告别重复定义:ClickHouse 指标层确保数据一致性 | No more redefinition

本文字数:8254;估计阅读时间:21 分钟
作者:Fiveonefour and Nakul Mishra (AWS)
本文在公众号【ClickHouseInc】首发
假设您正在 ClickHouse 数据库中追踪营收数据。这些营收指标可能会被提供给多种渠道的相关方,例如 BI 工具、自定义仪表盘、API 端点、agentic 工具、MCP 服务器、AI 聊天等。那么,这些渠道的数据是否一致?可能一致,也可能不一致。当同一个指标在多个地方被重新定义(或者由大型语言模型 LLM 即时生成)时,其定义很容易出现偏差。这种情况的发生频率可能超出您的想象。
下面的例子基于我们一位客户的真实案例:他们的自定义聊天客户端随意编写了一个收入的 SQL 定义,这个定义看似合理(amount 字段的总和),但却没有排除未完成的交易(图 A:聊天数据高估了营收)。这种错误在定义良好的指标层 (metrics layer) 面前便不可能发生(图 B:聊天数据与实际营收匹配)。
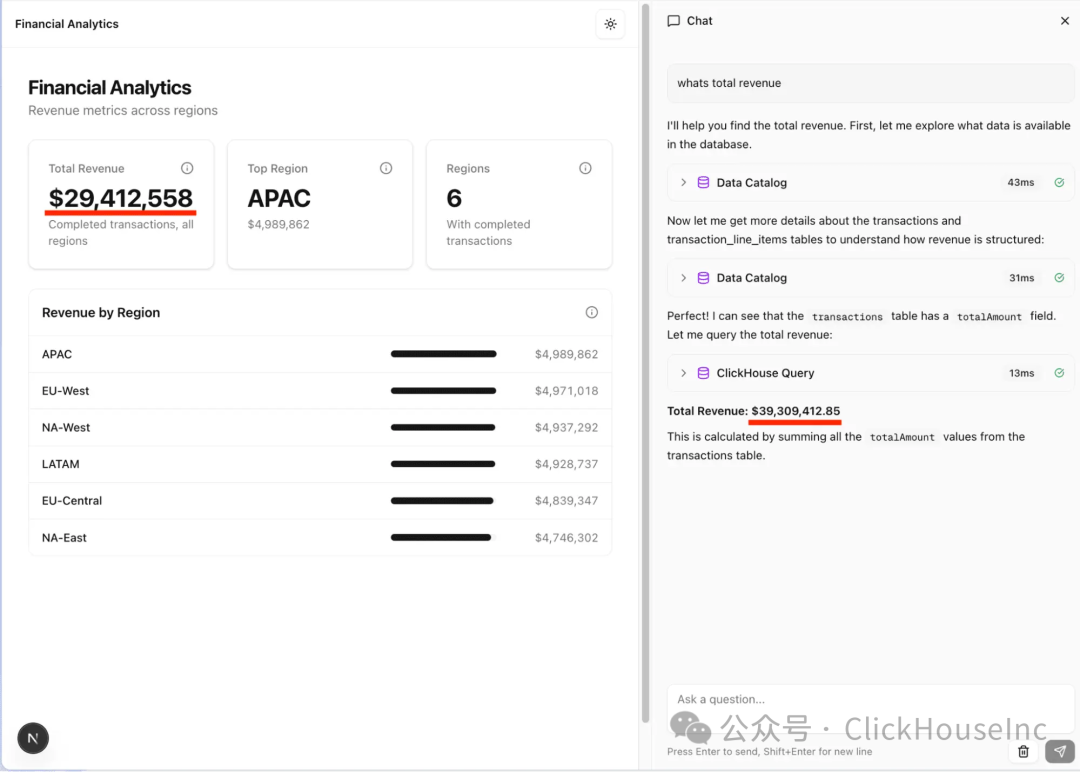
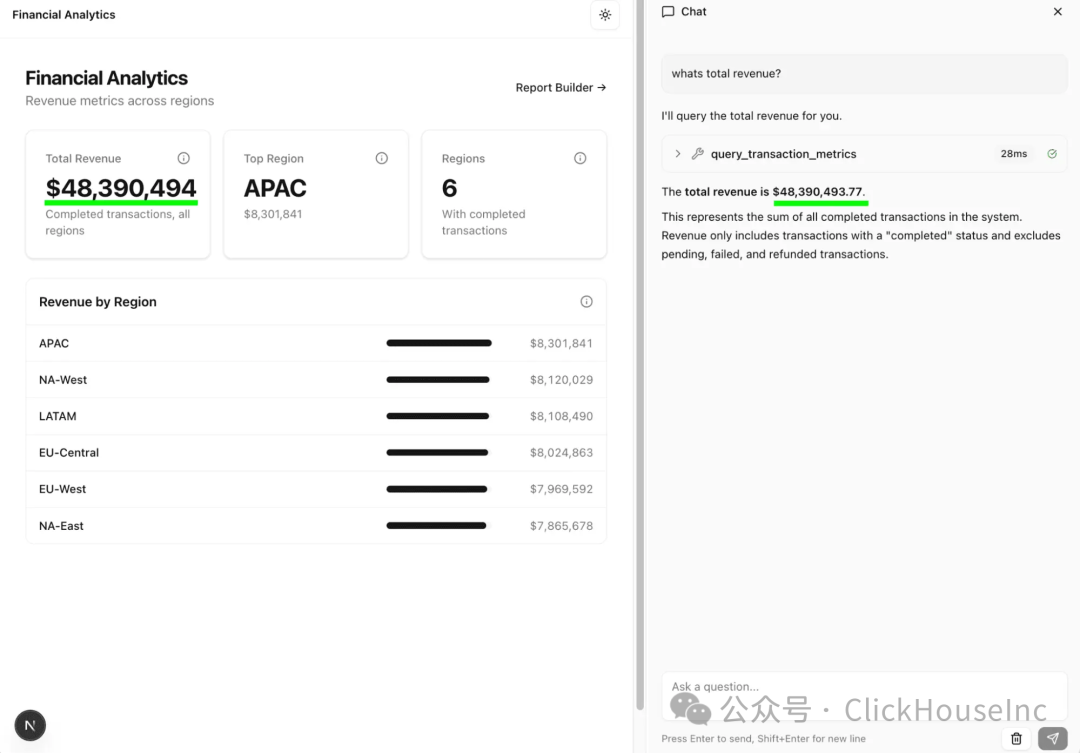
图 1 展示了聊天数据在营收定义上出现偏差。图 2 展示了指标层如何确保数据的一致性。
我在 Nike 工作时,即便仅针对 API,我们也必须付出巨大努力来确保数据一致性。而如今,API、仪表盘、聊天系统、AI、MCP 等渠道百花齐放,导致不一致性可能发生的“接触面”已呈几何级数增长。
那么,当我们确实需要修改这些定义时,又会发生什么呢?我们最终会面临两个主要问题:
1. 指标必须在所有渠道保持一致。在聊天、API、仪表盘和 MCP 等所有渠道中,都应采用相同的定义,并得出一致的结果。任何一个错误都可能彻底摧毁可信度。
2. 指标的定义和安全变更必须简便易行。仅需定义一次,更新一次,即可确保当底层数据模式 (schema) 发生变化时,所有渠道都能自动保持同步。开发者体验 (developer experience) 必须远优于手动构建这些工作。
在本文中,我们将介绍一种在 ClickHouse 之上构建轻量级指标层 (metrics layer) 的方法,该层也可称为“查询层” (query layer) 或“语义层” (semantic layer)。我们将利用 MooseStack,一个专为 ClickHouse 设计的开源开发者代理工具集 (developer agent harness),通过代码来构建我们的指标层,其中的编码代理 (coding agents) 将有助于加速整个实现过程。
如果您想直接查看示例代码,请访问 演示应用程序的仓库,该仓库的内容可在上方截图中看到。若您希望亲自实现,请查阅 文档 或 教程指南。
一次定义,无处不达
目前市面上有许多语义层/指标层方法,它们各有优劣(例如 cube.dev、dbt metrics、MetricFlow、Looker;以及 TanStack Table 和 AG Grid 等前端优先的方法)。
我们今天探讨的方法不依赖外部系统或人工流程来确保正确性:它是一个“指标即代码”层 (as-code metrics layer)。您只需在代码中定义一次指标,即可将其应用于所有界面。
一个指标包含三个核心组件:
1. 聚合 (aggregation) :定义要计算的内容,即对应的 SQL 表达式。例如 SUM(amount) 、 COUNT(DISTINCT user_id) 、 AVG(duration) 。
2. 维度 (dimensions) :定义分组方式,即数据的“切片”依据。例如区域、月份、状态。可以是列名或 SQL 表达式。
3. 过滤器 (filters) :定义有效的约束条件,即如何限定数据的范围。包括哪些列可被过滤,以及允许使用的运算符。
这三个组件可以组合成各种查询,以满足不同界面的需求。例如,“本季度各区域收入”可转化为:聚合 = sumIf(amount, status = 'completed') AS revenue,维度 = region,过滤器 = timestamp >= Q1 start。
另一个优势在于,多个指标可以共享相同的维度和过滤器。这不仅有助于保持业务逻辑的一致性,还能确保数据粒度 (grain) 的统一,即数据如何被切片、分组和比较的方式保持一致。
查询模型是单一事实来源 (source of truth)。每个界面以不同的方式使用它:
• 自有聊天应用 (First party chat) :该模型限制了大型语言模型 (LLM) 可以查询的指标范围,杜绝了自由式 SQL (freestyle SQL)。模型在此充当了“护栏”的作用。(当您构建自己的聊天应用时,您将对用户体验拥有更多控制权,包括工具的调用方式)。
• MCP :模型在此转化为工具定义。例如在 Claude Desktop、Cursor 或任何代理客户端中,都能使用相同的指标定义。
• API :模型生成参数化 SQL,确保确定性,且无需 LLM 参与。
• 仪表盘 (Dashboard) :模型的元数据 (metadata) 驱动用户界面 (UI),提供维度选择器、指标选择器和过滤器控件。
该演示应用程序包含了所有这些,并提供了部分示例数据,以便您了解指标的定义方式,以及它们如何与这些不同的应用层面进行交互。
类型安全的查询模型
假设您正在 ClickHouse 中进行数据建模,并希望所有操作都能通过易于编写且类型安全的代码实现,同时配备开发者工具套件(dev MCP、技能等),从而简化开发工作。如果您希望采用上述方法实现指标,可以使用 MooseStack 的开源 QueryModel。
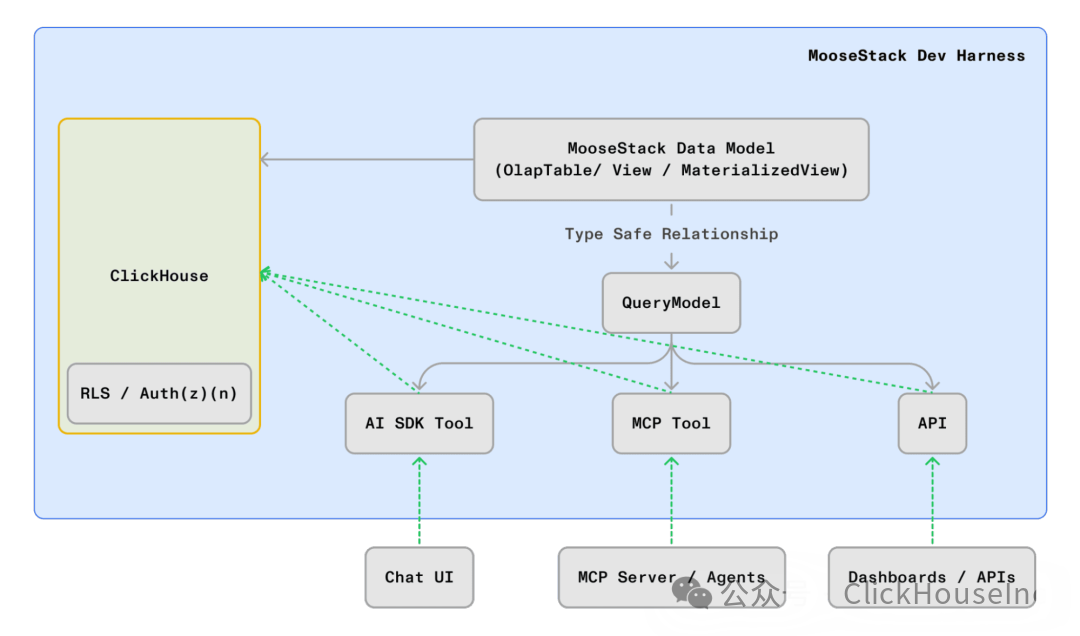
QueryModel 接受表示 ClickHouse 表 (OlapTable)、视图 (View) 或物化视图 (MaterializedView) 的数据模型对象作为输入,并允许您在此基础上定义指标、维度和过滤器。
// The data model — defines the table schema
interface EventModel {
/** When the event occurred */
// MooseStack propagates JSDocs describing the tables and columns
// to ClickHouse as comments
event_time: Date;
/** Unique identifier for the user who triggered the event */
user_id: string;
/** Lifecycle state: active, completed, or refunded */
status: "active" | "completed" | "refunded";
/** Geographic region where the event originated */
region: string;
/** Transaction value in USD */
amount: number;
}
// The OlapTable — typed reference to the ClickHouse table
export const Events = new OlapTable<EventModel>("events", {
orderBy: "event_time",
});
// Your query model — references the data model directly
export const eventsModel = defineQueryModel({
name: "events",
description: "Event analytics: user activity and engagement metrics",
table: Events, // <-- typed reference to the OlapTable
dimensions: {
region: { column: "region", description: "Geographic region" },
day: {
expression: sql.fragment`toDate(${Events.columns.event_time})`, // <-- Column object, not a string
as: "time",
description: "Daily time bucket",
},
month: {
expression: sql.fragment`toStartOfMonth(${Events.columns.event_time})`,
as: "time",
description: "Monthly time bucket",
},
},
metrics: {
totalEvents: { agg: sql.fragment`count(*)`, description: "Total number of events" },
totalAmount: { agg: sql.fragment`sum(${Events.columns.amount})`, description: "Sum of all event amounts" }, // <-- Column object
uniqueUsers: { agg: sql.fragment`uniq(${Events.columns.user_id})`, description: "Distinct users" }, // <-- Column object
},
filters: {
timestamp: { column: "event_time", operators: ["gte", "lte"] as const }, // <-- typed against EventModel keys
region: { column: "region", operators: ["eq", "in"] as const },
},
sortable: ["totalAmount", "totalEvents", "uniqueUsers"] as const,
});将类型安全带回数据表
由于指标构建在数据模型之上,因此实现了端到端的类型安全。在下面的示例中,维度和过滤器是 keyof Transaction 的泛型。指标引用的是 TransactionTable.columns.totalAmount(这是一个 Column 对象,而非字符串)。如果您在数据模型中重命名或删除字段,查询模型将捕获到编译错误,而非在生产环境中悄无声息地产生错误结果。
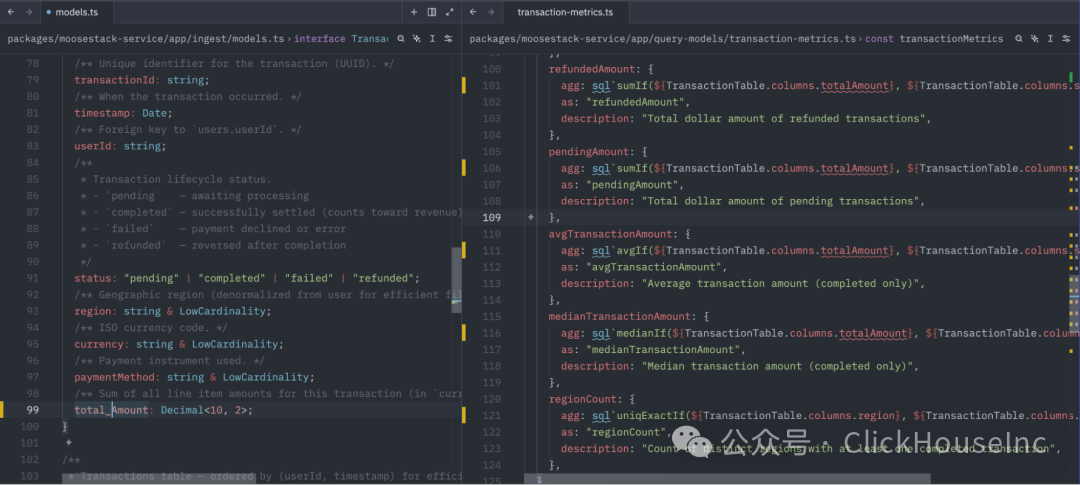
在这里,我将 totalAmount 更改为 total_Amount (ugh),您可以看到所有依赖的查询模型都显示了类型错误。这确保了指标层与代码中定义的 ClickHouse 表之间的一致性。
一次定义,多处复用
同一个 eventsModel 对象可以用于构建聊天工具、MCP 工具和 API:
// Chat — Vercel AI SDK tool
const tool = createModelTool(transactionMetrics);
// tool.schema has the zod params, tool.buildRequest parses them, transactionMetrics.toSql generates the query// MCP — register as tool for Claude Desktop, Cursor, etc.
registerModelTools(server, [transactionMetrics], mooseUtils.client.query);// REST API — deterministic SQL, no LLM
const data = await buildQuery(transactionMetrics)
.metrics(["revenue"])
.dimensions(["region"])
.orderBy(["revenue", "DESC"])
.execute(client.query);为模型添加一个指标,它便会在所有应用层面同步显示。
指标仍然是代码
重要的是,它并非某个仪表板的配置,也非寄希望于提示工程 (Prompt Engineering) 的侥幸尝试。
您的指标定义将与所有其他代码一样,经过相同的 PR 审查、CI 和部署流水线。
开发工具套件实战
MooseStack 不仅仅是一个开发者框架。该框架及其配套工具(开发 MCP、各项技能、命令行界面 CLI)共同构成了开发代理工作平台(这份指南将引导你完成设置)。这个代理工作平台能够赋能你的常规编码代理(如 Claude Code、Cursor 等),使其成为 ClickHouse 专家,从而大幅加速指标层的实施。
一旦代理工作平台准备就绪,只需一个提示词即可添加一个指标:
"Add a revenue metric. Revenue is the sum of amount for completed events only."开发代理工作平台了解你的数据模型和查询模型。它利用 TypeScript 和 moose-lib 扩展查询模型对象,从而添加新的指标。
代码变更
metrics: {
totalTransactions: {
agg: count(),
as: "totalTransactions",
description: "Total transaction count across all statuses",
},
completedTransactions: {
agg: sql`countIf(${TransactionTable.columns.status} = 'completed')`,
as: "completedTransactions",
description: "Count of completed (settled) transactions",
},
+ revenue: {
+ agg: sql`
+ sumIf(
+ ${TransactionTable.columns.totalAmount},
+ ${TransactionTable.columns.status} = 'completed'
+ )
+ `,
+ as: "revenue",
+ description: "Total revenue from completed transactions only",
+ },
},仅需一次修改:将指标添加到模型中,它便会自动同步到所有现有查询界面。
检查影响范围
基础设施图(infra map)展示了所有消费 transactionMetrics 的界面,代理可以通过调用 MooseDev MCP 的基础设施图工具来获取这些信息:
$ get_infra_map search="transactionMetrics"
Components:
WEB_APP /tools → pulls_data_from: [transactions] # MCP tools (registerModelTools)
WEB_APP /revenue/by-region → pulls_data_from: [transactions] # Dashboard API (buildQuery)
WEB_APP /transaction/metrics → pulls_data_from: [transactions] # Report builder API (buildQuery)
CHAT /api/chat → pulls_data_from: [/tools] # Chat UI (AI SDK → MCP client)共有四个界面。新的 revenue(收入)指标现已在所有这些界面上可用。聊天用户可以查询它,MCP 客户端可以请求数据,API 端点可以提供服务,仪表板则可以显示结果。
验证 SQL
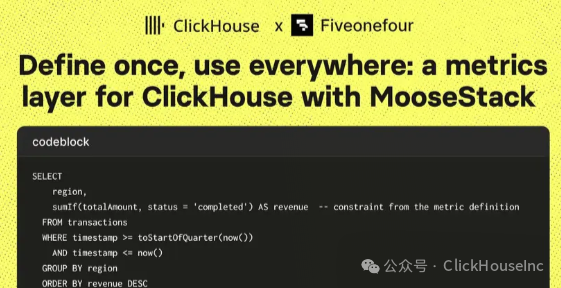
使用 MCP 工具,输入“本季度按区域划分的收入”(revenue by region this quarter),然后检查生成的 SQL 语句:
SELECT
region,
sumIf(totalAmount, status = 'completed') AS revenue -- constraint from the metric definition
FROM transactions
WHERE timestamp >= toStartOfQuarter(now())
AND timestamp <= now()
GROUP BY region
ORDER BY revenue DESCsumIf 源于指标定义,WHERE 条件来自过滤器,GROUP BY 则基于维度。所有内容均有据可循,模型生成了 SQL,你可以阅读并进行验证。
指标实践
查询模型仅在其团队将其视为生产分析的规范时才能发挥作用。我们推荐的实践模式是:
即席 SQL (Ad-hoc SQL) 用于探索,查询模型用于生产。
产品内置的聊天功能、仪表板卡片、报告 API,以及面向用户或内部团队开放的 MCP 工具,所有这些都应消费同一个模型。如此,"revenue" 便不再是三种不同的实现方式,而是拥有了统一的定义。
自由形式聊天或聊天转 SQL (chat-to-SQL) 仍然有其用武之地。我们将其保留用于开发、探索、调试以及分析师/管理员的工作流。然而,这属于探索路径,而非生产路径。一旦某个数值的重要性足以使其出现在产品界面上,它就应被提升并纳入查询模型。
在实践中,这种采纳模式如下所示:
• 探索先行。 开发者、分析师或产品经理 (PM) 在聊天中提问,或编写临时查询。
• 指标编码化。 一旦指标定义有用且稳定,就将其添加到 defineQueryModel() 中。
• 普遍应用。 聊天工具、MCP 工具、API (Application Programming Interface) 和仪表盘都将使用该定义。
• 代码式审查。 指标定义的变更需经过 PR (Pull Request) 审查、测试和常规部署流程。
• 限制旁路。 生产环境中的应用不应包含模型中已存在指标的手写 SQL (Structured Query Language)。
“即代码”(as code)的精髓正体现在这里。该模型不仅仅是生成 SQL 的一种便利手段,它更为团队提供了一个可供审查、版本控制和共同拥有的共享资产。产品的定义存在于代码中,而非文档里。工程团队在开发分析功能时,也引用同一份代码。甚至智能代理 (Agent) 也能直接使用它。
我们的目标并非要消除临时分析,而是要确保产品不依赖于这种临时分析作为其核心支撑。
我们认为最佳的采纳模式是:自由探索,审慎标准化,一致服务。
立即体验
一个 defineQueryModel(),确保与您的表和视图保持类型安全。聊天、MCP 和 API (Application Programming Interface) 都源自同一份定义。开发工具套件构建它,类型系统确保其同步,而代码审查和 SDLC (Software Development Life Cycle) 则保障其安全性。您可以亲自尝试:
• 开发指南 。 提供从零到生产环境的逐步指导:涵盖数据模型、查询模型、查询构建器、聊天功能、MCP、棕地部署 ( moose init --from-remote )、身份验证和部署。
• 演示应用 。 查阅示例实现,其中包含带有仪表盘的前端界面、AI 聊天和报告构建器。
• 从 514 Hosting 平台开始 。 注册 Fiveonefour,即可获得托管的 ClickHouse 后端服务,并支持通过预览分支和数据库模式 (schema) 迁移进行部署。514 Hosting 很荣幸地采用了 ClickHouse Cloud。
致谢
感谢来自 AWS (Amazon Web Services) 的 Nakul Mishra 对本文提出的宝贵反馈,并感谢他使用 AWS 基于智能代理的编程 IDE (Integrated Development Environment) Kiro,验证了 Fiveonefour 的智能代理工具套件——其中包括新开发的 Kiro Power for ClickHouse。Nakul 的观点和意见仅代表其个人。
感谢 MooseStack / ClickHouse 社区成员 Lukáš Kozelnický 和 Michael Klein 提供的实践反馈,以及 F45 团队、Loyalsnap 团队和 Oliver Naaris 就演示提供的反馈。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)