AI我知道:AI 的「价值观」从哪里来?——对齐、RLHF 与 AI 生态
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者: 丁闪闪 (连享会)
邮箱: lianxhcn@163.com
系列说明:本文是「AI我知道」系列推文的第五篇,面向经管、金融、社会学领域的研究者和学生。我们的目标不是把你训练成 AI 工程师,而是帮你建立足够扎实的概念框架,让你能更聪明地使用这些工具,并在研究和工作中做出有依据的判断。
- Title: AI我知道:AI 的「价值观」从哪里来?——对齐、RLHF 与 AI 生态
- Keywords: 对齐, RLHF, 指令微调, AI 生态, 大语言模型, 安全边界, ChatGPT
你有没有遇到过这种困惑?
把几个 AI 产品并排用一段时间之后,很多人都会生出一种很具体的感觉:它们明明都能写文章、改代码、总结论文,但说话的分寸并不一样。有的比较谨慎,有的更愿意往前走一步;有的习惯先提醒风险,有的更倾向直接给方案;同一个问题,换个平台再问,语气、边界和结论框架都可能变掉。
于是,问题就来了:这些差异到底从哪里来? AI 真的有自己的「价值观」吗?还是说,我们看到的只是训练方式、产品规则和使用场景共同作用之后的结果?
这一篇想讨论的,就是这个问题。对普通用户来说,要理解 AI 为什么会表现出某种偏好、某种谨慎,或者某种拒答方式,至少要先抓住三个概念:对齐(Alignment)、RLHF 和 AI 生态。它们分别回答三层问题:模型为什么不能只追求把话说通顺;人类反馈怎样把更像一个好助手的偏好写进模型行为;以及为什么同样是大模型,落到不同产品里,最后呈现出来的整体气质会明显不同。
1. 对齐:不是给 AI 灌输抽象道德,而是让它更适合合作
1.1 什么是「对齐」?
「对齐」这个词,听起来容易让人想到很大的哲学命题。但如果回到日常使用,它其实没有那么玄。
所谓对齐,就是尽量让模型的行为,朝着人类期待的任务方式靠拢。
这里说的,不是让模型永远正确,也不是让模型拥有人类那种真正的价值观。更实际的意思是:模型原本最擅长的事,是根据上下文生成下一个 token;但用户真正想要的,不只是一个会接话的系统,而是一个在合作时更有分寸、更少跑偏的助手。换句话说,大家希望它:
- 尽量听懂任务;
- 少编依据;
- 该谨慎的时候知道收住;
- 拿不准的时候愿意承认不确定;
- 在高风险问题上不过度自信;
- 在普通任务里又不至于僵硬得难以使用。
从这个角度看,对齐更像一种行为校准。它不是把模型训练成道德哲学家,而是让它更像一个可合作、可控制、也更可预期的助手。
1.2 为什么只有预训练还不够?
预训练当然非常重要。模型在海量文本中学到语言模式,才有了续写、归纳、表达这些基础能力。但这一步主要解决的,还是语言层面的问题:会不会说,像不像自然语言,能不能把一句话顺着接下去。
现实中的需求显然不止这些。用户并不需要一个只会顺着话往下讲、却不管真假、不看边界、也不判断任务目标的系统。也就是说,语言能力本身,并不自动等于可合作性。
这正是对齐要补的部分。它试图把模型从单纯的语言续写器,往任务助手的方向再推一步:不仅会生成内容,还要更接近一种可使用、可合作的行为方式。什么时候该保守一点,什么时候应该说清依据,什么时候需要把风险讲明白,这些都不是单靠预训练自然长出来的。
所以,对齐不是后来加上的小修小补,而是模型从能说,走向能被稳定使用的关键一步。
1.3 为什么你会感受到不同产品之间的气质差异?
因为很多你在日常使用中感受到的风格差异,本来就和对齐有关。
例如:
- 为什么有的模型回答更像老师,有的更像助理;
- 为什么有的模型遇到风险问题会明显更谨慎;
- 为什么有的模型更愿意说「我不确定」;
- 为什么有的平台习惯先讲原则,有的平台更愿意直接推进任务。
这些差异当然也和产品定位、目标用户、法律环境有关,但如果只看模型行为层面,其中相当一部分都可以理解为:对齐方式不同,外显出来的结果也会不同。
所以,很多人感受到的那种「脾气」,并不是模型天然有了某种人格,而更像是一整套训练、反馈和规则选择累积之后形成的表现。
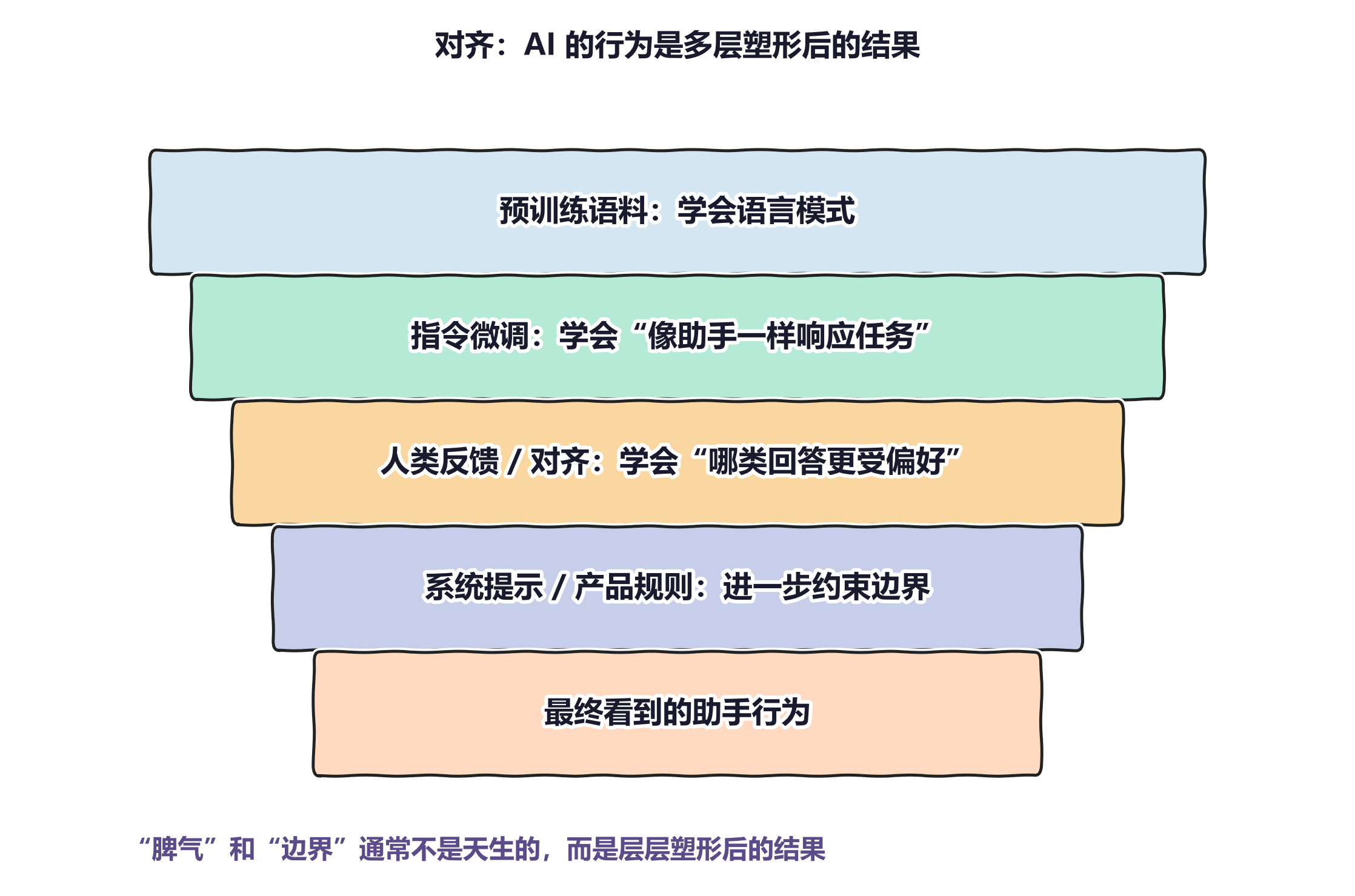
图 1:从普通用户视角看,AI 的最终行为更像多层因素共同作用后的结果。底层模型当然重要,但系统提示、对齐方式、产品规则和任务场景都会继续塑造它的表现。
2. RLHF:让模型学会什么样的回答更受人类偏好
2.1 RLHF 是什么?
如果说「对齐」描述的是目标,那么 RLHF 说的就是一条重要的实现路径。RLHF 的全称是 Reinforcement Learning from Human Feedback,通常译为「基于人类反馈的强化学习」。
这个名字听起来有点技术味,但可以先把它理解成一个很直观的想法:不只是让模型模仿文本,还要让它学习哪种回答更符合人类偏好。
举个简单的例子。面对同一个问题,模型可能给出两个都还说得通的回答:
- A 比较流畅,但带着一点想当然;
- B 没那么华丽,却会说明依据,保留不确定性。
如果人类标注者反复更偏好 B,那么训练系统就会逐渐学到:在类似任务里,B 这种回答更接近较好的回答。时间久了,模型的行为就会朝这个方向偏过去。
所以,RLHF 并不是把某套完整价值体系灌进模型,而是在持续告诉它:人类通常更愿意接受哪一类回答。
2.2 RLHF 实际上改变了什么?
它改变的不只是表面措辞,而是更深一层的行为倾向。
经过这类反馈之后,模型通常会更倾向于:
- 优先回应用户真正关心的任务;
- 少做无谓的发散;
- 拿不准时保留不确定性;
- 在高风险问题上更容易触发谨慎策略;
- 输出更接近人类认为有帮助、较安全、较可信的样子。
这也是为什么很多人会觉得,助手型模型这几年明显更会配合了。原因之一就在于,它们学到的已经不只是语言模式,还包括一整套关于怎样才算更好回答的偏好信号。
当然,RLHF 也不是万能的。它可以改善一类问题,但并不能消除所有问题。模型依然会幻觉,依然可能在复杂任务里判断失误,也依然可能因为反馈分布和产品策略不同,而呈现出不同的边界。
2.3 这是不是意味着模型真的有了「价值观」?
严格说,不是。
很多用户会自然地联想到:既然模型会拒绝某些请求,会提醒风险,也会表现出相对稳定的风格,那它是不是已经拥有某种价值观?这个判断很容易把问题说得过满。
更稳妥的理解是:模型是在行为层面学会了某种偏好模式,而不是像人一样形成了内在的伦理信念。
它没有人类那种自我意识,也没有真正意义上的道德体验。你看到的更多是下面几层东西叠在一起:
- 训练数据中的模式;
- 指令微调形成的行为倾向;
- 人类反馈带来的偏好校准;
- 产品规则施加的边界约束。
所以,当我们说某个模型更谨慎、更温和,或者更喜欢提醒风险时,更准确的意思通常是:它在这些维度上的行为,被训练和产品设计一起塑造成了这样,而不是它真的像人那样自己这么想。
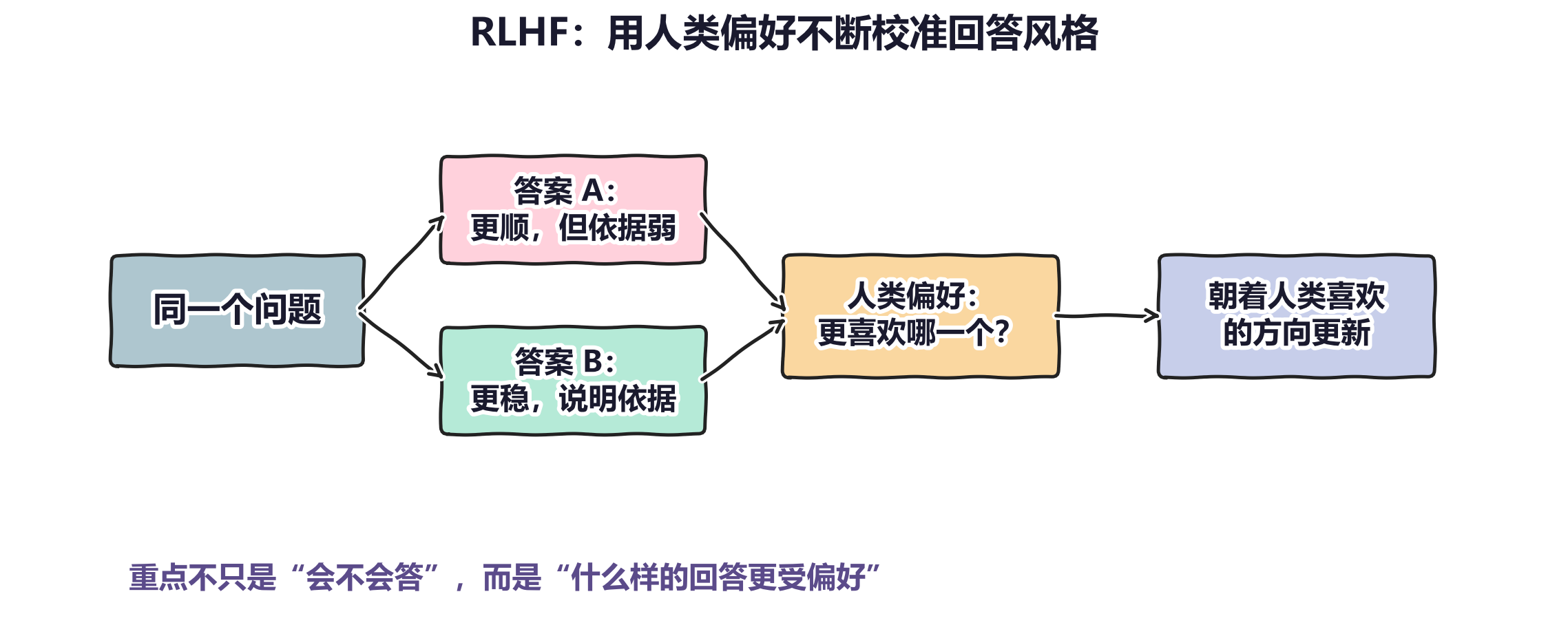
图 2:从普通用户角度看,RLHF 的核心不是学会正确答案,而是学会什么样的回答更像一个好助手。它改变的是行为偏好,而不只是表面措辞。
3. AI 生态:你看到的所谓「价值观」,往往是整个系统共同作用后的结果
3.1 为什么不能只盯着模型本身?
讲到这里,一个更重要的事实就清楚了:用户最终接触到的,并不只是一个模型,而是一个更大的系统。
这个系统至少包括:
- 底层基础模型;
- 指令微调和对齐训练;
- 系统提示与隐藏规则;
- 工具调用能力;
- 产品界面和交互方式;
- 内容政策与风控机制;
- 使用场景、行业规范与法律环境。
所以,很多你感受到的价值观差异,并不一定来自模型本体,而可能来自整条系统链条的不同配置。也就是说,用户面对的通常不是实验室里的一个抽象「裸模型」,而是 AI 生态中的一个具体产品。
3.2 为什么底层模型相近,产品表现也可能很不一样?
因为产品层还在继续塑造行为。
这一点对普通用户特别重要。很多人会觉得,只要底层模型差不多,最终体验应该也差不多。实际情况往往没有这么简单。哪怕模型接近,只要下面这些部分不同,表现就可能明显分化:
- 系统提示写法不同;
- 是否接入搜索、代码执行、文件读取等工具;
- 是否叠加了额外的安全策略;
- 是否面向企业、学生、开发者等不同人群;
- 是否在某些问题上优先强调谨慎与合规。
于是,你就会看到很真实的差异:同样一个问题,有的平台更偏向讲原则,有的平台更偏向完成任务;有的平台更容易拒答,有的平台更喜欢给折中方案;有的平台把「安全第一」放得更前,有的平台则更强调「效率第一」。
因此,与其说 AI 有某种固定的「价值观」,很多时候不如说:它所在的产品生态,继续对它的行为做了塑形。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)