强化学习实战8.4——用PPO打赢星际争霸【启动训练与结果分析】
强化学习,启动!
如果训练不起来,请复制文末的代码。(我转到服务器后做了一些修改,尽量按照文末的代码复制粘贴)
TIMESTEPS = 10000
iters = 0
while True:
print(f'On iteration:{iters}')
model.learn(total_timesteps=TIMESTEPS, tb_log_name='PPO', reset_num_timesteps=False)
model.save(f'{model_dir}/{TIMESTEPS*iters}')- TIMESTEPS = 10000:每一轮训练的时间步长(每轮训练 1 万步,对应星际 2 多局游戏)
- while True:无限循环训练,持续迭代优化模型
- model.learn(...):
total_timesteps=TIMESTEPS:本轮训练 1 万步tb_log_name='PPO':TensorBoard 日志标签reset_num_timesteps=False:关键! 不重置训练步数,保证多轮训练的日志连续、模型迭代不中断
- model.save(...):每轮训练结束后,自动保存模型,命名为
{TIMESTEPS*iters}(如 10000、20000、30000...),方便后续加载不同训练阶段的模型
出现这个就是开始了
然后在vscode打开tensorboard,实时查看训练日志
tensorboard --logdir ./logs中断恢复
1.最新模型文件
首先在model对应的文件夹中找到最新的模型,我们用时间戳命名的,找最大的就行。
model_name = '<最新的模型>'
model_dir = f'models/{model_name}/'
logs_dir = f'logs/{model_name}/'2. 加载指定步数的模型(断点续训)
然后确定继续训练步数,不会从零开始,不会浪费之前的计算
model = PPO.load(f'{model_dir}/<指定继训步数>.zip', env=env, tensorboard_log=logs_dir)3. 继续训练
model.learn(total_timesteps=TIMESTEPS, ...)
model.save(f'{model_dir}/{TIMESTEPS*iters}')
- 每轮训 10000 步
- 保存为
260000,270000,280000... - 实现无缝续训,直到满意
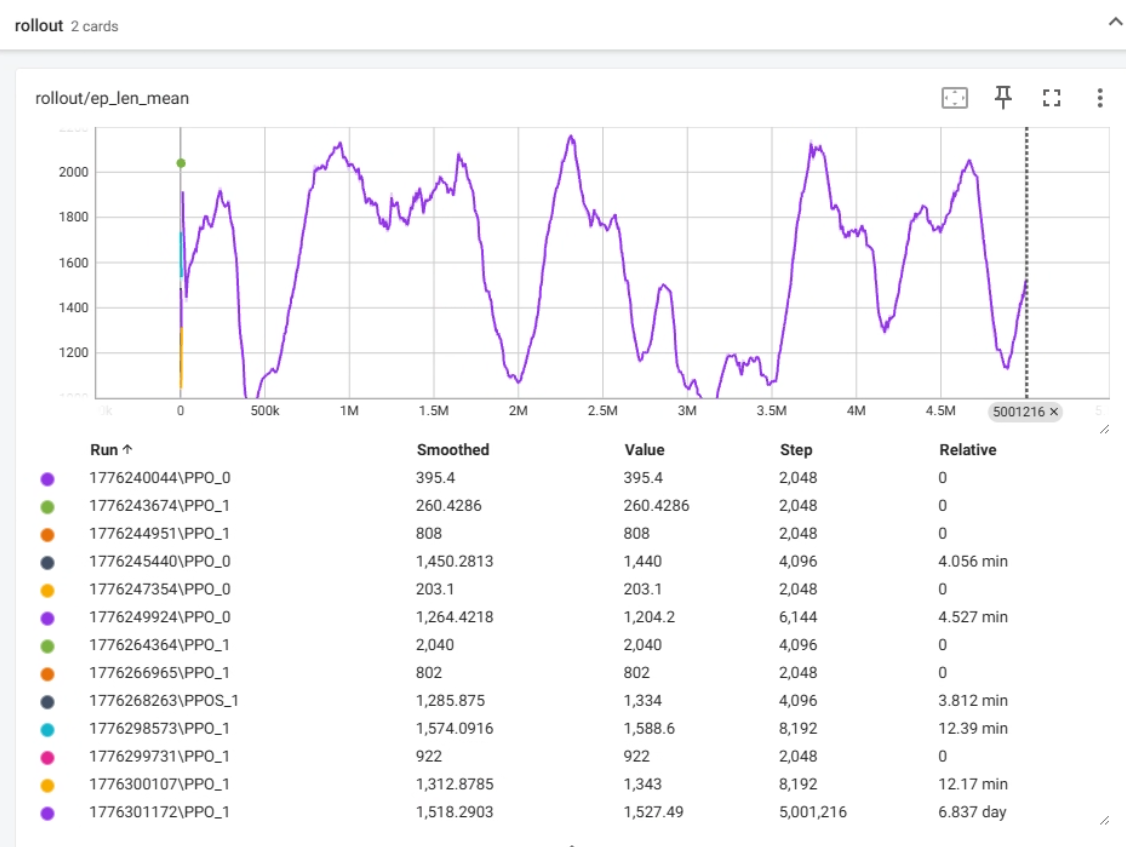
训练效果

经过一周的训练,我们打开tensorflow面板:
在训练步数一栏,步数大概在1000-2000徘徊
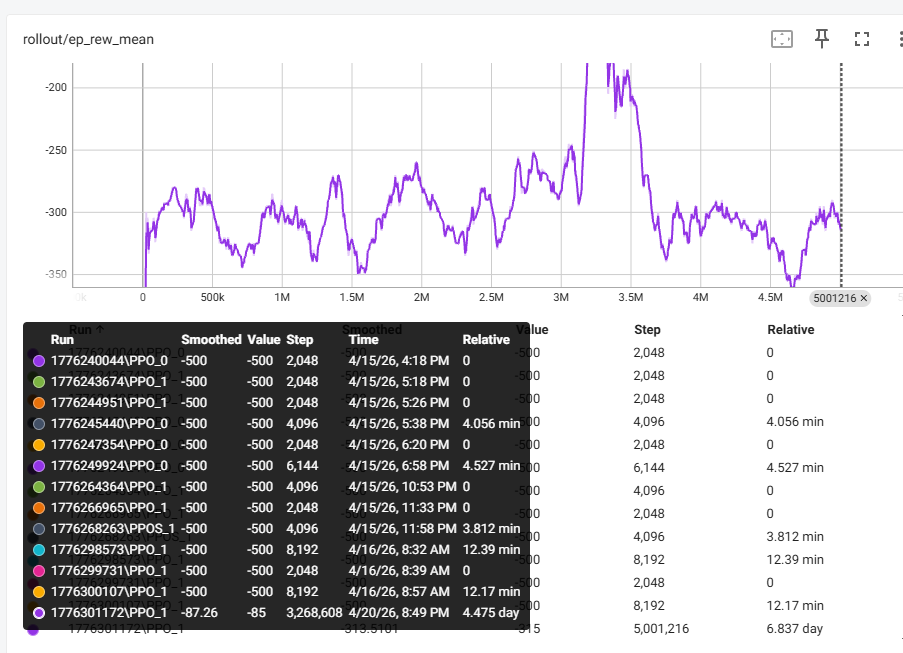
在奖励一栏,可以看到在32万步的时候,奖励达到了-85,这是非常非常非常棒的结果!!!
我们用callbacks记录了最好批次的模型,可以后续调用。
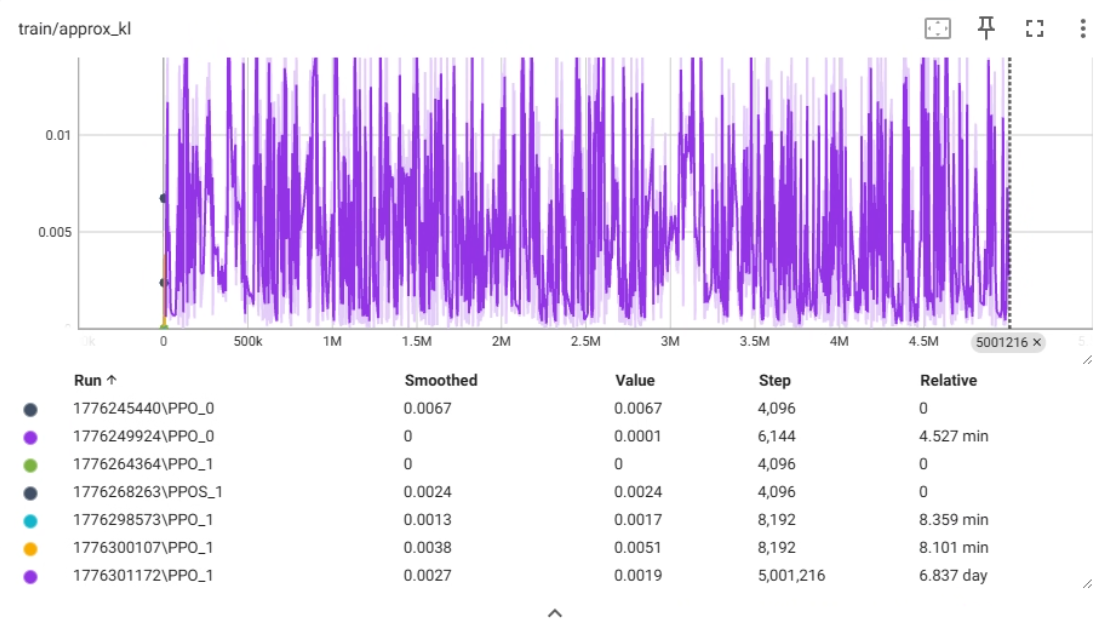
train/approx_kl 指标解释
train/approx_kl 代表 近似 KL 散度。
- 含义:KL 散度(Kullback-Leibler Divergence)用于衡量两个概率分布之间的差异。在 PPO 训练中,它衡量的是当前策略(更新后)与旧策略(更新前)之间的差异有多大。
- 通俗理解:它表示模型每一次更新时,“步子”迈得有多大。
- 如果数值很高,说明新策略和旧策略差别很大,模型正在剧烈地改变它的行为。
- 如果数值很低,说明新策略和旧策略差不多,模型只是在做微调。
数值范围与稳定性
- 图表中的数值主要集中在 0 到 0.015 之间。
- 相比于上一张
clip_fraction图,虽然这里依然有剧烈的锯齿状波动,但整体维持在一个相对低位的水平。 - 早期(0 - 500k步):波动非常剧烈,甚至在某些点冲得很高,说明训练初期模型在学习时非常“激进”,尝试大幅改变策略。
- 后期(2M - 5M步):波动依然存在,但整体趋势似乎略有下降或保持稳定,没有持续发散(即没有一直往上涨)。
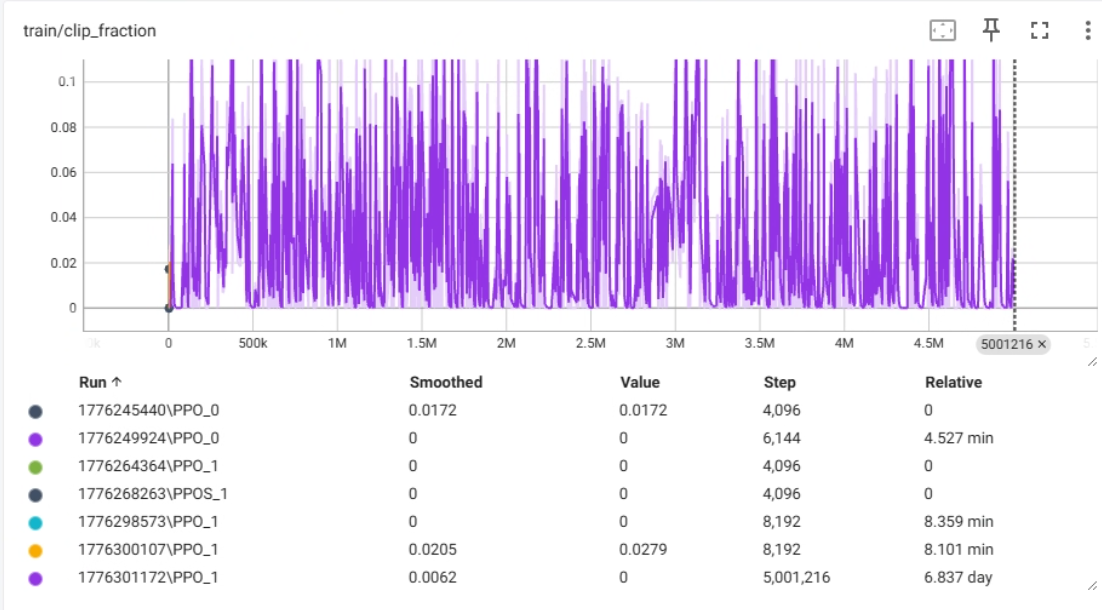
train/clip_fraction 指标解释
train/clip_fraction 是 PPO(Proximal Policy Optimization,近端策略优化)算法中的一个重要指标。
- 含义:它表示在当前的训练批次中,有多少比例的梯度更新被“裁剪”了。
- PPO 原理简述:PPO 为了防止策略更新步幅过大导致训练崩溃,引入了一个“裁剪”机制。它限制了新旧策略概率比率的变化范围(通常在 0.8 到 1.2 之间)。如果某个更新的比率超出了这个范围,就会被强行拉回到边界值,这就是“裁剪”。
- 这个指标的意义:
- 数值过高(接近 1.0):说明绝大多数更新都被裁剪了。这通常意味着学习率太高,或者 PPO 的裁剪范围(epsilon)太小。模型想要迈大步子,但被强行拉住,可能导致学习效率低下。
- 数值过低(接近 0):说明几乎没有更新被裁剪。这可能意味着学习率太低,或者策略更新非常保守。虽然训练稳定,但可能收敛速度很慢。
- 理想状态:通常希望这个值在一个适中的范围(例如 0.1 - 0.3 左右,但这取决于具体任务),表明模型正在积极地学习,同时受到 PPO 机制的有效约束。
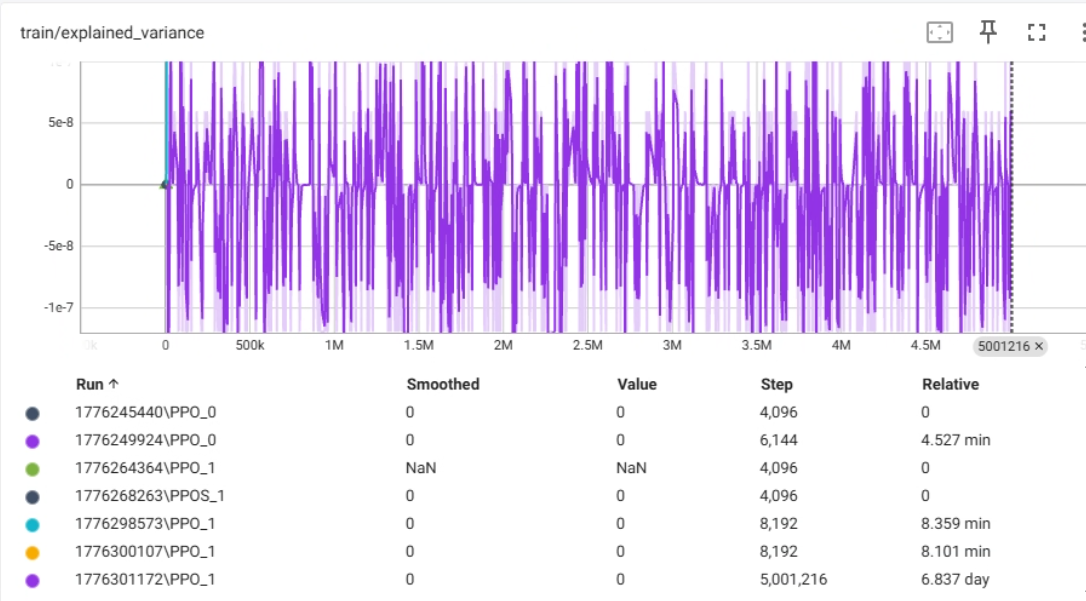
train/explained_variance 核心指标解释
train/explained_variance 衡量的是你的价值网络(Critic)预测的值与实际获得的回报之间的相关性。这是强化学习(尤其是 PPO 算法)中用于评估价值函数(Value Function / Critic)拟合好坏的重要指标。
- 数值为 1:完美预测。模型完全理解了环境,能准确预测未来的收益。
- 数值为 0:预测效果就像“瞎猜平均值”。模型没有学到任何有用的规律,预测值和随便猜一个平均数没区别。
- 数值为负数:预测比瞎猜还差。模型不仅没学会,甚至还在“误导”自己(预测值与实际值反向变动)。
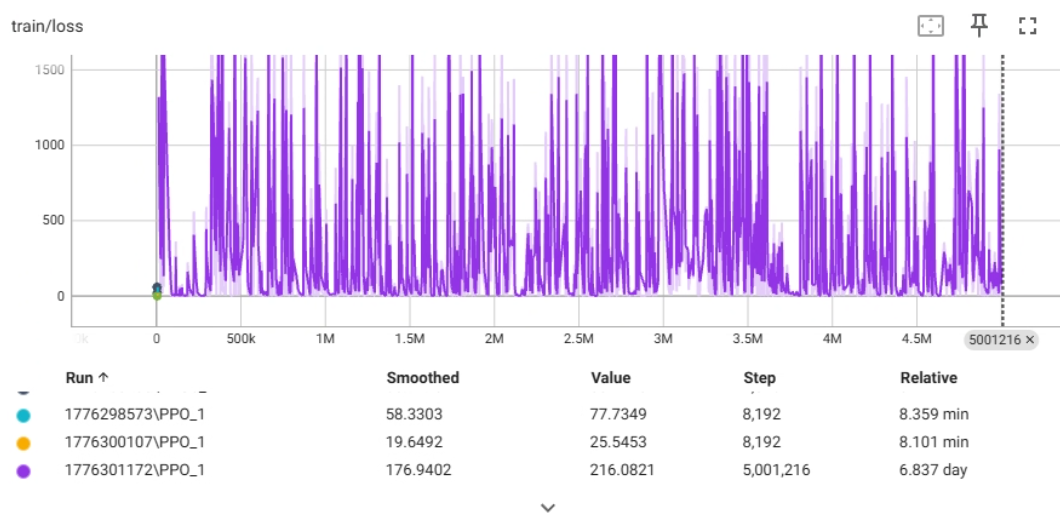
train/loss 指标解释
train/loss,这是整个训练过程中最核心的指标之一。
简单来说,Loss(损失)代表了模型“犯错”的程度。Loss 越低,说明模型预测得越准,犯错越少;Loss 越高,说明模型越困惑,预测越离谱。
在 PPO 算法中,这个 Loss 通常是 策略损失(Policy Loss) 和 价值函数损失(Value Loss) 的总和。
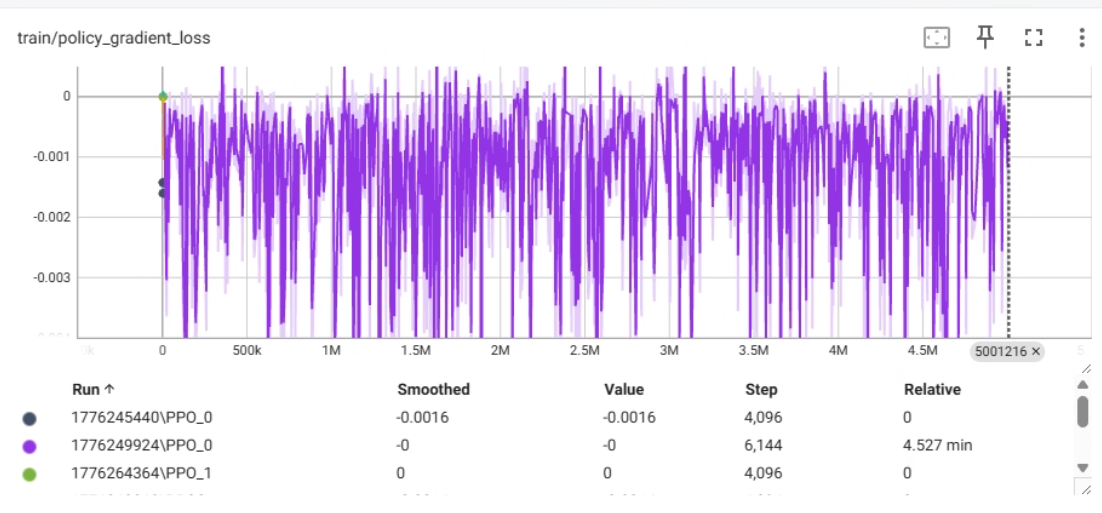
train/policy_gradient_loss 指标解释
train/policy_gradient_loss,这是 PPO 算法中专门衡量策略网络(Actor)更新力度的指标。
简单来说,它反映了模型为了获得更多奖励,想要改变自身行为的强烈程度。
核心指标解释
- 含义:这是 PPO 目标函数中的核心部分。它计算的是在考虑了“优势”(Advantage,即某个动作比平时好多少)之后,策略网络应该被更新多少。
- 数值通常为负:在 PPO 的实现中,为了使用梯度下降算法来最大化奖励,通常会对目标函数取反,所以你会看到这个 Loss 是负数。
- 解读:
- 绝对值越大(越负):说明模型认为当前的策略很糟糕,或者发现了巨大的改进空间,因此想要进行大幅度的修改。
- 绝对值越小(接近 0):说明模型认为当前的策略已经不错了,或者在这个批次的数据中没有学到什么新的有用信息,不需要做大的改动。
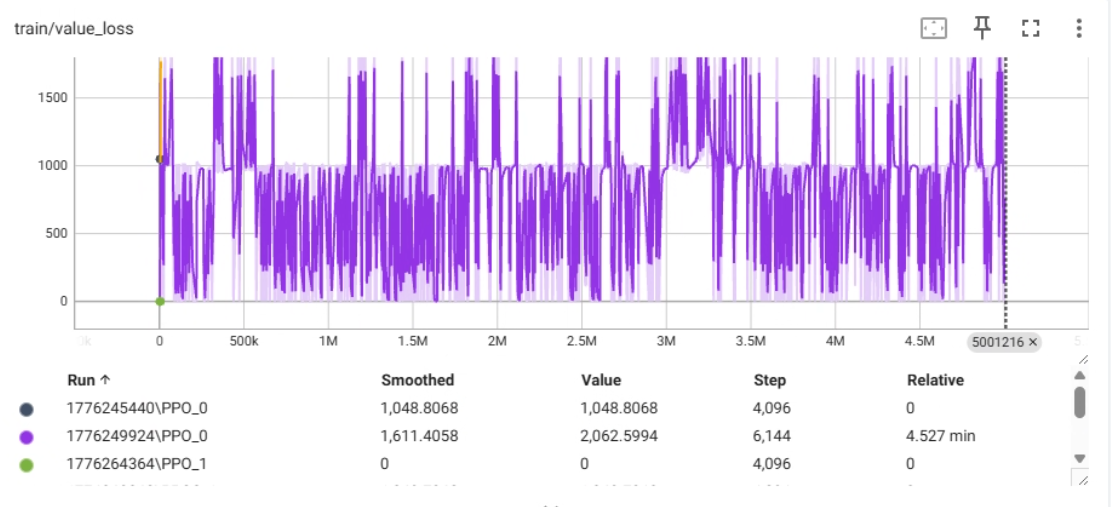
train/value_loss 指标解释
train/value_loss,它直接衡量的是 Critic(价值网络) 的预测误差。
这张图是整个训练问题的“罪魁祸首”,它揭示了为什么之前的总 Loss 会那么高。
- 含义:Critic 的工作是预测未来能获得多少奖励(Value)。
value_loss衡量的是 Critic 的预测值与实际获得的回报(Return)之间的差距(通常使用均方误差 MSE)。 - 解读:
- 数值越低越好:说明 Critic 预测得很准。
- 数值高:说明 Critic 完全是在“瞎猜”,预测值和真实结果天差地别。
在vscode也可以看到每个指定步数存下的模型
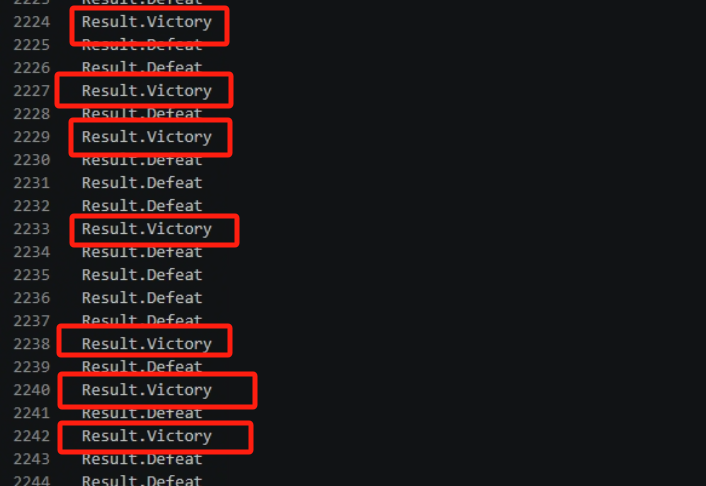
在result.txt中也可以看到victory的频次明显增加了
完整训练代码
WorkerRushBot.py
from sc2 import maps
from sc2.player import Bot, Computer
from sc2.main import run_game
from sc2.data import Race, Difficulty
from sc2.bot_ai import BotAI
import pickle
import time
import random
import numpy as np
from sc2.ids.unit_typeid import UnitTypeId
import math
import cv2
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import nest_asyncio
import asyncio
nest_asyncio.apply()
class WorkerRushBot(BotAI):
async def on_step(self, iteration: int):
try:
with open('transaction.pkl', 'rb') as f:
transaction = pickle.load(f)
except:
return
action = transaction['action']
if action is None:
return # 没有动作,直接跳过
action=transaction['action']
#print(f'迭代次数:{iteration}')
await self.distribute_workers()
if action==0:
have_builded = False
# 1. 优先补水晶塔
if self.supply_left < 4:
if self.can_afford(UnitTypeId.PYLON) and self.already_pending(UnitTypeId.PYLON) == 0:
if self.townhalls.exists:
await self.build(UnitTypeId.PYLON, near=self.townhalls.first)
have_builded = True
# --------------------------
# ✅ 【扩张分矿】永远不阻塞!
# --------------------------
if self.townhalls.amount < 4 and self.can_afford(UnitTypeId.NEXUS):
if self.already_pending(UnitTypeId.NEXUS) == 0:
await self.expand_now()
# --------------------------
# 【农民 / 气矿】独立运行
# --------------------------
for nexus in self.townhalls:
# 农民
if self.workers.closer_than(10, nexus).amount < 22:
if self.can_afford(UnitTypeId.PROBE) and nexus.is_idle:
nexus.train(UnitTypeId.PROBE)
# 气矿
for vespene in self.vespene_geyser.closer_than(15, nexus):
if self.can_afford(UnitTypeId.ASSIMILATOR):
worker = self.select_build_worker(vespene.position)
if worker is not None:
# 神族造气矿 官方唯一正确方法
worker.build_gas(vespene)
worker.stop(queue=True)
have_builded=False
#print('建造吸收间')
# --------------------------
# 【防御】不阻塞扩张
# --------------------------
pylon = self.structures(UnitTypeId.PYLON).ready
if pylon.exists and not have_builded:
near_pylon = pylon.first
# 熔炉
if not self.structures(UnitTypeId.FORGE).exists:
if self.can_afford(UnitTypeId.FORGE):
await self.build(UnitTypeId.FORGE, near=near_pylon)
have_builded = True
# 光子炮
elif self.structures(UnitTypeId.FORGE).ready:
if self.structures(UnitTypeId.PHOTONCANNON).amount < 3:
if self.can_afford(UnitTypeId.PHOTONCANNON):
await self.build(UnitTypeId.PHOTONCANNON, near=near_pylon)
have_builded = True
if action==1:
# 1:传送门、控制核心、星门
have_build = False # 正确拼写
# 全局最多造 4 个星门(暴兵效率最大化)
max_stargates = 4
current_stargates = self.structures(UnitTypeId.STARGATE).amount
for nexus in self.townhalls:
# 每个基地都造传送门
if not have_build:
if not self.structures(UnitTypeId.GATEWAY).closer_than(10, nexus).exists:
if self.can_afford(UnitTypeId.GATEWAY) and self.already_pending(UnitTypeId.GATEWAY) == 0:
await self.build(UnitTypeId.GATEWAY, near=nexus)
have_build = True # 正确拼写
# 每个基地都造控制核心
if not have_build:
if not self.structures(UnitTypeId.CYBERNETICSCORE).closer_than(10, nexus).exists:
if self.can_afford(UnitTypeId.CYBERNETICSCORE) and self.already_pending(UnitTypeId.CYBERNETICSCORE) == 0:
await self.build(UnitTypeId.CYBERNETICSCORE, near=nexus)
have_build = True
# ✅ 关键修复:允许造多个星门,直到 4 个
if not have_build:
if current_stargates < max_stargates: # 不限制“是否已有”,只限制总数
if self.can_afford(UnitTypeId.STARGATE) and self.already_pending(UnitTypeId.STARGATE) == 0:
await self.build(UnitTypeId.STARGATE, near=nexus)
have_build = True
if action==2:
#print(f'action={action}')
#2:虚空辉光舰
try:
# 遍历所有【已建成、空闲】的星门
for sg in self.structures(UnitTypeId.STARGATE).ready.idle:
# 如果钱够造虚空辉光舰
if self.can_afford(UnitTypeId.VOIDRAY):
# 让星门训练虚空辉光舰
sg.train(UnitTypeId.VOIDRAY)
#print('训练虚空战舰')
except Exception as e:
print(e)
if action==3:
#print(f'action={action}')
#3:侦查
# 1. 初始化 last_sent 时间戳(防止第一次运行报错)
try:
self.last_sent
except:
self.last_sent = 0
# 2. 控制侦查频率:距离上次侦查超过100帧才执行
if (iteration - self.last_sent) > 100:
try:
# 3. 优先选择空闲的探机
if self.units(UnitTypeId.PROBE).idle.exists:
probe = random.choice(self.units(UnitTypeId.PROBE).idle)
# 4. 没有空闲探机,就随机选一个探机
else:
probe = random.choice(self.units(UnitTypeId.PROBE))
# 5. 命令探机攻击/移动到敌人出生点
probe.attack(self.enemy_start_locations[0])
# 6. 更新最后一次侦查的帧号
self.last_sent = iteration
#print('侦查')
except:
pass
#4:进攻
if action == 4:
#print(f'action={action}')
try:
if(self.units(UnitTypeId.VOIDRAY).amount>1):
for voidray in self.units(UnitTypeId.VOIDRAY).idle:
# 优先级1:身边10格内有敌人单位 → 随机选一个攻击
if self.enemy_units.closer_than(10, voidray):
voidray.attack(random.choice(self.enemy_units.closer_than(10, voidray)))
# 优先级2:身边10格内有敌人建筑 → 随机选一个攻击
elif self.enemy_structures.closer_than(10, voidray):
voidray.attack(random.choice(self.enemy_structures.closer_than(10, voidray)))
# 优先级3:地图上有敌人单位 → 随机选一个攻击(A地板)
elif self.enemy_units:
voidray.attack(random.choice(self.enemy_units))
# 优先级4:地图上有敌人建筑 → 随机选一个攻击(拆家)
elif self.enemy_structures:
voidray.attack(random.choice(self.enemy_structures))
# 优先级5:找不到敌人 → 去敌人出生点
elif self.enemy_start_locations:
voidray.attack(self.enemy_start_locations[0])
#print('虚空辉光舰进攻')
except Exception as e:
print(e)
#5:撤退
if action == 5:
#print(f'action={action}')
try:
if self.units(UnitTypeId.VOIDRAY).amount > 0:
for voidray in self.units(UnitTypeId.VOIDRAY):
voidray.attack(self.start_location)
#print('撤退')
except Exception as e:
print(e)
# 画图:生成地图状态观测
# 1. 初始化空白地图
map = np.zeros(
(self.game_info.map_size[0], self.game_info.map_size[1], 3),
dtype=np.uint8
)
# 2. 绘制矿产资源(水晶矿)
for mineral in self.mineral_field:
pos = mineral.position # 获取矿点的坐标(x,y)
c = [175, 255, 255] # 基础颜色:青蓝色(代表水晶矿)
# 计算剩余矿量比例:当前矿量 / 初始满矿量(2250)
fraction = mineral.mineral_contents / 2250
if mineral.is_visible:
# 可见矿:按剩余矿量比例,调整颜色亮度(矿越多越亮)
map[math.ceil(pos.y)][math.ceil(pos.x)] = [int(fraction * i) for i in c]
else:
# 不可见/战争迷雾中的矿:显示灰色(代表未知)
map[math.ceil(pos.y)][math.ceil(pos.x)] = [50, 50, 50]
#3:绘制瓦斯资源
for vespene in self.vespene_geyser:
pos = vespene.position # 获取气矿的坐标(x,y)
c = [255, 175, 255] # 基础颜色:粉紫色(代表气矿)
# 计算剩余气矿量比例:当前气矿量 / 初始满矿量(2250)
fraction = vespene.vespene_contents / 2250
if vespene.is_visible:
# 可见气矿:按剩余气矿量比例,调整颜色亮度(气越多越亮)
map[math.ceil(pos.y)][math.ceil(pos.x)] = [int(fraction * i) for i in c]
else:
# 不可见/战争迷雾中的气矿:显示灰色(代表未知)
map[math.ceil(pos.y)][math.ceil(pos.x)] = [50, 50, 50]
#4:绘制基础设施
for structure in self.structures:
pos = structure.position # 获取建筑的坐标(x,y)
# 区分建筑类型:基地(nexus)用特殊颜色,其他建筑用另一种颜色
if structure.type_id == UnitTypeId.NEXUS:
c = [255, 255, 175] # 亮黄色(代表基地/主基地)
else:
c = [0, 255, 175] # 青绿色(代表其他己方建筑,如水晶塔、传送门、星门等)
# 计算血量比例:当前血量 / 最大血量(避免除零)
fraction = structure.health_percentage
# 按血量比例缩放颜色,绘制到地图上
map[math.ceil(pos.y)][math.ceil(pos.x)] = [int(fraction * i) for i in c]
#5:绘制我方单位
for unit in self.units:
pos = unit.position # 获取单位的坐标(x,y)
# 区分单位类型:虚空辉光舰用特殊蓝色,其他单位用亮绿色
if unit.type_id == UnitTypeId.VOIDRAY:
c = [255, 0, 0] # 蓝色(代表核心作战单位:虚空辉光舰)
else:
c = [175, 255, 0] # 亮绿色(代表其他己方单位:探机等)
# 直接获取血量百分比(0~1),无需手动计算
fraction = unit.health_percentage
# 按血量比例缩放颜色,绘制到地图上
map[math.ceil(pos.y)][math.ceil(pos.x)] = [int(fraction * i) for i in c]
#6:绘制敌人的起始位置(出生点)
for enemy_location in self.enemy_start_locations:
pos = enemy_location # 获取敌人出生点坐标
# 纯红色(代表敌人老家,显眼)
c = [0, 0, 255]
# 直接赋值,不需要遍历i
map[math.ceil(pos.y)][math.ceil(pos.x)] = c
#7:绘制敌人的基础设施(建筑)
for structure in self.enemy_structures:
pos = structure.position
# 亮红色(代表敌人建筑)
c = [0, 100, 255]
# 按血量比例缩放颜色(满血最亮,残血变暗)
fraction = structure.health_percentage
map[math.ceil(pos.y)][math.ceil(pos.x)] = [int(fraction * i) for i in c]
#8:绘制敌人的单位(兵力)
for unit in self.enemy_units:
pos = unit.position
# 橙红色(代表敌人活跃的单位/部队)
c = [100, 0, 255]
# 按血量比例缩放颜色
fraction = unit.health_percentage
map[math.ceil(pos.y)][math.ceil(pos.x)] = [int(fraction * i) for i in c]
# 计算奖励值
reward = 0 # 初始化奖励为0
try:
# 遍历所有己方的虚空辉光舰
for voidray in self.units(UnitTypeId.VOIDRAY):
# 条件1:虚空舰正在攻击,且目标在攻击范围内(有效攻击)
if voidray.is_attacking and voidray.target_in_range:
# 条件2:虚空舰8格范围内有敌人单位/建筑(在战场中,不是空跑)
if self.enemy_structures.closer_than(8, voidray) or self.enemy_units.closer_than(8, voidray):
# 满足所有条件,给奖励
reward += 0.015
except Exception as e:
# 捕获异常(比如没有虚空舰、敌人不存在),避免崩溃
print(f'reward error:{e}')
reward = 0 # 异常时奖励归零
# 每10帧打印一次日志,方便调试
if iteration % 10 == 0:
print(f'iteration:{iteration},RW:{reward},VR:{self.units(UnitTypeId.VOIDRAY).amount}')
# 9. 显示地图(缩放+翻转,适配OpenCV显示)
cv2.imshow(
'map',
cv2.flip(
cv2.resize(
map,
None,
fx=4, fy=4, # 放大3倍,方便观察
interpolation=cv2.INTER_NEAREST # 最近邻插值,保留像素块
),
0 # 0=上下翻转,修正坐标系
)
)
cv2.waitKey(1) # 等待1ms,刷新窗口(必须加,否则窗口卡死)
transaction['action']=None
with open('transaction.pkl','wb') as f:
pickle.dump(transaction,f)
if __name__ == "__main__":
print('WorkerRushBot.py start')
result=run_game(maps.get("2000AtmospheresAIE"), [
Bot(Race.Protoss, WorkerRushBot()),
Computer(Race.Zerg, Difficulty.Hard)
], realtime=False)
# 1. 记录比赛结果到日志文件
with open('result.txt', 'a') as f:
f.write(f'{result}\n')
# 2. 发放终局奖励/惩罚
if str(result) == 'Result.Victory':
print('Victory!')
rwd = 500 # 胜利,给+500大额奖励
else:
rwd = -500 # 失败/平局,给-500大额惩罚
# 3. 生成最终观测与交易数据,保存为pkl文件
map = np.zeros((244,244,3), dtype = np.uint8)
transaction = {'observation':map, 'reward':rwd, 'action':None, 'terminated':True,'truncated':False}
with open('transaction.pkl', 'wb') as f:
pickle.dump(transaction, f)
# 4. 清理OpenCV窗口,避免残留
cv2.destroyAllWindows()
cv2.waitKey(1)
time.sleep(1)StarCraft2Env.py
import numpy as np
import gymnasium as gym
import time
import pickle
import subprocess
import os # 用于检查文件
class StarCraft2Env(gym.Env):
def __init__(self):
super(StarCraft2Env, self).__init__()
self.observation_space = gym.spaces.Box(low=0, high=255, shape=(244, 244, 3), dtype=np.uint8)
self.action_space = gym.spaces.Discrete(6)
# 1. 在类初始化时定义超时变量
self.wait_time = 0
self.process = None
def step(self, action):
# --- 阶段 1:发送动作 ---
start_time = time.time()
self.wait_time = 0
while True:
try:
# 读取当前状态
with open('transaction.pkl', 'rb') as f:
transaction = pickle.load(f)
# 只有当 Bot 把 action 变回 None 时,我们才写入新动作
if transaction.get('action') is None:
transaction['action'] = action
with open('transaction.pkl', 'wb') as f:
pickle.dump(transaction, f)
break # 动作发送成功,跳出循环
except Exception as e:
pass # 文件被占用或不存在,忽略
time.sleep(0.05)
self.wait_time = time.time() - start_time
# 【修复】发送动作也要有超时,防止 Bot 死了不回 None
if self.wait_time > 30:
print("!!! 超时:Bot 未能在 30秒内接收动作,可能已卡死。")
self.close()
return self.reset()[0], 0, True, False, {}
# --- 阶段 2:等待结果 ---
start_time = time.time()
self.wait_time = 0
while True:
try:
with open('transaction.pkl', 'rb') as f:
transaction = pickle.load(f)
# 当 Bot 处理完动作,会将 action 设回 None,并填入新数据
if transaction.get('action') is None:
observation = transaction['observation']
reward = transaction['reward']
terminated = transaction['terminated']
truncated = transaction['truncated']
return observation, reward, terminated, truncated, {}
except Exception as e:
pass # 忽略读取错误
time.sleep(0.05)
self.wait_time = time.time() - start_time
# 【修复】等待结果超时
if self.wait_time > 60:
print(f"!!! ERROR: 环境超时 (等待结果 > 60s),强制重置。")
self.close()
# 返回随机/零观测,并标记 done=True,让 RL 重新开始
dummy_obs = np.zeros((244, 244, 3), dtype=np.uint8)
return dummy_obs, 0, True, False, {}
def reset(self, seed=None, options=None):
print('--- Resetting Environment ---')
self.wait_time = 0 # 【修复】重置计时器
# 1. 杀掉旧进程
self.close()
# 2. 初始化文件
# 创建一个初始的 transaction 文件,确保 Bot 启动时能读到
map_data = np.zeros((244, 244, 3), dtype=np.uint8)
transaction = {
'observation': map_data,
'reward': 0,
'action': None,
'terminated': False,
'truncated': False
}
with open('transaction.pkl', 'wb') as f:
pickle.dump(transaction, f)
# 3. 启动新进程
# 使用 shell=True 和 start 命令在 Windows 下启动新窗口
try:
subprocess.Popen(
['cmd', '/c', 'start', 'python', 'WorkerRushBot.py'],
shell=True
)
print("Bot 进程已启动...")
except Exception as e:
print(f"启动 Bot 失败: {e}")
# 4. 等待 Bot 初始化(给 Bot 一点时间加载游戏)
time.sleep(5)
return map_data, {}
def close(self):
# 【新增】确保能杀掉旧进程
if self.process:
try:
self.process.kill()
print("旧进程已杀掉")
except:
pass
self.process = NoneSC2_Training.ipynb
依赖库导入
# 1. 导入依赖库
from stable_baselines3 import PPO
import os
import time
from StarCraft2Env import StarCraft2Env
import torch as th
import torch.nn as nn
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor定义保存路径
model_name = f'{int(time.time())}'
model_dir = f'models/{model_name}/'
logs_dir = f'logs/{model_name}/'
if not os.path.exists(model_dir):
os.makedirs(model_dir)
if not os.path.exists(logs_dir):
os.makedirs(logs_dir)创建环境实例
env = StarCraft2Env()创建模型实例
model = PPO("MlpPolicy", env, verbose=1, tensorboard_log=logs_dir)开始训练
TIMESTEPS = 5000000 # 500万步
print(f"开始训练,目标:{TIMESTEPS} 步...")
try:
model.learn(total_timesteps=TIMESTEPS)
except KeyboardInterrupt:
print("手动停止训练")
finally:
env.close() # 确保调用环境的关闭函数,杀掉 SC2 进程
print("训练结束!")
model.save("final_model")保存模型
model.save(f'{model_dir}/{TIMESTEPS*iters}')
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)