OpenClaw 小龙虾爆火后,我为何坚持用纯 Java 自研一套企业级浏览器自动化平台?
OpenClaw / 小龙虾火了之后,我为什么还用纯 Java 做了一套浏览器自动化平台?
系列: SmartClaw:从零构建企业级浏览器自动化平台(第①篇)
日期: 2026-04-30
标签: Java / Spring Boot / Playwright / 浏览器自动化 / 架构设计 / OpenClaw / Playwright Java / 企业级自动化 / Agent调度
适合谁看: 架构师、后端负责人、自动化平台开发者

前言
OpenClaw / 小龙虾 爆火之后,很多人重新开始关注 Browser Agent、网页自动化和“让 AI 直接操作浏览器”这件事。
热度当然是好事,它把大家的注意力重新拉回到了一个很重要的问题:
如果浏览器真的是通用操作界面,那企业到底应该怎么把这件事做成一套能交付、能治理、能长期运行的平台?
某政务项目里,有 3 个人每天的工作就是:登录系统 A,复制数据,粘贴到系统 B,点提交。每天重复 200 次,耗时 5 小时。
这件事,机器 10 秒就能做完。
市面上的 RPA 工具(UiPath、影刀、来也)要么年费昂贵,要么私有化部署繁琐,要么不支持定制开发。于是我们自己动手,用纯 Java 构建了一套企业级浏览器自动化平台——SmartClaw。
本文是系列第①篇,不讲“概念架构图”,而讲这套系统在真实项目里为什么会长成现在这个样子。
如果你刚好是从 OpenClaw / 小龙虾 这个热点点进来的,那这篇文章更想回答的是另一个问题:
从“会操作浏览器”走到“企业能落地交付”,中间到底还差什么?
这篇你会看到 3 个核心问题:
- 为什么不用商业 RPA,而是自己做一套平台
- 为什么执行节点一定要放到客户电脑本地
- 为什么调度模型选 Pull,不选 Push / MQ 直推
一、核心目标
在不使用大模型的前提下,建设一套可在客户电脑安装并常驻运行的浏览器自动化平台,支持:
- 通用化:录制一次,多场景复用,模板版本化管理
- 稳定性:失败可恢复、可追踪、可回放截图
- 可交付:可安装、开机自启、可运维
- 可治理:审计日志、安全控制、幂等保护
这几个目标看起来普通,但它们直接决定了后面的技术选型。
比如:
- 因为要 常驻客户电脑,所以 Agent 不能依赖公网入站能力
- 因为要 多场景复用,所以必须有中间 DSL 层,而不是录屏回放
- 因为要 可治理,所以模板不能“录完即上线”,必须有草稿/审核/发布状态
二、技术核心选型对比
在动手撸代码之前,我们对比了市面上主流的技术栈,最终定了纯 Java + Playwright 这套组合。为什么这么选?
2.1 自动化核心引擎:Playwright vs Selenium vs Puppeteer
| 维度 | Selenium | Puppeteer | Playwright (SmartClaw的最终选择) |
|---|---|---|---|
| 稳定性 | 易因异步加载失败,常需 sleep |
限 Chromium 流畅 | 自带 Auto-waiting,智能等待元素可用,高稳定 |
| 隔离性 | 弱,多开实例沉重 | 强 | BrowserContext 毫秒级创建/销毁,环境纯净 |
| 语言支持 | Java/Python/C#等全栈 | Node.js 绝对主力 | Java/Node.js/Python/C# 全线支持且更新同步 |
Playwright 胜出关键点:它的 Auto-waiting 机制简直是企业级应用的救星。政企内部老系统常常充斥着各种异步渲染、延迟加载和千奇百怪的弹窗。使用 Playwright,你可以大幅减少硬编码在代码里的等待耗时,极大增强任务跑通率和执行速度。
2.2 开发语言及后端层:Java (Spring Boot) vs Python vs Node.js
- Python生态(如 OpenClaw)的优劣:AI和脚本生态极好,但真到了实施交付阶段,处理不同机器的环境隔离(虽然有 Docker,但很多客户机仅限 Windows 绿软)、与客户现存微服务体系做鉴权打通时,常常阻力很大。
- Java 的工程化优势:政企/金融领域客户最安心的技术栈。易于集成审批流、AD 域。把 Agent 打包成 Spring Boot Fat Jar 或是使用 GraalVM 编译为原生机器码,部署时只需一个 JRE 或者直接运行,把交付复杂度降到最低。
2.3 Agent 通信架构:Pull (拉取) vs Push (直推/WebSocket)
- Push 模型(MQ直推/WebSocket长连接)的痛点:服务端必须能主动"找"到 Agent Node。这意味着要么暴露防火墙入站端口(安全团队直接否决),要么维持 WebSocket 长连接(在严格的内网策略下也常被拦截)。某真实项目中,客户 IT 策略只允许 80/443 出站,所有非标准端口一律封禁,Push 方案第一轮就被安全评审打了回来。
- Pull 模型(短轮询/长轮询)的好处:Agent 只要能发外抛请求(Outbound)即可,完全不需要公网入站。无论网络环境多复杂——NAT、企业防火墙、代理上网——只要 Agent 能访问 Server 端 HTTP 端口就能正常工作。SmartClaw 采用 3 秒级轮询拉取任务,单个请求仅 KB 级开销,轻量且天生适用于各种复杂的企业局域网环境。
三、三面解耦架构
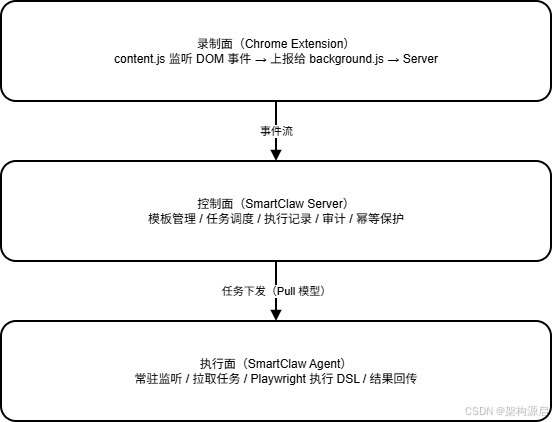
SmartClaw 的整体架构分为三个面,职责严格解耦。
如果只看图,很容易觉得这是“标准的前后端 + Agent 结构”。
真正的关键不在于分了三个面,而在于边界划分是否对:
- 录制面只负责“采集事实”,不负责解释动作
- 控制面负责“把事实变成模板、把模板变成任务”
- 执行面只负责“按照模板在本地把动作做出来”
这个边界划分的好处是:
任意一层变化,不会把另外两层一起拖下水。
┌─────────────────────────────────────────────────────────┐
│ 录制面(Chrome Extension) │
│ content.js 监听 DOM 事件 → 上报给 background.js → Server │
└───────────────────────────┬─────────────────────────────┘
│ 事件流
┌───────────────────────────▼─────────────────────────────┐
│ 控制面(SmartClaw Server) │
│ 模板管理 / 任务调度 / 执行记录 / 审计 / 幂等保护 │
└───────────────────────────┬─────────────────────────────┘
│ 任务下发(Pull 模型)
┌───────────────────────────▼─────────────────────────────┐
│ 执行面(SmartClaw Agent) │
│ 常驻监听 / 拉取任务 / Playwright 执行 DSL / 结果回传 │
└─────────────────────────────────────────────────────────┘
3.1 控制面:SmartClaw Server
Spring Boot 服务,核心模块:
| 模块 | 职责 |
|---|---|
RecorderService |
事件入库、Session 管理 |
EventToDslService |
事件序列 → DSL YAML 自动转换 |
TemplateService |
模板 CRUD、版本发布、签名校验 |
TaskDispatchService |
任务下发、幂等保护、租约管理 |
RunService |
执行记录、步骤状态、产物管理 |
AgentService |
心跳检测、在线状态、版本管理 |
如果映射到当前项目代码,可以直接对应到这些类:
- 录制转模板:
EventToDslService - 模板发布:
TemplateService - 任务下发:
TaskDispatchService - 运行记录:
RunService
这几个类共同组成了“控制面”。
数据库 MySQL 8.x,核心表:
task_template -- 模板(DRAFT/REVIEWED/PUBLISHED 版本流)
task_instance -- 任务实例(含幂等键)
task_run -- 执行记录
task_step_run -- 步骤执行明细
agent_node -- Agent 节点注册表
recorder_session -- 录制会话
recorder_event -- 录制事件原始数据
这里最重要的不是表多,而是两条约束:
task_instance.uk_idempotency_key—— 防止同一业务请求重复创建任务recorder_event.uk_session_seq—— 防止录制事件重复写入
也就是说,幂等不是靠应用层口头约定,而是压进数据库约束里的。
3.2 执行面:SmartClaw Agent
独立 Spring Boot Jar,常驻客户机器(macOS launchd / Windows WinSW)。
核心工作循环:
每 3s 拉取任务(Pull 模型,无需公网暴露 Agent)
↓
解析 DSL YAML
↓
Playwright 启动 Chromium,逐步执行
↓
每步完成上报 ServerApiClient
↓
全部完成 → finishRun → 关闭浏览器
对应的核心类是:
AgentScheduler:定时心跳、拉任务、重放失败上报ExecutionEngine:解析 DSL,逐步执行,做超时兜底FillExecutor/ClickExecutor/NavigateExecutor:动作执行器
这套设计本质上是在做一件事:
把“一个任务”拆成“一个个可报告、可重试、可截图的步骤”。
关键配置(application.yml):
smartclaw:
agent:
id: ${SMARTCLAW_AGENT_ID:agent-local-001}
heartbeat-interval-ms: 30000 # 每 30s 心跳
pull-interval-ms: 3000 # 每 3s 拉任务
task-timeout-ms: 300000 # 单任务最长 5 分钟
artifact-dir: ./artifacts # 截图/Trace 存储目录
browser-headless: false # 开发期显示浏览器
post-execution-delay-ms: 5000 # 完成后保持浏览器 5s 便于观察
3.3 录制面:Chrome Extension
三个文件:
content.js:注入目标页面,监听click/input/change/select四类事件background.js:接收 content.js 消息,批量上报给 Serverpopup.js:控制录制开始/停止,展示状态
这部分的核心价值不只是“把动作录下来”,而是把用户动作变成结构化、可评分的事件流。
否则后端根本没法做:
- selector 评分
- 输入去抖
- 变量抽取
- DSL 自动生成
3.4 代码亮点:核心调度链路
架构讲完了,来看两段真实代码。下面这段来自 TaskDispatchService.dispatch(),是幂等调度最核心的一段——同一个 idempotencyKey 绝不会重复创建任务:
@Transactional(rollbackFor = Exception.class)
public DispatchResult dispatch(DispatchRequest request) {
// 幂等检查:同一 idempotencyKey 不会重复创建任务
if (request.getIdempotencyKey() != null) {
TaskInstance existing = taskMapper.selectByIdempotencyKey(
request.getIdempotencyKey());
if (existing != null) {
log.info("Idempotent reuse: key={}", request.getIdempotencyKey());
TaskRun existingRun = runMapper.selectByInstanceId(
existing.getInstanceId());
return DispatchResult.builder()
.instanceId(existing.getInstanceId())
.runId(existingRun != null ? existingRun.getRunId()
: existing.getInstanceId())
.idempotentReused(true)
.build();
}
}
// 创建实例 + 创建 Run 记录(省略)
// ...
}
而 AgentController 则直接暴露了 Pull 模型的两个核心端点:
@RestController
@RequestMapping("/api/agent")
@RequiredArgsConstructor
public class AgentController {
private final AgentService agentService;
private final TaskDispatchService taskDispatchService;
@PostMapping("/heartbeat") // Agent 心跳上报
public Result<Map<String, Object>> heartbeat(
@RequestBody HeartbeatRequest request) {
agentService.heartbeat(request);
return Result.success(Map.of(
"ok", true,
"serverTime", Instant.now().toEpochMilli()));
}
@PostMapping("/pull") // Agent 拉取待执行任务
public Result<List<TaskPayload>> pull(
@RequestBody PullRequest request) {
List<TaskPayload> payloads = taskDispatchService.leaseNext(
request.getAgentId(),
Math.max(1, request.getMaxTasks()));
return Result.success(payloads);
}
}
两个类放在一起看,就是"控制面"最核心的两个能力:幂等调度和 Pull 模型通信。代码对应的正是架构图中 Server ↔ Agent 之间的两条带箭头的线。
四、关键接口设计
| 接口 | 方向 | 说明 |
|---|---|---|
POST /api/recorder/events |
Extension → Server | 批量上报录制事件 |
POST /api/agent/heartbeat |
Agent → Server | 心跳保活 |
POST /api/agent/pull |
Agent → Server | 拉取待执行任务 |
POST /api/runs/{runId}/steps |
Agent → Server | 上报步骤执行结果 |
POST /api/runs/{runId}/finish |
Agent → Server | 上报任务完成状态 |
这 5 个接口看起来简单,但已经把系统最核心的主链路闭环起来了:
录制 -> 生成模板 -> 发布模板 -> 创建任务 -> Agent 执行 -> 结果回传
五、基于当前架构,还能扩展到哪些场景?
SmartClaw 的核心能力是:“录制 → DSL 模板 → 调度 → Agent 执行 → 结果回传”。这条链路一旦稳定,很多看起来"不像自动化"的业务场景其实都可以接入。
下面按场景类型逐一展开。
5.1 跨系统数据搬运(最直接的落地场景)
现状:系统 A 有数据,系统 B 需要录入,两者之间没有接口对接,只能人工复制粘贴。
SmartClaw 能做什么:
系统 A(数据源)
↓ DSL navigate + assertTableContains 抓取数据
↓ 写入 ExecutionContext 变量
系统 B(目标系统)
↓ navigate + fill + clickRole 按模板填写
↓ waitText 确认提交成功
目前 ExecutionContext 已经支持变量传递,FillExecutor 支持 ${varName} 插值。只需在 DSL 层扩展一个 extractText 动作,即可把从页面抓到的值注入后续步骤变量,实现完整的跨系统搬运闭环。
典型行业:政务、医疗、教育(几乎所有无接口的老系统对接需求)。
5.2 自动化巡检 & 系统监控
场景:检查某个 Web 系统的核心页面是否可以正常访问、关键数据是否异常。
扩展点:
assertText/assertTableContains已经支持断言——失败即告警- 新增 DSL 动作
extractText,把抓到的指标值写入执行记录 - 配合
task_step_run历史数据,可以做趋势对比、阈值告警
# 巡检模板示例
steps:
- action: navigate
params: { url: "${monitorUrl}" }
- action: assertText
params: { selector: ".status-badge", expected: "正常" }
- action: screenshot # 留证截图
- action: extractText # (新增动作)提取指标值写入变量
params: { selector: ".user-count", varName: "activeUsers" }
应用场景:平台运营巡检、SLA 合规检查、政务系统可用性检测。
5.3 接入大模型(AI Agent 增强)
这是最有想象空间的方向。当前 SmartClaw"不使用大模型"是为了降低不确定性,尽快交付。但其架构对 LLM 接入是完全友好的:
当前链路:
人工录制 → DSL YAML → 调度 → Agent 执行
接入 LLM 后的升级链路:
自然语言需求("帮我创建一个新部门叫xx")
↓ LLM 理解意图
自动匹配或生成 DSL 模板
↓
SmartClaw 调度执行(执行层不变)
↓
结果回传 + 截图留证
关键在于:执行层(Agent + Playwright + 幂等 + 截图)完全不需要改动。LLM 只负责"把自然语言翻译成 DSL",其余由成熟稳定的执行引擎接管。
这也是 SmartClaw 和"纯 AI Agent"方案的本质区别:
SmartClaw 是让 AI 的输出变得可审计、可回滚、可兜底的基础设施。
以上 3 个场景(数据搬运、自动化巡检、AI Agent 增强)覆盖了 SmartClaw 最核心的扩展方向。它们的共同点是:执行引擎和幂等调度层不需要重写,只需要在 DSL 层扩展动作、在 Server 层扩展调度策略。这正是把复杂度封装进系统架构里,而不是每次都靠"堆人力"解决的意义所在。
六、OpenClaw / 小龙虾热潮之后,企业到底该看什么?
| 维度 | SmartClaw | 商业 RPA | OpenClaw |
|---|---|---|---|
| 部署方式 | 私有化,Agent Jar | SaaS 或复杂部署 | 私有化 |
| License 费用 | 无 | 高昂年费 | 无 |
| 开发语言 | Java(可定制) | 专有脚本语言 | Python |
| 执行引擎 | Playwright(成熟稳定) | 各家私有 | Playwright |
| 录制转脚本 | 自动生成 DSL YAML | 可视化录制 | 手写脚本 |
| 幂等保护 | 内置 uk_idempotency | 需自行实现 | 无 |
| 执行产物 | 截图+Trace 自动留证 | 部分支持 | 手动截图 |
如果只看热点讨论,大家最容易被吸引的是:
- 谁更像通用智能体
- 谁的演示更酷
- 谁能让模型直接操作浏览器
但如果你站在企业交付视角,真正该看的其实是:
- 能不能私有化部署
- 能不能被现有 Java / Spring 团队接住
- 能不能对模板、任务、执行结果做治理
- 能不能把客户机常驻执行、心跳、幂等、留证做完整
这里补一句很重要的话:
SmartClaw 不是要证明“自己比所有 RPA 都强”,而是针对一个很具体的约束集做最优解:
- 预算有限
- 目标系统没接口
- 需要私有化
- 希望 Java 团队能完全掌控
- 希望首条流程能尽快落地,不把复杂度全部压在模型层
在这个问题域里,它比“买一套大而全平台”更合适。
换句话说:
OpenClaw / 小龙虾让更多人开始关注“浏览器智能体”这件事;而SmartClaw更关心的是,怎样把这件事变成一套企业能真正上线的交付方案。
七、完整架构图(Mermaid)
如果你把这张图和代码一起看,会发现它并不是“为了画图而画图”:
AgentScheduler.heartbeat()对应心跳箭头AgentScheduler.pollAndExecute()对应拉任务箭头ExecutionEngine.reportStep()/finishOnce()对应结果回传箭头
八、下期预告
下一篇:《Chrome Extension 实战:精准录制用户操作,自动生成自动化脚本》
重点讲清楚:
content.js如何捕获 DOM 事件- Selector 优先级打分算法:
data-testid>aria-label>#id>.class - 如何把原始事件序列转成置信度可量化的 DSL YAML
项目开源地址:[SmartClaw(待发布)]
如果本文对你有帮助,欢迎点赞、收藏、转发。你的团队在浏览器自动化落地中遇到的最大坑是什么?是异步渲染、弹窗拦截,还是跨系统数据对不齐?欢迎在评论区交流 👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)