《SRE:Google 运维解密》读书笔记27: 数据完整性 - 当“数据还在”不等于“用户信了”
作者: andylin02
学习章节:第26章 数据完整性:读写一致
关键词:数据完整性、软删除、备份恢复、早期预警、分级防护、用户信任、可访问性
一、引言:当“数据还在”不等于“用户信了”
在上一章(第25章),我们学习了Google如何构建大规模数据处理管道,让海量数据在多个阶段之间可靠流转。然而,数据能够流动只是基础——用户读到的是否就是他们刚刚写下的,才是数据系统真正的“灵魂拷问”。
当用户至上时,用户认为数据完整性是什么,数据完整性就是什么。
假设Gmail用户界面出现Bug,显示空邮箱的时间过长,即使实际上没有丢失任何数据,用户也会认为数据已经丢失。这不仅是技术问题,更是信任危机——外界会质疑Google作为数据管理者的能力,云计算的可行性也会受到威胁。
本章的核心命题正是:SRE如何在复杂多变的系统中,保障用户“读到”的数据与他们“写入”的数据保持完全一致,从而守护用户对系统的信任。
核心观点:数据完整性没有银弹。Google通过分级防护体系——软删除(短期)、备份恢复(中期)、早期预警(长期),假设每一个保护机制都可能在最不合适的时间失效,用多层独立手段构建数据安全的纵深防御。
二、核心观点速览
| 维度 | 核心要点 |
|---|---|
| 数据完整性的本质 | 用户认为它是什么,它就是什么——本质上是用户信任问题,而非纯技术指标 |
| Gmail事件的关键启示 | 4天是“过长”的数据不可用时间,24小时是更合理的恢复目标 |
| 数据完整性的双维度 | 可访问性 + 准确性——用户能访问数据 + 访问到的数据是正确的 |
| 数据丢失的五大类型 | 服务器硬件故障、软件Bug、人为操作错误、恶意攻击、外部环境灾难 |
| 分级防护体系 | 第一层:软删除/回收站;第二层:备份与恢复;第三层:早期预警 |
| 软删除的关键价值 | 从源头拦截误删除,在Google使用量最高的工具上全面实现 |
| 早期预警的核心机制 | 离线校验系统扫描历史数据,主动发现损坏和错乱 |
| 数据完整性的考核指标 | 恢复时间目标(RTO)、恢复点目标(RPO)、每日/每小时数据丢失量 |
| RTO与RPO的权衡 | 更短的RTO通常意味着更高的成本,需要在业务价值和成本之间找到平衡 |
| 复制≠备份 | 数据恢复计划不应该依赖于复制机制 |
三、详细内容拆解
3.1 什么是数据完整性:从用户视角出发
“数据完整性是衡量为用户提供适当水平服务所需的数据存储的可访问性和准确性的标准。”但这个定义还不够。
数据完整性的精确定义来自两个核心维度:
| 维度 | 含义 | 用户关心的问题 |
|---|---|---|
| 可访问性 | 用户的数据在需要时能够被访问 | “我的邮件/照片/文件在哪里?” |
| 准确性 | 用户读到的数据与他们写入的数据完全一致 | “我的数据是正确的吗?” |
这个定义之所以“不够”,是因为它忽略了用户对系统的感知。正如Gmail例子所示,用户感知的完整性比客观的完整性更重要。如果用户认为数据已经丢失,即使技术上数据完好无损,系统的声誉也会受损。
实际可量化的SLO要求:结合用户对云服务时效性的真实预期(如2011年Gmail事件的四天不可用窗口),合理的数据恢复SLO起点应当设定在24小时内。
3.2 造成数据丢失的事故类型
由于数据丢失类型很多,没有任何一种银弹可以同时保护所有事故类型。
Google SRE根据大规模生产运维经验,将数据丢失事故归纳为以下五大类型:
| 类型 | 具体表现 | 典型场景 |
|---|---|---|
| 服务器硬件故障 | 磁盘损坏、内存错误、电源故障 | 批量磁盘老化期同时损坏,导致副本同步机制来不及补全 |
| 软件Bug | 应用逻辑错误、存储系统缺陷 | 数据删除逻辑Bug是最常见的永久性数据丢失原因 |
| 人为操作错误 | 误执行数据清除命令、配置错误 | 运维人员在压力下误操作,删除了错误的数据 |
| 恶意攻击 | 账号被劫持后恶意删除数据 | 攻击者先清空用户数据,再控制账号发送垃圾信息 |
| 外部环境灾难 | 自然灾害、电力中断、网络分区 | 整个数据中心因物理灾难而不可用 |
关键洞察:在更新速度极快、隐私要求高的场景中,大规模数据丢失和损坏通常是由应用程序Bug造成的。软删除机制正是在这种背景下被大规模采用。
3.3 Google SRE保障数据完整性的手段:分级防护体系
由于数据丢失类型繁多,Google选择建立分级防护体系——随着层级增加,所保护的数据丢失场景也更为罕见。
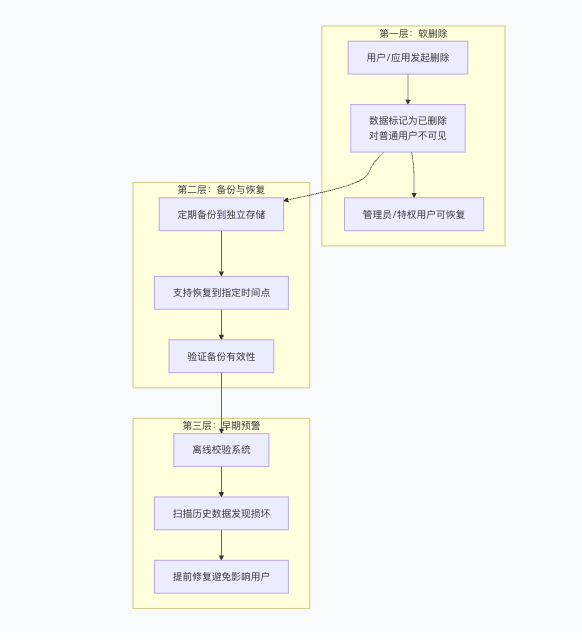
第一层:软删除——应对“误删除”的第一道防线
“软删除机制可以大幅度减少支持人员的压力。”
软删除意味着被删除的数据立刻被标记为已删除,这样除了管理后台代码之外其他代码不可见。管理后台包括司法取证场景、账号恢复、企业管理后台、用户支持,以及在线排错等。
软删除机制的核心价值:
| 价值维度 | 说明 |
|---|---|
| 技术层面 | 从源头拦截误删除,让数据在物理删除前有“后悔期” |
| 运维层面 | 大幅减少用户支持压力——Google在使用量最高的工具上都实现了这种机制,否则用户支持带来的压力是无法持续的 |
| 安全层面 | 结合账号被劫持场景——攻击者常先删除原始数据再滥用账号,软删除提供了事后恢复的机会 |
保留时长的设定考量:
| 因素 | 说明 |
|---|---|
| 组织政策与法律条文 | 不同行业对数据保留期限有不同要求 |
| 存储成本 | 存储空间是有限的,需要权衡成本与收益 |
| 产品价格与市场定位 | 付费产品的数据保护标准通常高于免费产品 |
Google的经验显示:大部分账号劫持和数据完整性问题会在60天内被汇报或检测到。因此,Google将软删除的默认保留期设为60天。
第二层:备份与恢复——硬删除后的“后悔药”
当数据已经物理删除,或者软删除窗口期已过,第一层防护就已失效。此时,备份和对应的恢复机制成为第二道防线。
备份与恢复的核心考虑因素:
| 考虑因素 | 具体问题 |
|---|---|
| 保留时长 | 备份保存多久? |
| 恢复速度 | 恢复全部数据需要多久? |
| 恢复粒度 | 能还原到多早的数据?能还原到多细的粒度? |
| 数据损失容忍度 | 允许损失多少数据? |
| 资源投入 | 愿意在备份恢复上投资多少? |
复制 ≠ 备份:虽然复制机制在某些场景下对数据恢复很有用,但数据恢复计划不应该依赖于复制机制。复制只解决“可用性”问题,不解决“误删除”或“数据损坏”问题。
第三层:早期预警——让“看不见的损坏”无处遁形
早期预警是分级防护体系的最后一层。Google同时发现最严重的数据删除案例经常是由于某个不熟悉现有代码的开发者实现新功能时造成的。
早期预警的核心是离线校验系统——不依赖于在线服务,独立扫描历史数据,主动发现数据损坏和错乱。这种“带外数据验证”(out-of-band data validation)机制不依赖于在线服务,独立扫描历史数据,主动发现数据损坏和错乱。
3.4 数据完整性的考核指标
在数据完整性领域,有两个核心指标指导SRE进行系统设计:
| 指标 | 英文 | 定义 | 数据完整性场景中的含义 |
|---|---|---|---|
| RTO | Recovery Time Objective | 从故障发生到系统完全恢复所需的时间 | 用户数据从“不可访问”到“可访问”的恢复时长 |
| RPO | Recovery Point Objective | 数据恢复后可以容忍丢失的最长时间窗口 | 数据能恢复到多早的状态,允许丢失多少数据 |
RTO与RPO的权衡:以Gmail 2011年事件为参考,4天被视为“过长”,Google将Apps的数据恢复SLO起点设定为24小时。
3.5 分级防护体系的互补关系
| 层级 | 保护范围 | 典型恢复窗口 | 适用场景 |
|---|---|---|---|
| 第一层:软删除 | 误删除、账号劫持 | 分钟到小时 | 最常见的用户误操作 |
| 第二层:备份恢复 | 物理删除、大规模损坏 | 小时到天 | 软删除窗口期已过或大规模数据损坏 |
| 第三层:早期预警 | 静默损坏、隐性错乱 | 天到周 | 用户未发现但实际已损坏的数据 |
这三层机制相互独立,各自针对不同类型的数据丢失场景。分级防护会引入多个层级,随着层级增加,所保护的数据丢失场景也更为罕见。
四、本章与其他章节的关联
| 关联章节 | 关联点 |
|---|---|
| 第4章 SLO | 数据完整性同样需要SLO量化——RTO、RPO是服务等级目标的具体体现 |
| 第6章 监控 | 早期预警机制本身就是监控的一种特殊形态——主动扫描发现静默损坏 |
| 第13-14章 应急响应 | 数据完整性事故触发时,需要标准的应急响应流程 |
| 第15章 事后总结 | 每次数据完整性事故都应进行事后总结,无指责地分析系统缺陷 |
| 第16章 跟踪故障 | 从事后总结中识别的改进措施需要通过跟踪系统闭环管理 |
| 第18章 SRE软件工程 | 软删除机制、备份恢复系统、离线校验系统都是SRE内部软件工程的产物 |
| 第23章 管理关键状态 | 数据本身就是分布式系统中最重要的“关键状态”,本章是第23章共识机制的应用场景 |
| 第25章 数据处理管道 | 数据管道处理完数据后,如何确保读写一致性正是本章的核心议题 |
五、第26章知识点脑图总结
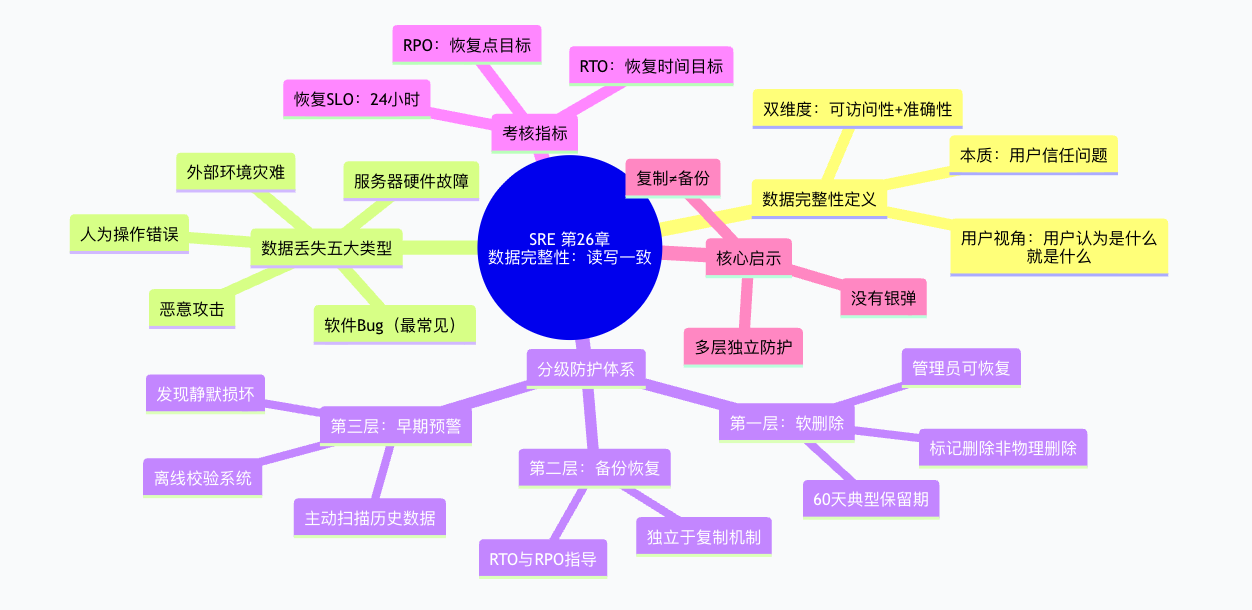
六、总结:一句话记住本章
数据完整性 = 软删除 + 备份恢复 + 早期预警——用分级独立防护体系,在用户认为数据已丢失之前主动介入。
| 关键点 | 一句话概括 |
|---|---|
| 数据完整性的本质 | 用户认为它是什么,它就是什么——是信任问题,而非纯技术指标 |
| 五大数据丢失类型 | 硬件故障、软件Bug、人为操作、恶意攻击、环境灾难 |
| 分级防护体系 | 软删除 → 备份恢复 → 早期预警,三层独立机制逐级应对罕见场景 |
| 软删除的价值 | 从源头拦截误删除,在Google使用量最高的工具上全面实现 |
| 早期预警的核心 | 离线校验系统主动扫描历史数据,让静默损坏无处遁形 |
| 复制 ≠ 备份 | 数据恢复计划不应该依赖于复制机制 |
| 两大考核指标 | RTO(恢复时间)+ RPO(恢复点) |
| 核心启示 | 没有银弹,需要多层次、相互独立的防护手段 |
行动建议:
-
本周内完成:评估当前系统的数据保护机制,对照五大事故类型找出防护盲点;确认软删除机制是否已覆盖所有可能被用户删除的数据
-
一个月内完成:为软删除设置合理的保留期(参考60天),并建立清理策略;明确RTO和RPO目标,记录在服务文档中
-
一个季度内完成:建立离线数据校验机制,定期扫描历史数据发现异常;至少进行一次备份恢复演练,验证恢复流程的有效性
-
长期坚持:定期审查数据保护策略,确保与业务发展和法规要求同步;将数据完整性纳入事后总结的必查项
七、高频考点自测
问题1:什么是数据完整性?为什么说“用户认为它是什么,它就是什么”?
参考答案:数据完整性可以从两个维度理解:可访问性(数据在需要时能被访问)和准确性(读取的数据与写入的数据一致)。之所以说“用户认为它是什么,它就是什么”,是因为这是用户信任问题。例如Gmail界面Bug显示空邮箱时间过长,即使技术上数据完好无损,用户也会认为数据已丢失,Google作为数据管理者的声誉同样会受损。最终,数据的价值由用户的感知和信任决定,而非技术指标。
问题2:Google SRE的数据完整性分级防护体系包含哪三层?各层的作用是什么?
参考答案:
-
第一层(软删除) :数据被标记为已删除但对管理员不可见,用户可在保留期内恢复。应对最常见的误删除场景
-
第二层(备份与恢复) :当软删除窗口已过或数据被物理删除时,从备份中恢复数据。设置RTO和RPO作为指导目标
-
第三层(早期预警) :通过离线校验系统主动扫描历史数据,在用户发现问题之前提前修复
问题3:软删除机制中,保留期应该如何设定?Google的经验值是多少?
参考答案:保留期的设定需要综合考虑组织政策与法律条文、存储成本和产品市场定位。在Google的经验中,大部分账号劫持和数据完整性问题会在60天内被汇报或检测到,因此60天是软删除的合理保留期——更长的保留期未必能带来等比例的保护效果。
问题4:为什么说“复制不等于备份”?
参考答案:复制解决的是“可用性”问题——当一台机器故障时,其他副本可以继续服务。但复制无法解决“误删除”或“数据损坏”问题:如果用户误删了数据,复制系统会忠实地将“删除”操作复制到所有副本,导致所有副本上的数据都被删除。数据恢复计划不应该依赖于复制机制。
问题5:如何衡量数据完整性系统的有效性?
参考答案:主要使用两个指标:① RTO(恢复时间目标)——从故障发生到系统完全恢复所需的时间,合理目标是24小时内;② RPO(恢复点目标)——数据恢复后可以容忍丢失的最长时间窗口。这两个指标的平衡需要在业务价值和成本之间权衡——更短的RTO通常意味着更高的成本。
八、延伸阅读推荐
-
《Google SRE 工作手册》第12章“数据完整性”:本章内容的工作手册版扩展
-
《Building Secure and Reliable Systems》第8章“Data Integrity”:数据完整性与安全性的交叉实践
-
《Designing Data-Intensive Applications》(Martin Kleppmann):关于分布式数据系统设计原则的经典著作,第11章“数据系统的未来”
-
Google Cloud数据保护指南:https://cloud.google.com/architecture/data-protection
-
2011年Gmail数据丢失事件回顾:四天恢复窗口的教训
-
《SRE 中文社区》:https://www.srenow.cn
-
Google SRE官方书籍网站:https://sre.google
学习下一章预告:第27章“可靠地进行产品的大规模发布”——从数据完整性转向发布工程,探讨如何在保证系统稳定性的前提下实现大规模软件发布。
本文为个人学习笔记,仅用于知识分享。如有错误,欢迎指正。
👍🏻 点赞 + 收藏 + 分享,让更多开发者看到这篇深度解析!❤️ 如果觉得有用,请给个赞支持一下作者!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)