Deep Agents 框架-基础篇
引言
本节主要介绍deepagents,这是新出来的,更上层的API。前面已经讲过langchain和langgraph,这里涉及重复的地方可能只会简单介绍一下。langchain、langgraph、deepagents三者之间的关系从功能定位上容易看出他们之间的抽象层级关系 langgraph --> langchain-->deepagents。deeagents定义是更高级别抽象,是harness架构的一个实践者。官方的建议是简单的用langchain,复杂的工作流用langgraph,更高级的长期运行的任务用deepagents(包括环境隔离,上下文管理、虚拟文件系统、沙箱环境等)。这句话你咋一看好像是懂了,但是当你接触到一些API示例的时候,你发现这段话的埋的坑特别深。因为你一开始的时候,你并不知道你的系统有多复杂,于是你信了他的鬼话(已近写了很多代码),后面你发现你的东西越来越复杂,你需要用图,这时候开始使用图API改造你langchain代码,这时候后你就开始意识到我为啥不一开始就用langgraph写以前我的逻辑(统一风格),我浪费这个时间重写我这个代码干嘛?用图的API写langchain代码比起重构那肯定是比起重构要节约很多时间(pyhon体系的毛病来了,默认忽略工程化,虽然一直在努力)。现在又来了一个deepagents,这个更高级的API鼓吹是提供了更多更高级的功能,所以你的第一印象是deepagents应该是会更好用,不用关心langchain、langgraph、代码全部用deepagents写。如果你这样想,那就是太天真了,如果你不懂langchain、langgraph,你根本没法玩deepagents。deepagents这玩意至少到目前为止,不是一个独立完整的框架。理想的场景是即使deepagents依赖于langgraph、langchain,也要把他们的能力包装到deepagents,对使用者来说,看到deepagents就行了。但是实际上不是的,deepagents的代码多半会存在langchain和langgraph代码,所以说用deepagents,你还得懂langchain和langgraph,学习成本相当高(每一门估计至少一周以上)。deepagents某种意义上来说不是一个完整的框架。从他与langchain和langgraph组合使用情况来看,他更像另外一个库,但是他的定位又是更高级,易用的API。综合起来像是个半吊子框架,相互穿插,有些混乱。deepagents如果从使用层面不能独立出来,那么他的学习成本和维护成本都是高昂的。另一个层面就是体现了工程化问题。
以上基本上是我对这个这个体系的最近研究的一些感悟,了解的目的最主要是主要是了解其到底能做到什么程度,做好工程化选择。这只是我个人的一个观点,仅供参考,如果确实如我所说,那么工程化问题就值得深思。
1 概览
这是开始构建由大语言模型驱动的智能体和应用的最简单方法——它内置了任务规划、用于上下文管理的文件系统、子智能体生成以及长期记忆等能力。你可以将 deep agents 用于任何任务,包括复杂的、多步骤的任务。我们将 deepagents 视为一种“智能体框架”。它拥有与其他智能体框架相同的核心工具调用循环,但额外提供了内置的工具和功能。deepagents 是一个独立的库,构建于 LangChain 的核心智能体模块之上。它利用 LangGraph 运行时来实现持久化执行、流式传输、人机协同等功能。
deepagents 代码仓库包含以下内容:
- Deep Agents SDK: 一个用于构建能够处理任何任务的智能体的软件包。
- Deep Agents CLI: 一个基于 Deep Agents SDK 构建的终端编码智能体。
- ACP 集成: 一个代理客户端协议连接器,用于在 Zed 等代码编辑器中使用 deep agents。
LangChain 是提供智能体核心构建模块的框架。要了解 LangChain、LangGraph 和 Deep Agents 之间的区别,请参阅“框架、运行时和框架”
这玩意应该是 Agent harnesses 智能体驾驭的衍生品,概念还比较新。
1.1 创建agent
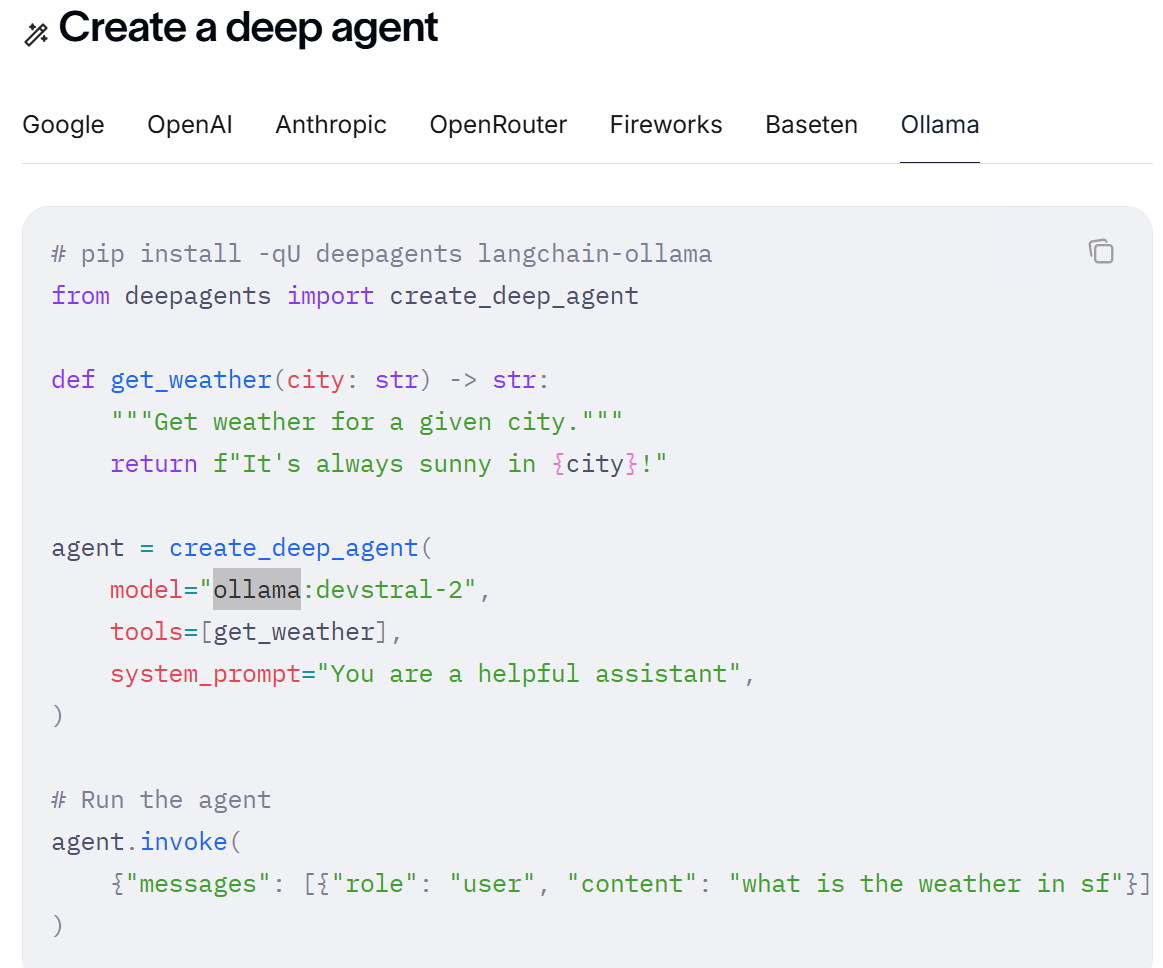
上面看起来和原始langchain agent很像
1.2 何时使用 Deep Agents
当您希望构建具备以下能力的智能体时,请使用 Deep Agents SDK:
🧩 处理复杂任务
- 处理需要规划和拆解的复杂多步骤任务。
- 将工作委派给专门的子智能体,以实现上下文隔离。
🧠 上下文与记忆管理
- 通过文件系统工具和摘要功能管理大量上下文信息。
- 在对话和线程之间持久化记忆。
🛠️ 基础设施与工具
- 灵活切换文件系统后端,支持内存状态、本地磁盘、持久化存储、沙箱或您自己的自定义后端。
- 在使用沙箱后端时,通过
execute工具执行 Shell 命令。 - 模型无关性:支持使用任何具备工具调用功能的模型,兼容各类前沿模型和开源模型。
🔒 安全与人工干预
- 通过声明式权限规则控制文件系统访问,限制智能体可读写的文件范围。
- 通过人机回环工作流,要求对敏感操作进行人工审批。
提示: 对于构建更简单的智能体,建议考虑使用 LangChain 的
create_agent或构建自定义的 LangGraph 工作流。
1.3 核心能力
Deep Agents SDK 提供了一系列强大的功能,旨在构建高效、安全且智能的代理。
🧩 规划与任务拆解
- 内置待办工具: 包含内置的
write_todos工具,使代理能够将复杂任务分解为独立的步骤。 - 动态适应: 支持跟踪进度,并随着新信息的出现调整计划。
🧠 上下文管理
- 文件系统工具: 提供
ls、read_file、write_file、edit_file等工具,允许代理将大量上下文卸载到内存或文件系统存储中。 - 防止溢出: 防止上下文窗口溢出,并支持处理可变长度的工具结果。
- 自动摘要: 当上下文窗口过长时,自动压缩旧的对话消息,确保代理在长时间会话中保持高效。
💻 Shell 执行
- 沙箱后端: 在使用沙箱后端时,代理会获得
execute工具来运行 Shell 命令(用于测试、构建、Git 操作和系统任务)。 - 安全隔离: 沙箱后端提供隔离环境,使代理能够执行代码而不会危及您的主机系统。
🔌 可插拔文件系统后端
- 灵活切换: 虚拟文件系统由可插拔后端提供支持,您可以根据用例进行切换。
- 多种选择: 可选择内存状态、本地磁盘、用于跨线程持久化的 LangGraph 存储、用于隔离代码执行的沙箱(如 Modal、Daytona、Deno),或通过复合路由组合多个后端。
- 自定义: 您也可以实现自己的自定义后端。
👥 子智能体生成
- 上下文隔离: 内置的
task工具使代理能够生成专门的子智能体,以实现上下文隔离。 - 专注任务: 这能保持主代理的上下文清洁,同时深入处理特定的子任务。
🗄️ 长期记忆
- 跨线程持久化: 使用 LangGraph 的 Memory Store 扩展代理,实现跨线程的持久化记忆。
- 信息存取: 代理可以保存和检索以前对话中的信息。
🔒 文件系统权限
- 规则声明: 声明权限规则,控制代理可以读写哪些文件和目录。
- 继承与覆盖: 子智能体可以继承或覆盖父代理的规则。
🤝 人机回环
- 人工审批: 利用 LangGraph 的中断功能,配置对敏感工具操作的人工审批。
- 执行控制: 控制哪些工具在执行前需要确认。
🛠️ 技能
- 功能扩展: 通过可重用的技能扩展代理,提供专门的工作流、领域知识和自定义指令。
💡 智能默认设置
- 预设提示词: 附带了经过优化的系统提示词,教导模型如何有效地使用其工具——在行动前规划、验证工作并管理上下文。
- 灵活定制: 您可以根据需要自定义或替换这些默认设置。
1.4 langchain vs langgraph vs deep agents
LangChain 维护着几个开源包,旨在帮助你构建智能体。它们在智能体开发栈中各自扮演着不同的角色。理解“智能体框架”、“智能体运行时”和“智能体驾驭”之间的区别,能帮你根据需求选择最合适的工具。
1.4.1 核心概念对比
| 类别 | 框架 | 运行时 | 驾驭 |
|---|---|---|---|
| 核心价值 | 抽象化 集成 |
持久化执行 流式传输 人机协同 持久化存储 |
预定义工具 提示词 子智能体 |
| 适用场景 | 快速上手 团队开发标准化 |
底层控制 长运行、有状态的工作流和智能体 |
更自主的智能体 处理复杂、非确定性任务的智能体 |
| 代表产品 | LangChain Vercel AI SDK CrewAI OpenAI Agents SDK Google ADK LlamaIndex |
LangGraph Temporal Inngest |
Deep Agents SDK Claude Agent SDK Manus |
1.4.2 智能体框架(例如 LangChain)
智能体框架提供了抽象化封装,让你在使用大语言模型进行开发时更容易上手。
LangChain 就是一个智能体框架,它提供了诸如结构化内容块、智能体循环和中间件等抽象概念。LangChain 的抽象设计旨在兼顾易用性与高级用例所需的灵活性。
虽然 LangChain 构建于 LangGraph 之上,但在使用 LangChain 时,你并不需要深入了解 LangGraph。
其他智能体框架的例子还包括 Vercel 的 AI SDK、CrewAI、OpenAI Agents SDK、Google ADK、LlamaIndex 等等
何时使用 LangChain
在以下情况请使用 LangChain:
- 你想快速构建智能体和自主应用。
- 你需要针对模型、工具和智能体循环的标准抽象。
- 你想要一个既易用又具备灵活性的框架。
- 你正在构建不需要复杂编排的简单智能体应用。
1.4.3 智能体运行时(例如 LangGraph)
智能体运行时提供了在生产环境中运行智能体所需的工具。支持的功能可能包括:
- 持久化执行: 智能体在遇到故障时能保持状态,可以长时间运行,并能从中断处恢复。
- 流式传输: 支持工作流和响应的流式输出。
- 人机协同: 通过检查和修改智能体状态来引入人工监督。
- 持久化存储: 用于状态管理的线程级和跨线程持久化。
- 底层控制: 直接控制智能体编排,无需高层抽象。
LangGraph 是一个用于构建、管理和部署长运行、有状态智能体的底层编排框架和运行时。
智能体框架通常层级更高,并且运行在智能体运行时之上。例如,LangChain 1.0 就是构建在 LangGraph 之上的。
其他智能体运行时的例子包括 Temporal、Inngest 以及其他持久化执行引擎。
何时使用 LangGraph
在以下情况请使用 LangGraph:
- 你需要对智能体编排进行细粒度的底层控制。
- 你需要为长运行、有状态的智能体提供持久化执行能力。
- 你正在构建结合了确定性步骤和智能体步骤的复杂工作流。
- 你需要用于智能体部署的生产级基础设施。
1.4.4 智能体驾驭(例如 Deep Agents SDK)
智能体框架是一种带有鲜明观点、“开箱即用”的框架,内置了构建复杂、长运行智能体所需的工具和能力。支持的功能可能包括:
- 规划能力: 通过待办事项列表跟踪多个任务。
- 任务委派: 通过子智能体委派工作并保持上下文整洁。
- 文件系统: 在不同的可插拔存储后端上读写文件。
- 令牌管理: 对话历史摘要和大型工具结果的移除。
Deep Agents SDK 构建在 LangGraph 之上,并增加了规划能力、用于上下文管理的文件系统、生成子智能体的能力等。Deep Agents 专为需要规划和拆解的复杂多步骤任务而设计。
任务示例包括处理搜索结果、脚本以及状态中的其他产物。
其他智能体框架的例子包括 Claude Agent SDK、Manus 以及其他编码命令行界面。
何时使用 Deep Agents SDK
在以下情况请使用 Deep Agents SDK:
- 你正在构建长时间运行的智能体。
- 你正在构建需要处理复杂多步骤任务的智能体。
- 你想使用预定义的工具,如文件系统操作、Bash 执行和自动化上下文工程。
- 你想使用预定义的提示词和子智能体。
2 起步
本指南将带您创建第一个具备规划、文件系统工具和子智能体功能的深度代理。您将构建一个能够进行研究和撰写报告的研究代理
🤖 使用 AI 编程助手?
如果您正在使用 AI 编程助手,建议安装以下组件以增强其能力:
📚 安装 LangChain 文档 MCP 服务器
- 目的: 让您的代理能够访问最新的 LangChain 文档和示例。
- 作用: 确保代理获取的信息是最新的,减少幻觉。
-
目的: 提高您的代理在 LangChain 生态系统任务中的表现。
- 作用: 赋予代理更专业的领域知识和处理能力。
2.1 先决条件
在开始之前,请确保您已具备以下条件:
🔑 API 密钥
- 您必须拥有一个模型提供商(例如 Gemini、Anthropic 或 OpenAI)的 API 密钥。
🛠️ 模型要求
1 安装依赖
pip install deepagents tavily-python本指南使用 Tavily 作为示例搜索提供商,但您可以替换为任何搜索 API(例如 DuckDuckGo、SerpAPI、Brave Search)。
2 设置API KE 3 创建搜索工具
3 创建搜索工具
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)4 创建deep agent
# System prompt to steer the agent to be an expert researcher
research_instructions = """You are an expert researcher. Your job is to conduct thorough research and then write a polished report.
You have access to an internet search tool as your primary means of gathering information.
## `internet_search`
Use this to run an internet search for a given query. You can specify the max number of results to return, the topic, and whether raw content should be included.
"""您可以传入 provider:model 格式的模型字符串,或者传入一个已初始化的模型实例。有关所有提供商支持的模型以及经过测试的推荐模型,请参阅“支持的模型”部分。
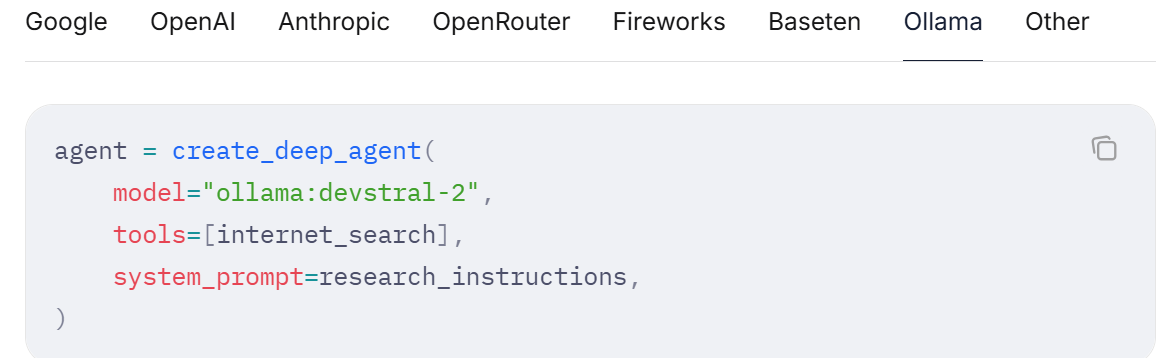
5 运行agent
result = agent.invoke({"messages": [{"role": "user", "content": "What is langgraph?"}]})
# Print the agent's response
print(result["messages"][-1].content)🤔 它是如何工作的?
您的深度代理会自动执行以下步骤:
📝 规划方法
使用内置的 write_todos 工具将研究任务分解为具体的步骤。
🔍 开展研究
调用 internet_search 工具来收集信息。
🧠 管理上下文
使用文件系统工具(write_file、read_file)将大量的搜索结果卸载存储,以防止上下文溢出。
👥 生成子智能体
根据需要生成子智能体,将复杂的子任务委派给专门的子智能体处理。
📄 综合报告
将调查结果汇编成连贯的响应,最终生成一份报告。
2.2 示例
有关您可以使用 Deep Agents 构建的代理、模式和应用,请参阅“示例”部分
2.3 流式传输
Deep Agents 利用 LangGraph 内置了流式传输功能,可提供代理执行的实时更新。
这使得您能够:
- 逐步观察输出: 实时查看生成过程。
- 审查与调试: 检查代理和子智能体的工作,包括工具调用、工具结果和大语言模型响应。
2.4 后续步骤
既然您已经构建了第一个深度代理,接下来可以:
🎨 自定义您的代理:了解自定义选项,包括自定义系统提示词、工具和子代理。
🧠 添加长期记忆:启用跨对话的持久化记忆。
🌐 部署到生产环境:了解 Deep Agents 的部署选项
2.5 总结
从步骤看起来和langchain agent使用差不多,一些外围的功能更自动化了。
3 自定义Deep Agents
以下是 create_deep_agent 的主要配置参数:
- 模型:指定智能体使用的大语言模型。
- 工具:定义智能体可以调用的功能或 API。
- 系统提示词:设定智能体的行为准则、角色和指令。
- 中间件:用于在请求处理流程中插入自定义逻辑。
- 子智能体:配置可被主智能体调用的专用子智能体。
- 后端:设置虚拟文件系统的存储方式(如内存、本地磁盘等)。
- 人机回环:配置需要人工审批的敏感操作。
- 技能:为智能体添加可重用的专业工作流或知识。
- 记忆:管理智能体的短期或长期记忆存储
create_deep_agent(
model: str | BaseChatModel | None = None,
tools: Sequence[BaseTool | Callable | dict[str, Any]] | None = None,
*,
system_prompt: str | SystemMessage | None = None,
middleware: Sequence[AgentMiddleware] = (),
subagents: Sequence[SubAgent | CompiledSubAgent | AsyncSubAgent] | None = None,
skills: list[str] | None = None,
memory: list[str] | None = None,
permissions: list[FilesystemPermission] | None = None,
backend: BackendProtocol | BackendFactory | None = None,
interrupt_on: dict[str, bool | InterruptOnConfig] | None = None,
response_format: ResponseFormat[ResponseT] | type[ResponseT] | dict[str, Any] | None = None,
context_schema: type[ContextT] | None = None,
checkpointer: Checkpointer | None = None,
store: BaseStore | None = None,
debug: bool = False,
name: str | None = None,
cache: BaseCache | None = None
) -> CompiledStateGraph[AgentState[ResponseT], ContextT, _InputAgentState, _OutputAgentState[ResponseT]]有关完整的参数列表,请参阅 create_deep_agent API 参考文档
3.1 模型参数
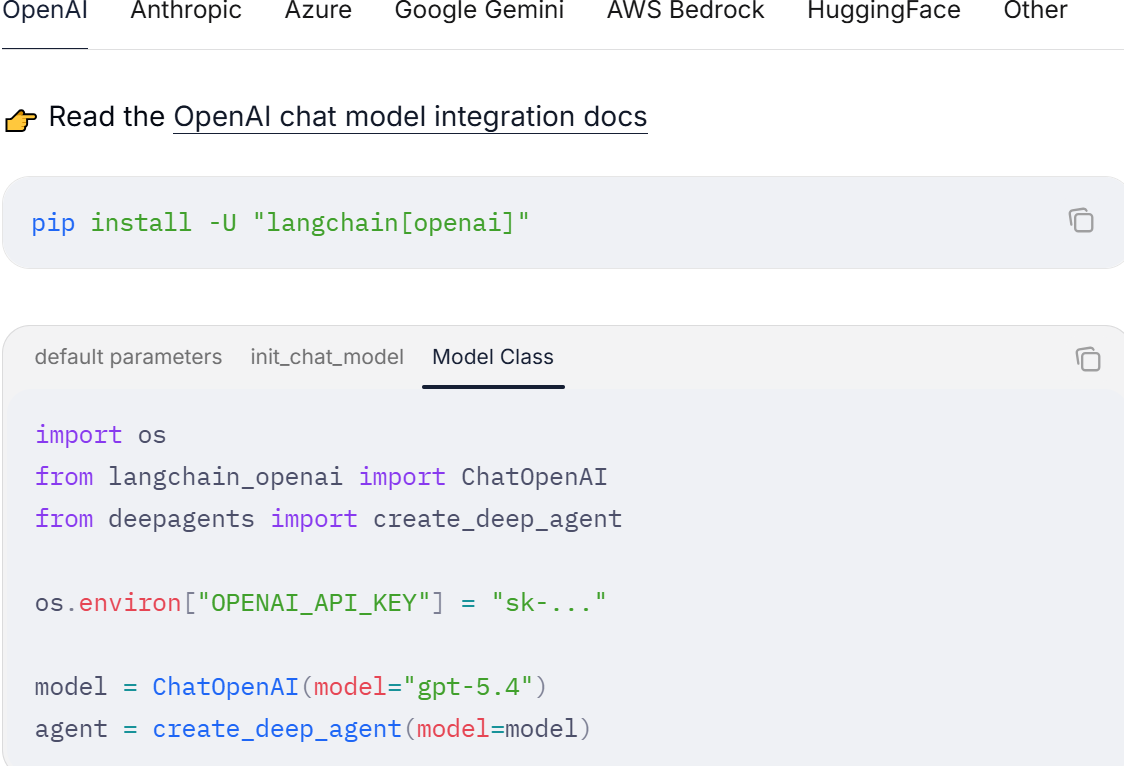
您可以传入 provider:model 格式的模型字符串,或者传入一个已初始化的模型实例。有关所有提供商支持的模型以及经过测试的推荐模型,请参阅“支持的模型”部分。
使用 provider:model 格式(例如 openai:gpt-5.4)可以快速在不同模型之间进行切换
连接弹性
LangChain 聊天模型具备内置的连接恢复机制,能够自动重试失败的 API 请求,并采用指数退避策略。
默认重试行为
- 重试次数:默认最多重试 6 次。
- 适用场景:
- 网络错误
- 速率限制(429)
- 服务器错误(5xx)
- 不重试的情况:客户端错误(如 401 未授权或 404 未找到)不会触发重试。
自定义配置:您可以通过在创建模型时调整 max_retries 参数,根据具体环境优化此行为。
from langchain.chat_models import init_chat_model
from deepagents import create_deep_agent
agent = create_deep_agent(
model=init_chat_model(
model="google_genai:gemini-3.1-pro-preview",
max_retries=10, # Increase for unreliable networks (default: 6)
timeout=120, # Increase timeout for slow connections
),
)针对在不稳定网络环境下运行的长时间代理任务,建议采取以下优化措施以增强系统的健壮性:
🛡️ 增强连接弹性与持久化
-
增加最大重试次数
- 建议将
max_retries参数增加到 10–15 次。 - 原因:长时间任务遭遇临时网络波动的概率更高,增加重试次数能显著提高任务最终成功的概率。
- 建议将
-
配合使用检查点
- 建议将高重试策略与检查点机制结合使用。
- 作用:确保在发生故障时,任务进度能够被保存和恢复,避免因重试失败导致整个长任务从头开始,从而保留已有的执行成果。
3.2 工具
除了用于规划、文件管理和生成子智能体的内置工具外,您还可以提供自定义工具来扩展智能体的能力
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[internet_search]
)3.3 系统提示词
Deep Agents 自带一个内置的系统提示词。该默认提示词包含了关于如何使用内置规划工具、文件系统工具以及子智能体的详细说明。当中间件添加特殊工具(如文件系统工具)时,相关的使用说明会自动追加到系统提示词中。除了默认设置外,每个深度代理还应包含一个自定义系统提示词,以专门针对其特定的使用场景进行优化。
from deepagents import create_deep_agent
research_instructions = """\
You are an expert researcher. Your job is to conduct \
thorough research, and then write a polished report. \
"""
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt=research_instructions,
)3.4 中间件
默认情况下,Deep Agents 内置了多种中间件来增强其功能。根据您启用的配置(如记忆、技能或人机回环),还会自动加载相应的扩展中间件。
默认中间件
以下中间件默认可用:
- TodoListMiddleware:跟踪和管理待办列表,帮助组织代理的任务和工作流。
- FilesystemMiddleware:处理文件系统操作,如读取、写入和导航目录。
- SubAgentMiddleware:生成并协调子智能体,以便将任务委派给专门的代理。
- SummarizationMiddleware:当对话过长时,自动压缩消息历史,确保不超出上下文限制。
- AnthropicPromptCachingMiddleware:在使用 Anthropic 模型时,自动减少冗余的令牌处理。
- PatchToolCallsMiddleware:当工具调用在收到结果前被中断或取消时,自动修复消息历史。
扩展中间件
如果您配置了特定功能,以下中间件也会被包含:
- MemoryMiddleware:当提供了
memory参数时,用于跨会话持久化和检索对话上下文。 - SkillsMiddleware:当提供了
skills参数时,用于启用自定义技能。 - HumanInTheLoopMiddleware:当提供了
interruptOn参数时,用于在指定节点暂停以等待人工批准或输入。
📦 预构建中间件
LangChain 提供了额外的预构建中间件,让您可以轻松添加各种通用功能,例如:
- 重试机制
- 降级策略
- PII(个人身份信息)检测
提示:
deepagents库还专门暴露了create_summarization_tool_middleware。与基于固定令牌间隔的总结不同,该中间件允许代理在合适的时机(例如任务之间)主动触发总结。
🏢 针对特定提供商的中间件
针对特定大语言模型提供商优化的中间件,请参阅官方集成和社区集成文档。
🛠️ 自定义中间件
您可以编写并提供额外的中间件,以实现以下目标:
- 扩展功能
- 添加工具
- 实现自定义钩子
from langchain.tools import tool
from langchain.agents.middleware import wrap_tool_call
from deepagents import create_deep_agent
@tool
def get_weather(city: str) -> str:
"""Get the weather in a city."""
return f"The weather in {city} is sunny."
call_count = [0] # Use list to allow modification in nested function
@wrap_tool_call
def log_tool_calls(request, handler):
"""Intercept and log every tool call - demonstrates cross-cutting concern."""
call_count[0] += 1
tool_name = request.name if hasattr(request, 'name') else str(request)
print(f"[Middleware] Tool call #{call_count[0]}: {tool_name}")
print(f"[Middleware] Arguments: {request.args if hasattr(request, 'args') else 'N/A'}")
# Execute the tool call
result = handler(request)
# Log the result
print(f"[Middleware] Tool call #{call_count[0]} completed")
return result
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[get_weather],
middleware=[log_tool_calls],
)前面langchain中间件可以通过装饰器和继承类两种方式实现。上面这种就是通过@wrap_tool_call实现的
⚠️ 初始化后请勿修改属性
在开发自定义中间件或组件时,这是一个关于并发安全的关键原则。
核心原则
- 禁止操作:在初始化完成后,不要直接修改组件自身的属性(例如在类实例中保存计数器或累积数据)。
- 潜在风险:在并发调用(并行处理多个请求)时,直接修改属性会导致竞争条件,因为多个线程可能会同时读写同一个属性,导致数据混乱。
正确做法:使用图状态
- 解决方案:如果您需要在不同的钩子调用之间跟踪数值或数据,请务必使用 图状态。
- 优势:图状态在设计上是按线程隔离的。这意味着每个对话线程都有独立的状态副本,因此对状态的更新是线程安全的,不会受到并发执行的影响。
#正确做法
class CustomMiddleware(AgentMiddleware):
def __init__(self):
pass
def before_agent(self, state, runtime):
return {"x": state.get("x", 0) + 1} # Update graph state instead#不要这样做
class CustomMiddleware(AgentMiddleware):
def __init__(self):
self.x = 1
def before_agent(self, state, runtime):
self.x += 1 # Mutation causes race conditions在开发自定义中间件时,原地修改是一个需要极力避免的操作模式,因为它会导致难以察觉的 Bug 和竞争条件。
为什么原地修改是危险的?
Deep Agents 框架中有许多操作是并发运行的,包括:
- 子智能体的执行
- 并行工具的调用
- 不同线程上的并发代理调用
如果您在钩子(如 before_agent)中直接修改 self.x 或其他共享值,这些并发操作会同时读写同一块内存区域,从而导致数据不一致或逻辑错误。
正确的解决方案
- 使用图状态:请务必通过扩展 图状态 来管理自定义属性。图状态是按线程隔离的,因此更新是安全的。
- 参考文档:关于如何扩展状态,请参阅“自定义中间件 - 自定义状态模式”章节。
建议:如果您必须在自定义中间件中使用变异操作,请务必仔细考虑当子智能体、并行工具或并发代理调用同时运行时可能发生的后果。
3.5 子图
为了隔离详细的工作流程并避免主上下文的过度膨胀,请使用子智能体:
- 上下文隔离:将复杂的任务委派给子智能体,主代理只需接收最终结果,而无需处理生成该结果的中间步骤和大量数据。
- 避免上下文膨胀:防止详细的中间结果(如多次网络搜索或文件读取的内容)填满主代理的上下文窗口,确保主代理专注于核心任务规划。
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
research_subagent = {
"name": "research-agent",
"description": "Used to research more in depth questions",
"system_prompt": "You are a great researcher",
"tools": [internet_search],
"model": "openai:gpt-5.4", # Optional override, defaults to main agent model
}
subagents = [research_subagent]
agent = create_deep_agent(
model="claude-sonnet-4-6",
subagents=subagents
)欲了解更多信息,请参阅子智能体相关文档
3.6 后端
深度代理的工具可以利用虚拟文件系统来存储、访问和编辑文件。默认情况下,深度代理使用 StateBackend。这是一种临时存储机制,文件保存在当前线程的状态中。如果您计划使用技能或记忆功能,则必须在创建代理之前,将预期的技能文件或记忆文件添加到后端中。
StateBackend
FilesystemBackend
LocalShellBackend
StoreBackend
CompositeBackend它是一种临时的文件系统后端,将文件存储在 LangGraph 的状态中,其生命周期仅限于单个线程。
📝 StateBackend 的特点
- 临时性:它就像一个智能体的临时草稿本,用于在执行过程中写入和读取中间结果。
- 线程内持久化:数据在单个线程的多次对话轮次中是持久化的,但当该线程的会话结束后,所有文件都会丢失。
- 默认选择:这是深度代理(Deep Agents)在未显式配置其他后端时的默认选择。
# By default we provide a StateBackend
agent = create_deep_agent(model="google_genai:gemini-3.1-pro-preview")
# Under the hood, it looks like
from deepagents.backends import StateBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=StateBackend()
)欲了解更多信息,请参阅后端相关文档。
沙箱
沙箱是一种特殊的后端,它能在一个隔离的环境中运行代理代码,拥有独立的文件系统和用于执行 Shell 命令的工具。当您希望深度代理执行以下操作,同时又不想影响本地机器的环境时,就应该使用沙箱后端:
- 写入文件
- 安装依赖
- 运行命令
在创建深度代理时,通过将沙箱后端传递给 backend 参数来完成配置:
import modal
from deepagents import create_deep_agent
from langchain_anthropic import ChatAnthropic
from langchain_modal import ModalSandbox
app = modal.App.lookup("your-app")
modal_sandbox = modal.Sandbox.create(app=app)
backend = ModalSandbox(sandbox=modal_sandbox)
agent = create_deep_agent(
model=ChatAnthropic(model="claude-sonnet-4-6"),
system_prompt="You are a Python coding assistant with sandbox access.",
backend=backend,
)
try:
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Create a small Python package and run pytest",
}
]
}
)
finally:
modal_sandbox.terminate()欲了解更多信息,请参阅沙箱相关文档
from langchain.tools import tool
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
@tool
def delete_file(path: str) -> str:
"""Delete a file from the filesystem."""
return f"Deleted {path}"
@tool
def read_file(path: str) -> str:
"""Read a file from the filesystem."""
return f"Contents of {path}"
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""Send an email."""
return f"Sent email to {to}"
# Checkpointer is REQUIRED for human-in-the-loop
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[delete_file, read_file, send_email],
interrupt_on={
"delete_file": True, # Default: approve, edit, reject
"read_file": False, # No interrupts needed
"send_email": {"allowed_decisions": ["approve", "reject"]}, # No editing
},
checkpointer=checkpointer # Required!
)您可以为代理和子智能体配置中断,既可以在调用工具时触发,也可以在工具调用内部触发。欲了解更多信息,请参阅人机交互相关文档
3.7 技能
您可以使用技能来为您的深度代理提供新的能力和专业特长。虽然工具倾向于覆盖较低级别的功能(如原生文件系统操作或规划),但技能则包含更丰富的内容:
- 详细指令:关于如何完成特定任务的逐步指南。
- 参考资料:相关的背景信息或知识库。
- 其他资产:如模板、脚本等。
渐进式披露
这些文件仅在代理确定技能对当前提示词有用时才会被加载。这种渐进式披露机制减少了代理在启动时必须考虑的 Token 数量和上下文长度,从而提高了效率。
提示:有关技能示例,请参阅 Deep Agents 示例技能库
配置方法
若要将技能添加到您的深度代理中,请将它们作为参数传递给 create_deep_agent 函数:
statebackend
from urllib.request import urlopen
from deepagents import create_deep_agent
from deepagents.backends.utils import create_file_data
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
skill_url = "https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/libs/cli/examples/skills/langgraph-docs/SKILL.md"
with urlopen(skill_url) as response:
skill_content = response.read().decode('utf-8')
skills_files = {
"/skills/langgraph-docs/SKILL.md": create_file_data(skill_content)
}
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/"],
checkpointer=checkpointer,
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "What is langgraph?",
}
],
# Seed the default StateBackend's in-state filesystem (virtual paths must start with "/").
"files": skills_files
},
config={"configurable": {"thread_id": "12345"}},
)storebankend
from urllib.request import urlopen
from deepagents import create_deep_agent
from deepagents.backends import StoreBackend
from deepagents.backends.utils import create_file_data
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
skill_url = "https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/libs/cli/examples/skills/langgraph-docs/SKILL.md"
with urlopen(skill_url) as response:
skill_content = response.read().decode('utf-8')
store.put(
namespace=("filesystem",),
key="/skills/langgraph-docs/SKILL.md",
value=create_file_data(skill_content)
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=StoreBackend(),
store=store,
skills=["/skills/"]
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "What is langgraph?",
}
]
},
config={"configurable": {"thread_id": "12345"}},
)文件系统bankend
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
from deepagents.backends.filesystem import FilesystemBackend
# Checkpointer is REQUIRED for human-in-the-loop
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=FilesystemBackend(root_dir="/Users/user/{project}"),
skills=["/Users/user/{project}/skills/"],
interrupt_on={
"write_file": True, # Default: approve, edit, reject
"read_file": False, # No interrupts needed
"edit_file": True # Default: approve, edit, reject
},
checkpointer=checkpointer, # Required!
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "What is langgraph?",
}
]
},
config={"configurable": {"thread_id": "12345"}},
)3.8 记忆
您可以使用 AGENTS.md 文件为您的深度代理提供额外的上下文信息。
statebackend
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langgraph.checkpoint.memory import MemorySaver
# Checkpointer is REQUIRED for human-in-the-loop
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=FilesystemBackend(root_dir="/Users/user/{project}"),
memory=[
"./AGENTS.md"
],
interrupt_on={
"write_file": True, # Default: approve, edit, reject
"read_file": False, # No interrupts needed
"edit_file": True # Default: approve, edit, reject
},
checkpointer=checkpointer, # Required!
)storebackend
from urllib.request import urlopen
from deepagents import create_deep_agent
from deepagents.backends import StoreBackend
from deepagents.backends.utils import create_file_data
from langgraph.store.memory import InMemoryStore
with urlopen("https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/examples/text-to-sql-agent/AGENTS.md") as response:
agents_md = response.read().decode("utf-8")
# Create the store and add the file to it
store = InMemoryStore()
file_data = create_file_data(agents_md)
store.put(
namespace=("filesystem",),
key="/AGENTS.md",
value=file_data
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=StoreBackend(),
store=store,
memory=[
"/AGENTS.md"
]
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Please tell me what's in your memory files.",
}
],
"files": {"/AGENTS.md": create_file_data(agents_md)},
},
config={"configurable": {"thread_id": "12345"}},
)FilesystemBackand
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langgraph.checkpoint.memory import MemorySaver
# Checkpointer is REQUIRED for human-in-the-loop
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=FilesystemBackend(root_dir="/Users/user/{project}"),
memory=[
"./AGENTS.md"
],
interrupt_on={
"write_file": True, # Default: approve, edit, reject
"read_file": False, # No interrupts needed
"edit_file": True # Default: approve, edit, reject
},
checkpointer=checkpointer, # Required!
)深度代理支持结构化输出。您可以通过将所需的结构化输出模式作为 response_format 参数传递给 create_deep_agent() 调用来进行设置。当模型生成结构化数据时,它会被捕获、验证,并返回到深度代理状态的 structured_response 键中
import os
from typing import Literal
from pydantic import BaseModel, Field
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
class WeatherReport(BaseModel):
"""A structured weather report with current conditions and forecast."""
location: str = Field(description="The location for this weather report")
temperature: float = Field(description="Current temperature in Celsius")
condition: str = Field(description="Current weather condition (e.g., sunny, cloudy, rainy)")
humidity: int = Field(description="Humidity percentage")
wind_speed: float = Field(description="Wind speed in km/h")
forecast: str = Field(description="Brief forecast for the next 24 hours")
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
response_format=WeatherReport,
tools=[internet_search]
)
result = agent.invoke({
"messages": [{
"role": "user",
"content": "What's the weather like in San Francisco?"
}]
})
print(result["structured_response"])
# location='San Francisco, California' temperature=18.3 condition='Sunny' humidity=48 wind_speed=7.6 forecast='Pleasant sunny conditions expected to continue with temperatures around 64°F (18°C) during the day, dropping to around 52°F (11°C) at night. Clear skies with minimal precipitation expected.'欲了解更多信息和示例,请参阅响应格式相关文档
4 Deep Agents Vs Claude Agent SDK
本页面介绍了 LangChain Deep Agents 与 Claude Agent SDK 的对比。两者均为用于构建自定义智能体的支撑框架,但在执行环境、部署方式以及厂商绑定方面做出了不同的权衡
4.1 概览
| 维度 | Deep Agents | Claude Agent SDK |
|---|---|---|
| 运行位置 | 在沙箱内部,或在沙箱外部远程执行命令 | 在沙箱内部 |
| 执行后端 | 可插拔式:支持本地、虚拟文件系统、远程沙箱或自定义后端 | 仅限于其运行所在沙箱的本地文件系统 |
| 模型提供商 | 任意模型(支持 Anthropic, OpenAI, Google 等 100+ 家服务商) | 仅限 Claude(支持 Anthropic, Bedrock, Vertex, Azure 等渠道) |
| 部署方式 | 1. 通过 deepagents deploy 使用 LangSmith 托管云2. 通过 langgraph build 自托管独立镜像 |
需自托管:需自行构建服务器、鉴权和流式传输层 (注:Claude 托管代理是另一款独立产品) |
| 多租户支持 | 内置支持:包含作用域线程、每用户沙箱、基于角色的访问控制 | 需自行构建 |
| 开源协议 | MIT | MIT(但 Claude Code 本身是专有软件) |
4.2 主要差异
4.2.1 智能体与执行环境
连接智能体与沙盒主要有两种模式:将智能体运行在沙盒内部,或者将智能体运行在沙盒外部并将沙盒作为工具使用。
Claude Agent SDK 仅支持第一种模式。你的智能体运行在沙盒内部,并针对沙盒的本地文件系统执行工具。Anthropic 托管的 Claude 托管智能体使用的是解耦模型,这反映了生产级智能体架构的未来发展方向。
Deep Agents 同时支持这两种模式,并允许你选择后端来将它们连接起来。在实践中,这意味着你可以:
- 在沙盒内部运行智能体(与 Claude Agent SDK 相同的模式)。
- 在长生命周期的容器中运行智能体,并将远程沙盒作为工具使用,通过网络执行命令。
- 在测试时换用虚拟文件系统,或者为你自己的基础设施换用自定义后端
4.2.3 多租户支持
当你将应用程序投入生产环境时,通常需要面向众多终端用户,因此必须为每个用户隔离环境。
在 Claude Agent SDK 中,SDK 将智能体与其沙盒紧密绑定。为了给每个用户提供隔离的执行环境,你必须构建一个 API 包装层,负责为每个用户启动一个沙盒,追踪哪个沙盒属于谁,并在之后将其销毁。
Deep Agents 直接处理这个问题:你可以在框架(Harness)中配置每个用户或每个助手的沙盒,其中已包含作用域线程、运行历史记录和基于角色的访问控制。如果你使用 LangSmith Sandbox,还可以直接获得一个认证代理,这样终端用户就可以在沙盒内调用第三方 API,而无需你为每个用户单独配置凭证。
4.2.4 核心区别
简单来说,Deep Agents 在这里省去了很多“造轮子”的麻烦:
- Claude Agent SDK:你需要自己动手写代码来管理用户的隔离环境(启动、追踪、销毁),相当于你要自己当“房东”给每个用户分房间。
- Deep Agents:它自带“物业管理”。它内置了隔离机制、权限管理和历史记录。特别是那个“认证代理”功能,相当于它帮用户解决了进门刷卡(API 密钥管理)的问题,你不用给每个用户单独发钥匙了
4.2.5 生产级智能体服务器
要想向终端用户开放自托管的 Claude Agent SDK 应用,你需要自己编写 HTTP/WebSocket 或 SSE 服务器,用来调用智能体、流式回传文本片段(tokens),并管理对话线程。这个服务器需要由你自己构建、运维和保障安全。
Deep Agents 的部署方案则直接包含了开箱即用的智能体服务器:自带流式传输端点、线程管理、运行历史记录、Webhooks 以及身份认证功能。
4.2.6 托管云或自托管
Claude Agent SDK 的部署方式仅限于自托管。该 SDK 与 Claude 托管智能体是两个独立的产品。针对 SDK 编写的代码无法直接部署到托管服务中。
Deep Agents 无需更改代码即可在两种模式下运行:
- 托管模式:使用
deepagents deploy命令部署到 LangSmith 托管云。 - 自托管模式:运行
langgraph build生成一个独立的 Docker 镜像,你可以将其部署到任何地方。
4.2.7 大语言模型
Claude Agent SDK 的执行环境将模型、后端和部署捆绑在一起,并优化这三者之间的支持。而在 Deep Agents 中,你可以独立选择模型提供商、执行后端和部署目标。通过选择这个框架,你在模型和基础设施的选择上保留了最大的灵活性
4.2.8 总结
- 选择 Deep Agents:如果你想要模型和基础设施的灵活性,需要内置的多租户部署功能,并且希望无需更改代码就能在“托管”和“自托管”模式之间切换。
- 选择 Claude Agent SDK:如果你坚定地只使用 Claude 模型,打算自托管,并且愿意亲自动手构建 API、身份认证和多租户层级
5 Harness 架构
智能体框架是多种不同能力的组合,旨在让构建长期运行的智能体变得更加容易。这些能力包括:
- 规划能力:让智能体学会拆解目标。
- 虚拟文件系统:提供一个模拟的文件操作环境。
- 文件系统权限:控制智能体对文件的读写范围。
- 任务委派(子智能体):允许主智能体将任务分派给专门的子智能体。
- 上下文与令牌管理:高效管理记忆和对话长度,防止溢出。
- 代码执行:赋予智能体编写并运行代码的能力。
- 人机协同:在关键节点允许人类介入进行确认或干预。
除了上述能力外,Deep Agents 还利用技能和记忆来提供额外的上下文信息和指令
核心定义与本质
- 本质:Harness = AI Agent 的全套支撑系统,包含代码、配置、规则、工具、状态、反馈等所有包裹在大模型之外的组件。
- 经典公式:
Agent = 大模型(Model) + Harness(驾驭层)
模型决定能力上限,Harness 决定实际落地效果 410。 - 比喻:若将 AI 智能体比作一辆车:
- 大模型 = 引擎(动力)
- Prompt = 方向盘(初步引导)
- Harness = 变速箱 + 制动器 + 仪表盘 + 安全带(有序输出、按规则行驶、掌握状态、防止失控)4
演进历程
-
Prompt Engineering(提示词工程)时代(2023–2024)
- 依赖人工调优指令(如 Few-shot、CoT)提升单次输出质量。
- 局限:脆弱、无状态、不可扩展 4。
-
Context Engineering(上下文工程)过渡期(2025)
- 引入 RAG、外部记忆(如 AutoGPT 的
.txt文件)、上下文压缩。 - 仍不足:只管“信息存取”,不管“流程执行”与“质量保障” 4。
- 引入 RAG、外部记忆(如 AutoGPT 的
-
Harness Engineering(驾驭工程)时代(2026 至今)
- 构建“约束 + 引导 + 监控 + 纠错”闭环系统。
- 核心目标:将非确定性的 LLM 转化为可信赖、可审计、可规模化的生产力工具
5.1 规划能力
该框架提供了一个 write_todos 工具,智能体可以使用它来维护一个结构化的任务列表。
功能特点:
- 跟踪多个任务及其状态:包括“待办”、“进行中”和“已完成”。
- 持久化存储在智能体状态中:确保任务列表不会丢失。
- 帮助智能体组织复杂的多步骤工作:让复杂的任务变得井井有条。
- 适用于长期运行的任务和规划:特别适合需要长时间处理的工作
5.2 虚拟文件系统访问
该框架提供了一个可配置的虚拟文件系统,它可以由不同的可插拔后端提供支持。这些后端支持以下文件系统操作:
| 工具 | 描述 |
|---|---|
| ls | 列出目录中的文件及其元数据(大小、修改时间)。 |
| read_file | 读取文件内容并带行号,支持通过偏移量/限制来读取大文件。也支持为非文本文件(如图像、视频、音频和文档)返回多模态内容块。请参见下方支持的文件扩展名。 |
| write_file | 创建新文件。 |
| edit_file | 在文件中执行精确的字符串替换(支持全局替换模式)。 |
| glob | 查找匹配特定模式的文件(例如 **/*.py)。 |
| grep | 搜索文件内容,提供多种输出模式(仅文件、带上下文的内容或计数)。 |
| execute | 在环境中运行 Shell 命令(仅限沙盒后端可用)。 |
支持的文件扩展名
| Type | Extensions |
|---|---|
| Image | .png, .jpg, .jpeg, .gif, .webp, .heic, .heif |
| Video | .mp4, .mpeg, .mov, .avi, .flv, .mpg, .webm, .wmv, .3gpp |
| Audio | .wav, .mp3, .aiff, .aac, .ogg, .flac |
| File | .pdf, .ppt, .pptx |
虚拟文件系统会被框架的其他几项能力所使用,例如技能、记忆、代码执行和上下文管理。在为 Deep Agents 构建自定义工具和中间件时,你也可以利用这个文件系统
5.3 文件系统权限
该框架支持声明式权限规则,用于控制智能体可以读取或写入哪些文件和目录。权限适用于上面列出的内置文件系统工具,并按照声明顺序进行评估,遵循“首次匹配生效”的原则。
工作原理:
- 传递规则列表:在创建智能体时,通过
permissions=参数传递一个规则列表。 - 规则定义:每个规则指定操作("read" 读取,"write" 写入)、路径(通配符模式)和模式("allow" 允许 或 "deny" 拒绝)。
- 匹配逻辑:第一条匹配的规则生效。如果没有规则匹配,则默认允许该操作。
为什么它很有用:
- 限制目录范围:将智能体限制在特定目录内(例如
/workspace/)。 - 保护敏感文件:保护敏感文件(例如
.env文件、凭证)。 - 子智能体权限隔离:给予子智能体比主智能体更窄的访问权限。
注意事项:
权限不适用于沙盒后端,因为沙盒后端通过 execute 工具支持任意命令执行。对于自定义验证逻辑,请使用后端策略钩子。有关完整的规则结构、示例和子智能体继承,请参阅权限文档
5.4 任务委派(子智能体)
该框架允许主智能体为独立的、多步骤的任务创建临时的“子智能体”。
为什么它很有用:
- 上下文隔离:子智能体的工作过程不会弄乱主智能体的上下文(记忆)。
- 并行执行:多个子智能体可以同时运行,提高效率。
- 专业化分工:子智能体可以拥有不同的工具或配置,术业有专攻。
- 令牌效率:庞大的子任务上下文会被压缩成一份最终结果,节省资源。
工作原理:
- 主智能体拥有一个
task工具。 - 当调用该工具时,它会创建一个拥有独立上下文的全新智能体实例。
- 子智能体自主执行任务,直到完成。
- 最后只向主智能体返回一份最终报告。
- 注意:子智能体是无状态的(不能像聊天那样来回发多条消息,只能给个最终结果)。
默认子智能体:
- 系统自动提供一个“通用型”子智能体。
- 它默认拥有文件系统工具。
- 你可以通过添加工具或中间件来自定义它。
自定义子智能体:
- 你可以定义拥有特定工具的专用子智能体。
- 例如:代码审查员、网络研究员、测试运行器。
- 通过
subagents参数进行配置。
5.5 上下文管理
该框架负责管理上下文,以便深度智能体能够在令牌限制范围内处理长期运行的任务,同时保留它们所需的信息。
工作原理:
输入上下文:系统提示词、记忆、技能和工具提示词,共同塑造了智能体启动时所知道的内容。
压缩:内置的“卸载”和“总结”功能,确保在任务进行中,上下文始终保持在窗口限制内。
隔离:子智能体将繁重的工作隔离开来,只返回结果(参见任务委派)。
长期记忆:通过虚拟文件系统,实现跨线程的持久化存储。
为什么它很有用:
突破限制:使得智能体能够执行超过单个上下文窗口限制的多步骤任务。
自动筛选:让最相关的信息保持在视野范围内,无需手动修剪。
节省成本:通过自动总结和卸载,减少令牌使用量。
有关配置详情,请参阅上下文工程。
5.6 代码执行
当使用沙箱后端(Sandbox Backend)时,Agent Harness 会暴露一个 execute 工具,允许 Agent 在隔离环境中运行 Shell 命令。这使得 Agent 能够作为任务的一部分安装依赖项、运行脚本和执行代码。
工作原理
- 协议检测:沙箱后端实现了
SandboxBackendProtocolV2接口。一旦 Harness 检测到该接口,就会自动将execute工具添加到 Agent 可用的工具集中。 - 功能限制:如果没有配置沙箱后端,Agent 仅拥有文件系统工具(如
read_file、write_file等),无法执行任何命令。 - 返回结果:
execute工具会返回合并后的标准输出(stdout)和标准错误(stderr)、退出码(exit code)。如果输出内容过大,系统会自动截断并保存为文件,供 Agent 增量读取。
核心价值
-
安全性
代码在隔离环境中运行,有效保护主机系统免受 Agent 操作的影响。即使 Agent 生成恶意代码或遭受攻击,风险也被限制在沙箱内部。 -
纯净环境
无需在本地进行复杂配置,即可使用特定的依赖库或操作系统配置。这消除了“在我机器上能跑”的环境差异问题。 -
可复现性
为团队提供一致的执行环境,确保不同成员或在不同时间运行的任务具有相同的行为表现。
有关沙箱的设置、支持的提供商以及文件传输 API 的详细信息,请参阅 Sandboxes 相关文档。
5.7 人机协同
该框架可以在特定的工具调用时暂停智能体的执行,以便让人类进行批准或修改。此功能通过 interrupt_on 参数按需开启。
配置方法:
- 在调用
create_deep_agent时,传递interrupt_on参数,该参数是一个将工具名称映射到中断配置的字典。 - 示例:
interrupt_on={"edit_file": True}会在每次编辑文件之前暂停。 - 当被提示时,你可以提供批准信息,或者修改工具的输入参数。
为什么它很有用:
- 安全闸门:防止破坏性操作(比如误删文件)。
- 用户验证:在进行昂贵的 API 调用之前,先让用户确认一下(省钱)。
- 交互式调试与指导:在运行过程中,人类可以随时介入纠正方向
5.8 技能
该框架支持“技能”,可以为你的深度智能体提供专门的工作流程和领域知识。
工作原理:
- 遵循标准:技能遵循“智能体技能”标准。
- 文件结构:每个技能都是一个目录,其中包含一个
SKILL.md文件,里面有指令和元数据。 - 丰富资源:技能目录里还可以包含额外的脚本、参考文档、模板和其他资源。
- 渐进式披露:技能只有在智能体判断对当前任务有用时才会被加载(平时是隐藏的)。
- 加载机制:智能体在启动时会读取每个
SKILL.md文件的“页眉元数据”(frontmatter),只有在需要时才会去查看完整的技能内容。
为什么它很有用:
- 节省令牌:只在需要时加载相关技能,大大减少了令牌消耗。
- 能力打包:将多种能力打包成更大的动作,并附带额外的上下文信息。
- 保持整洁:提供专业知识,但不会弄乱系统提示词(主指令)。
- 模块化与复用:让智能体的能力变得模块化,可以重复使用。
有关更多信息,请参阅技能文档。
5.9 记忆
该框架支持持久化的记忆文件,可以在多次对话中为你的深度智能体提供额外的上下文。这些文件通常包含通用的编码风格、偏好设置、惯例和指南,帮助智能体理解如何与你的代码库协作,并遵循你的偏好。
工作原理:
- 使用
AGENTS.md文件:利用这些文件来提供持久化的上下文。 - 始终加载:记忆文件是总是被加载的(这与使用渐进式披露的“技能”不同)。
- 配置路径:在创建智能体时,将一个或多个文件路径传递给
memory参数。 - 存储位置:文件存储在智能体的后端中(
StateBackend、StoreBackend或FilesystemBackend)。 - 自我进化:智能体可以根据你们的互动、反馈和识别出的模式来更新记忆。
为什么它很有用:
- 持久化上下文:提供持久的上下文,不需要在每次对话时都重新指定。
- 存储偏好:非常适合存储用户偏好、项目指南或领域知识。
- 始终可用:智能体随时可以使用这些信息,确保行为的一致性。
有关配置详情和示例,请参阅记忆文档。
6 模型
Deep Agents 可以与任何支持工具调用的 LangChain 聊天模型协同工作
6.1 支持的模型
请使用 提供商:模型 的格式来指定模型(例如 google_genai:gemini-3.1-pro-preview、openai:gpt-5.4 或 anthropic:claude-sonnet-4-6)。关于有效的提供商字符串,请参阅 init_chat_model 的 model_provider 参数。关于特定提供商的配置,请参阅聊天模型集成文档。
🌟 推荐模型
这些模型在 Deep Agents 评估套件中表现良好,该套件主要测试智能体的基本操作能力。注意: 通过这些评估只是必要条件,并不代表模型在更长、更复杂的任务中一定能表现出色。
| 提供商 | 模型 |
|---|---|
| gemini-3.1-pro-preview, gemini-3-flash-preview | |
| OpenAI | gpt-5.4, gpt-4o, gpt-5.4, o4-mini, gpt-5.2-codex, gpt-4o-mini, o3 |
| Anthropic | claude-opus-4-6, claude-opus-4-5, claude-sonnet-4-6, claude-sonnet-4, claude-sonnet-4-5, claude-haiku-4-5, claude-opus-4-1 |
| Open-weight (开源权重) | GLM-5, Kimi-K2.5, MiniMax-M2.5, qwen3.5-397B-A17B, devstral-2-123B |
Open-weight 模型可以通过 Baseten、Fireworks、OpenRouter 和 Ollama 等提供商获取。
6.2 配置模型参数
你可以通过两种方式配置模型:
- 使用字符串:在调用
create_deep_agent时,以提供商:模型的格式传递一个模型字符串。 - 使用实例:直接传递一个已经配置好的模型实例,以获得完全的控制权。
模型字符串会在底层通过 init_chat_model 函数进行解析和实例化。
若要配置特定于模型的参数(比如温度、最大令牌数等),你可以使用 init_chat_model 函数,或者直接实例化一个提供商的模型类:
#init_chat_model
from langchain.chat_models import init_chat_model
from deepagents import create_deep_agent
model = init_chat_model(
model="google_genai:gemini-3.1-pro-preview",
thinking_level="medium",
)
agent = create_deep_agent(model=model)
#
from langchain_google_genai import ChatGoogleGenerativeAI
from deepagents import create_deep_agent
model = ChatGoogleGenerativeAI(
model="gemini-3.1-pro-preview",
thinking_level="medium",
)
agent = create_deep_agent(model=model)可用参数因提供商而异。请参阅“聊天模型集成”页面,查看特定于提供商的配置选项。
6.3 在运行时选择模型
如果你的应用程序允许用户选择模型(例如使用 UI 中的下拉菜单),请使用中间件在运行时交换模型,而无需重新构建智能体。通过运行时上下文传递用户的模型选择,然后使用 @wrap_model_call 装饰器,通过 wrap_model_call 中间件在每次调用时覆盖模型:
from dataclasses import dataclass
from langchain.chat_models import init_chat_model
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from deepagents import create_deep_agent
from typing import Callable
@dataclass
class Context:
model: str
@wrap_model_call
def configurable_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
model_name = request.runtime.context.model
model = init_chat_model(model_name)
return handler(request.override(model=model))
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
middleware=[configurable_model],
context_schema=Context,
)
# Invoke with the user's model selection
result = agent.invoke(
{"messages": [{"role": "user", "content": "Hello!"}]},
context=Context(model="openai:gpt-5.4"),
)6.4 上下文工程
上下文工程是指以正确的格式提供正确的信息和工具,以便你的深度智能体能够可靠地完成任务。
深度智能体可以使用多种类型的上下文:
- 启动时:有些来源是在智能体启动时就提供的(比如系统预设)。
- 运行时:有些来源是在运行过程中才出现的(比如用户的输入)。
深度智能体内置了各种机制,用于在长时间运行的会话中管理这些上下文。
本页将概述你的深度智能体可以访问和管理的各种上下文类型。刚接触上下文工程?请查看概念概览,了解不同类型的上下文以及何时使用它们
6.5 上下文的类型
| 上下文类型 | 你可以控制的内容 | 作用范围 |
|---|---|---|
| 输入上下文 | 决定在启动时放入智能体提示词的内容(系统提示词、记忆、技能) | 静态的,每次运行都会应用 |
| 运行时上下文 | 在调用时传递的静态配置(用户元数据、API 密钥、连接信息) | 每次运行,并会传播给子智能体 |
| 上下文压缩 | 内置的卸载和摘要机制,用于将上下文保持在窗口限制内 | 自动的,当接近限制时触发 |
| 上下文隔离 | 使用子智能体来隔离繁重的工作,只将结果返回给主智能体 | 每个子智能体,仅在委托任务时 |
| 长期记忆 | 使用虚拟文件系统在多个线程间进行持久化存储 | 跨对话持久化 |
6.6 输入上下文
输入上下文是指在启动时提供给深度智能体的信息,这些信息会成为其系统提示词的一部分。最终的提示词由以下几个来源组成:
- 系统提示词
包含你提供的自定义指令,以及内置的智能体指导原则。 - 记忆
配置后始终会被加载的持久化AGENTS.md文件。 - 技能
仅在相关时才会加载的按需能力(渐进式披露)。 - 工具提示词
关于如何使用内置工具或自定义工具的说明。
6.6.1 系统提示词
你的自定义系统提示词会被前置(添加在前面)到内置的系统提示词中。包含关于规划的指导、文件系统工具的使用说明、子智能体的使用说明。你应该用它来定义:智能体的角色、行为、知识
from deepagents import create_deep_agent
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt=(
"You are a research assistant specializing in scientific literature. "
"Always cite sources. Use subagents for parallel research on different topics."
),
)system_prompt 参数是静态的,这意味着它在每次调用时不会改变。
为什么需要动态提示?
在某些用例中,你可能需要一个动态的提示词。例如:
- 权限控制:根据情况告诉模型“你拥有管理员权限”或者“你只有只读权限”。
- 用户偏好:从长期记忆中注入用户喜好,比如“用户喜欢简洁的回复”。
如何实现?
如果你的提示词依赖于上下文或 runtime.store(运行时存储),请使用 @dynamic_prompt 装饰器来构建感知上下文的指令。
技术细节:
- 你的中间件可以读取
request.runtime.context和request.runtime.store。 - 关于添加自定义中间件,请参阅“定制化”章节;关于示例,请参阅 LangChain 上下文工程指南。
关于工具(Tools)的特别说明:
- 不需要中间件的情况:如果仅仅是工具需要使用上下文或
runtime.store,你不需要写中间件。因为工具会直接接收ToolRuntime对象(其中包含运行时上下文和存储)。 - 需要中间件的情况:只有当你需要根据上下文更新系统提示词(也就是改变给模型的指令)时,才需要添加中间件。
6.6.2 记忆
记忆文件(即 AGENTS.md 文件)提供了持久化的上下文,这些内容始终会被加载到系统提示词中。
你应该用“记忆”来存储:
- 项目惯例(比如代码风格、命名规范)
- 用户偏好(比如“我喜欢用深色模式”)
- 关键准则(那些在每次对话中都必须遵守的规则
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
memory=["/project/AGENTS.md", "~/.deepagents/preferences.md"],
)与技能不同,记忆是始终被注入的——不存在渐进式披露。优化建议:
- 保持记忆最小化:以避免上下文过载(即令牌数超标)。
- 使用技能:将详细的工作流程和特定领域的内容放在“技能”中。
有关配置的详细信息,请参阅“记忆”章节
6.3.3 技能
技能提供了按需使用的能力。
工作机制:
- 启动时:智能体只会读取每个
SKILL.md文件的文件头(frontmatter,即元数据摘要)。 - 运行时:只有当智能体判断该技能与当前任务相关时,才会加载该技能的完整内容。
好处:
这种方式在提供专业工作流的同时,有效地减少了令牌的使用量
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/research/", "/skills/web-search/"],
)技能的编写最佳实践
核心原则:
- 保持专注:让每个技能只专注于单一的工作流或领域。
- 避免宽泛:宽泛或重叠的技能会稀释相关性,并且在加载时会膨胀上下文(浪费令牌)。
内容组织:
- 保持精简:在技能文件内部,保持主要内容简洁。
- 外部引用:将详细的参考资料移动到单独的文件中,然后在技能文件中引用它们(而不是把长文直接贴进去)。
区分用途:
- 记忆:用来存放那些“永远相关”的惯例。
有关编写和配置的详细信息,请参阅“技能”章节。
6.3.4 工具提示词
工具提示词是指导模型如何使用工具的指令。
基本原理:
所有工具都会向模型暴露元数据(通常是模式和描述),模型会在其提示词中看到这些信息。
- 当你通过
tools参数传递工具时,这些工具的元数据(模式和描述)就会呈现给模型。 - 深度智能体的内置工具通常被封装在中间件中,并且通常会通过更多的指导说明来更新系统提示词。
1. 内置工具
这些是中间件添加的“装备”能力(规划、文件系统、子智能体)。它们会自动将特定于工具的指令附加到系统提示词中,从而创建解释如何有效使用这些工具的提示词:
- 规划提示词:指导如何使用
write_todos来维护一个结构化的任务列表。 - 文件系统提示词:关于
ls、read_file、write_file、edit_file、glob、grep的文档(如果在使用沙盒后端,还包括execute)。 - 子智能体提示词:关于如何使用
task工具来委派工作的指导。 - 人机回环提示词:关于在指定工具调用时暂停的用法(当设置了
interrupt_on时)。 - 本地上下文提示词:当前目录和项目信息(仅限 CLI)。
2. 你提供的工具
通过 tools 参数传递的工具,其描述(来自工具模式)会被发送给模型。你也可以添加自定义中间件来添加工具并追加其自己的系统提示词指令。
编写建议:
对于你提供的工具,请务必提供清晰的名称、描述和参数描述。
- 这些内容会指导模型推理何时以及如何使用该工具。
- 在描述中包含“何时使用该工具”,并描述每个参数的作用。
@tool(parse_docstring=True)
def search_orders(
user_id: str,
status: str,
limit: int = 10
) -> str:
"""Search for user orders by status.
Use this when the user asks about order history or wants to check
order status. Always filter by the provided status.
Args:
user_id: Unique identifier for the user
status: Order status: 'pending', 'shipped', or 'delivered'
limit: Maximum number of results to return
"""
# Implementation here
...关于内置能力,请参阅 “Harness” 章节。关于直接传递工具,请参阅 “Customization” 章节
6.3.5 完整的系统提示词
深度智能体的系统消息——也就是模型在运行开始时接收到的组装好的系统提示词——由以下几个部分组成:
- 自定义系统提示词(如果你提供了的话)
- 基础智能体提示词
- 待办列表提示词:关于如何使用待办列表进行规划的指令
- 记忆提示词:
AGENTS.md内容 + 记忆使用指南(仅当提供了记忆文件时存在) - 技能提示词:技能存放路径 + 包含文件头信息的技能列表 + 使用说明(仅当提供了技能时存在)
- 虚拟文件系统提示词(文件系统 + 执行工具的文档,如果适用的话)
- 子智能体提示词:任务工具的使用说明
- 用户提供的中间件提示词(如果你提供了自定义中间件的话)
- 人机回环提示词(当设置了
interrupt_on时存在)
6.6 运行时上下文
运行时上下文是你调用 Agent 时传入的“单次运行”配置。 它不会自动包含在发给模型的提示词里;只有当工具、中间件或其他逻辑主动读取它,并将其添加到消息或系统提示词中时,模型才能看到它。运行时上下文用来存储用户元数据(如 ID、偏好设置、角色)、API 密钥、数据库连接、功能开关,或其他你的工具和框架需要的值。使用 context_schema 来定义数据的结构(Shape):可以使用 dataclasses.dataclass 或 typing.TypedDict 类。通过调用 invoke 或 ainvoke 时的 context 参数来传递具体的值。关于完整细节,请查阅 Runtime and LangGraph runtime context 文档。在工具内部: 请从注入的 ToolRuntime 中读取上下文。
from dataclasses import dataclass
from deepagents import create_deep_agent
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
api_key: str
@tool
def fetch_user_data(query: str, runtime: ToolRuntime[Context]) -> str:
"""Fetch data for the current user."""
user_id = runtime.context.user_id
return f"Data for user {user_id}: {query}"
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[fetch_user_data],
context_schema=Context,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "Get my recent activity"}]},
context=Context(user_id="user-123", api_key="sk-..."),
)运行时上下文会传播给所有的子智能体。当子智能体运行时,它会接收到与父代理完全相同的运行时上下文。如果需要为单个子智能体设置独立的上下文(例如使用命名空间键),请查阅 Subagents 文档
6.7 上下文压缩
长时间运行的任务会产生大量的工具输出和冗长的对话历史。上下文压缩的作用就是在保留任务相关细节的同时,缩小 Agent 工作记忆中的信息体积。以下是内置的机制,用于确保传递给大语言模型(LLMs)的上下文始终保持在窗口限制之内:
- 卸载
将大型的工具输入和结果存储到文件系统中,并在上下文中用引用链接来替代它们(即不直接占内存,而是指个路)。 - 摘要
当上下文接近限制时,利用 LLM 将旧的消息压缩生成一份摘要。
6.7.1 卸载
Deep Agents 利用内置的文件系统工具,自动将内容卸载(存储到磁盘),并在需要时搜索和检索这些已卸载的内容。当工具调用的输入或结果超过设定的 Token 阈值(默认为 20,000)时,就会触发内容卸载:
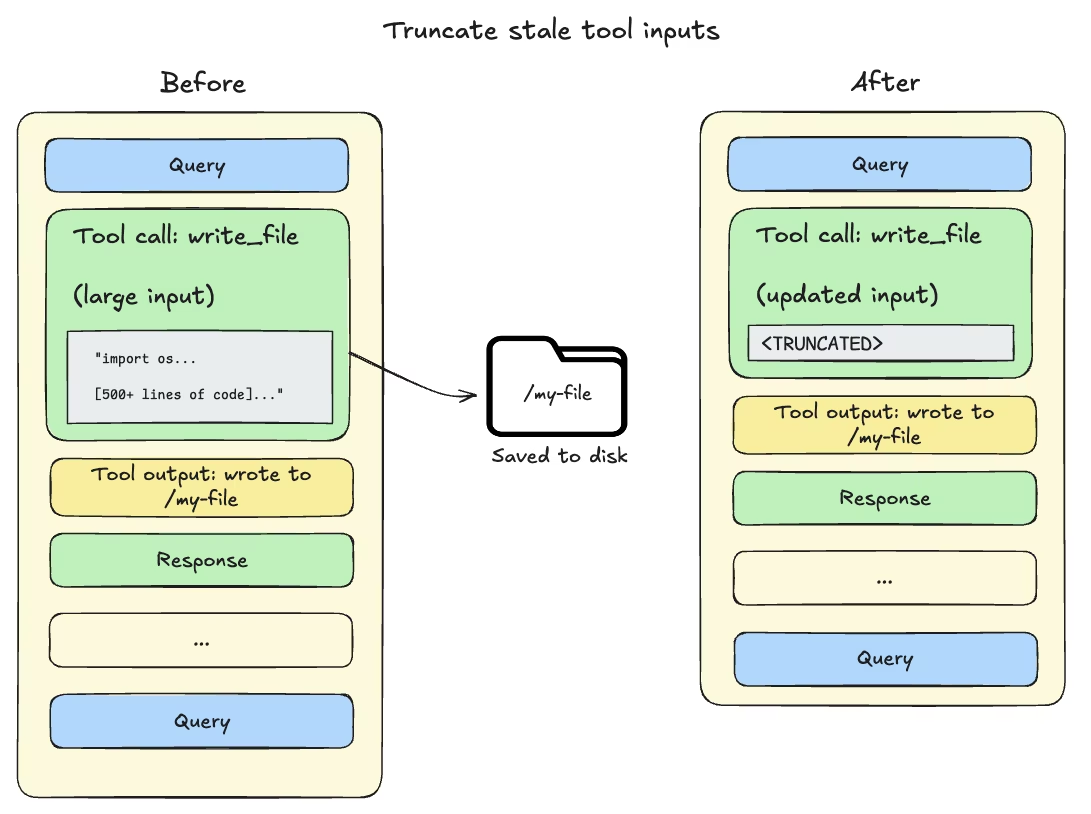
1 工具调用输入超过 20,000 Token 时:
文件写入和编辑操作会在 Agent 的对话历史中留下包含完整文件内容的工具调用记录。由于这些内容已经持久化到了文件系统中,历史记录里的完整内容往往就成了冗余数据。
当会话上下文占用量达到模型可用窗口的 85% 时,Deep Agents 会截断(删除)旧的工具调用记录,将其替换为指向磁盘上文件的指针,从而减小活跃上下文的大小。
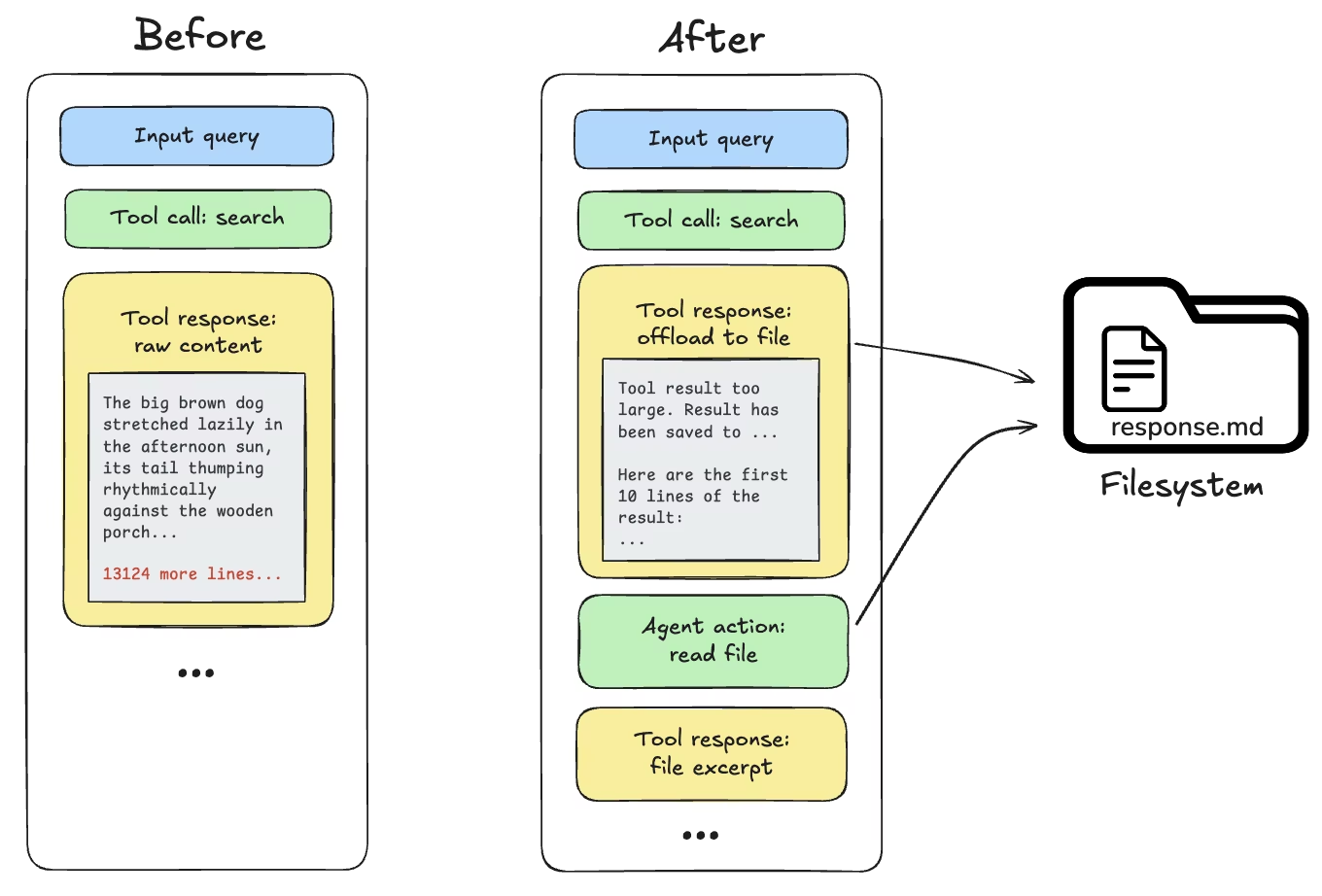
2 工具调用结果超过 20,000 Token 时:
当发生这种情况,Deep Agent 会将响应内容卸载(存储)到配置好的后端中,并用一个文件路径引用以及前 10 行的预览内容来替代原本庞大的结果。随后,Agent 可以根据需要重新读取或搜索该内容。
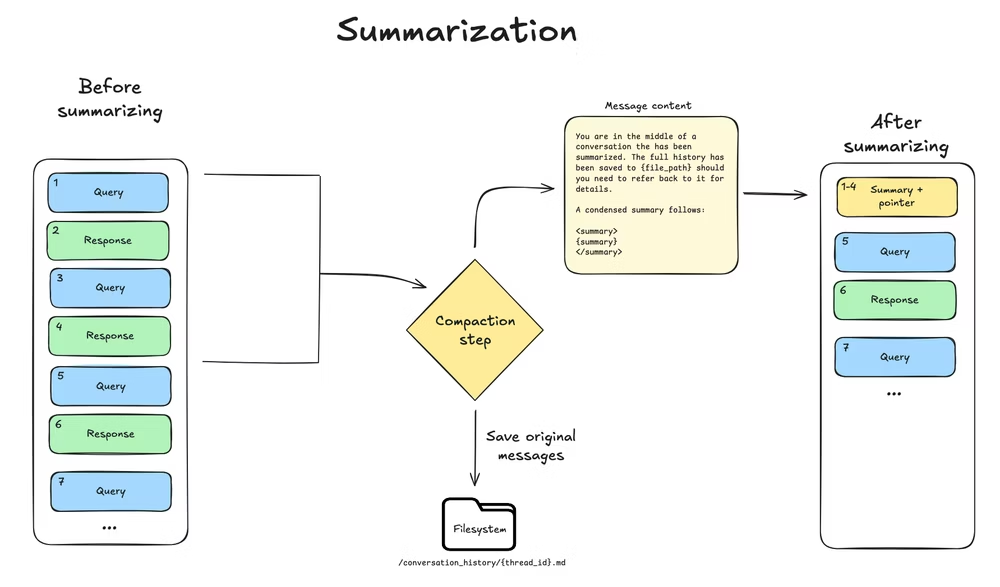
摘要
当上下文大小超过了模型的上下文窗口限制(例如达到了 max_input_tokens 的 85%),并且没有更多的上下文可以被卸载(即没法再通过存文件来省空间了)时,Deep Agent 会对消息历史进行摘要。
这个过程包含两个部分:
- 上下文内摘要:
LLM 会生成一份结构化的对话摘要,内容包括会话意图、创建的工件(产物)以及后续步骤。这份摘要将替代 Agent 工作记忆中的完整对话历史。 - 文件系统归档:
完整的、原始的对话消息会被写入文件系统,作为一份标准记录保存下来。
这种双重方法确保了 Agent 既能通过摘要掌握其目标和进度,又能在需要时通过搜索文件系统来恢复具体的细节。
配置:
- 触发阈值:当上下文占用达到模型配置文件中
max_input_tokens的 85% 时触发。 - 保留策略:保留 10% 的 Token 作为最近的上下文(即保留最新的对话内容不被压缩)。
- 默认回退值:如果无法获取模型配置文件,则默认回退到 170,000 Token 触发阈值,并保留 6 条消息。
- 错误处理:如果任何模型调用抛出了标准的
ContextOverflowError(上下文溢出错误),Deep Agent 会立即回退到摘要模式,并使用“摘要 + 最近保留的消息”进行重试。 - 处理方式:旧的消息由模型进行摘要生成
从 Agent 流式传输的 Token 通常会包含摘要步骤生成的 Token。你可以利用它们关联的元数据来过滤掉这些 Token:
for chunk in agent.stream(
{"messages": [...]},
stream_mode="messages",
version="v2",
):
token, metadata = chunk["data"]
if metadata.get("lc_source") == "summarization":
continue
else:
...摘要工具
摘要工具中间件需要 deepagents>=1.6.0 版本。
Deep Agents 包含一个可选的摘要工具,使 Agent 能够在合适的时机(例如在任务之间)触发摘要,而不是仅在达到固定的 Token 间隔时触发。
你可以通过将该工具添加到中间件列表中来启用它:
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import (
create_summarization_tool_middleware,
)
backend = StateBackend # if using default backend 内存状态
model = "google_genai:gemini-3.1-pro-preview"
agent = create_deep_agent(
model=model,
middleware=[
create_summarization_tool_middleware(model, backend),
],
)启用此功能不会禁用模型上下文限制达到 85% 时的默认摘要操作。有关详细信息,请参阅 SummarizationToolMiddleware API 参考文档
6.8 子智能体上下文隔离
子智能体是解决上下文膨胀问题的利器。当主代理使用那些会产生大量输出的工具(如网络搜索、文件读取、数据库查询)时,上下文窗口会迅速被填满。子智能体可以将这些工作隔离开来——主代理只会收到最终结果,而不会看到产生该结果所经历的数十次工具调用。你还可以独立配置每个子智能体(例如模型、工具、系统提示词和技能),使其与主代理不同。
工作原理:
- 主代理拥有一个用于分配工作的任务工具。
- 子智能体带着自己全新的上下文开始运行。
- 子智能体自主执行任务直到完成。
- 子智能体向主代理返回一份最终报告。
- 主代理的上下文保持干净。
最佳实践:
- 委托复杂任务:对于那些会弄乱主代理上下文的多步骤工作,请使用子智能体。
- 保持子智能体响应简洁:指示子智能体返回摘要,而不是原始数据:
research_subagent = {
"name": "researcher",
"description": "Conducts research on a topic",
"system_prompt": """You are a research assistant.
IMPORTANT: Return only the essential summary (under 500 words).
Do NOT include raw search results or detailed tool outputs.""",
"tools": [web_search],
}利用文件系统处理大数据:子智能体可以将结果写入文件;主代理只需读取它需要的部分。有关配置和上下文管理的详情,请参阅 Subagents 文档,了解运行时上下文传播和每个子智能体的命名空间管理。
6.9 长期记忆
使用默认文件系统时,Deep Agent 的工作记忆文件存储在 Agent 状态中,这仅在线程内持久化。长期记忆功能使 Deep Agent 能够跨不同的线程和对话持久化信息。Deep Agents 可以利用长期记忆来存储用户偏好、积累的知识、研究进度或任何应该超出单次会话范围的信息。
要使用长期记忆,你必须使用 CompositeBackend,它将特定路径(通常是 /memories/)路由到 LangGraph Store,后者提供持久的跨线程持久化。CompositeBackend 是一种混合存储系统,其中一些文件无限期持久化,而其他文件仍限定在单个线程范围内
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
def make_backend(runtime):
return CompositeBackend(
default=StateBackend(runtime),
routes={"/memories/": StoreBackend(runtime)},
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
store=InMemoryStore(),
backend=make_backend,
system_prompt="""When users tell you their preferences, save them to
/memories/user_preferences.txt so you remember them in future conversations.""",
)你不需要预先填充 /memories/ 目录下的文件。你只需提供后端配置、存储库以及系统提示词指令,告诉 Agent 该保存什么以及保存在哪里。例如,你可以提示 Agent 将偏好设置存储在 /memories/preferences.txt 中。该路径初始为空,当用户分享值得记住的信息时,Agent 会使用其文件系统工具(write_file、edit_file)按需创建文件。
若要预先植入记忆,请在 LangSmith 上部署时使用 Store API。有关设置和用例,请参阅 长期记忆 文档。
6.10 最佳实践
- 从正确的输入上下文开始 —— 保持记忆最小化,仅用于始终相关的约定;使用聚焦的技能(Skills)来处理特定任务的能力。
- 利用子代理处理繁重工作 —— 将多步骤、输出量大的任务委托出去,以保持主代理的上下文干净。
- 在配置中调整子代理输出 —— 如果你在调试时注意到子代理生成了过长的输出,可以在子代理的
system_prompt中添加指导,要求其创建摘要和总结返回内容。 - 使用文件系统 —— 将大量输出持久化到文件中(例如子代理写入或自动卸载),以便活动上下文保持小巧;当模型需要细节时,可以使用
read_file和grep拉取片段。 - 记录长期记忆结构 —— 告诉 Agent 什么内容存储在
/memories/中以及如何使用它。 - 为工具传递运行时上下文 —— 使用上下文传递用户元数据、API 密钥以及其他工具所需的静态配置。
6.11 相关资源
- Harness —— 上下文管理概览、卸载、摘要
- 子代理 —— 上下文隔离、运行时上下文传播
- 长期记忆 —— 跨线程持久化
- 技能 —— 渐进式披露和技能编写
- 后端 —— 文件系统后端和 CompositeBackend
- 上下文概念概览 —— 上下文类型和生命周期
7 后端
Deep Agents 通过 ls、read_file、write_file、edit_file、glob 和 grep 等工具向 Agent 暴露了一个文件系统界面。这些工具通过一个可插拔的后端进行操作。read_file 工具在所有后端中原生支持图像文件(.png、.jpg、.jpeg、.gif、.webp),并将它们作为多模态内容块返回。
沙箱和 LocalShellBackend 还提供了一个 execute 工具。本页面将解释如何:
- 选择后端,
- 将不同路径路由到不同后端,
- 实现你自己的虚拟文件系统(例如 S3 或 Postgres),
- 设置文件系统访问权限,
- 遵守后端协议
7.1 起步
这里有几个预构建的文件系统后端,你可以快速在你的 Deep Agent 中使用:
| 内置后端 | 描述 |
|---|---|
默认agent = create_deep_agent(model="...") |
状态中的临时存储。代理的默认文件系统后端存储在 langgraph 状态中。请注意,此文件系统仅在线程内持久化。 |
本地文件系统持久化agent = create_deep_agent(..., backend=FilesystemBackend(root_dir="/Users/...")) |
这使 Deep Agent 能够访问你本地机器的文件系统。你可以指定代理有权访问的根目录。请注意,提供的 root_dir 必须是绝对路径。 |
持久化存储 (LangGraph Store)agent = create_deep_agent(..., backend=StoreBackend()) |
这使代理能够访问跨线程持久化的长期存储。这对于存储长期记忆或适用于代理多次执行的指令非常有用。 |
沙箱agent = create_deep_agent(..., backend=sandbox) |
在隔离环境中执行代码。沙箱提供文件系统工具以及用于运行 Shell 命令的 execute 工具。可选择 Modal、Daytona、Deno 或本地 VFS。 |
本地 Shellagent = create_deep_agent(..., backend=LocalShellBackend(...)) |
直接在主机上访问文件系统和执行 Shell。无隔离——仅在受控的开发环境中使用。见下方的安全注意事项。 |
| 复合 默认临时, /memories/ 持久化。 |
复合后端具有最大的灵活性。你可以指定文件系统中的不同路由指向不同的后端。见下方的复合路由示例。 |
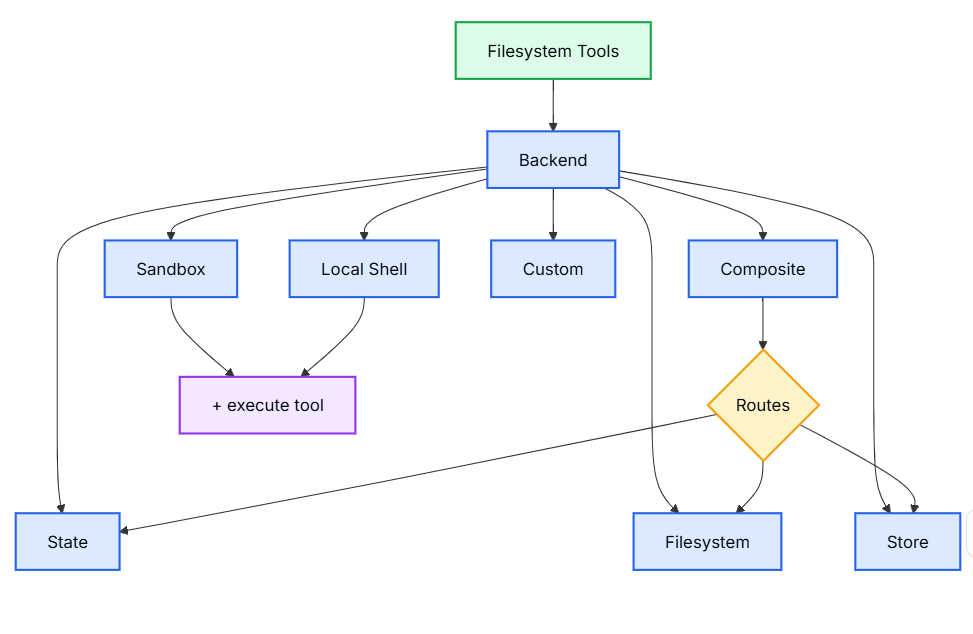
7.2 内置后端
7.2.1 StateBackend (ephemeral)
# By default we provide a StateBackend
agent = create_deep_agent(model="google_genai:gemini-3.1-pro-preview")
# Under the hood, it looks like
from deepagents.backends import StateBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=StateBackend()
)工作原理:
- 通过
StateBackend将文件存储在当前线程的 LangGraph 代理状态中。 - 通过检查点(checkpoints),在同一线程的多个代理回合中保持持久化。
最适合:
- 作为代理写入中间结果的草稿纸(scratch pad)。
- 自动移除(eviction)大型工具输出,随后代理可以逐块读回这些输出。
注意: 此后端由监督者代理(supervisor agent)和子代理(subagents)共享,子代理写入的任何文件在子代理执行完成后,仍会保留在 LangGraph 代理状态中。这些文件将继续可供监督者代理和其他子代理使用。
7.2.2 FilesystemBackend (本地磁盘)
FilesystemBackend 会在一个可配置的根目录下,进行真实文件的读取和写入操作。
FilesystemBackend 的核心作用是将 Agent 的文件操作直接映射到你指定的本地磁盘目录。当 Agent 使用 write_file 或 read_file 工具时,它会真实地创建、修改或读取你硬盘上的文件。
⚠️ 安全警告详解
你贴出的这段文字,本质上是一份高风险操作的安全清单。我们来逐条拆解:
适用与不适用场景
- 适用:
- 本地开发 CLI:比如你自己在电脑上运行的编程助手,需要修改你的项目代码。
- CI/CD 流水线:在自动化的构建和部署流程中,Agent 需要生成或修改文件。
- 不适用:
- Web 服务器或 HTTP API:绝对禁止。如果你的 Agent 通过网页接口提供服务,使用
FilesystemBackend意味着任何用户都可能通过提示词注入等方式,让 Agent 读取或删除服务器上的任意文件。在这种场景下,必须使用StateBackend或沙箱后端。
- Web 服务器或 HTTP API:绝对禁止。如果你的 Agent 通过网页接口提供服务,使用
主要安全风险
- 秘密泄露:Agent 可以读取其权限范围内的任何文件,包括
.env、id_rsa等包含 API 密钥和凭证的敏感文件。 - SSRF 攻击:如果 Agent 同时拥有网络访问工具(如
curl),它可能会将读取到的秘密文件内容发送到外部恶意服务器。 - 不可逆的文件修改:Agent 的操作是永久性的。一个错误的指令可能导致
rm -rf式的灾难性后果,文件被删除后难以恢复。
推荐的安全防护措施
- 启用 HITL (Human-in-the-Loop):为
execute或文件写入等敏感操作设置人工审批环节,让 AI 在执行危险操作前必须获得你的确认。 - 隔离秘密文件:确保 Agent 可访问的目录(
root_dir)中不包含任何敏感信息。 - 生产环境使用沙箱:在任何生产环境中,都应使用
SandboxBackend(如基于 Docker 的沙箱),将 Agent 的操作限制在一个完全隔离的环境中。 - 强制开启虚拟模式 (virtual_mode=True):这是最关键的一点。在初始化
FilesystemBackend时,必须同时设置root_dir和virtual_mode=True。virtual_mode=True会阻止 Agent 使用..、~或绝对路径来访问root_dir之外的目录,从而将 Agent 的活动范围牢牢锁在你指定的项目文件夹内。- 警告:如果
virtual_mode=False(默认值),即使设置了root_dir,也没有任何安全防护作用。
from deepagents.backends import FilesystemBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=FilesystemBackend(root_dir=".", virtual_mode=True)
)工作原理:
- 在可配置的
root_dir(根目录)下读取/写入真实文件。 - 你可以选择设置
virtual_mode=True,以便在root_dir下进行路径的沙箱化和标准化。 - 使用安全路径解析,尽可能防止不安全的符号链接遍历,可以使用
ripgrep进行快速grep搜索。
最适合:
- 你机器上的本地项目
- CI 沙箱环境
- 挂载的持久化卷
7.2.3 LocalShellBackend (local shell)
警告: 该后端赋予 Agent 直接的文件系统读写权限以及在你主机上无限制执行 Shell 命令的权限。请务必极其谨慎,仅在合适的环境中使用。
适用场景
- 本地开发命令行工具:例如运行在你自己电脑上的编程助手或开发工具。
- 个人开发环境:你完全信任该 Agent 生成的代码,并且是在你自己的机器上运行。
- CI/CD 流水线:前提是必须做好了完善的密钥管理。
不适用场景
- 生产环境:例如 Web 服务器、API 服务或多租户系统(绝对禁止)。
- 处理不可信的用户输入:或者执行不可信的代码时。
安全风险
- 任意命令执行:Agent 可以以你的用户权限执行任何 Shell 命令(例如
rm -rf /或格式化硬盘)。 - 文件读取:Agent 可以读取任何可访问的文件,包括敏感信息(API 密钥、凭证、
.env文件)。 - 秘密泄露:敏感数据可能会被暴露。
- 不可逆的操作:文件修改和命令执行是永久性的,无法撤销。
- 主机直接运行:命令直接在你的宿主机系统上运行,而不是在隔离环境中。
- 资源耗尽:命令可能会消耗无限的 CPU、内存或磁盘空间(例如挖矿脚本或死循环)。
推荐的安全防护措施
- 启用 HITL (Human-in-the-Loop):强烈建议开启人工介入中间件,在执行操作前进行审查和批准。
- 仅在专用环境运行:永远不要在共享系统或生产系统上使用。
- 使用沙箱后端:如果生产环境确实需要执行 Shell 命令,请使用基于 Docker 的沙箱后端。
关于虚拟模式的重要说明
注意: 当启用了 Shell 访问权限时,设置
virtual_mode=True无法提供任何安全保障。因为 Shell 命令(如cd /或cat /etc/passwd)可以绕过文件系统的限制,访问系统上的任何路径。
from deepagents.backends import LocalShellBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=LocalShellBackend(root_dir=".", env={"PATH": "/usr/bin:/bin"})
)它是如何工作的?
- 继承文件功能:它首先包含了
FilesystemBackend的所有功能,意味着 Agent 可以读写文件。 - 增加执行工具:它提供了一个
execute工具,允许 Agent 运行 Shell 命令。 - 无沙箱运行:这是最关键的一点。命令是通过 Python 的
subprocess.run(shell=True)直接在你的主机上运行的。这意味着没有隔离层,Agent 运行的程序就是你运行的程序。 - 资源限制:为了防止命令卡死或输出过大,它支持以下配置:
timeout:超时时间(默认 120 秒)。max_output_bytes:最大输出字节数(默认 100,000 字节)。env/inherit_env:用于控制环境变量。
关键安全机制:关于 root_dir
这里有一个非常重要的细节需要注意:
"Shell commands use root_dir as the working directory but can access any path on the system."
- 工作目录:命令会在
root_dir指定的目录下启动(就像你先cd进了那个文件夹)。 - 访问权限:但是,Shell 命令本身不受
root_dir限制。如果 Agent 运行cat /etc/passwd或者ls /,它依然可以访问你系统上的任何文件。 - 结论:在
LocalBackend中,root_dir仅仅是一个“起始位置”,而不是一个“监狱”。
最佳使用场景
- 本地编程助手:当你自己在电脑上开发,需要一个能帮你运行代码、测试脚本的助手时。
- 快速迭代开发:在开发过程中,当你信任 Agent 能够帮你执行命令(如
npm install,python test.py)以加快进度时。
7.2.4 StoreBackend (LangGraph store)
from langgraph.store.memory import InMemoryStore
from deepagents.backends import StoreBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=StoreBackend(
namespace=lambda ctx: (ctx.runtime.context.user_id,),
),
store=InMemoryStore() # Good for local dev; omit for LangSmith Deployment
)在本地开发时,我们通常需要自己配置一个 Store(比如使用 InMemoryStore 或连接 Redis/Postgres)来让 Agent 拥有长期记忆或跨会话的数据存储能力。
但是,当你把代码部署到 LangSmith Deployment 平台时:
- 不要在
create_deep_agent函数中传入store=...参数。 - 原因:LangSmith 平台会自动为你的 Agent 分配并管理一个持久化的存储后端。
namespace 参数用于控制数据隔离。在多用户部署中,务必设置命名空间工厂,以实现按用户或租户隔离数据。
工作原理:StoreBackend 将文件存储在运行时提供的 LangGraph BaseStore 中,从而实现跨线程的持久化存储。
最适合:
- 当你已经配置并运行了 LangGraph 存储时(例如 Redis、Postgres 或基于
BaseStore的云端实现)。 - 当你通过 LangSmith Deployment 部署代理时(系统会自动为你的代理配置一个存储)。
命名空间工厂
命名空间工厂控制 StoreBackend 读取和写入数据的位置。它接收一个 LangGraph Runtime(运行时),并返回一个用作存储命名空间的字符串元组。请使用命名空间工厂来隔离用户、租户或助手之间的数据。
在构建 StoreBackend 时,将命名空间工厂传递给 namespace 参数
NamespaceFactory = Callable[[Runtime], tuple[str, ...]]Runtime(运行时)提供:
rt.context—— 通过 LangGraph 上下文模式传递的用户自定义上下文(例如user_id)。rt.server_info—— 在 LangGraph Server 上运行时特有的服务器元数据(助手 ID、图 ID、认证用户)。rt.execution_info—— 执行身份信息(线程 ID、运行 ID、检查点 ID)。
Runtime 参数在 deepagents>=0.5.2 中可用。早期的 0.5.x 版本传递的是 BackendContext——请参见下文关于从 BackendContext 迁移的说明。rt.server_info 和 rt.execution_info 需要 deepagents>=0.5.0 版本。
通用命名空间模式
from deepagents.backends import StoreBackend
# Per-user: each user gets their own isolated storage
backend = StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
)
# Per-assistant: all users of the same assistant share storage
backend = StoreBackend(
namespace=lambda rt: (
rt.server_info.assistant_id,
),
)
# Per-thread: storage scoped to a single conversation
backend = StoreBackend(
namespace=lambda rt: (
rt.execution_info.thread_id,
),
)这段话主要是在讲如何定义和限制命名空间的规则,翻译过来就是:
您可以组合多个组件来创建更具体的作用域——例如,使用 (user_id, thread_id) 来实现每个用户、每个会话的隔离,或者添加像 "filesystem" 这样的后缀,以便在同一个作用域使用多个存储命名空间时进行区分。
命名空间组件必须仅包含字母数字字符、连字符、下划线、点、@、+、冒号和波浪号。通配符(*、?)会被拒绝,以防止 glob 注入。
如果没有提供命名空间工厂(namespace factory),传统的默认行为会使用 LangGraph 配置元数据中的 assistant_id。这意味着同一个 assistant 的所有用户将共享同一份存储。对于要上线到生产环境的多用户应用,请务必提供一个命名空间工厂。
7.2.4 CompositeBackend (router)
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(),
}
),
store=InMemoryStore() # Store passed to create_deep_agent, not backend
)工作原理
CompositeBackend 会根据路径前缀,将文件操作路由到不同的后端。并且,它会在文件列表和搜索结果中保留原始的路径前缀。
适用场景
- 混合存储需求:当你希望 Agent 同时拥有临时存储(ephemeral)和跨线程存储(cross-thread)时,
CompositeBackend允许你同时提供一个StateBackend和一个StoreBackend。 - 统一文件视图:当你有多个信息来源,但希望将它们作为单一文件系统的一部分提供给 Agent 时。
举个例子
假设你有长期记忆存储在某个 Store 的 /memories/ 路径下,同时你还有一个自定义后端,里面存放着可以通过 /docs/ 访问的文档。使用 CompositeBackend,你可以把这两者合并,让 Agent 感觉像是在操作同一个文件系统。
7.3 指定一个后端
请传递一个后端实例给 create_deep_agent(model=..., backend=...)。文件系统中间件会利用它来支持所有的工具操作。该后端必须实现 BackendProtocol 接口(例如 StateBackend()、FilesystemBackend(root_dir=".") 或 StoreBackend())。
如果省略该参数,默认会使用 StateBackend()
7.4 不同后端路由
将命名空间的不同部分路由到不同的后端。这通常用于持久化存储 /memories/*(例如长期记忆),同时保持其他所有内容仅作为临时(ephemeral)存储。
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, FilesystemBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": FilesystemBackend(root_dir="/deepagents/myagent", virtual_mode=True),
},
)
)行为表现
/workspace/plan.md→ 路由到 StateBackend(临时存储,用完即焚)。/memories/agent.md→ 路由到 FilesystemBackend,实际存储路径为/deepagents/myagent(持久化存储)。ls、glob、grep等命令会汇总所有后端的结果,并显示原始的路径前缀(让你感觉像是在操作同一个文件系统)。
注意事项
- 更长前缀优先:如果规则有冲突,路径匹配更精确(前缀更长)的规则会胜出。例如,专门针对
/memories/projects/的路由规则,可以覆盖掉通用的/memories/规则。 - StoreBackend 路由的前提:如果你要路由到
StoreBackend,请务必通过create_deep_agent(model=..., store=...)提供一个 store 实例,或者确保平台已经配置好了 store。
7.5 使用虚拟化文件系统
构建一个自定义后端,将远程或数据库文件系统(例如 S3 或 Postgres)映射到 tools 命名空间中。
设计指南:
- 路径映射:路径采用绝对路径形式(如
/x/y.txt)。你需要自行决定如何将其映射到底层的存储键或数据行。 - 高效查询:高效地实现
ls(列出目录)和glob(模式匹配)。如果底层存储支持,尽量在服务端进行过滤,否则再在本地进行过滤。 - 外部持久化存储:对于 S3、Postgres 等外部持久化存储,在调用写入或编辑操作的结果中,请将
files_update设为None(Python)或直接省略filesUpdate(JS)——只有纯内存状态的后端才需要返回文件更新字典。 - 方法命名:请直接使用
ls和glob作为方法名。 - 错误处理:返回结构化的结果类型。如果遇到文件缺失或模式无效的情况,请在结果中包含一个
error字段,不要直接抛出异常。
S3 风格的大纲示例:
from deepagents.backends.protocol import (
BackendProtocol, WriteResult, EditResult, LsResult, ReadResult, GrepResult, GlobResult,
)
class S3Backend(BackendProtocol):
def __init__(self, bucket: str, prefix: str = ""):
self.bucket = bucket
self.prefix = prefix.rstrip("/")
def _key(self, path: str) -> str:
return f"{self.prefix}{path}"
def ls(self, path: str) -> LsResult:
# List objects under _key(path); build FileInfo entries (path, size, modified_at)
...
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> ReadResult:
# Fetch object; return ReadResult(file_data=...) or ReadResult(error=...)
...
def grep(self, pattern: str, path: str | None = None, glob: str | None = None) -> GrepResult:
# Optionally filter server‑side; else list and scan content
...
def glob(self, pattern: str, path: str = "/") -> GlobResult:
# Apply glob relative to path across keys
...
def write(self, file_path: str, content: str) -> WriteResult:
# Enforce create‑only semantics; return WriteResult(path=file_path, files_update=None)
...
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
# Read → replace (respect uniqueness vs replace_all) → write → return occurrences
...数据表结构:
files(path text primary key, content text, created_at timestamptz, modified_at timestamptz)
(包含路径、内容、创建时间和修改时间字段)
将工具操作映射到 SQL 上:
ls(列出目录):使用 WHERE path LIKE $1 || '%' 进行查询。
glob(模式匹配):可以在 SQL 语句中直接过滤,或者先获取数据再在 Python 中应用 glob 规则。
grep(文本搜索):可以先通过文件扩展名或最后修改时间拉取候选行,然后再逐行扫描匹配内容。
7.6 权限
通过权限设置,你可以用一种声明式的方式,明确控制代理(Agent)能够读取或写入哪些文件和目录。这些权限规则适用于内置的文件系统工具,并且会在调用后端(backend)之前进行预先评估。
from deepagents import create_deep_agent, FilesystemPermission
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
),
"/policies/": StoreBackend(
namespace=lambda rt: (rt.context.org_id,),
),
},
),
permissions=[
FilesystemPermission(
operations=["write"],
paths=["/policies/**"],
mode="deny",
),
],
)如果想了解完整的配置选项(包括规则排序、子代理权限以及复合后端交互等),请查阅权限指南
7.7 添加策略钩子
对于那些基于路径的允许/拒绝规则之外的自定义验证逻辑(比如速率限制、审计日志、内容审查等),可以通过继承(subclassing)或者包装(wrapping)一个后端来执行企业级的规则
from deepagents.backends.filesystem import FilesystemBackend
from deepagents.backends.protocol import WriteResult, EditResult
class GuardedBackend(FilesystemBackend):
def __init__(self, *, deny_prefixes: list[str], **kwargs):
super().__init__(**kwargs)
self.deny_prefixes = [p if p.endswith("/") else p + "/" for p in deny_prefixes]
def write(self, file_path: str, content: str) -> WriteResult:
if any(file_path.startswith(p) for p in self.deny_prefixes):
return WriteResult(error=f"Writes are not allowed under {file_path}")
return super().write(file_path, content)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
if any(file_path.startswith(p) for p in self.deny_prefixes):
return EditResult(error=f"Edits are not allowed under {file_path}")
return super().edit(file_path, old_string, new_string, replace_all)通用包装器(适用于任何后端)
from deepagents.backends.protocol import (
BackendProtocol, WriteResult, EditResult, LsResult, ReadResult, GrepResult, GlobResult,
)
class PolicyWrapper(BackendProtocol):
def __init__(self, inner: BackendProtocol, deny_prefixes: list[str] | None = None):
self.inner = inner
self.deny_prefixes = [p if p.endswith("/") else p + "/" for p in (deny_prefixes or [])]
def _deny(self, path: str) -> bool:
return any(path.startswith(p) for p in self.deny_prefixes)
def ls(self, path: str) -> LsResult:
return self.inner.ls(path)
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> ReadResult:
return self.inner.read(file_path, offset=offset, limit=limit)
def grep(self, pattern: str, path: str | None = None, glob: str | None = None) -> GrepResult:
return self.inner.grep(pattern, path, glob)
def glob(self, pattern: str, path: str = "/") -> GlobResult:
return self.inner.glob(pattern, path)
def write(self, file_path: str, content: str) -> WriteResult:
if self._deny(file_path):
return WriteResult(error=f"Writes are not allowed under {file_path}")
return self.inner.write(file_path, content)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
if self._deny(file_path):
return EditResult(error=f"Edits are not allowed under {file_path}")
return self.inner.edit(file_path, old_string, new_string, replace_all)7.8 从后端工厂迁移
在 deepagents>=0.5.2 (Python) 和 deepagents>=1.9.1 (TypeScript) 版本中,命名空间工厂(namespace factories)现在接收的是 LangGraph Runtime 对象,而不再是之前的 BackendContext 包装器。
虽然旧的 BackendContext 形式通过向后兼容的 .runtime 和 .state 访问器依然可以使用,但这些访问器会发出弃用警告,并且将在 deepagents>=0.7 版本中被正式移除。
具体变动如下:
- 工厂函数的参数现在是一个 Runtime 对象,不再是 BackendContext。
- 去掉
.runtime访问器 —— 例如,原本的ctx.runtime.context.user_id现在需要改为rt.server_info.user.identity。 - 没有针对
ctx.state的直接替代方案。命名空间信息在单次运行(run)的生命周期内应当是只读且稳定的,而 state(状态)是可变的,并且会随着每一步(step)发生变化——如果基于它来派生命名空间,可能会导致数据被存入不一致的键(keys)下。如果你有必须读取代理状态(agent state)的用例,请提交一个 Issue(问题反馈)。
# Before (deprecated, removed in v0.7)
StoreBackend(
namespace=lambda ctx: (ctx.runtime.context.user_id,),
)
# After
StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
)7.9 协议引用
后端,必须包含以下这些核心方法和数据类型:
必须实现的核心方法:
- ls(path: str):列出目录内容。返回的条目至少要包含
path(路径)。如果有条件,尽量带上is_dir(是否目录)、size(大小)和modified_at(修改时间)。为了保证输出结果稳定,记得按路径进行排序。 - read(file_path: str, offset: int = 0, limit: int = 2000):读取文件数据。如果文件不存在,不要抛出异常,而是返回一个带有错误信息的
ReadResult(error="Error: File '/x' not found")。 - grep(pattern: str, path: Optional[str] = None, glob: Optional[str] = None):在文件中搜索文本。返回结构化的匹配结果;如果遇到错误,同样返回带有
error字段的GrepResult。 - glob(pattern: str, path: str = "/"):根据模式匹配文件。返回匹配到的文件列表(如果没有匹配到则返回空列表)。
- write(file_path: str, content: str):写入文件(仅限创建新文件)。如果文件已存在(发生冲突),返回带有
error的WriteResult。如果写入成功,需要设置path;对于纯内存状态的后端,需要设置files_update={...},而对于外部存储后端(如 S3、Postgres),则应将files_update设为None。 - edit(file_path: str, old_string: str, new_string: str, replace_all: bool = False):编辑文件内容。除非
replace_all=True,否则必须确保old_string在文件中是唯一的。如果找不到要替换的字符串,返回错误;如果成功,需要在结果中包含替换的次数(occurrences)。
支持的数据类型(结构化返回结果):
- LsResult:包含
error和entries(成功时是FileInfo列表,失败时为 None)。 - ReadResult:包含
error和file_data(成功时是FileData字典,失败时为 None)。 - GrepResult:包含
error和matches(成功时是GrepMatch列表,失败时为 None)。 - GlobResult:包含
error和matches(成功时是FileInfo列表,失败时为 None)。 - WriteResult:包含
error、path和files_update。 - EditResult:包含
error、path、files_update和occurrences(替换次数)。
基础数据字段:
- FileInfo:必须包含
path,可选包含is_dir、size、modified_at。 - GrepMatch:包含
path(文件路径)、line(行号)、text(匹配到的文本内容)。 - FileData:包含
content(内容字符串)、encoding(编码,如 "utf-8" 或 "base64")、created_at和modified_at。
8 子智能体
8.1 使用理由
子代理主要是为了解决“上下文臃肿”的问题。 当主代理使用那些会产生大量输出的工具(比如网页搜索、读取文件、数据库查询)时,上下文窗口很快就会被各种中间结果塞满。而子代理可以把这些繁琐的细节工作隔离出去——主代理最终只会收到一个简洁的结论,而不需要去消化为了得出这个结论所执行的几十次工具调用。
什么时候应该使用子代理:
✅ 处理那些会让主代理上下文变得杂乱无章的多步骤任务。
✅ 处理需要专属指令或特定工具的专业领域任务。
✅ 需要调用不同模型能力(比如某个步骤需要更强的推理模型,另一个需要更快的模型)的任务。
✅ 当你希望主代理能专注于高层级的协调与指挥时。
什么时候不应该使用子代理:
❌ 简单的、单一步骤就能搞定的任务。
❌ 需要保留或依赖中间步骤上下文信息的任务。
❌ 使用子代理带来的额外开销(比如时间、成本)超过了它带来的好处时。
简单来说,子代理就像是主代理手下的“专业外包团队”,把脏活累活打包出去,让主代理保持头脑清醒,只关注最终交付的结果。
8.2 配置
子代理(subagents)应该是一个由字典或 CompiledSubAgent 对象组成的列表。 这里面主要涉及两种类型:
默认子代理(Default subagent)
除非你手动提供了一个同名的同步子代理,否则 Deep Agents 框架会自动为你添加一个同步的“通用子代理(general-purpose subagent)”。
关于这个默认子代理,你有三种处理方式:
- 替换它:直接传入一个你自己写的、名字叫
general-purpose的子代理即可。 - 重命名或修改它的提示词(re-prompt):在当前激活的 harness profile(配置档案)上,设置
general_purpose_subagent=GeneralPurposeSubagentProfile(...)。 - 彻底移除它:在当前激活的 harness profile 上,设置
general_purpose_subagent=GeneralPurposeSubagentProfile(enabled=False)。
如果在经过上述操作后,系统中没有任何同步子代理了,Deep Agents 就不会再自动添加那个“任务工具(task tool)”。需要注意的是,这种机制只影响同步子代理,异步子代理依然会使用在“异步子代理”章节中描述的那些异步任务工具。
基于字典的子智能体
对于大多数使用场景,你只需要创建一个符合规范的字典,并包含以下字段即可
| 字段 (Field) | 类型 (Type) | 说明与继承规则 (Description & Inheritance) |
|---|---|---|
| name | str |
必填。子代理的唯一标识符。主代理调用 task() 工具时会用到它,同时也会作为元数据出现在消息流中。 |
| description | str |
必填。描述子代理的功能。需要具体且以行动为导向,主代理会根据它来决定何时委派任务。 |
| system_prompt | str |
必填。子代理的专属指令(包含工具使用指南和输出格式要求)。不会从主代理继承。 |
| tools | list[Callable] |
选填。子代理可用的工具列表。默认继承自主代理;一旦指定,将完全覆盖继承的工具。 |
| model | str | BaseChatModel |
选填。用于覆盖主代理的模型(可填模型字符串如 'openai:gpt-5.4' 或模型对象)。默认继承自主代理。 |
| middleware | list[Middleware] |
选填。额外的中间件(用于自定义行为、日志或限流等)。不会从主代理继承。 |
| interrupt_on | dict[str, bool] |
选填。配置特定工具的“人机协同”中断功能(需配合 checkpointer)。默认继承自主代理,子智能体的值会覆盖默认值。 |
| skills | list[str] |
选填。技能源码的目录路径列表。指定后子智能体将拥有独立的技能集,状态完全隔离。不会从主代理继承。 |
| response_format | ResponseFormat |
选填。结构化输出模式(如 Pydantic 模型)。设置后父代理收到的将是 JSON 而非自由文本。 |
| permissions | list[FilesystemPermission] |
选填。文件系统权限规则。默认继承自主代理;一旦指定,将完全替换掉父代理的权限。 |
- CLI(命令行)用户:你可以直接在磁盘上创建一个
AGENTS.md文件来定义子智能体,完全不用写代码。在这个文件里,name(名称)、description(描述)和model(模型)这些字段直接映射到文件的 YAML 头部(frontmatter)中,而 Markdown 的正文部分就会自动变成system_prompt(系统提示词)。具体的文件格式可以参考“Custom subagents(自定义子智能体)”章节。 - 部署(Deploy)用户:只需要在
subagents/目录下创建对应的文件夹,里面放上它们专属的deepagents.toml配置文件和AGENTS.md文件即可。打包工具(bundler)会自动发现并加载它们。完整的配置指南可以查看“Deploy subagents(部署子智能体)”章节。
对于更复杂的业务流程,你可以直接使用一个预先构建好的 LangGraph 图(CompiledSubAgent)来作为子代理。它的字段定义如下:
编译的子智能体
| 字段 (Field) | 类型 (Type) | 说明 (Description) |
|---|---|---|
| name | str |
必填。子代理的唯一标识符。该名称会作为元数据附加在 AI 消息和流式传输中,方便区分不同的代理。 |
| description | str |
必填。描述这个子代理的具体功能。 |
| runnable | Runnable |
必填。一个已经编译过的 LangGraph 图(传入前必须先调用 .compile() 方法)。 |
8.3 使用子智能体
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
research_subagent = {
"name": "research-agent",
"description": "Used to research more in depth questions",
"system_prompt": "You are a great researcher",
"tools": [internet_search],
"model": "openai:gpt-5.4", # Optional override, defaults to main agent model
}
subagents = [research_subagent]
agent = create_deep_agent(
model="claude-sonnet-4-6",
subagents=subagents
)8.4 使用编译的子智能体
对于更复杂的使用场景,你可以使用 CompiledSubAgent 来提供自定义的子智能体。你可以通过 LangChain 的 create_agent,或者使用图 API 创建一个自定义的 LangGraph 图来构建自定义子智能体。如果你正在创建一个自定义的 LangGraph 图,请确保该图包含一个名为 "messages" 的状态键:
from deepagents import create_deep_agent, CompiledSubAgent
from langchain.agents import create_agent
# Create a custom agent graph
custom_graph = create_agent(
model=your_model,
tools=specialized_tools,
prompt="You are a specialized agent for data analysis..."
)
# Use it as a custom subagent
custom_subagent = CompiledSubAgent(
name="data-analyzer",
description="Specialized agent for complex data analysis tasks",
runnable=custom_graph
)
subagents = [custom_subagent]
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[internet_search],
system_prompt=research_instructions,
subagents=subagents
)8.5 流
在流式传输追踪信息时,代理的名称会以 lc_agent_name 的形式出现在元数据(metadata)中。当你在查看追踪信息时,就可以利用这个元数据来轻松区分数据到底是来自哪个代理的。
下面这个例子展示了如何创建一个名为 main-agent 的深度代理(deep agent),以及一个名为 research-agent 的子代理:
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
research_subagent = {
"name": "research-agent",
"description": "Used to research more in depth questions",
"system_prompt": "You are a great researcher",
"tools": [internet_search],
"model": "google_genai:gemini-3.1-pro-preview", # Optional override, defaults to main agent model
}
subagents = [research_subagent]
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
subagents=subagents,
name="main-agent"
)
8.6 结构化输出
子代理(Subagents)支持结构化输出,这样一来,父代理接收到的就是可预测、易于解析的 JSON 数据,而不再是随意的自由文本。
你只需要在子代理的配置中传入 response_format 参数。当子代理任务完成时,它的结构化响应会被序列化为 JSON,并作为 ToolMessage 的内容返回给父代理。这里的 schema 接受任何 create_agent 所支持的格式,包括 Pydantic 模型、ToolStrategy(...)、ProviderStrategy(...),或者是原生的 schema 类型。
from pydantic import BaseModel, Field
from deepagents import create_deep_agent
class ResearchFindings(BaseModel):
"""Structured findings from a research task."""
summary: str = Field(description="Summary of findings")
confidence: float = Field(description="Confidence score from 0 to 1")
sources: list[str] = Field(description="List of source URLs")
research_subagent = {
"name": "researcher",
"description": "Researches topics and returns structured findings",
"system_prompt": "Research the given topic thoroughly. Return your findings.",
"tools": [web_search],
"response_format": ResearchFindings,
}
agent = create_deep_agent(
model="claude-sonnet-4-6",
subagents=[research_subagent],
)
result = await agent.ainvoke(
{"messages": [{"role": "user", "content": "Research recent advances in quantum computing"}]}
)
# The parent's ToolMessage contains JSON-serialized structured data:
# '{"summary": "...", "confidence": 0.87, "sources": ["https://..."]}'如果不设置 response_format,父代理就会原封不动地收到子代理最后一条消息的文本内容。而一旦设置了它,父代理就一定能收到符合该 schema 的有效 JSON 数据。这在父代理需要以编程方式处理结果,或者需要把结果传递给下游工具时,会非常有用。
关于 schema 类型和策略(工具调用与原生供应商模式)的更多细节,可以查阅“Structured output(结构化输出)”相关文档。
8.7 通用子智能体
除了你自己定义的子代理之外,每个深度代理(deep agent)其实都随时自带一个“通用子代理”(general-purpose subagent)。它的特点如下:
- 拥有和主代理完全相同的系统提示词(system prompt)
- 可以使用完全相同的工具
- 使用相同的模型(除非你手动覆盖)
- 会继承主代理的技能(前提是配置了技能的话)
如何覆盖通用子代理
如果你想在子代理列表中加入一个名为 name="general-purpose" 的子代理,就可以直接替换掉系统默认的那个。通过这种方式,你可以为这个通用子代理单独配置不同的模型、工具或者系统提示词。
from deepagents import create_deep_agent
# Main agent uses Gemini; general-purpose subagent uses GPT
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[internet_search],
subagents=[
{
"name": "general-purpose",
"description": "General-purpose agent for research and multi-step tasks",
"system_prompt": "You are a general-purpose assistant.",
"tools": [internet_search],
"model": "openai:gpt-5.4", # Different model for delegated tasks
},
],
)什么时候使用它
通用子代理非常适合用来实现“上下文隔离”,同时又不需要引入特殊的定制行为。主代理可以将复杂的多步骤任务委托给这个子代理,从而只拿回一个简洁的最终结果,避免了中间繁琐的工具调用过程污染上下文。
举个例子
与其让主代理自己进行 10 次网页搜索,导致大量搜索结果塞满它的上下文,不如直接把这些工作委托给通用子代理:task(name="general-purpose", task="调研量子计算的发展趋势")。这样一来,子代理会在内部默默完成所有的搜索工作,最后只向主代理返回一份精炼的总结。
技能继承机制
当你使用 create_deep_agent 来配置技能时,需要区分两种情况:
- 通用子代理(General-purpose subagent):它会自动继承主代理的所有技能。
- 自定义子代理(Custom subagents):默认情况下不会继承主代理的技能。如果你想让它们拥有特定的技能,需要通过
skills参数为它们单独指定。
只有那些配置了 skills 的子代理才会获得一个 SkillsMiddleware(技能中间件)实例——如果没有传入 skills 参数,自定义子代理是不会有的。
一旦启用了该中间件,技能状态会在父子代理之间实现完全的双向隔离:也就是说,父代理的技能对子代理不可见,同时子代理的技能也不会反向传播给父代理
from deepagents import create_deep_agent
# Research subagent with its own skills
research_subagent = {
"name": "researcher",
"description": "Research assistant with specialized skills",
"system_prompt": "You are a researcher.",
"tools": [web_search],
"skills": ["/skills/research/", "/skills/web-search/"], # Subagent-specific skills
}
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/main/"], # Main agent and GP subagent get these
subagents=[research_subagent], # Gets only /skills/research/ and /skills/web-search/
)8.8 最佳实践
8.8.1 编写清晰的描述
主代理是依靠描述来决定调用哪个子代理的,所以一定要写得具体明确:
✅ 好的例子:“分析财务数据,并生成带有置信度评分的投资见解”
❌ 不好的例子:“处理财务相关的事情”
8.8.2 保持系统详尽的提示词
记得在提示词中包含具体的指导,告诉子代理该如何使用工具以及如何规范输出格式。
research_subagent = {
"name": "research-agent",
"description": "Conducts in-depth research using web search and synthesizes findings",
"system_prompt": """You are a thorough researcher. Your job is to:
1. Break down the research question into searchable queries
2. Use internet_search to find relevant information
3. Synthesize findings into a comprehensive but concise summary
4. Cite sources when making claims
Output format:
- Summary (2-3 paragraphs)
- Key findings (bullet points)
- Sources (with URLs)
Keep your response under 500 words to maintain clean context.""",
"tools": [internet_search],
}8.8.3 精简工具集
只给子代理分配它们真正需要的工具。这样做不仅能提高它们的专注度,还能有效提升安全性
# ✅ Good: Focused tool set
email_agent = {
"name": "email-sender",
"tools": [send_email, validate_email], # Only email-related
}
# ❌ Bad: Too many tools
email_agent = {
"name": "email-sender",
"tools": [send_email, web_search, database_query, file_upload], # Unfocused
}8.8.4 根据任务选择合适的模型
不同的模型在不同的任务上往往各有所长。
subagents = [
{
"name": "contract-reviewer",
"description": "Reviews legal documents and contracts",
"system_prompt": "You are an expert legal reviewer...",
"tools": [read_document, analyze_contract],
"model": "google_genai:gemini-3.1-pro-preview", # Large context for long documents
},
{
"name": "financial-analyst",
"description": "Analyzes financial data and market trends",
"system_prompt": "You are an expert financial analyst...",
"tools": [get_stock_price, analyze_fundamentals],
"model": "openai:gpt-5.4", # Better for numerical analysis
},
]8.8.5 返回简洁的结果
记得在指令中明确要求子代理返回精炼的总结,而不是把未经处理的原始数据直接丢回来。
data_analyst = {
"system_prompt": """Analyze the data and return:
1. Key insights (3-5 bullet points)
2. Overall confidence score
3. Recommended next actions
Do NOT include:
- Raw data
- Intermediate calculations
- Detailed tool outputs
Keep response under 300 words."""
}8.8.6 常见模式
多个专业子智能体,你可以为不同的领域创建专门的子代理:
from deepagents import create_deep_agent
subagents = [
{
"name": "data-collector",
"description": "Gathers raw data from various sources",
"system_prompt": "Collect comprehensive data on the topic",
"tools": [web_search, api_call, database_query],
},
{
"name": "data-analyzer",
"description": "Analyzes collected data for insights",
"system_prompt": "Analyze data and extract key insights",
"tools": [statistical_analysis],
},
{
"name": "report-writer",
"description": "Writes polished reports from analysis",
"system_prompt": "Create professional reports from insights",
"tools": [format_document],
},
]
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt="You coordinate data analysis and reporting. Use subagents for specialized tasks.",
subagents=subagents
)工作流:
- 主代理制定宏观计划
- 将数据收集工作委托给 data-collector(数据收集员)
- 把结果传递给 data-analyzer(数据分析师)
- 将分析出的见解发送给 report-writer(报告撰写员)
- 最终汇编输出
在这个过程中,每个子代理都拥有干净、纯粹的上下文环境,可以全神贯注地只处理自己的任务。
8.8.7 上下文管理
当你带着运行时上下文(runtime context)去调用父智能体时,这些上下文会自动“遗传”给所有的子代理。也就是说,你在调用父代理(invoke / ainvoke)时传入了什么运行时上下文,每个子代理在运行时都会收到一模一样的内容。
这意味着,无论工具是在哪个子代理内部运行,它们都能直接访问到你当初提供给父代理的那些上下文信息
from dataclasses import dataclass
from deepagents import create_deep_agent
from langchain.messages import HumanMessage
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
session_id: str
@tool
def get_user_data(query: str, runtime: ToolRuntime[Context]) -> str:
"""Fetch data for the current user."""
user_id = runtime.context.user_id
return f"Data for user {user_id}: {query}"
research_subagent = {
"name": "researcher",
"description": "Conducts research for the current user",
"system_prompt": "You are a research assistant.",
"tools": [get_user_data],
}
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
subagents=[research_subagent],
context_schema=Context,
)
# Context flows to the researcher subagent and its tools automatically
result = await agent.invoke(
{"messages": [HumanMessage("Look up my recent activity")]},
context=Context(user_id="user-123", session_id="abc"),
)虽然所有的子代理都会默认继承父代理的同一套上下文,但如果你想给某个特定的子代理传递一些“私有”配置,可以通过以下两种方式来实现:
-
使用带命名空间的键(Namespaced keys):
在扁平的上下文映射中,用子代理的名字作为前缀。比如,专门给研究子代理(researcher)设置一个最大深度参数,可以写成researcher:max_depth。 -
在上下文类型中单独定义字段:
直接在你的上下文数据结构(context type)里,把这些特定的配置单独设为独立的字段。
这样就能在保证基础环境共享的同时,灵活地为不同的子代理定制专属参数啦。
from dataclasses import dataclass
from langchain.messages import HumanMessage
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
researcher_max_depth: int | None = None
fact_checker_strict_mode: bool | None = None
result = await agent.invoke(
{"messages": [HumanMessage("Research this and verify the claims")]},
context=Context(
user_id="user-123",
researcher_max_depth=3,
fact_checker_strict_mode=True,
),
)
@tool
def verify_claim(claim: str, runtime: ToolRuntime[Context]) -> str:
"""Verify a factual claim."""
strict_mode = runtime.context.fact_checker_strict_mode or False
if strict_mode:
return strict_verification(claim)
return basic_verification(claim)当同一个工具被父代理和多个子代理共享时,你可以通过 lc_agent_name 元数据(也就是在流式传输中使用的同一个值)来准确判断,到底是哪一个代理发起了这次工具调用。
from langchain.tools import tool, ToolRuntime
@tool
def shared_lookup(query: str, runtime: ToolRuntime) -> str:
"""Look up information."""
agent_name = runtime.config.get("metadata", {}).get("lc_agent_name")
if agent_name == "fact-checker":
return strict_lookup(query)
return general_lookup(query)一方面从 runtime.context 中读取特定代理的专属配置,另一方面则从 runtime.config 的元数据(metadata)中读取 lc_agent_name 来识别调用者。
from langchain.tools import tool, ToolRuntime
@tool
def flexible_search(query: str, runtime: ToolRuntime[Context]) -> str:
"""Search with agent-specific settings."""
agent_name = runtime.config.get("metadata", {}).get("lc_agent_name", "unknown")
ctx = runtime.context
if agent_name == "researcher":
max_results = ctx.researcher_max_depth or 5
else:
max_results = 5
include_raw = False
return perform_search(query, max_results=max_results, include_raw=include_raw)8.8.8 问题处理
问题: 主代理(Main agent)没有把任务分派出去,而是试图自己亲力亲为去干活。
解决方案:
1 把(子代理的)描述写得更具体、更精准一些。
简单来说,如果主代理“抢活干”,通常是因为它没能准确识别出哪些任务该交给谁。通过优化子代理的描述(description),让它能更清晰地匹配到特定任务,主代理就能更准确地触发委派机制啦。
# ✅ Good
{"name": "research-specialist", "description": "Conducts in-depth research on specific topics using web search. Use when you need detailed information that requires multiple searches."}
# ❌ Bad
{"name": "helper", "description": "helps with stuff"}2 指示主代理进行委派
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt="""...your instructions...
IMPORTANT: For complex tasks, delegate to your subagents using the task() tool.
This keeps your context clean and improves results.""",
subagents=[...]
)问题: 明明已经使用了子代理(subagents),但主代理的上下文依然被塞得满满当当。
解决方案:
1 指示子代理返回精简的结果(Instruct subagent to return concise results)
system_prompt="""...
IMPORTANT: Return only the essential summary.
Do NOT include raw data, intermediate search results, or detailed tool outputs.
Your response should be under 500 words."""2 利用文件系统来处理大规模数据(Use filesystem for large data)
system_prompt="""When you gather large amounts of data:
1. Save raw data to /data/raw_results.txt
2. Process and analyze the data
3. Return only the analysis summary
This keeps context clean."""选错了子智能体
问题: 主代理在处理某个任务时,调用了不合适的子代理(比如该做数学题的时候,却叫了个写文章的子代理过来)。
解决方案: 在描述中清晰地区分各个子代理的职能
subagents = [
{
"name": "quick-researcher",
"description": "For simple, quick research questions that need 1-2 searches. Use when you need basic facts or definitions.",
},
{
"name": "deep-researcher",
"description": "For complex, in-depth research requiring multiple searches, synthesis, and analysis. Use for comprehensive reports.",
}
]9 异步子智能体
异步子智能体让主智能体(supervisor agent)能够发起后台任务,并且立刻返回,不用干等着。这样一来,主智能体就可以在子智能体们后台并发干活的同时,继续和用户正常互动。而且,主智能体随时都能去检查任务进度、发送后续的跟进指令,甚至直接取消任务。
这其实是建立在普通子智能体基础上的进阶版——普通的子智能体是同步运行的,主智能必须得等它彻底干完活才能进行下一步。所以,当你遇到那些耗时很长、可以并行处理,或者需要在执行过程中随时调整方向(mid-flight steering)的任务时,用异步主智能就再合适不过啦。
异步子代理是 deepagents 0.5.0 版本中的一项预览功能。预览功能目前仍在积极开发中,相关 API 可能会发生变动。
异步子智能体可以与任何实现了 Agent Protocol(智能体协议)的服务器进行通信。你可以使用 LangSmith Deployments,也可以自行托管任何兼容该协议的服务器。每个子智能体都是独立于主智能体运行的,主智能体会通过 SDK 来控制它们,负责发起任务、检查进度、更新指令以及取消任务
9.1 使用场景
| 维度 | 同步子智能体 (Sync) | 异步智能体 (Async) |
|---|---|---|
| 执行模式 | 主智能体会阻塞等待,直到子智能体彻底完成 | 立即返回一个任务ID,主智能体继续执行其他工作 |
| 并发机制 | 虽然能并行,但属于阻塞式并行 | 非阻塞式并行(互不耽误) |
| 中途更新 | 不支持 | 支持(可通过 update_async_task 发送后续指令) |
| 任务取消 | 不支持 | 支持(可通过 cancel_async_task 取消运行中的任务) |
| 状态管理 | 无状态:每次调用之间没有持久状态 | 有状态:在自己的线程中跨交互保持状态 |
| 最佳适用场景 | 需要等待结果出来后才能继续下一步的任务 | 在聊天中需要交互式管理的长时间、复杂任务 |
9.2 配置异步子智能体
将异步子代理定义为一组 AsyncSubAgent 规格(specs)列表,每个规格指向一个 Agent Protocol(代理协议)服务器
from deepagents import AsyncSubAgent, create_deep_agent
async_subagents = [
AsyncSubAgent(
name="researcher",
description="Research agent for information gathering and synthesis",
graph_id="researcher",
# No url → ASGI transport (co-deployed in the same deployment)
),
AsyncSubAgent(
name="coder",
description="Coding agent for code generation and review",
graph_id="coder",
# url="https://coder-deployment.langsmith.dev" # Optional: HTTP transport for remote
),
]
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
subagents=async_subagents,
)| 字段 | 类型 | 描述 |
|---|---|---|
| name | str | 必填。唯一标识符。主管代理在发起任务时会用到这个名字。 |
| description | str | 必填。说明这个子代理是做什么的。主管代理会根据这段描述,来决定把任务委派给哪一个子代理。 |
| graph_id | str | 必填。对应 Agent Protocol 服务器上的图表 ID(或助手 ID)。如果是基于 LangGraph 的部署,这个 ID 必须和 langgraph.json 里注册的图表相匹配。 |
| url | str | 选填。如果不填,默认使用 ASGI 传输(进程内调用);如果填写了,就会通过 HTTP 传输去连接一个远程的 Agent Protocol 服务器。 |
| headers | dict[str, str] | 选填。发往远程服务器的请求中附带的额外请求头。通常用于你自己托管 Agent Protocol 服务器时的自定义身份验证。 |
对于基于 LangGraph 的部署,如果你采用的是共同部署(co-deployed setups),需要在同一个 langgraph.json 文件中注册所有的图表(graphs)
{
"graphs": {
"supervisor": "./src/supervisor.py:graph",
"researcher": "./src/researcher.py:graph",
"coder": "./src/coder.py:graph"
}
}9.3 使用异步子智能体工具
AsyncSubAgentMiddleware(异步子代理中间件)赋予主管代理(supervisor)的五个核心工具。
| 工具名称 | 作用 | 返回值 |
|---|---|---|
| start_async_task | 启动一个新的后台任务 | 立即返回一个任务 ID |
| check_async_task | 获取某个任务的当前状态和结果 | 任务状态 + 结果(如果已完成) |
| update_async_task | 向正在运行的任务发送新的指令 | 确认信息 + 更新后的状态 |
| cancel_async_task | 停止一个正在运行的任务 | 确认信息 |
| list_async_tasks | 列出所有被追踪的任务及其实时状态 | 所有任务的汇总信息 |
了解任务的生命周期
一次典型的交互通常遵循以下顺序:
- 启动(Launch):在服务器上创建一个新线程,并以任务描述作为输入启动运行(run),然后立即返回线程 ID 作为任务 ID。主管代理会将这个 ID 告知用户,并且不会主动轮询任务是否完成。
- 检查(Check):获取当前运行的状态。如果运行成功,它会提取线程状态来获取子代理的最终输出;如果仍在运行中,则向用户报告当前状态。
- 更新(Update):在同一个线程上创建一个带有“中断多任务(interrupt multitask)”策略的新运行。之前的运行会被打断,子代理会带着完整的对话历史以及新指令重新开始执行。在这个过程中,任务 ID 保持不变。
- 取消(Cancel):调用服务器上的
runs.cancel()接口,并将该任务标记为“已取消(cancelled)”。 - 列出(List):遍历所有被追踪的任务。对于未结束(非终端)的任务,它会并行从服务器获取实时状态;而对于已结束(终端状态,如成功、失败、已取消)的任务,则直接从缓存中返回结果。
9.4 了解状态管理
任务元数据存储在主管代理图(graph)的一个专用状态通道(async_tasks)中,与消息历史分开。这一点至关重要,因为深度代理(deep agents)在上下文窗口填满时会压缩其消息历史。如果任务 ID 仅存在于工具消息中,它们将在压缩过程中丢失。专用通道确保了主管代理即使在经过多轮总结后,依然可以通过 list_async_tasks 随时调取其任务。
每个被追踪的任务都会记录任务 ID、代理名称、线程 ID、运行 ID、状态以及时间戳(created_at、last_checked_at、last_updated_at)。
9.5 选择传输方式
ASGI 传输(共同部署)
当子代理配置中省略了 url 字段时,LangGraph SDK 会使用 ASGI 传输 —— 也就是 SDK 的调用会通过进程内的函数调用进行路由,而不是走 HTTP 网络请求。对于基于 LangGraph 的部署,这要求两个图表(graphs)都注册在同一个 langgraph.json 文件中。
ASGI 传输消除了网络延迟,并且不需要额外的身份验证配置。子代理依然会作为一个拥有独立状态的独立线程运行。这是推荐的默认方式。
HTTP 传输(远程)
添加一个 url 字段即可切换到 HTTP 传输,此时 SDK 的调用会通过网络发送到远程的 Agent Protocol 服务器。
AsyncSubAgent(
name="researcher",
description="Research agent",
graph_id="researcher",
url="https://my-research-deployment.langsmith.dev",
)在 LangGraph 部署中,身份验证(Authentication)是由 LangGraph SDK 自动处理的。它会自动从系统的环境变量中读取 LANGSMITH_API_KEY(或 LANGGRAPH_API_KEY)来完成认证。不过,如果你使用的是自己托管的 Agent Protocol 服务器,则可能会采用其他的身份验证机制。
当你的子代理需要独立扩展(independent scaling)、拥有不同的资源需求(例如某个子代理特别吃内存或显卡),或者是由不同的团队负责维护时,建议使用 HTTP 传输(HTTP transport) 方式。
9.6 选择部署拓扑结构
1. 单一部署(Single deployment)
所有代理都通过 ASGI 传输共同部署在同一台服务器上。对于基于 LangGraph 的部署,你只需要在同一个 langgraph.json 文件中注册所有的图表(graphs)即可。
- 适用场景:这是官方推荐的起步方案。只需要维护一台服务器,而且代理之间零网络延迟,开发和调试都非常方便。
2. 拆分部署(Split deployment)
主管代理(Supervisor)部署在一台服务器上,而子代理(Subagents)部署在另一台服务器上,两者之间通过 HTTP 传输进行通信。
- 适用场景:当子代理需要不同的计算资源配置(例如某些子代理需要更强的 GPU 算力),或者需要独立进行弹性扩展(例如某个子代理调用量极大,需要单独扩容)时使用。
3. 混合部署(Hybrid deployment)
这是一种结合了上述两者的灵活方案。在混合部署中,一部分子代理通过 ASGI 与主管代理共同部署,而另一部分子代理则通过 HTTP 远程部署。
- 适用场景:适合复杂的业务系统。你可以把高频调用、轻量级的子代理放在本地(ASGI)以降低延迟,而把重型、需要独立运维或跨团队协作的子代理放在远程服务器(HTTP)上。
9.7 最佳实践
9.7.1 为本地开发环境配置工作线程池
为本地开发环境配置工作线程池(Worker Pool)大小时,你需要根据并发的子代理运行数量来调整。在使用 langgraph dev 进行本地运行时,每一个正在活跃运行的任务都会占用一个工作线程槽位。举个简单的例子:如果你的主管代理(supervisor)需要同时并发处理 3 个子代理任务,那么你就至少需要配置 4 个槽位(1 个给主管代理本身 + 3 个给并发的子代理)。如果配置的槽位数量不足(Under-provisioning),新的任务启动请求就会被迫进入排队状态,导致程序卡顿或变慢。
langgraph dev --n-jobs-per-worker 109.7.2 撰写清晰的子代理描述
主管代理(Supervisor)正是依靠这些描述来决定该启动哪个子代理。因此,描述一定要具体明确,并且以行动为导向。
# Good
AsyncSubAgent(
name="researcher",
description="Conducts in-depth research using web search. Use for questions requiring multiple searches and synthesis.",
graph_id="researcher",
)
# Bad
AsyncSubAgent(
name="helper",
description="helps with stuff",
graph_id="helper",
)9.7.3 利用 Thread ID进行链路追踪:
在使用基于 LangGraph 的部署时,每一个异步子代理的运行都是一个标准的 LangGraph 运行,并且会在 LangSmith 中完全可见。
- 主管代理的追踪:你可以清晰地看到它调用了哪些工具,例如
launch(启动)、check(检查)、update(更新)、cancel(取消)以及list(列出)。 - 子代理的追踪:每一个子代理的运行都会作为一条独立的追踪记录出现,但它们会通过 Thread ID 相互关联起来。
9.8 问题处理
9.8.1 主管代理在启动后立即轮询
具体表现是:主管代理在启动子代理后,立刻陷入一个循环不断地调用 check(检查状态)。这会导致原本设计的异步执行,实际上变成了阻塞式的同步执行,失去了异步的优势。
解决方案:
- 中间件自动处理:系统内置的中间件通常会自动注入一些系统提示词规则,来防止主管代理出现这种“急不可耐”的轮询行为。
- 手动强化规则:如果这种轮询行为依然存在,你需要在自己的主管代理(Supervisor)的系统提示词(System Prompt)中,进一步强调和强化“不要频繁轮询”或“等待一段时间再检查”的行为指令。
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt="""...your instructions...
After launching an async subagent, ALWAYS return control to the user.
Never call check_async_task immediately after launch.""",
subagents=async_subagents,
)9.8.2 主管代理汇报过时的状态
具体表现为:主管代理在汇报任务进度时,直接引用了对话历史中较早前的旧状态,而不是发起一次新的 check 调用来获取最新进展。
解决方案:
- 依赖中间件提示:系统内置的中间件提示词已经明确告诉模型:“对话历史中的任务状态永远是过时的”。
- 手动添加明确指令:如果模型依然出现这种“偷懒”行为,你需要在主管代理的系统提示词(System Prompt)中增加更明确的指令,要求它在汇报任何状态之前,必须先调用
check或list工具来获取最新数据。
9.8.3 任务ID查找失败
- 具体表现:主管代理(Supervisor)在调用
check或cancel工具时,把任务ID(Task ID)截断或重新格式化了,导致无法找到对应的任务而报错。 - 解决方案:
- 系统内置的中间件提示词通常会指示模型必须使用完整的任务ID。
- 如果截断问题依然存在,这通常是特定模型自身的缺陷。你可以尝试更换一个模型,或者在你的系统提示词(System Prompt)中明确加上:“始终展示完整的 task_id,绝对不要截断或缩写它”。
9.8.4 子代理启动排队而非运行
- 具体表现:启动子代理时程序挂起,或者需要等待非常长的时间才能开始执行。
- 解决方案:这通常是因为工作线程池(Worker Pool)已经被占满了。你需要通过
--n-jobs-per-worker参数来增加线程池的大小,让系统有足够的槽位来运行新的任务。
9.8.5 参考实现
官方提供了一个名为 async-deep-agents 的代码仓库,里面包含了用 Python 和 TypeScript 两种语言编写的、可以直接运行的完整示例。
这些示例不仅可以直接部署到 LangSmith Deployments 上,还完美演示了前面文档中提到的核心概念:一个主管代理(Supervisor)带着研究员(researcher)和程序员(coder)两个子代理,并将它们作为后台任务来异步运行的整个流程。
10 人机回环
某些工具的操作可能比较敏感(比如删除文件、发送邮件、修改数据库等),在执行前必须经过人工审批。Deep Agents 通过 LangGraph 的中断(interrupt)机制完美支持了这一需求。你可以通过在创建 Agent 时配置 interrupt_on 参数,来灵活指定哪些工具在执行前需要“暂停并等待人工批准”
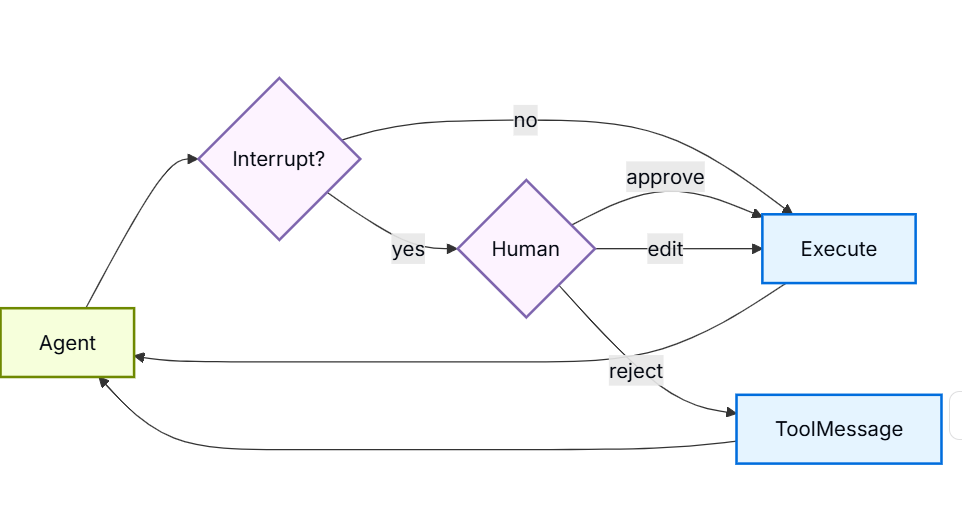
10.1 基本配置
interrupt_on 参数接收一个字典,用来将工具名称映射到对应的中断配置。每个工具都可以进行如下配置:
- 设为
True:启用中断,并使用默认行为(允许 approve、edit 和 reject 操作)。 - 设为
False:为该工具禁用中断。 - 设为
{"allowed_decisions": [...]}:自定义配置,指定具体允许哪些决策。
简单来说,就是通过这个字典来精细控制哪些工具在执行时可以被“打断”或干预,以及干预的方式有哪些。如果
from langchain.tools import tool
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
@tool
def delete_file(path: str) -> str:
"""Delete a file from the filesystem."""
return f"Deleted {path}"
@tool
def read_file(path: str) -> str:
"""Read a file from the filesystem."""
return f"Contents of {path}"
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""Send an email."""
return f"Sent email to {to}"
# Checkpointer is REQUIRED for human-in-the-loop
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[delete_file, read_file, send_email],
interrupt_on={
"delete_file": True, # Default: approve, edit, reject
"read_file": False, # No interrupts needed
"send_email": {"allowed_decisions": ["approve", "reject"]}, # No editing
},
checkpointer=checkpointer # Required!
)10.2 决策类型
这段是在进一步解释刚才提到的 allowed_decisions 列表具体能控制哪些操作。它的意思是:
allowed_decisions 列表用来控制在人工审核工具调用时,具体可以采取哪些行动:
"approve"(批准):按照 Agent 最初提议的参数,直接执行该工具。"edit"(编辑):在工具执行之前,先修改它的调用参数。"reject"(拒绝):完全跳过,不执行这次工具调用。
你可以根据实际需求,为每个工具自定义有哪些决策选项是可供选择的。
interrupt_on = {
# Sensitive operations: allow all options
"delete_file": {"allowed_decisions": ["approve", "edit", "reject"]},
# Moderate risk: approval or rejection only
"write_file": {"allowed_decisions": ["approve", "reject"]},
# Must approve (no rejection allowed)
"critical_operation": {"allowed_decisions": ["approve"]},
}10.3 处理中断
当触发中断时,Agent 会暂停执行并将控制权交还(给你或上层程序)。你需要检查返回结果中是否存在中断信号,并相应地进行处理。
from langchain_core.utils.uuid import uuid7
from langgraph.types import Command
# Create config with thread_id for state persistence
config = {"configurable": {"thread_id": str(uuid7())}}
# Invoke the agent
result = agent.invoke(
{"messages": [{"role": "user", "content": "Delete the file temp.txt"}]},
config=config,
version="v2",
)
# Check if execution was interrupted
if result.interrupts:
# Extract interrupt information
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
review_configs = interrupt_value["review_configs"]
# Create a lookup map from tool name to review config
config_map = {cfg["action_name"]: cfg for cfg in review_configs}
# Display the pending actions to the user
for action in action_requests:
review_config = config_map[action["name"]]
print(f"Tool: {action['name']}")
print(f"Arguments: {action['args']}")
print(f"Allowed decisions: {review_config['allowed_decisions']}")
# Get user decisions (one per action_request, in order)
decisions = [
{"type": "approve"} # User approved the deletion
]
# Resume execution with decisions
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config, # Must use the same config!
version="v2",
)
# Process final result
print(result.value["messages"][-1].content)10.4 多工具调用
当 Agent 调用了多个都需要批准的工具时,所有的中断请求会被打包成一个单一的中断。你必须按顺序为每一个工具提供相应的决策。
config = {"configurable": {"thread_id": str(uuid7())}}
result = agent.invoke(
{"messages": [{
"role": "user",
"content": "Delete temp.txt and send an email to admin@example.com"
}]},
config=config,
version="v2",
)
if result.interrupts:
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
# Two tools need approval
assert len(action_requests) == 2
# Provide decisions in the same order as action_requests
decisions = [
{"type": "approve"}, # First tool: delete_file
{"type": "reject"} # Second tool: send_email
]
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config,
version="v2",
)10.5 编辑工具参数
当 allowed_decisions 列表中包含 "edit" 时,你可以在工具执行之前,修改它的调用参数。
if result.interrupts:
interrupt_value = result.interrupts[0].value
action_request = interrupt_value["action_requests"][0]
# Original args from the agent
print(action_request["args"]) # {"to": "everyone@company.com", ...}
# User decides to edit the recipient
decisions = [{
"type": "edit",
"edited_action": {
"name": action_request["name"], # Must include the tool name
"args": {"to": "team@company.com", "subject": "...", "body": "..."}
}
}]
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config,
version="v2",
)10.6 子智能体中断
在使用子代理时,你既可以在工具调用时触发中断,也可以在工具内部触发中断。
关于工具调用时的中断
每个子代理都可以拥有自己独立的 interrupt_on 配置,这个配置会覆盖主代理(main agent)的设置。
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[delete_file, read_file],
interrupt_on={
"delete_file": True,
"read_file": False,
},
subagents=[{
"name": "file-manager",
"description": "Manages file operations",
"system_prompt": "You are a file management assistant.",
"tools": [delete_file, read_file],
"interrupt_on": {
# Override: require approval for reads in this subagent
"delete_file": True,
"read_file": True, # Different from main agent!
}
}],
checkpointer=checkpointer
)子代理触发中断时的处理
当子代理触发中断时,处理逻辑和之前完全一样——你只需要检查返回结果中是否有中断信号,然后使用 Command 来恢复执行即可。
工具内部的中断
子代理的工具还可以直接调用 interrupt() 函数,从而暂停执行并等待人工批准。
from langchain.agents import create_agent
from langchain_anthropic import ChatAnthropic
from langchain.messages import HumanMessage
from langchain.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command, interrupt
from deepagents.graph import create_deep_agent
from deepagents.middleware.subagents import CompiledSubAgent
@tool(description="Request human approval before proceeding with an action.")
def request_approval(action_description: str) -> str:
"""Request human approval using the interrupt() primitive."""
# interrupt() pauses execution and returns the value passed to Command(resume=...)
approval = interrupt({
"type": "approval_request",
"action": action_description,
"message": f"Please approve or reject: {action_description}",
})
if approval.get("approved"):
return f"Action '{action_description}' was APPROVED. Proceeding..."
else:
return f"Action '{action_description}' was REJECTED. Reason: {approval.get('reason', 'No reason provided')}"
def main():
checkpointer = InMemorySaver()
model = ChatAnthropic(
model_name="claude-sonnet-4-6",
max_tokens=4096,
)
compiled_subagent = create_agent(
model=model,
tools=[request_approval],
name="approval-agent",
)
parent_agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
checkpointer=checkpointer,
subagents=[
CompiledSubAgent(
name="approval-agent",
description="An agent that can request approvals",
runnable=compiled_subagent,
)
],
)
thread_id = "test_interrupt_directly"
config = {"configurable": {"thread_id": thread_id}}
print("Invoking agent - sub-agent will use request_approval tool...")
result = parent_agent.invoke(
{
"messages": [
HumanMessage(
content="Use the task tool to launch the approval-agent sub-agent. "
"Tell it to use the request_approval tool to request approval for 'deploying to production'."
)
]
},
config=config,
version="v2",
)
# Check for interrupt
if result.interrupts:
interrupt_value = result.interrupts[0].value
print(f"\nInterrupt received!")
print(f" Type: {interrupt_value.get('type')}")
print(f" Action: {interrupt_value.get('action')}")
print(f" Message: {interrupt_value.get('message')}")
print("\nResuming with Command(resume={'approved': True})...")
result2 = parent_agent.invoke(
Command(resume={"approved": True}),
config=config,
version="v2",
)
if not result2.interrupts:
print("\nExecution completed!")
# Find the tool response
tool_msgs = [m for m in result2.value.get("messages", []) if m.type == "tool"]
if tool_msgs:
print(f" Tool result: {tool_msgs[-1].content}")
else:
print("\nAnother interrupt occurred")
else:
print("\n No interrupt - the model may not have called request_approval")
if __name__ == "__main__":
main()“运行后,将会产生以下输出:”
Invoking agent - sub-agent will use request_approval tool...
Interrupt received!
Type: approval_request
Action: deploying to production
Message: Please approve or reject: deploying to production
Resuming with Command(resume={'approved': True})...
Execution completed!
Tool result: Great! The approval request has been processed. The action **"deploying to production"** was **APPROVED**. You can now proceed with the production deployment.10.7 最佳实践
10.7.1 始终使用检查点
人机交互功能必须依赖检查点(checkpointer),这样才能在“中断(interrupt)”和“恢复(resume)”之间,持久化保存 Agent 的当前状态。
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
tools=[...],
interrupt_on={...},
checkpointer=checkpointer # Required for HITL
)10.7.2 必须使用相同的线程 ID
在恢复(resume)执行时,你必须传入包含相同 thread_id 的配置(config)。
10.7.3 决策顺序需与行动请求保持一致
决策列表(decisions list)的顺序必须与行动请求(action_requests)的顺序完全匹配。
if result.interrupts:
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
# Create one decision per action, in order
decisions = []
for action in action_requests:
decision = get_user_decision(action) # Your logic
decisions.append(decision)
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config,
version="v2",
)10.7.4 根据风险程度量身定制配置
要依据工具的风险等级来设置不同的配置
11 权限
通过声明式的权限规则,来控制智能体(agent)可以读取或写入哪些文件和目录。只需将规则列表传递给 permissions= 参数,智能体内置的文件系统工具就会自动遵守这些规则。
使用权限功能需要 deepagents>=0.5.2 版本。
权限仅适用于内置的文件系统工具(ls、read_file、glob、grep、write_file、edit_file)。自定义工具以及访问文件系统的 MCP 工具不受此限制。此外,权限也不适用于沙箱后端(sandbox backends),因为沙箱后端支持通过 execute 工具执行任意命令。
当你需要对内置的文件系统工具进行基于路径的允许/拒绝规则控制时,请使用权限(permissions)功能。
而当你需要自定义的验证逻辑(比如速率限制、审计日志、内容审查),或者需要管控自定义工具时,则请使用后端策略钩子(backend policy hooks)。
11.1 基础用法
将 FilesystemPermission(文件系统权限)规则列表传递给 create_deep_agent 即可。规则会按照声明的顺序进行评估,且最先匹配到的规则生效。如果没有任何规则匹配,则默认允许该操作。
from deepagents import create_deep_agent, FilesystemPermission
# Read-only agent: deny all writes
agent = create_deep_agent(
model=model,
backend=backend,
permissions=[
FilesystemPermission(
operations=["write"],#写入
paths=["/**"], # 路径
mode="deny", #禁止
),
],
)
# 联合起来就是禁止匹配/**路径写入操作11.2 规则字段结构
每个 FilesystemPermission 规则都包含以下三个核心字段:
| 字段 (Field) | 类型 (Type) | 描述 (Description) |
|---|---|---|
| operations | list["read" | "write"] |
规则适用的操作类型。 • "read":涵盖 ls、read_file、glob、grep。• "write":涵盖 write_file、edit_file。 |
| paths | list[str] |
用于匹配文件路径的 Glob 模式(例如 ["/workspace/**"])。支持使用 ** 进行递归匹配,以及 {a,b} 进行多选匹配。 |
| mode | "allow" | "deny" |
决定是允许还是拒绝匹配到的操作。默认为 "allow"。 |
11.3 示例
隔离到工作区目录
仅允许在 /workspace/ 目录下进行读取和写入,并拒绝其他所有操作
agent = create_deep_agent(
model=model,
backend=backend,
permissions=[
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/**"],
mode="allow",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/**"],
mode="deny",
),
],
)保护特定文件
agent = create_deep_agent(
model=model,
backend=backend,
permissions=[
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/.env", "/workspace/examples/**"],
mode="deny",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/**"],
mode="allow",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/**"],
mode="deny",
),
],
)只读记忆体
允许智能体读取记忆文件,但阻止其进行修改。这一功能非常适合用于制定全组织范围内的策略,或者保护那些仅应由应用程序代码来更新的共享知识库。
如需了解更多背景信息,请参阅“只读与可写记忆体(read-only vs writable memory)”的相关说明。
agent = create_deep_agent(
model=model,
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
),
"/policies/": StoreBackend(
namespace=lambda rt: (rt.context.org_id,),
),
},
),
permissions=[
FilesystemPermission(
operations=["write"],
paths=["/memories/**", "/policies/**"],
mode="deny",
),
],
)拒绝所有访问
直接屏蔽所有的读取和写入操作。这相当于设定了一个极其严格的基线,你可以在此基础上,再逐层添加更具体的允许规则来开放必要的权限。
agent = create_deep_agent(
model=model,
backend=backend,
permissions=[
FilesystemPermission(
operations=["read", "write"],
paths=["/**"],
mode="deny",
),
],
)规则顺序
由于采用“首次匹配优先”的原则,规则的排列顺序至关重要。请务必将更具体的规则放在更宽泛的规则前面。
# Correct: deny .env, allow workspace, deny everything else
permissions=[
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/.env"],
mode="deny",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/**"],
mode="allow",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/**"],
mode="deny",
),
]
# Bug: /workspace/** matches .env first, so the deny never triggers
permissions=[
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/**"],
mode="allow",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/.env"],
mode="deny", # never reached
),
FilesystemPermission(
operations=["read", "write"],
paths=["/**"],
mode="deny",
),
]11.4 子智能体权限
默认情况下,子智能体会直接继承父智能体的权限。如果你想给子智能体分配不同的权限,只需在其配置(spec)中设置 permissions 字段即可。请注意,这样做会完全覆盖掉父智能体的规则,而不是在原有基础上进行叠加。
agent = create_deep_agent(
model=model,
backend=backend,
permissions=[
FilesystemPermission(
operations=["read", "write"],
paths=["/workspace/**"],
mode="allow",
),
FilesystemPermission(
operations=["read", "write"],
paths=["/**"],
mode="deny",
),
],
subagents=[
{
"name": "auditor",
"description": "Read-only code reviewer",
"system_prompt": "Review the code for issues.",
"permissions": [
FilesystemPermission(
operations=["write"],
paths=["/**"],
mode="deny",
),
FilesystemPermission(
operations=["read"],
paths=["/workspace/**"],
mode="allow",
),
FilesystemPermission(
operations=["read"],
paths=["/**"],
mode="deny",
),
],
}
],
)11.5 复合后端
当你使用带有沙盒(sandbox)默认配置的复合后端时,所有的权限路径都必须限定在已知的路由前缀之下。这是因为沙盒支持执行任意命令,如果单纯依靠基于路径的限制,是无法阻止用户通过 Shell 命令来绕过限制并访问文件系统的。因此,将权限限定在特定路由的后端上,可以有效避免这种安全冲突
from deepagents.backends import CompositeBackend
composite = CompositeBackend(
default=sandbox,
routes={"/memories/": memories_backend},
)
# Works: permissions are scoped to the /memories/ route
agent = create_deep_agent(
model=model,
backend=composite,
permissions=[
FilesystemPermission(
operations=["write"],
paths=["/memories/**"],
mode="deny",
),
],
)如果权限配置中包含了任何超出已定义路由范围的路径,系统将会直接抛出 NotImplementedError 错误
# Raises NotImplementedError: /workspace/** hits the sandbox default
agent = create_deep_agent(
model=model,
backend=composite,
permissions=[
FilesystemPermission(
operations=["write"],
paths=["/workspace/**"],
mode="deny",
),
],
)
# Also raises: /** covers both routes and the default
agent = create_deep_agent(
model=model,
backend=composite,
permissions=[
FilesystemPermission(
operations=["read"],
paths=["/**"],
mode="deny",
),
],
)12 记忆
记忆功能让你的代理(Agent)能够在多次对话中不断学习和进步。Deep Agents 通过引入基于文件系统的记忆,让“记忆”成为了一等公民:代理可以直接以文件的形式进行读写,而你则可以通过后端(backends)来掌控这些文件的具体存储位置。
本页面主要介绍的是长期记忆(long-term memory):也就是能够跨对话持续保留的记忆。如果你需要的是短期记忆(比如单次会话中的对话历史和暂存文件),请查阅上下文工程指南(context engineering guide)。短期记忆是作为代理状态的一部分被自动管理的。
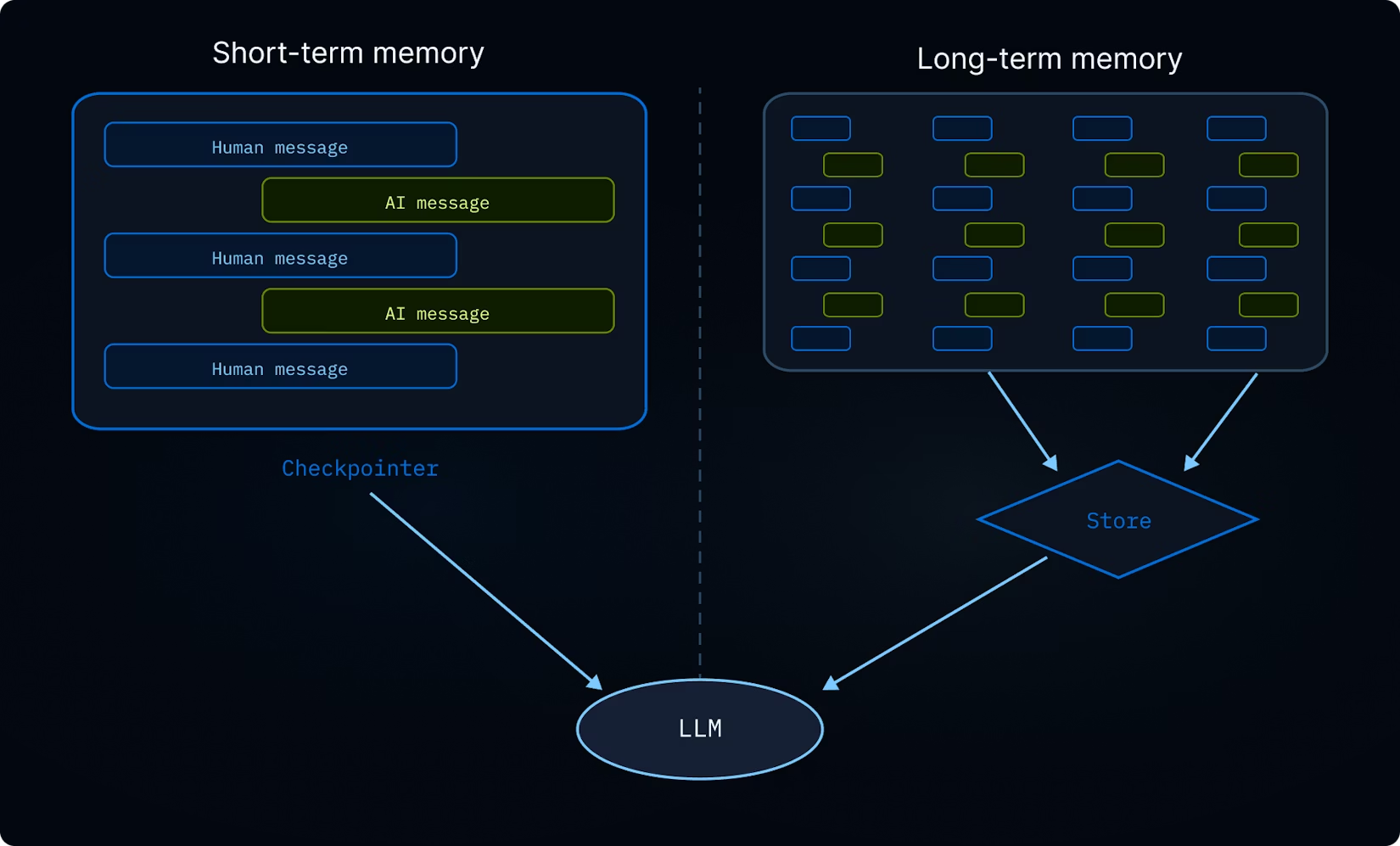
12.1 记忆工作原理
这段文档详细解释了 Deep Agents 的“文件系统记忆”是如何运作的,我们可以把它拆解成四个核心环节来理解:
1. 初始化:指向记忆文件
首先,你需要告诉 Agent 去哪里找它的“记忆”。
- 操作方法:在创建 Agent 时,通过
memory=参数传入文件路径。 - 技能注入:你还可以通过
skills=参数传入“技能”。这属于程序性记忆,本质上是一些可复用的指令,告诉 Agent 如何执行特定任务。 - 后端控制:具体的文件存储位置和访问权限由“后端”来控制。
2. 读取:灵活的加载机制
Agent 不会一股脑把所有文件都塞进脑子,而是根据情况聪明地读取:
- 启动时加载:Agent 可以在启动时将记忆文件加载到系统提示词中。
- 按需加载:为了节省资源,Agent 可以在对话过程中根据需要读取文件。
- 举例:对于“技能”,Agent 启动时只读取技能的简要描述。只有当它决定要执行某个任务时,才会去读取该技能的完整文件内容。这样能保持上下文精简,直到真正需要某项能力。
3. 更新:可选的写入能力
当 Agent 学到新东西时,它可以更新记忆文件:
- 如何更新:Agent 会使用内置的
edit_file工具来修改记忆文件。 - 更新时机:
- 对话中:这是默认方式,Agent 边聊边记。
- 后台合并:在对话间隙,Agent 可以在后台整理和更新记忆。
- 持久化:这些更改会被保存下来,在下一次对话中依然有效。
- 注意:并不是所有记忆都能改。开发者定义的技能或组织策略通常是只读的。
4. 常见模式:作用域
最后,文档提到了两种最通用的记忆管理模式:
- Agent 级记忆:所有用户共享同一套记忆(比如通用的知识库)。
- 用户级记忆:每个用户都有自己独立的记忆空间,互不干扰。
简单来说,这套机制让 Agent 既有“长期记忆”(存文件),又有“按需取用”的智慧(按需加载),还能“自我进化”(更新文件),并且权限分明。
12.2 记忆范围
gent 的记忆可以设定作用域,既可以让所有使用该 Agent 的人访问同一份记忆文件,也可以让记忆文件为每个用户独立所有。
Agent 级记忆
赋予 Agent 自身一种随时间不断进化的持久身份。Agent 级记忆在所有用户之间共享,因此 Agent 会通过每一次对话,逐步建立起自己的人格、积累知识并习得偏好。随着与用户的互动,它会不断培养专业能力、优化自身的方法,并记住哪些做法是行之有效的。如果拥有写入权限,它还可以学习和更新技能。
其中的关键在于后端命名空间(backend namespace):将其设置为 (assistant_id,),就意味着该 Agent 的所有对话都会读取并写入同一份记忆文件。
访问 rt.server_info 需要 deepagents>=0.5.0。如果是旧版本,请改用 get_config()["metadata"]["assistant_id"] 来读取 assistant ID。
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
memory=["/memories/AGENTS.md"],
skills=["/skills/"],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=lambda rt: (
rt.server_info.assistant_id,
),
),
"/skills/": StoreBackend(
namespace=lambda rt: (
rt.server_info.assistant_id,
),
),
},
),
)用户级记忆
为每个用户提供他们自己的记忆文件。Agent 会记住每位用户的偏好、上下文和历史记录,而 Agent 的核心指令则保持固定不变。如果存储在用户级后端中,用户还可以拥有专属的个人技能。
其命名空间使用的是 (user_id,),因此每个用户都会获得一份相互隔离的记忆文件副本。用户 A 的偏好绝不会泄露到用户 B 的对话中
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
memory=["/memories/preferences.md"],
skills=["/skills/"],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
),
"/skills/": StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
),
},
),
)完整示例:跨用户的隔离记忆
为不同用户预先填充各自的记忆,然后分别以两个不同用户的身份调用 Agent。这样你会发现,每个用户只能看到属于他们自己的偏好信息。
from langchain_core.utils.uuid import uuid7
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from deepagents.backends.utils import create_file_data
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # Use platform store when deploying to LangSmith
# Seed preferences for two users
store.put(
("user-alice",),
"/memories/preferences.md",
create_file_data("""## Preferences
- Likes concise bullet points
- Prefers Python examples
"""),
)
store.put(
("user-bob",),
"/memories/preferences.md",
create_file_data("""## Preferences
- Likes detailed explanations
- Prefers TypeScript examples
"""),
)
# Seed a skill for Alice
store.put(
("user-alice",),
"/skills/langgraph-docs/SKILL.md",
create_file_data("""---
name: langgraph-docs
description: Fetch relevant LangGraph documentation to provide accurate guidance.
---
# langgraph-docs
Use the fetch_url tool to read https://docs.langchain.com/llms.txt, then fetch relevant pages.
"""),
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
memory=["/memories/preferences.md"],
skills=["/skills/"],
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(
rt,
namespace=lambda rt: (rt.server_info.user.identity,),
),
"/skills/": StoreBackend(
rt,
namespace=lambda rt: (rt.server_info.user.identity,),
),
},
),
store=store,
)
# When deployed, each authenticated request resolves
# `rt.server_info.user.identity` to the calling user, so Alice and Bob
# automatically see only their own preferences.
agent.invoke(
{"messages": [{"role": "user", "content": "How do I read a CSV file?"}]},
config={"configurable": {"thread_id": str(uuid7())}},
)12.3 高级用法
除了记忆路径和作用域这些基础配置,你还可以设置更高级的记忆参数:
| 维度 | 解决的问题 | 可选配置 |
|---|---|---|
| 持续时间 | 记忆能存多久? | 短期(仅限单次对话)或 长期(跨对话持久保存) |
| 信息类型 | 存的是什么信息? | 情景记忆(过往经历)、程序性记忆(操作指令和技能)或 语义记忆(客观事实) |
| 作用域 | 谁能查看和修改? | 用户、Agent 或 组织 |
| 更新策略 | 什么时候写入记忆? | 对话中(默认)或 对话间隙(后台整理) |
| 读取方式 | 怎么读取记忆? | 加载到提示词中(默认)或 按需读取(例如技能文件) |
| Agent 权限 | Agent 能写入记忆吗? | 读写(默认)或 只读(常用于共享策略或固定技能) |
12.3.1 情景记忆
情景记忆用来存储过往经历的记录:发生了什么事、按什么顺序发生的,以及结果如何。与语义记忆(存储在 AGENTS.md 等文件中的事实和偏好)不同,情景记忆保留了完整的对话上下文,这样 Agent 就能回想起问题是如何被解决的,而不仅仅是从中学到了什么结论。
Deep Agents 已经使用了检查点机制(checkpointers),这就是支持情景记忆的底层原理:每一次对话都会作为带有检查点的线程被持久化保存。
如果想让过去的对话可以被搜索,只需将线程搜索功能封装成一个工具即可。注意,user_id 会直接从运行时上下文中提取,而不需要作为参数手动传入。
from langgraph_sdk import get_client
from langchain.tools import tool, ToolRuntime
client = get_client(url="<DEPLOYMENT_URL>")
@tool
async def search_past_conversations(query: str, runtime: ToolRuntime) -> str:
"""Search past conversations for relevant context."""
user_id = runtime.server_info.user.identity
threads = await client.threads.search(
metadata={"user_id": user_id},
limit=5,
)
results = []
for thread in threads:
history = await client.threads.get_history(thread_id=thread["thread_id"])
results.append(history)
return str(results)你可以通过调整元数据过滤器(metadata filter),来限定按用户或按组织来搜索线程
# Search conversations for a specific user
threads = await client.threads.search(
metadata={"user_id": user_id},
limit=5,
)
# Search conversations across an organization
threads = await client.threads.search(
metadata={"org_id": org_id},
limit=5,
)这对执行复杂多步任务的 Agent 非常有用。比如,一个写代码的 Agent 在遇到类似问题时,可以回头翻看之前的调试记录,然后直接跳过摸索阶段,直奔最可能的根本原因
12.3.2 组织级记忆
组织级记忆的逻辑和用户级记忆一样,只不过它的命名空间是面向整个组织的,而不是针对单个用户。它主要用来存放那些需要覆盖组织内所有用户和 Agent 的通用策略或知识。
为了防止有人通过共享状态进行提示词注入攻击,组织级记忆通常会被设置为只读。具体细节可以查看关于“只读与可写记忆”的说明。
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
memory=[
"/memories/preferences.md",
"/policies/compliance.md",
],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
),
"/policies/": StoreBackend(
namespace=lambda rt: (rt.context.org_id,),
),
},
),
)从你的应用代码中填充组织记忆
from langgraph_sdk import get_client
from deepagents.backends.utils import create_file_data
client = get_client(url="<DEPLOYMENT_URL>")
await client.store.put_item(
(org_id,),
"/compliance.md",
create_file_data("""## Compliance policies
- Never disclose internal pricing
- Always include disclaimers on financial advice
"""),
)可以通过权限设置来确保组织级记忆是只读的,或者使用策略钩子(policy hooks)来进行自定义的验证逻辑。
可以通过权限设置来确保组织级记忆是只读的,或者使用策略钩子(policy hooks)来进行自定义的验证逻辑。
12.3.3 后台整合
默认情况下,Agent 会在对话过程中写入记忆(即“热路径”)。另一种替代方案是在对话间隙将记忆处理作为后台任务,这有时也被称为“休眠期计算(sleep time compute)”。由一个独立的深度 Agent 来审查最近的对话,提取关键事实,并将它们与现有记忆进行合并。
表格
| 方式 | 优点 | 缺点 |
|---|---|---|
| 热路径(对话中) | 记忆立即可用,对用户透明 | 会增加延迟,Agent 需要一心多用 |
| 后台(对话间隙) | 用户端无延迟,可以跨多次对话进行综合处理 | 记忆要等到下一次对话时才可用,需要第二个 Agent |
对于大多数应用来说,热路径已经足够了。当你需要降低延迟,或者想要提升跨多次对话的记忆质量时,再考虑加入后台整合。
推荐的做法是,在你的主 Agent 旁边部署一个“整合 Agent”——也就是一个负责读取近期对话历史、提取关键事实并合并到记忆存储中的深度 Agent——并通过定时任务(cron)来触发它。
触发频率最好根据用户与 Agent 的实际互动频率来定:比如一个每天都有稳定流量的聊天产品,可以每隔几小时整合一次;而一个每周只被用几次的工具,只需要每晚或每周运行一次就够了。如果整合的频率远高于用户对话的频率,只会白白浪费 Token 跑空任务。
整合 Agent
整合 Agent 负责读取近期的对话历史,并将关键事实合并到记忆存储中。在 langgraph.json 中将其与主 Agent 一起注册即可。
from datetime import datetime, timedelta, timezone
from deepagents import create_deep_agent
from langchain.tools import tool, ToolRuntime
from langgraph_sdk import get_client
sdk_client = get_client(url="<DEPLOYMENT_URL>")
@tool
async def search_recent_conversations(query: str, runtime: ToolRuntime) -> str:
"""Search this user's conversations updated in the last 6 hours."""
user_id = runtime.server_info.user.identity
since = datetime.now(timezone.utc) - timedelta(hours=6)
threads = await sdk_client.threads.search(
metadata={"user_id": user_id},
updated_after=since.isoformat(),
limit=20,
)
conversations = []
for thread in threads:
history = await sdk_client.threads.get_history(
thread_id=thread["thread_id"]
)
conversations.append(history["values"]["messages"])
return str(conversations)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt="""Review recent conversations and update the user's memory file.
Merge new facts, remove outdated information, and keep it concise.""",
tools=[search_recent_conversations],
){
"dependencies": ["."],
"graphs": {
"agent": "./agent.py:agent",
"consolidation_agent": "./consolidation_agent.py:agent"
},
"env": ".env"
}定时任务(Cron)
通过一个定时任务(Cron job),按照固定的时间间隔自动运行整合 Agent。该 Agent 会搜索最近的对话,并将其综合整理进记忆里。记得让定时任务的频率与你的实际使用情况相匹配,这样记忆整合的节奏才能大致跟上真实的活跃度。

from langgraph_sdk import get_client
client = get_client(url="<DEPLOYMENT_URL>")
cron_job = await client.crons.create(
assistant_id="consolidation_agent",
schedule="0 */6 * * *",
input={"messages": [{"role": "user", "content": "Consolidate recent memories."}]},
)所有的 Cron 定时计划都是按照 UTC 时间来解析的。关于如何管理和删除定时任务,可以查看相关文档。
Cron 的执行间隔必须与整合 Agent 内部的回溯时间窗口保持一致。比如上面的例子中,定时任务每 6 小时运行一次(0 */6 * * *),而 Agent 的 search_recent_conversations 工具的回溯时间也刚好设置为 6 小时(timedelta(hours=6))——一定要确保这两者同步。
如果 Cron 运行的频率比回溯窗口更高,就会导致同一段对话被重复处理;反之,如果运行频率太低,那些超出时间窗口的对话记忆就会被漏掉。
想要了解更多关于部署带有后台进程的 Agent 的内容,可以查看“上线生产环境(going to production)”的相关指南。
关于记忆配置这块的翻译基本就这些啦!如果后面还有新的技术文档或者代码注释,随时发给我就行
12.3.4 只读记忆与可写记忆
默认情况下,Agent 对记忆文件拥有读和写的双重权限。但对于像组织策略或合规规则这类共享状态,你可能希望将其设为只读,这样 Agent 只能参考,无法修改。这样做不仅能防止通过共享记忆进行提示词注入,还能确保文件里的内容完全由你的应用代码来掌控。
12.3.5 并发写入
多个线程可以并行地向记忆中写入数据,但如果同时对同一个文件进行写入,就会引发“最后写入者胜出(last-write-wins)”的冲突。对于用户级记忆来说,这种情况很少见,因为用户通常一次只进行一场对话。但对于 Agent 级或组织级记忆,建议通过后台整合来将写入操作串行化,或者将记忆按主题拆分成不同的文件,以减少资源争用。
在实际应用中,如果某次写入因为冲突而失败,大语言模型(LLM)通常足够聪明,能够自行重试或优雅地恢复。因此,单次写入丢失并不会造成灾难性的后果。
12.3.6 同一部署环境中的多个 Agent
如果想在同一个部署环境中让每个 Agent 拥有自己独立的记忆空间,只需要在命名空间(namespace)中加入 assistant_id 即可。
果你只需要实现 Agent 之间的相互隔离,而不需要按用户进行区分,那么单独使用 assistant_id 就足够了。
另外,你可以利用 LangSmith 追踪功能来审计 Agent 到底往记忆里写了什么。每一次文件写入操作,都会在追踪记录中显示为一次工具调用(tool call),查起来非常方便。
13 技能
技能是可复用的智能体能力,提供专门的工作流和领域知识。你可以使用智能体技能为你的深度智能体赋予新的能力和专长。关于能提升智能体在 LangChain 生态任务表现的即用型技能,请参阅 LangChain 技能仓库。深度智能体技能遵循智能体技能规范
13.1 技能概念
技能是一个由文件夹组成的目录,其中每个文件夹包含一个或多个文件,这些文件包含智能体可以使用的上下文信息:
- 一个包含技能指令和元数据的
SKILL.md文件 - 附加脚本(可选)
- 附加参考资料,例如文档(可选)
- 附加资源,例如模板和其他资源(可选)
任何附加资源(脚本、文档、模板或其他资源)都必须在 SKILL.md 文件中被引用,并说明文件包含的内容以及如何使用,以便智能体能够决定何时使用它们。
13.2 工作原理
当你创建一个深度智能体时,你可以传入一个包含技能的目录列表。当智能体启动时,它会读取每个 SKILL.md 文件的前言部分。
当智能体接收到提示词时,它会检查在完成任务时是否可以使用任何技能。如果找到匹配的提示词,它就会查看技能的其余文件。这种仅在需要时才查看技能信息的模式被称为“渐进式披露”。
13.3 例子
skills/
├── langgraph-docs
│ └── SKILL.md
└── arxiv_search
├── SKILL.md
└── arxiv_search.py # code for searching arXivSKILL.md 文件总是遵循相同的模式,以前言中的元数据开始,后面跟着技能的说明。
下面的示例展示了一个技能,它提供了在收到提示时如何提供相关 LangGraph 文档的说明:
---
name: langgraph-docs
description: Use this skill for requests related to LangGraph in order to fetch relevant documentation to provide accurate, up-to-date guidance.
---
# langgraph-docs
## Overview
This skill explains how to access LangGraph Python documentation to help answer questions and guide implementation.
## Instructions
### 1. Fetch the Documentation Index
Use the fetch_url tool to read the following URL:
https://docs.langchain.com/llms.txt
This provides a structured list of all available documentation with descriptions.
### 2. Select Relevant Documentation
Based on the question, identify 2-4 most relevant documentation URLs from the index. Prioritize:
- Specific how-to guides for implementation questions
- Core concept pages for understanding questions
- Tutorials for end-to-end examples
- Reference docs for API details
### 3. Fetch Selected Documentation
Use the fetch_url tool to read the selected documentation URLs.
### 4. Provide Accurate Guidance
After reading the documentation, complete the user's request.关于更多技能示例,请参阅 Deep Agents 示例技能。
重要提示
有关编写技能文件时的约束和最佳实践,请参阅完整的智能体技能规范。值得注意的是:
- 如果
description(描述)字段超过 1024 个字符,它将被截断。 - 在 Deep Agents 中,
SKILL.md文件必须小于 10 MB。超过此限制的文件将在技能加载期间被跳过。
13.4 使用
在创建深度智能体时传入技能目录
StateBackend
from urllib.request import urlopen
from deepagents import create_deep_agent
from deepagents.backends.utils import create_file_data
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
skill_url = "https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/libs/cli/examples/skills/langgraph-docs/SKILL.md"
with urlopen(skill_url) as response:
skill_content = response.read().decode('utf-8')
skills_files = {
"/skills/langgraph-docs/SKILL.md": create_file_data(skill_content)
}
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/"],
checkpointer=checkpointer,
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "What is langgraph?",
}
],
# Seed the default StateBackend's in-state filesystem (virtual paths must start with "/").
"files": skills_files
},
config={"configurable": {"thread_id": "12345"}},
)StoreBackend
from urllib.request import urlopen
from deepagents import create_deep_agent
from deepagents.backends import StoreBackend
from deepagents.backends.utils import create_file_data
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
skill_url = "https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/libs/cli/examples/skills/langgraph-docs/SKILL.md"
with urlopen(skill_url) as response:
skill_content = response.read().decode('utf-8')
store.put(
namespace=("filesystem",),
key="/skills/langgraph-docs/SKILL.md",
value=create_file_data(skill_content)
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=StoreBackend(),
store=store,
skills=["/skills/"]
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "What is langgraph?",
}
]
},
config={"configurable": {"thread_id": "12345"}},
)FilesystemBackend
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
from deepagents.backends.filesystem import FilesystemBackend
# Checkpointer is REQUIRED for human-in-the-loop
checkpointer = MemorySaver()
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=FilesystemBackend(root_dir="/Users/user/{project}"),
skills=["/Users/user/{project}/skills/"],
interrupt_on={
"write_file": True, # Default: approve, edit, reject
"read_file": False, # No interrupts needed
"edit_file": True # Default: approve, edit, reject
},
checkpointer=checkpointer, # Required!
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "What is langgraph?",
}
]
},
config={"configurable": {"thread_id": "12345"}},
)skillslist[str]
技能源路径列表。
路径必须使用正斜杠指定,且相对于后端根目录。
如果省略,则不加载任何技能。
使用 StateBackend(默认)时,请通过 invoke(files={...}) 提供技能文件。使用 deepagents.backends.utils 中的 create_file_data() 来格式化文件内容;不支持原始字符串。使用 FilesystemBackend 时,技能从相对于后端 root_dir 的磁盘加载。
对于同名的技能,后面的源会覆盖前面的源(后者胜出)。
SDK 仅加载你在 skills 中传入的源。它不会自动扫描 CLI 目录,例如 ~/.deepagents/... 或 ~/.agents/...。
关于 CLI 存储约定,请参阅应用数据。
如果你想在 SDK 代码中实现类似 CLI 的分层效果,请按照优先级从低到高的顺序显式传入所有所需的源:
[
"<user-home>/.deepagents/{agent}/skills/",
"<user-home>/.agents/skills/",
"<project-root>/.deepagents/skills/",
"<project-root>/.agents/skills/",
]13.5 来源优先级
当多个技能源包含同名的技能时,skills 数组中后面列出的源中的技能将优先(后者胜出)。这使你可以对不同来源的技能进行分层。
# If both sources contain a skill named "web-search",
# the one from "/skills/project/" wins (loaded last).
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/user/", "/skills/project/"],
...
)13.6 子智能体技能
使用子智能体时,你可以配置每种类型可以访问哪些技能:
- 通用子智能体:当你将
skills传递给create_deep_agent时,会自动继承主智能体的技能。无需额外配置。 - 自定义子智能体:不会继承主智能体的技能。需要在每个子智能体定义中添加
skills参数,并指定该子智能体的技能源路径。
技能状态完全隔离:主智能体的技能对子智能体不可见,子智能体的技能对主智能体也不可见。
from deepagents import create_deep_agent
research_subagent = {
"name": "researcher",
"description": "Research assistant with specialized skills",
"system_prompt": "You are a researcher.",
"tools": [web_search],
"skills": ["/skills/research/", "/skills/web-search/"], # Subagent-specific skills
}
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/main/"], # Main agent and GP subagent get these
subagents=[research_subagent], # Researcher gets only its own skills
)13.7 子智能体能可见内容
当配置了技能后,一个“技能系统”部分会被注入到智能体的系统提示词中。智能体利用这些信息遵循一个三步流程:
- 匹配:当用户提示到达时,智能体会检查是否有任何技能的描述与任务相匹配。
- 读取:如果某个技能适用,智能体会使用其技能列表中显示的路径来读取完整的
SKILL.md文件。 - 执行:智能体会遵循技能的指令,并根据需要访问任何支持文件(脚本、模板、参考文档)。
请在你的 SKILL.md 前言中编写清晰、具体的描述。智能体仅根据描述来决定是否使用某个技能——详细的描述会带来更好的技能匹配效果。
13.8 在沙箱中执行技能脚本
在沙箱中执行技能脚本
技能可以包含与 SKILL.md 文件并列的脚本,例如,执行搜索或数据转换的 Python 文件。智能体可以从任何后端读取这些脚本,但要执行它们,智能体需要访问 shell——这只有沙箱后端才能提供。当你使用 CompositeBackend 将技能路由到 StoreBackend 进行持久化,同时使用沙箱作为默认后端时,技能文件存储在存储(Store)中,而不是代码运行的沙箱中。为了让沙箱能够使用这些脚本,你必须使用自定义中间件在智能体启动前将技能脚本上传到沙箱中:

#google
import asyncio
from pathlib import Path
from typing import Any
from daytona import Daytona
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StoreBackend
from deepagents.backends.utils import create_file_data
from langchain.agents.middleware import AgentMiddleware, AgentState
from langchain_daytona import DaytonaSandbox
from langgraph.runtime import Runtime
from langgraph.store.memory import InMemoryStore
# Identical skill bundles for every user: one shared store namespace.
SKILLS_SHARED_NAMESPACE = ("skills", "builtin")
class SkillSandboxSyncMiddleware(AgentMiddleware[AgentState, Any, Any]):
"""Copy shared skill files from the store into the sandbox before each agent run."""
def __init__(self, backend: CompositeBackend) -> None:
super().__init__()
self.backend = backend
async def abefore_agent(self, state: AgentState, runtime: Runtime[Any]) -> None:
store = runtime.store
files: list[tuple[str, bytes]] = []
for item in await store.asearch(SKILLS_SHARED_NAMESPACE):
key = str(item.key)
if ".." in key or any(c in key for c in ("*", "?")):
msg = f"Invalid key: {key}"
raise ValueError(msg)
normalized = key if key.startswith("/") else f"/{key}"
# CompositeBackend routes paths and batches uploads to the right backend.
files.append((f"/skills{normalized}", item.value["content"].encode()))
if files:
await self.backend.aupload_files(files)
async def seed_skill_store(store: InMemoryStore) -> None:
"""Load canonical skill files from disk into the shared store namespace (run once at deploy).
You can retrieve skills from any source (local filesystem, remote URL, etc.).
"""
skills_dir = Path(__file__).resolve().parent / "skills"
for file_path in sorted(p for p in skills_dir.rglob("*") if p.is_file()):
rel = file_path.relative_to(skills_dir).as_posix()
key = f"/{rel}"
await store.aput(
SKILLS_SHARED_NAMESPACE,
key,
create_file_data(file_path.read_text(encoding="utf-8")),
)
async def main() -> None:
store = InMemoryStore()
await seed_skill_store(store)
daytona = Daytona()
sandbox = daytona.create()
sandbox_backend = DaytonaSandbox(sandbox=sandbox)
backend = CompositeBackend(
default=sandbox_backend,
routes={
"/skills/": StoreBackend(
store=store,
namespace=lambda _rt: SKILLS_SHARED_NAMESPACE,
),
},
)
try:
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=backend,
skills=["/skills/"],
store=store,
middleware=[SkillSandboxSyncMiddleware(backend)],
)
finally:
sandbox.stop()
if __name__ == "__main__":
asyncio.run(main())中间件的 before_agent 钩子会在每次智能体调用之前运行,从该共享命名空间读取技能文件并将它们上传到沙箱文件系统中。一旦同步完成,智能体就可以使用 execute 工具执行脚本,就像处理沙箱中的任何其他文件一样。
有关更完整的示例(包括双向同步记忆),请参阅使用自定义中间件同步技能和记忆
13.9 技能与记忆
| 特性 | 技能 | 记忆 |
|---|---|---|
| 目的 | 通过渐进式披露发现的能力(按需调用) | 启动时始终加载的持久化上下文 |
| 加载方式 | 仅当智能体判断相关性时读取 | 始终注入到系统提示词中 |
| 格式 | 命名目录中的 SKILL.md |
AGENTS.md 文件 |
| 分层逻辑 | 用户 → 项目(后者胜出) | 用户 → 项目(合并) |
| 适用场景 | 特定于任务且内容可能较多的指令 | 始终相关的上下文(如项目规范、偏好设置) |
13.10 技能与工具使用场景
这里有一些使用工具和技能的通用指南:
- 当有大量上下文信息时,请使用技能,以减少系统提示词中的 Token 数量。
- 使用技能将能力捆绑成更大的操作,并提供超越单个工具描述的额外上下文。
- 如果智能体无法访问文件系统,请使用工具。
14 沙箱
智能体能够生成代码、与文件系统交互并运行 Shell 命令。由于我们无法预测智能体会执行什么操作,因此必须隔离其运行环境,使其无法访问凭证、文件或网络。沙箱通过在智能体的执行环境与你的主机系统之间创建边界来提供这种隔离。
在 Deep Agents 中,沙箱是定义智能体运行环境的后端。与其他仅暴露文件操作的后端(如 State、Filesystem、Store)不同,沙箱后端还会赋予智能体一个用于运行 Shell 命令的 execute 工具。当你配置沙箱后端时,智能体将获得:
- 所有标准的文件系统工具 (
ls,read_file,write_file,edit_file,glob,grep) - 用于在沙箱中运行任意 Shell 命令的
execute工具 - 一个保护你主机系统的安全边界
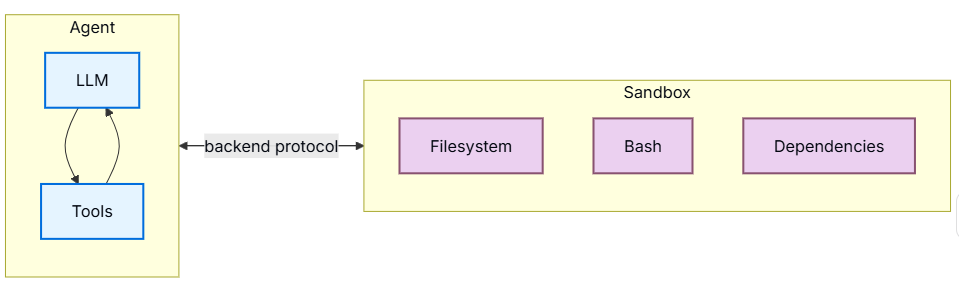
14.1 使用沙箱理由
沙箱主要用于安全目的。它们允许智能体执行任意代码、访问文件和使用网络,而不会危及你的凭证、本地文件或主机系统。这种隔离在智能体自主运行时至关重要。
沙箱对于以下场景特别有用:
- 编码智能体:自主运行的智能体可以使用 shell、git、克隆仓库(许多提供商提供原生 git API,例如 Daytona 的 git 操作),并为构建和测试管道运行 Docker-in-Docker。
- 数据分析智能体:在安全、隔离的环境中加载文件、安装数据分析库(如 pandas、numpy 等)、运行统计计算并创建 PowerPoint 演示文稿等输出。
沙箱本地使用请谨慎,没有不透风的墙
使用 Deep Agents CLI?
CLI 通过 --sandbox 标志内置了沙箱支持。请参阅使用远程沙箱以获取特定于 CLI 的设置、标志(--sandbox-id、--sandbox-setup)和示例。
14.2 基本使用
这些示例假设你已经使用提供商的 SDK 创建了沙箱/开发箱,并已设置好凭证。有关注册、身份验证和特定于提供商的生命周期详情,请参阅可用提供商。
from deepagents import create_deep_agent
from deepagents.backends import LangSmithSandbox
from langchain_anthropic import ChatAnthropic
from langsmith.sandbox import SandboxClient
client = SandboxClient()
ls_sandbox = client.create_sandbox(template_name="my-template")
backend = LangSmithSandbox(sandbox=ls_sandbox)
agent = create_deep_agent(
model=ChatAnthropic(model="claude-sonnet-4-6"),
system_prompt="You are a Python coding assistant with sandbox access.",
backend=backend,
)
try:
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Create a small Python package and run pytest",
}
]
}
)
finally:
client.delete_sandbox(ls_sandbox.name)14.3 可用供应商
有关特定于提供商的设置、身份验证和生命周期详情,请参阅沙箱集成。没有看到你的提供商?你可以实现自己的沙箱后端。请参阅贡献沙箱集成
14.4 生命周期与作用域
沙箱会消耗资源并产生费用,直到它们被关闭。如何管理它们的生命周期取决于你的应用程序。
你需要选择沙箱生命周期如何映射到应用程序的资源。有关此决策的更多信息,请参阅投入生产。
线程范围 (默认)
每次对话都会获得一个独立的沙箱。沙箱在第一次运行开始时创建,并在同一线程的后续消息中重用。当线程被清理(或沙箱的 TTL 过期)时,沙箱会被销毁。这是大多数智能体的正确默认设置。示例:一个数据分析机器人,每次对话都从一个干净的环境开始。
助手范围
给定助手的所有线程共享一个沙箱。沙箱 ID 存储在助手的配置中,因此每次对话都会返回到同一个环境。文件、已安装的包和已克隆的仓库会在对话之间持久存在。当智能体维护一个长期运行的工作区时,请使用此选项。
示例:一个编码助手,在对话之间维护一个已克隆的仓库和已安装的依赖项。
手范围的沙箱会随着时间的推移积累文件、已安装的包和其他沙箱内的状态。你需要配置沙箱提供商的 TTL(生存时间),定期使用快照进行重置,或实现清理逻辑,以防止沙箱的磁盘和内存无限制增长。而线程范围的沙箱则通过在每次对话时从头开始来避免这个问题
基本生命周期
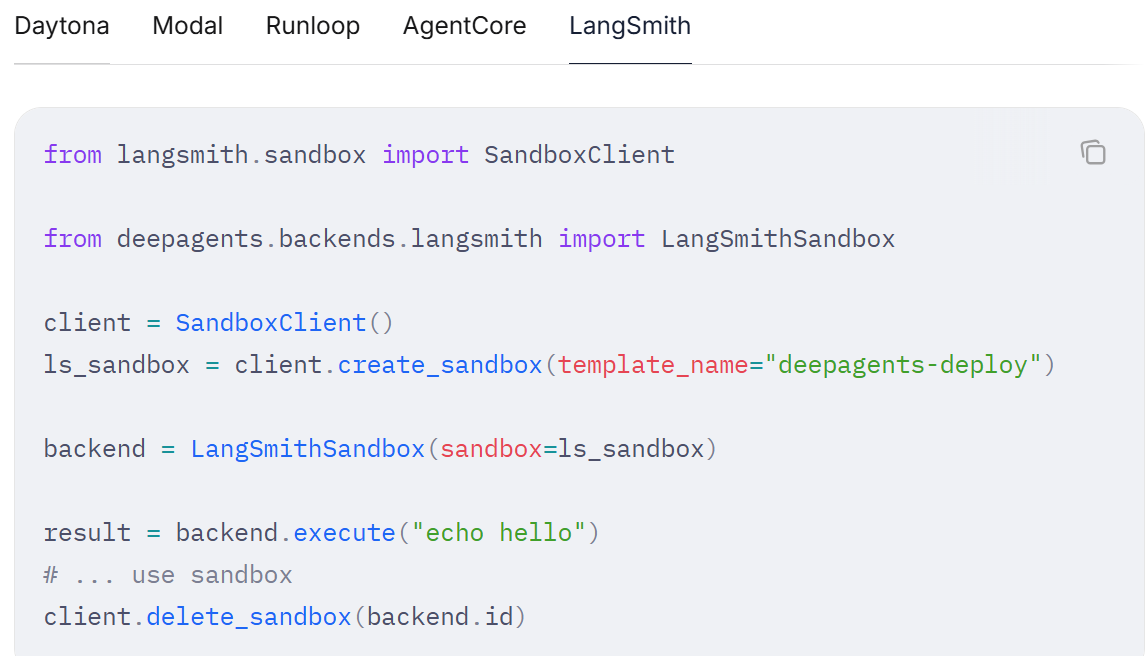
每次对话的生命周期
在聊天应用程序中,对话通常由 thread_id 表示。通常情况下,每个 thread_id 应该使用其自己唯一的沙箱。
你需要将沙箱 ID 和 thread_id 之间的映射关系存储在你的应用程序中,或者如果沙箱提供商允许附加元数据,则存储在沙箱中。
聊天应用程序的 TTL (生存时间)。当用户可以在空闲一段时间后重新参与时,你通常不知道他们是否会回来或何时回来。在沙箱上配置生存时间(TTL)——例如,归档 TTL 或删除 TTL——以便提供商自动清理空闲的沙箱。许多沙箱提供商都支持此功能。
以下示例展示了使用 Daytona 的“获取或创建”模式。对于其他提供商,请咨询沙箱提供商 API 以获取等效的标签、元数据和 TTL 选项:
from langchain_core.utils.uuid import uuid7
from daytona import CreateSandboxFromSnapshotParams, Daytona
from deepagents import create_deep_agent
from langchain_daytona import DaytonaSandbox
client = Daytona()
thread_id = str(uuid7())
# Get or create sandbox by thread_id
try:
sandbox = client.find_one(labels={"thread_id": thread_id})
except Exception:
params = CreateSandboxFromSnapshotParams(
labels={"thread_id": thread_id},
# Add TTL so the sandbox is cleaned up when idle
auto_delete_interval=3600,
)
sandbox = client.create(params)
backend = DaytonaSandbox(sandbox=sandbox)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=backend,
system_prompt="You are a coding assistant with sandbox access. You can create and run code in the sandbox.",
)
try:
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Create a hello world Python script and run it",
}
]
},
config={
"configurable": {
"thread_id": thread_id,
}
},
)
print(result["messages"][-1].content)
except Exception:
# Optional: delete the sandbox proactively on an exception
client.delete(sandbox)
raise14.5 集成模式
将智能体与沙箱集成主要有两种架构模式,具体取决于智能体的运行位置。
🤖 沙箱内智能体模式
智能体在沙箱内部运行,你通过网络与其通信。你需要构建一个预装了智能体框架的 Docker 或虚拟机镜像,在沙箱内运行它,然后从外部连接以发送消息。
优势:
- ✅ 紧密镜像本地开发环境。
- ✅ 智能体与环境紧密耦合。
权衡:
- 🔴 API 密钥必须存在于沙箱内(安全风险)。
- 🔴 更新需要重新构建镜像。
- 🔴 需要用于通信的基础设施(WebSocket 或 HTTP 层)。
要在沙箱中运行智能体,请构建一个镜像并在其上安装 deepagents。
FROM python:3.11
RUN pip install deepagents-cli然后在沙箱内运行智能体。要在沙箱内使用智能体,你必须添加额外的基础设施来处理你的应用程序与沙箱内智能体之间的通信。
沙箱即工具模式
在这种模式下,智能体运行在你的机器或服务器上。当它需要执行代码时,会调用沙箱工具(如 execute、read_file 或 write_file),这些工具会调用提供商的 API 在远程沙箱中运行操作。
优势:
- ✅ 即时更新:无需重新构建镜像即可立即更新智能体代码。
- ✅ 状态分离:智能体状态与执行环境更清晰地分离。
- ✅ 密钥安全:API 密钥保留在沙箱外部。
- ✅ 容错性:沙箱故障不会导致智能体状态丢失。
- ✅ 并行处理:可以选择在多个沙箱中并行运行任务。
- ✅ 按需付费:仅需为执行时间付费。
权衡:
- 🔴 网络延迟:每次执行调用都会产生网络延迟。
from daytona import Daytona
from deepagents import create_deep_agent
from dotenv import load_dotenv
from langchain_daytona import DaytonaSandbox
load_dotenv()
# Can also do this with AgentCore, E2B, Runloop, Modal
sandbox = Daytona().create()
backend = DaytonaSandbox(sandbox=sandbox)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
backend=backend,
system_prompt="You are a coding assistant with sandbox access. You can create and run code in the sandbox.",
)
try:
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Create a hello world Python script and run it",
}
]
}
)
print(result["messages"][-1].content)
except Exception:
# Optional: delete the sandbox proactively on an exception
sandbox.stop()
raise14.6 沙箱工作原理
隔离边界
所有沙箱提供商都会保护你的主机系统免受智能体的文件系统和 Shell 操作的影响。智能体无法读取你的本地文件、访问你机器上的环境变量或干扰其他进程。然而,仅靠沙箱无法防御以下风险:
- 上下文注入:控制部分智能体输入的攻击者可以指示智能体在沙箱内运行任意命令。沙箱虽然是隔离的,但智能体在沙箱内部拥有完全控制权。
- 网络数据渗漏:除非阻止网络访问,否则被上下文注入的智能体可以通过 HTTP 或 DNS 将数据发送出沙箱。部分提供商支持阻止网络访问(例如 Modal 的
blockNetwork: true)。
有关如何处理机密信息和减轻这些风险的更多信息,请参阅安全注意事项。
execute 方法
沙箱后端的架构非常简单:提供商必须实现的唯一方法是 execute(),它用于运行 Shell 命令并返回其输出。所有其他文件系统操作(如 read、write、edit、ls、glob、grep)都是由 BaseSandbox 基类在 execute() 之上构建的,该类通过构造脚本并在沙箱内通过 execute() 运行它们。
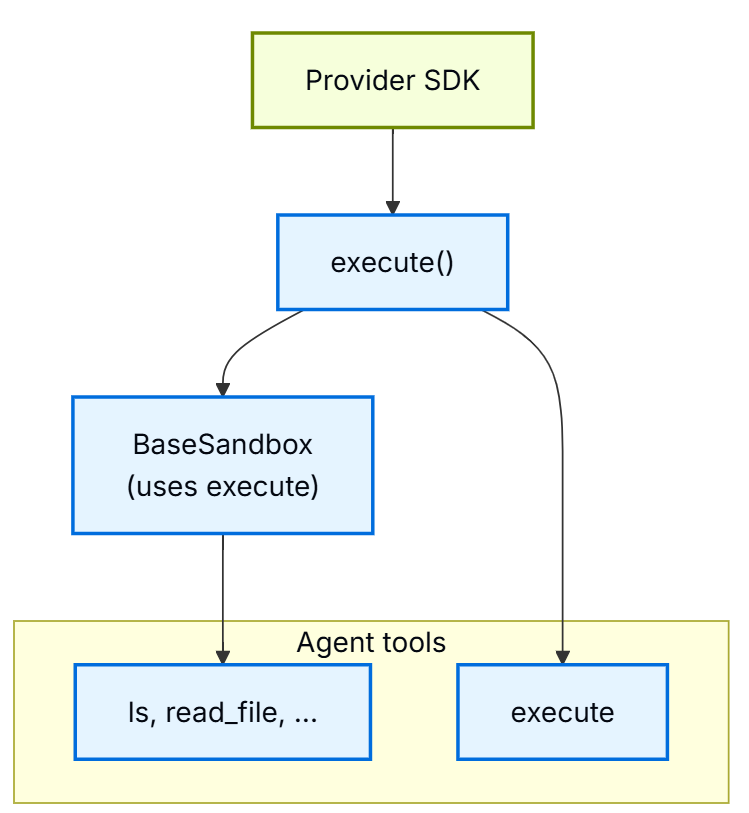
这种设计意味着:
- 添加新提供商非常简单:只需实现
execute()方法,基类会处理所有其他事务。 execute工具是条件可用的:在每次模型调用时,harness会检查后端是否实现了SandboxBackendProtocol。如果没有,该工具会被过滤掉,智能体也就无法看到它。- 当智能体调用
execute工具时:它提供一个命令字符串,并获取组合后的标准输出/标准错误、退出代码,以及如果输出过大时的截断通知。 - 你也可以在应用程序代码中直接调用后端的
execute()方法。
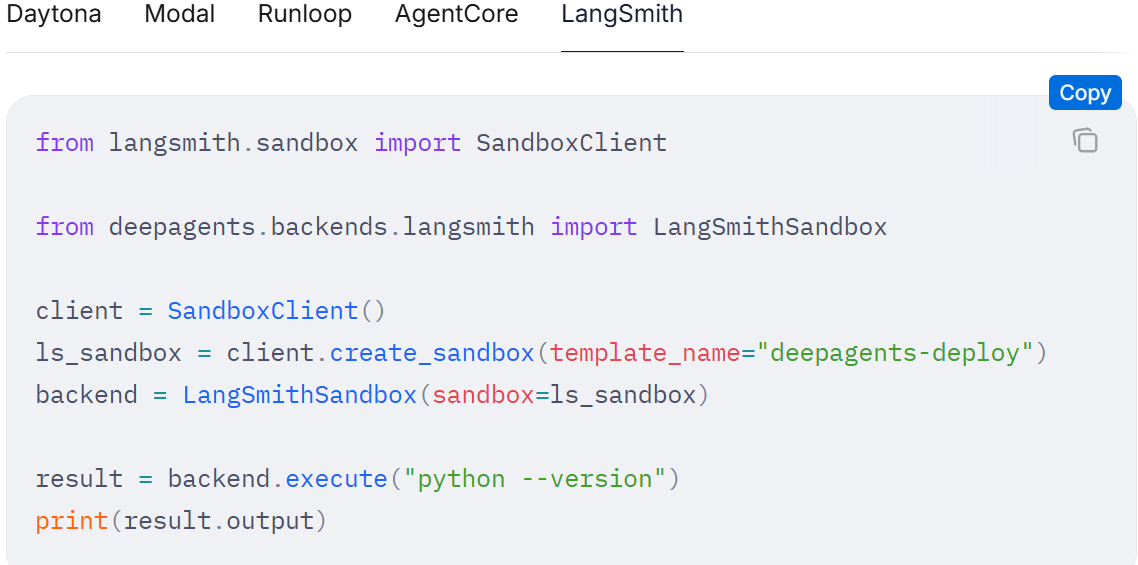
输出例子

如果命令产生的输出量过大,结果会自动保存到文件中,并指示代理使用 read_file 来增量读取。这样可以防止上下文窗口溢出。
文件访问的两个层面
文件在沙箱内外移动有两种截然不同的方式,理解何时使用每种方式至关重要:
1. 智能体文件系统工具
这是大型语言模型(LLM)在执行任务时调用的工具,例如 read_file、write_file、edit_file、ls、glob、grep 和 execute。这些工具最终通过在沙箱内部执行 execute() 来实现。智能体使用它们来读取代码、编写文件和运行命令,以完成其任务。
2. 文件传输 API
这是你的应用程序代码调用的 uploadFiles() 和 downloadFiles() 方法。这些方法使用提供商原生的文件传输 API(而非 Shell 命令),旨在在你的主机环境和沙箱之间移动文件。
使用场景:
- 在智能体运行前,用源代码、配置或数据初始化沙箱。
- 在智能体完成任务后,检索生成的代码、构建产物或报告等文件。
- 预先填充智能体所需的依赖项。
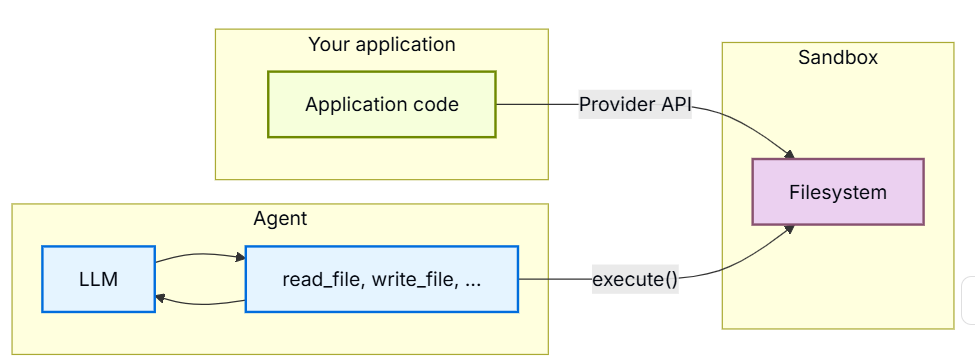
14.7 使用文件工作
DeepAgents 的沙箱后端支持文件传输 API,用于在你的应用程序和沙箱之间移动文件。
初始化沙箱
在智能体运行之前,使用 upload_files() 方法来填充沙箱。路径必须是绝对路径,内容必须是字节格式。
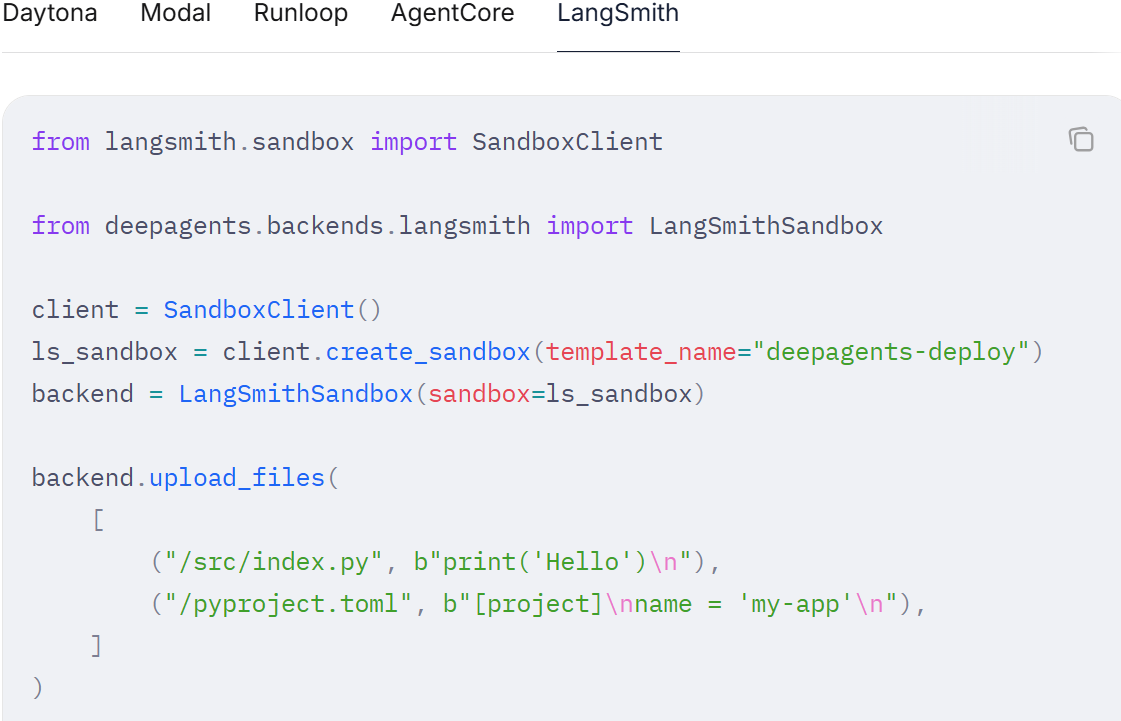
检索工件
在智能体完成任务后,使用 download_files() 方法从沙箱中检索文件。
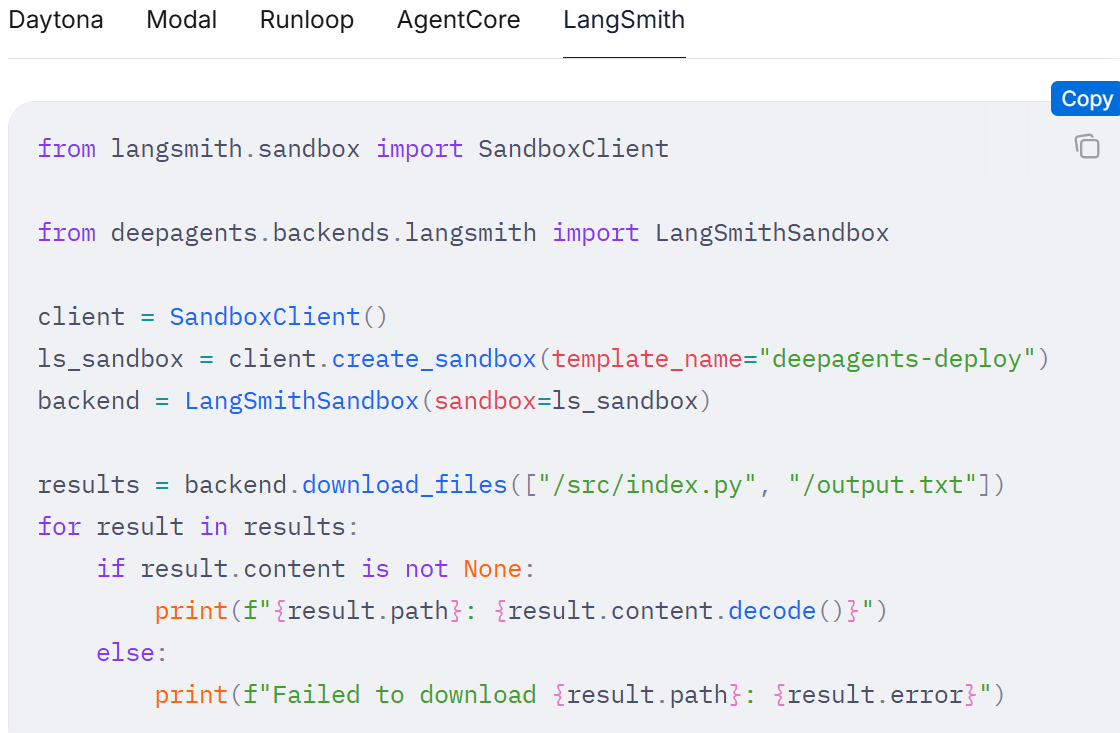
在沙箱内部,智能体使用文件系统工具(read_file, write_file)。而 upload_files 和 download_files 方法则是供你的应用程序代码使用,用于在主机和沙箱之间跨边界移动文件。
14.8 安全考虑
沙箱可以将代码执行与你的主机系统隔离开来,但它们无法防御上下文注入。控制了部分智能体输入的攻击者,可以指示智能体在沙箱内部读取文件、运行命令或窃取数据。这使得沙箱内的凭据尤其危险。
永远不要将机密信息放入沙箱中。 通过环境变量、挂载文件或 secrets 选项注入沙箱的 API 密钥、令牌、数据库凭据和其他机密信息,都可能被经过上下文注入的智能体读取并窃取。即使是短期或限定范围的凭据也适用此规则——如果智能体可以访问它们,攻击者也可以。
安全处理机密信息
如果你的智能体需要调用经过身份验证的 API 或访问受保护的资源,你有两种选择:
1. 在沙箱外部的工具中保留机密信息(推荐)
定义在主机环境(而非沙箱内部)中运行的工具,并在那里处理身份验证。智能体按名称调用这些工具,但永远看不到凭据。这是推荐的方法。
2. 使用注入凭据的网络代理
某些沙箱提供商支持代理,这些代理可以拦截来自沙箱的传出 HTTP 请求,并在转发之前附加凭据(例如 Authorization 标头)。智能体永远看不到机密信息——它只是向 URL 发出普通请求。目前,这种方法尚未在提供商中广泛普及。
如果你必须将机密信息注入到沙箱中(不推荐),请采取以下预防措施:
- 启用人工介入审批:对所有工具调用(不仅仅是敏感操作)都要求人工审批。
- 阻止或限制网络访问:限制沙箱的网络访问,以阻断数据渗漏的路径。
- 最小化凭据权限和时效:使用权限范围最窄、生命周期最短的凭据。
- 监控网络流量:监控沙箱的网络流量,留意意外的出站请求。
通用最佳实践
为了确保安全,请遵循以下通用准则:
- 审查沙箱输出:在应用程序中根据沙箱输出采取行动之前,务必先进行审查。
- 阻断网络连接:在不需要网络访问时,阻断沙箱的网络连接。
- 使用中间件过滤:使用中间件来过滤或编辑工具输出中的敏感模式。
- 视为不可信输入:将沙箱内部产生的所有内容都视为不可信的输入。
15 配置(profile)
Harness 和提供商配置文件仅支持 Python,且需要 deepagents>=0.5.4 版本。它们属于公开测试版 API,可能会在后续版本中进行更新
Harness 配置文件允许你打包配置,以便在选定特定提供商或模型时由 Deep Agents 应用。它是调整 Harness 针对特定模型行为的主要方式,而无需更改 create_deep_agent 的调用点。
- 功能:可调整系统提示、工具描述、排除或添加工具/中间件,以及通用的子智能体编辑。
- 使用方式:在 Python 中构建配置时使用
HarnessProfile;在加载或保存 YAML/JSON 文件时使用HarnessProfileConfig。 - 内置支持:Deep Agents 为 OpenAI 和 Anthropic (Claude) 模型提供了内置的 Harness 配置文件。
提供商配置是用于模型构建参数的一个较窄的配套 API,它不会影响 Harness 的行为。大多数调用者不需要它;仅在需要设置 init_chat_model 默认值、凭据检查或运行时派生的参数作为默认值时使用(例如在打包提供商集成时)。
15.1 驾驭配置
HarnessProfile 描述了 create_deep_agent 在构建聊天模型之后会应用的提示词组装、工具可见性、中间件以及默认子智能体的调整
from deepagents import (
GeneralPurposeSubagentProfile,
HarnessProfile,
register_harness_profile,
)
register_harness_profile(
"openai:gpt-5.4",
HarnessProfile(
system_prompt_suffix="Respond in under 100 words.",
excluded_tools={"execute"},
excluded_middleware={"SummarizationMiddleware"},
general_purpose_subagent=GeneralPurposeSubagentProfile(enabled=False),
),
)以下是 HarnessProfile 中用于微调智能体行为的关键参数:
-
base_system_prompt(string):
替换基础的 Deep Agents 系统提示词(对应提示词组装中的CUSTOM)。 -
system_prompt_suffix(string):
将文本追加到组装好的基础提示词末尾(对应SUFFIX)。此设置会同时应用于主智能体、声明式子智能体以及自动添加的通用子智能体。 -
tool_description_overrides(Mapping[str, str]):
覆盖特定工具的描述,通过工具名称作为键进行索引。 -
excluded_tools(frozenset[str]):
从工具集中移除特定的 Harness 级别工具。 -
excluded_middleware(frozenset[type[AgentMiddleware] | str]):
从中间件堆栈中剥离特定的中间件类。接受中间件类对象或其字符串名称。 -
extra_middleware(Sequence[AgentMiddleware] | Callable[[], Sequence[AgentMiddleware]]):
向该配置文件适用的每个堆栈追加中间件。 -
general_purpose_subagent(GeneralPurposeSubagentProfile):
禁用、重命名或重新提示通用子智能体。当此字段的system_prompt与base_system_prompt同时设置时,通用子智能体的提示词优先级更高。
提示词组装顺序
调用者提供的 system_prompt= 始终位于组装后提示词的最前端,而 system_prompt_suffix 始终位于最后——无论选择了哪种模型。
- 子智能体规则:同样的覆盖规则也适用于子智能体,每个子智能体都会根据其自身的模型重新运行配置文件解析。
中间件移除限制
excluded_middleware 参数无法移除 Deep Agents 运行所依赖的核心脚手架。
- 禁止移除的组件:如果你尝试在列表中指定
FilesystemMiddleware、SubAgentMiddleware或内部权限中间件,系统将抛出ValueError错误。
excluded_middleware 列表中的条目接受两种形式,你可以根据场景选择使用:
1. 中间件类或字符串名称
- 中间件类:通过精确类型匹配。
- 普通字符串:匹配
AgentMiddleware.name。 - 适用场景:主要用于内置中间件或公共别名,例如
"SummarizationMiddleware"。
2. 模块导入引用
- 格式:
module:Class(例如"my_pkg.middleware:TelemetryMiddleware")。 - 功能:用于从配置文件中定位特定的中间件类。
- 注意:导入引用是惰性解析的,这意味着只有在实际使用时才会加载。因此,请仅在受信任的本地配置中使用,因为加载过程会导入 Python 代码。
15.2 注册键
这两种配置文件类型(Harness 和 Provider)使用相同的键格式,并遵循特定的合并规则:
键格式
- 提供商级别:使用简单的提供商名称(如
"openai"),该配置将应用于该提供商下的所有模型。 - 模型级别:使用完全限定的键(如
"openai:gpt-5.4"),该配置仅应用于该特定模型。
合并规则
- 解析时合并:当同时存在提供商级别和模型级别的配置文件时,它们会在解析时进行合并。
- 继承与覆盖:未在模型级别设置的字段将继承自提供商级别的配置文件;而显式设置的模型级别值将覆盖提供商级别的值。
- 重新注册:在现有键下重新注册配置文件时,新的配置文件会合并到旧的之上,而不是直接替换它。
配置文件的设计初衷是针对特定模型或提供商进行调整,因此:
- 无通配符:不存在能匹配所有提供商的通配符键。
- 如何全局应用:若要将相同的配置(例如,移除
TodoListMiddleware)应用到所有模型,你需要为你使用的每一个提供商键都注册一次该配置文件。 - 最佳实践:配置文件适用于依赖所选模型的调整。而那些不依赖模型、需要全局生效的调整,应该在
create_deep_agent的调用点直接进行设置
15.3 合并语义
| 字段 | 合并行为 |
|---|---|
| base_system_prompt, system_prompt_suffix | 如果新配置中设置了值,则新值胜出;否则继承旧值。 |
| tool_description_overrides | 映射按字典键(key)合并;对于相同的键,新值胜出。 |
| excluded_tools, excluded_middleware | 取两个集合的并集(Set Union)。 |
| extra_middleware | 按具体类进行合并:新实例会替换其位置上的现有实例,新类则追加到末尾。 |
| general_purpose_subagent | 按字段合并:未设置的字段继承旧值。 |
| init_kwargs (provider) | 字典按键合并;对于相同的键,新值胜出。 |
| pre_init (provider) | 可调用对象(Callables)会形成链式调用:先执行现有的,再执行新的。 |
| init_kwargs_factory (provider) | 工厂函数会形成链式调用,并在每次 resolve_model 调用时合并它们的输出。 |
15.4 Provider 配置文件
ProviderProfile 用于声明 Deep Agents 应如何为给定的提供商或特定模型规格构建聊天模型。
它的使用有一个关键前提:
- 仅当你使用
provider:model格式的字符串来创建 deep agent 时,它才会生效。 - 如果你直接传入一个通过
init_chat_model预先配置好的模型实例,则此配置文件不适用。
from deepagents import ProviderProfile, register_provider_profile
register_provider_profile(
"openai",
ProviderProfile(init_kwargs={"temperature": 0}),
)Provider 配置文件包含以下三个核心参数,用于控制模型的初始化过程:
1. init_kwargs
- 类型:
Mapping[str, Any] - 功能: 静态初始化参数,这些参数会被直接转发给
init_chat_model函数。
2. pre_init
- 类型:
Callable[[str], None] - 功能: 在模型构建之前运行的副作用逻辑,例如用于验证凭据是否有效。
3. init_kwargs_factory
- 类型:
Callable[[], dict[str, Any]] - 功能: 一个工厂函数,用于从运行时状态(例如从环境变量中提取的请求头)动态派生参数字典
15.5 从配置文件加载配置文件
对于基于 YAML 或 JSON 的工作流,你可以使用 HarnessProfileConfig 类来加载配置。
HarnessProfileConfig 的作用
- 镜像声明式子集:它镜像了
HarnessProfile的声明式部分,包括提示词文本、工具描述覆盖、被排除的工具和中间件,以及对通用子智能体的编辑。 - 序列化支持:它拥有
to_dict和from_dict方法,方便进行序列化和反序列化。 - 职责分离:运行时特有的状态——例如中间件实例、工厂函数以及类形式的
excluded_middleware条目——仍然保留在HarnessProfile上,不包含在配置文件中。
注册流程
register_harness_profile 函数可以接受这两种类型中的任何一种。因此,基于配置文件的调用者无需手动进行转换步骤,可以直接使用 HarnessProfileConfig 进行注册。
# openai.yaml
base_system_prompt: You are helpful.
system_prompt_suffix: Respond briefly.
excluded_tools:
- execute
- grep
excluded_middleware:
- SummarizationMiddleware
- my_pkg.middleware:TelemetryMiddleware
general_purpose_subagent:
enabled: falseimport yaml
from deepagents import HarnessProfileConfig, register_harness_profile
with open("openai.yaml") as f:
register_harness_profile(
"openai",
HarnessProfileConfig.from_dict(yaml.safe_load(f)),
)15.6 以插件形式分发配置文件
你可以将配置文件作为插件进行分发,无需调用者手动运行 register_*_profile 函数,而是通过 importlib.metadata 的入口点(entry points)自动注册。
加载顺序
配置文件的加载遵循严格的顺序,后加载的会覆盖先加载的:
- 内置配置文件
- 通过入口点加载的插件配置文件
- 用户代码中直接调用
register_*_profile的配置文件
这三种方式最终都会汇入同一个累加式注册流程中,因此对于相同的键,后面的注册会层层叠加在前面之上。
声明入口点
你需要在分发包的 pyproject.toml 文件中,于相应的组(group)下声明一个入口点。
[project.entry-points."deepagents.harness_profiles"]
my_provider = "my_pkg.profiles:register_harness"
[project.entry-points."deepagents.provider_profiles"]
my_provider = "my_pkg.profiles:register_provider"当 deepagents.profiles 模块被导入时,这个可调用对象就会自动执行,完成相应的注册工作
from deepagents import (
HarnessProfile,
ProviderProfile,
register_harness_profile,
register_provider_profile,
)
def register_harness() -> None:
register_harness_profile(
"my_provider",
HarnessProfile(system_prompt_suffix="Batch independent tool calls in parallel."),
)
def register_provider() -> None:
register_provider_profile(
"my_provider",
ProviderProfile(init_kwargs={"temperature": 0}),
)15.7 相关资源
为了帮助你更全面地掌握 Deep Agents,以下是三个关键维度的延伸阅读指引:
1. Harness 概览
深入了解 Harness 的核心能力与设计哲学,探索其作为“开箱即用”智能体框架的完整功能集。
2. 模型配置
学习如何配置模型提供商及具体参数,掌握从 Provider Profile 到运行时模型初始化的全流程。
3. 深度定制
查看 create_deep_agent 的完整配置表面,了解如何通过工具、中间件和提示词微调,打造符合特定业务需求的智能体。
16 流
Deep Agents 在 LangGraph 的流式传输基础设施之上,提供了对子智能体流(subagent streams)的原生支持。这意味着当主智能体将任务委派给子智能体时,你可以独立地流式获取每个子智能体的更新,实时追踪其进度、LLM 生成的 Token 以及工具调用。
🚀 Deep Agent 流式传输的能力
-
流式传输子智能体进度
实时追踪每个子智能体在并行执行过程中的状态和进展。 -
流式传输 LLM Token
不仅限于主智能体,你还可以流式获取每个子智能体生成的 Token,实现更细粒度的实时反馈。 -
流式传输工具调用
能够实时看到子智能体在执行任务过程中调用了哪些工具以及返回的结果。 -
流式传输自定义更新
允许你在子智能体节点内部发射用户自定义的信号,用于传递特定的业务状态或日志。
16.1 开启子智能体流
Deep Agents 利用 LangGraph 的子图流式传输(subgraph streaming)功能,将子智能体执行过程中的事件暴露出来。为了确保你能接收到这些来自子智能体的事件,在调用流式传输方法时,必须显式启用 stream_subgraphs 参数。
from deepagents import create_deep_agent
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt="You are a helpful research assistant",
subagents=[
{
"name": "researcher",
"description": "Researches a topic in depth",
"system_prompt": "You are a thorough researcher.",
},
],
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Research quantum computing advances"}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
if chunk["ns"]:
# Subagent event - namespace identifies the source
print(f"[subagent: {chunk['ns']}]")
else:
# Main agent event
print("[main agent]")
print(chunk["data"])16.2 命令空间
当启用 stream_subgraphs 后,每个流式事件都会包含一个命名空间(namespace)。这个命名空间是一个由节点名称和任务 ID 组成的路径,它清晰地标识了事件是由哪一个智能体产生的,从而代表了智能体的层级结构。
| 命名空间 (Namespace) | 来源 (Source) |
|---|---|
() (空元组) |
主智能体 (Main agent) |
("tools:abc123",) |
由主智能体的任务工具调用 abc123 生成的子智能体 |
("tools:abc123", "model_request:def456") |
该子智能体内部的模型请求节点 |
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Plan my vacation"}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
# Check if this event came from a subagent
is_subagent = any(
segment.startswith("tools:") for segment in chunk["ns"]
)
if is_subagent:
# Extract the tool call ID from the namespace
tool_call_id = next(
s.split(":")[1] for s in chunk["ns"] if s.startswith("tools:")
)
print(f"Subagent {tool_call_id}: {chunk['data']}")
else:
print(f"Main agent: {chunk['data']}")16.3 子智能体进度
为了更清晰地追踪子智能体的执行进度,你可以使用 stream_mode="updates"。与流式传输原始消息不同,这种模式会在每个步骤完成时发出更新。这对于前端展示非常有用,因为它能让你确切地知道:
- 哪些子智能体处于活动状态。
- 它们刚刚完成了什么具体工作(例如工具调用结果或状态变更)
from deepagents import create_deep_agent
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt=(
"You are a project coordinator. Always delegate research tasks "
"to your researcher subagent using the task tool. Keep your final response to one sentence."
),
subagents=[
{
"name": "researcher",
"description": "Researches topics thoroughly",
"system_prompt": (
"You are a thorough researcher. Research the given topic "
"and provide a concise summary in 2-3 sentences."
),
},
],
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Write a short summary about AI safety"}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
# Main agent updates (empty namespace)
if not chunk["ns"]:
for node_name, data in chunk["data"].items():
if node_name == "tools":
# Subagent results returned to main agent
for msg in data.get("messages", []):
if msg.type == "tool":
print(f"\nSubagent complete: {msg.name}")
print(f" Result: {str(msg.content)[:200]}...")
else:
print(f"[main agent] step: {node_name}")
# Subagent updates (non-empty namespace)
else:
for node_name, data in chunk["data"].items():
print(f" [{chunk['ns'][0]}] step: {node_name}")上面这段代码严重的烂代码味道(长长的阶梯状代码),这种样板代码很多,无语,毫无美感。
[main agent] step: model_request
[tools:call_abc123] step: model_request
[tools:call_abc123] step: tools
[tools:call_abc123] step: model_request
Subagent complete: task
Result: ## AI Safety Report...
[main agent] step: model_request16.4 LLM Tokens
如果你希望实现类似“打字机”的实时效果,应该使用 stream_mode="messages"。这种模式允许你流式获取来自主智能体和子智能体的单个 Token。关键在于,每个消息事件都会携带元数据(metadata),你可以通过它来精准识别消息的来源智能体。
current_source = ""
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Research quantum computing advances"}]},
stream_mode="messages",
subgraphs=True,
version="v2",
):
if chunk["type"] == "messages":
token, metadata = chunk["data"]
# Check if this event came from a subagent (namespace contains "tools:")
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
if is_subagent:
# Token from a subagent
subagent_ns = next(s for s in chunk["ns"] if s.startswith("tools:"))
if subagent_ns != current_source:
print(f"\n\n--- [subagent: {subagent_ns}] ---")
current_source = subagent_ns
if token.content:
print(token.content, end="", flush=True)
else:
# Token from the main agent
if "main" != current_source:
print("\n\n--- [main agent] ---")
current_source = "main"
if token.content:
print(token.content, end="", flush=True)
print()16.5 工具调用
当子智能体使用工具时,你可以流式获取工具调用事件,以展示每个子智能体正在执行的操作。工具调用块会出现在 messages 流模式中。
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Research recent quantum computing advances"}]},
stream_mode="messages",
subgraphs=True,
version="v2",
):
if chunk["type"] == "messages":
token, metadata = chunk["data"]
# Identify source: "main" or the subagent namespace segment
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
source = next((s for s in chunk["ns"] if s.startswith("tools:")), "main") if is_subagent else "main"
# Tool call chunks (streaming tool invocations)
if token.tool_call_chunks:
for tc in token.tool_call_chunks:
if tc.get("name"):
print(f"\n[{source}] Tool call: {tc['name']}")
# Args stream in chunks - write them incrementally
if tc.get("args"):
print(tc["args"], end="", flush=True)
# Tool results
if token.type == "tool":
print(f"\n[{source}] Tool result [{token.name}]: {str(token.content)[:150]}")
# Regular AI content (skip tool call messages)
if token.type == "ai" and token.content and not token.tool_call_chunks:
print(token.content, end="", flush=True)
print()16.6 自定义更新
使用 get_stream_writer 在你的子智能体工具内部发射自定义的进度事件
import time
from langchain.tools import tool
from langgraph.config import get_stream_writer
from deepagents import create_deep_agent
@tool
def analyze_data(topic: str) -> str:
"""Run a data analysis on a given topic.
This tool performs the actual analysis and emits progress updates.
You MUST call this tool for any analysis request.
"""
writer = get_stream_writer()
writer({"status": "starting", "topic": topic, "progress": 0})
time.sleep(0.5)
writer({"status": "analyzing", "progress": 50})
time.sleep(0.5)
writer({"status": "complete", "progress": 100})
return (
f'Analysis of "{topic}": Customer sentiment is 85% positive, '
"driven by product quality and support response times."
)
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
system_prompt=(
"You are a coordinator. For any analysis request, you MUST delegate "
"to the analyst subagent using the task tool. Never try to answer directly. "
"After receiving the result, summarize it in one sentence."
),
subagents=[
{
"name": "analyst",
"description": "Performs data analysis with real-time progress tracking",
"system_prompt": (
"You are a data analyst. You MUST call the analyze_data tool "
"for every analysis request. Do not use any other tools. "
"After the analysis completes, report the result."
),
"tools": [analyze_data],
},
],
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Analyze customer satisfaction trends"}]},
stream_mode="custom",
subgraphs=True,
version="v2",
):
if chunk["type"] == "custom":
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
if is_subagent:
subagent_ns = next(s for s in chunk["ns"] if s.startswith("tools:"))
print(f"[{subagent_ns}]", chunk["data"])
else:
print("[main]", chunk["data"])[tools:call_abc123] {'status': 'starting', 'topic': 'customer satisfaction trends', 'progress': 0}
[tools:call_abc123] {'status': 'analyzing', 'progress': 50}
[tools:call_abc123] {'status': 'complete', 'progress': 100}16.7 流多模式
你可以组合多种流模式,从而获得智能体执行过程的完整全景
# Skip internal middleware steps - only show meaningful node names
INTERESTING_NODES = {"model_request", "tools"}
last_source = ""
mid_line = False # True when we've written tokens without a trailing newline
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Analyze the impact of remote work on team productivity"}]},
stream_mode=["updates", "messages", "custom"],
subgraphs=True,
version="v2",
):
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
source = "subagent" if is_subagent else "main"
if chunk["type"] == "updates":
for node_name in chunk["data"]:
if node_name not in INTERESTING_NODES:
continue
if mid_line:
print()
mid_line = False
print(f"[{source}] step: {node_name}")
elif chunk["type"] == "messages":
token, metadata = chunk["data"]
if token.content:
# Print a header when the source changes
if source != last_source:
if mid_line:
print()
mid_line = False
print(f"\n[{source}] ", end="")
last_source = source
print(token.content, end="", flush=True)
mid_line = True
elif chunk["type"] == "custom":
if mid_line:
print()
mid_line = False
print(f"[{source}] custom event:", chunk["data"])
print()16.8 通用模式
追踪子智能体生命周期
你可以监控子智能体何时启动、运行中以及完成:
active_subagents = {}
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Research the latest AI safety developments"}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
for node_name, data in chunk["data"].items():
# ─── Phase 1: Detect subagent starting ────────────────────────
# When the main agent's model_request contains task tool calls,
# a subagent has been spawned.
if not chunk["ns"] and node_name == "model_request":
for msg in data.get("messages", []):
for tc in getattr(msg, "tool_calls", []):
if tc["name"] == "task":
active_subagents[tc["id"]] = {
"type": tc["args"].get("subagent_type"),
"description": tc["args"].get("description", "")[:80],
"status": "pending",
}
print(
f'[lifecycle] PENDING → subagent "{tc["args"].get("subagent_type")}" '
f'({tc["id"]})'
)
# ─── Phase 2: Detect subagent running ─────────────────────────
# When we receive events from a tools:UUID namespace, that
# subagent is actively executing.
if chunk["ns"] and chunk["ns"][0].startswith("tools:"):
pregel_id = chunk["ns"][0].split(":")[1]
# Check if any pending subagent needs to be marked running.
# Note: the pregel task ID differs from the tool_call_id,
# so we mark any pending subagent as running on first subagent event.
for sub_id, sub in active_subagents.items():
if sub["status"] == "pending":
sub["status"] = "running"
print(
f'[lifecycle] RUNNING → subagent "{sub["type"]}" '
f"(pregel: {pregel_id})"
)
break
# ─── Phase 3: Detect subagent completing ──────────────────────
# When the main agent's tools node returns a tool message,
# the subagent has completed and returned its result.
if not chunk["ns"] and node_name == "tools":
for msg in data.get("messages", []):
if msg.type == "tool":
sub = active_subagents.get(msg.tool_call_id)
if sub:
sub["status"] = "complete"
print(
f'[lifecycle] COMPLETE → subagent "{sub["type"]}" '
f"({msg.tool_call_id})"
)
print(f" Result preview: {str(msg.content)[:120]}...")
# Print final state
print("\n--- Final subagent states ---")
for sub_id, sub in active_subagents.items():
print(f" {sub['type']}: {sub['status']}")用起来有点恶心,工程中到处是这种代码,恶心到吐。
16.9 v2格式流
需要 LangGraph >= 1.1 版本。此页面上的所有示例均使用推荐的 v2 流式传输格式 (version="v2")。
v2 格式 (推荐)
- 结构统一:每个数据块都是一个
StreamPart字典,包含type、ns(命名空间) 和data键。 - 优势:无论流模式如何、是否开启子图流,数据形状始终一致。消除了繁琐的嵌套元组解包,处理子智能体流变得非常直观。
旧格式 (Legacy)
- 结构复杂:通常返回
(namespace, payload)的元组,且payload内部结构随模式变化,需要大量解包代码。
#v2
# Unified format — no nested tuple unpacking
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Research quantum computing"}]},
stream_mode=["updates", "messages", "custom"],
subgraphs=True,
version="v2",
):
print(chunk["type"]) # "updates", "messages", or "custom"
print(chunk["ns"]) # () for main agent, ("tools:<id>",) for subagent
print(chunk["data"]) # payload
#v1
# Must handle (namespace, (mode, data)) nested tuples
for namespace, chunk in agent.stream(
{"messages": [{"role": "user", "content": "Research quantum computing"}]},
stream_mode=["updates", "messages", "custom"],
subgraphs=True,
):
mode, data = chunk[0], chunk[1]
print(mode) # "updates", "messages", or "custom"
print(namespace) # () for main agent, ("tools:<id>",) for subagent
print(data) # payload你可以查阅 LangGraph 的流式传输文档,以获取关于 v2 格式的更多详细信息,特别是类型收窄和Pydantic/数据类强制转换功能
16.10 引用
非常抱歉,刚才没有严格执行您的“默认翻译成中文”指令。以下是您提供的三段关于 Deep Agents 和 LangChain 的技术文档翻译:
- 子智能体:在 Deep Agents 中配置和使用子智能体。
- 前端流式传输:使用
useStream为 Deep Agents 构建 React 用户界面。 - LangChain 流式传输概览:LangChain 智能体的通用流式传输概念。
17 协议
17.1 ACP
Agent Client Protocol (ACP) 标准化了编程智能体与代码编辑器或集成开发环境之间的通信。通过 ACP 协议,您可以在任何兼容 ACP 的客户端上使用自定义的深度智能体,让您的代码编辑器能够提供项目上下文并接收丰富的更新信息。
ACP 专为智能体与编辑器的集成而设计。如果您希望您的智能体调用托管在外部服务器上的工具,请参阅模型上下文协议 (MCP)
这个玩意和MCP(stdio)差别有点不好区分。
17.1.1 起步

然后通过 ACP 暴露一个深度智能体。
这将启动一个运行在标准输入/输出(stdio)模式下的 ACP 服务器(它从 stdin 读取请求,并将响应写入 stdout)。在实际应用中,您通常将其作为由 ACP 客户端(例如您的编辑器)启动的命令来运行,随后客户端会通过标准输入/输出与服务器进行通信。
import asyncio
from acp import run_agent
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
from deepagents_acp.server import AgentServerACP
async def main() -> None:
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
# You can customize your deep agent here: set a custom prompt,
# add your own tools, attach middleware, or compose subagents.
system_prompt="You are a helpful coding assistant",
checkpointer=MemorySaver(),
)
server = AgentServerACP(agent)
await run_agent(server)
if __name__ == "__main__":
asyncio.run(main())示例编码智能体
deepagents-acp 包中包含了一个示例编码智能体,它集成了文件系统和 Shell 功能,您可以直接运行使用。
17.1.2 客户端
Deep agents 可以在任何能运行 ACP 代理服务器的地方工作。一些值得关注的 ACP 客户端包括:
- Zed
- JetBrains IDEs
- Visual Studio Code (通过 vscode-acp 插件)
- Neovim (通过 ACP 兼容插件)
Zed
Zed是一个支持ACP协议的IDE,在zed的配置文件中指定启动ACP服务的配置,Zed就能通过界面与其交互。
deepagents 代码仓库包含了一个演示用的 ACP 入口点,你可以将其注册到 Zed 中:
1 克隆 deepagents 代码仓库并安装依赖:
git clone https://github.com/langchain-ai/deepagents.git
cd deepagents/libs/acp
uv sync --all-groups
chmod +x run_demo_agent.sh2 配置演示智能体的凭证
cp .env.example .env然后在 .env 文件中设置 ANTHROPIC_API_KEY。接着在 Zed 的 settings.json 中配置你的 ACP 智能体服务器命令:
{
"agent_servers": {
"DeepAgents": {
"type": "custom",
"command": "/your/absolute/path/to/deepagents/libs/acp/run_demo_agent.sh"
}
}
}4 打开 Zed 的 Agents 面板,并开启一个 DeepAgents 对话线程。
Toad
如果你想将 ACP 智能体服务器作为本地开发工具运行,可以使用 Toad 来管理该进程
uv tool install -U batrachian-toad
toad acp "python path/to/your_server.py" .
# or
toad acp "uv run python path/to/your_server.py" .17.2 MCP
MCP前面langchain讲过
17.3 A2A
Agent2Agent (A2A) 是谷歌推出的一项协议,旨在实现对话式 AI 智能体之间的通信。LangSmith 已经实现了对 A2A 的支持,允许你的智能体通过这一标准化协议与其他兼容 A2A 的智能体进行通信。A2A 端点在 Agent Server 中可通过 /a2a/{assistant_id} 访问
17.3.1 支持的方法
Agent Server 支持以下 A2A RPC(远程过程调用)方法:
- message/send:向助手发送一条消息并接收完整的响应。
- message/stream:发送一条消息,并使用服务器发送事件(SSE)实时流式传输响应。
- tasks/get:检索先前创建的任务的状态和结果。
17.3.2 Agent Card 发现机制
每个助手都会自动展示一张 A2A Agent Card,其中描述了它的能力,并提供了其他智能体连接所需的信息。你可以使用以下方式检索任何助手的 Agent Card:
GET /.well-known/agent-card.json?assistant_id={assistant_id}
Agent Card 包含了助手的名称、描述、可用技能、支持的输入/输出模式,以及用于通信的 A2A 端点 URL。
17.3.3 依赖要求
要使用 A2A,请确保你已安装以下依赖:
langgraph-api >= 0.4.21
使用以下命令安装:
pip install "langgraph-api>=0.4.21"
17.3.4 使用概览
要启用 A2A,请遵循以下步骤:
- 升级环境:升级使用
langgraph-api>=0.4.21。 - 部署智能体:使用基于消息的状态结构来部署你的智能体。
- 建立连接:使用该端点与其他兼容 A2A 的智能体进行连接。
17.3.5 创建兼容 A2A 的智能体
本示例将创建一个兼容 A2A 的智能体,它利用 OpenAI 的 API 处理传入消息,并维持对话状态。该智能体定义了基于消息的状态结构,并能处理 A2A 协议的消息格式。
为了兼容 A2A 的“文本”部分,智能体的状态(State)中必须包含一个 messages 键。
A2A 协议使用两个标识符来维持对话的连续性:
- contextId:将消息分组到一个对话线程中(类似于会话 ID)。
- taskId:标识该对话中的每一个独立请求。
在发送第一条消息时,请省略 contextId 和 taskId —— 智能体将会生成并返回它们。对于对话中的所有后续消息,请包含上一条响应中的 contextId 和 taskId,以维持线程的连续性。
LangSmith 追踪:LangSmith 部署的 A2A 端点会自动将 A2A 的 contextId 转换为 LangSmith 追踪用的 thread_id,从而将对话中的所有消息归拢在同一个线程下
"""LangGraph A2A conversational agent.
Supports the A2A protocol with messages input for conversational interactions.
"""
from __future__ import annotations
import os
from dataclasses import dataclass
from typing import Any, Dict, List, TypedDict
from langgraph.graph import StateGraph
from langgraph.runtime import Runtime
from openai import AsyncOpenAI
class Context(TypedDict):
"""Context parameters for the agent."""
my_configurable_param: str
@dataclass
class State:
"""Input state for the agent.
Defines the initial structure for A2A conversational messages.
"""
messages: List[Dict[str, Any]]
async def call_model(state: State, runtime: Runtime[Context]) -> Dict[str, Any]:
"""Process conversational messages and returns output using OpenAI."""
# Initialize OpenAI client
client = AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Process the incoming messages
latest_message = state.messages[-1] if state.messages else {}
user_content = latest_message.get("content", "No message content")
# Create messages for OpenAI API
openai_messages = [
{
"role": "system",
"content": "You are a helpful conversational agent. Keep responses brief and engaging."
},
{
"role": "user",
"content": user_content
}
]
try:
# Make OpenAI API call
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=openai_messages,
max_tokens=100,
temperature=0.7
)
ai_response = response.choices[0].message.content
except Exception as e:
ai_response = f"I received your message but had trouble processing it. Error: {str(e)[:50]}..."
# Create a response message
response_message = {
"role": "assistant",
"content": ai_response
}
return {
"messages": state.messages + [response_message]
}
# Define the graph
graph = (
StateGraph(State, context_schema=Context)
.add_node(call_model)
.add_edge("__start__", "call_model")
.compile()
)17.3.6 智能体间的通信
一旦你的智能体通过 langgraph dev 在本地运行,或者已经部署到生产环境,你就可以使用 A2A 协议来促进它们之间的通信。
本示例展示了两个智能体如何通过向彼此的 A2A 端点发送 JSON-RPC 消息来进行通信。该脚本模拟了一场多轮对话,其中每个智能体都会处理对方的响应并继续对话
#!/usr/bin/env python3
"""Agent-to-Agent conversation simulation using the LangGraph A2A endpoint."""
import asyncio
import aiohttp
import os
import uuid
def extract_text(result: dict) -> str:
"""Best-effort extraction of response text from an A2A result."""
for art in result.get("result", {}).get("artifacts", []) or []:
for part in art.get("parts", []) or []:
if part.get("kind") == "text" and part.get("text"):
return part["text"]
msg = (result.get("result", {}).get("status", {}) or {}).get("message", {}) or {}
for part in msg.get("parts", []) or []:
if part.get("kind") == "text" and part.get("text"):
return part["text"]
return "(no text found)"
async def send_message(session, port, assistant_id, text, context_id=None, task_id=None):
"""Send an A2A message. Returns (response_text, returned_context_id, returned_task_id)."""
url = f"http://127.0.0.1:{port}/a2a/{assistant_id}"
message = {
"role": "user",
"parts": [{"kind": "text", "text": text}],
"messageId": str(uuid.uuid4()),
}
# A2A multi-turn continuity: reuse contextId and taskId across turns/agents
if context_id:
message["contextId"] = context_id
if task_id:
message["taskId"] = task_id
payload = {
"jsonrpc": "2.0",
"id": str(uuid.uuid4()),
"method": "message/send",
"params": {"message": message},
}
headers = {"Accept": "application/json"}
async with session.post(url, json=payload, headers=headers) as response:
result = await response.json()
returned_context_id = result.get("result", {}).get("contextId") or context_id
returned_task_id = result.get("result", {}).get("id")
return extract_text(result), returned_context_id, returned_task_id
async def simulate_conversation():
"""Simulate a conversation between two agents."""
#Assistant IDs
agent_a_id = os.getenv("AGENT_A_ID")
agent_b_id = os.getenv("AGENT_B_ID")
if not agent_a_id or not agent_b_id:
print("Set AGENT_A_ID and AGENT_B_ID environment variables")
return
message = "Hello! Let's have a conversation."
context_id = None
task_id = None
async with aiohttp.ClientSession() as session:
for i in range(3):
print(f"--- Round {i + 1} ---")
message, context_id, task_id = await send_message(
session, 2024, agent_a_id, message,
context_id=context_id,
task_id=task_id,
)
print(f"🔵 Agent A: {message}")
message, context_id, task_id = await send_message(
session, 2025, agent_b_id, message,
context_id=context_id,
task_id=task_id,
)
print(f"🔴 Agent B: {message}\n")
if __name__ == "__main__":
asyncio.run(simulate_conversation())查看完整可运行的示例,请参考:
- 两个 LangGraph 智能体通信:展示了两个 LangGraph 智能体使用 A2A 协议进行交互的示例。
- Google ADK 智能体与 LangChain 智能体:展示了 Google ADK 智能体如何使用 A2A 协议与 LangChain 智能体进行交互的示例。
17.3.7 分布式追踪
当多个智能体通过 A2A 进行通信时,LangSmith 可以将它们所有的追踪记录(Traces)归拢到同一个线程(Thread)中,让你对整场多智能体对话拥有一个统一的视图。
contextId 如何映射到 thread_id
Agent Server 的 A2A 端点会自动将 A2A 的 contextId 转换为 LangSmith 追踪用的 thread_id。这意味着,对话中的每一条消息,无论涉及多少个参与的智能体,都会自动出现在 LangSmith 的同一个线程里,而你无需进行任何额外的配置。
流程如下:
- 在第一条消息中,客户端省略
contextId。服务器会生成一个并在响应中返回。 - 客户端在随后的所有消息中携带这个
contextId,以保持对话的连续性。 - Agent Server 会将
contextId映射到 LangSmith 元数据中的thread_id,因此所有回合的对话都会显示在同一个线程中。
import asyncio
import aiohttp
import uuid
async def send_message(session, url, text, context_id=None, task_id=None, thread_id=None):
"""Send an A2A message and return (response_text, context_id, task_id)."""
# --- 1. Build the message ---
# On follow-up turns, include contextId and taskId inside the message object
# so the server associates them with the ongoing conversation.
message = {
"role": "user",
"parts": [{"kind": "text", "text": text}],
"messageId": str(uuid.uuid4()),
}
if context_id:
message["contextId"] = context_id
if task_id:
message["taskId"] = task_id
# --- 2. Set thread_id in metadata ---
# thread_id goes at the top level of the JSON-RPC payload, not inside params.
payload = {
"jsonrpc": "2.0",
"id": str(uuid.uuid4()),
"method": "message/send",
"params": {"message": message},
"metadata": {"thread_id": thread_id},
}
async with session.post(url, json=payload, headers={"Accept": "application/json"}) as response:
if response.status != 200:
raise RuntimeError(f"HTTP {response.status}: {await response.text()}")
result = await response.json()
if "error" in result:
raise RuntimeError(result["error"].get("message", "Unknown error"))
result_obj = result.get("result", {})
returned_context_id = result_obj.get("contextId") or context_id
returned_task_id = result_obj.get("id")
text_out = next(
(
part.get("text", "")
for art in result_obj.get("artifacts", []) or []
for part in art.get("parts", []) or []
if part.get("kind") == "text"
),
"(no text)",
)
return text_out, returned_context_id, returned_task_id
async def run_conversation(agent_a_url, agent_b_url):
# --- 3. Share thread_id across agents ---
# Generate a shared thread_id upfront. Once the server returns a contextId,
# use that instead — this keeps the A2A context and LangSmith thread in sync.
thread_id = str(uuid.uuid4())
context_id = None
task_id = None
message = "Hello! Let's collaborate."
async with aiohttp.ClientSession() as session:
for _ in range(3):
message, context_id, task_id = await send_message(
session, agent_a_url, message,
context_id=context_id, task_id=task_id,
thread_id=context_id or thread_id,
)
# Passing the same thread_id to every agent groups all traces in LangSmith
message, context_id, task_id = await send_message(
session, agent_b_url, message,
context_id=context_id, task_id=task_id,
thread_id=context_id or thread_id,
)
asyncio.run(run_conversation(
"http://localhost:2024/a2a/<agent_a_assistant_id>",
"http://localhost:2025/a2a/<agent_b_assistant_id>",
))- 构建消息:在后续的交流回合中,请务必在消息对象中包含
contextId和taskId,这样服务器才能将它们与正在进行的对话关联起来。而在第一条消息中请省略它们,因为服务器会生成一个contextId并在响应中返回。 - 在元数据中设置 thread_id:请将
thread_id传递在 JSON-RPC 负载的顶层metadata字段中,而不是放在params里面。 - 在智能体间共享 thread_id:在发送第一条消息之前,先生成一个随机的
thread_id。一旦服务器返回了contextId,就在随后的所有请求中将其用作thread_id,这样就能保持 A2A 对话上下文和 LangSmith 线程的同步。请将同一个thread_id传递给每一个智能体,以便所有的追踪记录都能归拢到一个线程中。
17.3.8 在非 LangGraph 智能体中接收 thread_id
上一节涵盖了客户端(发送方)的内容——即在发送消息时如何传播 thread_id。
如果你的某个智能体不是基于 LangGraph 构建的,它也需要在接收端提取并附加 thread_id,这样它的追踪记录才能落入同一个 LangSmith 线程中。
请使用 langsmith.integrations.otel.configure() 来设置自动追踪,并从传入的 A2A 请求元数据中提取 thread_id,以便将追踪记录归拢到同一个线程中。
from fastapi import FastAPI, Request
from langsmith.integrations.otel import configure as configure_otel
from opentelemetry import trace
import json
# --- 1. Configure OTel ---
# Set up automatic tracing to LangSmith for your non-LangGraph agent.
configure_otel(project_name="my-a2a-project")
tracer = trace.get_tracer(__name__)
app = FastAPI()
@app.middleware("http")
async def set_thread_id_middleware(request: Request, call_next):
thread_id = None
if request.method == "POST":
body_bytes = await request.body()
if body_bytes:
# --- 2. Extract thread_id from incoming A2A metadata ---
try:
body = json.loads(body_bytes)
thread_id = body.get("metadata", {}).get("thread_id")
except Exception:
pass
# Re-inject the body so downstream handlers can still read it
async def receive():
return {"type": "http.request", "body": body_bytes}
request._receive = receive
# --- 3. Attach thread_id to the trace ---
# langsmith.metadata.thread_id groups this trace with others in the same thread.
with tracer.start_as_current_span("agent") as span:
if thread_id:
span.set_attribute("langsmith.metadata.thread_id", thread_id)
return await call_next(request)注册你的智能体路由
请在此中间件之后,将你的智能体路由注册到 app 上。
启用追踪
在你的环境变量中设置 LANGSMITH_API_KEY,并(可选地)设置 LANGSMITH_PROJECT 以启用追踪功能。对话中的所有智能体都应该使用同一个项目,这样它们的追踪记录才能在一起显示。
在 LangSmith 中查看追踪
运行完多智能体对话后,打开 LangSmith 用户界面并导航到“Threads”(线程)页面。来自所有参与智能体的所有回合对话都会显示在同一个线程下,并通过共享的 thread_id 进行标识。
禁用 A2A
要禁用 A2A 端点,请在你的 langgraph.json 配置文件中将 disable_a2a 设置为 true。
{
"$schema": "https://langgra.ph/schema.json",
"http": {
"disable_a2a": true
}
}总结
本篇主要介绍了一下deepagents,他不是一个完整独立的高层api,某些地方还是会用到langchain和langgraph,所以对于从0开始的人来说学习成本比较高,可能选择使用那个方案容易迷茫或者造成混乱。可能了解了许多,对于如何工程化并无清楚认识,这可能还需要了解很多其他框架来支撑。下篇主要讲一下前端和后台交互

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)