【LangGraph】跨会话持久化(Store)——让 Agent 记住你的长期偏好
【LangGraph】新篇章:LangGraph 持久化(Persistence)*重点*
上一章-> 【LangGraph】线程级持久化深度实战(PostgreSQL + 重放机制)
前言
上一章我们介绍了线程级持久化(thread_id),它可以让 Agent 在同一会话内记住对话历史,回答 “我刚才问了什么”这类问题
但它有一个明显的局限:换一个 thread_id 就全忘了
比如:
当线程 thread_id = 1111:你说“我是小猫,我喜欢吃芝士汉堡”
切换到线程 thread_id = 2222:你问“我喜欢吃什么?”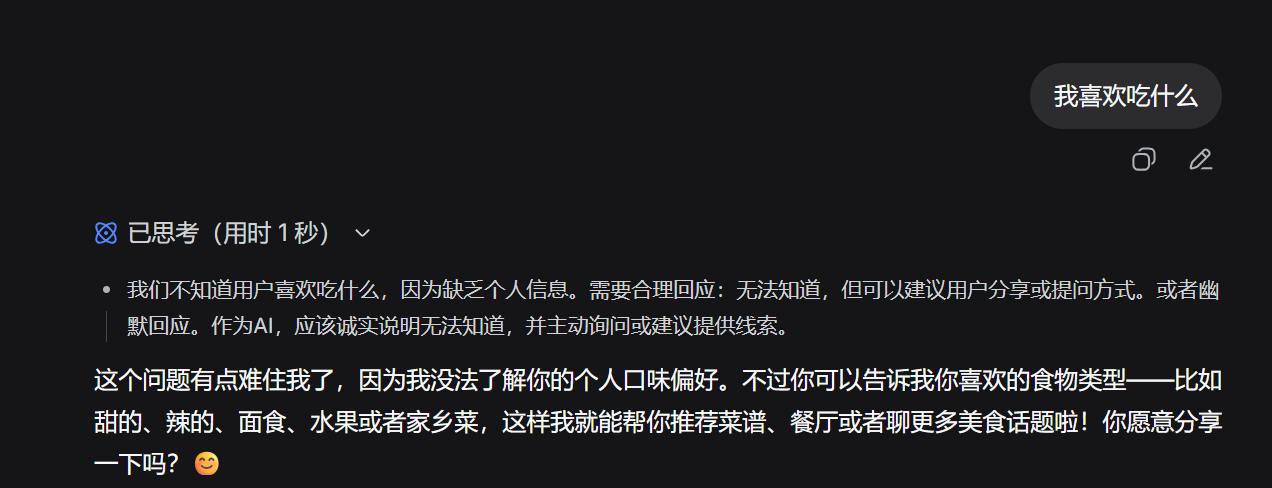
Agent 回答:“我不知道”
这在真实场景中显然不够用,我们希望 AI 能跨会话记住:
-
用户的姓名、年龄、职业
-
用户的偏好(喜欢吃什么、讨厌什么)
-
用户的健康信息(病史、过敏史)
这就是跨会话持久化(Store)要解决的问题
一、为什么需要 Store?
简单来说:
我们之前学习了线程级持久化,
线程级持久化(Checkpointer):让 Agent 拥有短期记忆,局限于一次会话
而跨会话持久化(Store):让 Agent 拥有长期记忆,可以在不同会话之间共享
目标:让 AI 像一个真正了解你的助手,而不是每次见面都像陌生人
举个例子:
Checkpointer = 一张便签纸,每次对话结束后就扔掉,下一次对话拿一张新白纸
Store = 一个笔记本,专门记录关于用户的“硬信息”,每次新会话都翻看这个笔记本,并根据新对话补充或修改
二、核心概念:Store vs Checkpointer
- Checkpointer 与 Store 核心区别
| 能力 | Checkpointer | Store |
|---|---|---|
| 作用 | 保存 Graph 运行状态(State) | 保存长期业务数据 |
| 粒度 | 会话级:thread_id 维度 |
业务级:通常 user_id 维度 |
| 生命周期 | 仅会话期间有效 | 永久存储、跨会话复用 |
| 典型内容 | 对话历史、节点状态、工具调用中间结果 | 用户画像、个人偏好、业务知识库、档案数据 |
| 写入方式 | 框架自动每步快照保存 | 业务主动调用 put() 写入 |
总结一下:
-
Checkpointer = 短期记忆(“你刚才说了什么”)
-
Store = 长期记忆(“你一直以来喜欢什么”)
三、核心设计:两步走
实现跨会话记忆通常分为两步:
-
提取:在对话中,用 LLM 从用户消息里抽取出结构化信息(如姓名、身高、喜好)
-
存储:将提取出的信息存入 Store,按 user_id 分类
在后续对话中,无论 thread_id 如何变化,只要 user_id 相同,Agent 就能从 Store 中读取这些信息,并注入到 Prompt 中,从而“记住”用户
四、结构化信息提取(关键设计)
直接存储原始对话文本会非常低效且难以检索
更好的做法是让 LLM 抽取出结构化数据
例如,定义一个 Person 模型:
from typing import Optional, List
from pydantic import BaseModel
class Person(BaseModel):
name: Optional[str]
height: Optional[str]
favorite: Optional[List[str]]
然后在某个节点中,用带有结构化输出的模型来提取:
model_with_tool=model.bind_tools(tools)
# 定义结构化输出模型
model_with_structured=model.with_structured_output(Person)
# 1.状态
class MessagesState(TypedDict):
# 定义消息
messages:Annotated[list[AnyMessage],operator.add]
# 调用大模型次数
llm_calls:int
# llm_calls:Annotated[int,operator.add]
# 2.定义节点
# 节点1
def extract_person(state:MessagesState,config:RunnableConfig,*,store:BaseStore):
"""LLM决定是否调用工具"""
people_info=model_with_structured.invoke(
[
SystemMessage(content="你是⼀个提取信息的专家,只从⽂本中提取我的相关信息,"
"不能提取别⼈的信息。如果你不知道要提取的属性的值,属性值返回null。")
] + state["messages"][-3:]
)
通过这种方式,用户的自然语言输入:
“我叫小猫,身高183,我喜欢吃芝士汉堡”
被自动转化为:
json
{
"name": "小猫",
"height": "183",
"favorite": ["芝士汉堡"]
}
五、写入 Store:命名空间设计
Store 使用命名空间(namespace)来组织数据。典型的做法是按 user_id 和类别划分:
user_id=config["configurable"]["user_id"]
namespace1=(user_id,"info")
user_id = config["configurable"]["user_id"]
namespace2 = (user_id, "pre")```
写入数据时使用 put 方法:
```python
# 写入基本信息
store.put(
namespace1,
str(uuid.uuid4()),
{
"name":people_info.name,
"height":people_info.height,
}
)
# 写入偏好
store.put(
namespace2,
str(uuid.uuid4()),
{
"favorite":people_info.favorite
}
)
return {
"llm_calls":state.get("llm_calls",0)+1
}
Store 采用“日志型存储”——每次 put 都会添加一条新记录,保留历史变更
读取时通常取最新的(limit=1)
六、读取 Store
在每次调用 LLM 之前,从 Store 中读取用户信息,并拼接到系统提示词中:
def llm_call(state:MessagesState,config:RunnableConfig,*,store:BaseStore):
user_id = config["configurable"]["user_id"]
namespace1 = (user_id, "info")
namespace2 = (user_id, "pre")
info_result=store.search(namespace1,limit=1)
pre_result=store.search(namespace2,limit=1)
print(info_result)
print(pre_result)
# messages 接受返回的所有消息HumanMessage、AIMessage、ToolMessage
messages=state["messages"]
# result 可能性1:有tool_call 的AImessage
# result 可能性2:无tool_call 的AImessage
result=model_with_tool.invoke(
[
SystemMessage(
content=f"你是⼀个乐于助⼈的助⼿,⽀持调⽤⼯具进⾏搜索。")
] +[HumanMessage(content= f"查询 LLM 前必须参考以下信息:"
f"1. ⽤⼾基本情况:{info_result[0].value} "
f"2. ⽤⼾偏好情况:{pre_result[0].value}")]
+messages
)
return {
"messages":[result],
"llm_calls":state.get("llm_calls",0)+1 #覆盖更新
}
通过这种方式,Agent 的每个回答都能“想起”用户的长期偏好
七、跨会话效果演示
第一次对话(建立长期记忆):
config1 = {
"configurable": {
"thread_id": "1111",
"user_id": "user_123"
}
}
agent.invoke(
{"messages": [HumanMessage(content="我叫小猫,183,我喜欢芝士汉堡")]},
config=config1
)
第二次对话(切换线程,但同一用户)
config2 = {
"configurable": {
"thread_id": "2222", # 不同的会话
"user_id": "user_123" # 相同的用户
}
}
agent.invoke(
{"messages": [HumanMessage(content="推荐一家餐厅")]},
config=config2
)
# Agent 会读取 Store 中的偏好,回答类似:
# “考虑到你喜欢芝士汉堡,推荐你去 XX 西餐厅...”
关键点:即使 thread_id 完全不同,只要 user_id 相同,Agent 就能跨会话调用长期记忆
八、进阶:Store + 对话压缩(Summary)
长时间的对话会导致 messages 列表无限膨胀,影响性能和成本。LangGraph 提供了对话压缩机制,配合 Store 可以实现更高效的长记忆
状态扩展:
class State(MessagesState):
summary: str # 存储历史摘要
在适当的时候(例如消息超过阈值),调用 LLM 生成摘要,并删除旧消息:
from langchain_core.messages import RemoveMessage
def summarize_conversation(state: State):
"""压缩历史对话,生成摘要"""
summary = state.get("summary", "")
if summary:
summary_messages=(
f"这是到⽬前为⽌的对话摘要:{summary}\n\n"
"基于上⾯的新消息扩展摘要:"
)
else:summary_messages="创建上面的对话摘要"
# 总结 消息列表+历史总结
messages=state["messages"]+[HumanMessage(content=summary_messages)]
result=model.invoke(messages)
return {
"summary":result.content,
"messages":[RemoveMessage(id=m.id)for m in state["messages"][:-1]]
}
组合效果
-
短期记忆:最近几条消息(保留细节)
-
压缩记忆:历史摘要(保留关键信息)
-
长期记忆:Store 中的用户画像(跨会话)
三者结合,Agent 可以在极低的 token 成本下,同时拥有细节、结构和长期偏好
九、系统架构图
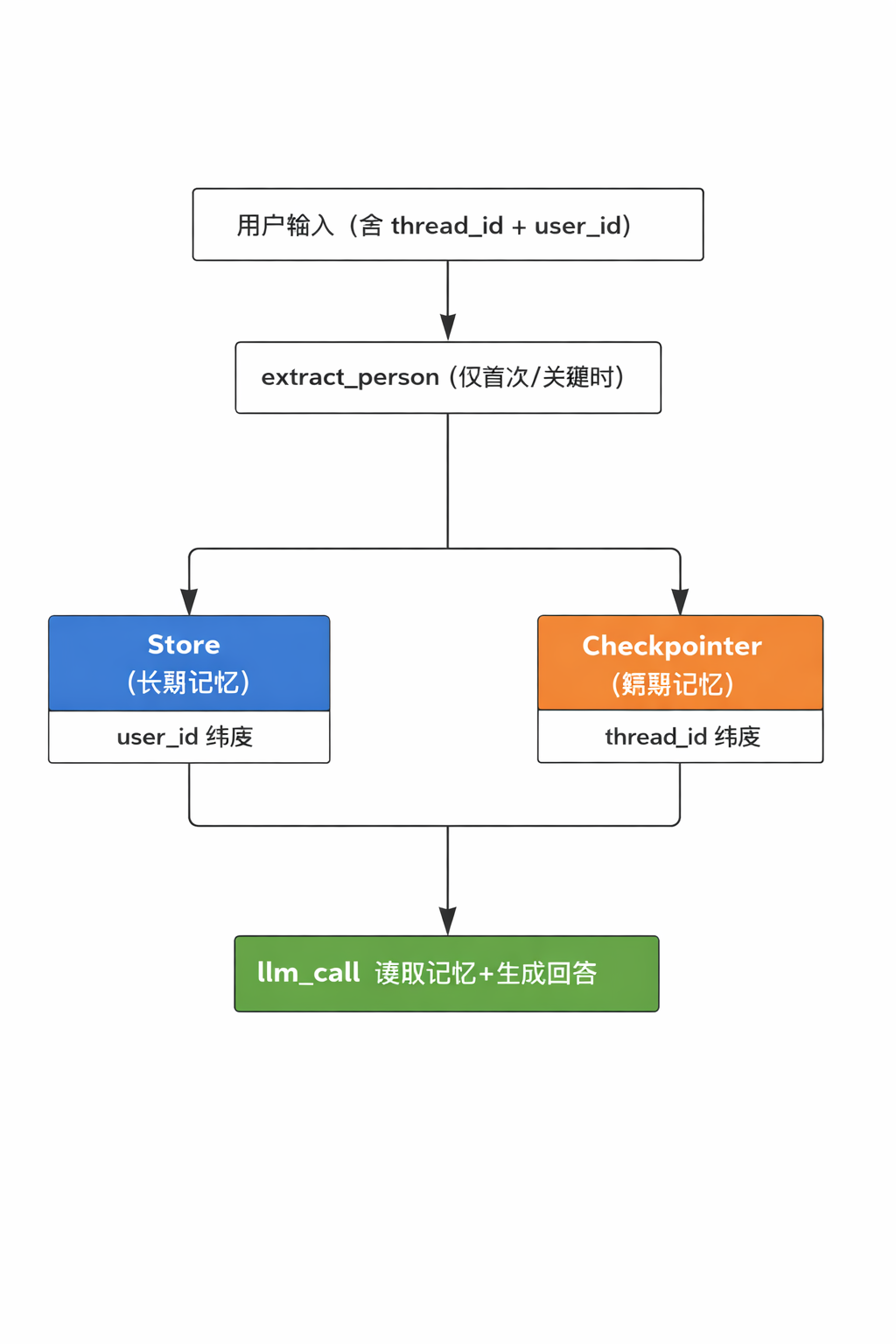
十、总结
——>为什么需要 Store?
Checkpointer(短期记忆):记住一次会话内的事情,会话结束就清零
像一次通话,挂了就忘
Store(长期记忆):记住跨会话的用户信息(如口味、偏好、姓名)
像专属笔记本,每次新会话都自动翻看,不会重头认识用户
核心目标:你的 Agent 不再只是一个“聊天机器人”,而是一个真正理解用户的智能助手
跨会话的持久化内容分享就到这了,下期将持久化的三大应用~拜拜

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)