Flink内存管理机制:从 Task 到 NetworkBuffer
Flink 的内存不是简单的大池子,而是一套分工明确的运行体系。哪一块紧张,系统就会在哪一层出现瓶颈。
一、为什么要理解 Flink 内存机制
很多 Flink 作业的问题,表面看是吞吐下降、延迟升高,实际根源常常在内存层:
- TaskManager 明明还有空闲内存,却频繁 OOM
- CPU 使用率不高,但作业吞吐始终上不去
- Backpressure 持续存在
- Checkpoint 越来越慢
- RocksDB 状态访问性能下降
不少人遇到性能问题后,第一反应是加机器或调大 JVM Heap。但在 Flink 1.20 中,TaskManager 采用的是统一内存模型,真正影响性能的往往不是总内存大小,而是内存如何被划分和使用。理解 Flink 的内存机制,是进行性能调优的重要基础。
二、Flink 的统一内存模型
JobManager内存模型
组成及配置
| 组成部分 | 配置参数 | 描述 | 默认值 |
|---|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size |
JobManager 的 JVM 堆内存。 | 计算得到 |
| 堆外内存 | jobmanager.memory.off-heap.size |
JobManager 的堆外内存(直接内存或本地内存) | 128MB |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size |
Flink JVM 进程的 Metaspace。 | 256MB |
| JVM 开销 |
|
用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 | min 192 MB;max 1 GB;fraction 0.1 |
通过配置参数设置整个 JM container 内存为 2624MB,各部分分配结果如下(JM 配置相对简单,后续不再展开):
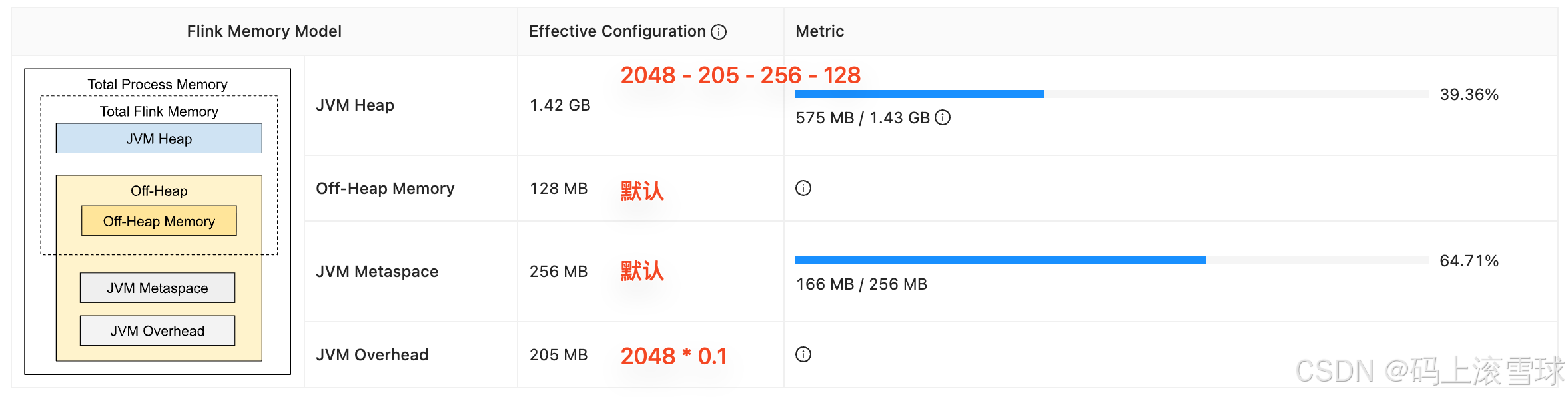
TaskManager内存模型
TaskManager 进程内存则更复杂一些,它会被拆分为多个区域,各自承担不同职责。
组成及配置
| 组成部分 | 配置参数 | 描述 | 默认值 |
|---|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size |
用于 Flink 框架的 JVM 堆内存(进阶配置)。 | 128MB |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size |
用于 Flink 应用的算子及用户代码的 JVM 堆内存。 | 计算得到 |
| 托管内存(Managed memory) | taskmanager.memory.managed.sizetaskmanager.memory.managed.fraction |
由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存,基于 Flink 总内存计算 | size:none fraction:0.4 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size |
用于 Flink 框架的堆外内存(直接内存或本地内存)(进阶配置)。 | 128MB |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size |
用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。 | 0 |
| 网络内存(Network Memory) | taskmanager.memory.network.mintaskmanager.memory.network.maxtaskmanager.memory.network.fraction |
用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分。 | min:64MB max:1GB fraction:0.1 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size |
Flink JVM 进程的 Metaspace。 | 256MB |
| JVM 开销 | taskmanager.memory.jvm-overhead.mintaskmanager.memory.jvm-overhead.maxtaskmanager.memory.jvm-overhead.fraction |
用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 | min 192 MB;max 1 GB;fraction 0.1 |
通过配置参数设置整个 TM container 内存为 1024MB,各部分分配结果如下:
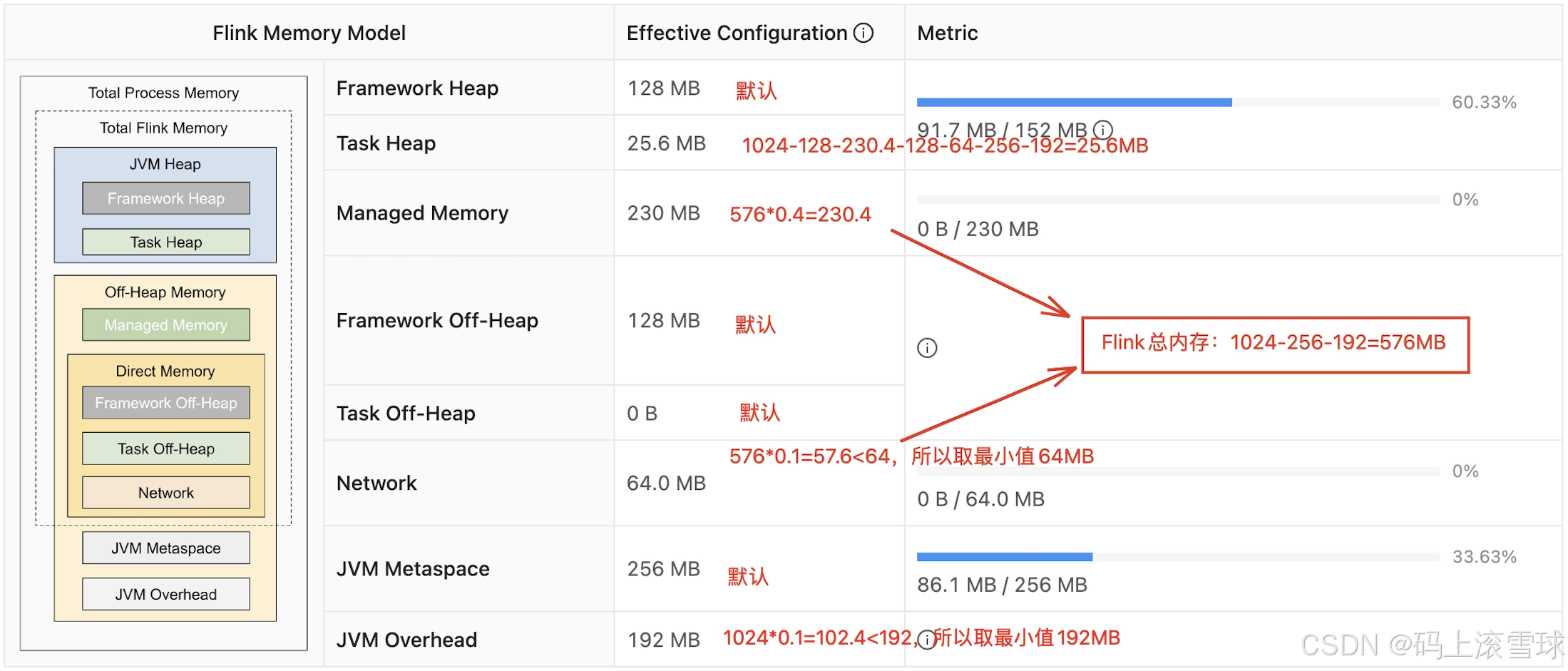
这意味着:Flink 的内存不是统一分配给 JVM,而是按用途精细切分。不同区域出现瓶颈,表现出的线上问题也完全不同。
三、源码解析:TaskManager 内存如何初始化
TaskManager 启动时,会根据配置计算各区域大小,并初始化对应组件。核心启动链路如下:
TaskManagerRunner.start()
└── startTaskManagerRunnerServices()
└── taskExecutorServiceFactory.createTaskExecutor()
└── startTaskManager() // TaskManagerRunner.java:589-676
├── TaskManagerServicesConfiguration.fromConfiguration()
├── TaskManagerServices.fromConfiguration()
│ ├── createShuffleEnvironment() // 初始化 Shuffle 网络环境
│ └── createMemoryManager() // 初始化托管内存管理器
└── new TaskExecutor(...)
└── taskExecutorService.start()
└── RpcEndpoint.start()
└── rpcServer.start()
关键类:
| 类 | 职责 |
|---|---|
TaskExecutorProcessUtils |
解析总内存配置并计算各区域大小 |
TaskExecutorMemoryConfiguration |
保存内存分配结果 |
MemoryManager |
管理托管内存 |
ShuffleEnvironment |
初始化网络 Buffer 系统 |
例如 TaskExecutorProcessUtils 会根据 taskmanager.memory.process.size 推导出:
- Heap 分配多少
- Managed Memory 分配多少
- Network Memory 分配多少
- JVM Overhead 预留多少
这也是为什么 Flink 推荐配置总进程内存,而不是单独调 JVM 参数。
四、NetworkBuffer:数据流动的关键内存
如果说 Task Heap 负责计算,那么 Network Memory 负责流动。它主要服务于:
- 上游
ResultPartition输出数据 - 下游
InputGate接收数据 - Credit-Based Flow Control 背压机制
- Shuffle 网络传输
核心组件:
| 组件 | 作用 |
|---|---|
NetworkBufferPool |
全局 Buffer 池 |
LocalBufferPool |
单任务本地 Buffer 池 |
BufferBuilder |
写入数据 |
BufferConsumer |
消费发送 |
常见的数据流调用路径为:requestBuffer() → write record → flush → recycle buffer。一旦 Network Buffer 不足,就会直接表现为:
- 吞吐下降
- 上游发送阻塞
- Backpressure 升高
- Checkpoint Barrier 传播变慢
所以有些阻塞情况以为是算子处理慢,实际是网络 Buffer 不够。
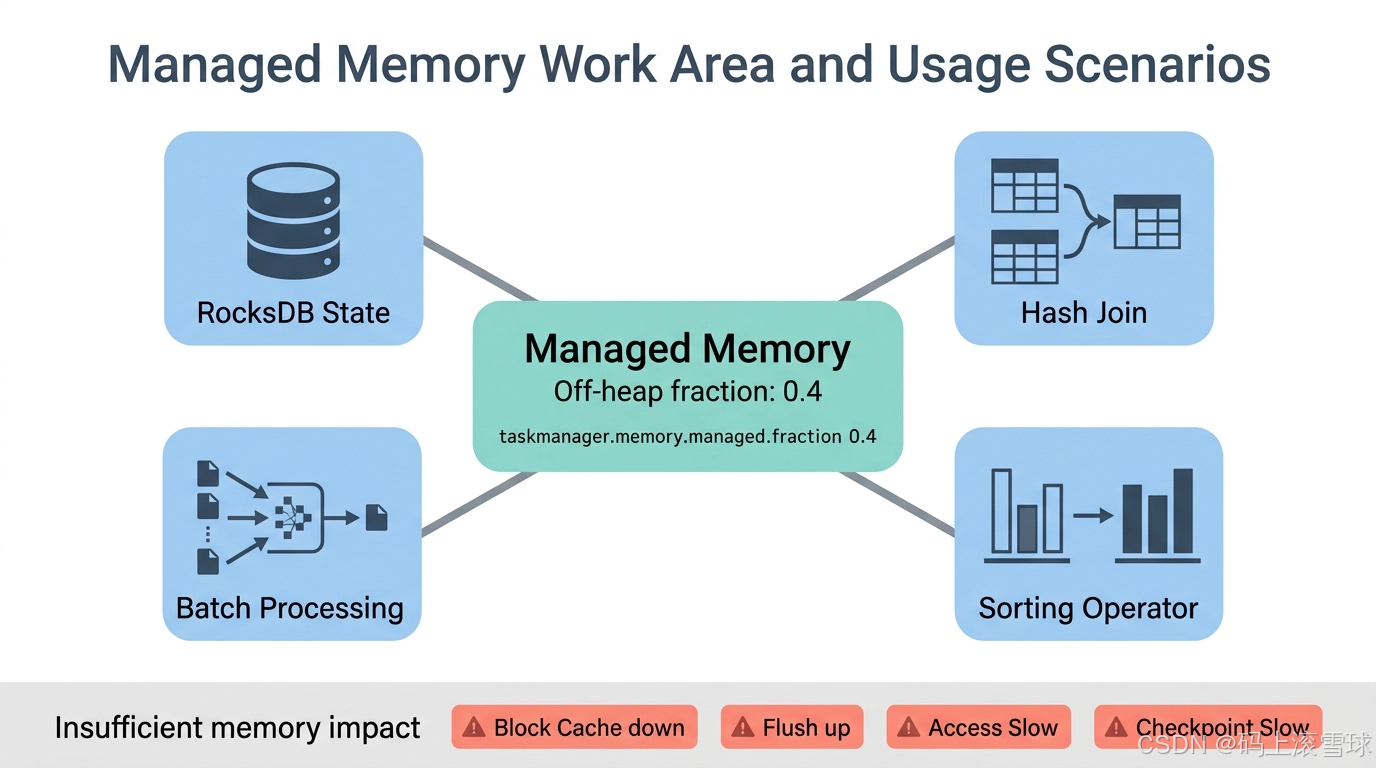
五、Managed Memory:计算与状态的工作区
Managed Memory 是 Flink 托管的内存区域,属于 off-heap 的范畴。它的设计目标是为计算密集型操作和状态管理提供专用内存空间,主要用于:
- Hash Join
- 排序算子
- 批处理算法
- RocksDB State Backend 缓存
配置示例:taskmanager.memory.managed.fraction: 0.4,表示总可用内存中一定比例分给托管内存。当作业状态很大,或 RocksDB 使用频繁时,这部分内存非常关键。如果 Managed Memory 太小,可能出现一系列性能问题:
| 问题现象 | 原因分析 | 代码层面表现 |
|---|---|---|
| RocksDB 频繁刷盘 | Block Cache 不足,导致频繁从磁盘读取数据 | RocksDB.flush() 调用次数激增 |
| 状态访问变慢 | 热点数据无法缓存在内存中 | 状态读取耗时从 μs 级变为 ms 级 |
| Checkpoint 变慢 | 序列化/反序列化需要频繁 IO | CheckpointStreamFactory 写入耗时增加 |
| CPU 飙升 | 大量时间消耗在内存分配和 GC 上 | UnsafeMemoryBudget.reserveMemory() 竞争加剧 |
六、Heap 与 Off-Heap 的区别
Flink 在运行中同时使用堆内与堆外内存。
| 类型 | 优点 | 风险 |
|---|---|---|
| Heap Memory | Java 对象访问快 | 容易触发 GC |
| Off-Heap Memory | 减少 GC 压力 | 排查复杂 |
| Direct Memory | 网络传输效率高 | 配置不足易 OOM |
例如:
- 用户代码对象通常在 Heap
- Network Buffer 常在 Direct Memory
- RocksDB 大量使用 Off-Heap
因此,GC 高,不一定是总内存不足;也可能是 Heap 配置过小,单数据对象过多。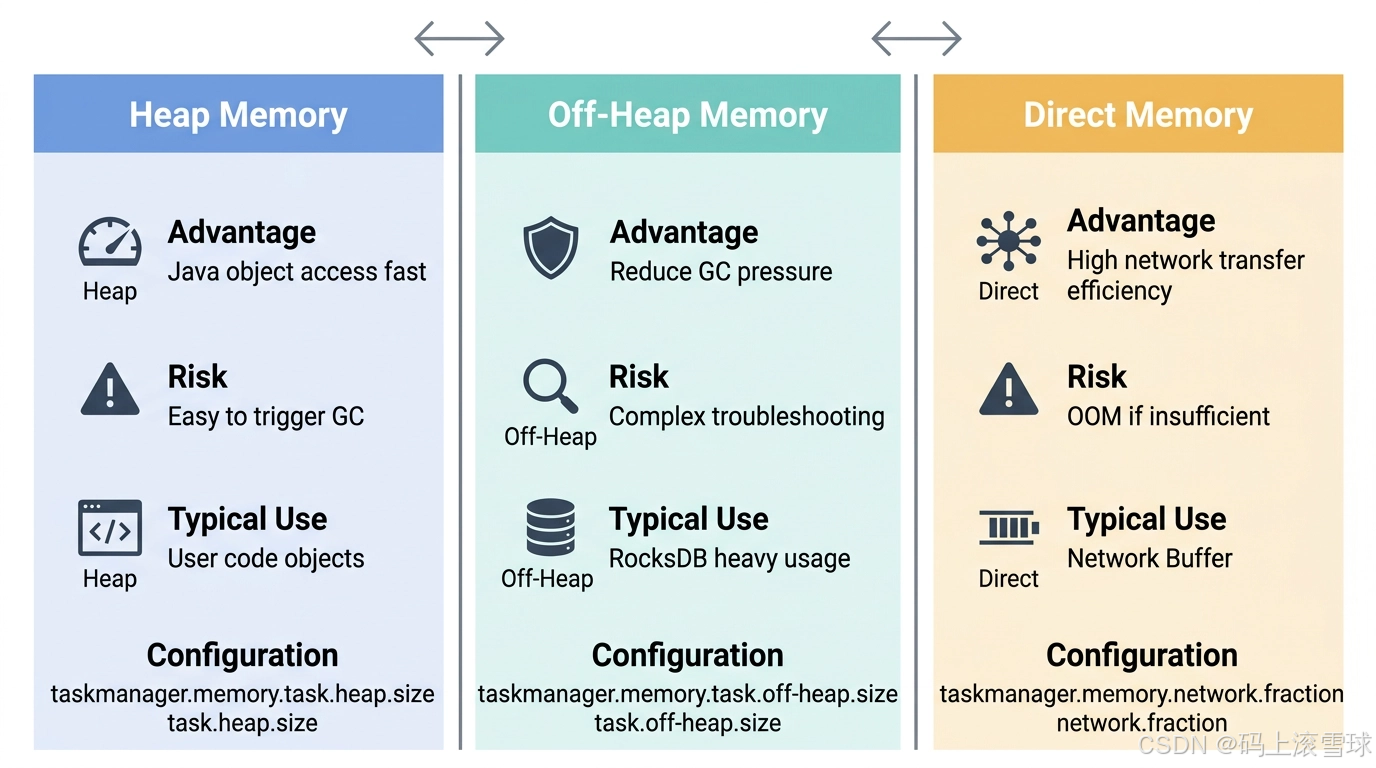
七、线上调优建议
1. 吞吐低 + Backpressure 高
优先检查:taskmanager.memory.network.fraction,适当提高 Network Memory。
2. Full GC 频繁
说明 Heap 压力大,可考虑:
- 提升 Task Heap(如果没有用到 Managed Memory,可以通过减小管理内存来增加堆内存,如
taskmanager.memory.managed.size: 50mb) - 减少对象创建
- 使用对象复用机制
3. RocksDB 慢
提高:taskmanager.memory.managed.size 让状态缓存更充足。
4. Checkpoint 慢
重点排查:
- Network Buffer 是否紧张
- Managed Memory 是否不足
- 状态数据是否过大
八、总结:内存决定了系统的运行节奏
我们可以这样理解 Flink 的内存体系:
| 区域 | 职责 |
|---|---|
| Heap | 承载对象与算子执行 |
| Managed Memory | 承载状态与算法计算 |
| Network Memory | 承载数据流动 |
| JVM Overhead | 保证进程稳定运行 |
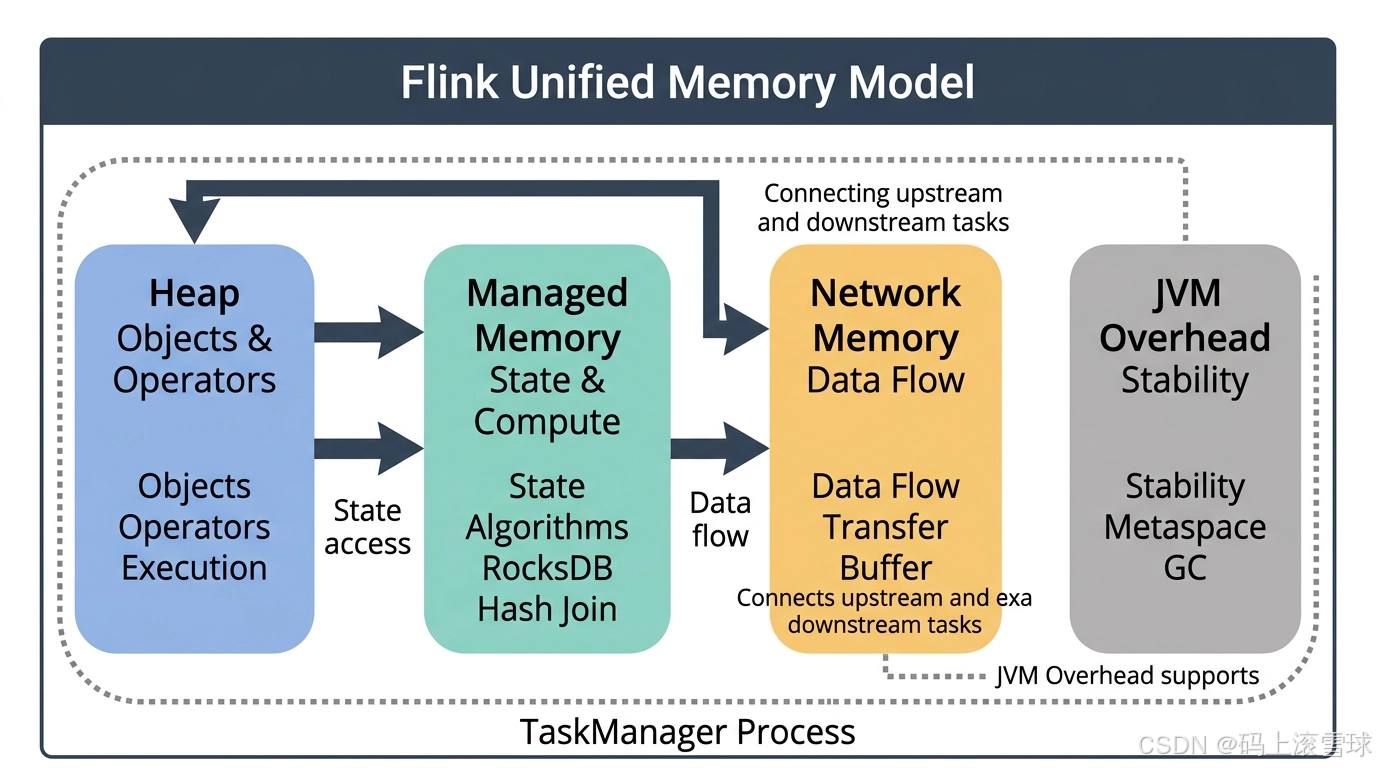
Flink 的内存不是简单的大池子,而是一套分工明确的运行体系。哪一块紧张,系统就会在哪一层出现瓶颈。
当我们理解了数据如何执行、如何传输,以及内存如何影响吞吐与稳定性后,真正的线上调优才刚刚开始:
- 并行度该怎么设置才合理?
- 背压出现后先看哪里?
- Checkpoint 参数如何在性能与稳定之间平衡?
- 资源很多,作业为什么还是跑不快?
这些问题,单靠理解原理还不够,更需要系统化的调优方法。
下一篇,我们进入:《Flink 作业调优实战:从并行度到 Checkpoint 策略》

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)