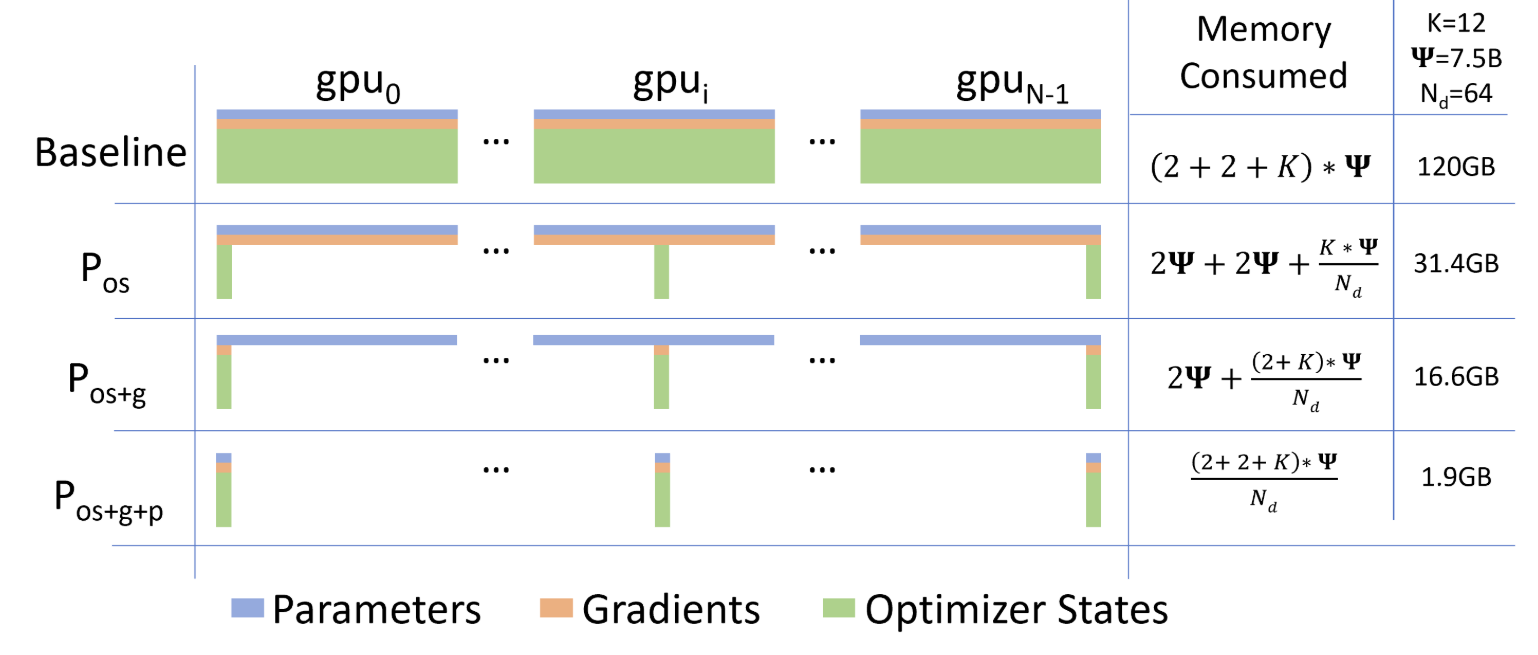
1. ZeRO 三个阶段
| 阶段 | 分片内容 | 单卡显存开销(比例) | 通信量 |
|---|---|---|---|
| ZeRO-1 | 仅优化器状态(OS) | P + G + OS/DP | 2Ψ(同标准 DP) |
| ZeRO-2 | OS + 梯度(G) | P + G/DP + OS/DP | 2Ψ |
| ZeRO-3 | OS + G + 参数(P) | (P+G+OS)/DP | 3Ψ(约 1.5× 标准 DP) |
-
公式记忆:
ZeRO-1: ∝P+G+OSDP
ZeRO-2: ∝P+GDP+OSDP
ZeRO-3: ∝PDP+GDP+OSDP -
效果:DP=64 时,ZeRO-3 将每参数显存从 16 Bytes 压缩至约 0.25 Bytes。
-
实测数据:1024 张 GPU + ZeRO-3 训练 1T 模型仅需单卡 15.6 GB。
-
分片会引入额外的通信开销。ZeRO 论文中对通信量(Communication Volume)进行了详细分析(假设模型参数量为 Ψ):
- ZeRO-1 / ZeRO-2:通信量为 2Ψ,与标准数据并行同阶。直观理解是把标准 DP 的
all-reduce用reduce-scatter + all-gather这类等价组合来实现后,总通信量量级不变,但通信“形态”发生了变化(例如 ZeRO-2 需要配合分片优化器在 step 内做参数分片的聚合/同步)。 - ZeRO-3:通信量为 3Ψ ,约为标准数据并行的 1.5 倍。这是因为在前向/反向传播中需要为计算临时聚合当前层所需参数分片(可理解为额外的参数
all-gather),再叠加梯度的reduce-scatter与更新后参数的同步通信。虽然通信量上升,但换来的是参数级别的全分片,使得单卡显存占用能随 GPU 数量近似按 1/DP 下降。
- ZeRO-1 / ZeRO-2:通信量为 2Ψ,与标准数据并行同阶。直观理解是把标准 DP 的
总的来说,ZeRO 系列论文和 DeepSpeed 的工程实现,核心就是在显存开销、通信带宽与计算时间三者之间找到一个工程上可接受、又足够通用的平衡点。由于 ZeRO 节省了大量显存,往往允许使用更大的 Batch Size,可以显著提升计算的算术强度,在部分场景下甚至能观察到超线性加速(Super-linear Speedup)的效果。
2. ZeRO-R(运行时显存优化)
-
目的:进一步降低激活、临时缓冲、显存碎片带来的隐式显存开销。
-
三个维度:
-
分区激活检查点:激活分片存储,按需 all-gather 重建。
-
恒定大小缓冲区:复用大块内存,减少碎片。
-
显存碎片整理:智能分配策略维持可用空间。
-
4、异构内存利用:Offload 与 Infinity
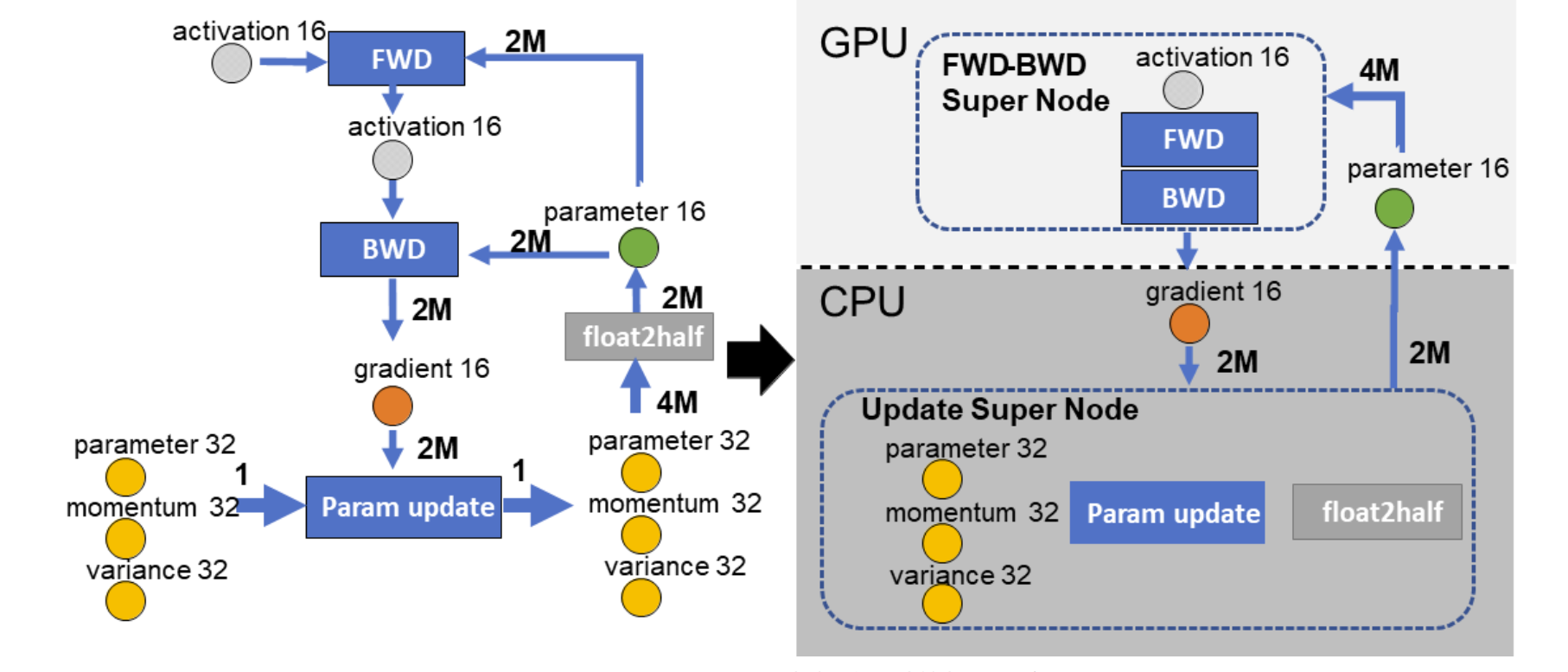
1. ZeRO-Offload
-
核心思路:将 FP32 master 和优化器状态卸载到 CPU 内存,GPU 专心前向/反向计算。
-
单卡数据流:GPU 前反向 → 梯度卸载至 CPU → CPU 更新 FP32 参数与状态 → 更新后参数回传 GPU。
-
关键优化:
-
高效的 CPU Adam(SIMD、多线程)。
-
单步延迟参数更新(DPU):CPU 更新与 GPU 下一步计算重叠,隐藏传输与计算延迟。
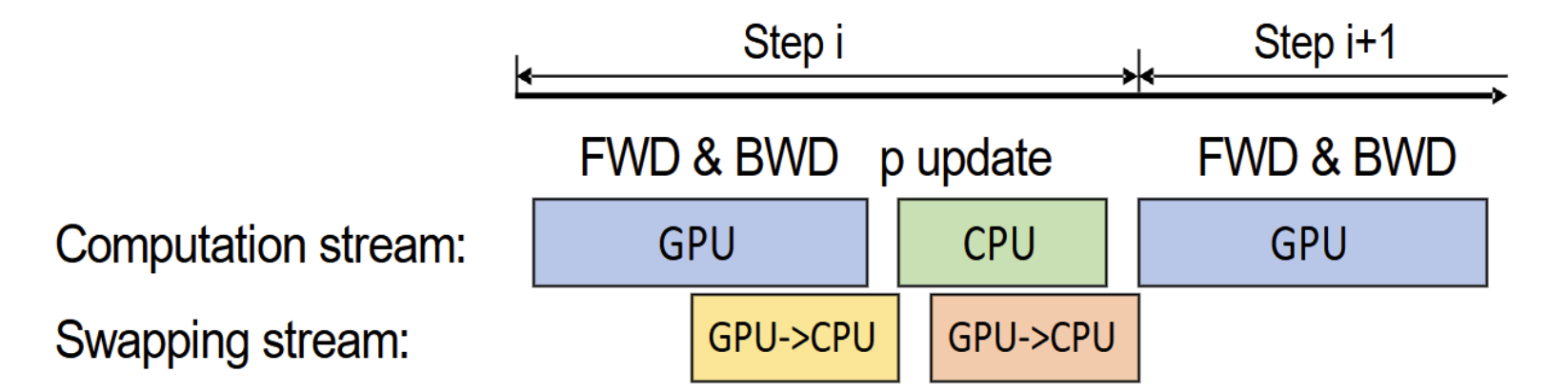
-
-
多卡场景:
-
在单卡 V100 (32GB) 的设置下可将可训练模型规模提升到 10B 量级(论文示例中最高约 13B),并在一定条件下保持较高吞吐(数量级可达数十 TFLOPS)。
-
不过在多卡训练场景下,ZeRO-Offload 通常不会简单地让每张卡各自与 CPU 做大规模同步(这会更容易触及 PCIe/主机内存带宽瓶颈),而是结合 ZeRO-2 的梯度分片机制来控制交换量,先在 GPU 端对梯度做 Reduce-Scatter,将 N 张卡上的梯度切分成 N 份;随后,每张 GPU 只需将自己负责的那 1/N 份梯度 Offload 到 CPU;接着,CPU 并行更新对应的参数分片;最后更新后的参数分片回传到各自 GPU,并通过 All-Gather 同步到需要完整参数副本的设备上。得益于这种“先分片、再 offload”的设计,CPU↔GPU 的交换开销通常不会随卡数线性膨胀,更有利于扩展到更大规模集群。
-
2. ZeRO-Infinity
如果说 ZeRO-Offload 把 CPU 内存也纳入了训练资源,那么 Ren 等人提出的 ZeRO-Infinity 3 则更进一步,把 NVMe SSD 甚至远程存储 也纳入了统一的“内存池”视角。
-
突破显存墙:构建 GPU HBM → CPU DRAM → NVMe SSD 三级异构内存体系。
-
引擎能力:Infinity Offload Engine 自动调度数据在三层间流动,实现全量卸载。
-
不过,将数据放在 NVMe 上最大的挑战是带宽(PCIe 3.0/4.0 远慢于 HBM)。
-
两大关键技术:
-
带宽为中心的切分:
-
传统的 Offload(如 ZeRO-Offload)通常受限于单张卡的 PCIe 带宽,而 ZeRO-Infinity 利用 All-Gather 通信模式,所有 GPU 并行从 CPU/NVMe 拉取数据分片(All-Gather),有效带宽随 GPU 数量线性增加。
-
模型状态被切分并存放在慢速存储(CPU + NVMe)中。与传统的让单个 GPU 负责所有数据传输不同,ZeRO-Infinity 让每张 GPU (GPU(0)GPU(0) 到 GPU(3)GPU(3))并行地通过 All-Gather 操作仅拉取自己负责的那一小部分数据(如 P0(0)P0(0))。这样一来,整个系统的有效带宽就变成了所有 GPU PCIe 带宽的总和,极大地提升了从慢速存储加载数据的效率。
-
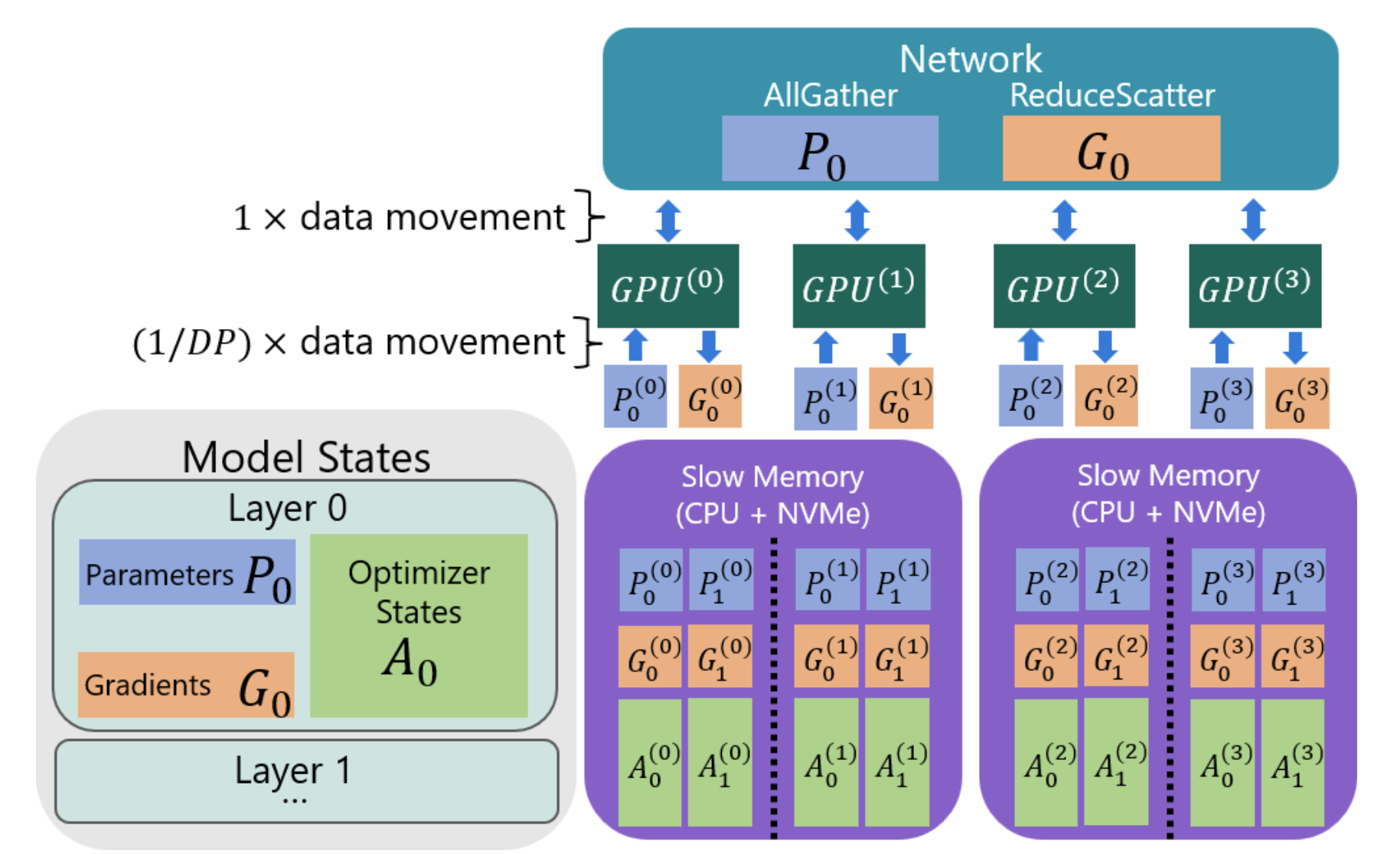
-
-
内存为中心的切片:超大算子拆成 small tiles 逐片计算,避免单层爆显存。每次只加载一个 Tile 到 GPU 参与计算,算完释放,再加载下一个。需要注意的是,这类 tiling 能在一些场景下降低对张量并行(TP)的刚性依赖,但并不意味着“完全替代模型并行”。
-
-
得益于这些技术,ZeRO-Infinity 实现了自动化模型切分,即在模型初始化阶段(
__init__)就自动进行切分和 Offload,防止初始化时就 OOM。 -
它还展现了惊人的扩展性,论文展示了在单台 DGX-2 节点(16 张 V100)上即可微调 1 万亿参数的模型;在 512 张 GPU 上可训练 32 万亿参数的模型。从设计目标来看,ZeRO-Infinity 甚至将视野投向了支撑百万亿参数规模的超大模型训练。
-
在相同硬件条件下(如 512 张 V100 GPU),ZeRO-Infinity 能支持的模型规模(32T)比最先进的 3D Parallelism(0.64T)高出 50 倍。
5、并行策略与生态
ZeRO 主要解决的是“模型状态如何分片”这个问题,但要在大规模集群上高效训练,还需要与其他并行策略配合使用,并理解它在更大生态中的位置。
1. 四类并行策略
-
数据并行(DP):同模型不同数据,显存冗余大;ZeRO 是其核心优化。
-
模型并行( MP):将同一个模型的计算与参数拆分到不同 GPU 上,以突破单卡显存限制。工程实践中更常见的是按张量维度拆分张量并行(TP):单层内算子横向切分至多卡,通信频繁,对跨节点带宽更敏感,适合节点内。
-
流水线并行(PP):按层纵向切分,利用微批次减少“气泡”空闲。
-
3D 并行:DP × TP × PP 联合,支撑超大规模模型训练。
2. 其他模块速览
| 模块名称 | 核心功能与技术特性 | 应用价值与互补性 |
|---|---|---|
| DeepSpeed-Inference / Compression |
|
|
| DeepSpeed-Chat 与 RLHF |
|
|
| DeepSpeed for Science |
|
|
核心总结:DeepSpeed 通过 ZeRO 系列解决“模型状态冗余”这一本质问题,并借助 Offload/Infinity 突破单卡显存与带宽限制,再结合 TP、PP 等多维并行,构建了从单卡到千卡集群、从训练到推理的完整系统优化方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)