转载--AI Agent 架构设计:错误处理与容错设计(OpenClaw、Claude Code、Hermes Agent 对比)
原文:https://mp.weixin.qq.com/s/jIr_zWzNEHTnwHt_bxcjoQ
Agent 的错误和普通软件的错误不一样
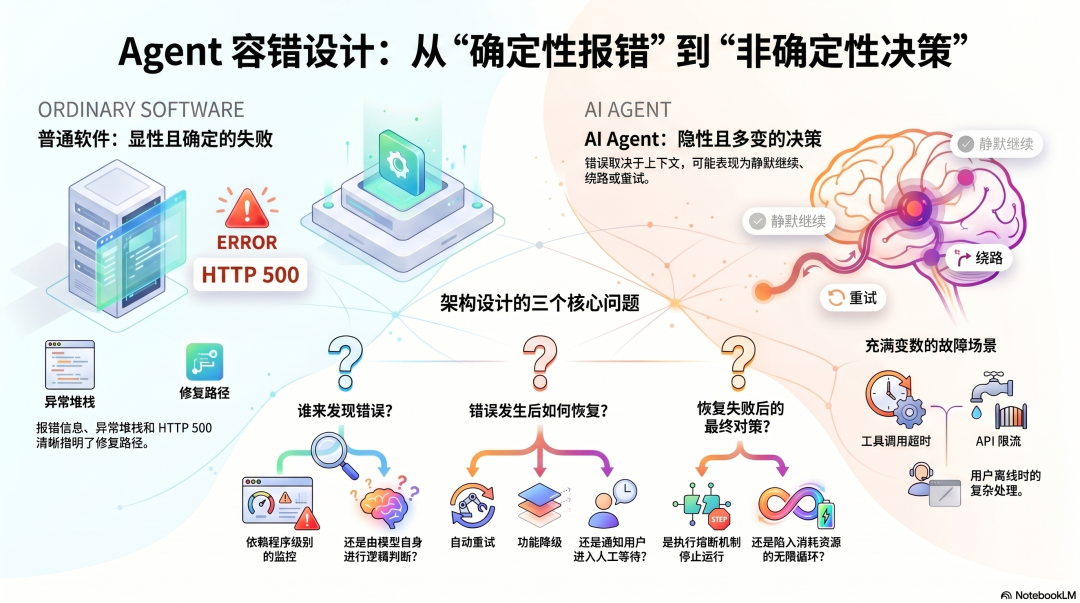
普通软件出错,你会看到报错信息、异常堆栈、HTTP 500。失败是可见的,位置是确定的,修复路径是清晰的。
Agent 的错误完全不同。
工具调用超时,模型可能选择重试,也可能选择绕路,也可能静默继续——这取决于当时上下文里的信息,不是确定性的代码逻辑。API 限流,下一步是等待还是切换模型?连续失败几次才该告诉用户?用户不在线的时候怎么处理?
这些问题没有标准答案,但架构设计给出了不同的默认选择。
三个框架在容错设计上的差异,集中体现在三个核心问题上:
谁来发现错误——程序级别的监控,还是模型自己判断?
错误发生后怎么恢复——重试、降级、还是通知用户等待?
恢复失败了怎么办——熔断、还是无限循环消耗资源?
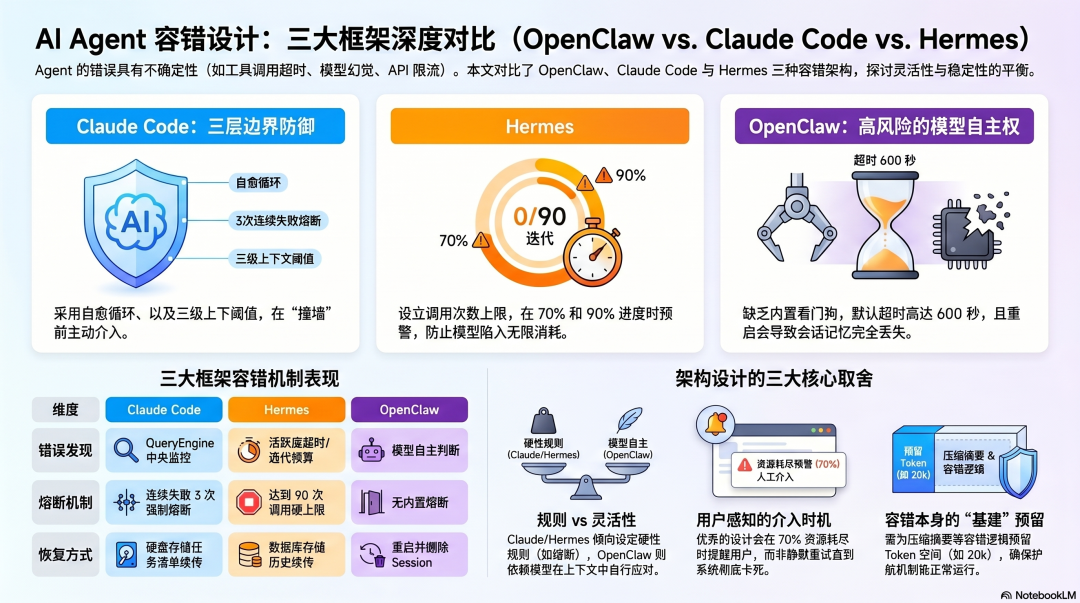
OpenClaw:依赖模型判断,生产中暴露了真实代价
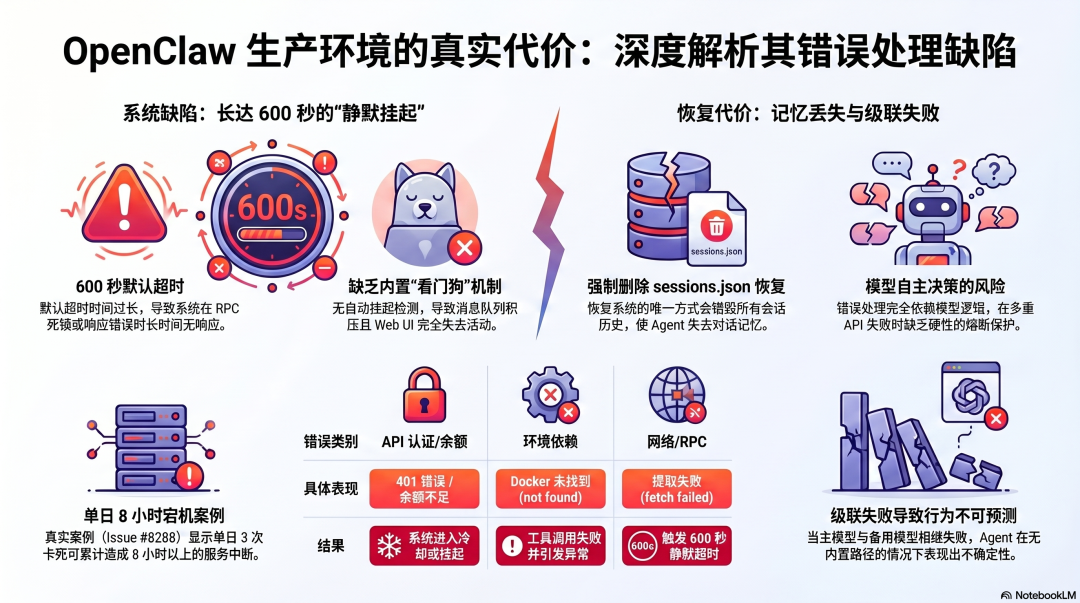
错误发现:没有内置的看门狗
OpenClaw 的错误处理有一个从 GitHub Issue 里能看到的真实问题:
当工具调用卡住(RPC 死锁、Provider 超时、响应格式错误),Agent 会静默挂起长达 600 秒——这是 agents/timeout.js 里
DEFAULT_AGENT_TIMEOUT_SECONDS 的默认值。
600 秒挂起期间:Telegram / Feishu消息队列但不处理,Web UI 无任何活动,用户完全看不到发生了什么。
2026 年 2 月,一位用户报告了一个具体案例(Issue #8288):单日内三次 Agent 卡死,累计超过 8 小时的宕机时间。
恢复方式只有一种:删除 sessions.json,重启 Gateway——这会销毁所有会话历史,Agent 失去完整的对话记忆。
这揭示了 OpenClaw 错误处理的根本缺陷:没有内置的看门狗机制,没有自动挂起检测,没有保留会话历史的优雅中止方式。
错误恢复:模型自主决策,风险集中
工具调用失败时,错误信息作为 tool_result 注入上下文,模型决定怎么处理——重试、换方案、还是向用户报告。
这在受信任环境里工作良好,但在多重失败叠加时会产生级联问题。同一案例里:
Anthropic API:401 Invalid bearer tokenAnthropic API:credit balance too low,进入冷却网络层:fetch failed TypeError依赖项:docker not found(Agent 尝试用 Docker 执行)LLM:多次请求超时 600 秒
主模型失败,Fallback 模型也失败,Agent 没有可靠路径完成当前回合。没有内置熔断,模型在这种情况下的行为是不确定的。
Claude Code:三层容错,每层有明确边界
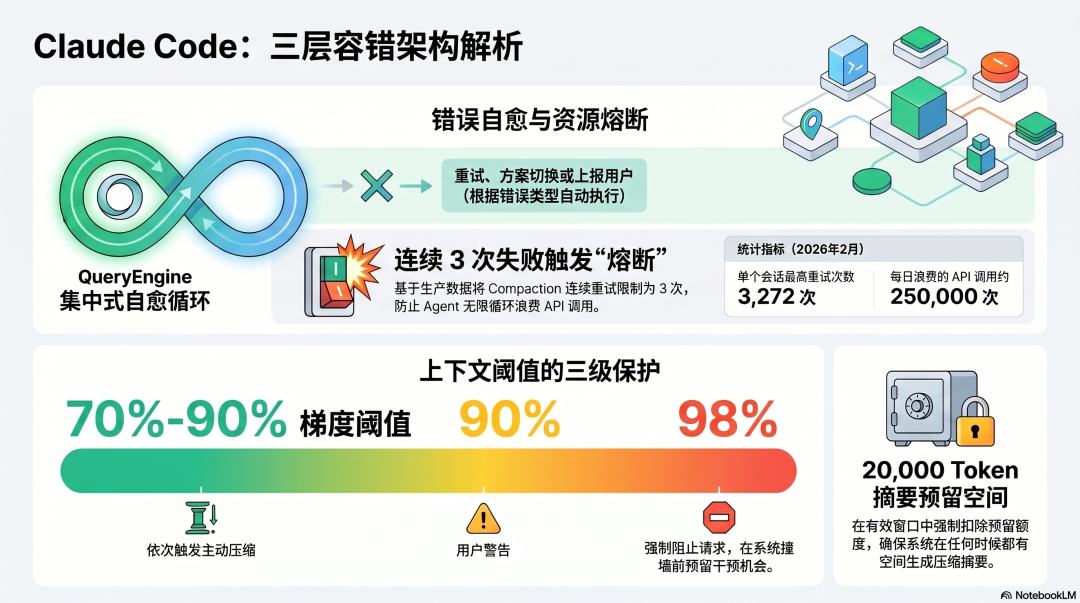
第一层:QueryEngine 自愈循环
Claude Code 的核心错误处理在 QueryEngine.ts——一个处理所有 LLM 调用、重试、流式错误的中央模块。
当工具调用失败,QueryEngine 的处理逻辑:工具调用失败↓分析错误类型↓可恢复(网络抖动、临时超时)→ 自动重试不可恢复(格式错误、权限拒绝)→ 上报给模型判断↓模型决定:换方案 / 请求用户输入 / 继续
把所有接触模型 API 的逻辑集中在一个模块里,是这个设计最重要的架构决策。 重试逻辑、速率限制处理、流式错误捕获,统一在这里处理——不同工具不需要各自实现重试,错误处理行为是一致的。
第二层:Compaction 熔断器
上下文压缩(Compaction)是 Claude Code 应对长 Session 的机制,但 Compaction 本身也可能失败。
从真实的生产数据来看,Anthropic 内部用 BigQuery 发现:2026 年 2 月,有 1,279 个会话出现 50 次以上连续 Compaction 失败,单个会话最多重试 3,272 次,每天浪费约 25 万次 API 调用。
修复方案是在源码里加了一行:
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES=3连续失败超过 3 次,停止重试,强制上报用户。
这个数字不是拍脑袋的,是从真实生产数据里推导出来的。 3 次熔断比无限重试节省了大量资源,也防止了 Agent 在失败状态里无限循环。
第三层:上下文阈值的三级保护
Claude Code 对上下文窗口的管理是三级阈值设计:
~70% 上下文使用率 → 自动触发 Compaction(主动压缩)~90% 上下文使用率 → 向用户显示警告~98% 上下文使用率 → 阻止新请求,要求手动处理
这个设计的价值在于:系统有三次机会在真正失败之前介入,而不是等到撞墙再处理。
有效上下文窗口的计算方式也值得关注——总窗口减去为 Compaction 摘要预留的 20,000 Token,保证在任何时候都有足够空间生成压缩摘要:
export function getEffectiveContextWindowSize(model: string): number {const reservedTokensForSummary = Math.min(getMaxOutputTokensForModel(model),MAX_OUTPUT_TOKENS_FOR_SUMMARY, // 20,000 Token 预留)return getContextWindowForModel(model) - reservedTokensForSummary}
预留空间不是浪费,是保证容错机制本身能够运行的基础设施。
Hermes Agent:高效容错与上下文管理机制
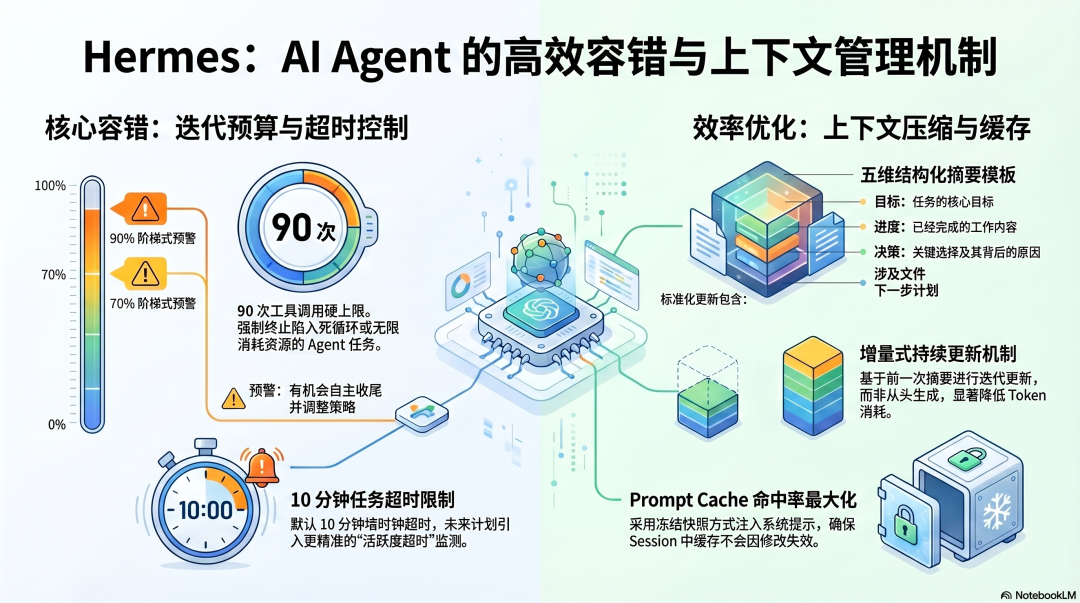
核心容错机制:迭代预算
Hermes 最重要的容错设计是迭代预算——每次会话有 90 次工具调用的硬上限:
0次 63次(70%) 81次(90%) 90次|________________|_________________|________________|开始执行 第一次警告 第二次警告 强制停止
这解决了 OpenClaw 遇到的核心问题:当 Agent 陷入循环(反复尝试失败的方法),迭代预算会强制终止,而不是无限消耗资源。
两次警告的设计也值得关注——不是直接撞上限才停,而是提前给 Agent 感知"剩余资源有限",让它有机会重新评估策略,在预算耗尽之前自主收尾。
超时设计:墙时钟的已知局限
Hermes 有默认 10 分钟的超时机制,但这是固定的墙时钟超时——从任务开始计时。
已知问题:合法的长时任务(比如等待慢 API 的数据分析)会被误杀。社区讨论的改进方向是活跃度超时——监测最后一次工具调用完成的时间,只有"静默"超过阈值才触发,能区分"正在工作"和"卡死"两种状态。这个改进截至 2026 年 4 月尚未实现。
上下文压缩:结构化摘要,持续更新
Hermes 的 ContextCompressor 使用结构化摘要模板:
Goal(目标):任务的核心目标Progress(进度):已完成什么Decisions(决策):做了哪些关键选择,为什么Files(文件):涉及的关键文件Next Steps(下一步):接下来要做什么
每次压缩不是从头生成摘要,而是更新上一次的摘要——这保证了摘要的连续性,也降低了单次压缩的 Token 消耗。
同时,Hermes 的系统提示在 Session 开始时作为冻结快照注入,Session 中不会修改——这最大化了 Prompt Cache 的命中率,也意味着系统提示层面不会产生因中途变化导致的缓存失效成本。
错误处理与容错设计的核心取舍
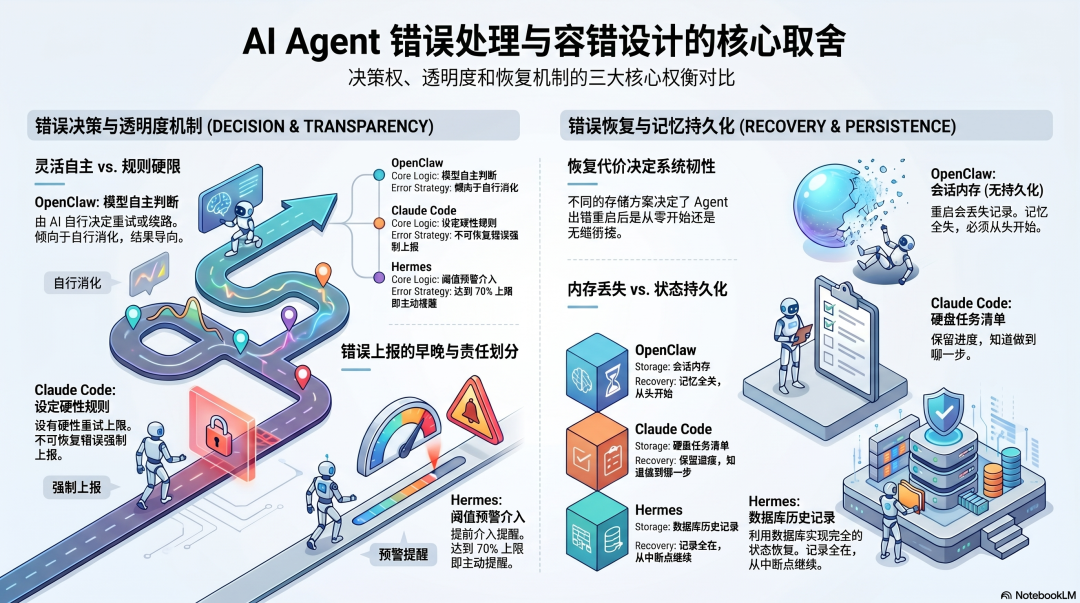
取舍一:出了问题,让 AI 自己想办法,还是给它设规则
OpenClaw 让模型自己决定——失败了,重试、换方法还是告诉用户,都由它判断。灵活,但你不知道它怎么处理的,有时候它会悄悄绕路,最后告诉你"完成了",但原来的问题根本没解决。
Claude Code 和 Hermes 设了硬规定:连续失败超过 3 次必须停下告诉用户,工具调用超过 90 次强制结束。少了灵活性,但出了问题知道往哪查。
取舍二:出了错,用户知道吗
OpenClaw 倾向于让 Agent 自己消化——绕路解决,继续往下跑,最后汇报"完成"。你感受不到中间出过问题,但拿到的结果可能不是你要的那个。
Claude Code 不可恢复的错误强制上报,不让模型自己决定要不要告诉你。
Hermes 更早介入——到了 70% 的次数上限就主动提醒,不等到出错才说。
选择谁来知道错误,就是选择谁来承担决策责任。
取舍三:出错之后,从哪里重新开始
OpenClaw 重启要删掉会话记录,Agent 醒来什么都不记得——之前做了什么、说了什么,全没了。
Claude Code 把任务清单存在硬盘上,重启后还在,知道做到哪一步了,能接着继续。
Hermes 用数据库存所有历史,重启后记录都在,从上次中断的地方接着走。
错误的代价,取决于恢复之后从哪里出发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)