因果模型之如何找到合适的Confounding项集合,并利用贝叶斯公式对ATE进行识别(part1)
提示:因果模型
因果模型
- Part1:如何找到合适的 C o n f o u n d i n g Confounding Confounding项集合,并利用贝叶斯公式对 A T E ATE ATE进行识别
-
- 因果机制的底层支撑及其推广—— M o d u l a r i t y Modularity Modularity假设与截断因子分解
-
- M o d u l a r i t y Modularity Modularity假设:对变量进行干预时,只会修改被干预变量本身的生成机制,其他变量的条件分布保持不变。
- 基于 M o d u l a r i t y Modularity Modularity假设,我们可以把单个 t r e a t m e n t treatment treatment T T T的干预,推广到整个干预集合,得到截断因子分解( T r u n c a t e d Truncated Truncated F a c t o r i z a t i o n Factorization Factorization)
- 将单一干预多 C o n f o u n d i n g Confounding Confounding项分布转化成观测数据里的可计算形式 P ( y ∣ d o ( T = t ) ) = ∑ i k P ( y ∣ t , w i ) p ( w i ) P(y|do(T=t))=\sum_{i}^{k}P(y|t,w_i)p(w_i) P(y∣do(T=t))=∑ikP(y∣t,wi)p(wi)
- 将多干预多 C o n f o u n d i n g Confounding Confounding项分布转化成观测数据里的可计算形式 P ( y ∣ d o ( S ) ) = ∑ i k P ( y ∣ s , w i ) p ( w i ) P(y|do(S))=\sum_{i}^{k}P(y|s,w_i)p(w_i) P(y∣do(S))=∑ikP(y∣s,wi)p(wi)
- 如何确定 C o n f o u n d i n g Confounding Confounding项集合——后门准则
- Part2:结构因果模型 S C M SCM SCM——用数学表达式描述因果图(未完待续...)
Part1:如何找到合适的 C o n f o u n d i n g Confounding Confounding项集合,并利用贝叶斯公式对 A T E ATE ATE进行识别
我们的核心目标:识别平均处理效应ATE,即:
A T E = E [ Y ( 1 ) − Y ( 0 ) ] = E [ Y ( 1 ) ] − E [ Y ( 0 ) ] ATE=E[Y(1)-Y(0)]=E[Y(1)]-E[Y(0)] ATE=E[Y(1)−Y(0)]=E[Y(1)]−E[Y(0)]
这里必须明确: Y ( t ) Y(t) Y(t)是在 d o ( T = t ) do(T=t) do(T=t)条件下的干预结果。为了对 A T E ATE ATE进行识别必须先对干预分布进行定义。因此,对干预分布定义为:
P ( Y ( t ) = y ) = P ( Y = y ∣ d o ( T = t ) ) = P ( y ∣ d o ( t ) ) P(Y(t)=y)=P(Y=y|do(T=t))=P(y|do(t)) P(Y(t)=y)=P(Y=y∣do(T=t))=P(y∣do(t))
我们先把 A T E ATE ATE展开成干预分布的期望差:
A T E = E [ Y ( 1 ) − Y ( 0 ) ] = E [ Y ( 1 ) ] − E [ Y ( 0 ) ] = E [ Y ∣ d o ( T = 1 ) ] − E [ Y ∣ d o ( T = 0 ) ] ATE=E[Y(1)-Y(0)]=E[Y(1)]-E[Y(0)]=E[Y|do(T=1)]-E[Y|do(T=0)] ATE=E[Y(1)−Y(0)]=E[Y(1)]−E[Y(0)]=E[Y∣do(T=1)]−E[Y∣do(T=0)]
我们现在的任务是需要将干预分布 P ( y ∣ d o ( T = t ) ) P(y|do(T=t)) P(y∣do(T=t))转化成观测数据里的可计算形式。
因果机制的底层支撑及其推广—— M o d u l a r i t y Modularity Modularity假设与截断因子分解
要得到干预分布,首先要知道它的因果机制。其中, M o d u l a r i t y Modularity Modularity假设(模块化假设)是该因果机制的基础。
M o d u l a r i t y Modularity Modularity假设:对变量进行干预时,只会修改被干预变量本身的生成机制,其他变量的条件分布保持不变。
如果我们对集合S内所有的元素进行干预,即将他们的生成设为常数,对于所有的个体 i i i我们有:
1、如果 i ∉ S , P ( x i ∣ p a i ) i\notin S,P(x_{i}|pa_{i}) i∈/S,P(xi∣pai)保持不变。
2、如果 i ∈ S i\in S i∈S,如果 x i x_i xi与干预情况一致,则: P ( x i ∣ p a i ) = 1 P(x_{i}|pa_{i})=1 P(xi∣pai)=1;如果 x i x_i xi不与干预结果一致,则: P ( x i ∣ p a i ) = 0 P(x_{i}|pa_{i})=0 P(xi∣pai)=0
这意味着在因果推断过程中,我们假设干预是局部的——对某个变量的干预在因果图中只会影响生成该变量的路径(也即:指向该变量的路径)。更数学化的表达是我们将 P ( x i ∣ p a i ) P(x_{i}|pa_{i}) P(xi∣pai)设为1/0;更生动化的表达是我们将生成 x i x_i xi的过程设为一个不变量/常量,这意味着该过程不再有变化,或者说该过程被阻断( b l o c k block block)了。此时,我们在因果图中可以将从 p a i pa_i pai到 x i x_i xi的有向路径移除了。
我们重新审视这一过程会发现,在干预前后,其因果图的变化仅仅是将干预前的图中生成干预变量的有向路径移除出去。因此不同的干预状况(包括不干预情况)的因果图可以共用一张底图。这正是操纵图(manipulated graph)的核心思想。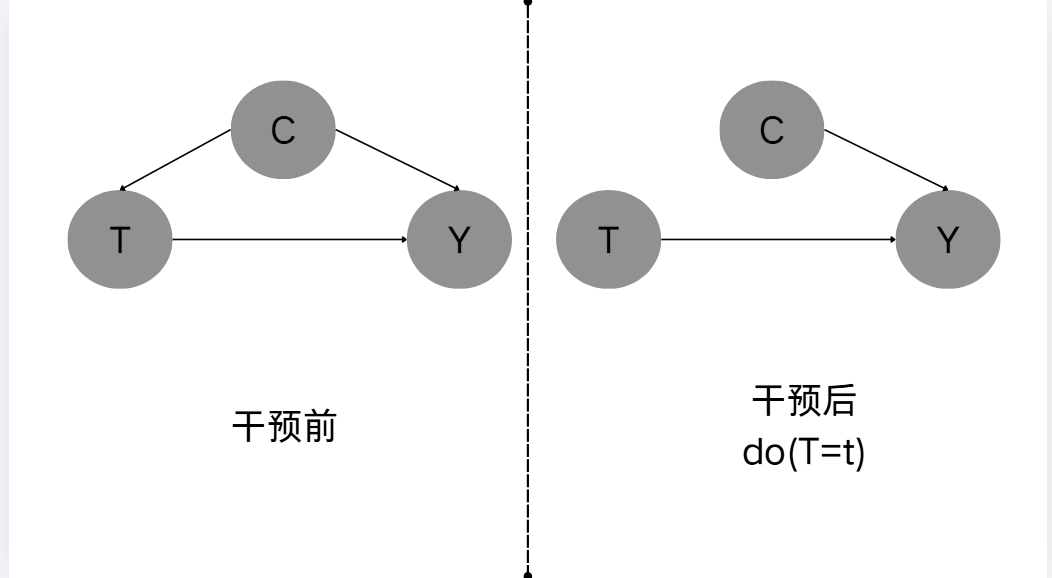
干预前后因果图如上图所示,右侧即位操纵图(manipulated graph)
这个过程与我们之前探讨的 c o n d i t i o n i n g conditioning conditioning条件化过程似乎有些相似————都是 b l o c k block block阻断掉某个路径。但仔细观察,我们不难发现有两大不同。
-
试验/观测对象不同。干预的试验对象是全体集合,条件化的观测对象是符合该条件的真子集。
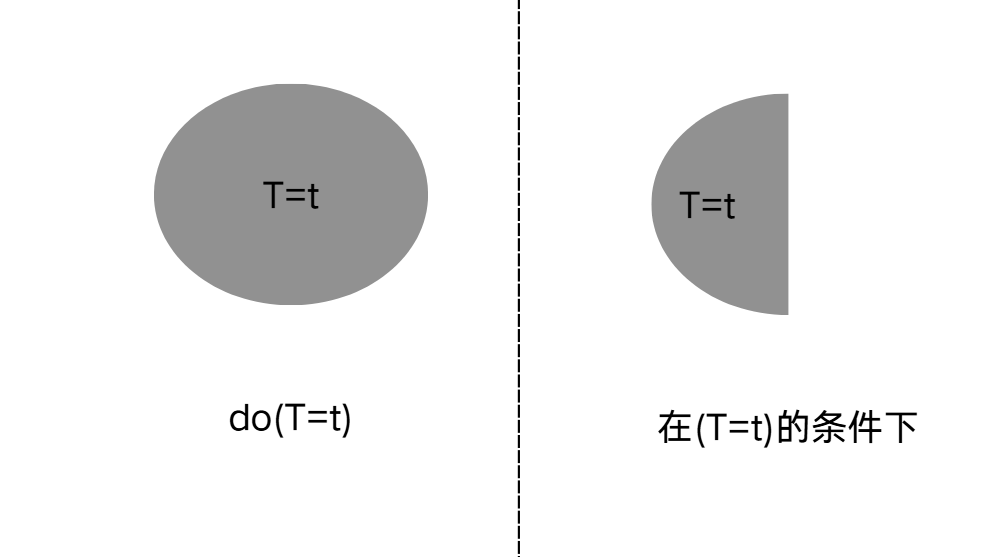
-
b l o c k block block阻断路径不同/ b l o c k block block阻断原理不同。在干预的情况下,是强制所有个体在的某一变量全部相同,那么原本影响该变量的因素将丝毫不起任何作用,此时是生成该变量的路径被 b l o c k block block阻断掉。而若是在某变量条件的情况下,我们只是对某变量符合该条件的个体进行观察。在这个真子集内部,由该变量导致的结果变量是一致的,也就是说在此真子集内条件变量产生的影响是常数/不变量,那么在量化的过程中是可以忽略的,因此,被 b l o c k block block阻断的路径是条件变量的影响路径。
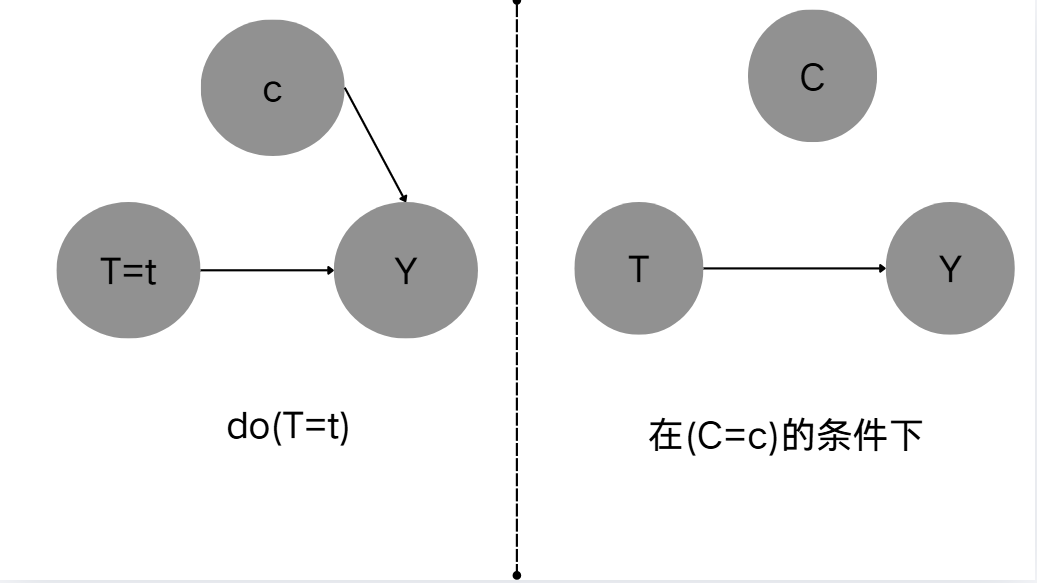
条件化分析
为了更好说明conditioning和干预的bock原理不同,我们用服用降血压药和心脏病的因果关系为例:
假设
- T:是否服用降血压药(是/否)
- M:血压水平(正常/非正常)
- Y:心脏病风险(高/低)
- W:年龄(青年/老年)
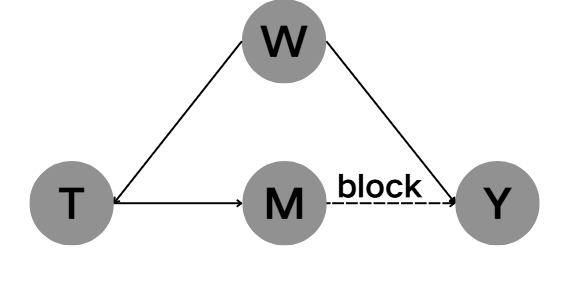
(图 1)
在我们在血压正常 M = 1 M=1 M=1条件下:
- 吃药的人,因为药物作用血压降到了正常;
- 没吃药的人,本身血压就正常;
在这个 “血压都正常” 的群体里,吃药与否对心脏病风险的差异就消失了 —— 因为中间的血压变量已经被固定,无法再传递药物的保护效应。因此,从M到Y的路径被 b l o c k block block阻断掉了,进而导致从T到Y的因果联系彻底断裂。
基于 M o d u l a r i t y Modularity Modularity假设,我们可以把单个 t r e a t m e n t treatment treatment T T T的干预,推广到整个干预集合,得到截断因子分解( T r u n c a t e d Truncated Truncated F a c t o r i z a t i o n Factorization Factorization)
根据有向无环图 D A G DAG DAG的性质——任何有向无环图至少有一个入度为 0 的顶点。(证明:反证。假设所有顶点的入度都 ≥ 1。从任意顶点出发,反复沿反向边走(即选择指向当前顶点的任意前驱)。由于每个顶点都有前驱,这个过程可以无限继续。但因为顶点数有限,一定会走到一个重复访问的顶点,从而形成一个有向环,与 DAG 假设矛盾。因此,至少存在一个入度为 0 的顶点。)证明一个非常经典的图论定理——有向无环图(DAG)一定存在拓扑序。
归纳法证明如下:
- 当图只有一个顶点时,显然成立。
- 假设对于任意含有 n−1 个顶点的 DAG,算法都能正确输出拓扑序。
- 对于含 n 个顶点的 DAG,取一个入度为 0 的顶点 u(存在性已证)。将 u 放在拓扑序的第一个位置。删除 u 及其出边后,剩余的图仍是无环的(因为删除顶点和边不会创造环)。由归纳假设,剩余图存在拓扑序 ( v 2 , v 3 , . . . v n ) (v_2,v_3,...v_n) (v2,v3,...vn) 。由于原图中任何从 u 出发的边都指向剩余图中的顶点,因此 ,u 排在所有后继之前。最终序列 ( u , v 2 , v 3 , . . . v n ) (u,v_2,v_3,...v_n) (u,v2,v3,...vn)就是原图的拓扑序。
基于有向无环图(DAG)一定存在拓扑序,构造一个DAG G中的拓扑序列如下: ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)
根据贝叶斯公式可将 P ( x 1 , x 2 , . . . , x n ) P(x_1,x_2,...,x_n) P(x1,x2,...,xn)展开得:
P ( x 1 , x 2 , . . . , x n ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) . . . P ( x n ∣ x 1 , x 2 , . . . , x n − 1 ) P(x_1,x_2,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_1,x_2,...,x_{n-1}) P(x1,x2,...,xn)=P(x1)P(x2∣x1)P(x3∣x1,x2)...P(xn∣x1,x2,...,xn−1)
其中 x 1 x_1 x1无入边,构造 P ( x k ∣ X k − 1 ) 中集合 P(x_k|X_{k-1})中集合 P(xk∣Xk−1)中集合X_{k-1}$即为拓扑序列中 x k x_k xk 之前节点集合。因此,根据拓扑序列, X k − 1 X_{k-1} Xk−1必包含 x k x_k xk的全部父节点以一些非父节点的非后代节点。
则根据 M a r k o v Markov Markov原理——在父节点的条件下, x i x_i xi独立于所有非后代节点,则得到贝叶斯网络分解:
P ( x 1 , x 2 , . . . , x n ) = ∏ i P ( x i ∣ p a i ) P(x_1,x_2,...,x_n)=\prod_{i}P(x_{i}|pa_{i}) P(x1,x2,...,xn)=∏iP(xi∣pai)
综上所述,由于 DAG 的无回路性质,拓扑排序必然存在,因此上述化简过程在贝叶斯网络中始终成立。
考虑单一干预变量时,在 M o d u l a r i t y Modularity Modularity假设下:
1、当 T T T与干预情况一致, P ( x 1 , x 2 , . . . , x n ∣ d o ( T = t ) ) = ∏ i ∉ T P ( x i ∣ p a i ) P(x_1,x_2,...,x_n|do(T=t))=\prod_{i\notin T}P(x_{i}|pa_{i}) P(x1,x2,...,xn∣do(T=t))=∏i∈/TP(xi∣pai)
2、当 T T T不与干预情况一致, P ( x 1 , x 2 , . . . , x n ∣ d o ( T = t ) ) = 0 P(x_1,x_2,...,x_n|do(T=t))=0 P(x1,x2,...,xn∣do(T=t))=0
由于 M o d u l a r i t y Modularity Modularity假设中蕴含的局部性原理,我们可以将单一干预源推广至多干预源集合中。
考虑多干预源集合时,在 M o d u l a r i t y Modularity Modularity假设下,当对集合 S S S内的所有 t r e a t m e n t treatment treatment进行干预的条件下,若 x i ∈ S x_i\in S xi∈S且 x i x_i xi干预,则: P ( x i ∣ p a i ) = 1 P(x_i|pa_i)=1 P(xi∣pai)=1;若 x i ∉ S x_i\notin S xi∈/S时, P ( x i ∣ p a i ) P(x_i|pa_i) P(xi∣pai)保持不变。则:截断因子分解( T r u n c a t e d Truncated Truncated F a c t o r i z a t i o n Factorization Factorization)表示为:
1、若整体 X X X与干预情况保持一致,则: P ( x 1 , x 2 , . . . , x n ∣ d o ( S = s ) ) = ∏ i ∉ S P ( x i ∣ p a i ) P(x_1,x_2,...,x_n|do(S=s))=\prod_{i\notin S}P(x_{i}|pa_{i}) P(x1,x2,...,xn∣do(S=s))=∏i∈/SP(xi∣pai)
2、若整体 X X X不与干预情况保持一致,则: P ( x 1 , x 2 , . . . , x n ∣ d o ( S = s ) ) = 0 P(x_1,x_2,...,x_n|do(S=s))=0 P(x1,x2,...,xn∣do(S=s))=0
由上文分析可知,我们可知干预前与干预后的因果图只是发生生成干预变量路径的移除,因此其干预条件下的联合分布表现为仅仅发生某些 P ( x i ∣ p a i ) P(x_i|pa_i) P(xi∣pai)因子常数化,这就是截断的本质所在。
将单一干预多 C o n f o u n d i n g Confounding Confounding项分布转化成观测数据里的可计算形式 P ( y ∣ d o ( T = t ) ) = ∑ i k P ( y ∣ t , w i ) p ( w i ) P(y|do(T=t))=\sum_{i}^{k}P(y|t,w_i)p(w_i) P(y∣do(T=t))=∑ikP(y∣t,wi)p(wi)
假设处理的因果图如下: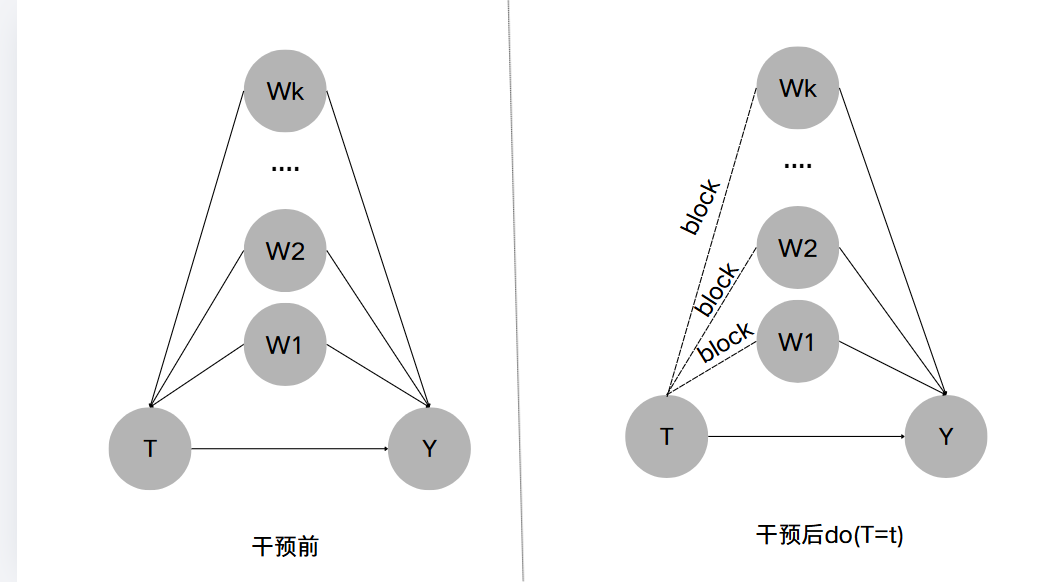
根据条件概率乘法原则可得: P ( y , w i ∣ d o ( t ) ) = P ( y ∣ d o ( t ) , w i ) ⋅ P ( w i ∣ d o ( t ) ) ( 1 ) P(y,w_i|do(t))=P(y|do(t),w_i)\cdot P(w_i|do(t))(1) P(y,wi∣do(t))=P(y∣do(t),wi)⋅P(wi∣do(t))(1)
对 w w w进行边缘求和可得到: P ( y ∣ d o ( t ) ) = ∑ i k P ( y , w i ∣ d o ( t ) ) ( 2 ) P(y|do(t))=\sum_{i}^{k}P(y,w_i|do(t))(2) P(y∣do(t))=∑ikP(y,wi∣do(t))(2)
( w 1 , w 2 , . . . , w k 是 W 的所有可能取值 w_1,w_2,...,w_k是W的所有可能取值 w1,w2,...,wk是W的所有可能取值)
由 ( 1 ) ( 2 ) (1)(2) (1)(2)得:
P ( y ∣ d o ( t ) ) = ∑ i k P ( y ∣ d o ( t ) , w i ) ⋅ P ( w i ∣ d o ( t ) ) ( 3 ) P(y|do(t))=\sum_{i}^{k}P(y|do(t),w_i)\cdot P(w_i|do(t))(3) P(y∣do(t))=∑ikP(y∣do(t),wi)⋅P(wi∣do(t))(3)
一、
由于所有 w w w阻断了所有从T到Y的后门路径(也即: W 满足后门准则),因此T不会对W进行干预,则:
∀ w i , P ( w i ∣ d o ( t ) ) = P ( w i ) ( 4 ) \forall w_i,P(w_i|do(t))=P(w_i)(4) ∀wi,P(wi∣do(t))=P(wi)(4)
二、
证明 P ( y ∣ d o ( t ) , w i ) = P ( y ∣ t , w i ) P(y|do(t),w_i)=P(y|t,w_i) P(y∣do(t),wi)=P(y∣t,wi)如下:
根据贝叶斯网络分解和 M o d u l a r i t y Modularity Modularity假设可得:
P ( y , w i ∣ d o ( t ) ) = P ( w i ) ⋅ P ( y ∣ t , w i ) ( 5 ) P(y,w_i|do(t))=P(w_i)\cdot P(y|t,w_i)(5) P(y,wi∣do(t))=P(wi)⋅P(y∣t,wi)(5)
根据 ( 1 ) ( 4 ) (1)(4) (1)(4)得:
P ( y , w i ∣ d o ( t ) ) = P ( y ∣ d o ( t ) , w i ) ⋅ P ( w i ) ( 6 ) P(y,w_i|do(t))=P(y|do(t),w_i)\cdot P(w_i)(6) P(y,wi∣do(t))=P(y∣do(t),wi)⋅P(wi)(6)
根据 ( 5 ) ( 6 ) (5)(6) (5)(6)得到:
P ( w i ) ⋅ P ( y ∣ w i , t ) = P ( y ∣ d o ( t ) , w i ) ⋅ P ( w i ) ( 7 ) P(w_i)\cdot P(y|w_i,t)=P(y|do(t),w_i)\cdot P(w_i)(7) P(wi)⋅P(y∣wi,t)=P(y∣do(t),wi)⋅P(wi)(7)
根据 p o s i t i v i t y positivity positivity原则可知: P ( w i ) > 0 ( 8 ) P(w_i)>0 (8) P(wi)>0(8)
由 ( 7 ) ( 8 ) (7)(8) (7)(8)可得:
P ( y ∣ w i , t ) = P ( y ∣ d o ( t ) , w i ) ( 9 ) P(y|w_i,t)=P(y|do(t),w_i)(9) P(y∣wi,t)=P(y∣do(t),wi)(9)
由 ( 3 ) ( 4 ) ( 5 ) (3)(4)(5) (3)(4)(5)可得:
P ( y ∣ d o ( t ) ) = ∑ i k P ( y ∣ t , w i ) ⋅ P ( w i ) ( 10 ) {P(y|do(t))=\sum_{i}^{k}P(y|t,w_i)\cdot P(w_i)}(10) P(y∣do(t))=∑ikP(y∣t,wi)⋅P(wi)(10)
在得到干预分布后,我们将目光转回到 A T E ATE ATE的识别上。
根据期望的定义可得:
E [ Y ∣ d o ( t ) ] = ∑ y y P ( y ∣ d o ( t ) ) ( 11 ) E[Y|do(t)]=\sum_{y}yP(y|do(t))(11) E[Y∣do(t)]=∑yyP(y∣do(t))(11)
由 ( 10 ) ( 11 ) (10)(11) (10)(11)得:
E [ Y ∣ d o ( t ) ] = ∑ y y ⋅ ( ∑ i k P ( y ∣ t , w i ) ⋅ P ( w i ) ) ( 12 ) E[Y|do(t)]=\sum_{y}y \cdot (\sum_{i}^{k}P(y|t,w_i)\cdot P(w_i))(12) E[Y∣do(t)]=∑yy⋅(∑ikP(y∣t,wi)⋅P(wi))(12)
交换求和次序可得:
E [ Y ∣ d o ( t ) ] = ∑ i k P ( w i ) ( ∑ y y ⋅ P ( y ∣ t , w i ) ) ( 13 ) E[Y|do(t)]=\sum_{i}^{k}P(w_i) (\sum_{y} y\cdot P(y|t,w_i))(13) E[Y∣do(t)]=∑ikP(wi)(∑yy⋅P(y∣t,wi))(13)
由期望的定义可知:
E [ Y ∣ d o ( t ) ] = ∑ i k P ( w i ) E [ Y ∣ t , w i ] ( 14 ) E[Y|do(t)]=\sum_{i}^{k}P(w_i) E[Y|t,w_i](14) E[Y∣do(t)]=∑ikP(wi)E[Y∣t,wi](14)
观察 E [ Y ∣ t , w i ] = ∑ y y ⋅ P ( y ∣ t , w i ) E[Y|t,w_i]=\sum_{y} y\cdot P(y|t,w_i) E[Y∣t,wi]=∑yy⋅P(y∣t,wi)。已知 t r e a t m e n t treatment treatment已经被固定且 y y y是观测数据不可改变,而改变 C o n f o u n d i n g Confounding Confounding项的划分,即可改变结果。因此, E [ Y ∣ t , w i ] E[Y|t,w_i] E[Y∣t,wi]是关于 w w w的函数。则:
E [ Y ∣ d o ( t ) ] = E w [ E ( Y ∣ t , w ) ] = E w E ( Y ∣ t , w ) ( 15 ) E[Y|do(t)]=E_{w}[E(Y|t,w)]=E_{w}E(Y|t,w)(15) E[Y∣do(t)]=Ew[E(Y∣t,w)]=EwE(Y∣t,w)(15)其中,第二个等式是由于期望的计算原则——先计算最右边再往左边。
当 t r e a t m e n t treatment treatment是二值便利时,则 A T E ATE ATE可以识别为:
A T E = E [ Y ( 1 ) ] − E [ Y ( 0 ) ] = E w E ( Y ∣ T = 1 , w ) − E w E ( Y ∣ T = 0 , w ) ( 16 ) ATE=E[Y(1)]-E[Y(0)]=E_wE(Y|T=1,w)-E_wE(Y|T=0,w)(16) ATE=E[Y(1)]−E[Y(0)]=EwE(Y∣T=1,w)−EwE(Y∣T=0,w)(16)
将多干预多 C o n f o u n d i n g Confounding Confounding项分布转化成观测数据里的可计算形式 P ( y ∣ d o ( S ) ) = ∑ i k P ( y ∣ s , w i ) p ( w i ) P(y|do(S))=\sum_{i}^{k}P(y|s,w_i)p(w_i) P(y∣do(S))=∑ikP(y∣s,wi)p(wi)
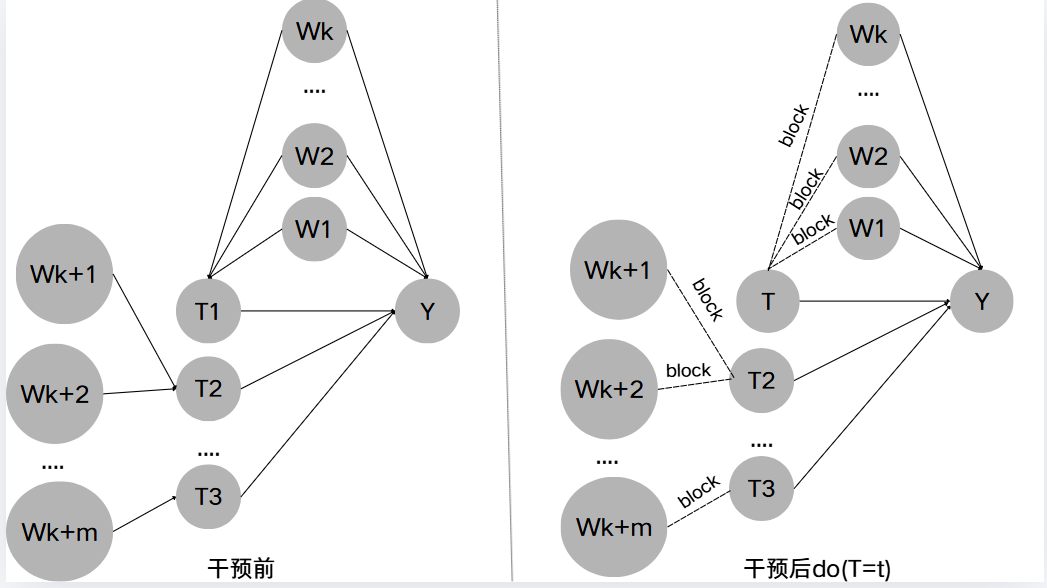
由 M o d u l a r i t y Modularity Modularity假设可轻松将 P ( y ∣ d o ( T = t ) ) = ∑ i k P ( y ∣ t , w i ) p ( w i ) P(y|do(T=t))=\sum_{i}^{k}P(y|t,w_i)p(w_i) P(y∣do(T=t))=∑ikP(y∣t,wi)p(wi)推广至 P ( y ∣ d o ( S ) ) = ∑ i k P ( y ∣ s , w i ) p ( w i ) P(y|do(S))=\sum_{i}^{k}P(y|s,w_i)p(w_i) P(y∣do(S))=∑ikP(y∣s,wi)p(wi)。因而:
E [ S ∣ d o ( s ) ] = E w E ( Y ∣ s , w ) ( 17 ) E[S|do(s)]=E_{w}E(Y|s,w)(17) E[S∣do(s)]=EwE(Y∣s,w)(17)
**至此,在已知 C o n f o u n d i n g Confounding Confounding项集合下,我们可知如何将 A T E ATE ATE识别为可观测数据分布上进行计算的方法。**接下来,我们需要如何确定 C o n f o u n d i n g Confounding Confounding项集合。
如何确定 C o n f o u n d i n g Confounding Confounding项集合——后门准则
观察前文我们对干预分布的推导,我们不难看出集合 W W W有两大特征:
- W W W阻断了从T到Y的所有后门路径。
后门路径定义如下:
T到Y的一条无向路径,如果满足:
1、路径中存在箭头指向T(表示有箭头"进入T",形成混杂)
2、不是T到Y的纯因果路径。(存在T-混杂变量-Y的非因果路径(无向路径))
则称为后门路径。 - 干预分布需要在 W W W的条件下。1)结合我们之前所学的知识点,当我们在对碰撞点 c o l l i d e r collider collider及其后代条件下时,本质上增加了从T到Y的非因果联系。因此,我们需要确保不要把碰撞点 c o l l i d e r collider collider及其后代包含进集合 W W W中。2)我们不可对在T到Y的因果联系链上的因素进行条件分布。因为一旦条件化,则会导致从T到Y的因果链断裂或减少。
当我们继续审视前文的推导过程,我们不难发现我们总结的集合 W W W两大特征是推导过程的隐含条件缺一不可。
1、阻断所有后门路径本质上是在保证干预后的因果图内只包含从T到Y的纯因果关系。
如何保证不遗漏任何后门路径的方法:枚举 T 与 Y 之间所有无向路径(排除纯因果路径,剩下的就是全部后门路径)。
2、避免碰撞点 c o l l i d e r collider collider及其后代包含进集合 W W W中本质上是避免在因果图中增加新的从T到Y非因果联系(相当于增加了好后门路径)。避免将T到Y的因果联系链上的因素纳入集合 W W W中本质上是避免从T到Y的因果链断裂或减少。
条件化错误
因果链断裂/减少(在下列所有因果图对M进行条件化):
(图 1)
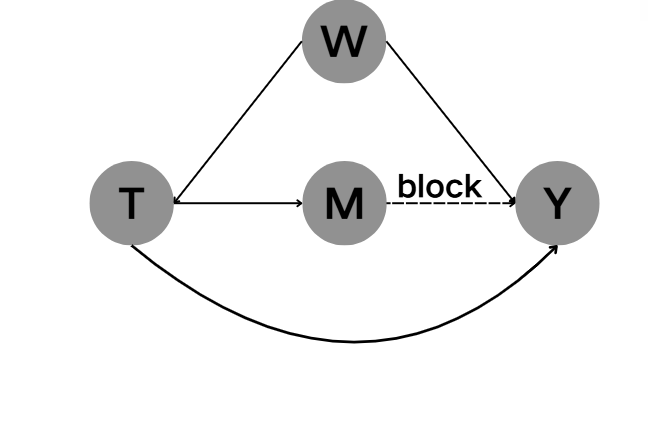
(图 2)
根据前文对 C o n d i t i o n i n g 的 b l o c k Conditioning的block Conditioning的block的解释,以上两张图中从M到Y的结果被阻断了。对于第一张图,则是从T到Y的因果链彻底断裂。对于第二张图,由于从T到Y的因果链不止一条,则是从T到Y的因果链减少。
增加了因果联系一(也可以人为增加了后门路径):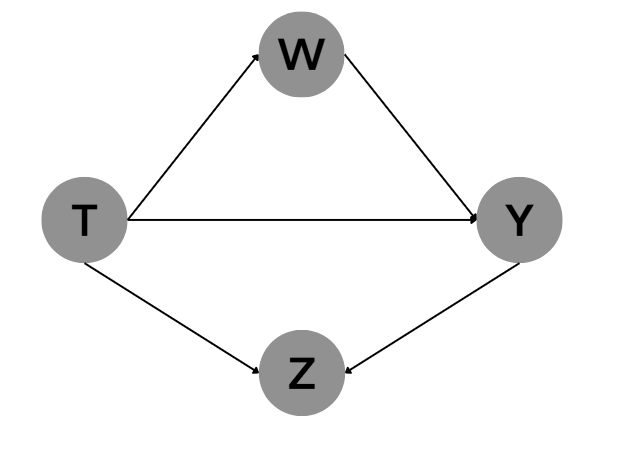
(图 3)
增加了因果联系二(也可以人为增加了后门路径):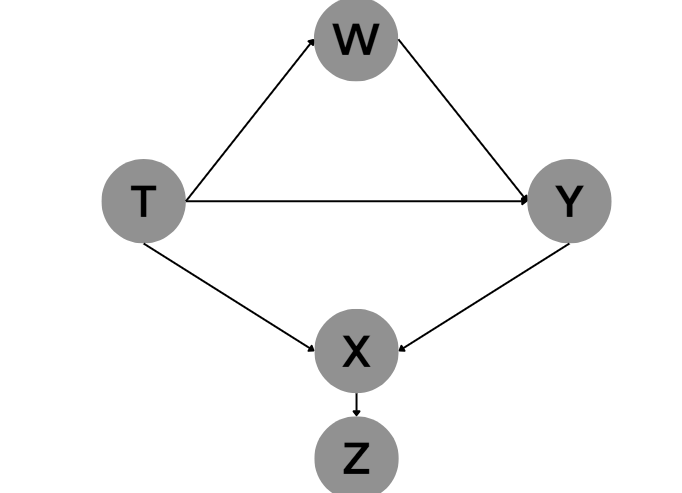
(图 4)
图3和图4,对Z进行条件化后,根据碰撞点原理,会增加从T到Y的非因果联系,影响从T到Y的 A T E ATE ATE的识别。
从上面四张图片不难看出, Z Z Z都有一个共同点就是:是T的后代。
开发后门路径错误
M − B i a s M-Bias M−Bias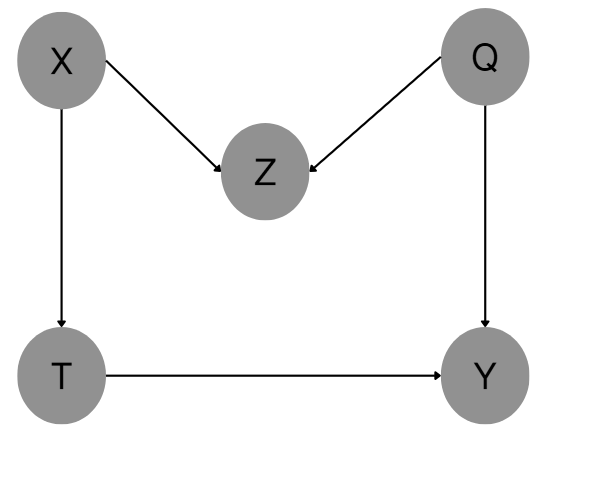
此时对Z进行条件话,相当于打开了从T到Y的后门路径。
从以上五张图可以总结出一个后门准则( B a c k d o o r Backdoor Backdoor C r i t e r i o n Criterion Criterion)
- W阻断所有后门路径
- W不包含T的任何后代
从前面分析我们不难看出该后门准则( B a c k d o o r Backdoor Backdoor C r i t e r i o n Criterion Criterion)是保证前文关于 A T E ATE ATE推导的充分条件。证明如下:
由于W阻断所有从T到Y的所有后门路径,因此可以说,W使得 T 和 Y 在所有后门路径上 d‑分离。又因为W 不包含 T 的后代,即避免了从T到Y因果链条的断裂/缺失,又避免对碰撞点条件化的过程中打开了新的后门路径。总而言之,W使得T到Y的所有后门路径上d-分离的同时保证了T到Y因果联系的完整性。使得在进行概率计算的时候在保留因果效应的同时截断非因果联系
当后门路径存在时,后门准则提供了一种简单、直观、可机械化执行的调整方法。具体地,后门调整公式( B a c k d o o r A d j u s t m e n t Backdoor Adjustment BackdoorAdjustment)为
P ( y ∣ d o ( t ) ) = ∑ w P ( y ∣ t , w ) P ( w ) P(y|do(t))=\sum_{w}P(y|t,w)P(w) P(y∣do(t))=∑wP(y∣t,w)P(w)
但是,即便因果图存在后门路径,仍可通过前门准则、工具变量等其他架构完成识别,并非必须依赖后门准则。
例如下图所示: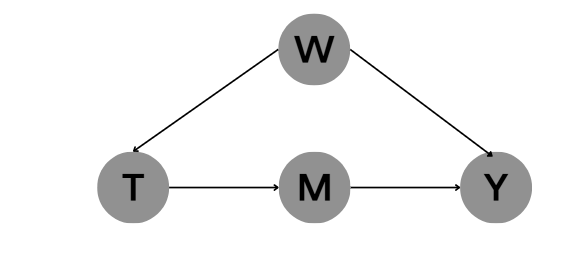
观察该因果图有一下几大特征:
- 从T到Y无直接因果路径(必须经过中介点M)
- 因果路径从T到M不存在后门路径。(注意:路径T-W-Y-M被碰撞点Y阻断。)
- 因果路径从M到Y存在后门路径:M-T-W-Y。此时,只要在T的条件下,即可以阻断该路径。
因此,即使不利用后门调整公式,我们也可以通过先识别T到M,再识别从M到Y的方式识别从T到Y的因果效应。
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( y ∣ m , t ′ ) P ( t ′ ) P(y|do(t))=\sum_{m}P(m|t)\sum_{t^{'}}P(y|m,t^{'})P(t^{'}) P(y∣do(t))=∑mP(m∣t)∑t′P(y∣m,t′)P(t′)
利用实际例子来演示后门调整公式
因果图如下所示: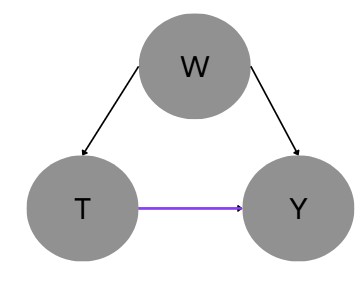
- W:天气(0=晴天,1=雨天)
- T:是否带伞(0=不带,1=带)
- Y:是否淋湿(0=未淋湿,1=淋湿)
观测数据如下所示;
| W | T | Y | 概率 |
|---|---|---|---|
| 0 | 0 | 0 | 0.40 |
| 0 | 0 | 1 | 0.10 |
| 0 | 1 | 0 | 0.05 |
| 0 | 1 | 1 | 0.05 |
| 1 | 0 | 0 | 0.05 |
| 1 | 0 | 1 | 0.05 |
| 1 | 1 | 0 | 0.10 |
| 1 | 1 | 1 | 0.20 |
P ( w = 0 ) = 0.40 + 0.10 + 0.05 + 0.05 = 0.60 P(w=0)=0.40+0.10+0.05+0.05=0.60 P(w=0)=0.40+0.10+0.05+0.05=0.60
P ( w = 1 ) = 0.05 + 0.05 + 0.10 + 0.20 = 0.40 P(w=1)=0.05+0.05+0.10+0.20=0.40 P(w=1)=0.05+0.05+0.10+0.20=0.40
P ( Y = 1 ∣ T = 1 , W = 0 ) = 0.05 0.05 + 0.05 = 0.50 P(Y=1|T=1,W=0)=\frac{0.05}{0.05+0.05}=0.50 P(Y=1∣T=1,W=0)=0.05+0.050.05=0.50
E [ Y ∣ T = 1 , W = 0 ] = 0.50 E[Y|T=1,W=0]=0.50 E[Y∣T=1,W=0]=0.50
P ( Y = 1 ∣ T = 1 , W = 1 ) = 0.20 0.20 + 0.10 = 0.6667 P(Y=1|T=1,W=1)=\frac{0.20}{0.20+0.10}=0.6667 P(Y=1∣T=1,W=1)=0.20+0.100.20=0.6667
E [ Y ∣ T = 1 , W = 1 ] = 0.6667 E[Y|T=1,W=1]=0.6667 E[Y∣T=1,W=1]=0.6667
后门调整公式计算 E [ Y ∣ d o ( T = 1 ) ] E[Y|do(T=1)] E[Y∣do(T=1)]
E [ Y ∣ d o ( T = 1 ) ] = ∑ w P ( w ) ⋅ E [ Y ∣ T = 1 , w ] = P ( W = 0 ) ⋅ E [ Y ∣ T = 1 , W = 0 ] + P ( W = 1 ) ⋅ E [ Y ∣ T = 1 , W = 1 ] = 0.6 ⋅ 0.5 + 0.4 ⋅ 0.6667 = 0.5667 E[Y|do(T=1)]=\sum_{w}P(w)\cdot E[Y|T=1,w]=P(W=0)\cdot E[Y|T=1,W=0]+P(W=1)\cdot E[Y|T=1,W=1]=0.6\cdot 0.5+0.4\cdot 0.6667=0.5667 E[Y∣do(T=1)]=∑wP(w)⋅E[Y∣T=1,w]=P(W=0)⋅E[Y∣T=1,W=0]+P(W=1)⋅E[Y∣T=1,W=1]=0.6⋅0.5+0.4⋅0.6667=0.5667
对比未调整的观测均值(错误估计)
E [ Y ∣ T = 1 ] = 0.05 + 0.02 0.05 + 0.05 + 0.10 + 0.20 = 0.25 0.4 = 0.625 E[Y|T=1]=\frac{0.05+0.02}{0.05+0.05+0.10+0.20}=\frac{0.25}{0.4}=0.625 E[Y∣T=1]=0.05+0.05+0.10+0.200.05+0.02=0.40.25=0.625
Part2:结构因果模型 S C M SCM SCM——用数学表达式描述因果图(未完待续…)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)