高空抛物轨迹实时追踪(高斯背景建模+卡尔曼追踪器+图片相似度模型)
高空抛物轨迹实时追踪
项目连接: 高空抛物😂
- 包含完整代码
- 方便修改的配置文件
- 易于扩展
- 快速运行demo
算法结构
下图展示了本算法的结构。算法核心由三部分构成,在显式代码编写中也分为三部分
- 目标检测
- 数据关联
- 目标追踪
算法处理的数据是具有时序信息的图像帧,每次输入一帧图像,目标检测器识别出移动的主体(即分离出背景和前景)。获取到的目标(前景)以中心点坐标形式。算法维护一个始终贯穿整个时序的追踪器队列,针对每次出现的目标都会做出两种判断:
(a)此目标是否可以和已有追踪器最优关联;
(b)此目标是否为新目标。
这样每一帧结束要么会有新的关联产生,要么更新关联,要么删除关联。最终,在一个个追踪器中记录的轨迹信息经过判断后将以适合的方式展示。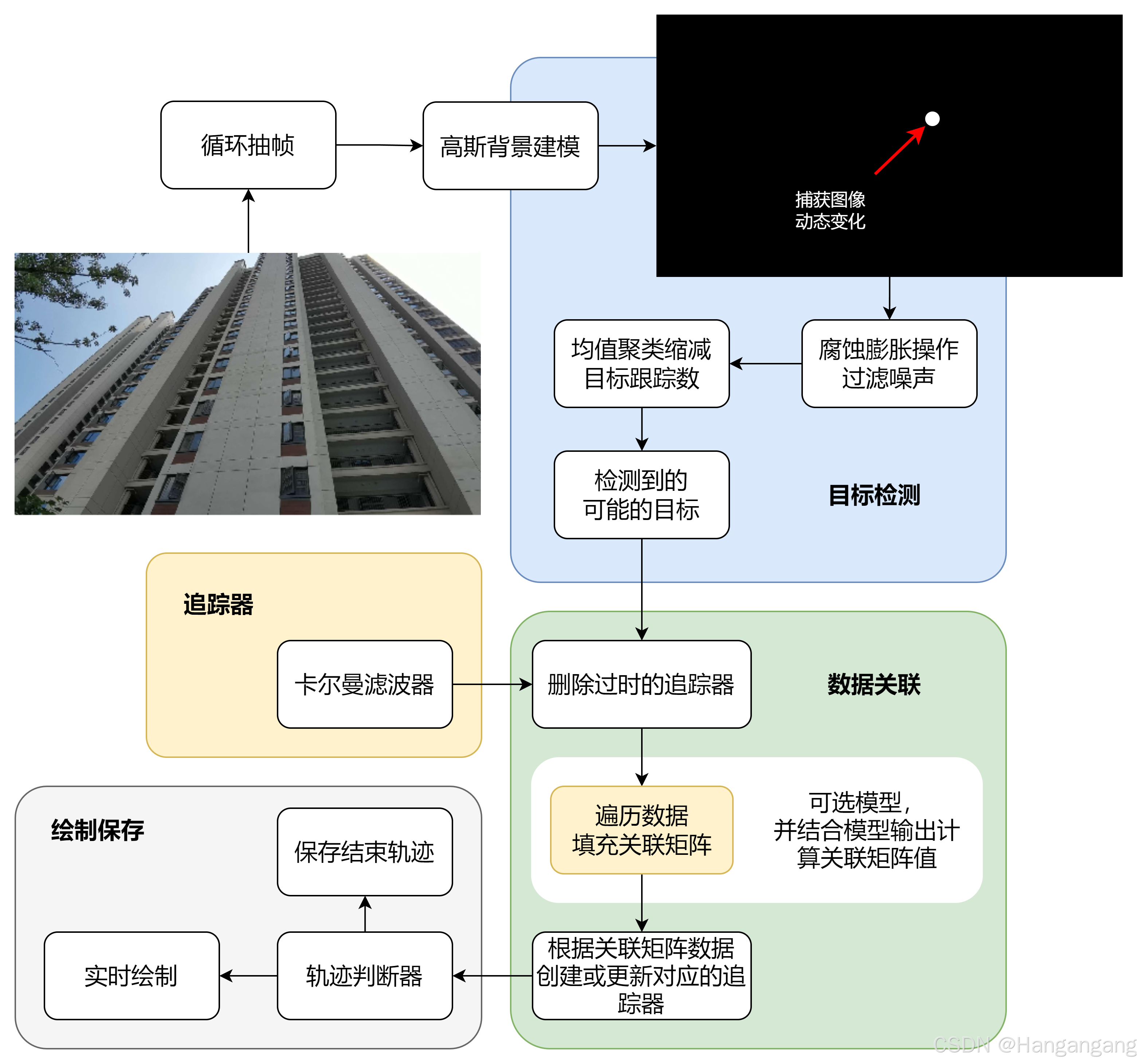
目标检测
高空抛物的物体复杂,使用成熟的目标检测算法(YOLO等)难以囊括,主要的方法可参看:
高空抛物监测Opencv+SORT
本算法选用常用的高斯背景建模,并对建模后的图像进行形态学操作去除一部分噪声。针对镜头中移动物体过多导致的追踪器溢出,在图像去噪之后又使用了均值聚类算法,这一操作明显过滤了画面大幅扰动带来的性能风险。
202409022133
画面中闪烁的绿点为聚类中心,灰色的轨迹为初始轨迹,红色的轨迹为抛物轨迹。可以看出尽管树枝扰动但是算法仍然保持了一定的稳定性。
下面的代码易于更改,可以随时修改其他方法。
import cv2
import yaml
from sklearn.cluster import MeanShift
# 读取配置文件
with open('./conf/config.yaml', 'r', encoding='utf-8') as file:
config = yaml.safe_load(file)
MIN_DETECT_OBJECT = config['background_subtractor']['min_detect_object']
kernel_size = (config['kernel_size']['width'], config['kernel_size']['height'])
bg_subtract_params = {
'history': config['background_subtractor']['history'],
'varThreshold': config['background_subtractor']['var_threshold'],
'detectShadows': config['background_subtractor']['detect_shadows']
}
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, kernel_size)
bg_subtract = cv2.createBackgroundSubtractorMOG2(**bg_subtract_params)
def detect_targets(image):
"""
基于高斯背景建模的目标检测器
:param image: 当前帧
:return: 返回当前画面中主要移动的物体中心坐标
"""
targets = []
image = bg_subtract.apply(image) # 背景建模
image = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel) # 去除噪点
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 寻找轮廓
# 给出符合阈值的轮廓
for c in contours:
perimeter = cv2.arcLength(c, True)
if perimeter > MIN_DETECT_OBJECT:
x, y, w, h = cv2.boundingRect(c)
cx, cy = x + w // 2, y + h // 2
targets.append([cx, cy])
if len(targets) == 0:
return targets
ms = MeanShift(max_iter=100)
ms.fit(targets)
cluster_centers = ms.cluster_centers_
return cluster_centers
目标追踪与数据关联
目标追踪是从上一帧(或之前)追踪目标与当前帧识别出的目标进行匹配,量化来看就是对每个目标和每个追踪进行置信度的计算,实际上就是一个二维的关联矩阵。矩阵的每个值代表这个目标与当前追踪器能够匹配的可信程度。
常见的目标追踪算法又DeepSort与ByteSort算法等,这些算法尝试找到最优的匹配方式。
参看:目标追踪DeepSORT与ByteTrack.
本算法是简化版本,基于高空抛物的目标检测之困难,我们实际上难以获得目标框及其置信度的信息。算法尝试使用简化的DIOU来衡量卡尔曼滤波器下一步预测与测量值之间的距离。算法对计算出的中心坐标进行矩形框复原,你可以在配置文件中更改矩形框的大小。这个简化的计算方式如下:
D I O U = 1 − d D DIOU=1-\frac{d}{D} DIOU=1−Dd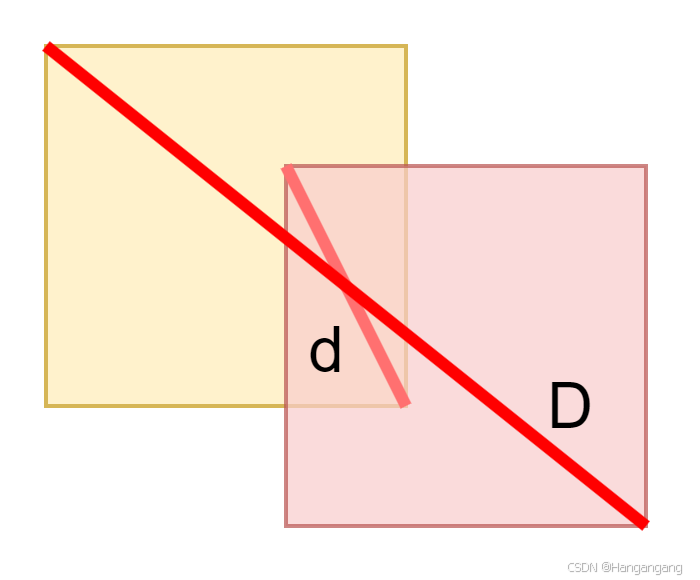
这样,如果期望引入计算图片相似度模型可以分配不同的权重来衡量关联的指标。
下面的代码完整展示了不使用相似度模型来进行最优关联的算法,算法维护了一个数据关联矩阵,以简化的DIOU作为唯一的置信度,并且假设置信度大于0.5即采用。
对于数据关联矩阵分别扫描横竖记录最大值,对追踪器而言如果没有关联目标则丢失追踪一帧,对目标而言如果全部都匹配不上则新建追踪器。
你可能会注意到下图有一个目标被同时分配到两个追踪器,实际上由于高空抛物目标的特性这种情况并不产生明显影响,更进一步当前算法没有关注图像本身的信息所以本质上无法完全判断谁会更好,你也可以尝试修改这一点。

import cv2
import numpy as np
from tracker.TargetTracker import TargetTracker
from target.Targets import detect_targets
from utils.box import bbox_diou
import yaml
with open('./conf/config.yaml', 'r', encoding='utf-8') as file:
config = yaml.safe_load(file)
# 必要参数
MAX_MISSED_FRAMES = config['kalman_filter']['max_missed_frames']
MAX_TRACKED_FRAMES = config['kalman_filter']['max_tracked_frames']
MAX_KF_NUM = config['kalman_filter']['max_filter_count']
MIN_CONFIDENCE = config['kalman_filter']['min_confidence']
IMG_SIZE = config['image']['size']
# 初始跟踪状态(无目标,无跟踪)
kalman_filters = []
def data_association(image):
"""
数据关联器
:param image: 当前帧
:return: None
"""
global kalman_filters
# 移除过时的跟踪器
to_remove = []
for i in range(len(kalman_filters)):
if (kalman_filters[i].target_missed_frames >= MAX_MISSED_FRAMES or
kalman_filters[i].target_tracked_frames >= MAX_TRACKED_FRAMES):
kalman_filters[i].save_line_track2pic(image)
to_remove.append(i)
for i in reversed(to_remove):
del kalman_filters[i]
# 获取目标列表
target_list = detect_targets(image)
if len(target_list) > 0 and len(kalman_filters) > 0:
# 关联矩阵
associate_matrix = np.zeros((len(kalman_filters), len(target_list)))
for tg_id, tg in enumerate(target_list):
cx, cy = tg # 当前目标中心点坐标
tg_box = [cx - IMG_SIZE // 2, cy - IMG_SIZE // 2,
cx + IMG_SIZE // 2, cy + IMG_SIZE // 2]
for kf_id, kf in enumerate(kalman_filters):
kf_pre_center = kf.get_prediction()
kf_box = [kf_pre_center[0] - IMG_SIZE // 2, kf_pre_center[1] - IMG_SIZE // 2,
kf_pre_center[0] + IMG_SIZE // 2, kf_pre_center[1] + IMG_SIZE // 2]
diou = bbox_diou(kf_box, tg_box)
confidence = diou
associate_matrix[kf_id][tg_id] = confidence
# 扫描矩阵,按照最大可信度分配目标
for kf_id in range(len(associate_matrix)):
max_value_i = np.max(associate_matrix[kf_id, :])
if max_value_i < MIN_CONFIDENCE:
kalman_filters[kf_id].target_missed_frames += 1
continue
max_index_i = np.argmax(associate_matrix[kf_id, :])
cx, cy = target_list[max_index_i]
kalman_filters[kf_id].update(np.array([[np.float32(cx)], [np.float32(cy)]])) # 更新参数
kalman_filters[kf_id].track_save_or_not() # 判断路径是否保留
for tg_id in range(len(associate_matrix[0])):
max_value_i = np.max(associate_matrix[:, tg_id])
if max_value_i < MIN_CONFIDENCE:
if len(kalman_filters) >= MAX_KF_NUM:
continue
cx, cy = target_list[tg_id]
kf = TargetTracker((cx, cy))
kalman_filters.append(kf)
elif len(kalman_filters) > 0:
for _, kf in enumerate(kalman_filters):
kf.target_missed_frames += 1
else:
for _, tg in enumerate(target_list):
if len(kalman_filters) >= MAX_KF_NUM:
continue
cx, cy = tg
kf = TargetTracker((cx, cy))
kalman_filters.append(kf)
# 绘制
for i, kf in enumerate(kalman_filters):
kf.draw_line_track2pic(image)
for cx, cy in target_list:
cv2.circle(image, (int(cx), int(cy)), 4, (255, 255, 255), -1)
return image
下面的代码展示了追踪器的部分,每一个追踪器实例绑定唯一一个追踪的目标:
- 初始化卡尔曼滤波器
- 位置与运动信息
- 历史坐标点,时间
- 已连续检测和丢失的帧数
- 轨迹可保存标识
- 颜色
def __init__(self, center):
self.kalman_filter = cv2.KalmanFilter(4, 2)
self.kalman_filter.transitionMatrix = np.array([[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
self.kalman_filter.measurementMatrix = 1.0 * np.eye(2, 4, dtype=np.float32) # 设置测量噪声协方差矩阵
self.kalman_filter.processNoiseCov = 1e-5 * np.eye(4, 4, dtype=np.float32) # 设置过程噪声协方差矩阵
self.kalman_filter.measurementNoiseCov = 1e-3 * np.eye(2, 2, dtype=np.float32) # 设置测量噪声协方差矩阵
self.kalman_filter.errorCovPost = 1.0 * np.eye(4, 4, dtype=np.float32) # 设置估计误差协方差矩阵
self.kalman_filter.statePost = np.array([[0], [0], [0], [0]], np.float32) # 初始化状态向量
# 初始化位置与运动信息
self.kalman_filter.statePre = np.array([[center[0]], [center[1]], [0], [0]], np.float32)
self.kalman_filter.statePost = np.array([[center[0]], [center[1]], [0], [0]], np.float32)
self.history = [] # 存储历史位置
self.target_max_confidence = 0.0 # 锁定最大可信的目标(可选)
self.target_missed_frames = 0 # 连续未检测到帧数
self.target_tracked_frames = 1 # 已经追踪的帧数
self.is_save = False # 是否达到保存条件
self.feature = None # 保存特征(可选,计算图像相似性时可用)
self.appearance_update_frequency = 0 # 目标图像定期更新(可选)
self.object_color = (0, 0, 0) # 不同的配置颜色以醒目的标识
self.create_time = datetime.now() # 记录初次探测时间
保存图片
算法通过轨迹判断在适当的时候显示轨迹,并在目标消失后记录轨迹图片。
全局配置文件
✨你可以在conf目录下修改全局配置文件的参数设置,以匹配不同的实际需求,下面是配置文件的详细注释:
# 用于图像膨胀腐蚀操作的核大小
kernel_size:
width: 4
height: 4
background_subtractor:
history: 100 # 卡尔曼滤波器背景建模帧数
var_threshold: 45 # 背景变化范围
detect_shadows: False # 是否检测背景
min_detect_object: 5 # 最小探测物体大小
kalman_filter:
max_missed_frames: 30 # 追踪器允许的最长目标跟踪丢失帧数
max_tracked_frames: 500 # 最长的目标追踪帧数
max_filter_count: 10 # 同时追踪的最大数目
min_confidence: 0.5 # 可信度
image:
min_show_num: 10 # 可展示的轨迹最小记录帧数
size: 40 # 图片相似度或DIOU计算截取图片大小
save:
# 检测结果保存路径,路径从项目根目录开始
save_path: './save/'
小结
算法结构
- 算法结构分为三个核心部分:目标检测、数据关联和目标追踪。
处理具有时序信息的图像帧,使用目标检测器识别移动主体,然后通过追踪器队列进行目标追踪和更新。
目标检测
- 使用高斯背景建模和形态学操作去除噪声,为了防止追踪器溢出,采用了均值聚类算法进一步过滤噪声。
- 提供了一个基于高斯背景建模的目标检测器函数 detect_targets(),该函数返回当前画面中主要移动物体的中心坐标。
目标追踪与数据关联
- 介绍了一个简化版的目标追踪算法,它基于简化DIOU来衡量卡尔曼滤波器预测与实际测量之间的距离。
- 使用简化版的DIOU构建数据关联矩阵,并通过该矩阵来决定如何更新追踪器的状态。
- 提供了 data_association() 函数用于实现目标与追踪器之间的匹配。
追踪器
- 每个追踪器实例绑定唯一一个追踪目标,并初始化卡尔曼滤波器。
- 跟踪器维护着目标的位置与运动信息,以及连续检测和丢失的帧数。
转载请注明出处。
视频素材来源于网络,侵权删除。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)