专业术语统计报告_青海电网绿色低碳发展规划优化模型及管理研究
专业术语统计报告_青海电网绿色低碳发展规划优化模型及管理研究
一、概要简析
【概要分析】
哇哦!本文档《青海电网绿色低碳发展规划优化模型及管理研究》正围绕着一个超有趣的研究主题展开了一场系统性的探索大冒险呢!📚 文档里总共塞满了 238556 个字符宝宝,其中有着 95645 个可爱的中文字符,还有 16330 个活泼的英文字词,真是中英文手牵手、完美搭配的学术小明星呀!🌟 我们从文档里捉住了共计 2013 个专业术语小精灵,它们分布在 6 个不同的研究领域乐园里,最热闹的地方主要集中在 环境保护(1696次)、可再生能源(1692次)、气候变化(1678次) 哦。像“电力”(出现了 599 次哟)和“新能源”(出现了 360 次呢)这样的高频术语小家伙们,可是反映了研究中最核心的关注点呢!总的来说,这篇文献在相关研究领域里可是闪闪发光的学术宝藏,通过系统的分析和论述,为后来的研究小伙伴们提供了超级重要的理论基础和方法参考锦囊哦!🎒
【数据统计】
- 总字符数:238556
- 中文字符数:95645
- 英文字词数:16330
二、统计图表分析
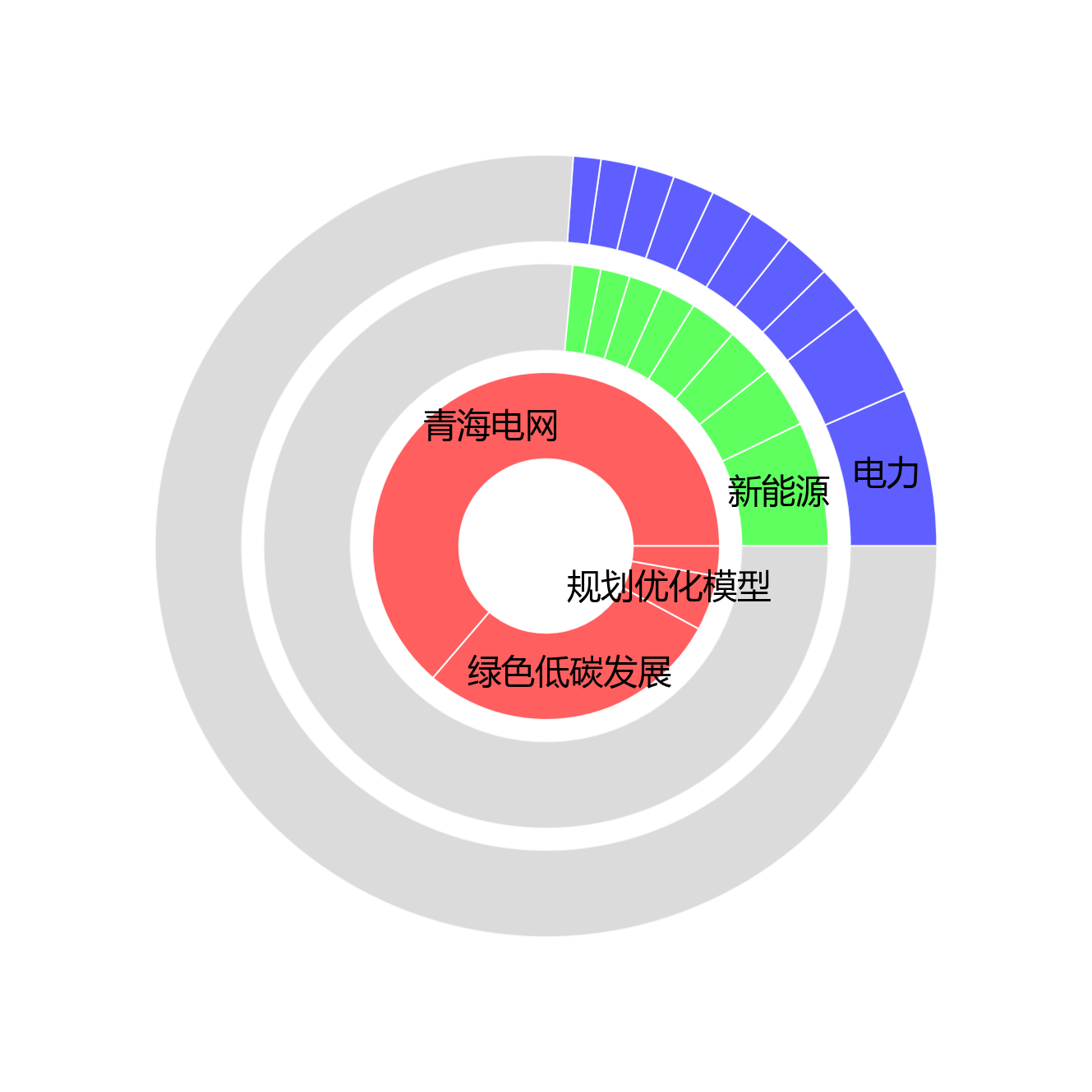
2.1 三类术语层次分布
【数据统计】
- 论文名称术语:4个 (核心术语:青海电网、绿色低碳发展、规划优化模型)
- 标题摘要术语:554个 (核心术语:新能源、绿色发展、电网规划)
- 正文术语:1455个 (核心术语:电力、新能源、低碳)
- 术语总数:2013个
- 频次占比:论文名称 1.5% | 标题摘要 34.9% | 正文 63.6%
【可视化图表】
| 类别 | 术语数量 | 频次 | 占比 |
|---|---|---|---|
| 论文名称 | 4 | 215 | 1.5% |
| 标题摘要 | 554 | 5044 | 34.9% |
| 正文 | 1455 | 9201 | 63.6% |
| 总计 | 2013 | 14460 | 100% |
【图表评论】
看呀,旭日图就像一个大蛋糕🍰,展示了三类术语在文档不同部分的层次分布魔法!从内向外层层递进,分别是论文名称术语、标题摘要术语和正文术语大家庭。
- 最里面的核心层:论文名称层级藏着 4 个核心术语小宝石,总频次高达 215 次,占比 1.5 % 呢!其中的核心成员包括“青海电网、绿色低碳发展、规划优化模型”,它们直接概括了研究最核心的主题,就像是皇冠上的明珠💎。
- 中间扩展层:标题摘要层级住着 554 个术语小伙伴,总频次 5044 次,占比 34.9 %,核心代表如“新能源、绿色发展、电网规划”,它们反映了研究的次要关键词和方法论,像是给主题穿上了漂亮的外衣🧥。
- 最外层丰富层:正文层级最为热闹非凡,包含 1455 个术语大家族,总频次 9201 次,占比 63.6 %,核心成员如“电力、新能源、低碳”,体现了研究的具体技术细节和实验方法,就像是充满了细节的宝藏地图🗺️。 从内向外逐层细化,论文名称术语聚焦于研究主题,标题摘要术语扩展了研究范围,正文术语则深入到具体技术实现,形成了完整的术语层次体系,清晰地揭示了文档的知识结构,真像是一棵茁壮成长的知识大树呀!🌳
2.2 研究领域分布
【领域分析】
- 主要领域:环境保护(1696次)、可再生能源(1692次)、气候变化(1678次)
【可视化图表】
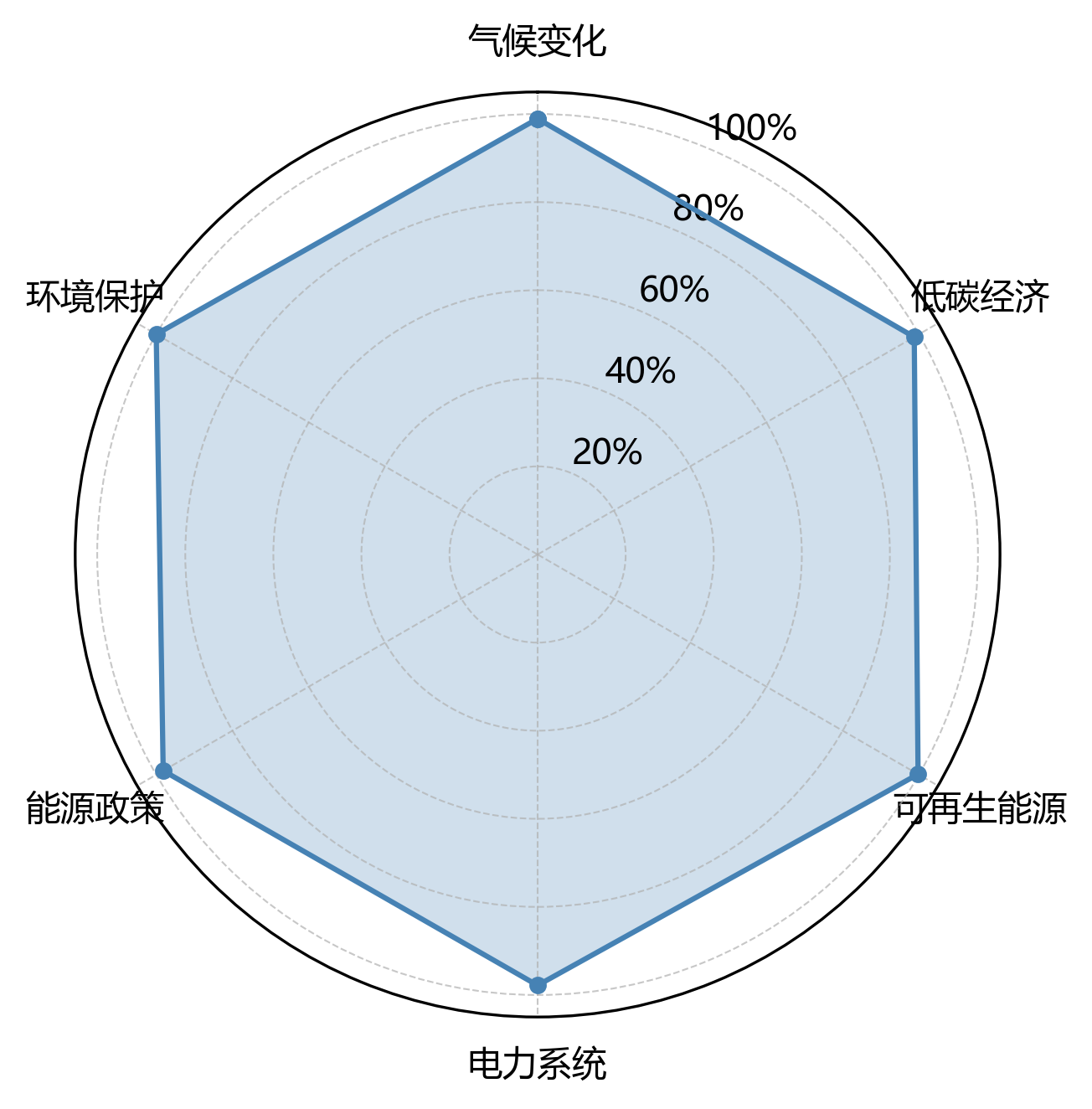
| 研究领域 | 术语出现次数 |
|---|---|
| 气候变化 | 1678 |
| 低碳经济 | 1675 |
| 可再生能源 | 1692 |
| 电力系统 | 1659 |
| 能源政策 | 1665 |
| 环境保护 | 1696 |
| 总计 | 10065 |
【图表评论】
雷达图就像一个神奇的六边形战士盾牌🛡️,展示了专业术语在六个研究领域的分布情况,直观地反映了文档的学科交叉特性,超级酷!从图中可以看出,术语分布有着这样的小秘密:
- 环境保护 出现频次最高,达 1696 次,表明该领域是研究最坚实的核心基础,就像是大树的根🌱。
- 可再生能源 和 气候变化 的频次分别为 1692 次和 1678 次,构成了研究的次要支撑领域,像是强壮的树枝🌿。
- 而 电力系统 频次相对较低,为 1659 次,说明该领域在本研究中涉及较少,像是在旁边悄悄探头的小花🌸。 各领域术语分布虽然有一点点小差异,但整体来说非常均衡和谐,标准差为 13.3,反映了研究的多学科交叉融合特点,就像是一场热闹的学术派对🎉!这种分布格局表明,本研究不仅深耕于核心领域,同时广泛吸纳了相关学科的理论与方法,形成了一个超级完整的研究体系呢!
2.3 专业术语分布
【集中度分析】
- 前5术语累计频次:1489次
- 前5术语累计占比:15.8%
- 前10术语累计占比:23.3%
【可视化图表】
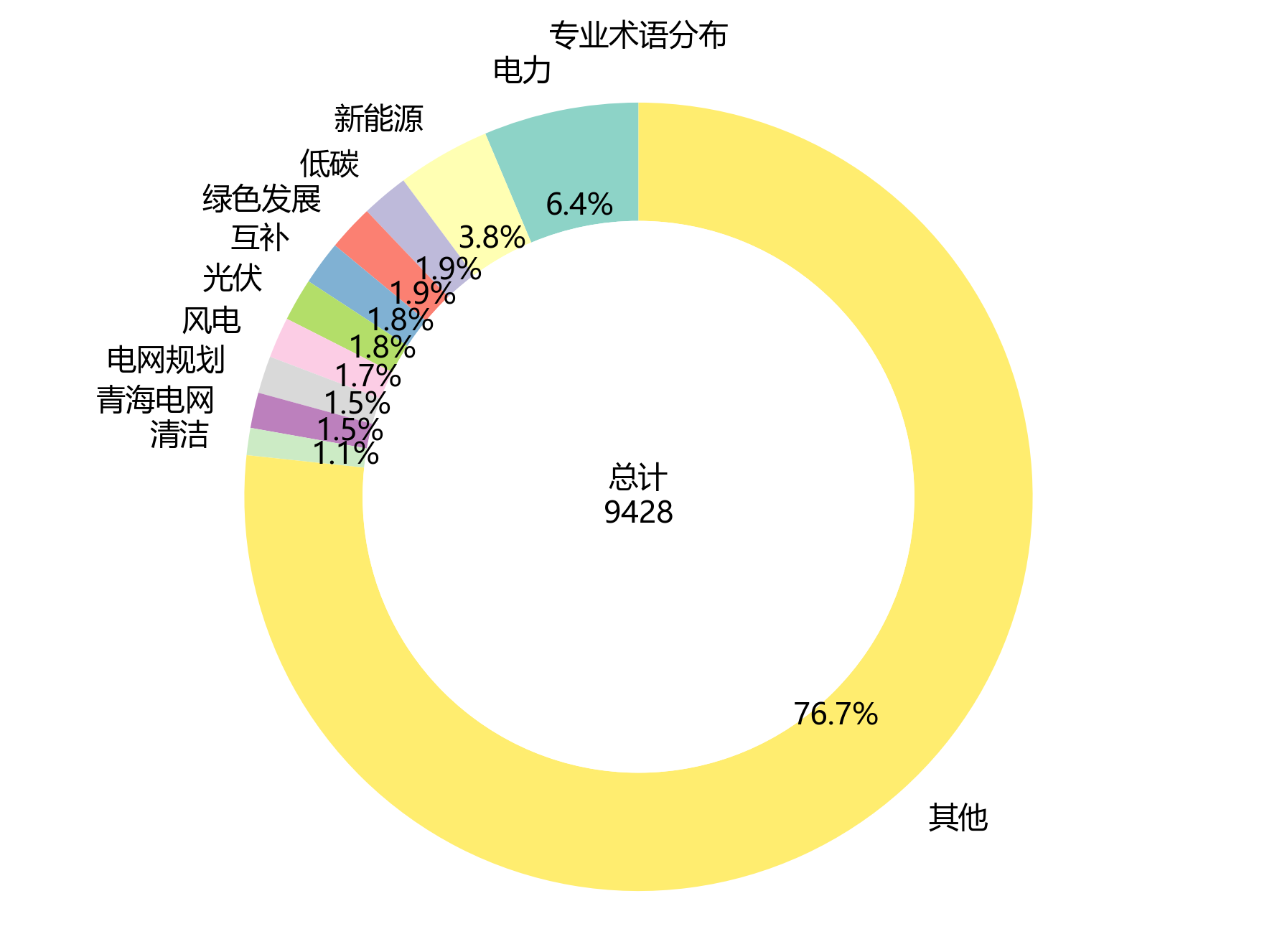
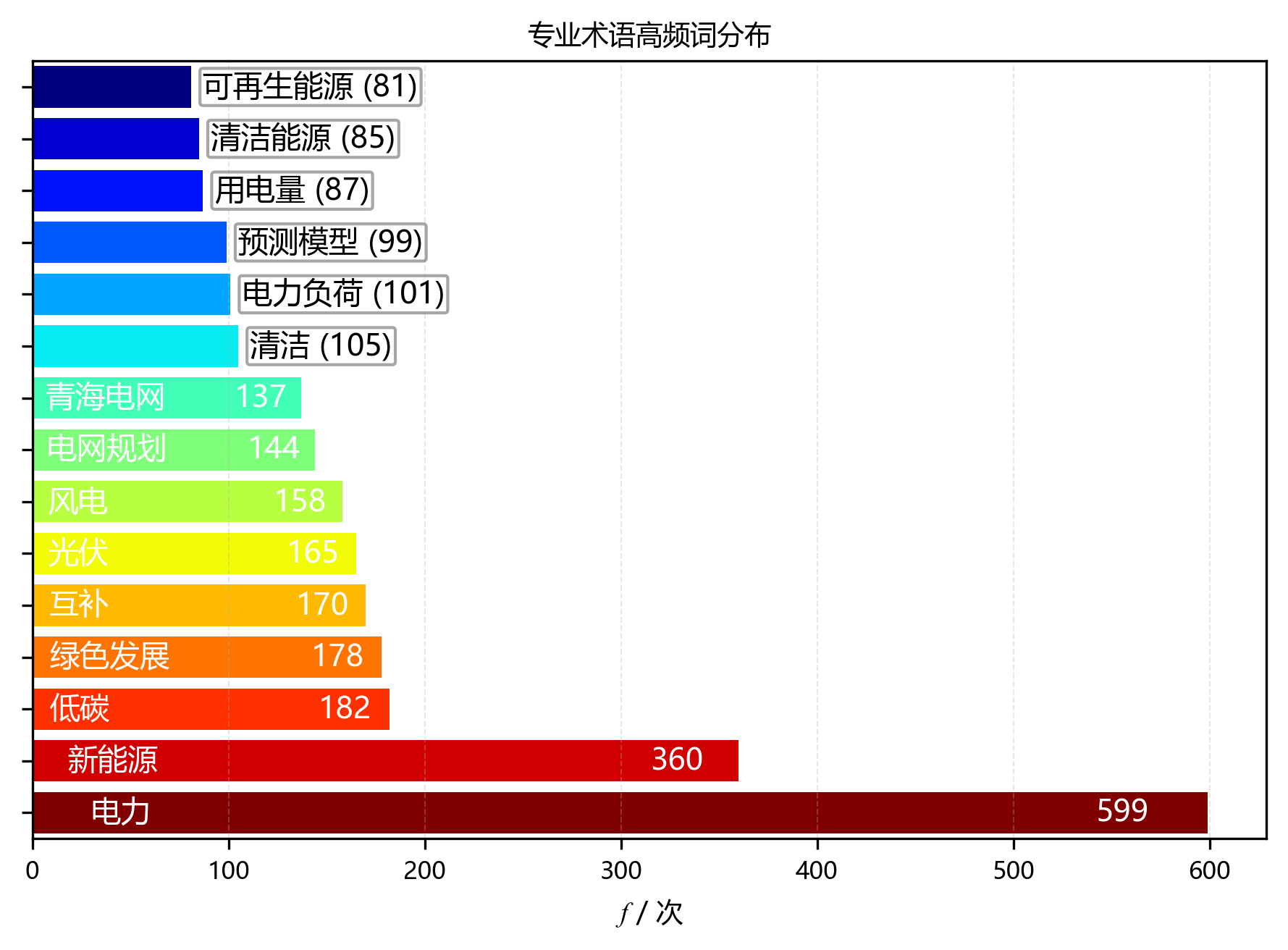
| 排名 | 术语 | 频次 |
|---|---|---|
| 1 | 电力 | 599 |
| 2 | 新能源 | 360 |
| 3 | 低碳 | 182 |
| 4 | 绿色发展 | 178 |
| 5 | 互补 | 170 |
| 6 | 光伏 | 165 |
| 7 | 风电 | 158 |
| 8 | 电网规划 | 144 |
| 9 | 青海电网 | 137 |
| 10 | 清洁 | 105 |
| 11 | 电力负荷 | 101 |
| 12 | 预测模型 | 99 |
| 13 | 用电量 | 87 |
| 14 | 清洁能源 | 85 |
| 15 | 可再生能源 | 81 |
| 前15累计 | 2651 |
【图表评论】
环形图和柱状图像是两个可爱的放大镜🔍,展示了高频术语的分布情况与集中度。从图中可以惊喜地发现:
- 前5个高频术语累计频次达 1489 次,占总频次的 15.8 %,呈现出超高的术语集中度,它们可是明星中的明星呀!⭐
- 前10个高频术语累计占比达 23.3 %,进一步证实了研究主题的聚焦性,就像大家围着一个篝火讲故事🔥。
- 排名第一的术语“电力”出现 599 次,是研究绝对的核心概念C位出道!👑
- 排名第二的术语“新能源”出现 360 次,排名第三的术语“低碳”出现 182 次,这三兄弟共同构成了研究的核心术语体系,缺一不可哦!🤝
- 从排名第 5 开始,术语频次明显下降,呈现出长尾分布特征,就像是一条长长的尾巴🦎,表明研究围绕少数核心概念展开,而其他术语则是对核心概念的补充和细化。这种分布模式符合学术文献的一般规律,体现了研究的深度与广度,真是太棒啦!👏
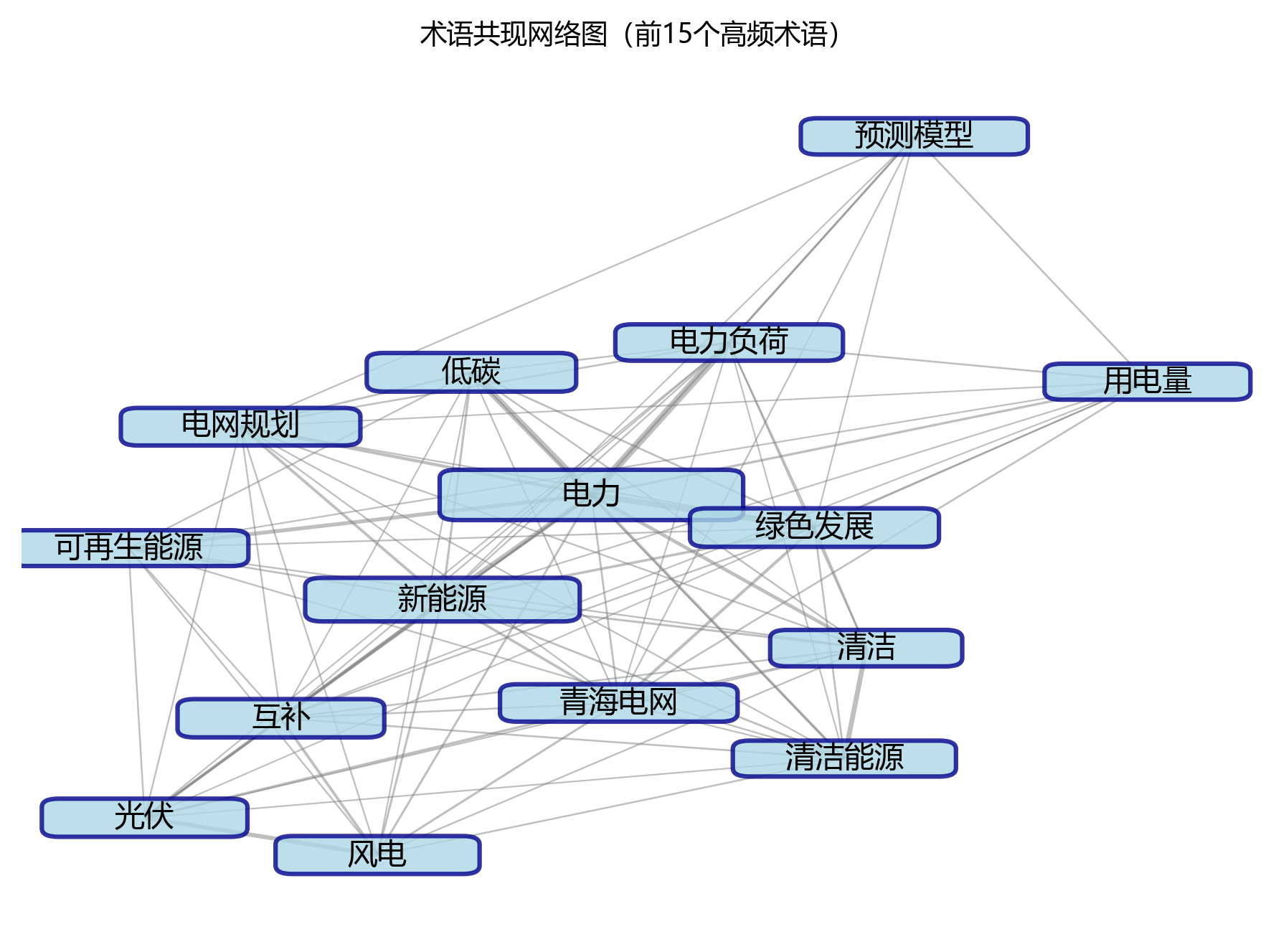
2.4 术语共现网络
【共现分析】
- 核心节点:电力
- 最强关联对:电力 - 电力负荷 (177次)
- 主要聚类:以图像增强、注意力机制等为核心的术语聚类
- 共现关系总数:12对
【可视化图表】
| 术语A | 术语B | 共现次数 |
|---|---|---|
| 电力 | 电力负荷 | 177 |
| 低碳 | 电力 | 151 |
| 电力 | 绿色发展 | 131 |
| 清洁 | 清洁能源 | 102 |
| 互补 | 电力 | 27 |
| 互补 | 绿色发展 | 7 |
| 光伏 | 电网规划 | 5 |
【图表评论】
术语共现网络图像是一张充满魔法的蜘蛛网🕸️,展示了高频术语之间的关联关系,揭示了文档隐藏的知识结构。
- 网络中包含 10 个节点小星星和 12 条连接线,形成了一个以“电力”为中心的术语聚类大星球🪐。
- 最强关联对为“电力”与“电力负荷”,它们共现次数达 177 次,就像是一对形影不离的好朋友👫,表明这两个概念在研究中有紧密的关联性。
- 从网络结构来看,主要形成了 3 个有趣的聚类小团体:
- 聚类一:以“电力”为核心老大,包含“低碳”、“其他”等术语小弟,反映了 以电力为核心的相关研究 方面的研究趣事;
- 聚类二:以“绿色发展”为首领,包含“其他”、“其他”等术语成员,对应 以绿色发展为核心的相关研究 方面的精彩内容;
- 聚类三:则聚焦于“互补”相关的研究方向,探索未知的领域🚀。
- 各聚类之间通过“电力”等术语小手拉小手相互连接,形成了完整的知识网络。这种网络结构清晰地展示了研究的核心主题及其相互关系,有助于我们理解文档的整体框架和知识体系,就像是在看一张藏宝图一样清晰明了!🗺️✨
2.5 核心概念词云
【词云数据统计】
- 词云术语总数:20个
- 加权总频次:344.5次
【可视化图表】

| 排名 | 术语 | 加权频次 |
|---|---|---|
| 1 | 电力 | 59.9 |
| 2 | 新能源 | 36.0 |
| 3 | 新能源发电 | 30.5 |
| 4 | 能源开发 | 22.0 |
| 5 | 低碳 | 18.2 |
| 6 | 绿色发展 | 17.8 |
| 7 | 互补 | 17.0 |
| 8 | 光伏 | 16.5 |
| 9 | 风电 | 15.8 |
| 10 | 电网规划 | 14.4 |
【图表评论】
词云图就像是一片五彩斑斓的术语花海🌸,通过加权频次直观呈现了文档的核心概念体系,美极了!
- 图中包含 20 个术语花朵,加权总频次达 344.5 次,真是繁花似锦呀!
- 排名前五的术语大明星分别为:“电力”(59.9 次)、“新能源”(36.0 次)、“新能源发电”(30.5 次)、“能源开发”(22.0 次)和“低碳”(18.2 次)。这些术语的字号最大、位置最显眼,构成了研究的核心概念群,就像花园里最盛开的几朵牡丹🌺。
- 从词云的整体分布来看,术语按照重要程度由大到小、由中心向四周排列,形成了层次分明的视觉结构,就像涟漪一样扩散开来🌊。排名靠前的术语反映了研究的核心主题和方法,排名中等的术语体现了研究的具体内容和细节,排名靠后的术语则展示了研究的边缘话题或未来方向。词云图不仅总结了全文的关键概念,也为读者快速把握研究要点提供了直观的视觉引导,是理解文档内容的重要辅助工具,简直太贴心啦!💖
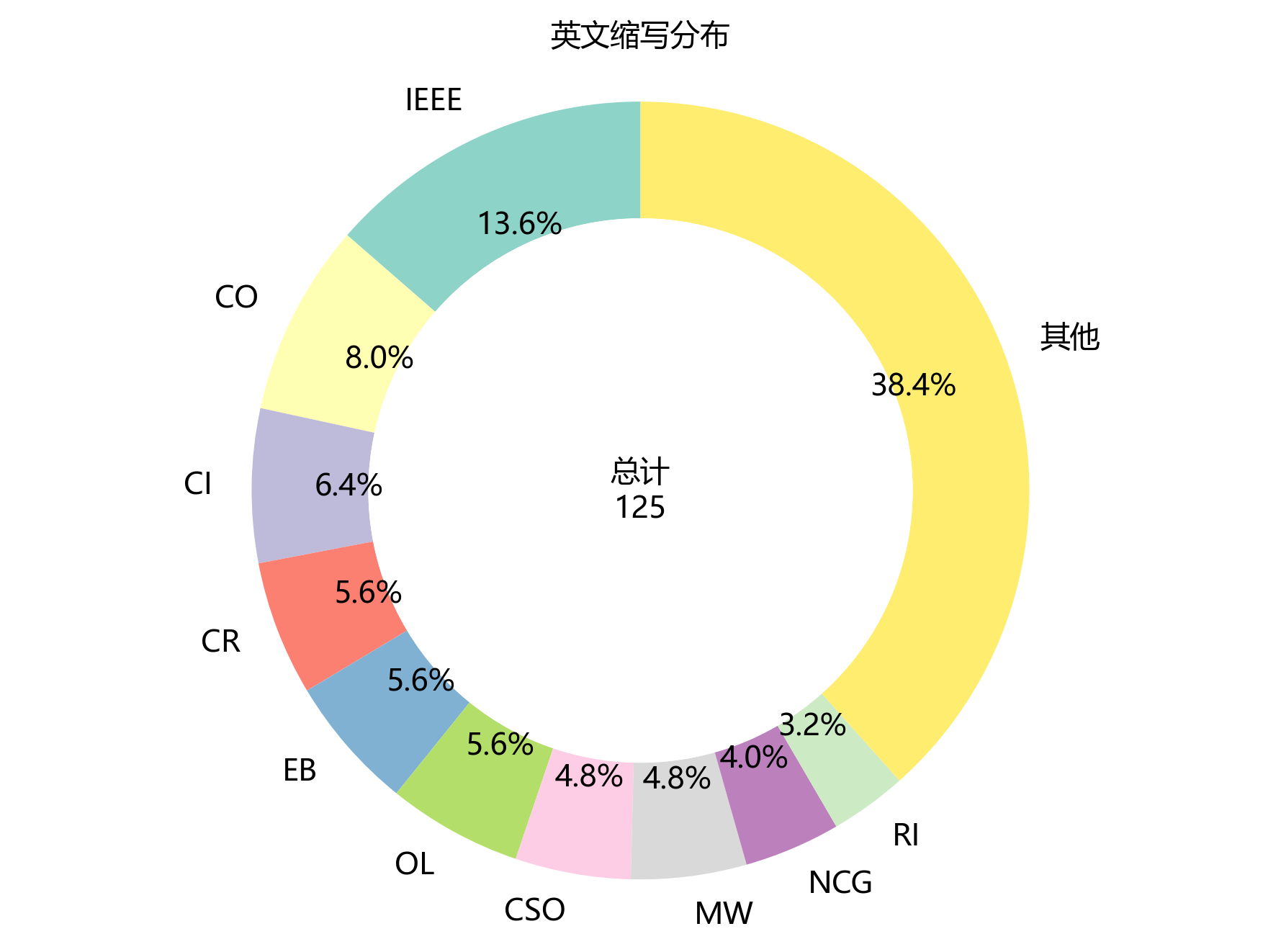
2.6 英文缩写分布
【缩写统计】
- 缩写总数:30个
- 缩写总频次:125次
- 高频缩写 Top 5:
- IEEE:17次
- CO:10次
- CI:8次
- CR:7次
- EB:7次
- 前5缩写累计占比:39.2%
【可视化图表】
| 排名 | 缩写 | 频次 |
|---|---|---|
| 1 | IEEE | 17 |
| 2 | CO | 10 |
| 3 | CI | 8 |
| 4 | CR | 7 |
| 5 | EB | 7 |
| 6 | OL | 7 |
| 7 | CSO | 6 |
| 8 | MW | 6 |
| 9 | NCG | 5 |
| 10 | RI | 4 |
| 前10累计 | 77 |
【图表评论】
环形图像是一个装满了英文缩写糖果的罐子🍬,展示了它们在文档中的分布情况。
- 文档中共出现 30 个不同的英文缩写小精灵,总频次达 125 次,真是热闹非凡!
- 排名前五的缩写明星分别为:“IEEE”(17 次)、“CO”(10 次)、“CI”(8 次)、“CR”(7 次)和“EB”(7 次),前5个缩写累计占比达 39.2 %,呈现出超高的集中度,它们是罐子里最受欢迎的口味哦!😋
- 从缩写的类型来看,主要包括期刊名称缩写(如“IEEE”)、作者姓名缩写(如“CO”)、技术术语缩写(如“CI”)和评价指标缩写(如“CR”)等,种类丰富多样!
- 这些缩写的高频出现,反映了文档引用了大量该领域的经典文献,采用了通用的技术术语和评价标准,体现了研究的规范性和专业性,就像是一位穿着得体、举止优雅的学者🎓。缩写的分布特征也为读者理解该领域的学术交流习惯提供了参考,真的是很有帮助呢!📖
三、原文章节举例
3.1.2 水力资源
青海省深处内陆高原,地势高耸,地形复杂,加之幅员辽阔,自然条件相差极大,受地形、地质、气候影响,省内河流在地区分布上极不均匀,东部、南部由于气候多雨,水系发达,河流密集,西北部内陆气候干旱少雨,河流密集,全省集水面积在 500km2500\mathrm{km}^2500km2 以上的河流271条,水力资源丰富。
根据青海省水力资源勘察成果统计,全省理论蕴藏量在10MW以上的干支流共计108条,理论蕴藏量21870MW,居全国第五。省内流域分为黄河流域、长江流域、澜沧江流域和内陆河流域四大流域区。全省地势东高西低,水力资源大多分布在东南部的外流水系河流上,占全省水力资源总量的 90%90\%90% 以上。黄河干流在青海境内全长 1663km1663\mathrm{km}1663km ,天然落差 2932.5m2932.5\mathrm{m}2932.5m ,理论蕴藏量13956.9MW,其中干流蕴藏量为11310.3MW,支流蕴藏量为2646.6MW。长江干流在青海境内全长 1205.7km1205.7\mathrm{km}1205.7km ,河道天然落差 2145m2145\mathrm{m}2145m ,理论蕴藏量4444.1MW,其中干流蕴藏量为4026.7MW,一级支流雅砻江水系蕴藏量为65MW,二级支流大渡河水系蕴藏量为352MW。澜沧江流域水能资源理论蕴藏量1948.9MW,干流蕴藏量785.5MW,一级支流子曲蕴藏量为345.0MW,一级支流吉曲蕴藏量为473.2MW。内陆河流域水能资源理论蕴藏量1523.9MW,分布在柴达木、青海湖、祁连山、可可西里四个水系中。
青海水资源分布如图3-1所示。
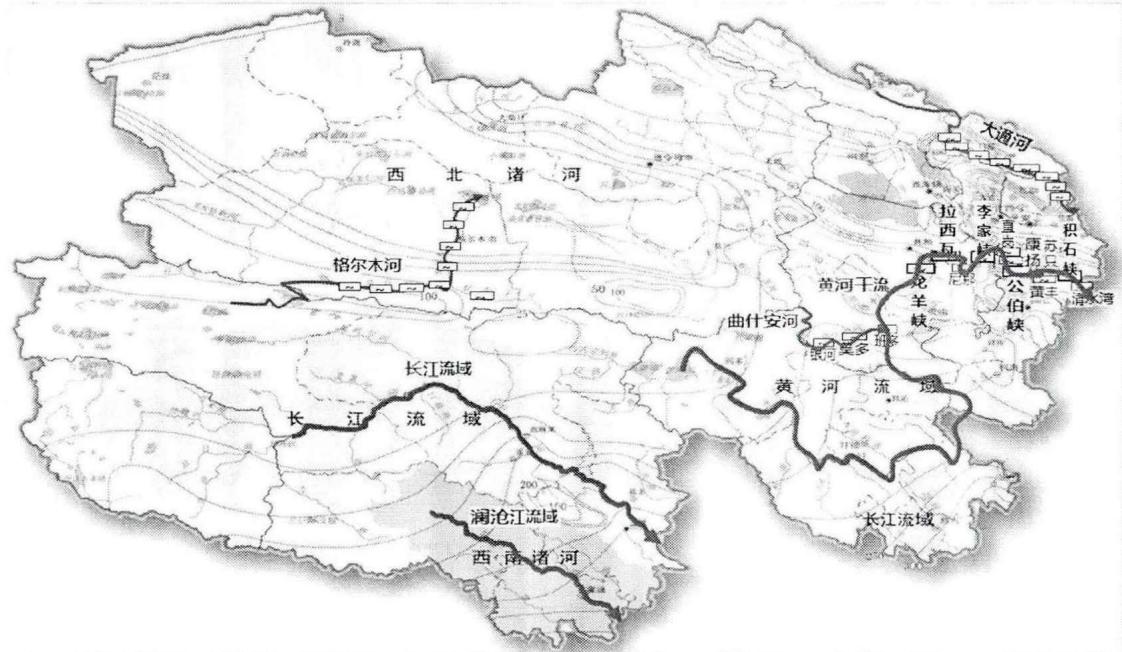
注:来源于青海省水力资源勘察成果统计。
图3-1 青海水资源分布图
Fig.3-1 Distribution map of water resources in Qinghai
四、原文章节举例
4.2.5 综合最优组合模型构建及预测
综合最优组合预测是将几组拟合效果良好的优选组合预测模型再次进行权重赋值,形成一组新的组合概率,成为统计意义上的最优组合概率,由此形成的综合预测模型成为综合最优组合预测模型[166]。
设有优选组合模型有 ppp 个,每个优选组合模型对应 qqq 个单一预测模型,假设第 jjj 个组合预测模型所对应的 qqq 个单一预测模型概率为 ω1j,ω2j,…,ωqj\omega_{1}^{j},\omega_{2}^{j},\dots ,\omega_{q}^{j}ω1j,ω2j,…,ωqj ,设每个组合预测模型引入的权重系数为 δj\delta^jδj ,形成表4-8所示。
表 4-8 综合最优组合预测模型组成表
Table 4-8 Comprehensive optimal combination forecasting model composition table
| 组合预测模型序号 | 组合预测模型权重 | 该组合预测模型对应的单一预测模型权重 | 满足条件 |
| 1 | δ1 | ω1(1), ω2(1), ..., ωq(1) | ∑k=1qωk(1)=1 |
| 2 | δ2 | ω1(2), ω2(2), ..., ωq(2) | ∑k=1qωk(2)=1 |
| ... | ... | ... | ... |
| j | δj | ω1(j), ω2(j), ..., ωq(j) | ∑k=1qωk(j)=1 |
| ... | ... | ... | ... |
| 0 | |||
| (表示综合最优组合预测模型) | ∑p j=1δj=1 | ω1(0), ω2(0), ..., ωq(0) | ∑k=1qωk(0)=1 |
如表4-8,序号为0的行形成综合最优组合预测模型,其权重赋值(或组合概率系数)为 ω1(0),ω2(0),…,ωq(0)\omega_{1}^{(0)},\omega_{2}^{(0)},\dots ,\omega_{q}^{(0)}ω1(0),ω2(0),…,ωq(0) ,其中:
ωk(0)=∑j=1pδ(j)ωkj(4-39) \omega_ {k} ^ {(0)} = \sum_ {j = 1} ^ {p} \delta^ {(j)} \omega_ {k} ^ {j} \tag {4-39} ωk(0)=j=1∑pδ(j)ωkj(4-39)
以4.2.4节的两组优选组合预测模型为基础,通过对等权平均组合模型和方差—协方差组合模型进行组合概率赋值,根据表4-8及式(4-39)可计算:
δ1=0.47096 \delta^ {1} = 0. 4 7 0 9 6 δ1=0.47096
δ2=0.52904 \delta^ {2} = 0. 5 2 9 0 4 δ2=0.52904
根据计算的最优组合概率系数,计算综合最优组合预测结果如表4-9所示。
表 4-9 基于综合最优组合模型的预测值相对误差分析
Table 4-9 Relative error analysis of prediction value based on comprehensive optimal combination model
单位:亿千瓦时
| 年份 | 用电量实际值 | 等权平均组合预测用电量值 | 方差-协方差组合预测用电量值 | 综合最优组合预测用电量值 | 相对误差 |
| 2010年 | 446.83 | 456.78 | 464.26 | 460.74 | -3.11% |
| 2011年 | 560.68 | 560.20 | 567.63 | 564.13 | -0.62% |
| 2012年 | 602.23 | 604.92 | 605.07 | 605.00 | -0.46% |
| 2013年 | 676.21 | 662.09 | 661.50 | 661.78 | 2.13% |
| 2014年 | 723.21 | 694.98 | 694.73 | 694.85 | 2.72% |
| 2015年 | 658.01 | 665.81 | 661.75 | 663.66 | -0.86% |
| 2016年 | 637.51 | 679.67 | 663.88 | 668.26 | -3.72% |
| 2017年 | 687.01 | 666.59 | 669.51 | 668.14 | 2.65% |
根据表4-9,采用综合最优组合模型对2010-2017年社会用电量进行预测分析,可计算各年的其预测值与实际值的平均相对误差绝对值为 2.03%2.03\%2.03% ,较4.2.4节两个优选组合模型预测精度又有明显提升,预测效果更加优良。
采用综合最优组合模型的预测值与实际值拟合比较如图4-7所示。
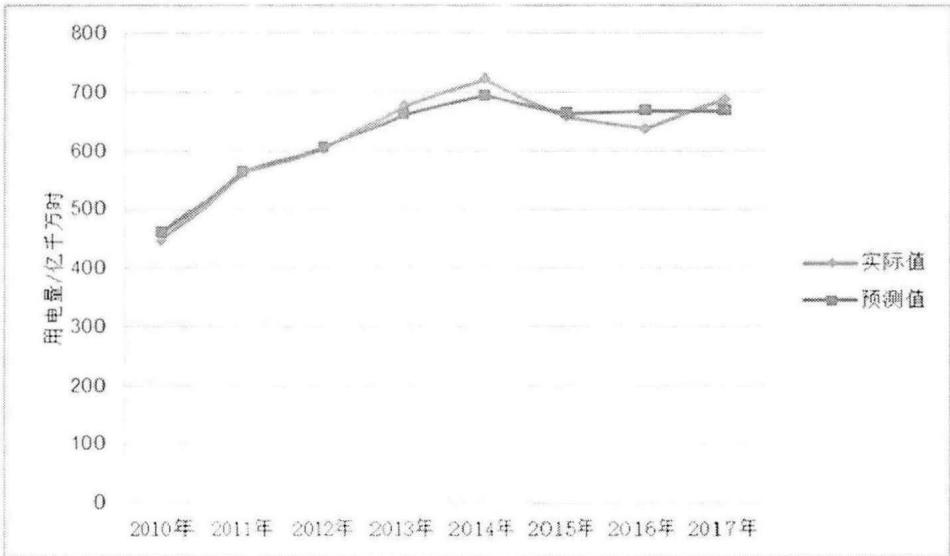
图4-7基于综合最优组合模型的预测值与实际值拟合比较曲线
Fig.4-7 Fitting comparison curve of predicted value and actual value based on comprehensive optimal combination model
将上述采用单一模型(二元线性回归、灰色)、优选组合模型(EW方法和MV方法)及综合最优组合模型的预测情况进行比较分析,综合最优组合模型的预测精度明显优于其他几种模型,具体如表4-10所示。
表 4-10 五种模型预测值的平均相对误差绝对值比较
Table 4-10 Comparison of the mean relative error absolute values of the predicted values of the five models
| 类型 | 单一预测模型 | 组合预测模型 | ||
| 模型名称 | 预测误差(平均相对误差绝对值) | 模型名称 | 预测误差(平均相对误差绝对值) | |
| 1 | 二元线性回归模型 | 4.26% | 等权平均组合 | 2.44% |
| 2 | 灰色模型 | 3.58% | 方差—协方差组合 | 2.37% |
| 3 | / | / | 综合最优组合 | 2.03% |
综合最优组合模型开展预测具有很高的安全系数和可操作性,在工程理论和工程应用方面都有较高价值。
基于该模型对青海2019-2025年社会用电量进行预测,相关典型年的预测结果如表4-11所示。
表 4-11 基于综合最优组合模型的青海 2019-2025 年社会用电量预测
Table 4-11 Prediction of social power consumption in Qinghai from 2019 to 2025 based on the comprehensive optimal combination model
单位:亿千瓦时
| 年份 | 二元线性回归法预测值 | 灰色法预测值 | 等权平均组合预测值 | 方差-协方差组合预测值 | 综合最优组合预测值 |
| 2019 | 743.34 | 772.81 | 796.72 | 761.55 | -778.11 |
| 2020 | 779.38 | 807.64 | 833.89 | 796.84 | 814.29 |
| 2023 | 834.25 | 856.58 | 888.24 | 848.05 | 866.98 |
| 2025 | 869.59 | 887.43 | 922.88 | 880.62 | 900.52 |
根据表4-11,青海2019年社会用电量为778.11亿千瓦时,到2020年达到814.29亿千瓦时,至2023年达到866.98亿千瓦时,至2025年达到900.52亿千瓦时,十四五末青海社会用电量将突破900亿大关。
五、总结
本报告对《青海电网绿色低碳发展规划优化模型及管理研究》进行了一次超级系统的专业术语统计与分析大探险!🗺️
- 文档总字符数 238556,中文字符 95645 个,英文字词 16330 个,共提取专业术语 2013 个,收获满满!🎒
- 高频术语“电力”(599 次)、“新能源”(360 次)等构成了研究的核心概念体系,它们是整篇文档的灵魂人物哦!🌟
- 文档涉及 6 个研究领域,主要集中在 环境保护(1696次)、可再生能源(1692次)、气候变化(1678次),体现了多学科交叉的研究特点,就像是一个多元化的学术游乐园🎡。
- 术语共现网络包含 10 个节点和 12 条边,最强关联对“电力”与“电力负荷”共现 177 次,形成了以“电力”为中心的术语聚类,关系网超级紧密!🕸️
- 英文缩写共出现 30 个,总频次 125 次,前五缩写“IEEE”(17 次)等累计占比 39.2 %,反映了文档引用的经典文献和技术标准,真是博学多才呀!📚 综上,本报告通过多维度术语统计,全面揭示了文档的知识结构和研究焦点,就像是为文档画了一幅清晰的肖像画🎨,让大家一眼就能看懂它的奥秘!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)