MCP模型上下文协议
什么是MCP
模型上下文协议 (MCP) 是一个标准化的人工智能应用架构框架,它促进了人工智能系统与各种数据源、工具和服务之间的通信。正如 USB-C 为设备提供通用接口以便与多种配件交互一样,MCP 为人工智能应用提供了一种标准化的方式,使其能够连接到不同的工具、数据库和外部服务。
MCP 的核心是客户端-服务器架构,它使 AI 应用能够发现、访问和利用各种功能,而无需进行硬编码集成。这种设计为 AI 应用创建了一个更具可扩展性、可维护性和稳健性的生态系统;也就是说agent作为MCP的client,调用不同的MCP server(每一项工具/能力都做成MCP server)
为什么需要MCP
llm具有很强大的信息处理能力,但是它本身与外部世界隔绝,它既无法与外部世界的数据连通(数据库、网盘),也无法使用外部工具(联网搜索、读写文件)。
真实的agent往往需要很多的能力,如果没有MCP,每有一个数据源过来就添加一个工具,每个tool工具都要使用专门的数据格式、数据库、api接口、RAG......,前期还能支撑过来,等数据源高达数十上百,就会发现太乱了,东西太多了。而且每个LLM都不一定适配之前写的工具,也不能保证百分百复用。带来的后果就是不同的大模型需要写不同的tool,工作量太多,太乱。
有了MCP之后,只要别人已经做好一个MCP server,你的agent就可以向后端发起标准化的MCP请求就能调用外部工具和数据;MCP 工具可以单独跑在另一台服务器、另一个进程,不用像tool那样跑在同一个进程里面。
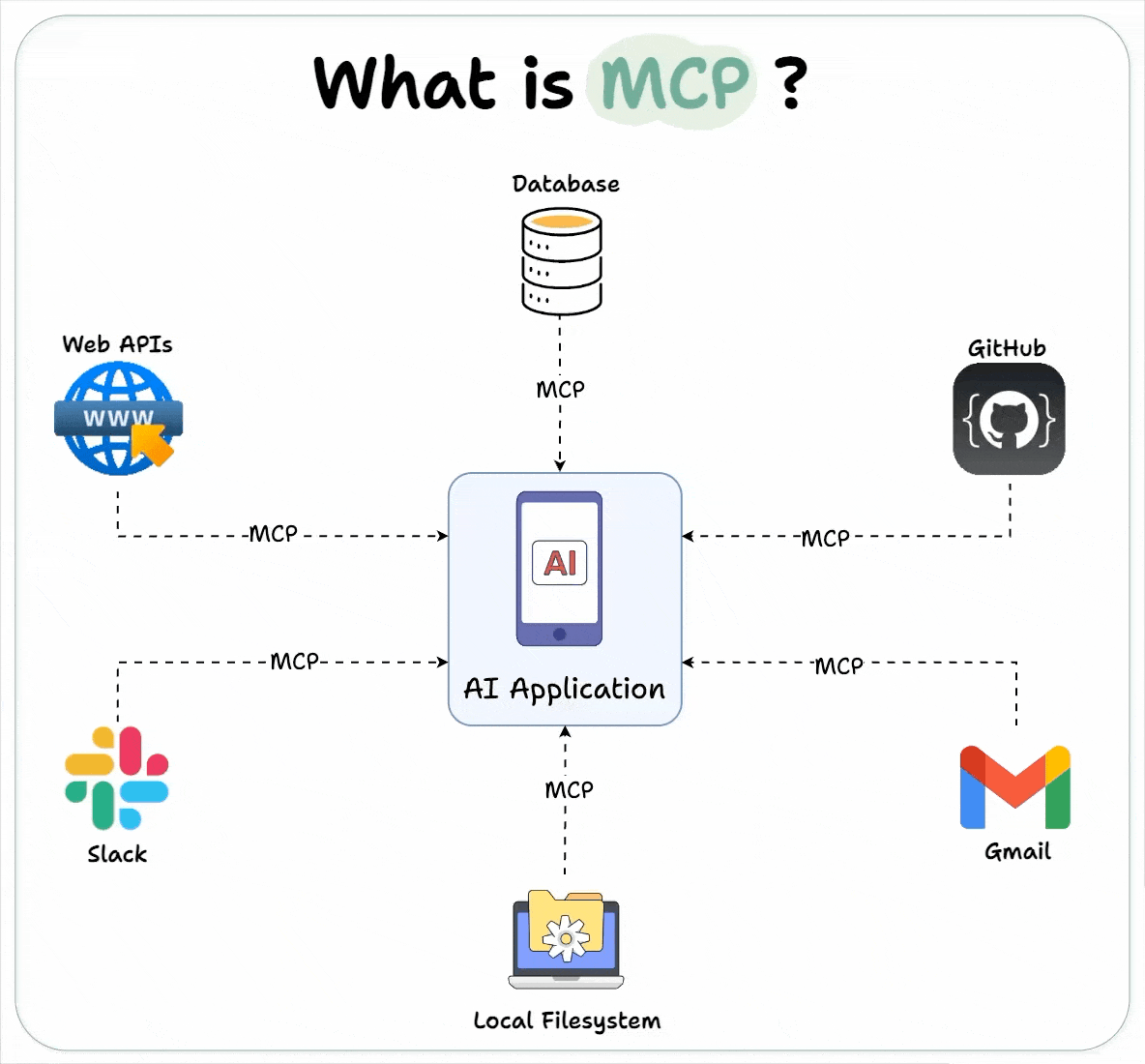
所以说MCP 就是 AI 界的 USB 标准:
-
电脑 = 大模型(Client,如 Claude Desktop, IDE)。
-
USB 设备 = 你的数据源(Server,如本地文件、数据库、Slack)。
-
MCP 协议 = 那个通用的 USB 插口形状和传输规则。
只要你的数据源支持 MCP,任何大模型都能直接“插”上去读取数据,不需要重复造轮子!
MCP的构成
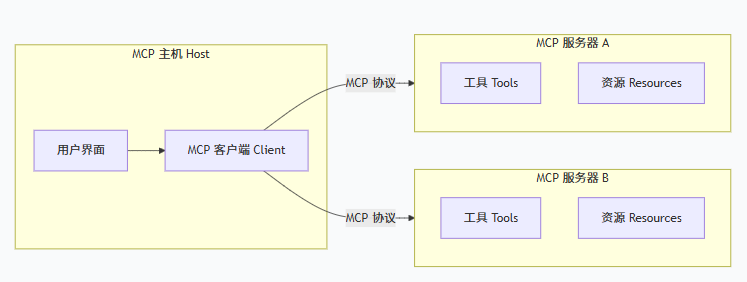
MCP 采用客户端-服务器架构,其中 MCP 主机(例如Claude Code或cherry stodio、cursor等 AI 应用)与一个或多个 MCP 服务器建立连接。MCP 主机通过为每个 MCP 服务器创建一个 MCP 客户端来实现这一点。每个 MCP 客户端与其对应的 MCP 服务器保持一对一的专用连接。
MCP架构的关键组成包括:
-
MCP 主机:用于协调和管理一个或多个 MCP 客户端的 AI 应用程序(比如你的cc、deepseek)
-
MCP 客户端:一个维护与 MCP 服务器连接并从 MCP 服务器获取上下文以供 MCP 主机使用的组件。
-
MCP 服务器:一个为 MCP 客户端提供上下文信息的程序
MCP协议底层
MCP协议底层有两部分:消息规范和数据传输方式
-
数据层:定义了基于 JSON-RPC 的客户端-服务器通信协议,统一请求、响应、通知格式,包括生命周期管理和核心元素,如工具、资源、提示和通知。
-
传输层:定义了客户端和服务器之间进行数据交换的通信机制和通道,包括特定于传输的连接建立、消息帧和授权。
MCP server
MCP Server 是一个轻量级的程序,专门把工具、数据、提示词封装成符合 MCP 标准的能力,对外提供给任何 MCP 客户端调用。
它通常专注于某个特定的领域(比如“文件操作”、“GitHub 管理”或“数据库查询”)。它不关心是哪个 AI 模型在调用它,也不关心用户是用什么软件(Cursor 还是 Claude Desktop)在操作,它只关心一件事:“只要你用 MCP 协议发指令,我就帮你执行并返回结果。”
MCP server三大核心能力:
- Tools:可被 AI 调用的函数(类似远程 @tool)
- Resources:上下文数据源(文件、知识库、数据库内容)
- Prompts:可共享的提示词模板
工具Tool
这是 Server 允许 AI 执行的主动操作,AI可以这些工具进行查询、搜索、计算等行为
server = MCPServer()
# 2. 定义一个 Tool(远程函数)
@server.tool()
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
return f"{city} 的天气:晴天,25℃"资源Resources
这是 Server 提供给 AI 的被动数据,都是可供AI读取的各种数据源(上下文、pdf、数据库......)
# 1. 注册一个资源(比如用户信息、知识库、文档内容)
@server.resource("user://123")
def get_user_info():
"""返回用户信息资源"""
return {
"name": "jran",
"age": 20,
"preferences": "喜欢AI、编程、Agent"
}提示词Prompt
这是 Server 预先写好的通用对话模板,你可以写角色设定、翻译模板、任务模板等内容
# 注册一个提示词模板
@server.prompt("customer_service")
def customer_service_prompt(user_query: str):
"""客服角色提示词"""
return f"""
你是专业客服,语气友好、简洁。
用户问题:{user_query}
请礼貌回答。
"""MCP client
Client(客户端) 扮演着指挥官和桥梁的关键角色。简单来说,它是连接“大脑”(大语言模型/LLM)与“手脚”(MCP Server 提供的工具和数据)的中间枢纽。
Client 的主要工作就是代表宿主应用(Host)去管理与各种 Server 的连接,并将 Server 的能力“翻译”给大模型听,同时把大模型的指令“传达”给 Server 执行
Elicitation输入请求
“通过 UI 界面,协助用户完成复杂的指令。”
-
概念: Server 提供一个任务模板(Prompt)然后向Client发起结构化请求,Client 负责将这个模板渲染成用户界面(UI),引导用户填入必要的参数,然后将填好的内容交给 AI。
-
作用:
-
Server 提供了一个git-commit的 Prompt。
-
Client 弹出一个窗口问用户:“你想提交什么更改?(参数1)”、“提交信息写什么?(参数2)”。
-
用户填完后,Client 把这些信息打包发给 LLM。
-
-
Client 的职责:
-
发现: 获取 Server 提供了哪些 Prompts。
-
渲染: 当用户选择某个 Prompt 时,Client 要能画出对应的输入框或表单。
-
提交: 将用户输入的内容(Elicited info)作为上下文发送给 LLM。
-
Roots管理文件系统范围
“定义 Server 可以访问哪些数据。”
-
概念: Client 需要告诉 Server:“这是我的工作区(Workspace),你只能在这个范围内读取文件。”
-
作用: 它是 MCP 的安全基石。如果没有 Roots,Server 就无法知道它应该在哪个文件夹下工作,或者可能会越权访问用户隐私。
-
Client 的职责: 维护一个允许访问的文件路径列表,并在初始化时同步给 Server。
Sampling请求 LLM 生成
“允许 Server 使用 Client 的 AI 能力。”
-
概念: 这是一个反向操作。通常是 Client 调用 Server,但 Sampling 允许 Server 反过来请求 Client:“请借我用一下你的 LLM,帮我处理这段数据。”
-
作用: 赋予了工具Agentic(代理) 的能力,让工具不再是死板的代码,而是具备了一定的推理能力(例如:Server 抓取网页后,自己调用 AI 生成摘要)。
-
Client 的职责: 接收 Server 的采样请求,转发给 LLM,并将生成的文本返回给 Server。
MCP的传输模式
MCP有三种运行传输模式
-
stdio:本地子进程方式,最常用、最简单。你的 Agent 直接拉起一个本地 MCP Server 进程,进程间通信。
-
HTTP with SSE:远程部署,跨机器调用,适合企业服务。(已弃用)
-
Streamable HTTP:长连接,适合实时对话、流式返回。
Stdio(标准输入输出)
定位:本地集成的默认标准
这是 MCP 最基础、最常用的模式,主要用于像 Claude Desktop、Cursor 或 IDE 这样的桌面应用连接本地运行的脚本。
-
工作原理:
-
客户端作为父进程,启动服务器脚本(子进程)。
-
发送:客户端将 JSON-RPC 消息写入服务器的stdin(标准输入)。
-
接收:服务器将处理结果打印到stdout(标准输出)。
-
日志:服务器的调试信息必须打印到stderr(标准错误),否则会破坏通信协议。
-
-
生命周期:
-
连接与进程绑定。进程结束,连接即断开。
-
-
适用场景:
-
本地开发。
-
单机工具(如本地文件操作、本地数据库访问)。
-
Streamable HTTP
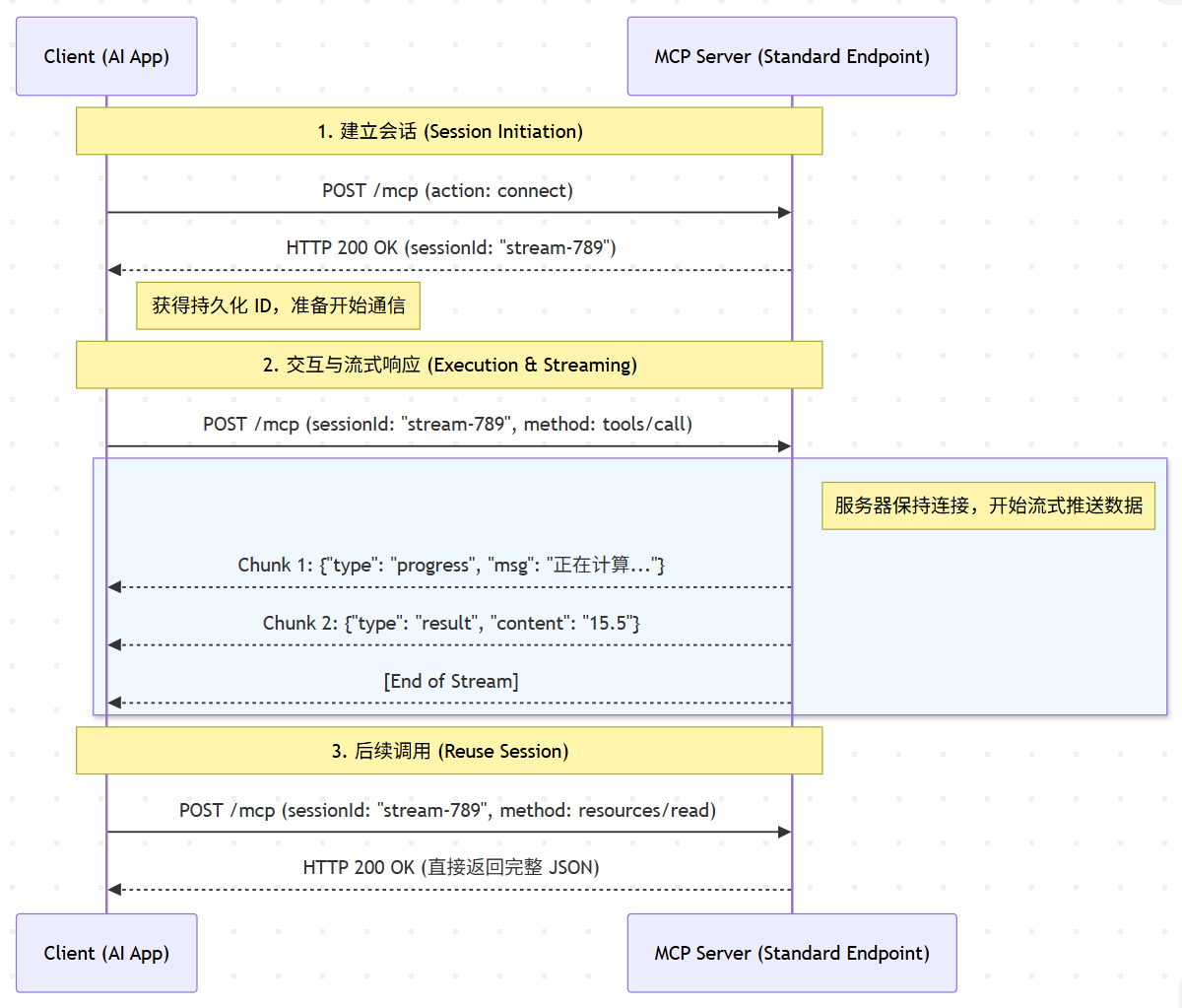
定位:远程服务的终极形态 (Protocol 2024-11-05+)
这是官方文档推荐用来取代 SSE 的新标准。它利用 HTTP 的流式特性,实现了“单通道、全双工模拟”。
-
工作原理:
-
统一入口:不再区分 SSE 和 Message 端点,通常只有一个统一的 Endpoint(如 /mcp)。
-
消息封装:
-
客户端发送 POST 请求,Body 中包含 JSON-RPC 消息。
-
服务器保持连接不关闭,将响应逐行流式传回。
-
-
无状态化:因为请求和响应在同一个 HTTP 上下文中,服务器不需要维护复杂的 Session ID 映射。
-
-
核心优势:
-
防火墙友好:使用标准的 HTTP POST,更容易穿透企业代理。
-
鉴权灵活:完全支持标准的 HTTP Header。
-
架构简单:对于负载均衡器(Load Balancer)和网关更加透明。
-
用FastMCP框架快速建立MCP server
from fastmcp import FastMCP
from typing import Annotated
from pydantic import Field
# 1. 初始化
mcp = FastMCP("fast-health-calculator")
# 2. 定义工具
# 注意:FastMCP 会自动读取函数参数类型 (a: float, b: float) 生成 Schema
# 也会自动读取文档字符串 ("计算两个数字的和") 作为工具描述
@mcp.tool()
async def add(a: float, b: float) -> float:
"""计算两个数字的和"""
return a + b
@mcp.tool()
async def calculate_bmi(weight_kg: float, height_m: float) -> str:
"""
计算 BMI 指数并返回健康建议。
Args:
weight_kg: 体重 (公斤)
height_m: 身高 (米)
"""
if height_m <= 0:
return "错误:身高必须大于 0"
bmi = weight_kg / (height_m ** 2)
result = f"BMI 指数: {bmi:.2f}"
if bmi < 18.5:
return f"{result} (偏瘦)"
elif bmi < 24.9:
return f"{result} (正常)"
else:
return f"{result} (偏胖)"
# 模拟一份静态数据
HEALTH_GUIDELINES = """
1. 每天保持 8 小时睡眠。
2. 多吃蔬菜水果,少吃糖。
3. 每周至少运动 150 分钟。
"""
# 定义资源:使用自定义的 URI 协议头 (health://)
@mcp.resource("resource://health-guidelines", mime_type="text/plain")
async def get_health_guidelines() -> str:
"""获取通用的健康生活指南"""
return HEALTH_GUIDELINES
# 定义提示词模板
@mcp.prompt()
async def analyze_my_health(
name: Annotated[str, Field(description="用户的姓名或昵称")],
weight: Annotated[float, Field(description="体重,单位:公斤 (kg)")],
height: Annotated[float, Field(description="身高,单位:米 (m)")]
) -> str:
"""创建一个让 AI 分析个人健康状况的提示词"""
return f"""
请扮演一位专业的健康顾问。
用户 {name} 的体重是 {weight}kg,身高是 {height}m。
请执行以下步骤:
1. 使用 'calculate_bmi' 工具计算他的 BMI。
2. 读取 'health://guidelines' 资源,结合指南给出建议。
"""
搭建MCP client
import asyncio
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(
model="kimi-k2.5",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_BASE_URL")
)
async def main():
client = MultiServerMCPClient(
{
"fast-health-calculator": {
"transport": "stdio",
"command": "python",
"args": [r"D:\\llm\\LLMProject\\MCP协议\\first_server.py"],
},
}
)
tools = await client.get_tools()
print(tools)
# 获取提示词
prompt = await client.get_prompt(prompt_name="analyze_my_health", server_name="fast-health-calculator",arguments={"name": "Alice", "weight": "60", "height": "1.65"})
print(prompt)
# 获取资源
resources = await client.get_resources(server_name="fast-health-calculator", uris=["resource://health-guidelines"])
print(resources[0].as_string())
if __name__ == "__main__":
asyncio.run(main())MultiServerMCPClient()函数负责创建一个连接多个MCP server的MCP客户端,这个字典参数就是服务器配置表
-
key:服务器名字
-
value:服务器连接方式
在这里fast-health-calculator是我们给MCP服务器起的名字,transport是通信方式,command就是解释器/可执行程序,用来运行后面的服务端脚本,args是路径参数,告诉python要运行哪个文件。
这段代码就是让client找到服务器,启动服务器,连接服务器。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)