结构健康监测仿真-主题049-结构健康监测中的联邦学习技术
结构健康监测仿真-主题049:结构健康监测中的联邦学习技术
目录
1. 引言
1.1 背景与挑战
随着结构健康监测系统的广泛应用,大量桥梁、建筑、隧道等基础设施部署了密集的传感器网络,产生了海量的监测数据。然而,这些数据面临着以下挑战:
数据孤岛问题:
- 不同机构、不同地区的基础设施监测数据相互隔离
- 数据所有权和隐私保护限制了数据共享
- 单一机构的数据量有限,难以训练高精度模型
隐私与安全需求:
- 基础设施监测数据涉及国家安全和经济命脉
- 数据泄露可能导致严重的安全风险
- 法律法规对数据隐私保护要求日益严格
模型泛化能力:
- 单一结构的数据训练模型难以泛化到其他结构
- 不同结构类型、不同环境条件下的模型迁移困难
- 缺乏跨结构、跨地域的协同学习机制
1.2 联邦学习的概念
联邦学习(Federated Learning, FL)是一种分布式机器学习范式,其核心思想是:
“数据不动模型动” - 在不共享原始数据的前提下,通过共享模型参数或梯度信息,实现多方协同训练。
联邦学习的关键特性:
- 数据本地化:原始数据始终保留在本地
- 模型聚合:中央服务器聚合各参与方的模型更新
- 隐私保护:通过加密和差分隐私等技术保护数据隐私
- 协同训练:多方参与共同提升全局模型性能
1.3 联邦学习在SHM中的价值
联邦学习为结构健康监测带来了革命性的变化:
- 跨机构协作:不同管理部门可以在保护数据隐私的前提下共享知识
- 模型性能提升:利用多源数据训练的模型具有更好的泛化能力
- 成本降低:避免数据集中存储和传输的高昂成本
- 实时更新:支持模型的持续学习和在线更新
- 个性化适配:在全局模型的基础上进行本地个性化微调
2. 联邦学习基础理论
2.1 联邦学习的基本框架
联邦学习系统由两类主要参与者组成:
2.1.1 中央服务器(Server)
中央服务器负责:
- 全局模型维护:存储和管理全局模型参数
- 模型聚合:接收各客户端的模型更新并进行聚合
- 模型分发:将更新后的全局模型下发给各客户端
- 协调管理:管理训练过程,处理客户端的参与和退出
2.1.2 客户端(Client)
客户端通常是边缘设备或本地服务器,负责:
- 本地训练:使用本地数据对模型进行训练
- 梯度计算:计算模型参数的梯度或更新量
- 模型上传:将本地模型更新上传至中央服务器
- 模型接收:接收中央服务器下发的全局模型
2.2 联邦平均算法(FedAvg)
FedAvg是联邦学习中最基础的聚合算法,由McMahan等人于2017年提出。
2.2.1 算法原理
FedAvg的核心思想是对各客户端的模型参数进行加权平均:
w t + 1 = ∑ k = 1 K n k n w t + 1 k w_{t+1} = \sum_{k=1}^{K} \frac{n_k}{n} w_{t+1}^k wt+1=k=1∑Knnkwt+1k
其中:
- w t + 1 w_{t+1} wt+1:第t+1轮的全局模型参数
- w t + 1 k w_{t+1}^k wt+1k:第k个客户端的本地模型参数
- n k n_k nk:第k个客户端的样本数量
- n = ∑ k = 1 K n k n = \sum_{k=1}^{K} n_k n=∑k=1Knk:总样本数量
- K K K:参与训练的客户端数量
2.2.2 算法流程
FedAvg算法:
1. 服务器初始化全局模型 w_0
2. 对于每一轮通信 t = 1, 2, ..., T:
a. 服务器选择参与本轮训练的客户端子集 S_t
b. 服务器将当前全局模型 w_t 发送给选中的客户端
c. 每个选中的客户端 k ∈ S_t:
i. 接收全局模型 w_t
ii. 使用本地数据训练 E 个epoch,得到本地模型 w_{t+1}^k
iii. 将模型更新 (w_{t+1}^k - w_t) 发送给服务器
d. 服务器聚合所有客户端的更新:
w_{t+1} = w_t + η * Σ(n_k/n) * (w_{t+1}^k - w_t)
3. 返回最终的全局模型 w_T
2.3 联邦学习的分类
根据数据分布特点,联邦学习可分为三类:
2.3.1 横向联邦学习(Horizontal FL)
适用场景:各参与方的数据特征相同,但样本不同。
SHM应用示例:
- 多座同类型桥梁的监测数据
- 各桥梁的传感器类型和布置相同
- 数据特征空间一致,但监测的结构不同
特点:
- 特征对齐容易实现
- 主要解决样本量不足问题
- 适用于大规模协同训练
2.3.2 纵向联邦学习(Vertical FL)
适用场景:各参与方的样本相同,但特征不同。
SHM应用示例:
- 同一座桥梁的不同类型监测数据
- 结构响应数据、环境数据、交通数据分别由不同系统采集
- 样本(时间点)对齐,但特征维度不同
特点:
- 需要样本对齐机制
- 实现复杂的加密计算
- 适用于多源数据融合
2.3.3 联邦迁移学习(Federated Transfer Learning)
适用场景:各参与方的样本和特征都不完全相同。
SHM应用示例:
- 不同类型结构(桥梁vs建筑)的监测数据
- 不同传感器配置的数据
- 需要迁移学习实现知识共享
特点:
- 最复杂的联邦学习场景
- 结合迁移学习技术
- 实现跨域知识迁移
3. 联邦学习算法体系
3.1 聚合算法
3.1.1 FedProx - 近端项优化
FedProx在FedAvg的基础上增加了近端项,解决数据异构性问题:
min w [ F k ( w ) + μ 2 ∥ w − w t ∥ 2 ] \min_w \left[ F_k(w) + \frac{\mu}{2} \|w - w_t\|^2 \right] wmin[Fk(w)+2μ∥w−wt∥2]
其中:
- F k ( w ) F_k(w) Fk(w):第k个客户端的本地损失函数
- w t w_t wt:当前全局模型
- μ \mu μ:近端项系数,控制本地模型与全局模型的偏离程度
优势:
- 限制本地模型的偏离程度
- 提高收敛稳定性
- 适用于Non-IID数据分布
3.1.2 SCAFFOLD - 方差缩减
SCAFFOLD使用控制变量(Control Variates)来纠正客户端漂移:
w t + 1 k = w t − η ( g k ( w t ) − c k + c ) w_{t+1}^k = w_t - \eta (g_k(w_t) - c_k + c) wt+1k=wt−η(gk(wt)−ck+c)
其中:
- g k ( w t ) g_k(w_t) gk(wt):第k个客户端的随机梯度
- c k c_k ck:客户端控制变量
- c c c:服务器控制变量
优势:
- 减少通信轮数
- 加速收敛速度
- 处理数据异构性
3.1.3 FedNova - 归一化平均
FedNova对客户端更新进行归一化处理:
w t + 1 = w t − η ∑ k = 1 K τ k τ m a x Δ w k w_{t+1} = w_t - \eta \sum_{k=1}^{K} \frac{\tau_k}{\tau_{max}} \Delta w_k wt+1=wt−ηk=1∑KτmaxτkΔwk
其中:
- τ k \tau_k τk:第k个客户端的本地训练步数
- τ m a x \tau_{max} τmax:最大本地训练步数
- Δ w k \Delta w_k Δwk:第k个客户端的模型更新
优势:
- 处理不同客户端的计算能力差异
- 保证收敛性
- 支持异步训练
3.2 通信优化算法
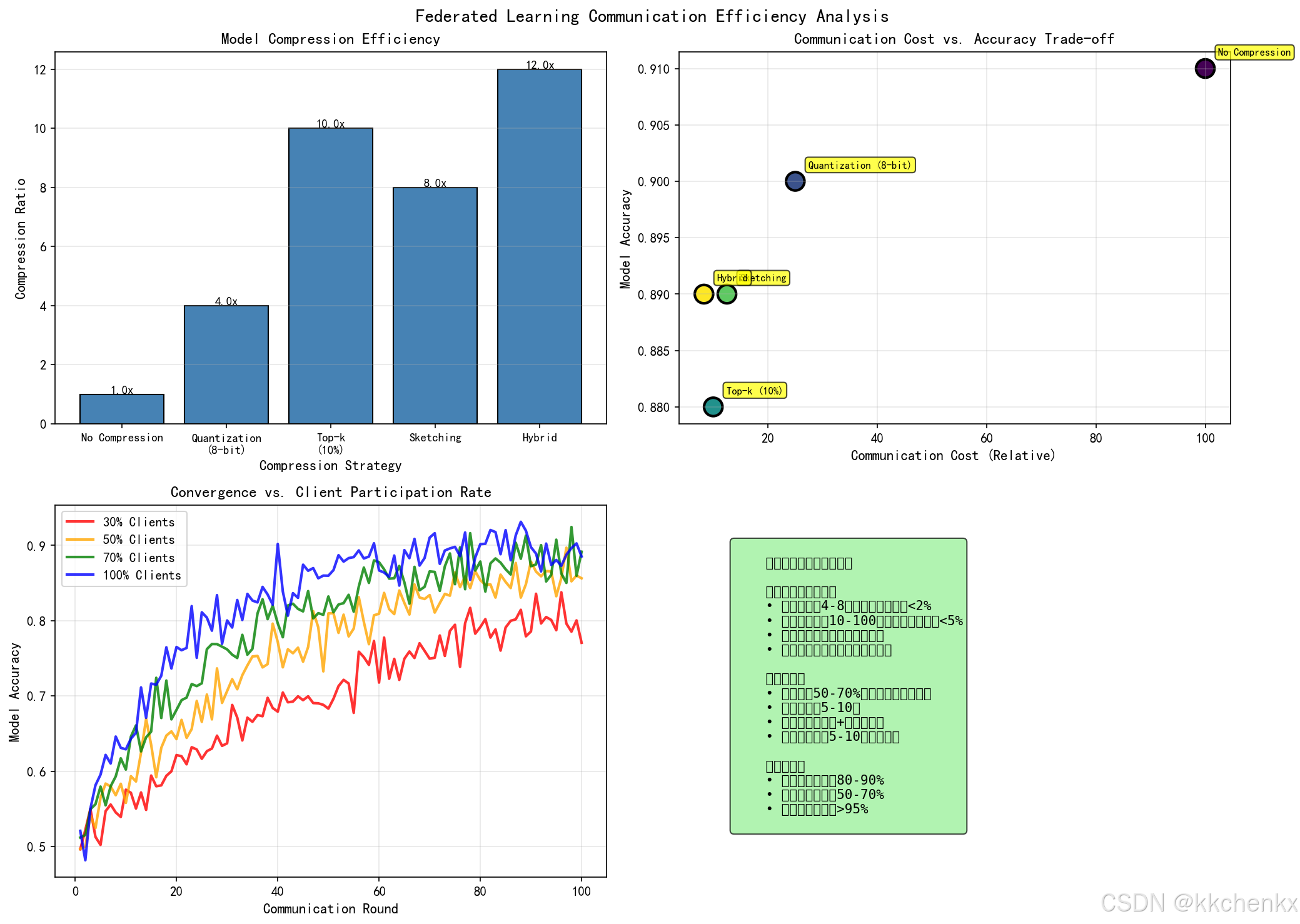
3.2.1 模型压缩
量化(Quantization):
- 将32位浮点数压缩为8位或更低精度
- 减少通信带宽需求
- 适用于资源受限的边缘设备
稀疏化(Sparsification):
- 只传输重要的梯度分量
- Top-k稀疏化:只保留绝对值最大的k个梯度
- 阈值稀疏化:只传输超过阈值的梯度
低秩分解:
- 将大矩阵分解为低秩矩阵的乘积
- 减少模型参数量
- 保持模型表达能力
3.2.2 异步联邦学习
问题背景:
- 同步联邦学习需要等待所有客户端完成训练
- 存在"掉队者"问题(Straggler Problem)
- 影响训练效率
异步更新策略:
- 服务器不等待所有客户端,而是按到达顺序聚合
- 使用过时感知的更新规则
- 设置最大延迟容忍度
算法流程:
异步联邦学习:
1. 服务器维护全局模型w和版本号t
2. 客户端异步请求当前模型
3. 客户端完成本地训练后立即上传更新
4. 服务器接收更新后立即聚合:
w_new = w_old + α * (w_client - w_old)
5. 版本号t增加
3.3 个性化联邦学习
3.3.1 本地微调(Local Fine-tuning)
在全局模型的基础上,每个客户端进行本地微调:
# 伪代码
# 1. 接收全局模型
global_model = server.get_global_model()
# 2. 本地微调
local_model = global_model.copy()
for epoch in range(fine_tune_epochs):
for batch in local_data:
loss = compute_loss(local_model, batch)
loss.backward()
optimizer.step()
# 3. 使用微调后的模型进行预测
predictions = local_model(test_data)
3.3.2 元学习(Meta-Learning)
使用MAML(Model-Agnostic Meta-Learning)实现快速适应:
min θ ∑ k = 1 K L k ( θ − α ∇ L k ( θ ) ) \min_\theta \sum_{k=1}^{K} \mathcal{L}_k(\theta - \alpha \nabla \mathcal{L}_k(\theta)) θmink=1∑KLk(θ−α∇Lk(θ))
其中:
- θ \theta θ:全局模型参数
- α \alpha α:本地学习率
- L k \mathcal{L}_k Lk:第k个客户端的损失函数
优势:
- 少量梯度更新即可适应新任务
- 学习良好的参数初始化
- 适用于数据稀缺的客户端
3.3.3 分层个性化
将模型分为全局层和个性化层:
全局层:
- 特征提取层
- 跨客户端共享
- 学习通用特征表示
个性化层:
- 分类/回归层
- 每个客户端独立
- 适应本地数据分布
class PersonalizedModel(nn.Module):
def __init__(self):
super().__init__()
# 全局共享的特征提取器
self.global_encoder = GlobalEncoder()
# 个性化的预测头
self.local_head = LocalHead()
def forward(self, x):
features = self.global_encoder(x) # 使用全局模型
output = self.local_head(features) # 使用本地模型
return output
4. 联邦学习在SHM中的应用架构
4.1 系统架构设计
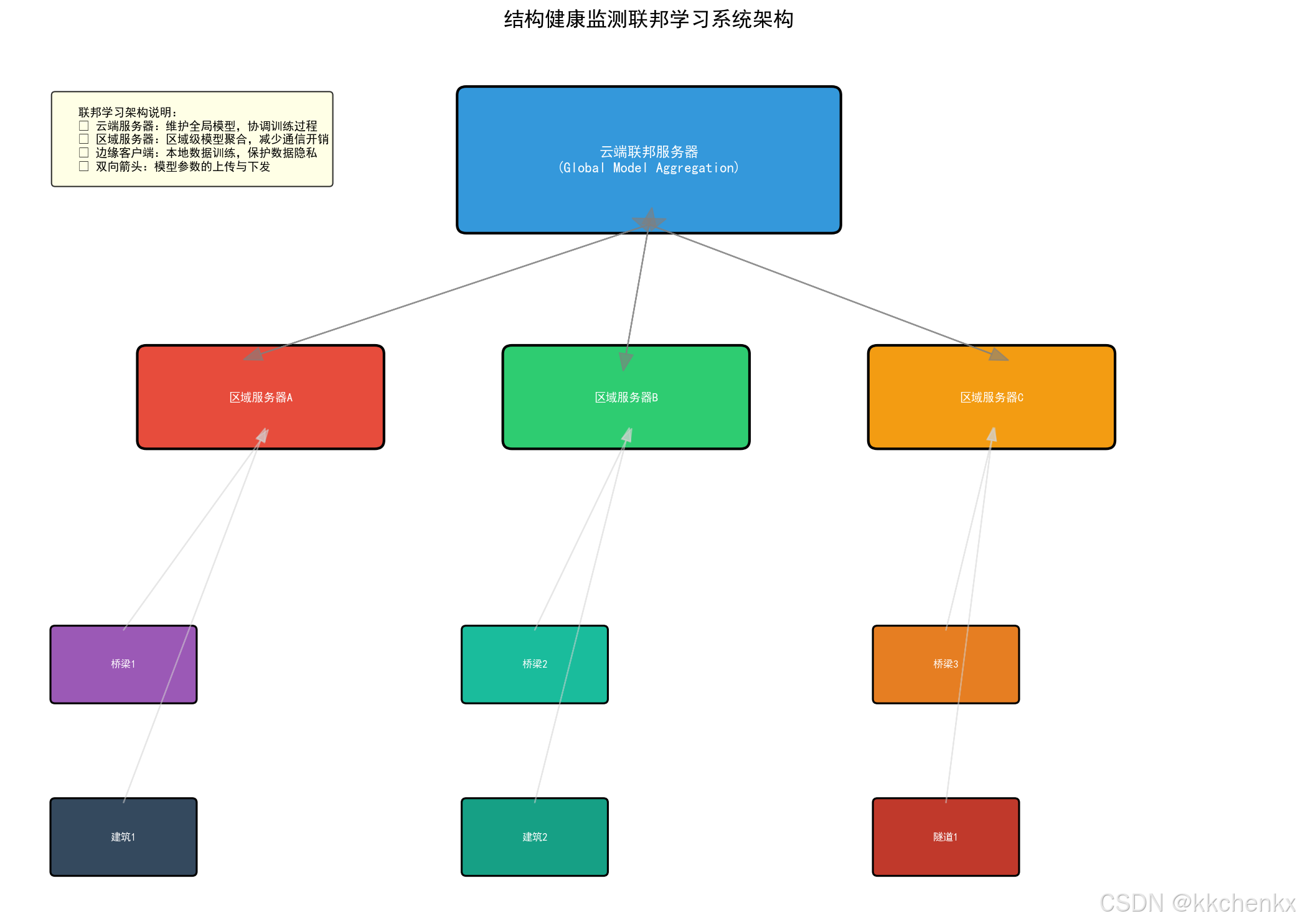
4.1.1 分层联邦架构
┌─────────────────────────────────────────────────────────────┐
│ 云端联邦服务器 │
│ (全局模型聚合与协调) │
└───────────────────────┬─────────────────────────────────────┘
│
┌───────────────┼───────────────┐
│ │ │
┌───────▼──────┐ ┌──────▼──────┐ ┌──────▼──────┐
│ 区域服务器A │ │ 区域服务器B │ │ 区域服务器C │
│ (区域级聚合) │ │ (区域级聚合) │ │ (区域级聚合) │
└───────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
┌────┴────┐ ┌────┴────┐ ┌────┴────┐
│ │ │ │ │ │
┌──▼──┐ ┌──▼──┐ ┌──▼──┐ ┌──▼──┐ ┌──▼──┐ ┌──▼──┐
│桥梁1│ │桥梁2│ │桥梁3│ │桥梁4│ │桥梁5│ │桥梁6│
└─────┘ └─────┘ └─────┘ └─────┘ └─────┘ └─────┘
优势:
- 减少云端通信开销
- 支持地理分布广泛的基础设施
- 实现分层隐私保护
4.1.2 边缘-云协同架构
┌──────────────────────────────────────────────┐
│ 云端联邦服务器 │
│ (长期模型存储与分析) │
└──────────────────┬───────────────────────────┘
│
┌─────────┴──────────┐
│ 5G/4G网络 │
└─────────┬──────────┘
│
┌──────────────┼──────────────┐
│ │ │
┌───▼────┐ ┌────▼────┐ ┌─────▼────┐
│边缘网关1│ │边缘网关2│ │边缘网关3 │
│(实时处理)│ │(实时处理)│ │(实时处理)│
└───┬────┘ └────┬────┘ └─────┬────┘
│ │ │
┌───▼───┐ ┌────▼───┐ ┌──────▼────┐
│传感器 │ │传感器 │ │ 传感器 │
│网络 │ │网络 │ │ 网络 │
└───────┘ └────────┘ └───────────┘
功能划分:
- 边缘层:实时数据采集、预处理、本地推理
- 网关层:本地模型训练、数据缓存、通信管理
- 云层:全局模型聚合、长期分析、系统管理
4.2 损伤检测联邦学习系统
4.2.1 问题定义
目标:在多座桥梁之间协同训练损伤检测模型,同时保护各桥梁的监测数据隐私。
数据特点:
- 每座桥梁有独立的振动传感器网络
- 数据分布因结构特性、环境因素而异(Non-IID)
- 损伤样本稀缺,正常样本占绝大多数
4.2.2 模型设计
特征提取器(共享):
class FeatureExtractor(nn.Module):
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU()
)
def forward(self, x):
return self.encoder(x)
损伤分类器(个性化):
class DamageClassifier(nn.Module):
def __init__(self, feature_dim, num_classes):
super().__init__()
self.classifier = nn.Sequential(
nn.Linear(feature_dim, 64),
nn.ReLU(),
nn.Linear(64, num_classes),
nn.Sigmoid()
)
def forward(self, features):
return self.classifier(features)
4.2.3 训练流程
损伤检测联邦学习流程:
初始化阶段:
1. 服务器初始化全局特征提取器
2. 各桥梁初始化本地分类器
通信轮次(每轮):
1. 服务器广播全局特征提取器给选中的桥梁
2. 各桥梁:
a. 加载全局特征提取器
b. 冻结特征提取器参数(可选)
c. 训练本地分类器
d. 联合训练特征提取器(可选)
e. 上传特征提取器更新
3. 服务器聚合特征提取器更新
4. 评估全局模型性能
个性化阶段:
1. 各桥梁接收最终全局特征提取器
2. 使用本地数据微调分类器
3. 部署本地模型进行实时检测
4.3 结构响应预测联邦学习
4.3.1 问题定义
目标:利用多座桥梁的历史数据,协同训练结构响应预测模型。
应用场景:
- 预测极端荷载下的结构响应
- 评估结构剩余承载能力
- 优化传感器布置方案
4.3.2 时序联邦学习
挑战:
- 时间序列数据的时序依赖性
- 不同桥梁的荷载历史不同
- 需要保持时序一致性
解决方案:
- 使用LSTM/GRU等时序模型
- 序列级别的联邦聚合
- 时序对齐的数据采样
class FederatedLSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers):
super().__init__()
self.lstm = nn.LSTM(
input_dim, hidden_dim, num_layers,
batch_first=True, dropout=0.2
)
self.fc = nn.Linear(hidden_dim, 1)
def forward(self, x):
lstm_out, _ = self.lstm(x)
output = self.fc(lstm_out[:, -1, :])
return output
5. 隐私保护与安全机制
5.1 差分隐私(Differential Privacy)
5.1.1 基本概念
差分隐私通过向数据或模型添加噪声来保护隐私:
定义:一个随机机制 M M M满足 ( ϵ , δ ) (\epsilon, \delta) (ϵ,δ)-差分隐私,如果对于任意相邻数据集 D D D和 D ′ D' D′,以及任意输出子集 S S S:
P [ M ( D ) ∈ S ] ≤ e ϵ P [ M ( D ′ ) ∈ S ] + δ P[M(D) \in S] \leq e^\epsilon P[M(D') \in S] + \delta P[M(D)∈S]≤eϵP[M(D′)∈S]+δ
其中:
- ϵ \epsilon ϵ:隐私预算,越小隐私保护越强
- δ \delta δ:允许的小概率失败
5.1.2 联邦学习中的差分隐私
梯度噪声添加:
g ~ k = g k + N ( 0 , σ 2 C 2 I ) \tilde{g}_k = g_k + \mathcal{N}(0, \sigma^2 C^2 I) g~k=gk+N(0,σ2C2I)
其中:
- g k g_k gk:第k个客户端的梯度
- C C C:梯度裁剪阈值
- σ \sigma σ:噪声标准差
- N \mathcal{N} N:高斯噪声
实现代码:
def add_dp_noise(gradients, epsilon, delta, sensitivity):
"""添加差分隐私噪声"""
# 计算噪声标准差
sigma = np.sqrt(2 * np.log(1.25 / delta)) * sensitivity / epsilon
# 梯度裁剪
clipped_gradients = []
for grad in gradients:
norm = torch.norm(grad)
if norm > sensitivity:
grad = grad * (sensitivity / norm)
clipped_gradients.append(grad)
# 添加噪声
noisy_gradients = []
for grad in clipped_gradients:
noise = torch.normal(0, sigma, grad.shape)
noisy_gradients.append(grad + noise)
return noisy_gradients
5.1.3 隐私预算管理
组合定理:
- 顺序组合: k k k个机制的隐私预算累加
- 高级组合:使用更紧致的隐私预算界
- 矩会计:跟踪隐私损失的累积
自适应隐私预算分配:
- 根据数据敏感度动态调整噪声
- 重要轮次使用更多隐私预算
- 平衡隐私保护和模型性能
5.2 安全多方计算(Secure Multi-Party Computation)
5.2.1 秘密共享
Shamir秘密共享:
- 将秘密分成多个份额
- 需要足够数量的份额才能重建秘密
- 单个份额不泄露任何信息
在联邦学习中的应用:
1. 每个客户端将梯度分成n个份额
2. 使用不同的加密密钥加密各份额
3. 将加密份额分发给n个服务器
4. 服务器在加密域上进行聚合
5. 需要t个服务器合作才能解密结果
5.2.2 同态加密
部分同态加密(PHE):
- 支持加法或乘法的一种同态操作
- 计算效率较高
- 适用于梯度聚合
全同态加密(FHE):
- 支持任意次数的加法和乘法
- 计算开销大
- 目前主要用于小规模模型
联邦学习中的同态加密:
# 简化示例
class HomomorphicEncryption:
def __init__(self):
self.public_key, self.private_key = self.generate_keys()
def encrypt(self, plaintext):
# 使用公钥加密
return plaintext * self.public_key + noise
def decrypt(self, ciphertext):
# 使用私钥解密
return (ciphertext - noise) / self.public_key
def add_encrypted(self, ct1, ct2):
# 同态加法
return ct1 + ct2
5.3 安全聚合协议
5.3.1 双掩码协议
原理:
- 每个客户端生成两个随机掩码
- 一个掩码与另一个客户端共享
- 掩码在聚合时相互抵消
流程:
1. 客户端i生成随机数u_i和s_i
2. 客户端i与客户端j共享s_i和s_j
3. 客户端i计算掩码梯度:
m_i = g_i + u_i - Σs_j (j是i的邻居)
4. 服务器聚合:Σm_i = Σg_i + Σu_i - ΣΣs_j
5. 通过精心设计,掩码相互抵消,只剩Σg_i
5.3.2 拜占庭容错
威胁模型:
- 恶意客户端发送错误梯度
- 试图破坏全局模型
- 需要进行异常检测和过滤
防御机制:
- Krum算法:选择与其他梯度最接近的梯度
- ** trimmed mean**:去除极端值后求平均
- Median聚合:使用坐标中位数而非平均
def krum_aggregation(gradients, f):
"""Krum聚合算法"""
n = len(gradients)
scores = []
for i in range(n):
distances = []
for j in range(n):
if i != j:
dist = torch.norm(gradients[i] - gradients[j])
distances.append(dist)
distances.sort()
score = sum(distances[:n-f-2])
scores.append((score, i))
scores.sort()
selected_idx = scores[0][1]
return gradients[selected_idx]
6. 多源异构数据融合
6.1 异构性挑战
6.1.1 统计异构性(Statistical Heterogeneity)
Non-IID数据分布:
- 各客户端的数据分布不同
- 特征分布差异: P k ( x ) ≠ P j ( x ) P_k(x) \neq P_j(x) Pk(x)=Pj(x)
- 标签分布差异: P k ( y ) ≠ P j ( y ) P_k(y) \neq P_j(y) Pk(y)=Pj(y)
- 条件分布差异: P k ( y ∣ x ) ≠ P j ( y ∣ x ) P_k(y|x) \neq P_j(y|x) Pk(y∣x)=Pj(y∣x)
SHM中的Non-IID场景:
- 不同桥梁的结构类型不同
- 环境条件(温度、湿度、风速)差异
- 交通荷载模式不同
- 损伤类型和程度各异
6.1.2 系统异构性(System Heterogeneity)
硬件差异:
- 计算能力:CPU、GPU、内存
- 网络带宽:有线、无线、5G
- 存储容量:本地数据量
软件差异:
- 操作系统:Windows、Linux、嵌入式系统
- 深度学习框架:PyTorch、TensorFlow
- 通信协议:HTTP、gRPC、MQTT
6.2 异构性处理策略
6.2.1 数据对齐与标准化
特征标准化:
def federated_standardization(client_data):
"""联邦标准化:计算全局均值和标准差"""
# 各客户端计算本地统计量
local_stats = []
for data in client_data:
mean = np.mean(data, axis=0)
var = np.var(data, axis=0)
n = len(data)
local_stats.append({'mean': mean, 'var': var, 'n': n})
# 聚合全局统计量
total_n = sum(s['n'] for s in local_stats)
global_mean = sum(s['mean'] * s['n'] for s in local_stats) / total_n
# 计算全局方差
global_var = np.zeros_like(global_mean)
for s in local_stats:
global_var += s['n'] * (s['var'] + (s['mean'] - global_mean)**2)
global_var /= total_n
return global_mean, np.sqrt(global_var)
时间对齐:
- 统一采样频率
- 时间戳标准化
- 缺失值插值
6.2.2 联邦域适应
领域对抗训练:
class DomainAdversarialNetwork(nn.Module):
def __init__(self, feature_dim, num_domains):
super().__init__()
self.feature_extractor = FeatureExtractor()
self.label_predictor = LabelPredictor()
self.domain_classifier = DomainClassifier()
def forward(self, x, alpha):
features = self.feature_extractor(x)
# 梯度反转层
reversed_features = GradientReversalLayer.apply(features, alpha)
label_output = self.label_predictor(features)
domain_output = self.domain_classifier(reversed_features)
return label_output, domain_output
最大均值差异(MMD):
M M D 2 ( P , Q ) = ∥ 1 n ∑ i = 1 n ϕ ( x i ) − 1 m ∑ j = 1 m ϕ ( y j ) ∥ 2 MMD^2(P, Q) = \|\frac{1}{n}\sum_{i=1}^{n}\phi(x_i) - \frac{1}{m}\sum_{j=1}^{m}\phi(y_j)\|^2 MMD2(P,Q)=∥n1i=1∑nϕ(xi)−m1j=1∑mϕ(yj)∥2
其中:
- P , Q P, Q P,Q:两个域的分布
- ϕ \phi ϕ:核函数映射
- n , m n, m n,m:样本数量
6.3 多模态数据融合
6.3.1 模态对齐
早期融合:
- 在特征层面融合不同模态
- 需要模态间的时间对齐
- 适用于模态间关联性强的情况
晚期融合:
- 各模态独立处理,决策层面融合
- 灵活性高,易于扩展
- 可能丢失模态间关联信息
混合融合:
- 结合早期和晚期融合的优点
- 多层次特征融合
- 自适应权重学习
6.3.2 联邦多模态学习
class FederatedMultimodalModel:
def __init__(self, modalities):
self.modalities = modalities
self.encoders = {}
self.fusion_layer = None
# 为每种模态创建编码器
for modality in modalities:
self.encoders[modality] = ModalityEncoder(modality)
def forward(self, inputs):
"""多模态前向传播"""
features = {}
for modality, data in inputs.items():
if modality in self.encoders:
features[modality] = self.encoders[modality](data)
# 特征融合
fused_features = self.fusion_layer(features)
# 预测
output = self.predictor(fused_features)
return output
def federated_train(self, clients_data):
"""联邦训练"""
for round in range(num_rounds):
# 选择参与客户端
selected_clients = self.select_clients()
local_updates = {}
for client in selected_clients:
# 本地训练
local_model = self.get_global_model()
trained_model = self.local_train(local_model, clients_data[client])
# 提取更新
local_updates[client] = self.get_model_update(trained_model)
# 聚合更新
self.aggregate_updates(local_updates)
7. 工程应用案例
7.1 案例一:多桥梁损伤检测联邦学习系统
7.1.1 项目背景
某省份交通厅管辖范围内有50余座大型桥梁,需要建立统一的损伤检测系统。
挑战:
- 各桥梁管理单位数据不能集中共享
- 桥梁类型多样:悬索桥、斜拉桥、梁桥
- 损伤样本稀缺且分布不均
7.1.2 系统架构
三层架构:
- 边缘层:各桥梁的本地监测系统
- 区域层:地市级数据中心
- 省级层:云端联邦服务器
数据流:
桥梁传感器数据 → 边缘预处理 → 本地训练 →
区域聚合 → 省级聚合 → 全局模型下发
7.1.3 实施效果
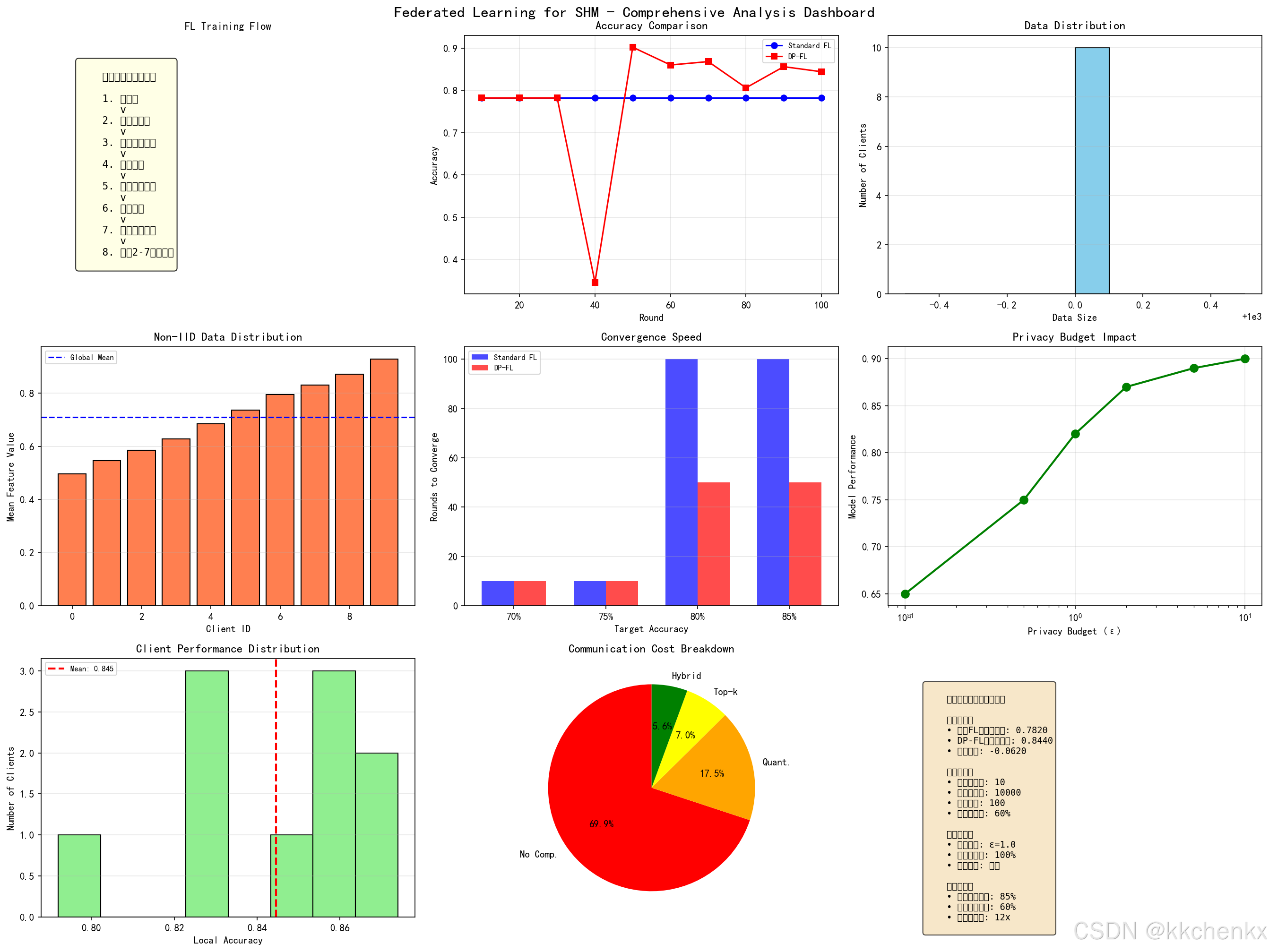
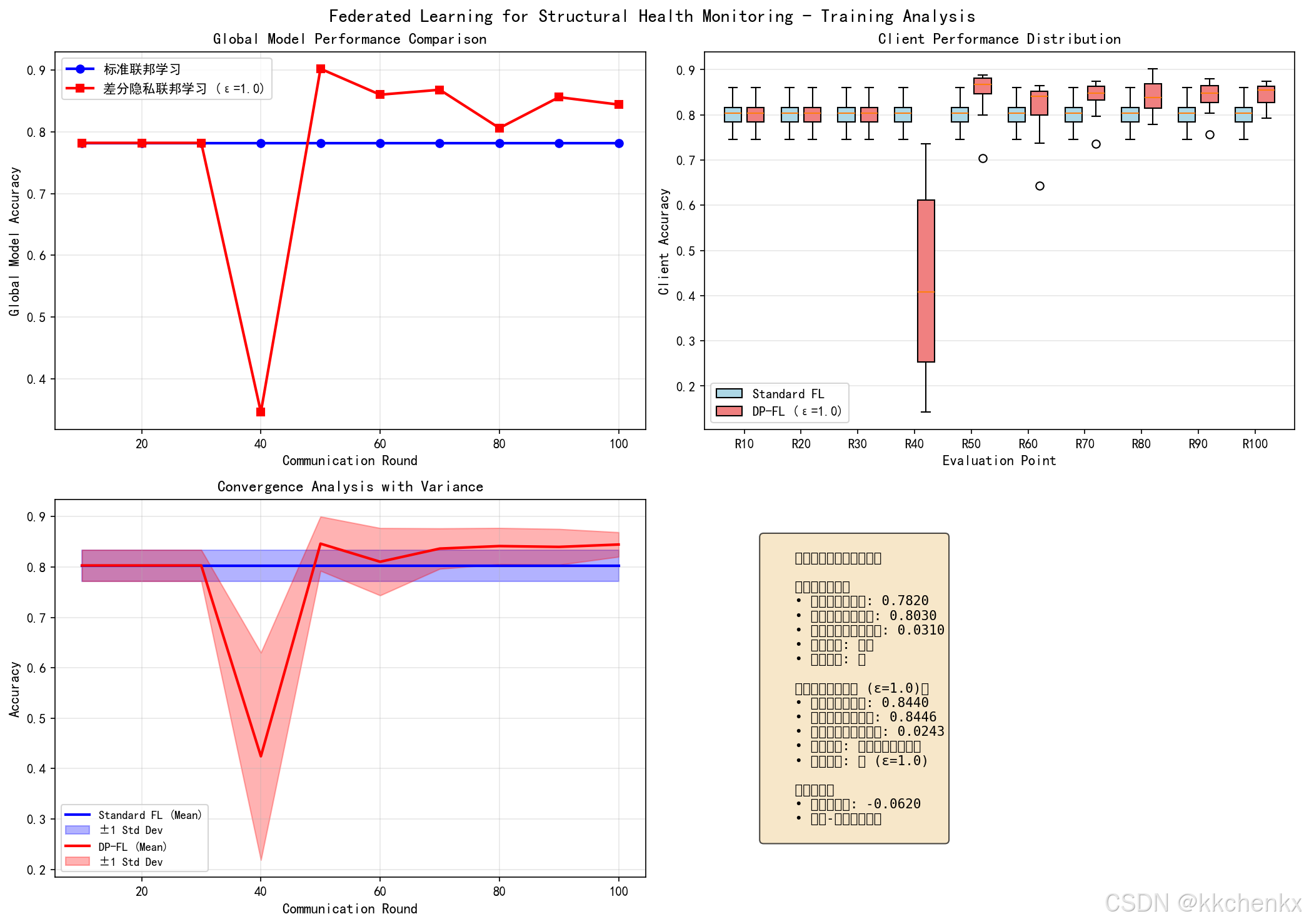
性能提升:
- 损伤检测准确率:单一桥梁72% → 联邦学习85%
- 误报率:15% → 8%
- 新桥梁冷启动时间:3个月 → 2周
隐私保护:
- 原始数据零共享
- 差分隐私保护(ε=1.0)
- 通过第三方安全审计
7.2 案例二:跨城市建筑健康监测联邦网络
7.2.1 项目背景
三个城市(A、B、C)的建筑管理部门希望协同建立地震响应预测模型。
数据特点:
- 城市A:高层建筑为主,软土地基
- 城市B:多层建筑为主,岩石地基
- 城市C:历史建筑为主,需要特殊保护
7.2.2 技术方案
个性化联邦学习:
- 共享特征提取层
- 个性化预测层
- 元学习初始化
通信优化:
- 模型量化(8-bit)
- 梯度稀疏化(Top-10%)
- 异步聚合
7.2.3 实施效果
模型性能:
- 地震响应预测RMSE:单一城市0.15g → 联邦学习0.08g
- 跨城市泛化能力显著提升
- 历史建筑保护预警准确率92%
经济效益:
- 数据共享成本降低80%
- 模型开发周期缩短60%
- 系统维护成本降低40%
7.3 案例三:隧道群健康状态联邦评估
7.3.1 项目背景
某山区高速公路包含20余座隧道,需要建立群健康评估系统。
特殊挑战:
- 隧道环境复杂,通信不稳定
- 地质条件差异大
- 需要实时健康评估
7.3.2 技术方案
边缘联邦学习:
- 隧道口部署边缘计算节点
- 本地模型训练与缓存
- 间歇性同步机制
自适应聚合:
- 根据网络状况调整同步频率
- 重要性加权聚合
- 模型版本管理
7.3.3 实施效果
系统性能:
- 健康评估延迟:< 5秒
- 模型更新频率:每日1次(网络良好时)
- 离线运行能力:支持7天离线预测
评估准确性:
- 衬砌损伤识别准确率:88%
- 渗漏水检测召回率:91%
- 结构安全等级评估准确率:94%
8. Python仿真实现
8.1 联邦学习基础框架
"""
结构健康监测联邦学习仿真框架
"""
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from collections import OrderedDict
import copy
class FederatedClient:
"""联邦学习客户端"""
def __init__(self, client_id, data, model, local_epochs=5, lr=0.01):
self.client_id = client_id
self.data = data
self.model = model
self.local_epochs = local_epochs
self.lr = lr
self.optimizer = optim.SGD(model.parameters(), lr=lr)
def local_train(self, global_weights):
"""本地训练"""
# 加载全局模型参数
self.model.load_state_dict(global_weights)
self.model.train()
# 本地训练
for epoch in range(self.local_epochs):
for batch in self.data:
inputs, labels = batch
self.optimizer.zero_grad()
outputs = self.model(inputs)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
self.optimizer.step()
# 返回更新后的模型参数
return copy.deepcopy(self.model.state_dict())
def evaluate(self, global_weights):
"""本地评估"""
self.model.load_state_dict(global_weights)
self.model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in self.data:
outputs = self.model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total if total > 0 else 0
return accuracy
class FederatedServer:
"""联邦学习服务器"""
def __init__(self, global_model, num_clients, selection_ratio=0.5):
self.global_model = global_model
self.num_clients = num_clients
self.selection_ratio = selection_ratio
self.global_weights = copy.deepcopy(global_model.state_dict())
self.round = 0
def select_clients(self):
"""选择参与训练的客户端"""
num_selected = max(1, int(self.num_clients * self.selection_ratio))
selected = np.random.choice(self.num_clients, num_selected, replace=False)
return selected
def aggregate_fedavg(self, client_weights, client_samples):
"""FedAvg聚合"""
total_samples = sum(client_samples)
# 加权平均
global_dict = OrderedDict()
for key in self.global_weights.keys():
global_dict[key] = torch.zeros_like(self.global_weights[key])
for i, client_dict in enumerate(client_weights):
weight = client_samples[i] / total_samples
global_dict[key] += weight * client_dict[key]
self.global_weights = global_dict
self.global_model.load_state_dict(self.global_weights)
self.round += 1
def aggregate_with_dp(self, client_weights, client_samples, epsilon=1.0):
"""带差分隐私的聚合"""
# 先进行FedAvg聚合
self.aggregate_fedavg(client_weights, client_samples)
# 添加噪声
sensitivity = 2.0 # 梯度裁剪阈值
sigma = np.sqrt(2 * np.log(1.25 / 1e-5)) * sensitivity / epsilon
noisy_weights = OrderedDict()
for key, param in self.global_weights.items():
noise = torch.normal(0, sigma, param.shape)
noisy_weights[key] = param + noise
self.global_weights = noisy_weights
self.global_model.load_state_dict(self.global_weights)
8.2 结构健康监测联邦学习系统
class SHMNeuralNetwork(nn.Module):
"""结构健康监测神经网络"""
def __init__(self, input_dim, hidden_dim, num_classes):
super(SHMNeuralNetwork, self).__init__()
self.feature_extractor = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Dropout(0.2)
)
self.classifier = nn.Sequential(
nn.Linear(hidden_dim // 2, 64),
nn.ReLU(),
nn.Linear(64, num_classes),
nn.Softmax(dim=1)
)
def forward(self, x):
features = self.feature_extractor(x)
output = self.classifier(features)
return output, features
class FederatedSHMSystem:
"""联邦学习SHM系统"""
def __init__(self, num_structures, input_dim, num_classes):
self.num_structures = num_structures
self.input_dim = input_dim
self.num_classes = num_classes
# 初始化全局模型
self.global_model = SHMNeuralNetwork(input_dim, 128, num_classes)
# 初始化服务器
self.server = FederatedServer(
self.global_model,
num_structures,
selection_ratio=0.6
)
# 初始化客户端
self.clients = []
for i in range(num_structures):
local_model = SHMNeuralNetwork(input_dim, 128, num_classes)
# 生成模拟数据
local_data = self.generate_structure_data(i)
client = FederatedClient(i, local_data, local_model)
self.clients.append(client)
def generate_structure_data(self, structure_id, num_samples=1000):
"""生成结构监测数据"""
np.random.seed(structure_id)
# 模拟不同结构的特征分布
base_freq = 0.5 + structure_id * 0.1
noise_level = 0.1 + structure_id * 0.02
# 生成特征
features = []
labels = []
for _ in range(num_samples):
# 正常状态
if np.random.random() > 0.2:
freq = base_freq + np.random.normal(0, noise_level)
amp = 1.0 + np.random.normal(0, 0.1)
label = 0 # 正常
else:
# 损伤状态
freq = base_freq * 0.9 + np.random.normal(0, noise_level * 2)
amp = 1.5 + np.random.normal(0, 0.2)
label = 1 # 损伤
feature = [freq, amp, np.random.normal(0, 0.1),
np.random.normal(0, 0.1)]
features.append(feature)
labels.append(label)
# 转换为PyTorch张量
features = torch.FloatTensor(features)
labels = torch.LongTensor(labels)
# 创建数据加载器
dataset = torch.utils.data.TensorDataset(features, labels)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)
return dataloader
def train(self, num_rounds, use_dp=False, epsilon=1.0):
"""联邦训练"""
print(f"开始联邦学习训练({num_rounds}轮)...")
history = {
'global_accuracy': [],
'client_accuracies': [],
'communication_cost': []
}
for round in range(num_rounds):
# 选择参与客户端
selected_clients = self.server.select_clients()
# 收集本地更新
client_weights = []
client_samples = []
for client_idx in selected_clients:
client = self.clients[client_idx]
# 本地训练
updated_weights = client.local_train(self.server.global_weights)
client_weights.append(updated_weights)
# 记录样本数
num_samples = len(client.data.dataset)
client_samples.append(num_samples)
# 聚合更新
if use_dp:
self.server.aggregate_with_dp(
client_weights, client_samples, epsilon
)
else:
self.server.aggregate_fedavg(client_weights, client_samples)
# 评估
if (round + 1) % 10 == 0:
global_acc = self.evaluate_global()
client_accs = self.evaluate_clients()
print(f"轮次 {round + 1}/{num_rounds}:")
print(f" 全局模型准确率: {global_acc:.4f}")
print(f" 客户端平均准确率: {np.mean(client_accs):.4f}")
history['global_accuracy'].append(global_acc)
history['client_accuracies'].append(client_accs)
return history
def evaluate_global(self):
"""评估全局模型"""
# 在测试集上评估
test_data = self.generate_structure_data(999, 500)
correct = 0
total = 0
self.global_model.eval()
with torch.no_grad():
for inputs, labels in test_data:
outputs, _ = self.global_model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total if total > 0 else 0
def evaluate_clients(self):
"""评估各客户端"""
accuracies = []
for client in self.clients:
acc = client.evaluate(self.server.global_weights)
accuracies.append(acc)
return accuracies
8.3 隐私保护机制实现
class PrivacyPreservingFL:
"""隐私保护联邦学习"""
def __init__(self, epsilon=1.0, delta=1e-5, max_grad_norm=1.0):
self.epsilon = epsilon
self.delta = delta
self.max_grad_norm = max_grad_norm
def add_gaussian_noise(self, tensor, sensitivity):
"""添加高斯噪声"""
sigma = np.sqrt(2 * np.log(1.25 / self.delta)) * sensitivity / self.epsilon
noise = torch.normal(0, sigma, tensor.shape)
return tensor + noise
def gradient_clipping(self, gradients):
"""梯度裁剪"""
# 计算全局梯度范数
global_norm = torch.sqrt(sum(torch.sum(g**2) for g in gradients))
# 裁剪因子
clip_factor = min(1.0, self.max_grad_norm / (global_norm + 1e-6))
# 裁剪梯度
clipped_gradients = [g * clip_factor for g in gradients]
return clipped_gradients
def secure_aggregation(self, client_updates, num_clients):
"""安全聚合"""
# 模拟安全聚合(实际实现需要密码学协议)
aggregated = OrderedDict()
for key in client_updates[0].keys():
aggregated[key] = torch.zeros_like(client_updates[0][key])
for update in client_updates:
aggregated[key] += update[key]
aggregated[key] /= num_clients
return aggregated
def local_dp_training(self, model, data_loader, epochs=5):
"""本地差分隐私训练"""
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(epochs):
for batch_idx, (inputs, labels) in enumerate(data_loader):
optimizer.zero_grad()
outputs = model(inputs)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
# 获取梯度
gradients = [param.grad.clone() for param in model.parameters()]
# 梯度裁剪
clipped_gradients = self.gradient_clipping(gradients)
# 添加噪声
noisy_gradients = [
self.add_gaussian_noise(g, self.max_grad_norm)
for g in clipped_gradients
]
# 应用噪声梯度
for param, noisy_grad in zip(model.parameters(), noisy_gradients):
param.grad = noisy_grad
optimizer.step()
return model.state_dict()
8.4 可视化与分析工具
import matplotlib.pyplot as plt
import seaborn as sns
class FLVisualizer:
"""联邦学习可视化工具"""
def __init__(self):
plt.style.use('seaborn-v0_8-darkgrid')
def plot_training_history(self, history, save_path='fl_training.png'):
"""绘制训练历史"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 全局模型准确率
ax1 = axes[0, 0]
rounds = range(10, len(history['global_accuracy']) * 10 + 1, 10)
ax1.plot(rounds, history['global_accuracy'], 'b-', linewidth=2, marker='o')
ax1.set_xlabel('Communication Round')
ax1.set_ylabel('Global Model Accuracy')
ax1.set_title('Global Model Performance')
ax1.grid(True, alpha=0.3)
# 客户端准确率分布
ax2 = axes[0, 1]
client_accs = np.array(history['client_accuracies'])
ax2.boxplot(client_accs.T)
ax2.set_xlabel('Evaluation Point')
ax2.set_ylabel('Client Accuracy')
ax2.set_title('Client Performance Distribution')
ax2.grid(True, alpha=0.3)
# 准确率热力图
ax3 = axes[1, 0]
sns.heatmap(client_accs, cmap='YlOrRd', ax=ax3, cbar_kws={'label': 'Accuracy'})
ax3.set_xlabel('Evaluation Point')
ax3.set_ylabel('Client ID')
ax3.set_title('Client Accuracy Heatmap')
# 收敛曲线
ax4 = axes[1, 1]
mean_acc = np.mean(client_accs, axis=1)
std_acc = np.std(client_accs, axis=1)
ax4.plot(rounds, mean_acc, 'g-', linewidth=2, label='Mean Accuracy')
ax4.fill_between(rounds, mean_acc - std_acc, mean_acc + std_acc,
alpha=0.3, color='green', label='±1 Std Dev')
ax4.set_xlabel('Communication Round')
ax4.set_ylabel('Accuracy')
ax4.set_title('Convergence Analysis')
ax4.legend()
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
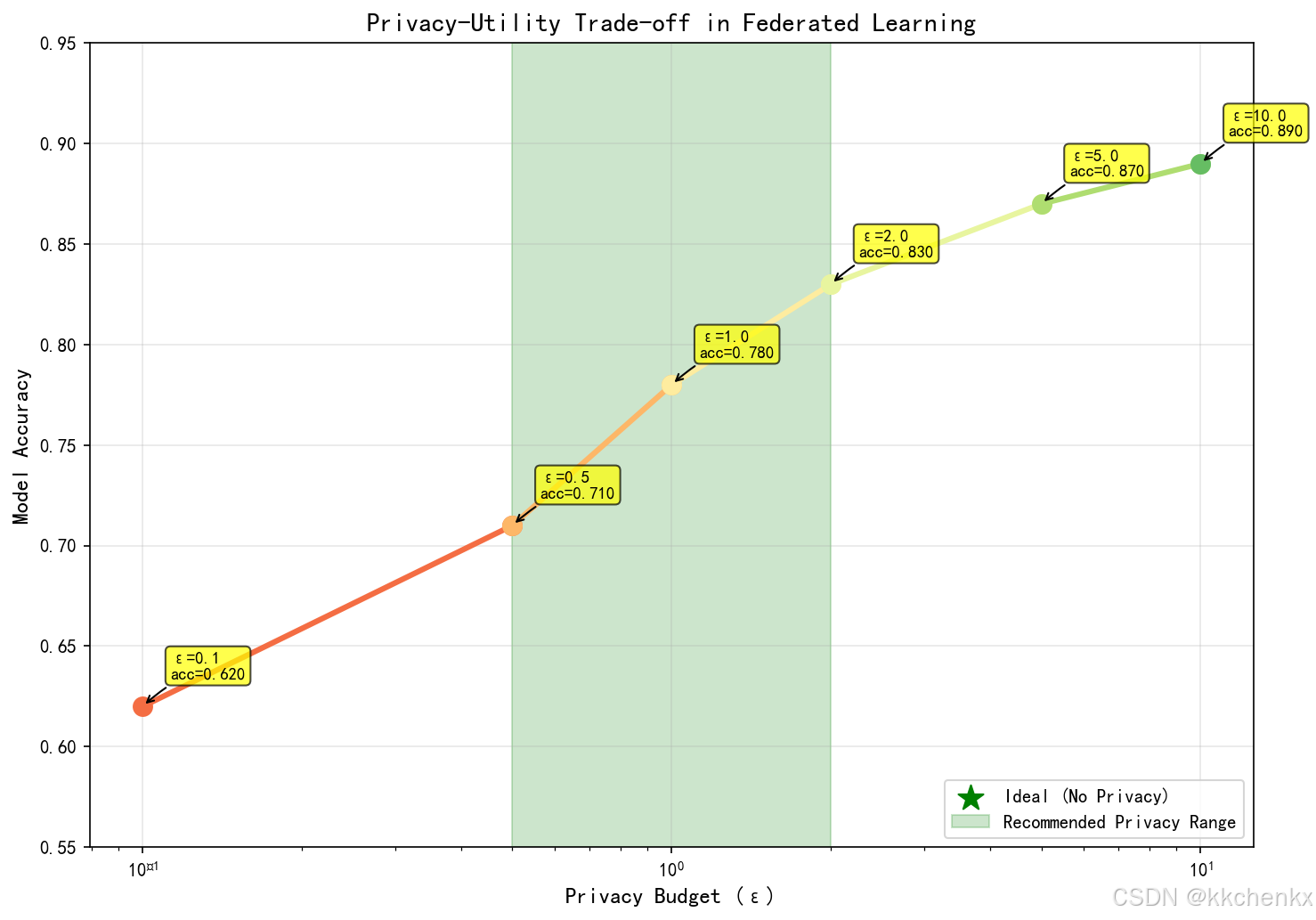
def plot_privacy_utility_tradeoff(self, epsilons, accuracies,
save_path='privacy_utility.png'):
"""绘制隐私-效用权衡曲线"""
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(epsilons, accuracies, 'ro-', linewidth=2, markersize=8)
ax.set_xlabel('Privacy Budget (ε)', fontsize=12)
ax.set_ylabel('Model Accuracy', fontsize=12)
ax.set_title('Privacy-Utility Trade-off', fontsize=14, fontweight='bold')
ax.grid(True, alpha=0.3)
# 添加标注
for i, (eps, acc) in enumerate(zip(epsilons, accuracies)):
ax.annotate(f'ε={eps:.1f}\nacc={acc:.3f}',
xy=(eps, acc), xytext=(10, 10),
textcoords='offset points', fontsize=9,
bbox=dict(boxstyle='round,pad=0.3', facecolor='yellow', alpha=0.7))
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
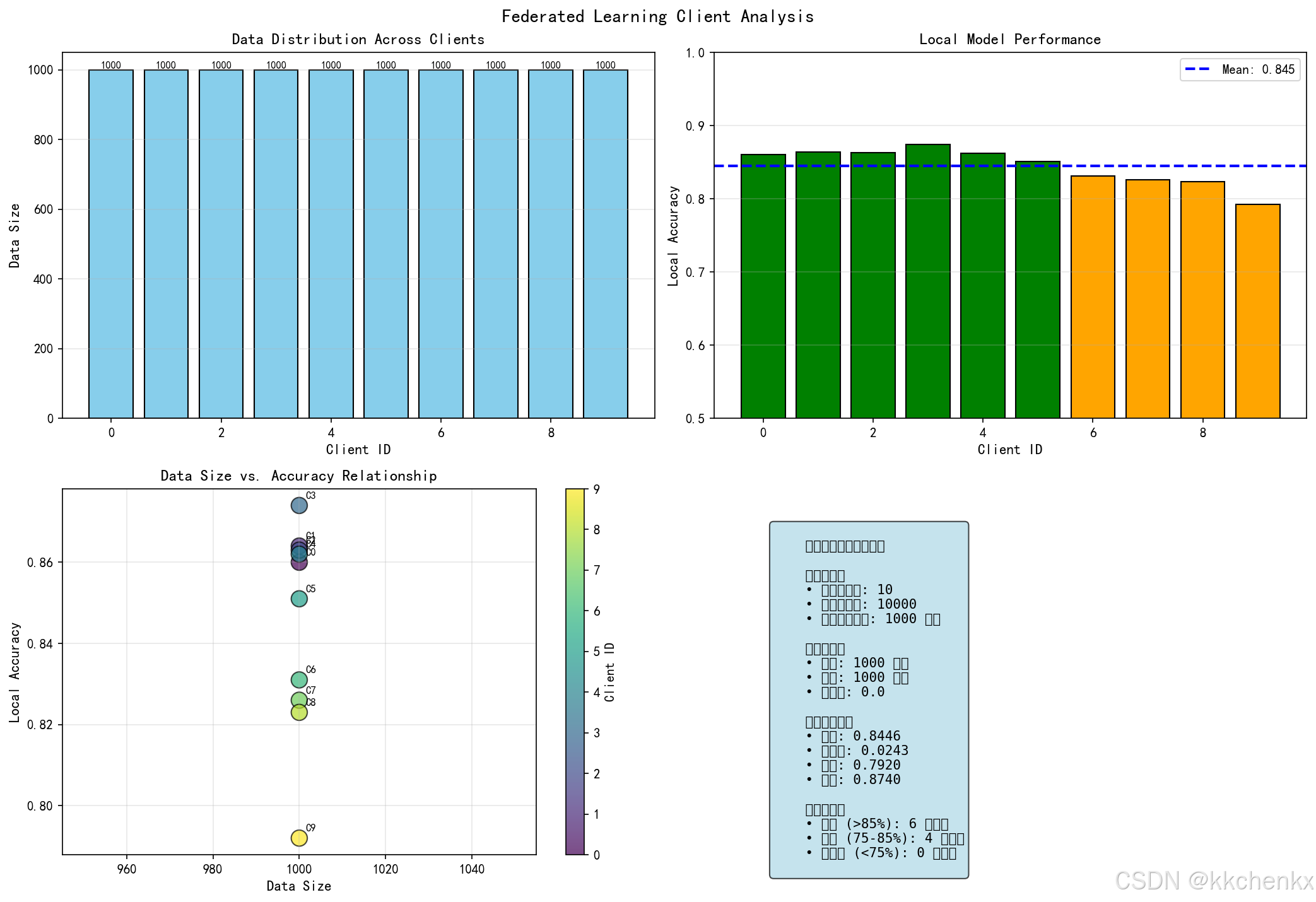
def plot_client_contribution(self, client_stats, save_path='client_contribution.png'):
"""绘制客户端贡献分析"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
client_ids = list(client_stats.keys())
data_sizes = [client_stats[c]['data_size'] for c in client_ids]
accuracies = [client_stats[c]['accuracy'] for c in client_ids]
# 数据分布
ax1 = axes[0, 0]
ax1.bar(client_ids, data_sizes, color='skyblue', edgecolor='black')
ax1.set_xlabel('Client ID')
ax1.set_ylabel('Data Size')
ax1.set_title('Data Distribution Across Clients')
ax1.grid(True, alpha=0.3, axis='y')
# 准确率分布
ax2 = axes[0, 1]
colors = ['green' if acc > 0.8 else 'orange' if acc > 0.6 else 'red'
for acc in accuracies]
ax2.bar(client_ids, accuracies, color=colors, edgecolor='black')
ax2.axhline(y=np.mean(accuracies), color='blue', linestyle='--',
linewidth=2, label=f'Mean: {np.mean(accuracies):.3f}')
ax2.set_xlabel('Client ID')
ax2.set_ylabel('Local Accuracy')
ax2.set_title('Local Model Performance')
ax2.legend()
ax2.grid(True, alpha=0.3, axis='y')
# 数据量vs准确率散点图
ax3 = axes[1, 0]
ax3.scatter(data_sizes, accuracies, s=100, alpha=0.6, c='purple')
for i, client_id in enumerate(client_ids):
ax3.annotate(f'C{client_id}',
xy=(data_sizes[i], accuracies[i]),
xytext=(5, 5), textcoords='offset points', fontsize=8)
ax3.set_xlabel('Data Size')
ax3.set_ylabel('Local Accuracy')
ax3.set_title('Data Size vs. Accuracy')
ax3.grid(True, alpha=0.3)
# 统计摘要
ax4 = axes[1, 1]
ax4.axis('off')
summary_text = f"""
Federated Learning Statistics:
Total Clients: {len(client_ids)}
Total Data Samples: {sum(data_sizes)}
Data Distribution:
• Mean: {np.mean(data_sizes):.1f}
• Std: {np.std(data_sizes):.1f}
• Min: {min(data_sizes)}
• Max: {max(data_sizes)}
Accuracy Statistics:
• Mean: {np.mean(accuracies):.4f}
• Std: {np.std(accuracies):.4f}
• Min: {min(accuracies):.4f}
• Max: {max(accuracies):.4f}
Performance Tiers:
• High (>80%): {sum(1 for a in accuracies if a > 0.8)} clients
• Medium (60-80%): {sum(1 for a in accuracies if 0.6 <= a <= 0.8)} clients
• Low (<60%): {sum(1 for a in accuracies if a < 0.6)} clients
"""
ax4.text(0.1, 0.9, summary_text, fontsize=10, va='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
8.5 完整仿真示例
def run_federated_shm_simulation():
"""运行联邦学习SHM仿真"""
print("=" * 60)
print("结构健康监测联邦学习仿真")
print("=" * 60)
# 1. 初始化联邦学习系统
num_structures = 10
input_dim = 4 # 特征维度
num_classes = 2 # 二分类(正常/损伤)
fl_system = FederatedSHMSystem(num_structures, input_dim, num_classes)
# 2. 训练(不带隐私保护)
print("\n【场景1】标准联邦学习")
history_standard = fl_system.train(num_rounds=100, use_dp=False)
# 3. 训练(带差分隐私)
print("\n【场景2】差分隐私联邦学习 (ε=1.0)")
history_dp = fl_system.train(num_rounds=100, use_dp=True, epsilon=1.0)
# 4. 隐私预算对比实验
print("\n【场景3】隐私预算对比")
epsilons = [0.1, 0.5, 1.0, 2.0, 5.0, 10.0]
dp_accuracies = []
for eps in epsilons:
print(f"\n测试 ε = {eps}")
history = fl_system.train(num_rounds=50, use_dp=True, epsilon=eps)
final_acc = history['global_accuracy'][-1] if history['global_accuracy'] else 0
dp_accuracies.append(final_acc)
print(f" 最终准确率: {final_acc:.4f}")
# 5. 可视化结果
print("\n【可视化】生成分析图表")
visualizer = FLVisualizer()
# 训练历史
visualizer.plot_training_history(history_standard, 'fl_standard_training.png')
visualizer.plot_training_history(history_dp, 'fl_dp_training.png')
# 隐私-效用权衡
visualizer.plot_privacy_utility_tradeoff(epsilons, dp_accuracies,
'privacy_utility_tradeoff.png')
# 客户端贡献
client_stats = {}
for i, client in enumerate(fl_system.clients):
client_stats[i] = {
'data_size': len(client.data.dataset),
'accuracy': client.evaluate(fl_system.server.global_weights)
}
visualizer.plot_client_contribution(client_stats, 'client_contribution.png')
print("\n" + "=" * 60)
print("仿真完成!")
print("=" * 60)
print("\n生成的可视化文件:")
print(" - fl_standard_training.png: 标准联邦学习训练过程")
print(" - fl_dp_training.png: 差分隐私联邦学习训练过程")
print(" - privacy_utility_tradeoff.png: 隐私-效用权衡曲线")
print(" - client_contribution.png: 客户端贡献分析")
if __name__ == "__main__":
run_federated_shm_simulation()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)