LLM基础,底层机制详解——速学指南
文章深入剖析了AI编程的核心原理,解释了大语言模型(LLM)如何通过“续写模式”生成代码,并详细阐述了其能力边界和常见误区。文章强调上下文供给、规则约束和验证机制的重要性,并提出了LLM选型矩阵和分层使用策略,旨在帮助开发者更精准地操控AI,避免盲目依赖模型能力,从而实现高效、可靠的AI编程。

你身边是不是也有这样的人——
一种人把 AI 当神仙,丢一句"帮我写个登录功能",代码出来了直接合入主分支,出了 Bug 一脸懵逼:“AI 写的啊,它怎么会错?”
另一种人把 AI 当骗子,试了两次发现生成的代码跑不起来,从此逢人就说:“AI 编程?割韭菜的,根本不能用。”
**说实话,这两种人都没搞明白一件事:AI 写代码到底是怎么工作的。**
你不需要成为 AI 专家,但你得知道——当你敲下一行 Prompt 的时候,模型背后发生了什么。它为什么有时候聪明得吓人,有时候又蠢得离谱?它到底"理解"代码吗?还是只是在瞎蒙?
这一章,我们就把这些事掰开揉碎了说清楚。不搞玄学,不讲数学公式,说人话、看本质、能落地。

一、LLM 究竟是什么?
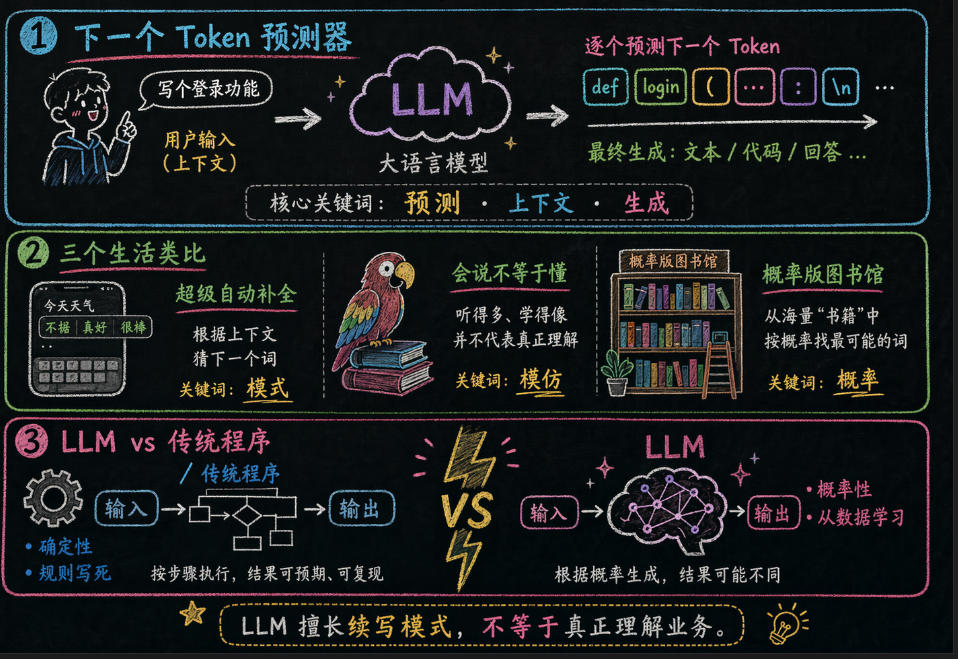
在聊 LLM 怎么写代码之前,你得先搞清楚它到底是什么。
1.1 一句话定义
**大语言模型(Large Language Model,简称 LLM)是一种基于深度学习的人工智能系统,通过在海量文本数据上训练,学会了理解和生成人类语言——包括编程语言。**
但这句话太学术了。说人话就是:它的本质是一个超大规模的"下一个词预测器"——给定前文,预测下一个最可能出现的 Token。
就像你手机输入法会建议”下一个词”,但 LLM 能补全整篇文章、整段代码。更稳妥地说,LLM 的训练目标确实是根据前文预测下一个 Token;但在大规模训练、表示学习和后续对齐之后,它会表现出一定的语义建模、模式归纳与任务执行能力。它不是像人类那样稳定地“理解”你的真实意图,但也不只是毫无结构地乱猜。
说白了,**LLM 会写代码,不是因为它像人类程序员那样理解业务,而是因为它极度擅长续写模式**。这也是它厉害和危险的地方:模式像的时候,它写得很顺;一旦你的业务规则、内部约束、最新 SDK 文档没喂给它,它就很可能一本正经地胡说。
你现在每天感受到的“AI 真会写代码啊”,底层其实不是“理解”,而是“高密度模式拟合 + 上下文条件生成”。
讲到这儿,很多人其实已经隐约明白了:原来 AI 写代码这事儿,核心不只是模型强不强,还包括你给它什么上下文、你怎么约束它、你有没有验证它。
1.2 三个生活类比,秒懂 LLM
如果觉得"下一个词预测器"还是太抽象,试试这三个类比:
| 类比 | 怎么理解 | 关键洞察 |
| 📱 超级自动补全 | 就像手机输入法的"下一个词建议",但 LLM 能补全整篇文章、整段代码 | 本质是预测,不是理解 |
| 🦜 读过万卷书的"鹦鹉" | 它能模仿书中的语言模式来回答问题,但并不真正"理解"含义 | 会说不等于懂 |
| 📚 概率版的全知图书馆 | 它记住了海量文本中的统计规律,但回答基于概率而非推理 | 概率高 ≠ 事实对 |
1.3 LLM 能做什么?不能做什么?
知道了 LLM 的本质,你就不会对它抱有不切实际的期望。来看看它的能力边界:
| ✅ LLM 能做什么 | ❌ LLM 不能做什么 |
| 📝 文本生成:写文章、写邮件、写代码、写文档 | 🕐 访问实时信息(除非联网工具辅助) |
| 📖 文本理解:摘要、翻译、问答、分类 | ✅ 保证输出的事实准确性(幻觉问题) |
| 💻 代码相关:补全、解释、Bug 修复、重构、测试生成 | ⚙️ 执行代码或操作文件(除非接入工具) |
| 🧠 推理与规划:数学推理、逻辑分析、任务拆解 | 🏢 真正"理解"业务上下文和隐含规则 |
| 🔧 工具调用:搜索网页、执行代码、操作文件、调用 API | 👤 替代人类的判断力和责任 |
1.4 LLM 与传统程序的本质区别
这是最需要理解的一点。LLM 和你平时写的程序,根本不是一类东西:
| 维度 | 传统程序 | LLM |
| 确定性 | 相同输入永远产生相同输出 | 相同输入可能产生不同输出(受 Temperature、采样策略影响) |
| 规则来源 | 规则由人编写 | 规则从数据中学习,隐含在千亿参数中 |
| 可解释性 | 可解释、可调试 | 黑盒模型,难以精确解释为何产生某个输出 |
| 错误类型 | Bug(逻辑错误) | 幻觉(编造看似合理但实际错误的内容) |
| 修复方式 | 改代码 | 改 Prompt / 换模型 / 给更多上下文 |
**记住这个核心区别:传统程序是"确定性"的,LLM 是"概率性"的。** 这就是为什么你不能像信任一个排序函数那样信任 AI 的输出——它每次给你的答案可能不一样。
1.5 关键术语速查
后面会反复提到这些术语,先混个脸熟:
| 术语 | 含义 | 类比 |
| Parameter(参数) | 模型内部的"旋钮",训练过程自动调整 | 大脑中的突触连接 |
| Token | 模型处理文本的最小单位 | 中文约 1 字 = 1-1.5 Token |
| Context Window | 模型单次可读写的最大 Token 数 | 一次能看多长的"白板" |
| Inference(推理) | 模型根据输入生成输出的过程 | 学生根据题目写答案 |
| Fine-tuning(微调) | 在预训练基础上用小数据集继续训练 | 大学生选专业深造 |
| Hallucination(幻觉) | 模型编造看似合理但实际错误的内容 | 学生"一本正经地胡说八道" |
1.6 为什么今天的 LLM 不只是“会续写”:训练与对齐
如果只说“LLM 是下一个 Token 预测器”,容易让人误以为它只是一个更大的自动补全器。这个说法抓住了训练目标,但没把今天模型的真实工程形态讲完整。
更完整的理解是:**预训练**让模型学会语言和代码中的统计规律;**指令微调(SFT)**让它更会按要求回答;**偏好对齐(如 RLHF、DPO)**让它更符合人类偏好与安全要 求;而工具使用训练、代码专项训练、多轮任务数据,又进一步强化了它在真实产品中的表现。
所以今天你看到的聊天模型、编码模型、推理模型,不只是“会续写”这么简单, 而是“预训练 + 对齐 + 工具链 + 产品约束”共同作用的结果。把这一层补上,后面再看代码生成、上下文窗口、模型选型,你就不会把“模型能力”和“系统能力”混成一回事。


二、一图看懂:LLM 吐出代码的完整流水线

知道了 LLM 是什么,接下来我们看一个最关键的问题:当你敲下一行 Prompt,到 AI 吐出代码,中间到底发生了什么?
理解这条流水线,你就能精准定位问题出在哪个环节——是输入不够好?还是模型没理解?还是输出有幻觉?
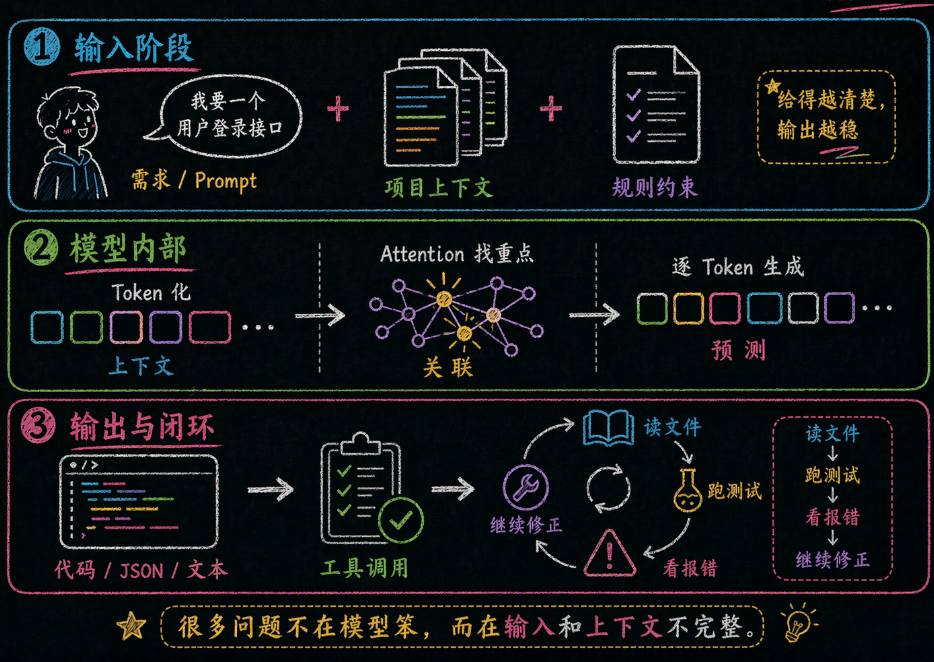
这个流程里最容易被忽略的,不是模型本身,而是最前面的两件事:你到底给了什么目标,以及你到底给了多少靠谱上下文。
你给一句“帮我加个登录功能”,和你给一句“用 Next.js App Router + NextAuth 实现邮箱密码登录,禁止改 API 签名,补 3 个边界测试”,后面整个生成链条已经不是一个难度了。
你也别小看“规则文件”和“上下文供给”。很多时候模型不是不会,而是你没把它放到“能做对”的位置上。比如你只给它一段报错,不给调用链;只给它局部组件,不给状态来源;只给它旧文档,不给新版 SDK。那它不瞎猜才怪。
**❌ 一个经典误区**
很多人把“模型效果差”直接归因到“模型笨”。真相往往是:你给了一个半瞎的任务定义,再让它在半瞎的上下文里硬猜。
走到流水线中间,模型会先把输入切成 Token,再通过注意力机制在整段上下文里找重点,然后一小步一小步预测下一个 Token。到了这儿,它生成的已经不只是文本了,也可能是 JSON、代码、SQL,甚至是一个工具调用请求。
如果它接的是带工具的 Agent 系统,这事儿还会继续:它会去读文件、跑测试、看报错,再把这些新结果重新塞回上下文里,继续下一轮生成。所以你现在看到很多 IDE Agent 很像“会自己干活”,本质上就是这条循环被接长了。
聊到这里,下一步就该拆最容易让人误会的一个词了:**大模型为什么叫“大”?**很多人第一反应就是“参数多”。这当然没错,但只说这一层,远远不够。



三、大模型凭什么叫"大"?
你可能好奇:为什么叫"大"语言模型?小模型不行吗?
答案是:**"大"不只是形容词,而是质变的起点。**大模型之所以叫"大",是因为它在四个维度上都大到了让人震撼的程度。你如果只把“大模型”理解成“模型文件更大”“参数更多”,那其实只看到了表层。参数量确实是最直观的一层,但它不是全部。
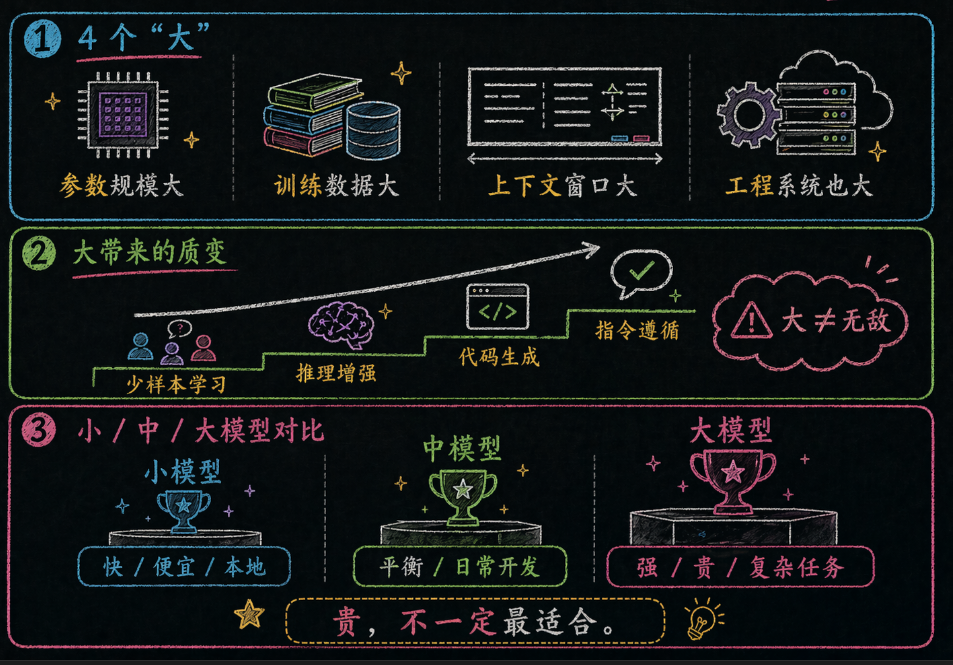
3.1、大模型的4个“大”

这 4 个“大”里,最容易被外行忽略的是最后那个:工程系统也大。因为一个能稳定服务几百万用户的大模型,不只是一个 checkpoint 文件那么简单,它背后还站着数据清洗、分布式训练、推理调度、缓存、对齐、安全策略、工具链集成这些极其重的工程体系。
参数越多,模型理论上能表示的模式越复杂;数据越多,它见过的语言、代码、框架和错误修复样本就越丰富;上下文窗口越大,它单次请求里能读进去的材料就越多;工程系统越重,它越可能在真实产品里稳定跑起来。
但别高兴太早,**大不等于无敌**。这句话你一定得记住。模型大了,边际收益会递减;上下文大了,不代表它就真的理解得更稳;最贵的模型,也一样可能在错误上下文里非常自信地说错话。
**⚠️ 别把“贵”误当“对”**
很多团队一上来就默认“最强模型全包”,结果是简单任务也烧大模型,复杂任务仍然翻车。问题不在预算不够,而在没有任务分层意识。
3.2 "大"带来了什么质变?
模型不是"大"了就一定好,但"大"到一定程度,会出现一种神奇的现象——**涌现能力(Emergent Abilities)**。
什么是涌现?简单说就是:小模型做不到、大模型突然能做到的能力。 就像水温到 100°C 突然沸腾——不是线性变热,而是质变。
典型的涌现能力包括:
🧠 **少样本学习**:给 2-3 个例子就能学会新任务
🔗 **思维链推理**:能一步步推理复杂问题
💻 **代码生成**:能写出完整的功能代码
📋 **指令遵循**:能精确遵守复杂的格式要求
关键洞察:这些能力不是被”编程”进去的,而是随着模型规模、数据质量、训练方法和对齐方式提升,逐步表现出更强的综合能力。工程上,人们常把这种非线性增强概括为“涌现”,但它并没有一个适用于所有模型的固定参数门槛。
另一个质变是**上下文学习(In-Context Learning)**——不需要重新训练模型,只需在 Prompt 中给出示例,模型就能学会新任务。这就是 Vibe Coding 的技术基础:**用自然语言"教"模型写代码。**
3.3 小模型 vs 大模型:实用对比
| 维度 | 小模型(<10B) | 中模型(10B-100B) | 大模型(>100B) |
| 部署方式 | 通常可本地运行 | 一般需要中端服务器 | 常见部署方式是云端 API 或高端集群 |
| 响应速度 | 通常较快(常见为亚秒级) | 一般较快(常见为百毫秒到数秒) | 通常更慢(常见为秒级) |
| 代码能力 | 通常更适合简单补全 | 一般可胜任功能开发、重构 | 通常更适合架构设计、复杂 Debug |
| 成本 | 通常成本一般成本可控 | 一般成本可控 | 通常成本更高 |
| 代表模型 | Phi-3, Qwen2-7B | Llama 3 70B, Mixtral | GPT-5.4, Claude 4.6 |
这个时候再往前走一步,你会发现另一个高频误解:很多人把所有模型都当成同一种东西。其实不是。聊天模型、推理模型、代码模型、Embedding 模型、工具型模型,干的活根本不是一回事。
四、大模型的种类:别把所有模型都当成一个桶



很多人以为"大模型"就是一个东西——其实不然。不同架构、不同训练方式、不同模态的模型,行为差异巨大。选错模型,就像用自行车跑高速——不是车不好,是用错了地方。
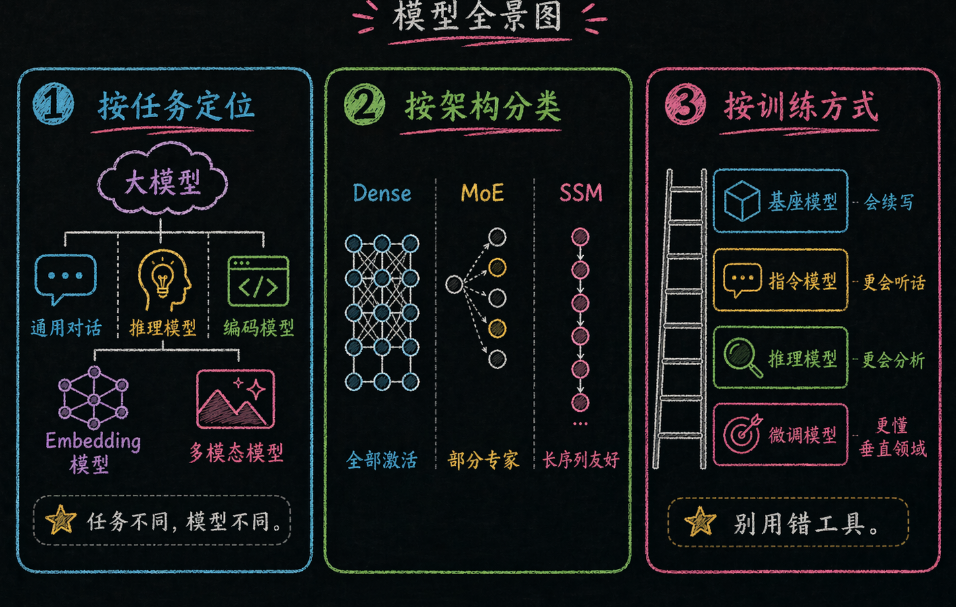
最常见的分类误伤,发生在下面两个地方。
一个是把 **Embedding 模型** 当成聊天模型。Embedding 模型本质上不是拿来“回答问题”的,而是拿来把文本变成向量,方便做检索、聚类和相似度匹配。OpenAI 的 Embeddings 文档就很明确:它的作用是把文本编码成向量,用于搜索、聚类、推荐、分类这些场景。
另一个,是把 **推理模型** 和 **编码模型**混为一谈。推理模型更擅长方案分析、约束权衡、长链路定位;编码模型更擅长把模式写出来、补全出来、重构出来。你让推理模型干所有脏活累活,成本会炸;你让偏编码的模型去做复杂架构权衡,它也容易一本正经地拍脑袋。
| 任务 | 更适合的模型类型 | 原因 |
| 批量格式转换 | 小模型 / 编码模型 | 模式稳定,没必要烧大模型 |
| 跨文件重构 | 强编码 + 强上下文模型 | 需要更稳的代码理解和执行 |
| 复杂根因分析 | 推理模型 | 需要多步分析和排除假设 |
| RAG 检索 | Embedding + 主模型 | 检索和生成是两件事 |
| 看设计稿 / 截图 | 多模态模型 | 要先看懂图,再谈生成代码 |
4.1 按架构分类:Dense vs MoE vs SSM
| 架构 | 工作方式 | 代表模型 | 优缺点 |
| Dense Transformer | 所有参数在每次推理时都被激活 | Claude 3.5 Sonnet, Llama 3 405B | ✅ 推理质量高 ❌ 计算成本大 |
| MoE(混合专家) | 每次推理只激活部分"专家"参数(通常 2/8) | GPT-4, Mixtral 8x7B, DeepSeek-V3 | ✅ 性价比高 ❌ 总参数量大 |
| SSM(状态空间模型) | 线性复杂度,适合超长序列 | Mamba, Jamba | ✅ 推理快 ❌ 代码能力仍在验证 |
直觉类比:MoE 就像一个公司有 8 个部门,每次任务只派 2 个部门参与——总人手多,但每次只动用一部分,省钱又高效。
4.2 按训练方式分类:基座 vs 指令 vs 推理 vs 微调
这是对你最有影响的分类维度——因为**你日常用的都是指令模型或推理模型**,基座模型不适合直接对话。
| 类型 | 行为特点 | 代表 | 用途 |
| 基座模型 | 续写文本,不一定会"听指令" | Llama 3 Base, Qwen2 Base | 微调的起点,不适合直接用 |
| 指令模型 | 能听懂指令、以对话形式交互 | GPT-5.4, Claude 4.6 | 日常对话、代码生成 |
| 推理模型 | 输出前进行内部推理,慢但准 | o1/o3, Claude 4.6 Extended Thinking | 复杂逻辑、架构设计 |
| 微调模型 | 在特定领域表现更好 | CodeLlama, MedPaLM | 垂直领域专业化 |
**💡 推理模型的代价**
推理模型(o1/o3/Claude 4.6 Extended Thinking)在输出前会进行内部"思考",准确率大幅提升,但代价是**更慢(思考时间 10-60 秒)、更贵(Token 消耗 3-10 倍)**。传统模型像"脱口而出",推理模型像"打草稿再回答"。
模型分类一旦想清楚,后面很多选型争论会立刻降温。但分类再清楚,也还没触到底。真正的底层,是它到底在“算”什么。Attention、Embedding、Token、Next Token Prediction 这些词如果一直是糊的,你后面所有判断都会悬空。
五、LLM 究竟在计算什么?
先来一个生活类比。你可以把模型想成一个非常非常厉害的“填空高手”。它手上不是一本标准答案,而是看过海量语料后形成的一种直觉:在当前上下文里,什么东西最可能接在后面。
这个“最可能接在后面”,就是所谓的 **Next Token Prediction**。注意,它预测的不是“下一个单词”这么简单,而是“下一个 Token”。
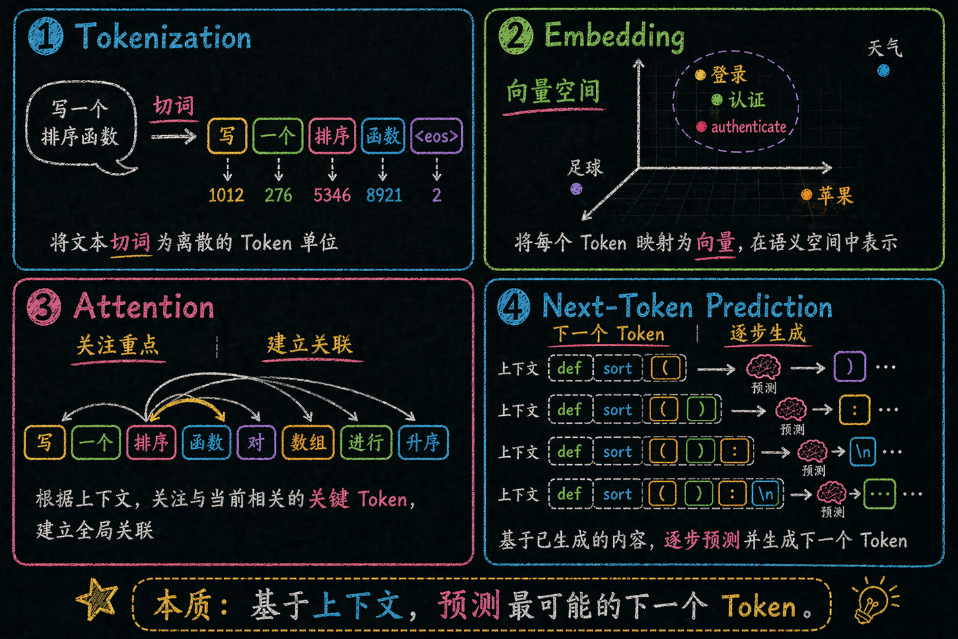
我们从更底层看一下第二章中的流水线,这样能更容易理解LLM的运行机制
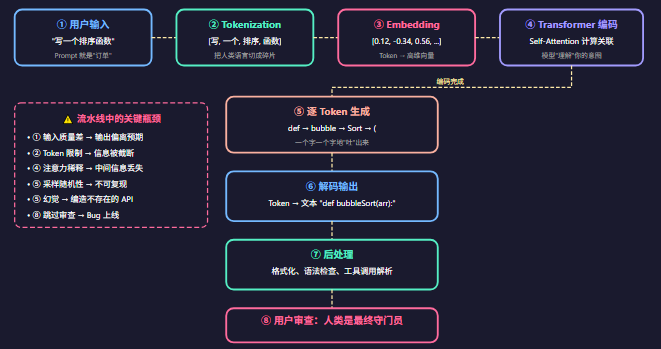
① 用户输入:你的 Prompt 就是"订单"
输入质量决定输出质量(Garbage In, Garbage Out)
结构化 Prompt vs 随意聊天,效果差异巨大
上下文供给:你附带的文件、规则、历史对话都算输入
**② Tokenization:把人类语言切成模型能消化的碎片**
中文:1 个汉字 ≈ 1-2 个 Token
英文:1 个单词 ≈ 1-1.5 个 Token
代码:缩进、特殊符号(=>, ::, ===)可能消耗多个 Token
**③ Embedding:把 Token 映射到"语义空间"**
每个 Token 被映射为一个高维向量(如 4096 维或 12288 维)
语义相近的词在向量空间中距离更近
这是 RAG(检索增强生成)的技术基础
**④ Transformer 编码:模型"理解"你的意图**
Self-Attention 机制:每个 Token 都可以"看到"所有其他 Token
多层堆叠:底层捕捉语法,高层捕捉语义
"Lost in the Middle":中间位置的信息容易被忽略
**⑤ 逐 Token 生成:模型一个字一个字地"吐"出来**
本质:每步预测下一个最可能的 Token
Temperature:控制随机性(0 = 确定性,1 = 创造性)
为什么看起来"思考"了?因为统计模式足够强大
**⑥ 解码输出:从概率分布到可读文本**
选择策略:贪心(选最高概率)vs 采样(按概率随机选)
流式输出:逐 Token 返回,用户看到"打字机效果"
**⑦ 后处理:工具链的"最后一公里"**
语法高亮、格式化
工具调用解析(Function Calling 的结构化输出)
**⑧ 用户审查:人类是最终的质量守门员**
AI 输出默认是"草稿",不是"成品"
必须经过:阅读理解 → 运行测试 → 安全审查 → 决定采纳
**⚠️ 流水线中的关键瓶颈**
每个环节都可能出问题。最常见的瓶颈是:**① 输入质量差**(模糊的 Prompt)、**④ 上下文不足**(缺少关键文件)、**⑤ 幻觉**(编造不存在的 API)。理解流水线,你就能精准定位问题出在哪。
5.1 模型眼中的世界:token
在模型眼里,你写的不是"代码",而是一串 Token。Token 不是单词,也不是单个字符,而是"子词级别"的片段。
英文:"Hello world" → 约 2-3 个 Token
中文:"你好世界" → 4 个 Token(一个字一个 Token)
代码:"function getUser()" → 约 5-6 个 Token
代码的 Token 切分有个特点:**缩进、特定语法符号(比如 =>、::)都容易被单独算成 Token**。这就是为什么 AI 有时候会把缩进搞错——因为在它的视角里,缩进符号和其他 Token 是平级的,没有"层级"的概念。
**⚠️ Token 和你的钱包直接相关**
API 计费是按 Token 算的。一次典型的代码补全约 700 Token,一次 Agent 多文件修改约 8,000 Token,一次长上下文对话(50 轮)可能消耗 100,000+ Token。理解 Token 不只是技术好奇,而是省钱技能。
再往里走,Token 会先被映射成向量。这一步你可以理解成:模型把人类看得懂的符号,翻译成自己能计算的数字坐标。语义相近的内容,通常会在这个高维空间里更靠近。Embedding 文档里也是这么定义的:嵌入向量会尽量保留内容和意义,相近内容在向量空间中也更近。来源
5.2 把文字变成坐标:Embedding
如果说 Token 是模型的"字母表",那 Embedding 就是它的"字典"。
Embedding 做的事情很简单:**把一段文字映射到一个高维向量空间**。说人话就是,给每段文字分配一个"坐标",语义相近的文字坐标也相近。
这有什么用?比如你想在 10 万行代码里找到和当前需求最相关的函数——靠关键词匹配是做不到的(你搜"用户登录",代码里可能写的是 authenticate())。但用 Embedding,模型能理解这两个词的语义是相近的,从而找到正确的函数。
这就是 **RAG(检索增强生成)**的基础。后面的章节会详细讲。
但这里有个很容易被忽略的事实:**Embedding 模型和聊天模型不是同一类模型。**你把一句话发给聊天模型,它会继续往下写;你把一句话发给 Embedding 模型,它通常只会回你一串数字,比如 [0.018, -0.224, 0.731, ...]。这串数字不能直接给人读,但特别适合让机器拿来做"相似度计算"。
**LLM 负责"说",Embedding 模型负责"找"。**一个擅长生成答案,一个擅长先把最相关的上下文捞出来。
5.2.1 Embedding 模型到底在输出什么?
它输出的是一个固定长度的向量。你可以把它理解成:模型把一段文本、代码、日志或者文档片段,压缩成了一组高维特征。这个特征不是人手工定义的,而是模型在训练时自己学出来的。
当两段内容语义接近时,它们在向量空间里的位置通常也更近。所以检索系统会用**余弦相似度**、点积或者欧氏距离,去比较"查询"和"候选内容"谁更像。不是逐字匹配,而是在比"意思像不像"。
| 维度 | 生成模型(LLM) | Embedding 模型 |
| 核心输出 | 自然语言、代码、结构化结果 | 向量表示 |
| 最擅长 | 回答、补全、解释、规划 | 检索、召回、聚类、相似度匹配 |
| 单独使用体验 | 可以直接对话 | 通常不能直接聊天,要配合向量库和 LLM |
| 在 Vibe Coding 里的角色 | 写代码、改代码、解释代码 | 把相关代码、文档、报错经验先找出来 |
5.2.2 它在代码场景里是怎么工作的?
如果你做的是代码助手、团队知识库、仓库问答、自动上下文补全,典型链路一般是这样的:
先把仓库里的代码、文档、报错记录、设计说明切成一段段合理片段
用 Embedding 模型把这些片段都编码成向量
把向量和原文、文件路径、符号名等元数据一起存进向量数据库
用户提问时,再把问题也编码成向量
系统在向量库里找出最相近的 Top-K 片段
最后把这些片段塞回 LLM,让它在带上下文的前提下生成答案
用户问题
↓
Embedding(问题)
↓
向量检索 Top-K
↓
相关代码 / 文档 / 日志片段
↓
LLM 结合上下文生成答案
这也是为什么很多 AI 编程工具看起来像是"它知道整个项目"。很多时候不是它真的把整个仓库都记住了,而是系统在背后先用 Embedding 找相关内容,再把这些内容喂给 LLM。
5.2.3 为什么 Embedding 对代码检索特别重要?
因为代码世界里,同一个意思经常会有完全不同的写法。你搜"支付回调验签失败",仓库里可能对应的是 verifySignature、webhookGuard,甚至是一段写在测试和注释里的说明。纯关键词检索很容易漏,Embedding 更容易把这些"意思相近、写法不同"的东西连起来。
而且代码不是孤立的。高质量检索不只是找一个函数本身,还要把它的调用方、测试、README、错误日志、Issue 记录一起召回。**Embedding 真正的价值,不是帮你找到一行代码,而是帮你找到一组足够让 LLM 开始可靠推理的上下文。**
**⚠️ 三个常见误区**
**误区 1:Embedding 模型越强,回答就一定越准。**不对。它只负责召回相关内容,最终答案还要看召回质量、上下文组织和 LLM 本身。
**误区 2:有了 Embedding,就不需要切分文档。**不对。切分太大,噪声多;切分太碎,上下文断裂。函数级、类级、章节级通常比按字符硬切更稳。
**误区 3:向量相似就等于事实正确。**也不对。相似度高只说明"像",不说明"真"。过期文档、旧版本 API、错误示例一样可能被召回。
5.2.4 真正在工程里要注意什么?
你如果后面要做自己的代码库问答系统,至少记住这四件事:
**切分要按语义结构来。**优先按函数、类、模块、文档章节切,不要粗暴地每 1000 个字符硬切一次。
**元数据要保留全。**文件路径、语言类型、仓库版本、符号名、更新时间,经常比正文还重要。
**检索后最好再重排。** Embedding 擅长大范围召回,精排可以再交给 reranker 或 LLM 做二次筛选。
**Embedding 模型版本要稳定。**同一批数据混用不同向量空间,检索结果会漂,索引往往需要重建。
**💡 Embedding 的常见应用**
🔍**语义搜索**:用自然语言搜代码,而不是精确匹配
📋 **文档去重**:找到语义重复的文档
📚 **知识库检索**:RAG 的核心组件
🔗 **代码相似性查找**:发现重复实现
常用模型:OpenAI text-embedding、Cohere Embed、Sentence Transformers
5.3 模型的"关注力":Attention
但光有向量还不够。因为“苹果 手机”里的“苹果”和“苹果 水果”里的“苹果”不是一回事。模型还得知道这些 Token 是按什么顺序出现的、它们彼此之间谁和谁更相关。这个时候,**Attention**上场了。
这是 Transformer 架构的核心。简单说:**模型在处理每个 Token 的时候,会"关注"输入中其他所有 Token,并计算它们之间的关联度。**
直觉理解就是——模型在读到某个词的时候,会回头看看前面哪些词跟它最有关。就像你在读代码的时候,看到一个变量名,会自动去找它在哪里定义的——Attention 机制就是在模拟这个过程。
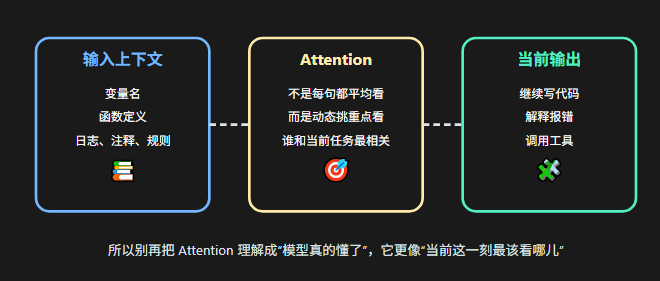
Transformer 论文里讲得很直接:它提出了一种完全基于注意力机制的架构,不再依赖 RNN 那种强串行结构;而且自注意力层在长距离依赖上路径更短、并行性更强。论文表 1 还专门对比了不同层类型的复杂度和最大路径长度。来源
如果你愿意看一眼公式,缩放点积注意力长这样:
Attention(Q, K, V) = softmax(QK^T / sqrt(dk)) V
别被公式吓到。可以把它拆成人话:
Q:我现在想找什么
K:每个位置各自代表什么标签
V:每个位置真正带着什么内容
softmax:给所有候选相关性打分,最后变成权重
但这里有个巨坑,叫做 **"Lost in the Middle"(中间迷失)**现象:
**❌ 长上下文的错觉**
模型号称支持 200K Token 的上下文,但你把 10 万行代码全塞进去,它反而会漏掉关键信息。因为**中间位置的信息最容易被忽略**。
就像你给一个人看一份 500 页的文档,他能记住开头和结尾,但中间的内容……大概率是模糊的。
所以最佳实践是:**重要信息前置,关键约束重复强调。**别把最重要的业务规则藏在上下文的第 80% 位置,模型会"看不见"的。
5.4 Next-Token Prediction:它不是在思考,是在猜
这是最需要理解的一点。
LLM 生成代码的本质是:**基于已经生成的内容,预测下一个最合适的 Token。**
它不是"思考完了整段代码再输出",而是"猜一个 Token,输出,再猜下一个"。这就是为什么它是"概率生成器"而不是"确定性编译器"。
有两个参数控制它的"创造力":
| 参数 | 作用 | 调低 | 调高 |
| Temperature | 控制输出的确定性 | 更保守、更可预测 | 更有创意、更不稳定 |
| Top-p | 限制候选词范围 | 只选最高概率的词 | 允许更多候选词参与 |
| Top-k | 限制候选词数量 | 只从 top-k 个词中选 | 更多词参与竞争 |
写代码的时候,Temperature 通常要调低(0.1-0.3),因为代码需要精确,不需要"创意"。写诗的时候才需要高 Temperature。
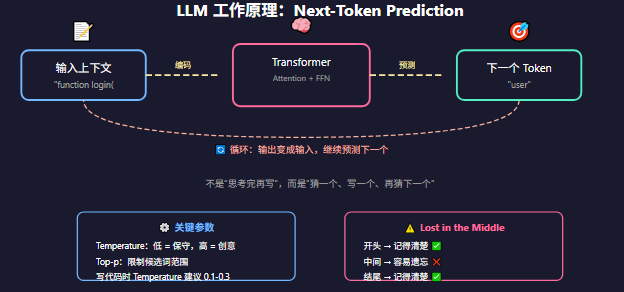
💡 核心洞察
LLM 不是"理解"了代码再写,而是一个 Token 一个 Token 地猜。它之所以看起来"理解"了,是因为训练数据量够大,让它学会了代码中的统计模式。
**这意味着:它不会"反思"自己的输出是否正确。**它生成了一段有 Bug 的代码,不是因为它是笨蛋,而是因为在它看来,这段代码的 Token 序列在训练数据中出现过类似的模式。
到这里,原理层的地基算是打下来了。下一步就该回答一个更现实的问题:这些能力不是天生就有的,那模型到底怎么被训练成今天这个样子的?这一步如果不讲清,很多人会把“预训练”“微调”“对齐”“工具调用”全混在一起。



六、大模型是怎么训练出来的?从海量数据到可对话、可编程
你可以把 LLM 的训练过程想成一个人从“读海量资料”到“学会按要求答题”,再到“学会别乱说话”,最后再到“学会用工具”的过程。顺序大致是这样的:
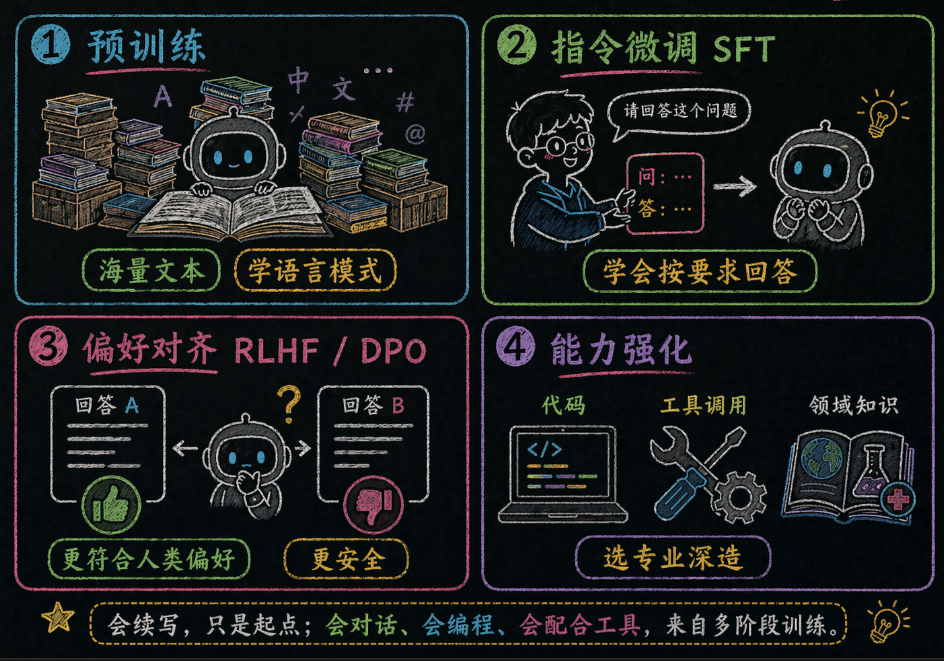
6.1 阶段一:预训练 —— “读万卷书”
预训练阶段,模型做的事情只有一个:**预测下一个 Token。**
它"读"了什么?公开网页(Common Crawl,占比 60-70%)、书籍、学术论文——以及最重要的,**数十亿行 GitHub 公开代码**。规模是数百亿到数万亿 Token。
在这个阶段,模型学会了:
📐 语法规则(if 后面要跟条件,for 后面要循环)
🏗️ 流行框架惯例(React 的组件写法、Express 的路由写法)
🧩 常见设计模式(Factory、Observer、Middleware 等)
对于代码能力来说,公开代码仓库特别关键。Codex 那篇经典论文就写得很直接:他们引入了一个在公开代码上微调的 GPT 模型,HumanEval 上 Codex 解出了 **28.8%** 的题,而 GPT-3 是**0%**,GPT-J 是**11.4%**。这说明高质量代码数据和代码定向训练,对“写代码”这件事影响非常大。来源
| 指标 | 结果 | 说明 |
| Codex on HumanEval | 28.8% | 代码定向训练后,代码生成能力明显提升 |
| GPT-3 on HumanEval | 0% | 同论文摘要给出的对照值 |
| GPT-J on HumanEval | 11.4% | 说明不是“只要会语言就会写代码” |
这张表不是在说“某个模型永远更强”,而是在提醒你:**代码能力不是白送的,它和训练数据、任务形式、评测方式强相关**。
但这时候的模型是个"自由人"——你问它问题,它可能答非所问;你让它写代码,它可能给你写一首诗。因为它只学会了"语言的统计模式",还没学会"听人说话"。
类比:一个读过万卷书但不会社交的"书呆子"。
6.2 阶段二:指令微调(SFT)—— "学会答题"
所以有了第二步:**指令微调(SFT - Supervised Fine-Tuning)**。
这一步用的是人工编写的高质量"指令-响应对"数据集。比如:
指令:"把这个 Python 函数改成异步版本"
响应:[正确的异步代码]
指令:"解释这段代码的作用"
响应:[清晰的中文解释]
这一步的目标很明确:**让模型学会"听指令",而不是自由发挥。**你说"输出 JSON",它就输出 JSON;你说"解释代码",它就解释代码——而不是自作主张给你写首诗。
但 SFT 有局限:数据质量和多样性决定上限,过度 SFT 会导致模型"死板",丧失灵活性。
这也是 InstructGPT 论文最重要的洞察之一:**把模型做大,不会自动让它更擅长遵循用户指令**。论文里有一个非常炸裂的结果:在人工偏好评测里,**1.3B 的 InstructGPT 输出,居然比 175B 的 GPT-3 更受标注者偏好**,虽然参数量差了 100 倍。来源
这件事的含义特别大:**“更大”不自动等于“更好用”**。如果一个模型没有经过足够好的指令微调和对齐,它可能很有知识,但不一定很配合。
6.3、阶段三:偏好对齐(RLHF/DPO)—— "学会做人"
SFT 后的模型可能输出有害、不诚实、无用的内容。所以需要**偏好对齐**——让模型学习"什么样的回答人类更喜欢"。
对齐的目标三个 H:**Helpful(有用)、Honest(诚实)、Harmless(无害)**。
主要方法有三种:
| 方法 | 怎么做 | 优缺点 |
| RLHF | 人类排序 → 训练奖励模型 → 强化学习优化 | ✅ 效果好 ❌ 流程复杂 |
| DPO | 跳过奖励模型,直接用偏好数据优化 | ✅ 更简单稳定 ❌ 数据要求高 |
| RLAIF | 用另一个强模型代替人类标注员 | ✅ 大规模低成本 ❌ 可能引入偏见 |
不同厂商的对齐策略不同,这直接影响了模型的行为风格。比如有的模型更"保守"(宁可不说也不能说错),有的更"积极"(先给了再说,对不对另说)。这种差异在代码场景中特别明显——**保守的模型遇到不确定的 API 会说"我不确定",积极的模型会直接编一个看起来很像的。**
这一步对编程尤其重要,因为编程场景里最烦人的不是它不会,而是它“像会”。你让它输出 JSON,它少一个括号;你让它修 bug,它顺手改了无关模块;你让它查 SDK,它把别的版本的方法签名搬过来。对齐做得更好,模型通常会更保守、更愿意承认不确定、更愿意遵守约束。
6.4 阶段四:能力强化训练 —— "选专业深造"
这是 2025-2026 年最大的突破点。模型在基础能力之上,进行专项强化:
**代码能力强化**:用高质量代码数据继续训练,学习代码风格、调试技巧、测试编写
**推理能力强化**:思维链(CoT)强化,o1/o3/Claude 4.6 系列的特点——生成代码前进行复杂 Debug 分析和架构推演
**工具调用训练**:Function Calling / Tool Use——模型学会输出结构化的工具调用请求,而不是硬答。2025-2026 年,工具调用能力已经成为模型的核心竞争点。这一步是 Vibe Coding 时代非常关键的分水岭。因为一个只能空想的模型,和一个会读文件、会跑测试、会调 API 的模型,完全不是一个物种。
工具调用训练的目标,就是让模型学会:
什么时候该去读文件,而不是瞎猜
什么时候该调用搜索或文档工具
什么时候应该返回结构化的工具调用请求
什么时候根据工具结果继续下一步
你今天在 IDE Agent 里看到的很多“像是在自己干活”的表现,本质上都来自这条链被训练得越来越顺了。
**⚠️ 别什么都用推理模型**
如果你只是让 AI 补全一个 for 循环,用推理模型就像请一个诺贝尔奖得主帮你写购物清单——杀鸡用牛刀,又慢又贵。
推理模型的工作方式:传统模型"脱口而出",推理模型"打草稿再回答"。代价是更慢(思考时间 10-60 秒)、更贵(Token 消耗 3-10 倍)。
训练讲完,我们终于可以回到最关心的问题了:既然模型见了这么多代码、又会注意力、又做了对齐、还会调工具,那它为什么还是会翻车?这个地方,才是你真正该有边界感的地方。

七、为什么 LLM 会写代码,但又经常写得像那么回事地翻车?



先说结论:LLM 最擅长的是高重复、强模式、低歧义的代码任务;最容易翻车的是隐藏规则多、状态链长、边界复杂、风险高的任务。
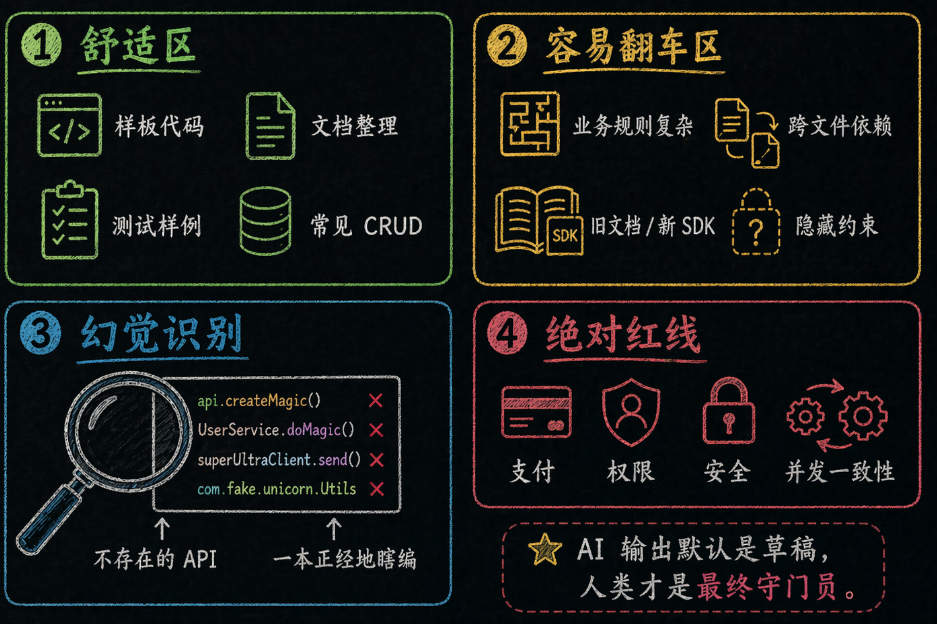
7.1 绝对舒适区:这些地方它可以信任
**✅ AI 的强项清单**
**样板代码**:for 循环、class 定义、API 路由、CRUD 操作——训练数据中重复出现了亿万次
**高频设计模式**:Factory、Observer、Middleware——GitHub 上被反复实现的模式
**语言转译**:Python ↔︎ JavaScript ↔︎ Go——模型"读"过大量多语言实现
**基础单测生成**:Happy path + 常见边界条件
**文档整理**:函数文档字符串、README、API 文档——结构化文本生成是看家本领
7.2 容易翻车区:这些地方你必须盯紧
**❌ AI 的弱项清单**
**隐式业务规则**:模型不知道你公司的特殊规则。比如"订单金额超过 1 万需要主管审批"
**长链路状态依赖**:跨多个模块的修改容易遗漏。比如改了 API 忘了改前端类型定义
**新发布的冷门 API**:训练数据截止后的新知识,模型要么不知道,要么瞎编
**复杂边界条件**:并发竞争、资源泄漏、极端输入——训练数据中样本很少
**❌ 问题代码:只相信模型写出来的“看起来对”**
export async function updateRole(userId: string, role: string) {
await db.user.update({ where: { id: userId }, data: { role } });
return { ok: true };
}
**✅ 修复代码:把权限、审计、边界一起补上**
export async function updateRole(
operatorId: string,
userId: string,
role: Role
) {
const operator = await requireAdmin(operatorId);
if (operator.id === userId) throw new Error("禁止修改自己的角色");
await db.$transaction(async (tx) => {
await tx.user.update({ where: { id: userId }, data: { role } });
await tx.auditLog.create({
data: {
actorId: operatorId,
action: "user.role.update",
targetId: userId,
payload: { role }
}
});
});
return { ok: true };
}
上面这个对比很典型。模型在第一版里不是不会写更新逻辑,而是它没法自动知道你系统里还有“只有管理员能改角色”“不能改自己”“必须记审计日志”这些隐含规则。这就是**AI 会写代码,但不天然知道你业务的真相**。
7.3 幻觉的代码体现:怎么识别 AI 在"瞎编"
幻觉(Hallucination)在代码场景的表现特别隐蔽——因为**看起来工整的代码不一定能跑**。常见的幻觉体现有:
| 幻觉类型 | 具体表现 | 怎么发现 |
| 🔴 捏造 API | 调用不存在的属性或方法 | 运行时报 undefined is not a function |
| 🔴 捏造依赖 | 推荐不存在的 NPM 包名 | npm install 报错 404 |
| 🔴 生搬硬套 | 用错误的异常处理方式处理所有错误 | 代码审查时发现 |
| 🔴 供应链风险 | 推荐恶意同名篡改包 | 依赖扫描工具检测 |
npm install
报错 404
**⚠️ 供应链投毒风险**
模型推荐不存在的包已经够糟糕了,更可怕的是它可能推荐一个**名字很像但恶意的包**。比如你想要 lodash,它可能推荐 lodsh——这个包里可能藏着挖矿脚本。所以**任何 AI 推荐的依赖包,安装前必须去 npmjs.com 确认存在且可信。**
真实翻车场景
**🚨 案例一:新 SDK 刚发,你让 AI 直接接入**
结果它把上一版本的方法签名写上去了,代码补得飞快,运行时报一屏参数错误。根因很简单:**训练知识是旧的,你又没喂官方文档**。这不是模型“蠢”,是工作流有洞。
**🚨 案例二:你把关键约束埋在超长上下文中间**
模型前面读了 8 万 Token,后面也读了 8 万 Token,中间那句“支付金额必须以分为单位存储”被它看漏了。最后页面是好的,账务是错的。典型的**Lost in the Middle** 式翻车。
**🚨 案例三:为了让测试变绿,模型偷偷改了测试**
这事儿在 Agent 工具里太常见了。模型如果没被明确约束“不要改变测试语义”,它很可能会用最快的方式把 CI 变绿,而不是把问题修对。
7.4 高风险区域:绝对不能放手的红线
**🚨 这些区域必须人工审查,100% 不能交给 AI 独立完成**
🔒 **安全逻辑**:认证、授权、加密实现
💰 **支付流程**:金额计算、事务一致性
🔑 **权限判断**:RBAC、ABAC 实现
⚡ **并发一致性**:锁、竞态条件处理
🐌 **性能瓶颈**:N+1 查询、内存泄漏
建议直接在规则文件(CLAUDE.md、.cursorrules)里标注"禁区",让 AI 知道哪些地方不能碰。
**💡 一句话总结**
**样板代码放心交,业务逻辑盯着搞,安全权限亲手搞。**
记住这个原则,你就已经超越了 80% 的 Vibe Coder。


八、上下文窗口与记忆:长 ≠ 好

到这里你可能会有一个问题:既然模型有这么多弱项,那我把整个项目的代码都喂给它,让它全面了解上下文,不就行了吗?
想法很好,但现实骨感。
这是现在 AI 编程里最容易被误会的一块。大家都听说过上下文窗口越来越长,动不动几十万 Token,甚至更多。然后很多人就自然得出一个错误结论:窗口大了,模型就更“记得住”。
真相不是这样。
OpenAI 关于 conversation state 的文档里写得很明确:**上下文窗口是单次请求里可用的 Token 总量**,里面包含输入 Token、输出 Token,某些模型还包含 reasoning tokens。来源

8.1 长上下文的三大错觉
**错觉一:窗口越大,理解越深。**
错。模型号称支持 200K Token 的上下文,但这不意味着它真的能"理解"200K Token 的内容。信息密度和理解质量通常成反比——塞进去的东西越多,模型越容易"看花眼"。
**错觉二:模型"记住"了上次告诉它的信息。**
错。模型没有长期记忆。每次对话对它来说都是"从零开始",除非你使用了记忆功能或规则文件。它不会自动记住你上一次告诉它的业务规则。
**错觉三:塞入整个仓库,AI 就能全面理解。**
大错特错。把整个 src/ 目录丢给模型,反而会导致它**找错修改位置、混淆类名、遗漏关键依赖**。因为上下文中的噪声会稀释信号——100K Token 的上下文 ≠ 100K Token 的理解力。
所以你今天在项目里遇到的很多奇葩现象,其实都能解释:
为什么你明明贴了规范,它还是没照做
为什么你把整个仓库都喂进去,它反而开始改错文件
为什么长会话一到后半程,模型越来越散
因为问题从来都不是“喂少了”这么简单,很多时候反而是“喂太多、但组织得太差”。
**❌ 错误喂法:把整个仓库一股脑塞进去**
请阅读整个项目,修复订单页面的金额显示问题,并顺便优化性能。
**✅ 更稳的喂法:目标 + 约束 + 入口 + 直接依赖**
目标:修复订单详情页金额显示错误。
约束:金额必须以“分”为存储单位,不允许改 API 签名。
入口文件:app/orders/[id]/page.tsx
直接依赖:lib/money.ts, api/order.ts
验证:订单 123 的 1099 分应显示为 ¥10.99
你会发现,好的上下文工程本质上就是一句话:**不是给得越多越好,而是给得越准越好**。
8.2 最佳实践:怎么给上下文最有效
**✅ 上下文供给三原则**
**重要信息前置**:把最关键的目标和约束放在最前面
**结构化呈现**:用列表、表格、代码块,不要大段自然语言
**模块化供给**:按模块/任务给上下文,不要一次性给整个仓库
类比一下:你给新员工 onboarding,会直接把 10 万行代码丢给他让他自己看吗?不会。你会先给他讲项目概览、模块划分、关键入口——**给 AI 也一样。**
8.3 记忆机制的三种形态
| 类型 | 生命周期 | 典型应用 | 适合存什么 |
| 当前会话 | 会话结束即消失 | 对话上下文 | 当前任务的中间信息 |
| 结构化 RAG | 持久化 | 向量数据库 | 大型文档库、历史 Issue |
| 规则文件 | 持久化 | CLAUDE.md, .cursorrules | 项目约束、编码规范 |
8.4 上下文窗口的实际限制
不同模型的上下文窗口差异很大——从 8K 到 200K+ Token。但有几个关键点你需要知道:
📊**实际可用窗口通常略小于标称值**——需要保留空间给输出
🧠 **大窗口 ≠ 好理解**——窗口越大,信息组织越重要
⚡ **窗口越大,推理越慢**——Attention 计算量随上下文长度二次增长
实际建议:即使有大窗口,也要精简上下文,只给必要信息。小窗口(8K-32K)只能处理单文件,中窗口(32K-128K)可以处理中型项目,大窗口(128K-200K+)可以处理大型项目——但信息组织更重要。
聊到这里,理论、训练、边界、上下文,我们都铺完了。最后就差最现实的一块:回到你每天工作的地方,模型到底该怎么选?什么时候该上大模型,什么时候用小模型更香?



九、编码模型到底该怎么选?别再只看排行榜了
很多团队刚开始接 AI 编程,选型方式特别像买显卡:哪个更强、哪个更贵、哪个榜单高,就上哪个。这个思路在今天已经不够用了。
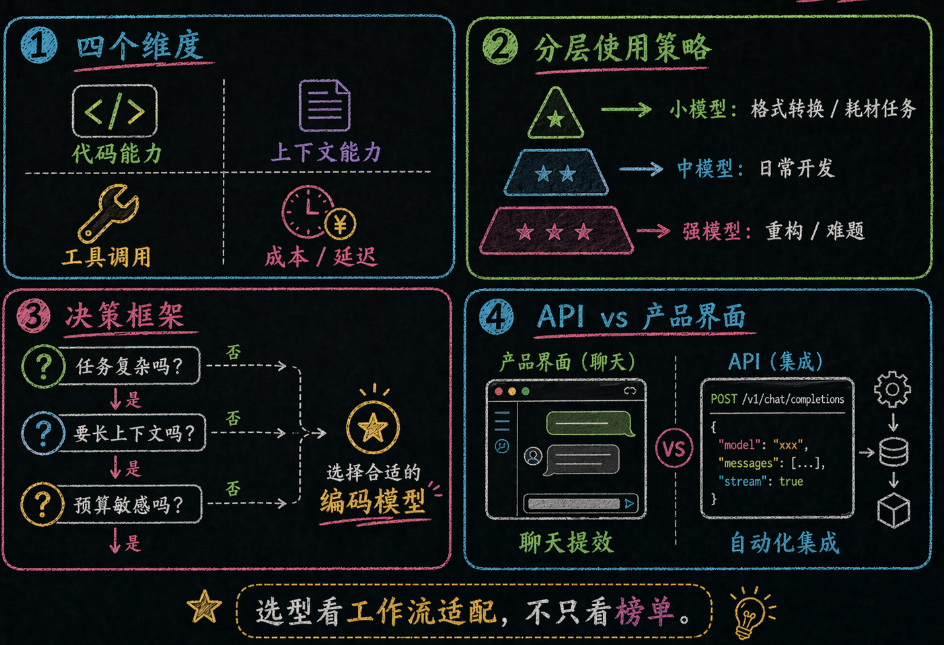
因为模型选型真正要匹配的,不是抽象的“强弱”,而是具体任务。
**✅ 一个实用判断法**
你别问“哪个模型最强”,你要问:**我这件事是补全、重构、调试、架构、检索、还是多模态理解?**
如果是日常补全、简单格式转换、批量改写,优先小模型,快而且便宜;如果是跨文件重构、复杂 bug、架构权衡,优先推理更稳的强模型;如果要看截图和界面稿,那就是多模态模型的活;如果你在做 RAG,别忘了主模型之外,你还需要 Embedding 模型配合。
至于排行榜,它不是没用,但只能当参考。像 SWE-bench 这种基准很好,因为它把真实 GitHub issue 和修复 patch 拉进来评估,SWE-bench Verified 还专门做了 **500 个工程师确认可解的问题**。这类基准能帮助你理解模型的代码能力边界。来源
但你千万别迷信它。**榜单高,不等于适合你当前的工程流**。同一个模型,放进不同 IDE、规则系统、上下文供给方式里,效果可能差一大截。
很多榜单上的头部模型,彼此分差往往并不大;但一旦放进不同 IDE、规则系统、检索策略和 Agent 工作流里,体感差异可能会被明显放大。
所以选型的核心不是"哪个模型最强",而是"哪个模型 + 哪个工作流最适合我的任务"。
9.1 选型矩阵:关注四个维度
| 维度 | 看什么 | 为什么重要 |
| 编码能力 | HumanEval、SWE-bench | 决定代码输出的正确率 |
| 上下文能力 | 支持 Token 数、长文本理解质量 | 决定能不能处理大项目 |
| 工具调用能力 | Function Calling 准确性 | 决定能不能接入外部工具 |
| 成本/延迟 | 每百万 Token 价格、响应时间 | 决定日常使用的经济性 |
9.2 分层使用策略
聪明的团队不会"万事皆用最强模型",而是分层使用:
| 层级 | 模型 | 场景 | 成本 |
| L1 快模 | Haiku / GPT-4o-mini | 补全、格式转换、分类 | $ |
| L2 中模 | Sonnet / GPT-5 | 功能开发、重构 | $$ |
| L3 大模 | Opus 4.6 | 架构设计、复杂 Debug | $$$ |
| L4 多模态 | Gemini | 设计稿转代码 | $$ |
**💡 省钱技巧**
用 Opus 做 JSON 格式转换,每次等 30 秒、花 $0.5——这是在烧钱。这种任务交给 Haiku,0.5 秒搞定,花 $0.001。
**模型选对的省钱效果,远比单纯换便宜模型显著。**更进一步,可以通过 Router/Dispatcher 自动根据任务复杂度选择合适的模型。
**总结就是:大模型负责难题,小模型负责耗材,规则系统负责兜底,测试负责验真。**
9.4 选型决策框架
给你一个实操框架,别再看排行榜选模型了:
**列任务清单**:你日常开发中哪些任务想让 AI 帮忙?
**测试 2-3 个模型**:用真实任务测,不要用排行榜
**对比输出质量**:准确率、可读性、可维护性
**评估成本**:每次会话的 Token 消耗 × 单价
**考虑合规**:团队的技术栈偏好、数据安全要求
9.5 API vs 产品界面:用对工具事半功倍
同一个模型,你在 ChatGPT 网页上用和在 Cursor 里用,体验完全不一样。这不是错觉,而是因为**产品界面和 API 是两个完全不同的东西**。
打个比方:API 就像买食材自己做饭,产品界面就像去餐厅点菜。同样的食材(模型),体验天差地别。
| 场景 | 推荐方式 | 原因 |
| 日常编码、调试 | 产品界面(Cursor、Claude Code) | 开箱即用,上下文自动管理 |
| CI/CD 代码审查 | API | 需要嵌入自动化流程 |
| 批量文档生成 | API | 并发处理,成本可控 |
| 快速原型验证 | 产品界面(Bolt.new、Lovable) | 最快速度看到效果 |
| 团队知识库集成 | API + RAG | 需要自定义检索逻辑 |
**⚠️ API 的隐性成本**
API 看起来更便宜(没有产品溢价),但你需要自己实现:上下文管理、错误处理、流式输出、工具调用解析。这些开发成本加起来,可能比产品界面的订阅费还高。
**最聪明的做法是混合使用**:产品界面做日常开发 + API 做自动化流程。
走到这里,我们就大致明白了AI 写代码这件事,不是魔法,不是搜索,不是编译,也不是“它突然理解了你的世界”。它是一个在海量模式上训练出来的生成系统,会在上下文里找重点、一步步往后猜;它能非常像一个程序员,但它并不天然知道你的业务真相。

十、总结:从"盲盒玩家"到"精准操控"



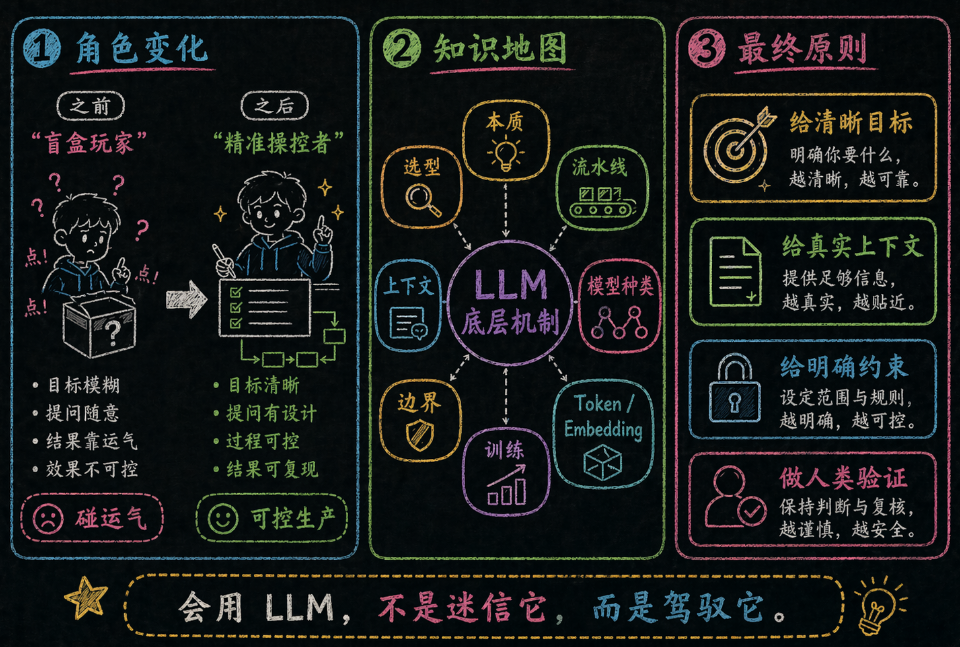
如果这篇你只记住一句话,我希望是这句:
**LLM 会写代码,是因为它极度擅长续写模式;LLM 会翻车,是因为模式再像,也替代不了真实上下文、业务边界和验证机制。**
这也是为什么我一直觉得,Vibe Coding 最怕的不是“模型不够强”,而是人类太快把判断权全交出去了。你不需要真的去训练一个大模型,但你一定得知道它是怎么工作的。因为只有这样,你才知道什么时候该信它,什么时候该拦它,什么时候该补文档,什么时候该上测试,什么时候该把任务拆小。
说到底,未来高水平开发者的分水岭,不是“会不会用 AI”,而是:
会不会定义清楚问题
会不会组织清楚上下文
会不会给模型设边界
会不会用验证把“看起来对”变成“真的对”
**✅ 本章真正的升级点**
从今天开始,你再看到 AI 写代码,不会只说“这模型真牛”。你会开始问:它现在依赖了什么上下文?它是在模式续写,还是在用工具补真相?这个任务到底适不适合交给它?
这才叫真正理解 LLM。不是会背 Transformer、RLHF、Token 这些词,而是你终于知道:**AI 编程这件事,为什么能成,为什么会翻车,又为什么工程方法比“咒语”更重要。**
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。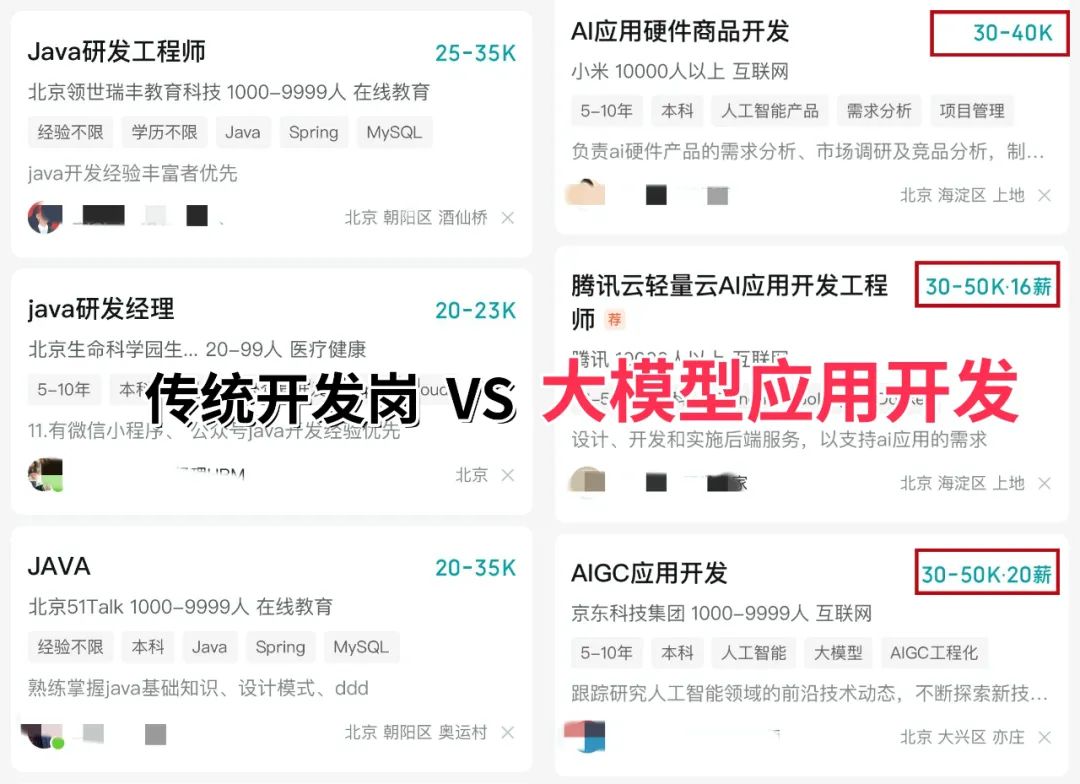
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。
👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线
2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。
3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
5、面试试题/经验
【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码
适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇

3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献164条内容
已为社区贡献164条内容

所有评论(0)