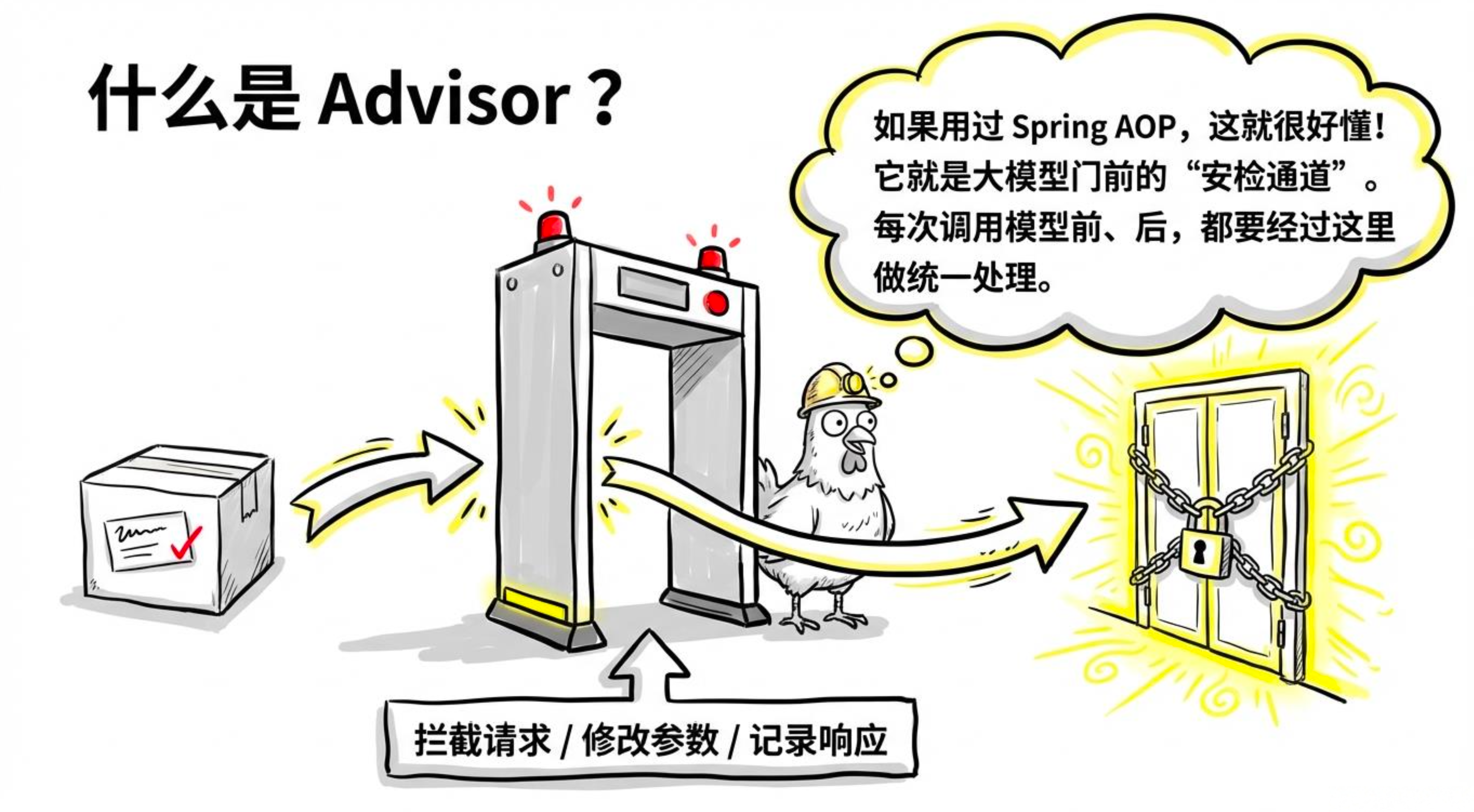
Advisor 机制——Spring AI 的“AOP 拦截器“

在构建基于大语言模型的应用程序时,我们常常需要在调用模型前后执行一些通用逻辑,比如管理对话历史、注入检索上下文、记录日志、过滤敏感词等。如果每次调用都手动编写这些代码,不仅冗余,而且难以维护。
Spring AI 提供了一套优雅的解决方案——Advisor(顾问/拦截器)。它的设计思想与 Spring AOP 如出一辙,但专门针对 AI 调用链进行了优化。本文将带你全面了解 Advisor 的执行原理、内置实现,并手把手教你编写自定义 Advisor。
一、Advisor 机制
1.1Advisor 执行链:请求与响应的“中间站”
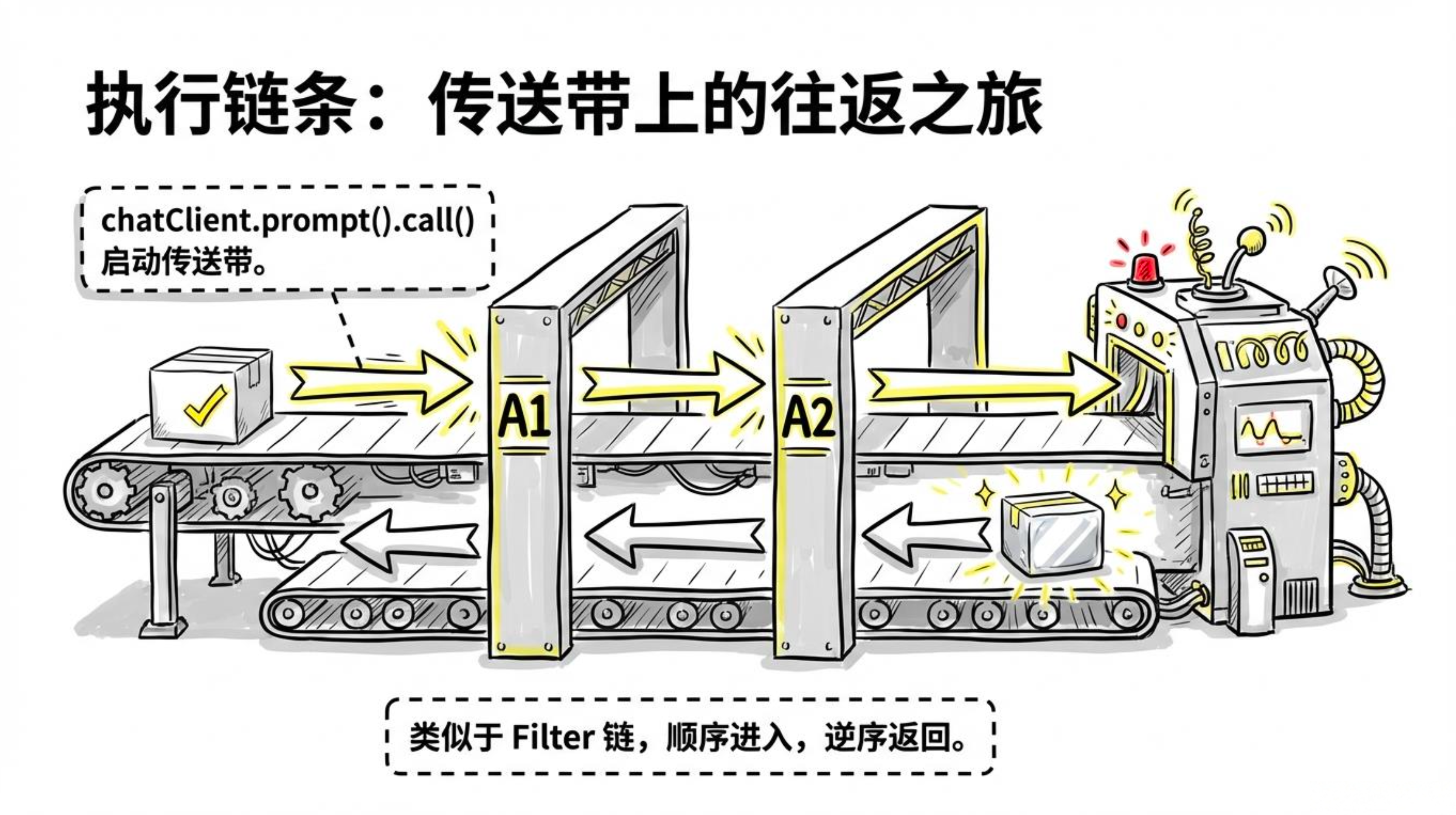
当你调用 chatClient.prompt().user("...").call() 时,请求并不会直接发送给 AI 模型,而是会依次经过一个 Advisor 链:
请求 → Advisor1(前置处理)
→ Advisor2(前置处理)
→ 实际调用模型
→ Advisor2(后置处理)
→ Advisor1(后置处理)
→ 返回响应请求 → Advisor1 → Advisor2 → ... → AdvisorN → AI 模型
响应 ← Advisor1 ← Advisor2 ← ... ← AdvisorN ← AI 模型每个 Advisor 都可以在请求到达模型之前修改请求(如添加系统提示词、注入历史消息),也可以在模型返回响应之后修改响应(如过滤输出、追加元数据)。多个 Advisor 按照注册顺序依次执行,形成一个清晰的横切关注点处理管道。
1.2内置 Advisor:开箱即用的利器
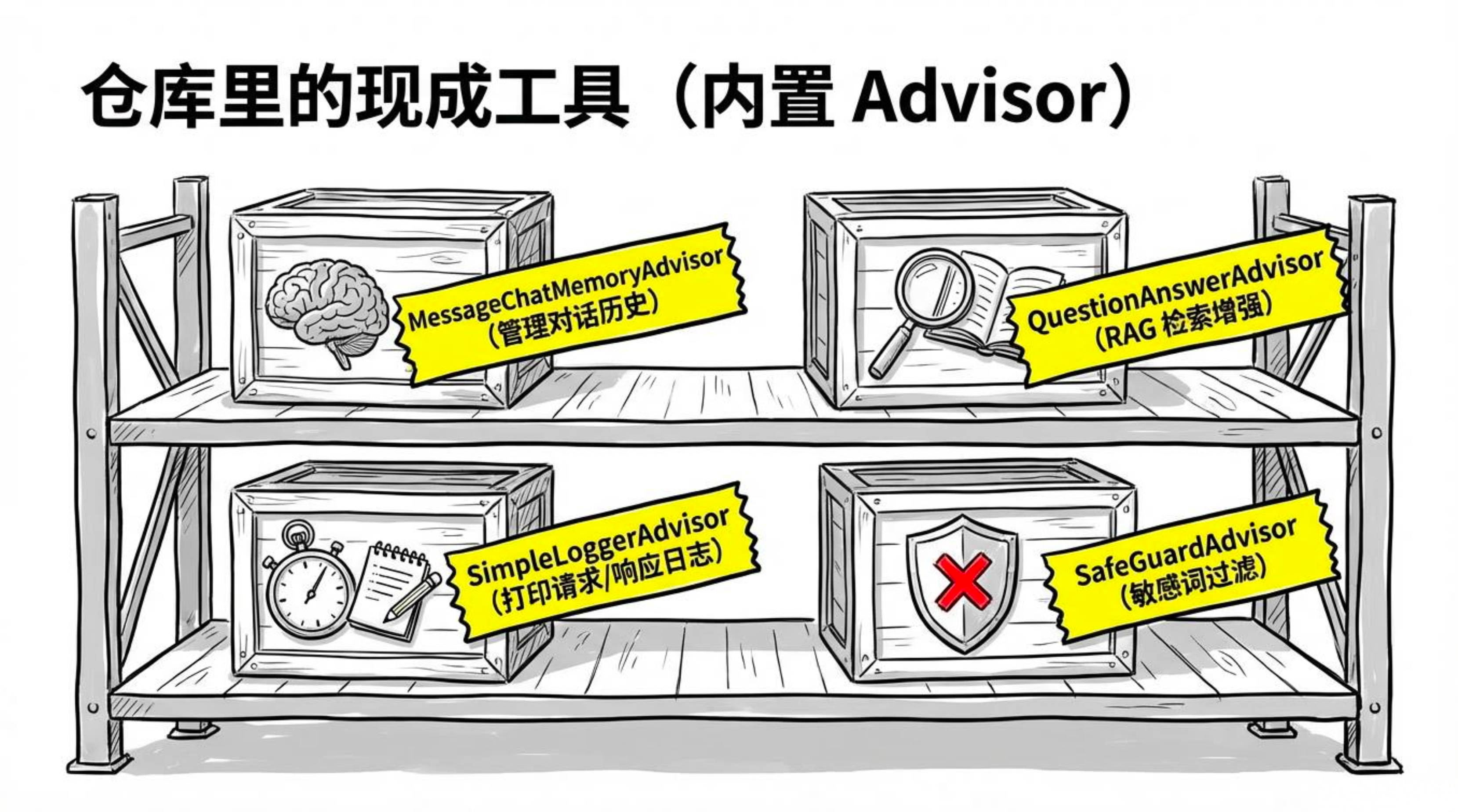
Spring AI 已经为我们提供了几个常用的 Advisor,覆盖了大部分典型场景:
| Advisor | 作用 |
|---|---|
MessageChatMemoryAdvisor |
自动管理对话历史,实现多轮记忆 |
QuestionAnswerAdvisor |
结合 RAG(检索增强生成)注入相关文档片段 |
SimpleLoggerAdvisor |
打印请求和响应的日志(DEBUG 级别) |
SafeGuardAdvisor |
过滤请求或响应中的敏感词 |
1.3使用内置 Advisor
package com.jichi.springai.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/advisor-demo")
public class AdvisorDemoController {
private final ChatClient chatClient;
private final MessageWindowChatMemory chatMemory;
public AdvisorDemoController(ChatClient.Builder builder) {
this.chatMemory = MessageWindowChatMemory.builder().maxMessages(10).build();
this.chatClient = builder
.defaultSystem("你是一个 Java 技术助手")
.defaultAdvisors(
new SimpleLoggerAdvisor(), // 打印请求/响应日志,开发调试用
MessageChatMemoryAdvisor.builder(chatMemory).build() // 对话记忆
)
.build();
}
@GetMapping
public String chat(
@RequestParam String message,
@RequestParam(defaultValue = "default") String conversationId) {
return chatClient.prompt()
.user(message)
.advisors(MessageChatMemoryAdvisor.builder(chatMemory)
.conversationId(conversationId)
.build())
.call()
.content();
}
}以 SimpleLoggerAdvisor 为例,它默认使用 DEBUG 级别输出日志,因此需要先在 application.yml 中开启:
logging:
level:
org.springframework.ai.chat.client: DEBUG注意:多个 Advisor 按照
advisors()方法中的注册顺序执行。建议将日志类、过滤类放在前面,记忆类或检索类放在后面。
1.4自定义 Advisor:实现业务定制
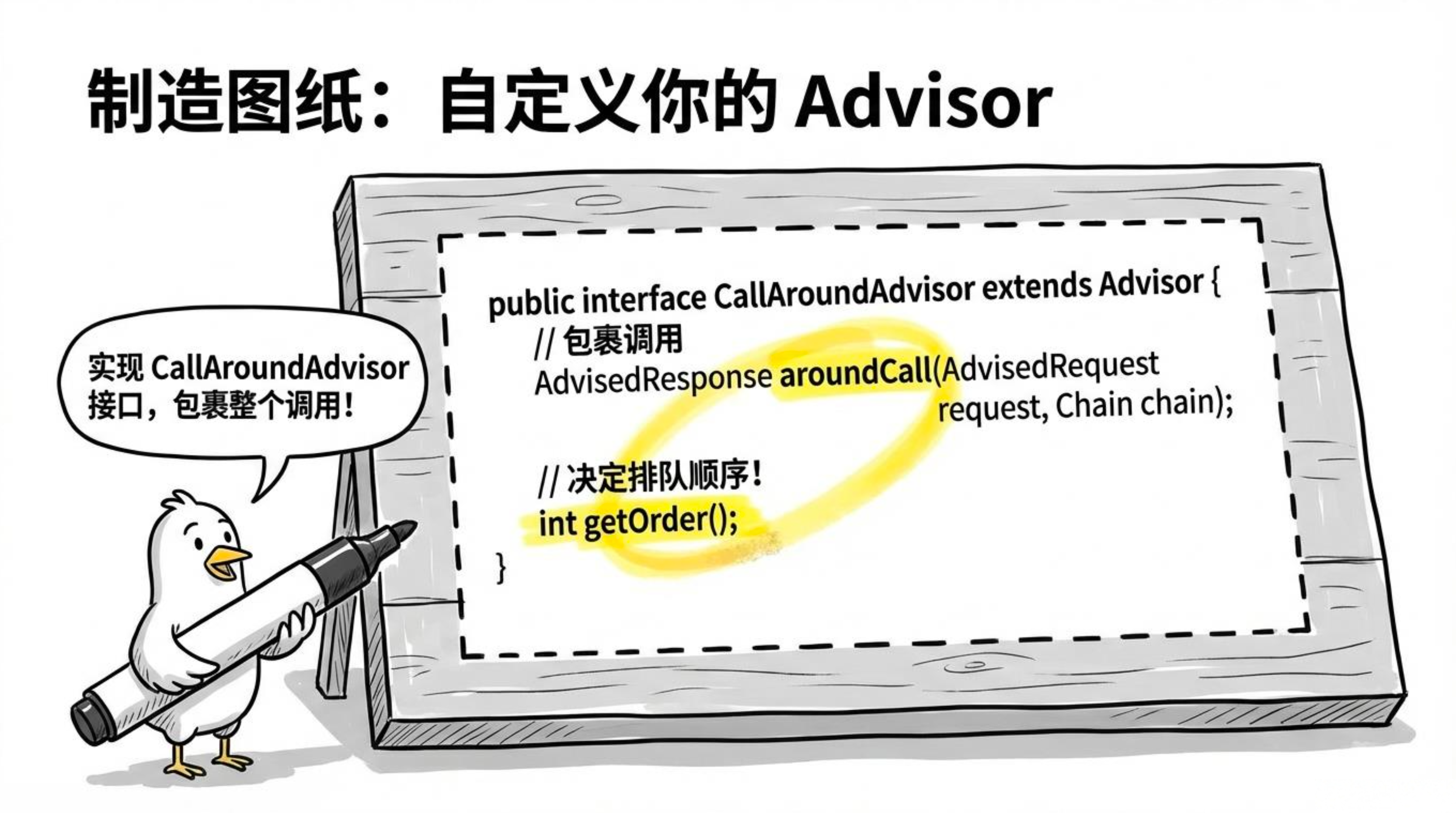
当内置 Advisor 无法满足需求时,你可以轻松实现自己的 Advisor。Spring AI 提供了两个接口:
-
CallAdvisor:同步调用场景 -
StreamAdvisor:流式响应场景(处理逐 token 输出)
实现步骤
自定义 Advisor 的核心是实现 aroundCall 方法(以同步为例):
public class MyCustomAdvisor implements CallAdvisor {
@Override
public AdvisedResponse aroundCall(AdvisedRequest request, CallAdvisorChain chain) {
// 1. 请求前处理:修改用户提示词、添加系统消息、记录开始时间等
AdvisedRequest modifiedRequest = request;
System.out.println("[Before] 原始请求: " + request.userText());
// 2. 调用链中的下一个 Advisor 或最终的目标模型
AdvisedResponse response = chain.next(modifiedRequest);
// 3. 响应后处理:过滤内容、追加统计信息、记录结束时间等
String originalContent = response.response().getResult().getOutput().getText();
String filteredContent = originalContent.replace("敏感词", "***");
System.out.println("[After] 响应已过滤");
// 返回新的响应(可以包装或修改)
return new AdvisedResponse(response.response(), response.advisedRequest());
}
}二、日志记录 Advisor
下面是我们将要实现的日志记录器。它会拦截每次调用,在调用前记录用户消息,调用后记录模型回复和耗时。
2.1完整代码
package com.studying.advisor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.model.Generation;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.MessageType;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
import java.util.Optional;
import java.util.stream.Collectors;
@Component
public class LoggingAdvisor implements CallAdvisor, StreamAdvisor {
private static final Logger log = LoggerFactory.getLogger(LoggingAdvisor.class);
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
long start = System.currentTimeMillis();
// 1. 只记录用户消息(过滤掉 system 提示词)
String userMessage = request.prompt().getInstructions().stream()
.filter(msg -> msg.getMessageType() == MessageType.USER)
.map(msg -> msg.getText())
.collect(Collectors.joining("\n"));
log.info("[AI调用] 用户消息: {}", userMessage);
// 2. 继续执行后续 Advisor 及实际模型调用
ChatClientResponse response = chain.nextCall(request);
// 3. 记录模型回复及耗时
long elapsed = System.currentTimeMillis() - start;
String aiReply = response.chatResponse().getResult().getOutput().getText();
log.info("[AI调用] 模型回复({}ms): {}", elapsed, aiReply);
return response;
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest request, StreamAdvisorChain chain) {
long start = System.currentTimeMillis();
String userMessage = request.prompt().getInstructions().stream()
.filter(msg -> msg.getMessageType() == MessageType.USER)
.map(msg -> msg.getText())
.collect(Collectors.joining("\n"));
log.info("[AI流式调用] 用户消息: {}", userMessage);
StringBuilder fullResponse = new StringBuilder();
return chain.nextStream(request)
.doOnNext(response -> Optional.ofNullable(response.chatResponse())
.map(ChatResponse::getResult)
.map(Generation::getOutput)
.map(AssistantMessage::getText)
.ifPresent(fullResponse::append))
.doOnComplete(() -> {
long elapsed = System.currentTimeMillis() - start;
log.info("[AI流式调用] 模型回复({}ms): {}", elapsed, fullResponse);
});
}
@Override
public String getName() {
return "LoggingAdvisor";
}
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE; // 最先执行,保证耗时包含所有后续环节
}
}2.2关键点解析
-
adviseCall方法-
记录开始时间戳。
-
从
request.prompt()获取用户消息(getContents()会返回当前对话中所有消息拼接后的文本,方便记录)。 -
调用
chain.nextCall(request)继续执行链路(可能还有其他 Advisor 或最终模型调用)。 -
从响应中提取模型回复文本,并对过长内容做截断处理(避免日志爆炸)。
-
计算总耗时并打印。
-
-
adviseStream方法-
流式调用本质返回
Flux<ChatClientResponse>,因此我们需要借助 Project Reactor 的doOnComplete钩子来记录完整耗时。 -
同样在开始时记录用户消息,在流结束时打印耗时。
-
-
执行顺序
getOrder()返回HIGHEST_PRECEDENCE(最小 order 值),确保日志 Advisor 最先执行,从而记录的耗时能包含整个调用链(包括其他 Advisor 的逻辑)。
2.3将 Advisor 注册到 ChatClient
有了 Advisor,我们还需要它真正生效。最佳实践是在构建 ChatClient Bean 时通过 defaultAdvisors(...) 注册。
下面是一个 REST Controller 示例:
package com.jichi.springai.controller;
import com.jichi.springai.advisor.LoggingAdvisor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/logging-advisor")
public class LoggingAdvisorController {
private final ChatClient chatClient;
public LoggingAdvisorController(ChatClient.Builder builder, LoggingAdvisor loggingAdvisor) {
this.chatClient = builder
.defaultSystem("你是一个 Java 技术助手")
.defaultAdvisors(loggingAdvisor) // 关键:注册日志 Advisor
.build();
}
@GetMapping
public String chat(@RequestParam String message) {
return chatClient.prompt()
.user(message)
.call()
.content();
}
}说明:
defaultAdvisors可以接受多个 Advisor,它们会按getOrder()排序后依次执行。这里我们只注册了LoggingAdvisor。
2.4测试效果
启动 Spring Boot 应用,使用 curl 发送请求:
curl "http://localhost:8080/api/logging-advisor?message=什么是Spring AI"控制台将输出类似下面的日志:
[AI调用] 用户消息: 什么是Spring AI
[AI调用] 模型回复(1243ms): Spring AI 是一个用于构建 AI 应用的 Java 框架...如果使用流式接口(需要额外定义 stream 端点,原理相同),则会输出:
[AI流式调用] 用户消息: 讲个笑话
[AI流式调用] 完成,小狗爱吃猫咪...耗时 872ms三、限流 Advisor
3.1为什么要限流?
大模型调用通常涉及:
-
昂贵的计算资源(GPU/TPU)
-
按 token 计费的 API 成本
-
共享的服务能力(多用户场景)
如果没有限流措施,恶意用户或 bug 程序可能短时间内发起大量请求,导致:
-
服务响应变慢甚至 OOM
-
账单激增(尤其是按量付费的外部模型)
-
影响其他正常用户的体验
传统的做法是在 Controller 层硬编码限流逻辑,但这种方式与业务混合、复用性差。使用 Advisor 可以将限流抽离为独立的能力,按需添加到任何 ChatClient 上。
3.2 Guava RateLimiter 简介
Google Guava 提供的 RateLimiter 基于令牌桶算法(Token Bucket):
-
以固定的速率往桶里添加令牌。
-
每个请求需要获取一个令牌才能继续执行。
-
如果没有令牌,可以选择阻塞等待(
acquire())或快速失败(tryAcquire())。
对于 REST API 限流,通常采用快速失败模式,直接返回错误提示,避免线程阻塞。
3.3实现 RateLimitAdvisor
我们将在之前 LoggingAdvisor 的基础上,新增一个限流 Advisor。为了让示例清晰,这里给出完整的独立实现。
3.3.1添加依赖(pom.xml)
https://mvnrepository.com/artifact/com.google.guava/guava
引入当前最新的依赖 ---> 33.6.0-jre
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.6.0-jre</version>
</dependency>3.3.2 RateLimitAdvisor 完整代码
package com.studying.advisor;
import com.google.common.util.concurrent.RateLimiter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@Component
@Slf4j
public class RateLimitAdvisor implements CallAdvisor {
// 每个用户每秒最多 x 次调用(自定义)
private static final double PERMITS_PER_SECOND = 0.1;
private final Map<String, RateLimiter> limiters = new ConcurrentHashMap<>();
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
log.info("进入 RateLimitAdvisor");
// 从 context 中获取 userId(由调用方通过 .advisors(a -> a.param("userId", userId)) 传入)
String userId = (String) request.context()
.getOrDefault("userId", "anonymous");
// 为每个用户创建独立的 RateLimiter
RateLimiter limiter = limiters.computeIfAbsent(userId,
k -> RateLimiter.create(PERMITS_PER_SECOND));
// 非阻塞获取令牌,拿不到立即抛出异常
if (!limiter.tryAcquire()) {
throw new RuntimeException("请求过于频繁,请稍后再试");
}
// 放行,继续执行后续 Advisor 或模型调用
return chain.nextCall(request);
}
@Override
public String getName() {
return "RateLimitAdvisor";
}
@Override
public int getOrder() {
return 10; // 在日志 Advisor(order=HIGHEST_PRECEDENCE)之后执行,但在其他业务 Advisor 之前
}
}3.3.3关键点说明
-
用户标识隔离
使用ConcurrentHashMap<String, RateLimiter>存储每个用户的限流器,确保不同用户互不影响。 -
非阻塞限流
tryAcquire()立即返回true/false,避免线程等待。若获取失败,抛出RuntimeException(可自定义业务异常),由 Spring 统一异常处理器返回 429 Too Many Requests。 -
从
request.context()获取参数
Spring AI 的Advisor可以通过chatClient.prompt().advisors(a -> a.param("key", value))传递上下文参数,这些参数最终会出现在ChatClientRequest.context()中。这让我们无需修改原有方法签名即可传递动态数据(如 userId)。 -
执行顺序
getOrder()返回10,大于LoggingAdvisor的HIGHEST_PRECEDENCE(即Integer.MIN_VALUE)。这意味着日志记录会先执行(包容整个调用链),限流紧随其后。顺序很重要:如果限流先执行且被拒绝,日志中就不会有这条失败的记录,可能不利于排查。通常建议日志最优先。
3.4在 Controller 中使用并传递 userId
为了演示限流效果,我们需要一个能够传入 userId 的端点。下面是一个示例 Controller:
package com.jichi.springai.controller;
import com.jichi.springai.advisor.RateLimitAdvisor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/rate-limit")
public class RateLimitController {
private final ChatClient chatClient;
public RateLimitController(ChatClient.Builder builder, RateLimitAdvisor rateLimitAdvisor) {
this.chatClient = builder
.defaultSystem("你是一个 Java 技术助手")
.defaultAdvisors(rateLimitAdvisor) // 注册限流 Advisor
.build();
}
@GetMapping
public String chat(@RequestParam String message,
@RequestParam(defaultValue = "anonymous") String userId) {
return chatClient.prompt()
.user(message)
.advisors(a -> a.param("userId", userId)) // 关键:将 userId 传递给 Advisor
.call()
.content();
}
}注意:如果你同时想使用日志 Advisor,可以在 builder.defaultAdvisors(loggingAdvisor, rateLimitAdvisor) 中传入多个,它们会按 getOrder() 自动排序。
3.5测试限流效果
启动应用后,用 curl 模拟同一个用户的快速连续请求:
# 第一次请求 —— 应该成功
curl "http://localhost:8080/api/rate-limit?message=你好&userId=user001"
# 立即再次请求 —— 大概率被限流,返回错误
curl "http://localhost:8080/api/rate-limit?message=你好&userId=user001"第二次请求的响应会包含异常信息(例如 "请求过于频繁,请稍后再试"),控制台可以看到对应的堆栈。
如果想测试并发场景,可以用 & 在后台同时发送多个请求(Linux/Mac):
curl "http://localhost:8080/api/rate-limit?message=你好&userId=user001" &
curl "http://localhost:8080/api/rate-limit?message=你好&userId=user001" &你会发现最多只有 2 个请求成功(因为每秒 2 个令牌),多余的会立即失败。
3.6进阶思考:与日志 Advisor 组合
在实际项目中,我们往往同时需要日志和限流功能。两者可以轻松共存:
// 在 Controller 中同时注册
this.chatClient = builder
.defaultSystem("你是一个助手")
.defaultAdvisors(loggingAdvisor, rateLimitAdvisor) // 顺序按 order 值升序执行
.build();执行流程:
-
LoggingAdvisor记录请求开始时间。 -
RateLimitAdvisor检查令牌,如果不通过则抛异常。 -
若通过,继续调用模型。
-
LoggingAdvisor在chain.nextCall()返回后记录耗时和响应。
如果限流触发异常,日志 Advisor 仍会记录开始消息,但不会记录结束消息(因为异常抛出,没有正常返回)。为了更健壮的日志,可以在 LoggingAdvisor 中添加 try-finally 或使用 @Around 风格的环绕逻辑,这点留给读者作为练习。
四、敏感词过滤 Advisor
4.1为什么需要内容安全 Advisor?
大模型本质上是“基于统计的文本生成器”,它的输出无法保证 100% 符合企业的安全标准。常见风险包括:
-
用户输入含有政治敏感、色情、暴力等违禁词。
-
模型回复中意外泄露内部数据或产生有害建议。
-
需要满足国家法律法规(如《网络安全法》)、App Store 审核等要求。
传统的做法是在 Controller 层手动校验,但每个调用接口都要写重复代码。利用 Advisor,我们可以在请求进入模型之前和响应返回用户之前进行双重检查,实现一次编写、全局生效。
4.2实现 ContentSafetyAdvisor
下面的 ContentSafetyAdvisor 同时检查用户输入和模型输出。如果发现敏感词,它会直接返回一条安全提示,而不会真正调用模型(或替换掉模型的实际输出)。
完整代码
package com.studying.advisor;
import org.apache.commons.lang3.StringUtils;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.MessageType;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.model.Generation;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class ContentSafetyAdvisor implements CallAdvisor {
// 实际项目可以对接阿里云内容安全、腾讯云天御等服务
private static final List<String> BLOCKED_KEYWORDS = List.of(
"违禁词1", "违禁词2"
);
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// 1. 检查输入
String userMessage = request.prompt().getInstructions().stream()
.filter(msg -> msg.getMessageType() == MessageType.USER)
.map(msg -> msg.getText())
.collect(Collectors.joining("\n"));
if (containsBlockedContent(userMessage)) {
// 拦截,返回一个"安全"的响应,不真正调用模型
return buildSafeResponse(request, "您的输入包含不当内容,请重新输入。");
}
// 2. 正常调用
ChatClientResponse response = chain.nextCall(request);
// 3. 检查输出
String aiContent = response.chatResponse().getResult().getOutput().getText();
if (containsBlockedContent(aiContent)) {
// 模型输出了不当内容,替换
return buildSafeResponse(request, "内容审核未通过,请换个问题试试。");
}
return response;
}
private boolean containsBlockedContent(String text) {
if (StringUtils.isBlank(text)) {
return false;
}
return BLOCKED_KEYWORDS.stream().anyMatch(text::contains);
}
private ChatClientResponse buildSafeResponse(ChatClientRequest request, String message) {
// 构造一个假的 ChatResponse 返回
//模拟模型的回复文本
AssistantMessage assistantMessage = new AssistantMessage(message);
//Spring AI 中一次生成结果的包装
Generation generation = new Generation(assistantMessage);
//包装了整个模型响应,List.of(generation) 表示这次只生成了一段内容
ChatResponse chatResponse = new ChatResponse(List.of(generation));
return ChatClientResponse.builder()
.chatResponse(chatResponse)
.context(request.context()) //将原始请求的上下文透传,保证后续 Advisor 能拿到同样的参数(比如 userId)
.build();
}
@Override
public String getName() {
return "ContentSafetyAdvisor";
}
@Override
public int getOrder() {
return 5; // 在限流之后、日志之后执行(根据实际需要调整)
}
}核心逻辑解析
-
输入检查
调用request.prompt().getContents()获取用户拼接后的文本,然后检查是否包含任何违禁词。如果命中,立即通过buildSafeResponse()返回一个定制的安全提示,不再执行chain.nextCall(request),从而跳过真实的模型调用和后续 Advisor。 -
输出检查
只有当输入安全时,才会调用模型。得到响应后,提取response.chatResponse().getResult().getOutput().getText()并再次进行敏感词检测。如果输出违规,同样使用安全提示替换原始响应。 -
构造假响应
buildSafeResponse()方法手写了一个ChatResponse对象,其中包含一个AssistantMessage和Generation。这种技巧可以无缝替换真实响应,调用方(Controller)完全感知不到异常,只会收到一条文本提示。 -
执行顺序
getOrder()返回5,介于限流(order=10)和日志(order=HIGHEST_PRECEDENCE)之间。通常建议的顺序是:日志 → 内容安全 → 限流 → 其他业务 Advisor。因为安全检查和限流都需要在真实调用前完成,但日志应该记录最原始的信息
4.3挂载 Advisor
和之前一样,通过 ChatClient.Builder 的 defaultAdvisors 注册:
package com.jichi.springai.controller;
import com.jichi.springai.advisor.ContentSafetyAdvisor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/content-safety")
public class ContentSafetyController {
private final ChatClient chatClient;
public ContentSafetyController(ChatClient.Builder builder,
ContentSafetyAdvisor contentSafetyAdvisor) {
this.chatClient = builder
.defaultSystem("你是一个 Java 技术助手")
.defaultAdvisors(contentSafetyAdvisor) // 挂载内容安全 Advisor
.build();
}
@GetMapping
public String chat(@RequestParam String message) {
return chatClient.prompt()
.user(message)
.call()
.content();
}
}4.4测试效果
启动应用,用 curl 分别测试正常请求和被拦截的请求。
4.4.1 正常请求(不包含敏感词)
curl "http://localhost:8080/api/content-safety?message=什么是Spring AI"正常返回模型生成的答案。
4.4.2 触发输入拦截(包含屏蔽词)
curl "http://localhost:8080/api/content-safety?message=违禁词1怎么用"返回:
您的输入包含不当内容,请重新输入。4.4.3 如果模型意外输出敏感词(可以通过 prompt 注入触发)
会返回预设的“内容审核未通过”提示。
4.5扩展:对接专业内容安全服务
示例中使用的是内存中的静态敏感词列表。在生产环境,你应该对接专业的云服务,例如:
-
阿里云内容安全:支持文本、图片、视频,每日亿级调用。
-
腾讯云天御:提供敏感词库、自定义词库、垃圾文本识别。
-
开源方案:如
SensitiveWords项目。
对接方式非常简单,只需要在 containsBlockedContent 方法中调用远程 API 或本地 Trie 树匹配即可。例如:
private boolean containsBlockedContent(String text) {
// 调用阿里云 SDK
return aliyunGreenClient.textScan(text).isViolation();
}4.6与其它 Advisor 的协作
如果你同时使用了日志、限流和内容安全三个 Advisor,推荐如下顺序配置:
this.chatClient = builder
.defaultAdvisors(loggingAdvisor, contentSafetyAdvisor, rateLimitAdvisor)
.build();对应的 getOrder() 值建议:
-
LoggingAdvisor:Integer.MIN_VALUE(最先执行) -
ContentSafetyAdvisor:5 -
RateLimitAdvisor:10
4.7流式调用的挑战与提示
本文示例仅实现了 CallAdvisor(一次性调用)。对于流式调用(StreamAdvisor),内容安全检查会更复杂,因为输出是分片到达的。一个常见的策略是:
-
在
adviseStream中,累积所有片段成一个完整的文本。 -
当流结束时,对整个文本进行审核。
-
如果发现违规,则丢弃已发送的片段并发送错误提示。
(这需要配合Flux的doOnNext缓存和onErrorResume处理)
实际项目中,也可以选择只对输入做流式拦截,而输出检查切换到同步模式。这部分内容将在后续文章中展开。
五、Token 用量统计 Advisor
5.1为什么要统计 Token 用量?
无论你是使用 OpenAI、Azure OpenAI 还是国内的智谱、通义千问等模型,几乎都按照 Token 数量 计费:
-
Prompt Token:用户输入消耗的 Token(通常费率较低)。
-
Completion Token:模型生成内容消耗的 Token(费率较高)。
-
总 Token = Prompt + Completion。
如果没有用量统计,你可能面临:
-
月底账单来了却不知道是哪个用户消耗了大量 Token。
-
无法设置配额限制,导致恶意刷单造成巨额费用。
-
缺乏数据支撑来优化 Prompt(减少不必要的输入 Token)。
-
无法向客户提供详细的使用报表。
Spring AI 的 ChatResponse 中已经内置了 Usage 信息(前提是模型提供商返回了用量数据)。我们只需要在响应返回之前“偷看”一下这个数据,并累计到用户维度的计数器里即可。
5.2实现 TokenUsageAdvisor
下面的 TokenUsageAdvisor 实现了 CallAdvisor,它会在模型调用完成后提取 ChatResponse 中的 Usage,并按 userId 累加到内存中的 ConcurrentHashMap。
完整代码
package com.jichi.springai.advisor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.LongAdder;
@Component
public class TokenUsageAdvisor implements CallAdvisor {
private static final Logger log = LoggerFactory.getLogger(TokenUsageAdvisor.class);
// 内存中统计各用户累计 Token,生产环境换成数据库或 Redis
private final ConcurrentHashMap<String, LongAdder> userTokenCount = new ConcurrentHashMap<>();
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// 1. 调用后续 Advisor 和模型(必须调用,否则得不到响应)
ChatClientResponse response = chain.nextCall(request);
// 2. 从响应中提取 Token 用量
ChatResponse chatResponse = response.chatResponse();
if (chatResponse != null
&& chatResponse.getMetadata() != null
&& chatResponse.getMetadata().getUsage() != null) {
var usage = chatResponse.getMetadata().getUsage();
String userId = (String) request.context()
.getOrDefault("userId", "anonymous");
long total = usage.getTotalTokens() != null ? usage.getTotalTokens() : 0L;
// 累计该用户的 Token 用量(线程安全)
userTokenCount.computeIfAbsent(userId, k -> new LongAdder()).add(total);
log.info("[Token统计] userId={}, 本次 prompt={}, completion={}, total={}, 累计={}",
userId,
usage.getPromptTokens(),
usage.getCompletionTokens(),
total,
userTokenCount.get(userId).sum());
}
return response;
}
/** 查询某用户的累计 Token 消耗(供 Controller 调用) */
public long getTotalTokens(String userId) {
LongAdder adder = userTokenCount.get(userId);
return adder != null ? adder.sum() : 0L;
}
@Override
public String getName() {
return "TokenUsageAdvisor";
}
@Override
public int getOrder() {
return 20; // 最后执行,确保拿到完整响应(在所有修改响应的 Advisor 之后)
}
}代码解析
-
数据存储:使用
ConcurrentHashMap<String, LongAdder>存储每个用户的累计 Token。LongAdder是比AtomicLong更适合高并发累加场景的计数器,效率更高。 -
提取 Token 信息:
response.chatResponse().getMetadata().getUsage()返回一个Usage对象,包含:-
getPromptTokens():输入 Token 数 -
getCompletionTokens():输出 Token 数 -
getTotalTokens():总 Token 数
-
-
用户标识:通过
request.context().get("userId")获取,需要调用方通过.advisors(a -> a.param("userId", userId))传递(与限流 Advisor 相同)。 -
执行顺序:
getOrder()返回20,确保它在最后执行。这是因为:-
如果之前有内容安全 Advisor 替换了响应(
buildSafeResponse),那个响应中很可能没有Usage信息,我们不希望统计错误的零值。 -
让它在所有可能修改响应的 Advisor 之后执行,保证拿到的是真正发给用户的最终响应(及其用量)。
-
-
日志输出:每次调用后打印本次消耗和累计值,方便实时观察。
5.3在 Controller 中使用并暴露统计端点
为了演示,我们创建一个 TokenUsageController,它有两个端点:
-
/api/token-usage:普通聊天接口,需要传入userId。 -
/api/token-usage/stats:查询某个用户的累计 Token 消耗。
package com.jichi.springai.controller;
import com.jichi.springai.advisor.TokenUsageAdvisor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/token-usage")
public class TokenUsageController {
private final ChatClient chatClient;
private final TokenUsageAdvisor tokenUsageAdvisor;
public TokenUsageController(ChatClient.Builder builder,
TokenUsageAdvisor tokenUsageAdvisor) {
this.tokenUsageAdvisor = tokenUsageAdvisor;
this.chatClient = builder
.defaultSystem("你是一个 Java 技术助手")
.defaultAdvisors(tokenUsageAdvisor) // 挂载 Token 统计 Advisor
.build();
}
@GetMapping
public String chat(@RequestParam String message,
@RequestParam(defaultValue = "anonymous") String userId) {
return chatClient.prompt()
.user(message)
.advisors(a -> a.param("userId", userId)) // 传 userId 给 Advisor
.call()
.content();
}
/** 查询某用户累计消耗的 Token 数 */
@GetMapping("/stats")
public String stats(@RequestParam String userId) {
long total = tokenUsageAdvisor.getTotalTokens(userId);
return String.format("用户 %s 累计消耗 Token:%d", userId, total);
}
}5.4测试验证
启动应用后,用 curl 模拟两个用户的不同请求。
1. 用户 user001 发起两次对话
curl "http://localhost:8080/api/token-usage?message=什么是Spring AI&userId=user001"
curl "http://localhost:8080/api/token-usage?message=讲一下RAG&userId=user001"控制台输出:
[Token统计] userId=user001, 本次 prompt=25, completion=312, total=337, 累计=337
[Token统计] userId=user001, 本次 prompt=18, completion=256, total=274, 累计=6112. 查询 user001 累计消耗
curl "http://localhost:8080/api/token-usage/stats?userId=user001"返回:
用户 user001 累计消耗 Token:6113. 另一个用户 user002 调用
curl "http://localhost:8080/api/token-usage?message=你好&userId=user002"控制台输出:
[Token统计] userId=user002, 本次 prompt=12, completion=45, total=57, 累计=575.5进阶:流式调用的 Token 统计
对于流式调用(stream()),ChatResponse 并不是一次性返回的,而是分多次下发。Spring AI 在处理流式响应时,最后一个 ChatResponse 通常会包含完整的 Usage 信息(取决于具体实现)。要实现流式 Token 统计,可以同时实现 StreamAdvisor:
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest request, StreamAdvisorChain chain) {
return chain.nextStream(request)
.doOnNext(response -> {
// 尝试从每个 response 中提取 usage(通常只有最后一个包含)
ChatResponse chatResponse = response.chatResponse();
if (chatResponse != null && chatResponse.getMetadata() != null
&& chatResponse.getMetadata().getUsage() != null
&& chatResponse.getMetadata().getUsage().getTotalTokens() != null) {
// 累加逻辑(注意避免重复累加,可以用一个标志位)
}
});
}六、组合使用所有 Advisor
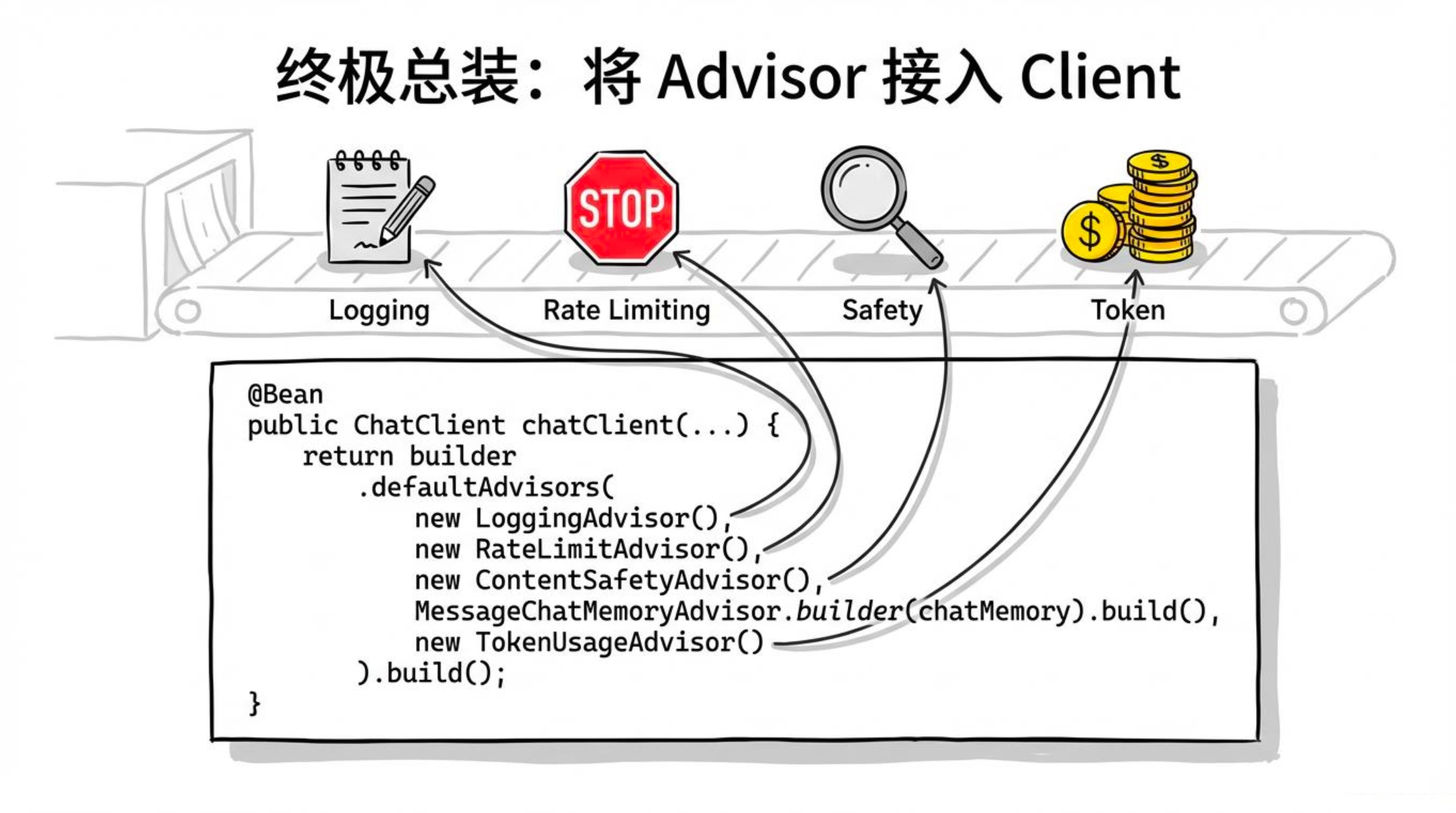
6.1为什么需要组合多个 Advisor?
一个成熟的生产级 AI 接口往往需要同时满足多个非功能性需求:
-
可观测性:记录每次调用的请求、响应和耗时(LoggingAdvisor)
-
稳定性:防止单个用户过度调用导致服务抖动(RateLimitAdvisor)
-
合规性:拦截输入/输出中的敏感内容(ContentSafetyAdvisor)
-
成本控制:统计每个用户的 Token 消耗,用于计费或配额管理(TokenUsageAdvisor)
-
体验优化:记住对话上下文,实现多轮连续对话(MessageChatMemoryAdvisor)
这些关注点相互独立,又需要协同工作。如果写在业务代码中,Controller 会变得臃肿不堪;而利用 Advisor 的组合能力,我们可以像搭积木一样按需组装,并且任意调整顺序。
6.2完整代码:FullAdvisorController
下面的控制器同时注册了五个 Advisor(四个自定义 + 一个框架内置),并展示了如何通过运行时参数传递 userId 和 conversationId。
package com.jichi.springai.controller;
import com.jichi.springai.advisor.LoggingAdvisor;
import com.jichi.springai.advisor.RateLimitAdvisor;
import com.jichi.springai.advisor.ContentSafetyAdvisor;
import com.jichi.springai.advisor.TokenUsageAdvisor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/full-advisor")
public class FullAdvisorController {
private final ChatClient chatClient;
private final MessageWindowChatMemory chatMemory;
private final TokenUsageAdvisor tokenUsageAdvisor;
public FullAdvisorController(
ChatClient.Builder builder,
RateLimitAdvisor rateLimitAdvisor,
ContentSafetyAdvisor contentSafetyAdvisor,
TokenUsageAdvisor tokenUsageAdvisor) {
this.tokenUsageAdvisor = tokenUsageAdvisor;
// 创建对话记忆:保留最近 10 条消息
this.chatMemory = MessageWindowChatMemory.builder().maxMessages(10).build();
this.chatClient = builder
.defaultSystem("你是一个 Java 技术助手")
.defaultAdvisors(
new LoggingAdvisor(), // order = HIGHEST_PRECEDENCE
rateLimitAdvisor, // order = 10
contentSafetyAdvisor, // order = 5
tokenUsageAdvisor // order = LOWEST_PRECEDENCE
)
.build();
}
@GetMapping
public String chat(
@RequestParam String message,
@RequestParam(defaultValue = "anonymous") String userId,
@RequestParam(defaultValue = "default") String conversationId) {
return chatClient.prompt()
.user(message)
// 传递 userId 给限流和 Token 统计 Advisor
.advisors(a -> a.param("userId", userId))
// 动态添加对话记忆 Advisor(每次请求单独绑定 conversationId)
.advisors(MessageChatMemoryAdvisor.builder(chatMemory)
.conversationId(conversationId)
.build())
.call()
.content();
}
/** 查询某用户累计 Token 消耗 */
@GetMapping("/token-usage")
public String tokenUsage(@RequestParam String userId) {
long total = tokenUsageAdvisor.getTotalTokens(userId);
return String.format("用户 %s 累计消耗 Token:%d", userId, total);
}
}6.3各 Advisor 的作用回顾及顺序设置
6.3.1 执行顺序(按 getOrder() 从小到大)
| Advisor | order 值 | 作用 |
|---|---|---|
LoggingAdvisor |
Integer.MIN_VALUE(最高优先级) |
记录调用开始、结束和总耗时 |
ContentSafetyAdvisor |
5 |
检查用户输入是否包含敏感词 |
RateLimitAdvisor |
10 |
对用户进行令牌桶限流 |
MessageChatMemoryAdvisor |
(框架默认,约 1000) | 加载历史消息并保存本轮对话 |
TokenUsageAdvisor |
Integer.MAX_VALUE(最低优先级) |
提取 Token 用量并累计 |
为什么这样排序?
-
日志在最前:可以记录整个调用链的耗时,包括所有后续 Advisor 的处理时间。
-
内容安全在限流之前:如果输入已经违规,直接返回拦截提示,无需消耗令牌,也不占用限流配额。同时避免对恶意内容进行无意义的限流计数。
-
限流在记忆和模型调用之前:在真正消耗资源(加载历史、调用模型)前快速拒绝超频请求,节省系统开销。
-
记忆在 Token 统计之前:记忆 Advisor 会修改请求(添加历史消息),Token 统计应该基于最终发给模型的完整 Prompt 用量,因此要放在记忆之后。
-
Token 统计在最后:确保拿到的
ChatResponse是最终返回给用户的响应,并且包含了准确的用量信息(不被其他 Advisor 修改或丢失)。
6.3.2 建议的顺序:
- 日志(
HIGHEST_PRECEDENCE):记录完整的调用耗时 - 限流:快速拦截超频请求,避免浪费
- 内容安全:输入检查
- 对话记忆:注入历史消息
- RAG:注入检索到的相关内容
- Token 统计(
LOWEST_PRECEDENCE):统计完整的 Token 消耗
6.3.3 对话记忆的特殊性
MessageChatMemoryAdvisor 不是通过 defaultAdvisors 静态注册的,而是在每次请求时通过 .advisors(...) 动态添加,并传入 conversationId。这样做的好处是:
-
不同用户可以拥有独立的会话空间。
-
同一个用户可以开启多个会话(例如
conversationId=session001和session002)。 -
避免在全局 Builder 中绑定固定的记忆实现,提高灵活性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)