letentSync模型
LatentSync是字节跳动与北京交通大学联合开发的开源端到端唇形同步(Lip Sync)模型,核心目标是用音频驱动生成唇形与语音精准对齐的说话人脸视频。
框架
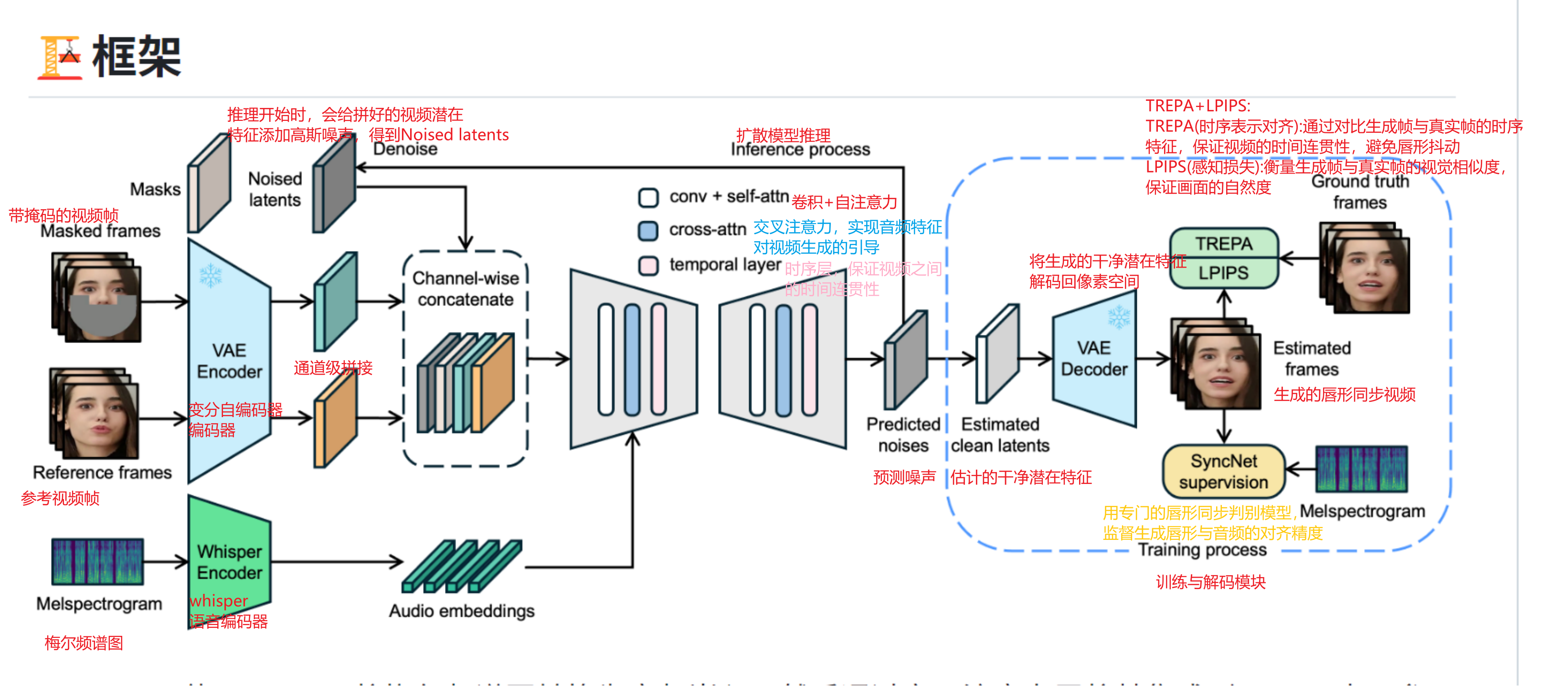
LatentSync 扩散模型推理
一、前置准备(推理第一步:预处理 + 编码)
1.输入两路视频帧
- 参考帧:整张人脸清晰完整,保留长相、表情、头姿,全程不改动。
- 掩码帧:同一张人脸,只把嘴唇区域掩码涂黑 / 打码,其他地方不变。
2.VAE 编码器压缩
把参考帧、掩码帧,都塞进 VAE Encoder,变成低维潜在特征 Latent(相当于把高清图压缩成小尺寸特征,减少计算)。
3.视频特征拼接
参考特征 + 掩码特征 通道拼接,得到待修复的视频整体潜变量。
4.音频侧编码
语音转梅尔频谱 → 送入 Whisper Encoder → 得到音频语义嵌入作用:记住每个时间点发什么音、语速、停顿,后面用来指挥嘴型
二、扩散核心推理全过程(关键 6 步)
第 1 步:给掩码视频潜变量加高斯随机噪声
在嘴部缺失的视频潜变量上,加标准随机高斯噪声
效果:嘴部区域变成完全混乱的噪点,看不出任何唇形;人脸其他区域被参考帧约束,基本不乱。
第 2 步:设置迭代去噪步数
比如设 20/50 步,扩散推理就是循环做 20~50 次去噪。
第 3 步:每一步内部:多模块协同计算
- 交叉注意力 Cross-Attention
把音频嵌入注入进来,告诉模型:当前这一时刻该张嘴、闭嘴、还是微张。 - 空间自注意力 + 卷积
保证除嘴唇外的五官、脸型不崩坏、不走样。 - 时序 Temporal 层
约束前后帧连贯,不让嘴部乱跳、抖动、闪帧。 - 模型预测当前噪声
网络算出:现在这张混乱的潜变量里,混杂了多少随机噪声。
第 4 步:减去预测噪声,更新潜变量
公式人话:
新的干净一点的特征 = 当前带噪特征 − 模型预测出来的噪声
每走一步,嘴部噪点少一点、轮廓清晰一点。
第 5 步:循环迭代去噪
重复第 3、4 步,走完设定的所有扩散步数。
从全是噪点 → 慢慢浮现嘴型 → 唇形越来越标准 → 和语音节奏完全匹配。
第 6 步:输出干净潜变量
迭代结束,得到去噪完成、唇形已生成好的纯净视频潜变量。
三、解码还原成视频帧
把最终干净潜变量送入 VAE Decoder
低维特征 → 还原回高清像素画面
结果:
整张脸和原图保持一致,只有原本打码的嘴唇区域,被生成出和语音同步的自然开合唇形。
四、推理时隐含的双重校验
1.和原原型视频比对
约束非嘴唇区域:脸型、表情、姿态不能有出入,只改嘴。
2.音唇对齐隐性校验
推理时继承训练好的 SyncNet 约束,自动保证:
发音时刻 ↔ 嘴巴开合幅度 严丝合缝,不超前、不滞后。
极简一句话完整版
先把嘴部打码的视频压成特征、加上随机噪声,再用音频当指挥,经过几十轮逐步预测噪声、减掉噪声,一点点把噪点抹掉,在掩码位置生成匹配语音的唇形,最后解码变回完整视频。
变分自编码器 VAE 超通俗原理
一句话核心原理
VAE 不是简单把图片压缩解压,它是把图片强行塞进一个标准正态分布的概率空间,学会:用概率分布描述一张图,再从分布还原出原图。
1. 拆开两个词理解
- 自编码器 AE:输入图片 → 压缩成中间向量 → 再还原回原图
- 变分 V:不存一个固定向量,改成存一个概率分布(均值 + 方差),这就是和普通 AE 最大区别。
2.VAE 结构就三块
- Encoder 编码器输入一张人脸视频帧,不输出一个特征向量,而是输出两组参数:
- 均值 μ
- 方差 σ
意思:这张图片,在潜空间大概落在哪个范围、波动多大。
2.重参数采样
用 μ 和 σ,从这个正态分布里随机采样一个 latent 潜变量。
这一步是精髓:保证能随机生成新图片、新细节,不是死板复刻。
3.Decoder 解码器
拿采样出来的 latent 向量,重构还原回原始图片尺寸。
3. VAE 训练时只守两个规则(核心原理本质)
规则 1:重构损失
解码出来的图,要尽量和输入原图一模一样。
保证:压缩再解压,画面不能崩、人脸不能走样。
规则 2:KL 散度损失
强行让所有图片的潜变量分布,都贴近标准高斯分布 N (0,1)。
作用:
- 把所有人脸、表情、姿态规整到同一个空间
- 后面扩散模型加高斯噪声、去噪才能正常工作
- 可以在潜空间插值、生成新唇形、新细节
4. 放到你 LatentSync 里对应起来
- 输入视频每一帧 → VAE Encoder
算出 μ、σ → 采样得到 latent 潜变量(小尺寸特征) - 扩散模型就在这个 高斯分布约束的潜空间 做加噪、去噪、补唇形
- 修完的 latent → VAE Decoder 变回高清视频帧
5. 大白话终极总结
1.Encoder:把图片变成概率分布,不是单点;
2.采样:从分布里抓一个特征向量;
3.Decoder:把特征向量再画回图片;
4.同时约束:还原要像原图、分布要标准正态;
5.给扩散模型提供一个适合加噪、去噪、修图的完美中间空间。
6. 和普通普通编码器最大区别
普通自编码器:只能记住并复刻原图,没法合理随机生成;
VAE:是概率版编码器,既能还原原图,又能在潜空间合理随机生成新细节(比如新的自然唇形),刚好适配扩散模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)