深度学习篇---BERT
BERT 是 Bidirectional Encoder Representations from Transformers 的缩写,由 Google AI 在 2018 年提出(论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》)。它是第一个真正意义上的双向预训练语言模型,彻底改变了自然语言处理(NLP)的范式。
一句话:BERT 就是 NLP 领域的“ResNet + ImageNet 预训练”—— 它在海量文本上预训练后,可以微调适配几乎所有 NLP 任务,效果远超传统方法。
一、BERT 的核心创新(与之前的 NLP 模型对比)
1.1 之前的 NLP 模型(如 ELMo、GPT-1)
| 模型 | 方向性 | 预训练任务 | 缺点 |
|---|---|---|---|
| Word2Vec / GloVe | 静态词向量 | 词共现统计 | 无法处理一词多义 |
| ELMo | 单向(LSTM 堆叠) | 语言模型 | 只是浅层拼接,不是真双向 |
| GPT-1 | 单向(从左到右) | 语言模型 | 看不到未来信息,不适合理解任务 |
1.2 BERT 的三大突破
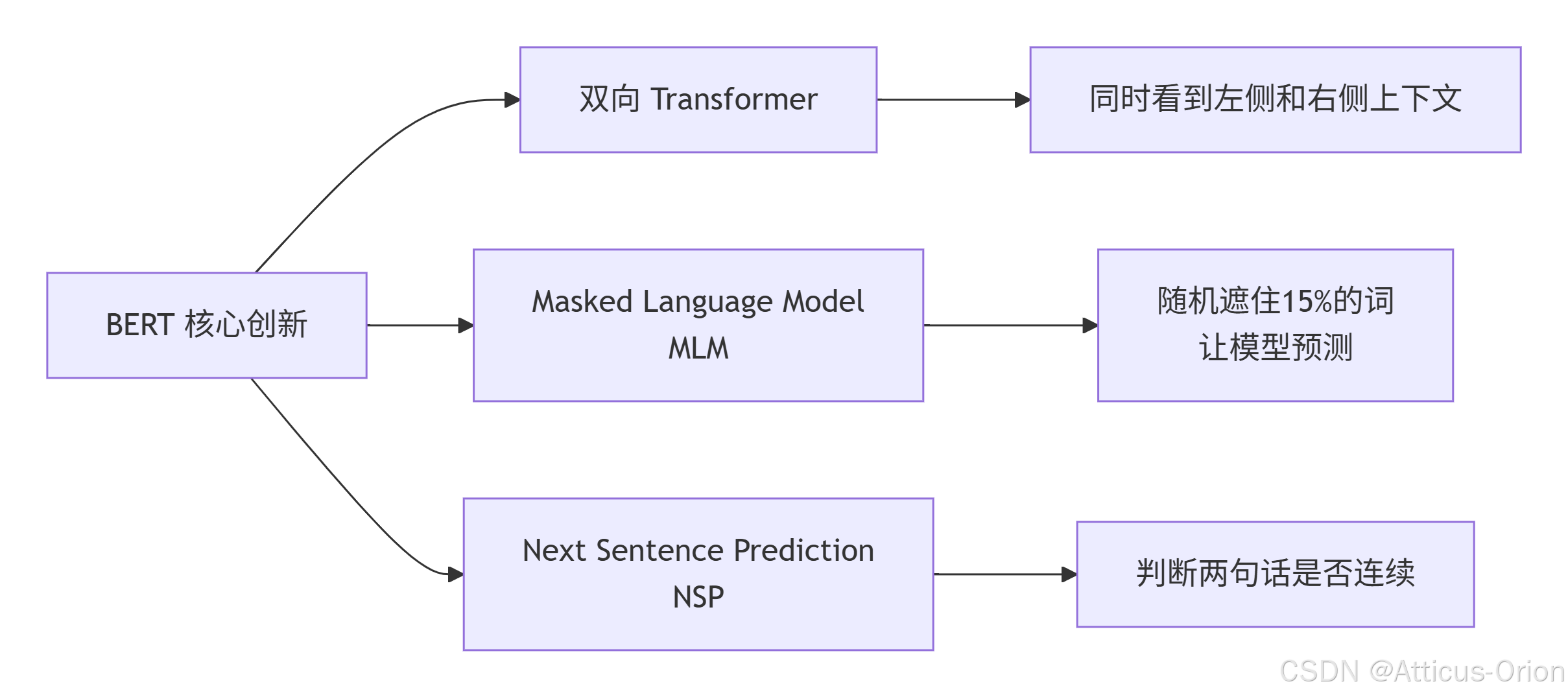
关键创新解释:
-
双向性:在处理“我 [MASK] 银行”时,同时看到“我”和“银行”两个方向的信息,能准确预测“去”而不是“的”。
-
MLM(掩码语言模型):类似完形填空,迫使模型理解词之间的深层关系。
-
NSP(下一句预测):理解段落级别的连贯性,对问答、推理任务至关重要。
二、BERT 的模型规模(参数量与变体)
| 模型版本 | 层数(Transformer Block) | 隐藏层维度 | 注意力头数 | 参数量 | 内存占用(FP32) |
|---|---|---|---|---|---|
| BERT-Tiny | 2 | 128 | 2 | 4.4M | ~18 MB |
| BERT-Mini | 4 | 256 | 4 | 11.4M | ~46 MB |
| BERT-Small | 4 | 512 | 8 | 28.9M | ~116 MB |
| BERT-Medium | 8 | 512 | 8 | 41.7M | ~167 MB |
| BERT-Base | 12 | 768 | 12 | 110M | ~440 MB |
| BERT-Large | 24 | 1024 | 16 | 340M | ~1.3 GB |
实际部署时,BERT-Base(110M 参数)是最常用的版本,性能与大小的平衡最好。
三、BERT 能做什么?(NLP 任务的统一框架)
3.1 典型任务及输入输出格式
| 任务类型 | 示例 | 输入格式 | 输出格式 |
|---|---|---|---|
| 文本分类 | 情感分析、垃圾邮件检测 | [CLS] 今天天气真好 [SEP] | [CLS] 标签(积极/消极) |
| 句子对分类 | 语义相似度、推理判断 | [CLS] 句子A [SEP] 句子B [SEP] | [CLS] 标签(蕴含/矛盾) |
| 问答系统 | SQuAD 任务 | [CLS] 问题 [SEP] 段落 [SEP] | 输出答案的开始/结束位置 |
| 序列标注 | 命名实体识别、分词 | [CLS] 小明在北京大学读书 [SEP] | 每个词输出标签(PER/LOC/ORG) |
3.2 在 Jetson + IMX219 场景中的应用(多模态)
虽然 BERT 用于文本,但在视觉项目中常作为语义理解的后处理模块:

实际例子:
-
视觉问答(VQA):图像 → 物体检测 → 标签序列 + 用户问题 → BERT 输出答案
-
场景图生成:OCR 提取店铺名称 → BERT 判断行业类别(如“小李烧烤” → 餐饮)
-
智能导盲眼镜:识别标志牌文字 → BERT 提取关键指令(如“小心台阶”)
四、BERT 在 Jetson Orin 系列上的部署挑战
4.1 性能基准(Jetson Orin NX,TensorRT 加速)
| 模型 | 输入长度 | 推理延迟(FP16) | 吞吐量(batch=1) | 内存占用 |
|---|---|---|---|---|
| BERT-Tiny | 128 tokens | 2.3 ms | 435 QPS | ~50 MB |
| BERT-Mini | 128 tokens | 4.1 ms | 244 QPS | ~100 MB |
| BERT-Small | 128 tokens | 7.2 ms | 139 QPS | ~200 MB |
| BERT-Base | 128 tokens | 18.5 ms | 54 QPS | ~650 MB |
| BERT-Base | 512 tokens | 52 ms | 19 QPS | ~1.2 GB |
QPS = Queries Per Second(每秒查询次数)
关键结论:
-
Orin Nano (8GB):只能跑 BERT-Small 及以下(BERT-Base 内存不足)
-
Orin NX (16GB):可跑 BERT-Base(128 tokens),但 512 长文本会吃力
4.2 主要性能瓶颈
| 瓶颈 | 说明 | BERT 的影响程度 |
|---|---|---|
| 内存带宽 | Transformer 的矩阵乘法频繁读写权重 | ⚠️ 严重(相比 CNN 更依赖带宽) |
| 计算量 | 自注意力的 Q/K/V 计算 | ⚠️ 严重(O(L²×d) 复杂度) |
| 内存容量 | 存储模型权重 + 中间激活 | ⚠️ 严重(BERT-Base 约 650MB) |
| 批处理效率 | 变长输入导致 padding 浪费 | ⚠️ 中等(需使用 Dynamic Batching) |
五、在 Jetson 上优化 BERT 的实战技巧
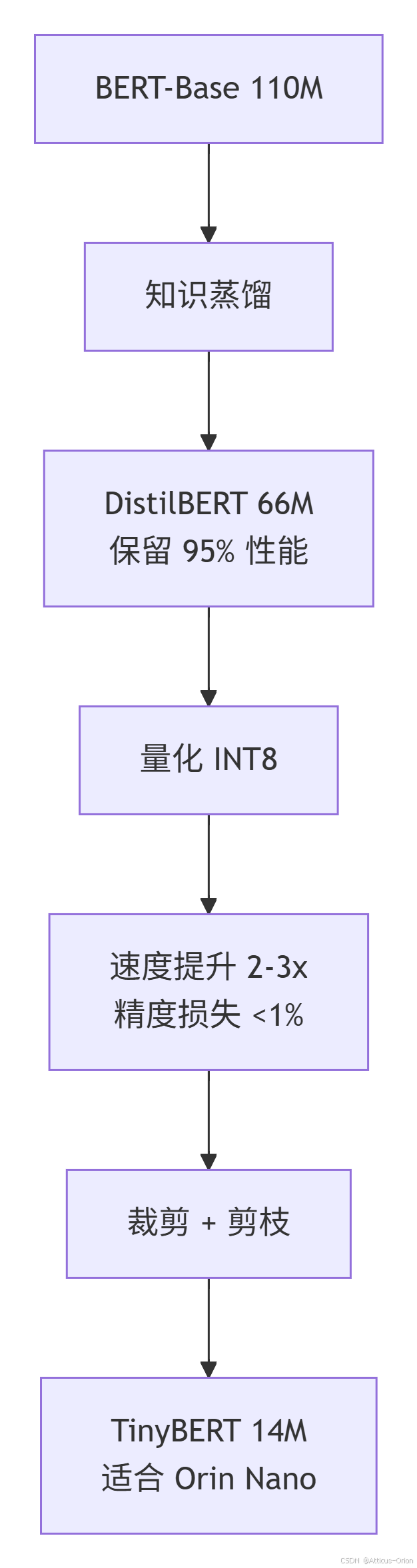
5.1 模型压缩方法(从大到小)
5.2 TensorRT 部署命令示例
# 1. 将 HuggingFace BERT 导出为 ONNX
python -m transformers.onnx --model=bert-base-uncased . --feature=sequence-classification
# 2. TensorRT 转换(FP16 优化)
trtexec --onnx=model.onnx \
--fp16 \
--minShapes=input_ids:1x64,attention_mask:1x64 \
--optShapes=input_ids:4x128,attention_mask:4x128 \
--maxShapes=input_ids:8x256,attention_mask:8x256 \
--workspace=4096 \
--saveEngine=bert.engine
# 3. 在 Orin NX 上测试延迟
trtexec --loadEngine=bert.engine --batch=15.3 精度与速度权衡
| 优化策略 | 精度保留 | 加速比 | 适用场景 |
|---|---|---|---|
| FP32 原版 | 100% | 1x | 开发调试 |
| FP16(TensorRT) | 99.9% | 2-3x | 生产环境默认选项 |
| INT8 量化 | 98-99% | 4-5x | 边缘设备 + 非敏感任务 |
| INT8 + 剪枝(50%稀疏) | 96-98% | 6-8x | 性能极致优化 |
六、BERT 与 ViT 的对比(都是 Transformer)
| 维度 | BERT | ViT |
|---|---|---|
| 输入形式 | 文本序列(词 + [CLS] + [SEP]) | 图像 Patch 序列 + 位置编码 |
| 预训练任务 | MLM + NSP | 监督分类(ImageNet)或自监督(MAE) |
| 典型用途 | 文本理解、问答、分类 | 图像分类、检测、分割 |
| 参数量(基础版) | 110M | 86M(ViT-B) |
| 双向性 | ✅ 真双向(MLM 训练) | ✅ 双向(注意力无方向限制) |
| 在 Jetson 上的难度 | 中等(内存敏感) | 较高(计算量更大) |
共同点:都是 Transformer Encoder 架构,都依赖大规模预训练,都有轻量化变体。
七、选型建议(结合你的场景)
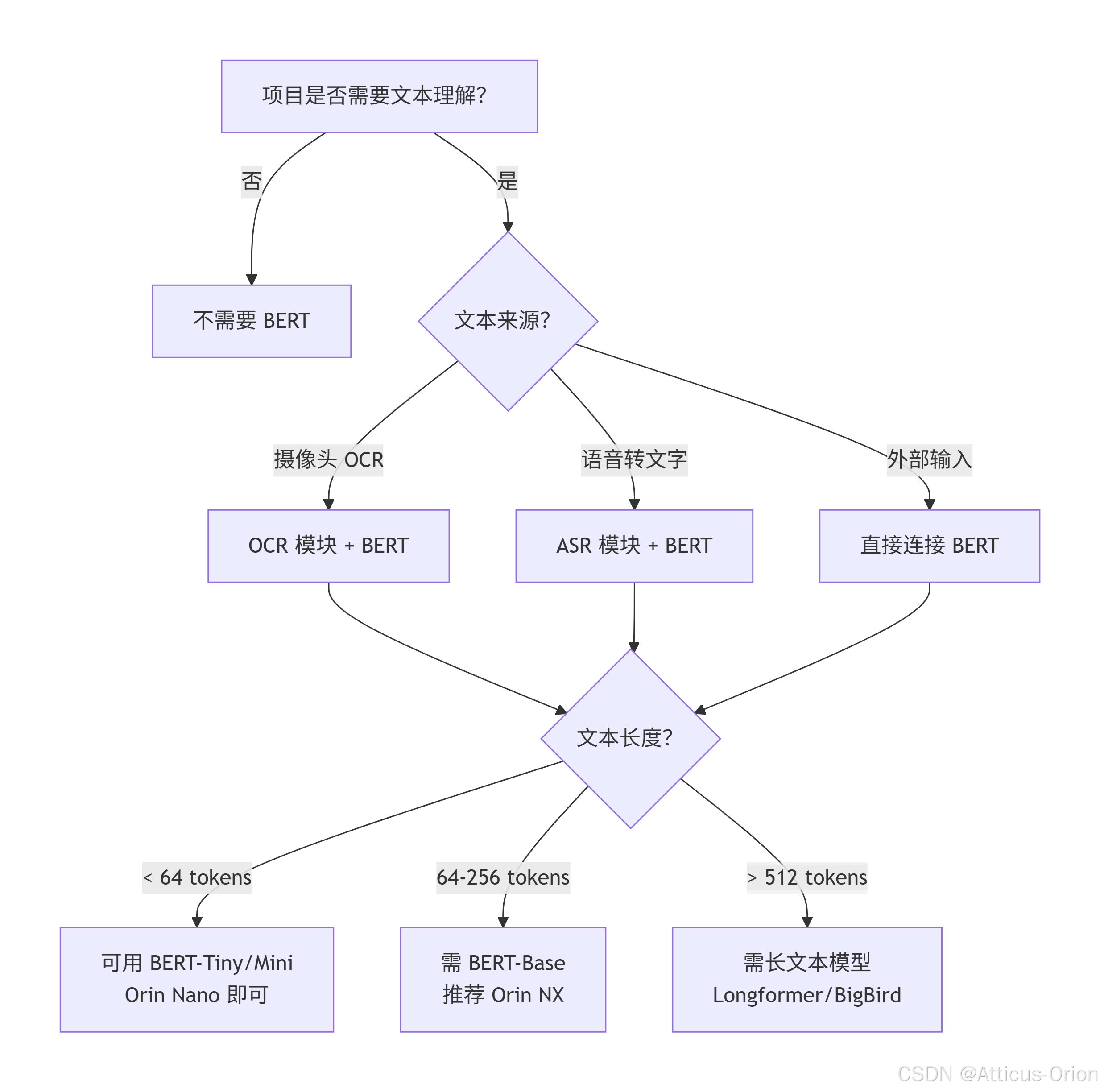
7.1 什么时候在 Jetson 上部署 BERT?
7.2 实际组合方案
| 项目场景 | 推荐 BERT 模型 | Jetson 型号 | 预期延迟 |
|---|---|---|---|
| 智能门禁(识别工牌姓名) | BERT-Tiny | Orin Nano 4GB | <10ms |
| 导盲眼镜(理解标志牌) | DistilBERT | Orin Nano 8GB | 15ms |
| 零售识别(商品+评价分析) | BERT-Base (INT8) | Orin NX 8GB | 25ms |
| 多轮对话机器人 | BERT-Base (FP16) | Orin NX 16GB | 35ms |
八、一句话总结 BERT
BERT 是 NLP 的通用“大模型基座”,通过 MLM 预训练学会了理解词语的上下文关系。在 Jetson 边缘设备上,BERT-Base 只能跑在 Orin NX(16GB 最佳),而 Orin Nano 适合 Tiny/Mini/Small 变体;如果项目同时需要视觉+文本理解,BERT 通常作为后排模块配合 CNN/ViT 工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)