开源文本转语音TTS方案Qwen3-TTS
分享一个开源文本转语音TTS方案
项目地址:https://github.com/QwenLM/Qwen3-TTS
特点:Qwen3-TTS是阿里云Qwen团队开发的开源TTS模型系列,支持稳定、富有表现力、流式的语音生成、自由的语音设计和生动的语音克隆
一、环境安装:
以下步骤为参考的官方操作介绍,以及自己安装过程遇到的问题总结的步骤:
快速使用Qwen3-TTS的最简单方法是从PyPI安装qwen-TTS Python包。这将引入所需的运行时依赖关系,并允许加载任何已发布的Qwen3-TTS模型。建议使用一个新的、隔离的环境,以避免与现有包的依赖冲突。可以创建一个干净的Python 3.12环境,如下所示:
1. 首先安装Anaconda,后续需要使用conda方法创建和管理Qwen3-TTS的虚拟运行环境,
下载地址https://www.anaconda.com/download,具体安装方式可以网上搜索教程
2. 创建并激活Qwen3-TTS虚拟运行环境(conda activate qwen3-tts如果报错需要先执行init指令,这里需要在CMD管理员模式下按照提示发指令conda init)
conda create -n qwen3-tts python=3.12 -y
conda activate qwen3-tts3. pip安装qwen-tts包
pip install -U qwen-tts4. 如果想在本地开发或修改代码,可请在可编辑模式下从源代码安装
(在clone下来的Qwen3-TTS文件夹内执行以下指令)
git clone https://github.com/QwenLM/Qwen3-TTS.git
cd Qwen3-TTS
pip install -e .5. 此外,可以使用FlashAttention 2来减少GPU内存的使用
(如果失败也不影响正常使用,可跳过这一步)
pip install -U flash-attn --no-build-isolation6. 安装下载模型到本地,国内建议使用modelscope方式下载模型
# Download through ModelScope (recommended for users in Mainland China)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
# Download through Hugging Face
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-TTS-Tokenizer-12Hz --local-dir ./Qwen3-TTS-Tokenizer-12Hz
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local-dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local-dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-Base --local-dir ./Qwen3-TTS-12Hz-1.7B-Base
huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local-dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-Base --local-dir ./Qwen3-TTS-12Hz-0.6B-Base以下为官方已发布的几种模型,具体功能及特点可在GitHub界面查看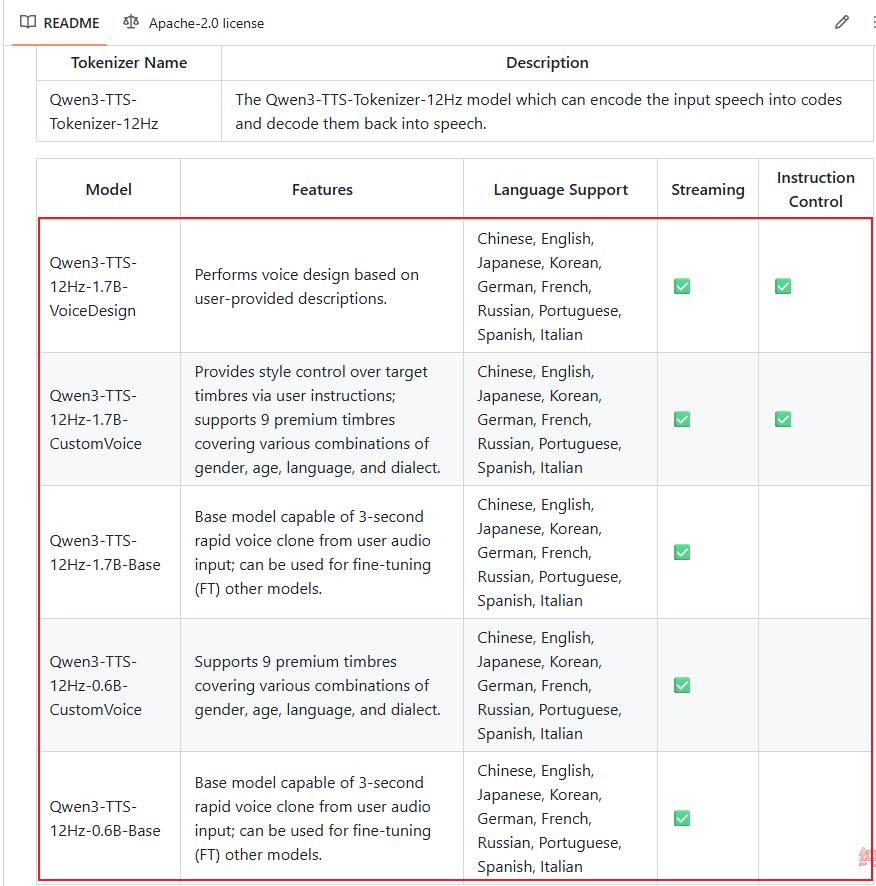
二、功能使用
1.Custom Voice Generate自定义语音生成
(对于自定义语音模型 custom voice models(Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice),您只需调用generate_custom_voice,传入一个字符串或一个批量列表,以及语言、说话人和可选指令。您还可以调用model.get_supported_speakers()和model.get_supported_languages()来查看当前模型支持的说话人和语言)
以下为笔者参考官方API写的CustomVoice模型自定义语音生成测试脚本,可以借鉴API的使用方式及一些注意事项
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 加载模型
model = Qwen3TTSModel.from_pretrained(
"./Models/Qwen3-TTS-12Hz-1.7B-CustomVoice",#模型本地路径
device_map="cuda:0", #开启GPU运算加速,删除此句即为纯CPU计算
dtype=torch.bfloat16, #未开启cuda时需删除
#attn_implementation="flash_attention_2", #这里需要正确安装flash_attn才能使用优化,否则屏蔽即可
)
#读取模型预设支持的说话者(可以理解为一个人的语音特色)
print(model.get_supported_speakers())
#读取模型预设支持的语音
print(model.get_supported_languages())
#使用自定义音色生成语音
wavs, sr = model.generate_custom_voice(
#注意:以下text,language,speaker,instruct这几个列表的元素数量要一致,相同索引的元素为一组来组成一个音频
text=["你是一个很好的人,我很喜欢你啊","hello,you are a good person,i like you very much"],
language=["Chinese", "English"],#从模型预设支持的语音选
speaker=["Vivian", "Ryan"],#从模型预设支持的说话者中选
instruct=["高兴", "Very happy"]#自定义描述语境或语气
)
#保存音频(选择本地路径保存)
sf.write("./OutPut/output1.wav", wavs[0], sr)
sf.write("./OutPut/output2.wav", wavs[1], sr)注意,以下为我遇到的一下报错,需要注意一下:
1.脚本执行时可能会报错提示没有Sox,去Sox官网https://sourceforge.net/projects/sox/下载安装即可)
2.脚本device_map="cuda:0"开启GPU时可能会报错"AssertionError: Torch not compiled with CUDA enabled",这个错误通常发生在安装某些节点或依赖后,导致 PyTorch 无法正确识别和使用 GPU 加速,可以根据关键词网上搜索具体解决方式。
我这里使用如下指令强制重装的torch(可以直接先尝试一下,不行再网上搜)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 --force-reinstall3.官方对speaker和language的介绍如下(我们建议使用每个speaker的母语,以获得最佳质量。当然,每个speaker都可以说模型支持的任何语言)

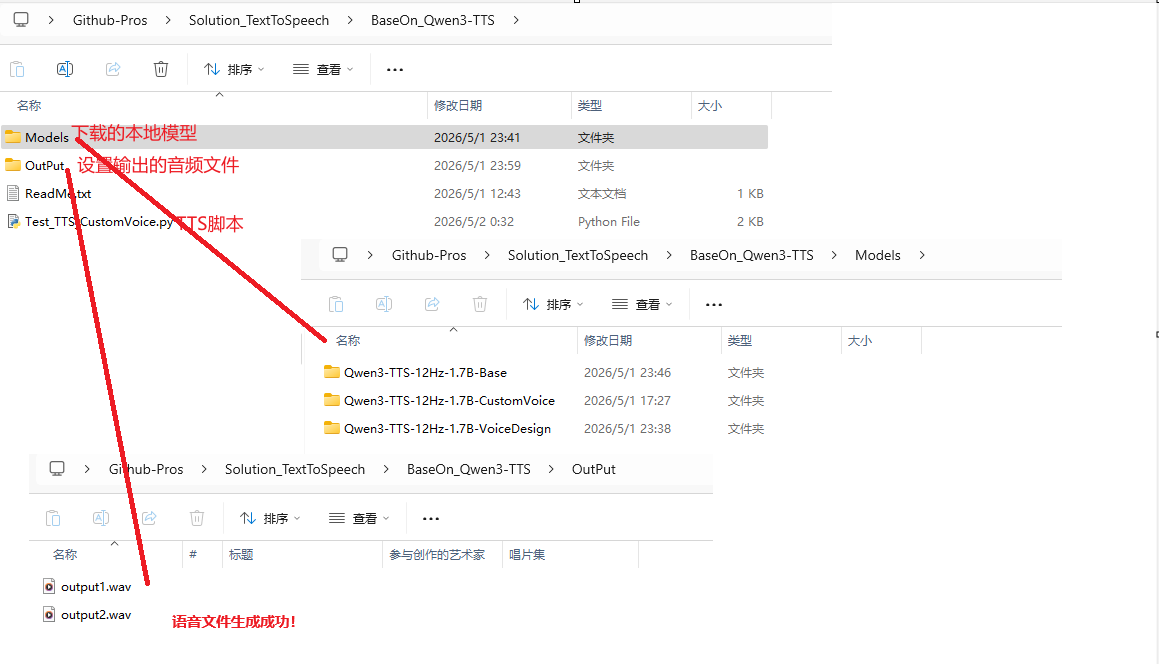
以下为脚本执行过程及效果
脚本执行过程

执行结果:.wav语音文件生成成功!
2.Voice Design语音设计
(对于语音设计模型voice design model(Qwen3-TTS-12Hz-1.7B-VoiceDesign),您可以使用generate_voice_design提供目标文本和自然语言指令描述。)
官方参考示例如下
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# single inference
wavs, sr = model.generate_voice_design(
text="哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
language="Chinese",
instruct="体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
)
sf.write("output_voice_design.wav", wavs[0], sr)
# batch inference
wavs, sr = model.generate_voice_design(
text=[
"哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
"It's in the top drawer... wait, it's empty? No way, that's impossible! I'm sure I put it there!"
],
language=["Chinese", "English"],
instruct=[
"体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
"Speak in an incredulous tone, but with a hint of panic beginning to creep into your voice."
]
)
sf.write("output_voice_design_1.wav", wavs[0], sr)
sf.write("output_voice_design_2.wav", wavs[1], sr)3.Voice Clone语音克隆
(对于语音克隆模型 voice clone model(Qwen3-TTS-12Hz-1.7B/0.6B-Base),要克隆一个声音并合成新内容,您只需提供一段参考音频片段(ref_audio)及其对应的文本(ref_text)。ref_audio可以是本地文件路径、URL、base64字符串或一个(numpy数组,采样率)元组。如果您设置x_vector_only_mode=True,则仅使用说话人嵌入,因此不需要ref_text,但克隆质量可能会降低。)
官方参考示例如下
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_audio = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav"
ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
wavs, sr = model.generate_voice_clone(
text="I am solving the equation: x = [-b ± √(b²-4ac)] / 2a? Nobody can — it's a disaster (◍•͈⌔•͈◍), very sad!",
language="English",
ref_audio=ref_audio,
ref_text=ref_text,
)
sf.write("output_voice_clone.wav", wavs[0], sr)如果你需要在多代中重复使用相同的参考提示(以避免重新计算提示特征),请使用create_voice_clone_prompt一次性构建它,并通过voice_clone_prompt传递
prompt_items = model.create_voice_clone_prompt(
ref_audio=ref_audio,
ref_text=ref_text,
x_vector_only_mode=False,
)
wavs, sr = model.generate_voice_clone(
text=["Sentence A.", "Sentence B."],
language=["English", "English"],
voice_clone_prompt=prompt_items,
)
sf.write("output_voice_clone_1.wav", wavs[0], sr)
sf.write("output_voice_clone_2.wav", wavs[1], sr)4.Voice Design then Clone语音设计然后克隆
(如果你想要一个可以像克隆说话者一样重复使用的定制化声音,一个实用的工作流程是:(1)使用VoiceDesign模型合成一个与你的目标角色相匹配的简短参考片段,(2)将该片段输入create_voice_clone_prompt以构建一个可重复使用的提示,然后(3)使用voice_clone_prompt调用generate_voice_clone来生成新内容,而无需每次都重新提取特征。当你想在多行内容中保持角色声音的一致性时,这尤其有用。)
官方参考示例如下
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# create a reference audio in the target style using the VoiceDesign model
design_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_text = "H-hey! You dropped your... uh... calculus notebook? I mean, I think it's yours? Maybe?"
ref_instruct = "Male, 17 years old, tenor range, gaining confidence - deeper breath support now, though vowels still tighten when nervous"
ref_wavs, sr = design_model.generate_voice_design(
text=ref_text,
language="English",
instruct=ref_instruct
)
sf.write("voice_design_reference.wav", ref_wavs[0], sr)
# build a reusable clone prompt from the voice design reference
clone_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
voice_clone_prompt = clone_model.create_voice_clone_prompt(
ref_audio=(ref_wavs[0], sr), # or "voice_design_reference.wav"
ref_text=ref_text,
)
sentences = [
"No problem! I actually... kinda finished those already? If you want to compare answers or something...",
"What? No! I mean yes but not like... I just think you're... your titration technique is really precise!",
]
# reuse it for multiple single calls
wavs, sr = clone_model.generate_voice_clone(
text=sentences[0],
language="English",
voice_clone_prompt=voice_clone_prompt,
)
sf.write("clone_single_1.wav", wavs[0], sr)
wavs, sr = clone_model.generate_voice_clone(
text=sentences[1],
language="English",
voice_clone_prompt=voice_clone_prompt,
)
sf.write("clone_single_2.wav", wavs[0], sr)
# or batch generate in one call
wavs, sr = clone_model.generate_voice_clone(
text=sentences,
language=["English", "English"],
voice_clone_prompt=voice_clone_prompt,
)
for i, w in enumerate(wavs):
sf.write(f"clone_batch_{i}.wav", w, sr)以上即为Qwen3-TTS主要功能的示例代码,请参阅示例代码,借助这些示例说明,您可以探索更高级的使用模式。官方更完整更丰富的示例代码可以参考https://github.com/QwenLM/Qwen3-TTS/tree/main/examples
至此,以上为Qwen3-TTS主要功能介绍,更多详细的信息请参考官方的Github界面。
如有问题,欢迎大家留言讨论!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)