(一)OpenDriveVLA 环境部署与推理实践
前言
OpenDriveVLA 是当前自动驾驶领域最受关注的视觉语言动作(Vision-Language-Action)模型之一,基于 Qwen2.5 系列大模型构建,能够直接从多模态输入(图像、文本指令)输出端到端的驾驶轨迹。
本文将带你从零完成 OpenDriveVLA 的环境部署与推理验证,重点解决国内模型下载受限、分布式启动报错等问题。
一、系统与硬件要求
- 操作系统:Ubuntu 20.04/22.04(推荐)
- 显卡:NVIDIA GPU(推荐 16GB + 运行 0.5B 模型)
- CUDA 版本:12.2(与官方指定PyTorch 2.1.2兼容)
- Python 版本:3.10(官方指定,避免依赖冲突)
二、模型下载(国内镜像高速方案)
直接从 Hugging Face 官网下载模型受限,本文使用国内镜像站hf-mirror.com实现满速下载。
2.1 配置国内镜像环境变量
# 临时生效(仅当前终端)
export HF_ENDPOINT=https://hf-mirror.com
# 永久生效(推荐,写入bashrc)
echo "export HF_ENDPOINT=https://hf-mirror.com" >> ~/.bashrc
source ~/.bashrc
2.2 安装 Hugging Face 命令行工具
pip install -U huggingface_hub
2.3 获取HuggingFace token
2.4 下载预训练模型
huggingface-cli download \
--resume-download \
OpenDriveVLA/DriveVLA-Qwen2.5-0.5B-Instruct \
--local-dir checkpoints/DriveVLA-Qwen2.5-0.5B-Instruct \
--local-dir-use-symlinks False
参数说明:
-
resume-download:支持断点续传,网络中断后重新运行即可继续
-
local-dir-use-symlinks False:禁用软链接,下载文件直接保存到指定目录
三、模型推理运行(两种方式)
3.1 推荐:一键脚本运行(最稳定)
官方提供了完整的推理 + 评估脚本,自动处理所有路径和环境变量,是最不容易出错的方式。
# 确保在项目根目录执行
cd OpenDriveVLA
# 运行推理脚本(参数1:模型路径 参数2:使用的GPU数量)
bash scripts/eval_drivevla.sh checkpoints/DriveVLA-Qwen2.5-0.5B-Instruct 1
脚本会自动完成以下操作:
– 创建带时间戳的唯一输出目录;
– 用 torchrun 正确启动分布式推理;
– 保存推理结果到output/模型名称/时间戳/results/plan_conv.json;
– 自动运行评估脚本;
3.2 手动分步运行(适合调试)
如果需要单独调试推理流程,可按以下步骤执行,注意绝对不能直接用 python 启动。
步骤 1:设置 Python 路径(否则提示找不到projects路径)
export PYTHONPATH=$PWD:$PYTHONPATH
步骤 2:用 torchrun 启动推理
torchrun --nproc_per_node=1 drivevla/inference_drivevla.py \
--num-workers 4 \
--bf16 \
--model-path checkpoints/DriveVLA-Qwen2.5-0.5B-Instruct \
--output output/plan_conv.json
关键注意事项:
- 必须用torchrun而非直接python启动(原因见下文原理部分)
- –nproc_per_node=1表示使用 1 张 GPU,多卡环境改为对应数量即可
- –output必须指定具体的 JSON 文件路径,不能是文件夹(否则会报错)
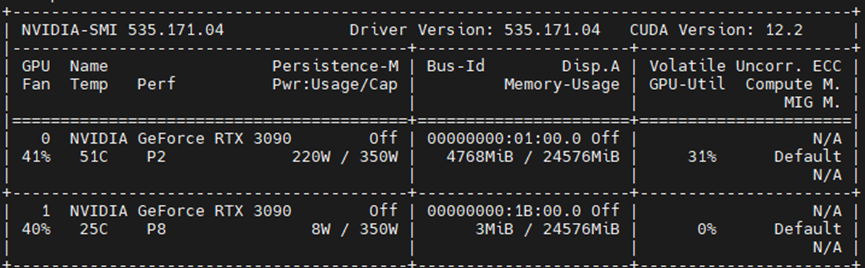
3.3 单卡3090推理时显存占用
四、为什么必须用 torchrun 启动?
torchrun是 PyTorch 官方提供的分布式任务启动器,在 LLM 推理和训练中扮演着关键角色,其作用在不同场景下有所不同:
4.1 训练场景:数据并行
– 每张显卡复制一份完整模型;
– 不同显卡处理不同批次的数据;
– 最后汇总梯度更新模型参数;
核心目的:加速训练过程;
4.2 推理场景:模型并行
– 大模型无法完整加载到单张显卡;
– 将模型的不同层(注意力层、全连接层等)拆分到多张 GPU;
– 数据在多张卡之间流转完成推理;
核心目的:解决单卡显存不足问题;
4.3 直接用 python 启动的问题
OpenDriveVLA 的推理代码内置了 DeepSpeed 分布式支持,直接用python运行会:
– 触发 DeepSpeed 自动初始化流程;
– 尝试检测 MPI 环境;
– 最终抛出ModuleNotFoundError: No module named 'mpi4py’错误;
而用torchrun启动会正确初始化 PyTorch 原生分布式环境,绕过 MPI 依赖,让推理正常运行。
五、总结
本文完整介绍了 OpenDriveVLA 的环境部署与推理流程,核心要点总结:
- 国内下载模型必须配置HF_ENDPOINT=https://hf-mirror.com镜像;
- 推理必须用torchrun启动,绝对不能直接用python;
- 测试模型只需跑推理,可跳过评估步骤避免数据集依赖;
CSDN 标签建议:自动驾驶、大模型、OpenDriveVLA、视觉语言模型、环境部署、PyTorch、torchrun、Hugging Face
本文为CSDN原创,转载请注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)