爆火的 Skills 仓库:致力于把 Claude Code /CodeX 调教成顶级工程师
最近爆火的一个 Skills 开源仓库, GitHub 迅速冲到 33.9K 多星。
它不提供框架,不训练模型,也不承诺“一句话生成完整项目”。它做的事情更朴素:把一个成熟工程师每天会做的需求澄清、测试驱动、PRD、Issue 拆分、架构复盘,写成一组 AI Agent 能反复调用的工作流。
这个仓库叫 mattpocock/skills,地址是:https://github.com/mattpocock/skills
它为什么会被开发者迅速传播呢?
mattpocock/skills 到底是什么?
它是一套面向 AI 编程 Agent 的技能库。
它的作者是 Matt Pocock,在开发者圈子里,他最响亮的头衔是“TypeScript 魔法师”。
仓库描述很直接:这些是他每天用于真实工程的 Agent Skills。注意这里的关键词不是“提示词”,而是“技能”。
传统提示词更像一次性指令:你把一大段规则贴给模型,希望它这次表现好一点。Skill 则更像一个可复用的小模块:每个目录里有一个 SKILL.md,里面写清楚这个技能什么时候触发、该怎么工作、要遵守哪些流程,必要时还可以带上参考文档和脚本。
Anthropic 在 Agent Skills 里把这种设计称为 progressive disclosure,也就是“渐进式披露”:Agent 启动时只需要知道技能名称和描述;真正需要用到某个技能时,再读取完整说明;如果说明里还引用了更多资料,再按需加载。
这件事的意义很实际:你不用把所有工程规范都塞进一个巨大的 CLAUDE.md 或系统提示词里。你可以把复杂流程拆成一个个小技能,让 Agent 在合适的时候拿出来用。
这个仓库最有价值的,不是“会写代码”

很多 AI 编程工具的演示都喜欢跳到最后一步:生成代码、跑测试、提 PR。
但真实工程里,最容易出问题的往往不是“代码写不出来”,而是前面几步根本没想清楚:
需求是不是说完整了?
公共接口应该长什么样?
测试到底验证行为,还是锁死实现细节?
一个功能应该拆成几个可以独立交付的垂直切片?
代码库已经变成一团泥时,应该先动哪里?
mattpocock/skills 的聪明之处就在这里。它没有试图发明一个全能 Agent,而是把工程师本来就该做的动作,变成 Agent 可以遵循的流程。
比如 /grill-me 非常短,却抓住了一个关键点:在开工前,Agent 要围绕计划和设计持续提问,一次只问一个问题;如果问题能通过读代码回答,就不要打扰用户,自己去探索代码库。
这和很多“自动开干”的 Agent 习惯正好相反。它承认一个事实:软件开发最贵的错误,不是少写了几行代码,而是 Agent 很自信地做了用户并不想要的东西。
从想法到 PR,它给了一条完整链路
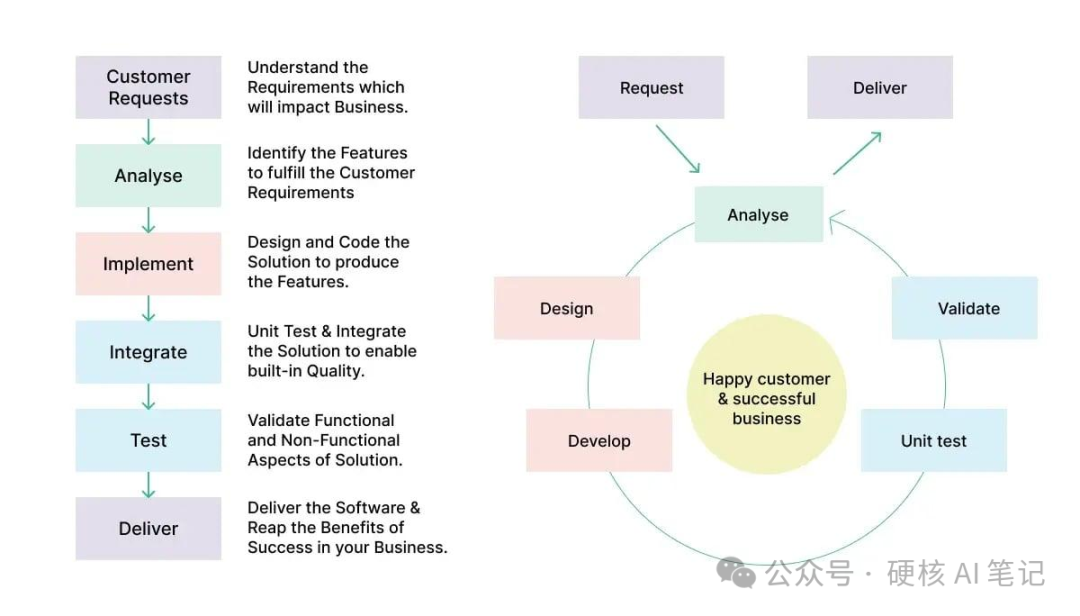
如果只看 README,当前仓库主要分成几类:工程类、效率类、杂项工具类,此外还有 deprecated 和 personal 目录。核心使用场景集中在 AI 编程工作流上。
最适合普通开发者先看的,是这一条链路:
第一步,用 grill-me 把需求问清楚。
不要急着让 Agent 写代码。先让它把设计树走一遍:有哪些约束、有哪些依赖、哪些决定会影响后面的实现。它不只是问问题,还要给出推荐答案。
第二步,用 to-prd 把上下文沉淀成 PRD。
这个技能不会重新采访用户,而是把当前对话和代码库理解整理成问题、方案、用户故事、实现决策、测试决策和非目标范围。它的价值是把一次聊天变成可追踪的工程文档。
第三步,用 to-issues 拆成垂直切片。
很多项目失败在“横向拆分”:先写一堆 schema,再写一堆接口,再写一堆 UI,最后才发现端到端跑不通。这个仓库强调 vertical slices,也就是每个 Issue 都尽量贯穿 schema、接口、UI、测试,形成一个能独立验证的小闭环。
第四步,用 tdd 进入红绿重构循环。
tdd 技能明确反对一次性写完所有测试再补实现。它要求一次只写一个失败测试,然后写最少代码让它通过,再进入下一个行为。测试应该验证公共接口和可观察行为,而不是内部实现细节。
第五步,用 improve-codebase-architecture 定期清理复杂度。
这个技能关注所谓 deep module:用更小的接口承载更多行为,把复杂度藏到正确的位置。它会先读 CONTEXT.md 和 ADR,再寻找浅模块、泄漏的接口、难以测试的模块,以及可以提升局部性和杠杆率的重构机会。
你会发现,这不是“AI 替你写代码”的思路,而是“让 AI 按工程纪律工作”的思路。
为什么它会突然流行?
我觉得有三个原因。
第一个原因是,开发者已经吃过“氛围编程”的亏。
模型越来越强,生成速度越来越快,但代码生成速度提升之后,工程熵也会更快积累。需求没对齐,测试不可靠,接口随手改,架构债滚得更快。mattpocock/skills 刚好站在这个反方向:它不卖神奇能力,它把注意力拉回工程基本功。
第二个原因是,它足够小。
很多团队喜欢写一份巨大的 Agent 规则文档,里面塞满代码风格、业务术语、测试偏好、分支规范、沟通规则。问题是规则越大,越难维护,也越容易互相冲突。
Skill 的形态更像 Unix 工具:一个技能只处理一个明确场景。要澄清需求就用 grill-me,要 TDD 就用 tdd,要拆 Issue 就用 to-issues。小,意味着可读、可改、可替换。
第三个原因是,它看起来像一个真实工程师的工作台,而不是包装过的产品。
这个仓库不是一个宏大的 AI DevOps 平台。它更像作者把自己的工作流公开了:哪些步骤必须问清楚,哪些测试不能乱写,哪些架构词必须统一,哪些 Git 操作需要护栏。这种“个人真实使用过”的痕迹,反而比抽象框架更容易让开发者信任。
它适合谁?
如果你已经在用 Claude Code、Codex 或类似的编码 Agent,并且发现 Agent 经常“很努力但方向不对”,这个仓库值得看。
它尤其适合三类人:
一类是开发者。你可以把它当作一个工程搭档的行为规范,让 Agent 不只是产出代码,而是先帮你澄清需求、拆任务、补测试。
一类是小团队。团队如果还没有成熟的 PRD、Issue、测试和架构复盘流程,可以先借它建立一套轻量流程,再慢慢改成自己的版本。
还有一类是正在写自己 Skills 的人。它给出的启发不是“复制这几个技能”,而是学习它的取舍:每个技能只做一件事,把触发条件写清楚,把流程写短,把复杂资料放到单独文件里按需加载。
但它也不是所有团队都能直接拿来用。
比如,部分工作流默认和 GitHub Issues 结合。如果你的团队主工作台是 Linear、Jira 或其他系统,就需要改技能内容。再比如,某些技能带有作者个人工作方式的强烈偏好,直接照搬可能不适合你的代码库。
所以更合理的用法不是“全量安装,然后相信它”,而是先挑 3 到 5 个高频技能跑起来,再按自己的流程改。
怎么开始用?
仓库 README 给出的快速方式很简单:
npx skills@latest add mattpocock/skills
然后选择你想安装的技能,以及要安装到哪些编码 Agent 上。
如果你只想先试最核心的一组,可以从这些开始:
npx skills@latest add mattpocock/skills
安装后优先关注:
grill-me:开工前澄清计划和设计
to-prd:把当前上下文整理成 PRD
to-issues:把计划拆成垂直切片
tdd:按红绿重构循环写代码
improve-codebase-architecture:定期找架构改进机会
实际使用时,不要把它当成“更强提示词”。更准确的心态是:这是给 Agent 装上的工程习惯。
真正的启发:AI 编程会回到流程
过去一年,很多人对 AI 编程的想象是模型越来越强,直到一次提示就能完成整个项目。
但 mattpocock/skills 走红说明,开发者正在意识到另一件事:模型能力只是底座,真正决定产出质量的,是流程、反馈和约束。
一个强模型,如果没有需求澄清,会很快偏航。
一个强模型,如果没有测试反馈,会在错误方向上跑得更快。
一个强模型,如果没有架构语言,会把代码库越写越难改。
所以这个仓库最值得学习的,不是某个具体技能,而是一种写 Agent 工作流的方式:少写万能规则,多写小技能;少堆抽象口号,多固化具体动作;少追求一次性自动化,多建立可验证的反馈闭环。
mattpocock/skills 的爆火,本质上不是提示词工程的胜利,而是软件工程基本功在 AI 时代的回潮。
当每个人都能让 AI 写代码时,差距不会消失。差距会转移到另一个地方:你能不能让 AI 像一个可靠工程师那样工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)