如何将影像组学风险评分与结直肠癌的ECM重塑、免疫微环境及代谢通路建立关联,并进一步解释其与患者预后及潜在治疗响应的机制联系
01
导语
各位同学,大家好。做影像组学最怕什么?最怕模型精度很高,但问起“为什么高风险的影像特征就预示预后差”时,只能含糊其辞。说白了,就是缺了生物学机制的“娘家”。今天这篇文献给我们打了一个绝佳样板:它不满足于用CT影像建个风险评分、算个AUC,而是把影像定义的高/低风险组直接“扔”进代谢组和转录组里找答案——结果发现高风险肿瘤富集ECM重塑,低风险肿瘤则有CD8+ T细胞高浸润,还锁定了丁酸代谢和氮代谢两条保护性通路。一句话:让影像特征与细胞外基质、免疫微环境、代谢重编程真正对上话,这才是从“黑箱预测”升级到“讲好疾病故事”的关键一步。

★题目:Integration of radiomics, deep learning, transcriptomics, and metabolomics reveals prognostic risk stratification and underlying biological mechanisms in colorectal cancer
(整合放射组学、深度学习、转录组学和代谢组学揭示结直肠癌预后风险分层及潜在生物学机制)
★期刊:《npj Precision Oncology》(中科院1区,IF=8)
★研究疾病:结直肠癌(CRC)
★生物学机制:ECM重塑、免疫微环境及代谢通路
★发表时间:2026年3月
02
研究背景-从 “临床问题” 落到 “生物学问题”
结直肠癌(CRC)是全球发病率第三、死亡率第二的恶性肿瘤,其预后异质性显著,但当前临床实践中主要依赖病理TNM分期指导治疗决策和风险判断。然而,TNM分期无法充分反映肿瘤内部的分子和代谢异质性,导致许多患者被过度治疗或治疗不足。影像学,尤其是增强CT,是CRC诊疗中的常规手段,但其传统影像特征(如大小、形态、边界)所提供的信息有限,难以揭示肿瘤的生物学行为。近年来,影像组学和深度学习技术可以从医学图像中高通量提取定量特征,无创地反映肿瘤的微观异质性,已在多种肿瘤的预后预测中展现出巨大潜力。然而,现有研究多集中于模型预测性能的优化,缺乏对影像模型所定义的风险分层背后生物学机制的系统解析,这严重限制了模型的临床可解释性和推广价值。此外,不同机器学习算法对模型性能影响巨大,目前尚无公认的最优算法组合。因此,如何在构建高精度影像预后模型的同时,从代谢和转录层面揭示其生物学基础,是影像组学领域亟待解决的关键科学问题。
03
研究目的(明确写出“三层目的”)
本研究旨在构建一个基于增强CT的深度学习影像组学模型(DLRM),并通过系统评估十种机器学习算法的117种组合,筛选出最优模型用于结直肠癌患者的预后风险分层。具体而言,本研究包含三层核心目的:第一,技术层目的——开发一个稳健的影像风险评分(DLRM-RS),能够在多中心数据中显著区分高、低风险患者,并进一步联合临床指标(CEA、N分期)构建列线图,提升个体化预后预测性能。第二,机制层目的——利用代谢组学(NMR)和转录组学(RNA-seq),系统比较高风险与低风险肿瘤之间的差异代谢通路和基因表达谱,揭示影像风险分层背后的生物学本质,尤其是细胞外基质重塑、免疫微环境状态以及关键代谢通路(如丁酸代谢、氮代谢)的变化。第三,验证层目的——在公共数据库(TCGA)中独立验证上述关键代谢通路与患者总生存期的关联,从而为影像模型的生物学解释提供跨组学、跨队列的循证支持。
04
研究思路(最核心:怎么挂靠机制)
本研究的核心思路是以影像模型定义的表型风险分组为桥梁,反向挂靠多组学数据,揭示其内在生物学机制。首先,从四个中心的1183例CRC患者静脉期CT图像中提取1437个影像组学特征和512个深度学习特征,经可重复性、冗余性和单变量Cox筛选后,采用十种机器学习算法的117种组合进行建模与交叉验证,选择平均C-index最高的Lasso+GBM组合构建DLRM-RS,将患者分为高、低风险组。其次,挂靠机制的关键设计:在同一中心(中心3)的52例患者肿瘤组织中采集代谢组学数据,比较高、低风险组之间的代谢谱差异,识别出丁酸代谢、氮代谢等关键通路;同时在TCIA数据库中获取19例患者的转录组数据,通过GSEA分析发现高风险组富集ECM相关通路、低风险组富集免疫相关通路(如CD8+ T细胞浸润),且代谢组和转录组共同指向丁酸代谢和氮代谢。最后,在TCGA-CRC队列(n=417)中利用GSVA评分验证这两个代谢通路的预后价值。整个思路实现了“影像模型 → 表型分层 → 多组学差异 → 生物学通路 → 独立验证”的完整闭环,使影像组学从“黑箱预测”走向“可解释的机制关联”。

图 1:研究整体工作流程图
05
数据和方法(机制部分怎么设计)
数据:研究共纳入来自四个中心的1183例结直肠癌患者,其中中心1的622例按7:3划分为训练队列(435例)和内部验证队列(187例),中心2+中心3的313例作为外部验证队列1,中心4的248例作为外部验证队列2,用于影像模型构建与验证;从中心3选取52例患者的肿瘤及癌旁组织进行代谢组学(NMR)分析,用于比较高低风险组的代谢差异;从TCIA数据库获取19例患者的转录组数据,用于通路富集和免疫浸润分析;从TCGA数据库获取417例患者的转录组及生存数据,用于独立验证关键代谢通路的预后价值。
方法:CT图像预处理(固定窗宽25HU + 重采样至1mm³)→ 肿瘤分割(3D Slicer手动勾画)→ 特征提取(1437个影像组学特征 + 512个深度学习特征)→ 特征筛选(ICC>0.8 + Spearman |r|<0.8 + 单变量Cox)→ 十种机器学习算法的117种组合建模(Lasso+GBM最优)→ 计算DLRM风险评分(最佳截断值-0.380)→ 划分高/低风险组 → 代谢组学分析(OPLS-DA + VIP>1 + t检验筛选差异代谢物 + MetaboAnalyst通路富集)→ 转录组分析(GSEA富集GO/KEGG + CIBERSORT免疫浸润)→ TCGA验证(GSVA评分 + Kaplan‑Meier生存分析)。
06
研究结果(“从表型到机制”)
1. 影像模型构建(表型分层)通过117种算法组合筛选,Lasso+GBM模型的平均C-index最高(0.768),最终纳入9个影像组学特征和6个深度学习特征。以-0.380为截断值划分高/低风险组,Kaplan‑Meier分析显示高风险组总生存显著更差(所有队列p<0.001),3年AUC达0.720~0.759,5年AUC达0.720~0.744,验证了模型稳健的分层能力。
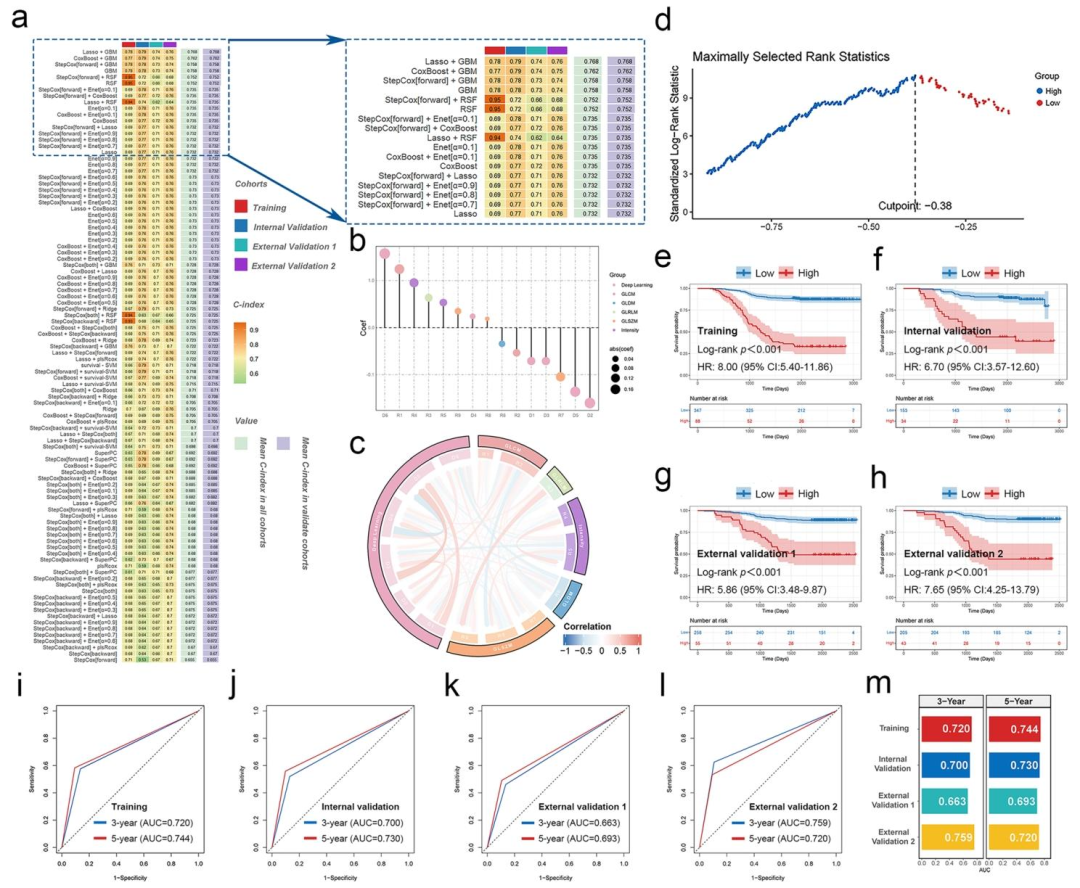
图 2(DLRM-RS的构建与验证):该图呈现了影像模型的核心结果。图2a显示Lasso+GBM组合在所有队列中平均C-index最高(0.768),确立了最优算法。图2b展示15个入选特征的权重,其中深度学习特征feature_172权重最大,提示深度特征对预后贡献突出。图2c的特征相关性热图显示多重共线性低,保证模型稳定性。图2d确定风险评分截断值-0.380。图2e‑h的Kaplan‑Meier曲线显示高风险组总生存显著更差(p<0.001),图2i‑m的时间依赖ROC曲线验证了3年/5年AUC的稳健性。这些结果将影像特征转化为可量化的风险表型,为后续机制分析奠定分层基础。
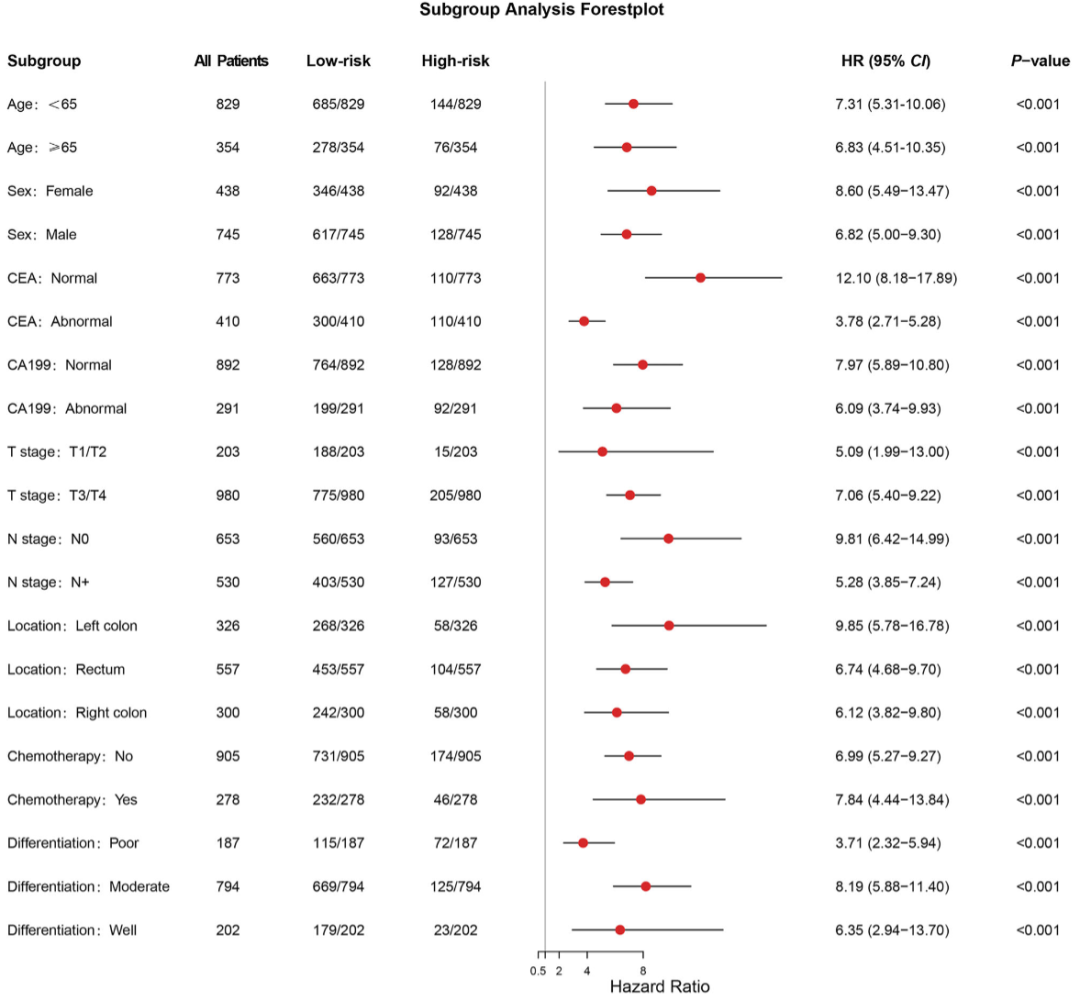
图 3(亚组森林图):该图展示了DLRM-RS在不同临床亚组中的风险比(HR)。无论年龄(≥65岁或<65岁)、性别、CEA/CA199水平、T分期(T1-2 vs T3-4)、N分期(N0 vs N+)、肿瘤位置、是否接受术后化疗或分化程度,高风险组的死亡风险均显著高于低风险组(所有p<0.001)。所有HR的点估计值均>1,且95%置信区间完全不跨过1。该图说明影像风险分层不依赖于特定临床特征,具有广泛的适用性,从而支持将DLRM-RS作为独立于传统临床因素的表型标签用于后续多组学机制探索。
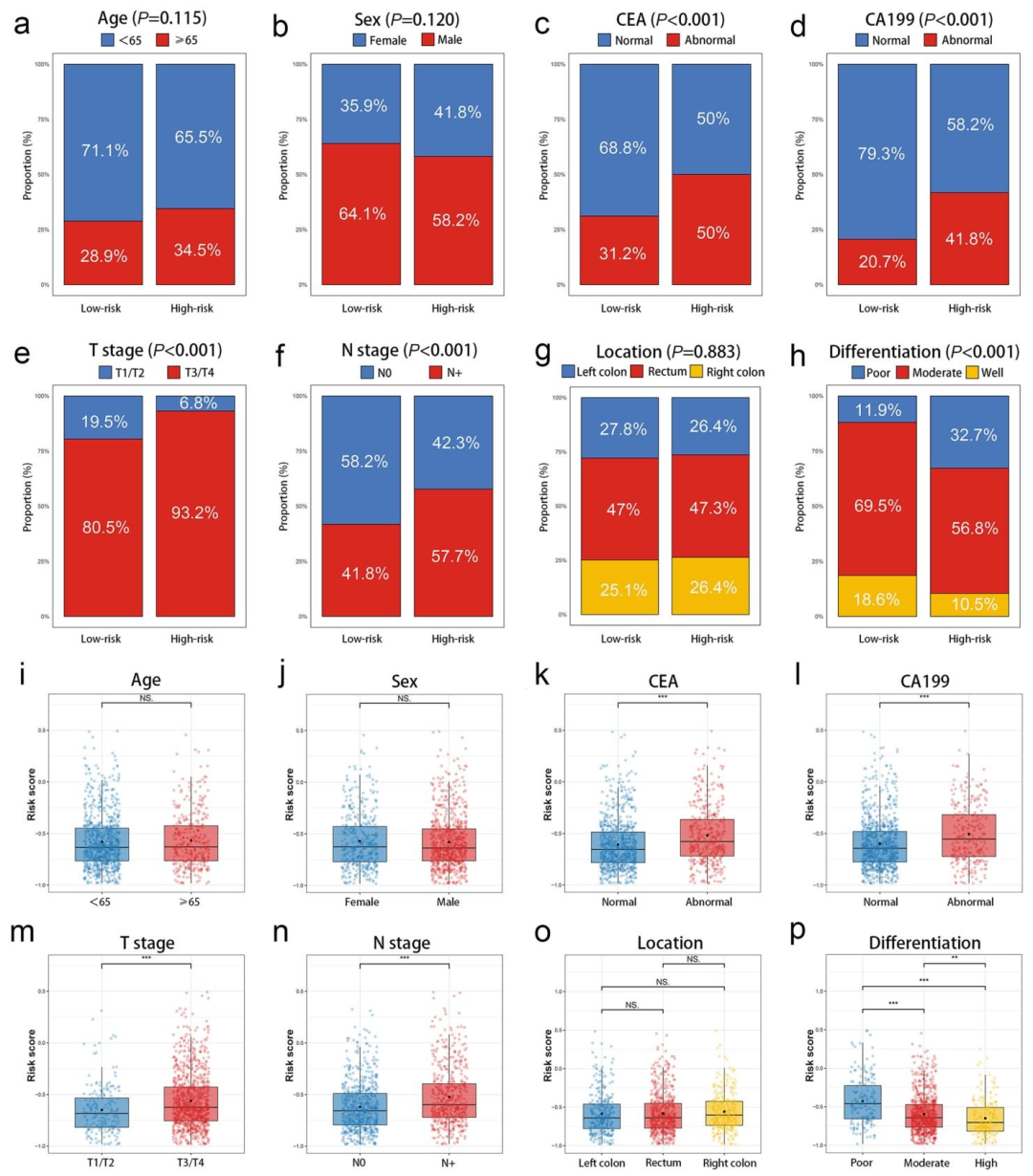
图 4(风险分组与临床特征的关联):该图通过条形图(图4a‑h)和箱线图(图4i‑p)展示了高风险组与不良临床特征的正相关。高风险组中T3-4期、N+期、CEA/CA199升高、低分化的比例显著更高,且这些特征对应的DLRM-RS评分也显著升高。而年龄、性别、肿瘤位置在两组间无显著差异。该图揭示了影像风险评分反映肿瘤侵袭性,即高风险影像表型对应着更晚的病理分期和更强的恶性潜能。这一关联为后续机制解释提供了临床病理层面的佐证:高风险肿瘤在代谢和转录层面应呈现促进展特征。
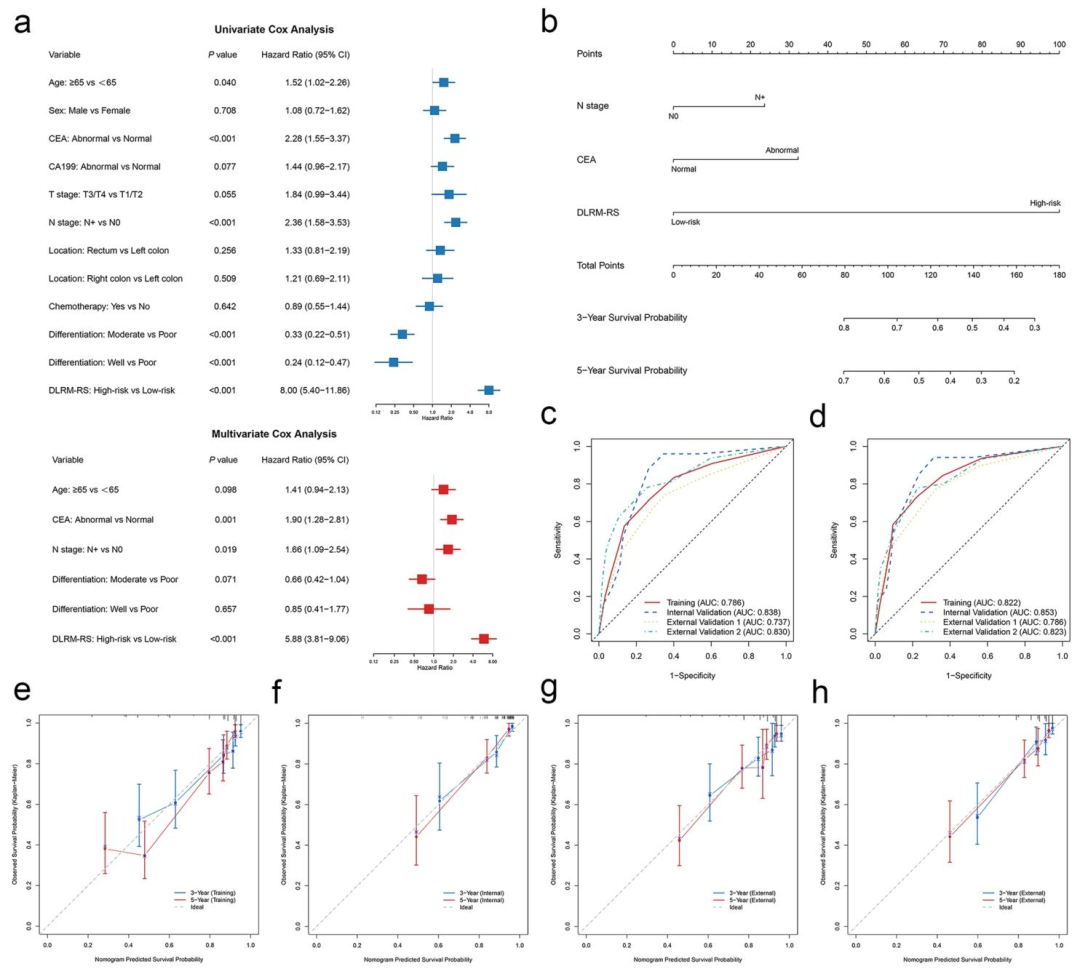
图 5(列线图构建与评估):该图将影像风险评分与临床独立预后因素(CEA、N分期)整合。图5a的多变量Cox回归显示DLRM-RS仍为显著独立预后因子(HR=5.88)。图5b构建的列线图可个体化预测3年/5年生存概率。图5c‑d的时间依赖ROC和表2的C-index比较表明,列线图的预测性能(C-index 0.787-0.804)显著优于单纯临床模型或DLRM-RS模型。图5e‑h的校准曲线显示预测与实际生存高度一致。该图实现了从影像表型到临床决策工具的转化,同时说明影像特征与临床指标互补,共同反映肿瘤的生物学恶性程度。
2. 代谢组学发现(机制线索)高、低风险组及正常组织的代谢谱呈明显分离。27种代谢物在两组间差异显著,富集于丁酸代谢、氮代谢、丙氨酸代谢等通路。17种代谢物为肿瘤发生与风险分层的共同特征,其中丁酸代谢和氮代谢是高低风险组差异最显著的代谢通路,提示其可能参与预后调控。
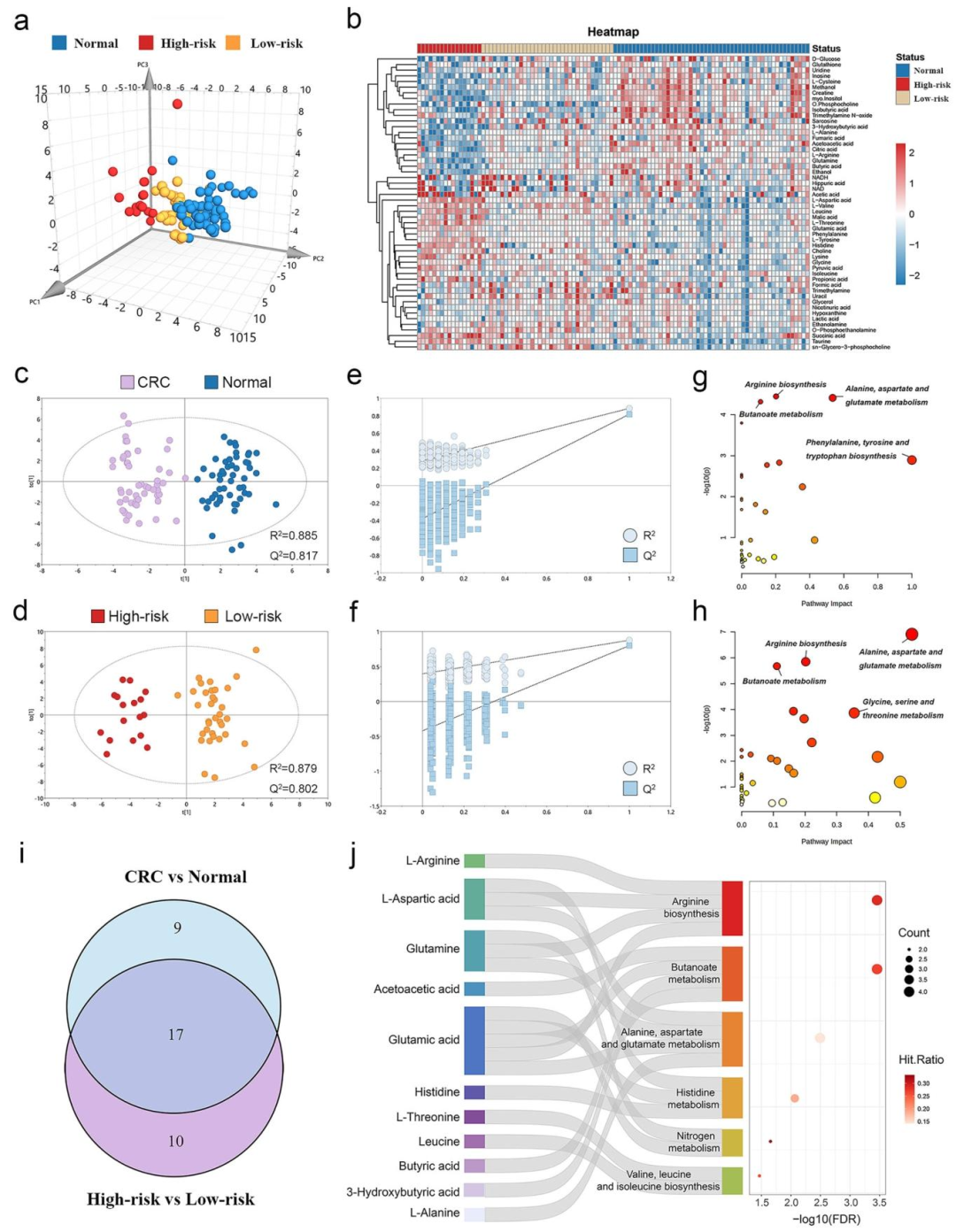
图 6(代谢组学发现:机制线索):该图是影像风险分层挂靠代谢机制的核心证据。图6a‑b的PCA和热图显示高、低风险组及正常组织的代谢谱显著分离,表明影像定义的风险组具有独特的代谢表型。图6c‑f的OPLS-DA和置换检验证实模型可靠。图6g‑h的通路富集分析显示,高风险组中丁酸代谢、氮代谢、丙氨酸代谢等通路显著改变。图6i‑j的Venn图和Sankey图指出,17种共同代谢物富集于丁酸代谢和氮代谢,提示这两条通路是连接肿瘤发生与风险分层的代谢枢纽。影像风险评分因此与特定的代谢重编程直接关联。
3. 转录组学发现(机制深化)高风险组显著富集细胞外基质相关通路(胶原组织、ECM结构成分),低风险组则富集免疫相关通路(抗原加工提呈、免疫突触)。CD8+ T细胞在低风险组中浸润更高。同时,转录组也证实丁酸代谢和氮代谢在低风险组中上调,与代谢组结果一致。
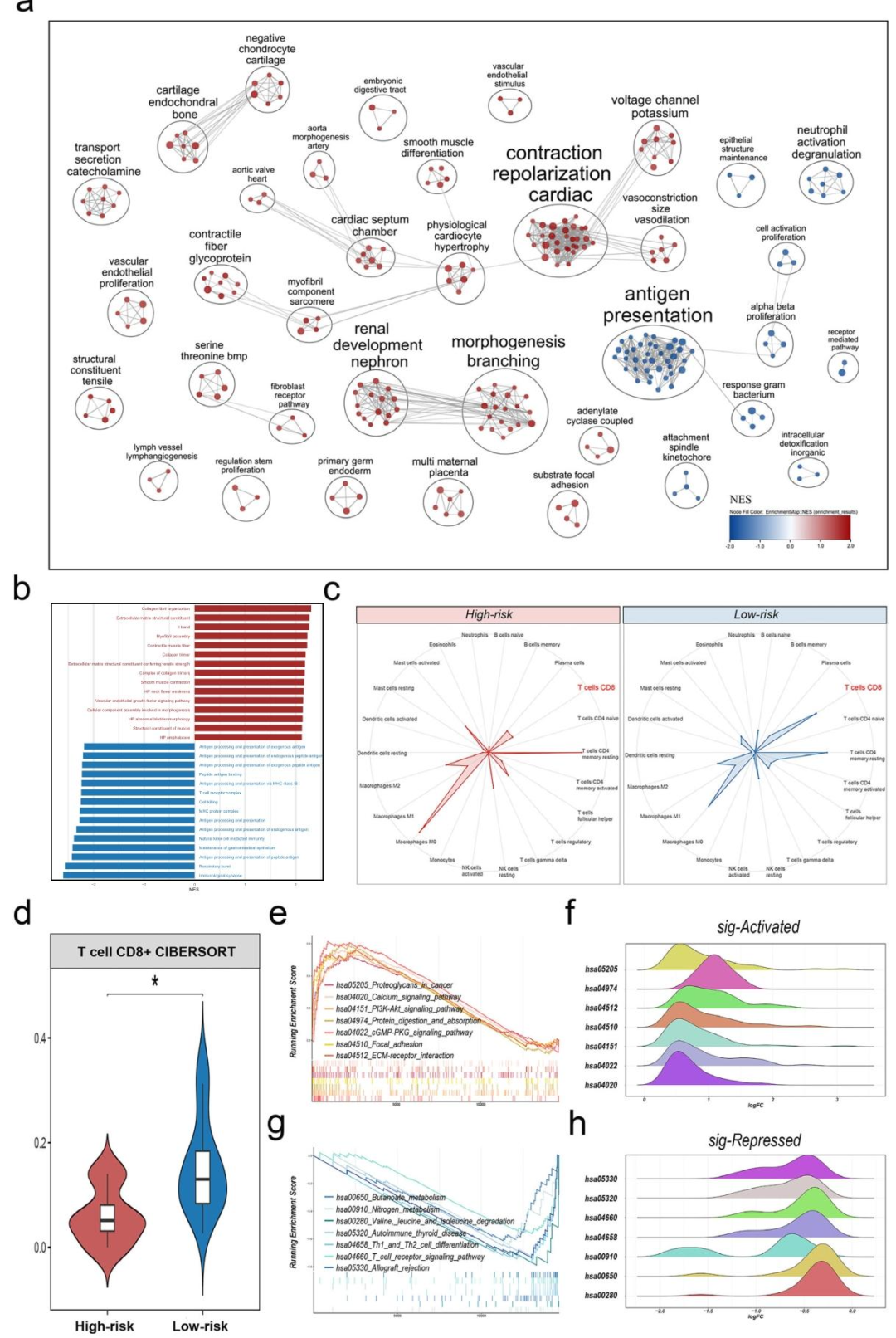
图 7(转录组学发现:机制深化):该图从转录层面深化了机制理解。图7a‑b的GSEA网络图和条形图显示:高风险组富集细胞外基质(ECM)相关通路(胶原组织、ECM结构成分),低风险组富集免疫相关通路(抗原加工提呈、免疫突触)。图7c‑d的雷达图和小提琴图表明低风险组CD8+ T细胞浸润显著更高。图7e‑h的KEGG GSEA进一步验证丁酸代谢和氮代谢在低风险组上调。该图将影像风险表型与ECM重塑(促进展)和免疫激活(保护性)的生物学过程直接挂钩,解释了为什么高风险影像特征预示更差预后。
4. 独立验证(机制确认)在TCGA‑CRC队列(417例)中,根据GSVA评分将患者分为高、低分组。丁酸代谢评分低者总生存更差(HR=0.52,p=0.007),氮代谢评分低者也与不良预后相关(HR=0.56,p=0.018),独立验证了这两个代谢通路的预后价值。
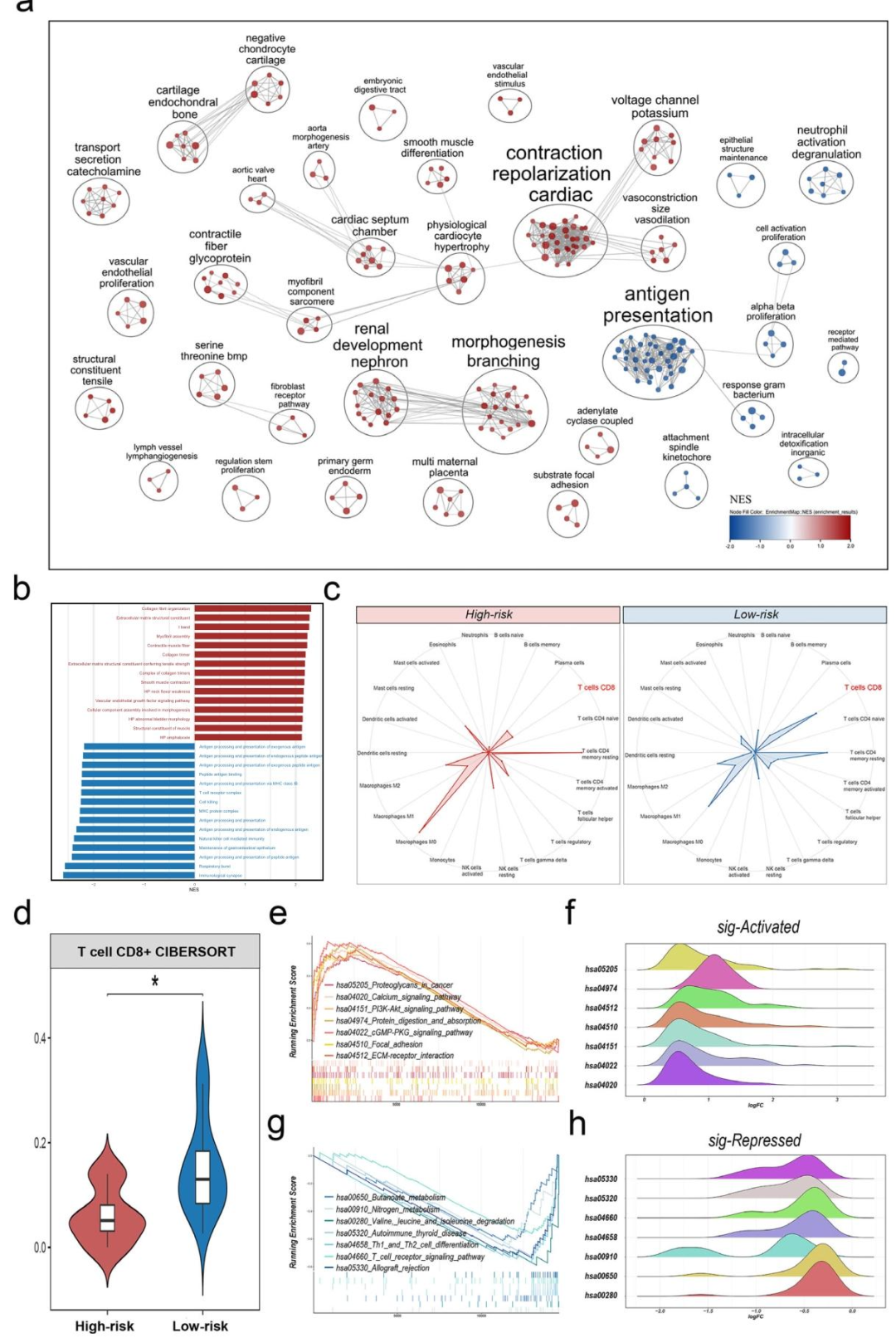
图 8(独立验证:机制确认):该图在TCGA-CRC队列(n=417)中独立验证了关键代谢通路的预后价值。通过GSVA计算每个样本的丁酸代谢和氮代谢通路富集评分,按中位数分为高、低评分组。图8a显示:丁酸代谢低评分组的总生存显著更差(HR=0.52,p=0.007);图8b显示:氮代谢低评分组同样与不良预后相关(HR=0.56,p=0.018)。该结果在独立公共数据中确认了代谢组和转录组的发现,证明影像风险评分所关联的代谢通路差异具有跨队列的预后一致性,从而完成了“影像表型→多组学机制→独立验证”的完整证据链。
07
讨论(把机制故事讲圆)
本研究通过多中心、多组学整合分析,成功构建了基于CT影像的深度学习影像组学风险分层模型(DLRM-RS),并系统揭示了其背后的生物学机制。首先,DLRM-RS不仅在内部和外部验证队列中均表现出稳健的预后预测能力,还能在年龄、性别、TNM分期、化疗状态等多个临床亚组中一致区分高、低风险患者,体现了良好的泛化性。其次,本研究通过代谢组学和转录组学的双向验证,首次将影像风险表型与丁酸代谢、氮代谢两条保护性代谢通路直接关联,并在TCGA独立队列中证实其低活性与不良预后显著相关,为影像模型提供了可解释的分子基础。在机制层面,高风险肿瘤显著富集细胞外基质重塑相关通路(如胶原纤维组织、ECM结构成分),这与肿瘤进展、转移和耐药性密切相关;而低风险肿瘤则呈现免疫激活特征,包括抗原加工提呈、免疫突触形成及更高的CD8+ T细胞浸润,提示其可能对免疫治疗更敏感。值得注意的是,丁酸代谢作为肠道菌群来源的短链脂肪酸代谢途径,其保护作用可能与HDAC抑制、抗炎及免疫调节有关,而氮代谢则可能通过调控氧化还原平衡和谷氨酰胺利用影响肿瘤生长。本研究也存在一定局限性:代谢组和转录组样本量较小,且未进行体外或体内功能实验验证;影像模型依赖手动分割,未来可探索全自动方法;丁酸代谢与免疫微环境的因果关系尚需进一步研究。尽管如此,本研究为影像组学从“黑箱预测”走向“机制导向的精准医学”提供了可复制的范式。
08
这篇文献的可借鉴思路
这篇文献为影像组学研究提供了多条可迁移、可复制的借鉴思路。第一,“影像表型驱动机制发现”的核心策略值得推广:不强行要求影像特征与基因一一对应,而是先构建稳健的影像风险模型,将患者分为高、低风险组,再以此为标签反向挖掘多组学差异,这种“表型优先、机制跟进”的思路极大降低了影像-组学关联的难度。第二,多算法系统性筛选是提升模型稳健性的有效手段:本研究评估了十种机器学习算法的117种组合,避免了因算法选择偏差导致的过拟合或低泛化能力,未来研究可借助类似框架(如Mime包)进行自动化算法比较。第三,多组学交叉验证增强了机制结论的可信度:代谢组和转录组独立且一致地指向丁酸代谢和氮代谢,并在公共队列中完成外部验证,这种“发现→验证→解释”的闭环设计值得效仿。第四,临床与机制的闭环叙事:研究从TNM分期的不足出发,构建影像模型,揭示ECM和免疫机制,最终回到列线图和通路验证,形成了“问题-工具-机制-应用”的完整故事线。第五,可视化表达丰富且逻辑清晰(如Sankey图、GSEA网络图、多组学热图),极大提升了论文的可读性和说服力。对于希望开展类似研究的学者,建议优先选择已有公共组学数据(TCIA、TCGA、GEO)支持的癌种,并尽量纳入多中心影像数据,以便在模型构建之初就考虑外部验证。最后,若条件允许,可加入简单的功能实验(如细胞系中关键通路的干预),将机制关联提升至因果层面,进一步强化论文的生物学深度。
09
结语
总而言之,这篇文献告诉我们:影像组学的高分密码,不在AUC的小数点后几位,而在能否给模型找到生物学“实锤”。通过影像表型驱动多组学挖掘,让风险评分落地到ECM重塑、免疫浸润和代谢通路,既解释了“为什么高危患者预后差”,又为后续治疗靶点提供了线索。希望大家以后做研究时,也能少一点“算命式”建模,多一点“破案式”溯源——让每一张CT图像背后,都站着清晰的细胞、通路和机制。这样,你的影像组学研究才能有根有据、有血有肉,真正讲好临床与基础交叉的科学故事。
参考文献:Li Z, Cai R, Qin Y, Liao X, Wang E, Wu X, Zhao Y, Lu Z, Lin Y. Integration of radiomics, deep learning, transcriptomics, and metabolomics reveals prognostic risk stratification and underlying biological mechanisms in colorectal cancer. NPJ Precis Oncol. 2026 Mar 6. doi: 10.1038/s41698-026-01331-2.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)