转载--AI Agent 架构设计:Agent 为什么越用越贵(OpenClaw、Claude Code、Hermes Agent 对比)
原文:https://mp.weixin.qq.com/s/tJgJ10jDN8RS9YTUIfFuIw
一个让人不安的计费方式
语言模型的计费方式,和你直觉里的软件成本完全不同。
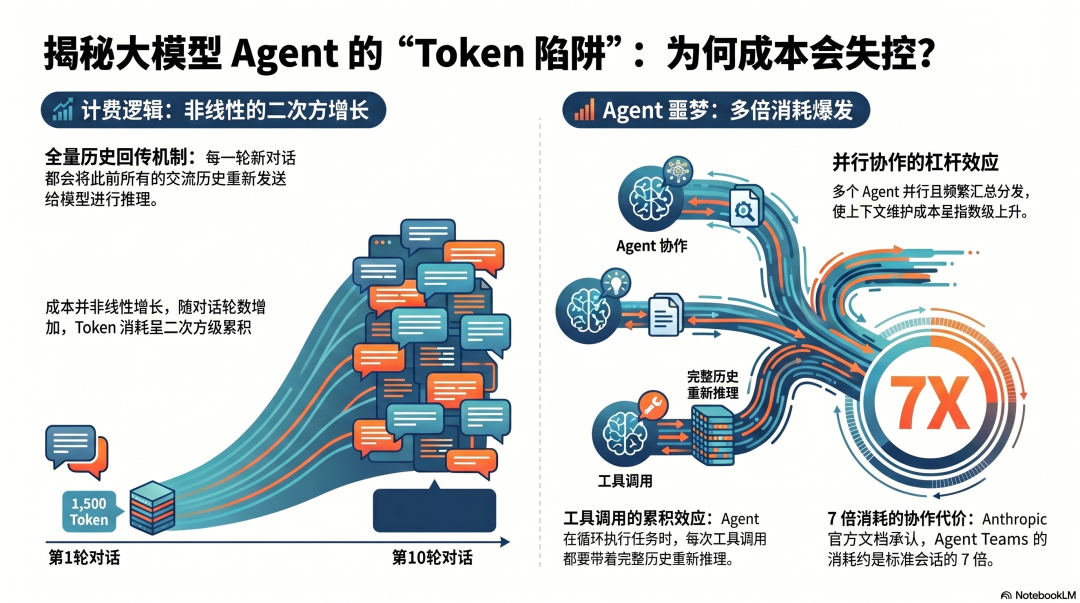
普通软件,你买一个功能,用多少次成本差不多。语言模型,每次调用都重新把整个对话历史发给模型——不只是你刚才说的那句话,是从对话开始到现在的全部内容。
第一轮对话:发 1,000 Token,收 500 Token。 第十轮对话:发 10,000 Token(包含前九轮的全部内容),收 500 Token。
Token 消耗不是线性增长,是二次方增长。
这在简单问答里问题不大。但在 Agent 的执行循环里——每次工具调用都要带着完整历史重新推理——Token 消耗以惊人的速度积累。
一个 Agent Teams 场景:开 5 个并行 Agent,每个 Agent 维护独立上下文,每轮工具调用后结果汇总给协调者,协调者再分发新任务……Anthropic 官方文档直接承认:Agent Teams 消耗的 Token 约是标准 Session 的 7 倍。
三个框架对这个问题,给出了三种架构层面的应对方式。
Token 成本的四个主要来源
在看三个框架怎么省之前,先把钱花在哪里说清楚。
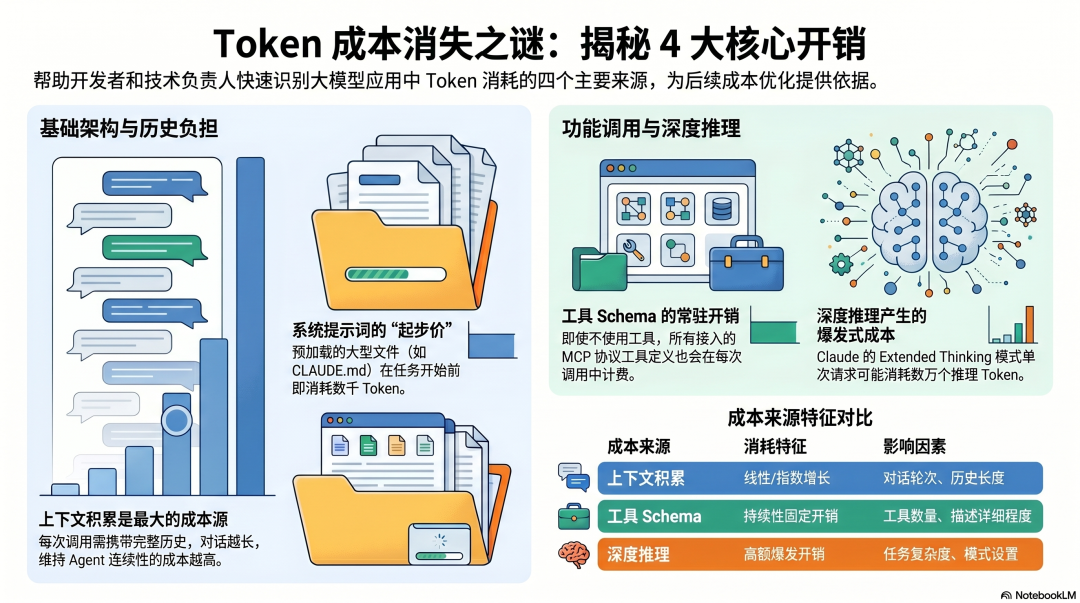
来源一:上下文积累每次调用都带着完整历史,对话越长越贵。这是最大的成本来源,也是最难控制的——因为历史是 Agent 工作的基础,删掉了就失去了连续性。
来源二:工具 Schema 注入每个工具的完整定义(名称、参数、描述)都注入在系统提示里。接 5 个 MCP 服务器,每个暴露 10 个工具,就是 50 个工具的 Schema 常驻在每次调用里。不管用不用,都在计费。
来源三:系统提示CLAUDE.md、SOUL.md、MEMORY.md 每次对话开始都加载进去。一个 5,000 Token 的 CLAUDE.md,每次对话都先花 5,000 Token,还没开始干活。
来源四:Extended ThinkingClaude 的深度推理模式,每次请求可能消耗数万个推理 Token,按输出 Token 计费。默认开启,但并非所有任务都需要。
知道钱花在哪里,才能决定从哪里省。
OpenClaw:成本随规模线性增长,缺乏精细控制
全量加载,无延迟优化
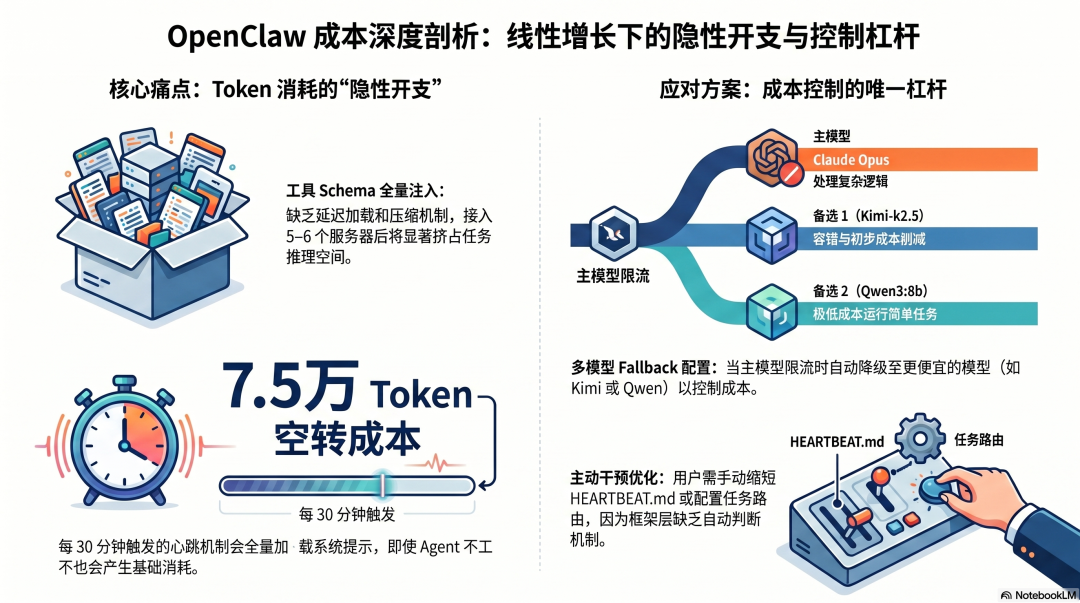
OpenClaw 对工具 Schema 的处理是全量加载——连接了多少 MCP 服务器,就把多少工具的完整 Schema 注入上下文。
这在工具数量少的时候不是问题,但当用户开始接入更多服务(邮件、日历、GitHub、Notion、Slack……),工具 Schema 占用的 Token 开始显著增长。
社区实践里有明确记录:接超过 5-6 个 MCP 服务器后,上下文里的工具列表开始明显占用推理空间,实际任务的 Token 预算被压缩。没有延迟加载机制,没有工具语义搜索,也没有内置的 Schema 压缩。
心跳的隐性成本
OpenClaw 的心跳机制(每 30 分钟触发一次)每次都带着完整的系统提示运行——SOUL.md、AGENTS.md、MEMORY.md 全部加载。
按官方文档估算:每次心跳约 200 Token 的巡逻清单,加上系统提示,默认 30 分钟间隔每天产生约 7.5 万 Token 的心跳成本——这是在 Agent 什么都不做的时候的基础消耗。
用户可以通过缩短 HEARTBEAT.md 来降低这个成本,但这需要主动去做,不是默认优化的。
多模型 Fallback:成本控制的唯一杠杆
OpenClaw 在成本控制上最有价值的设计,是多模型 Fallback 配置:
{"fallbacks": ["anthropic/claude-opus-4-5","moonshot/kimi-k2.5","ollama/qwen3:8b"]}
当主模型(通常是 Claude Opus 或 Sonnet)出现限流或错误,自动降级到更便宜的模型。这不只是容错,也是成本控制——便宜模型能完成的任务,不需要用贵模型。
但任务路由(什么任务用什么模型)需要用户手动配置,框架层没有自动判断机制。
Claude Code:三层成本优化,有真实数据支撑
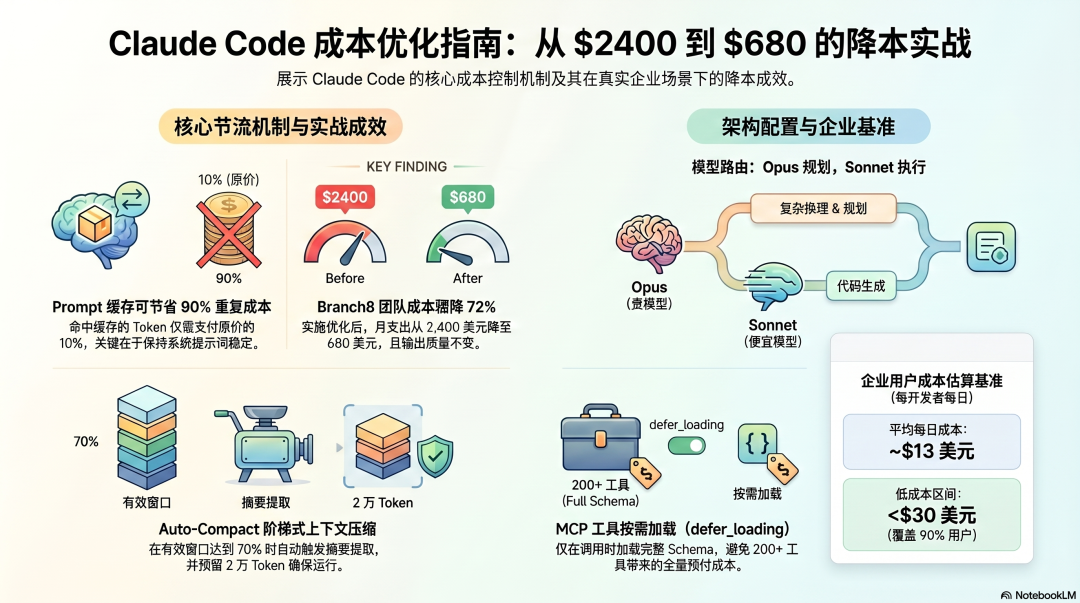
Prompt Cache:最高效的成本杠杆
Prompt Cache 是 Claude Code 成本控制里效果最显著的机制——命中缓存的 Token 只需支付原价的 10%。
关键是怎么让缓存命中率最大化。Claude Code 的系统提示在 Session 开始时冻结,整个 Session 内不修改。这保证了系统提示作为稳定的缓存前缀,每次调用都能命中。
如果系统提示中途被修改(哪怕一个字符),缓存前缀失效,这次及之后的调用都要按原价计费。
一个真实的团队案例:Branch8 在 2026 年记录了 6 个月的使用数据,第一个月花了 2,400 美元,实施 Prompt Cache 等优化后,第三个月降到 680 美元——降幅 72%,输出质量不变。 他们把大部分收益归因于两件事:Prompt Cache(节省约 90% 的重复 Token 成本)和 Session 专注(专注在一个任务上,不让不相关上下文积累)。
2026 年 3 月,Anthropic 的缓存系统出现了一个已知的 bug(GitHub Issue #40524):两个缓存相关的 bug 导致 Token 消耗 10-20 倍膨胀,用户需要反向工程二进制文件才发现原因。如果某天你的成本突然暴涨但任务没变,先检查这里。
Auto-Compact:上下文积累的自动控制
Claude Code 的 Auto-Compact 在上下文达到有效窗口的 70% 时自动触发,把历史压缩成摘要继续工作。
有效窗口的计算预留了 20,000 Token 给压缩摘要本身——这个预留保证了 Compaction 机制在上下文最紧张的时候也能运行,不会因为没有输出空间而失败。
三级阈值(70%/90%/98%)让成本控制也成为了连续的过程,不是撞到上限才开始处理。
渐进式 Skills 加载:工具 Schema 的按需支付
Claude Code 的 defer_loading: true 让 MCP 工具的 Schema 按需加载——Session 开始时只加载工具名称列表(极少 Token),完整 Schema 只在真正需要时才加载。
这把工具 Schema 的成本从"全量预付"变成了"按需支付"。连接 200 个工具,平时只有工具名称的 Token 成本,调用某个工具才付那个工具的 Schema 费用。
对于重度 MCP 用户,这个机制的 Token 节省效果非常显著:同样接 10 个 MCP 服务器,渐进加载比全量加载可以节省数千 Token 的每次基础成本。
模型路由:Opus 做规划,Sonnet 做执行
Claude Code 有一个 opusplan 模型别名,实现自动的模型分层路由:
Plan 模式(复杂推理、架构决策)→ Claude Opus(贵但精准)执行模式(代码生成、文件操作)→ Claude Sonnet(便宜且够用)
规划质量来自 Opus,执行成本来自 Sonnet。这是在"全程用贵模型"和"全程用便宜模型"之间找到的实际平衡点——用 Opus 的地方是真的需要 Opus 的判断能力,其他地方不浪费。
企业用户的实际成本数据:跨企业部署的平均成本约 13 美元/开发者/活跃日,90% 的用户低于 30 美元/活跃日。 这是 Anthropic 官方公布的基准,可以用来估算自己的团队成本。
Hermes Agent:模型灵活性是成本控制的最大杠杆
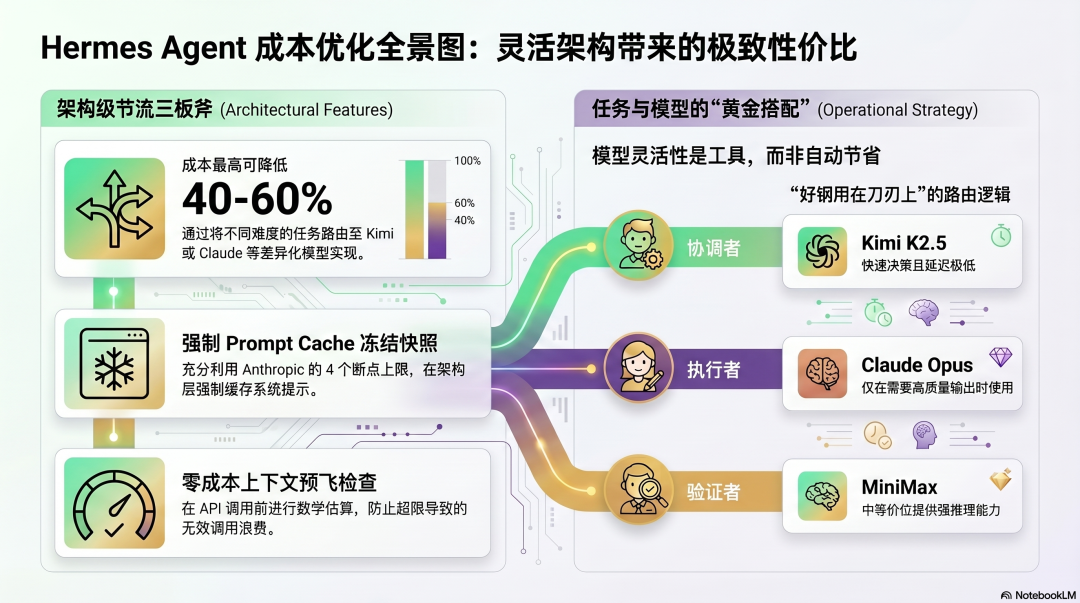
200+ 模型端点:真正的价格竞争
Hermes 对成本控制最大的架构贡献是模型无关性——支持 Nous Portal、OpenRouter(200+ 模型)、Kimi/Moonshot、MiniMax、OpenAI、Anthropic 等任意兼容端点。
切换模型只需一条命令:hermes model,不需要修改代码,不需要重启 Agent。
这让 Hermes 能做到真正的任务-模型匹配:
协调者(需要快速决策)→ Kimi K2.5(便宜,延迟低)执行者(需要高质量输出)→ Claude Opus(贵,但只用在刀刃上)验证者(需要推理能力)→ MiniMax(中等价位,推理强)
Hermes 社区记录的实践:协调任务用便宜模型,执行关键任务用高质量模型,整体成本比全程用 Claude Sonnet 低 40-60%——但这个节省需要用户主动判断哪些任务需要什么质量的模型,有一定的运营复杂度。
Prompt Cache:冻结快照的架构保障
Hermes 系统提示在 Session 开始时作为冻结快照注入,整个 Session 内不修改——这和 Claude Code 的思路相同,但是在架构层面强制实现的,不是用户配置项。
Cache 标记放置在:系统提示(第一个断点)+ 最后三条非系统消息(第二到第四个断点)。Anthropic 的最大断点数是 4 个,Hermes 充分利用了这个上限。
上下文预飞检查:在浪费发生前阻止
Hermes 的 should_compress_preflight() 在每次 API 调用之前运行一个轻量的字符数估算,判断是否需要先压缩再调用:
def should_compress_preflight(self, messages):rough_estimate = estimate_messages_tokens_rough(messages)return rough_estimate >= self.threshold_tokens
这不需要调用模型(纯数学运算),成本是零。但它阻止了一类常见的浪费:上下文已经超限,调用 API 失败,再来处理失败——先检查,不满足就先压缩,然后再发请求。
成本的真实限制
Hermes 的模型灵活性是强大的,但成本节省不是自动的:
"Hermes 的成本优势只有在你主动将任务路由到更便宜的 Provider 时才会显现——这需要了解哪些任务需要高质量模型,哪些不需要。这对大多数用户来说是非平凡的运营开销。"
这是 utilo.io 基准测试的直接结论。模型灵活性是工具,不是自动节省。 不配置的话,Hermes 的成本和 OpenClaw 差不多。
成本控制的核心取舍
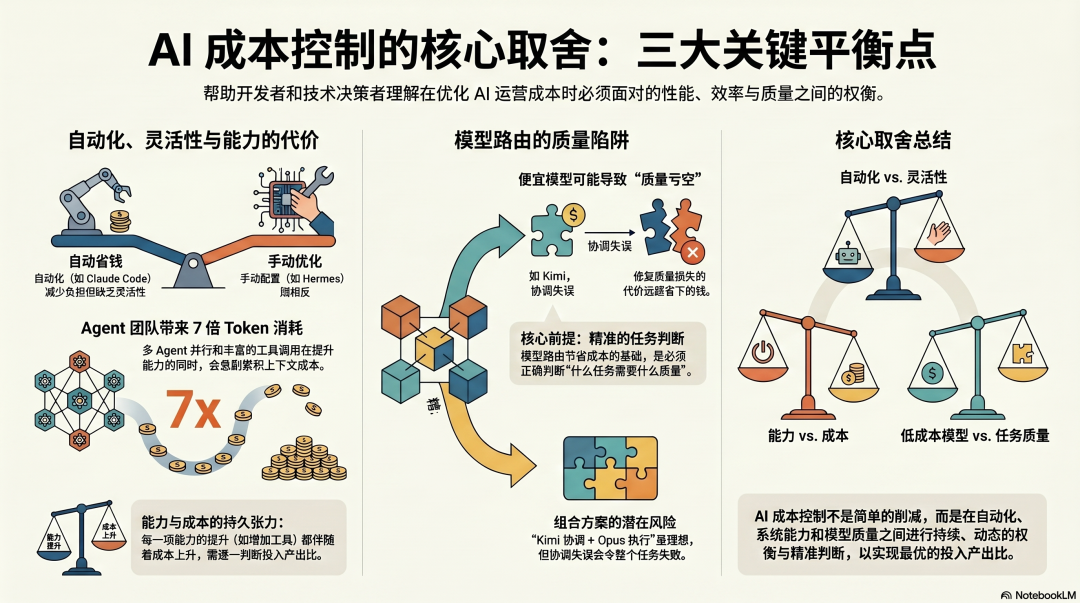
取舍一:自动省钱 vs. 手动优化
Claude Code 的 Auto-Compact 和延迟加载是开箱即用的——不需要配置,默认就在帮你省钱。Hermes 的模型路由节省需要用户主动配置,OpenClaw 的多模型 Fallback 也需要手动设定。自动优化减少了运营负担,但灵活性不如手动配置。
取舍二:能力和成本的张力
Agent Teams 消耗 7 倍 Token,多 Agent 并行是能力,也是成本。每次工具调用都在积累上下文,工具丰富是能力,也是成本。这个张力没有完美解法——只能在每个具体任务上判断,这个能力提升值不值得这个成本。
取舍三:便宜模型的质量风险
用 Kimi 做协调、用 Opus 做执行,听起来很美,但便宜模型协调失误的代价,可能是整个任务的质量。模型路由的节省,建立在正确判断"什么任务需要什么质量"的前提上。 这个判断做错了,省下的成本会以质量损失的方式加倍还回来。
用户能做什么
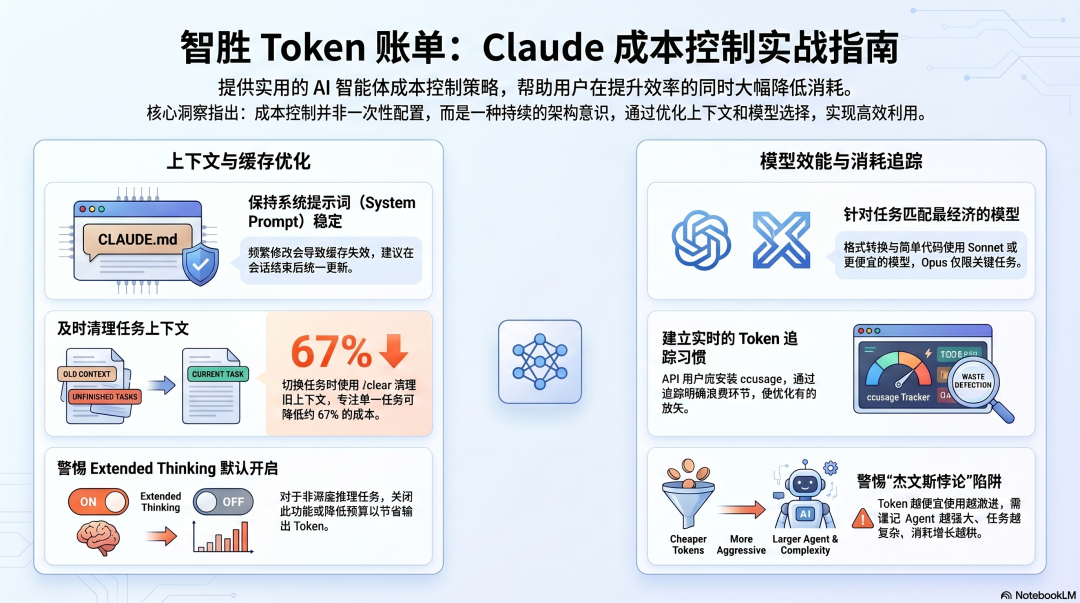
结合三个框架的设计和真实数据,几个最有效的成本控制策略:
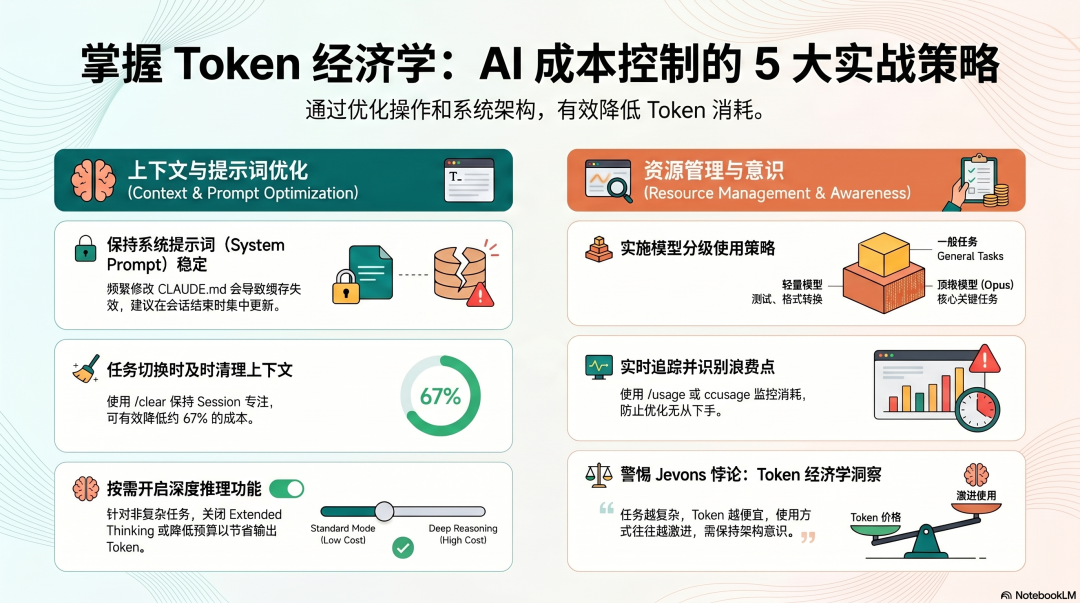
第一:保持系统提示稳定不变。 中途修改 CLAUDE.md/SOUL.md 会让 Prompt Cache 失效,此后每次调用都按原价计费。把所有修改攒在 Session 结束后一次性更新。
第二:任务之间用 /clear 清理上下文。 切换到不相关任务时,旧的上下文是纯粹的成本浪费。Branch8 的数据证明:Session 专注(一次只做一件事)能降低约 67% 的成本。
第三:测试任务用便宜模型,关键任务用好模型。 不是所有任务都需要 Claude Opus——文件格式转换、简单代码生成、模板填充,Sonnet 或更便宜的模型完全够用。
第四:追踪你的 Token 消耗。 Claude Code 用 /usage,API 用户安装 ccusage。不追踪就不知道哪里在浪费,优化无从下手。
第五:警惕 Extended Thinking 的默认开启。 对于不需要深度推理的任务,关掉 Extended Thinking 或降低预算,可以节省大量输出 Token。
Token 经济学的核心洞察来自 Karpathy——Token 越便宜,使用方式越激进,Jevons 悖论在这里成立。Agent 越强大,单次任务消耗的 Token 越多;任务越复杂,上下文积累越快。 成本控制不是一次性的配置,是持续的架构意识。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)