嵌入模型(Embedding)彻底吃透:原理、选型、接入与 RAG
·
引言
前面所讲的大语言模型都是生成式模型,根据我们的问题生成答案。
接下来我们所讲的嵌入模型(一种表示型模型)。
比如给一段话:你好,我叫XXX。这一段话可以通过嵌入模型表示成另一种形态[0.3,0.2,0.7...],可以称之为向量。即为输入文本生成一个最佳,富含语义的数值表示。
因此由于文本经由嵌入模型生成了向量,我们则可以通过数学来度量语义!
“喜悦”:【0.6,-0.4....】
"愉快":【0.6,-0.2...】
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
什么是嵌入模型?
大语言模型是生成式模型 。它理解输入并生成新的文本(回答问题、写文章)。它内部实际上也使用嵌入技术来理解输入,但最终目标是“创造”。
而嵌入模型(Embedding Model)是表示型模型。它的目标不是生成文本,而是为输入的文本创建一个最佳的、富含语义的数值表示(向量)。
由于计算机天生擅长处理数字,但不理解文字、图片的含义。嵌入(Embedding)的核⼼思想就是将 人类世界的符号(如单词、句子、产品、用户、图片)转换为计算机能够理解的数值形式(即向量, 本质上是一个数字列表),并且要求这种转换能够保留原始符号的语义和关系。
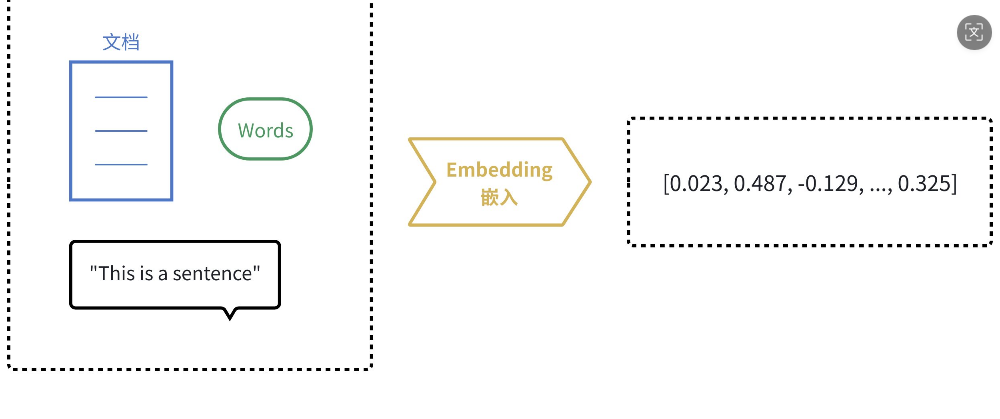
我们可以把它想象成一个翻译过程,把人类语言“翻译”成计算机的“数学语言”。
结论:既然是“数学语言”,那么我们可以用数学的方式来比较向量,从而达到【度量语义】的的!
用数学方式度量语义:
1.欧式距离:直线距离越短,相似度越高
2.余弦相似度:只关注向量在方向上的差异,在文本和语义的世界里,“方向”代表“含义”,“长度”代表“文本的长度”,“词汇的多少”
维度越高,能捕捉的语义复杂度就越强。
嵌入模型则可以根据相似性进行匹配,而不是基于精确匹配的查询(MySQL)
嵌入模型应用场景
根据嵌入的特性,由此延伸出了许多嵌入模型在 AI 应用的使用场景:
语义搜索(Semantic Search)
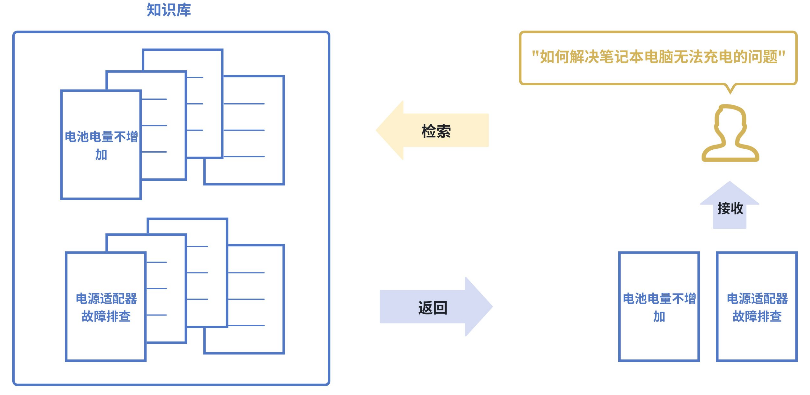
传统搜索:依赖关键词匹配(搜 “ 苹果 ” ,只能找到包含 “ 苹果 ” 这个词的文档)。
语义搜索:则能将查询和文档都转换为向量,通过计算向量间的相似度来找到相关内容,即使文档中没有查询的确切词汇也能被检索到。如下图所示,即使知识库中并未直接出现 “ 笔记本电脑无法充电” 这个词组,语义搜索也能通过向量相似度精准地找到该文档。
检索增强生成(Retrieval-Augmented Generation, RAG)
这是当前大语言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌入模型在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。
例如:一家公司的内部客服机器人接到员工提问: “ 我们今年新增加的带薪育儿假政策具体是怎样的?” 系统会首先使用嵌入模型在公司的最新人事制度文档、福利更新备忘录等资料中进行语义搜索,找到关于 “今年育⼉假规定” 的具体条款,然后将这些【条款】和【问题】一起提交给 LLM, LLM 便能生成一个准确、具体的摘要回答,而非仅凭其内部训练数据可能产生的过时或泛泛的答案。
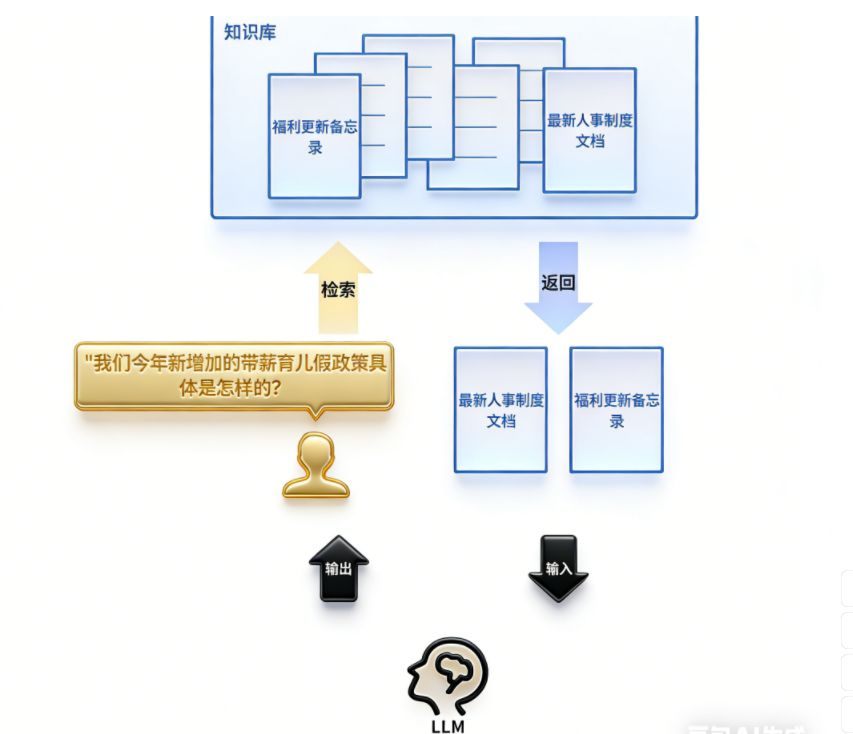
实际上,嵌入模型主要负责【检索】部分,而将问题与答案整合就是【增强(提示词)】部分,打包一起发给LLM最终生成结果的流程则是【生成】部分,因此整个流程被称为【检索增强生成】
推荐系统(Recommendation Systems)
将用户(根据其历史行为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的用户,其向量会接近;相似的物品,其向量也会接近。通过计算用户和物品向量的相似度,就可以进行精准推荐。
例如:一个流媒体平台将用户 A(喜欢观看《盗梦空间》和《哈利波特》)和所有电影都表示为向量。系统 发现用户A 的向量与那些也喜欢《盗梦空间》和《哈利波特》的用户向量很接近,而这些用户普遍还喜欢 《星际穿越》。尽管用户A从未看过《星际穿越》,但通过计算用户向量与电影向量的相似度,系统会将这部电影推荐给用户 A。
异常检测(Anomaly Detection)
正常数据的向量通常会聚集在一起。如果一个新数据的向量远离大多数向量的聚集区,它就可能是一个异常点(如垃圾邮件、欺诈交易)。
例如:一个信用卡交易反欺诈系统,通过学习海量正常交易记录(如金额、地点、时间、商户类型等特征的向量)形成了“正常交易”的向量聚集区。当一笔新的交易产生时,系统将其转换为向量。如果该向量出现在“正常聚集区”之外(例如,一笔发生在通常消费地之外的高额交易),系统则会将其标记为潜在的欺诈交易并进行警报。

主流的嵌入模型
text-embedding-3-large (OpenAI):OpenAI 最强大的英语和非英语任务嵌入模型。默认维度
3072,可降维如1024维;输⼊令牌⻓度支持为8192
Qwen3-Embedding-8B (阿里巴巴) :开源模型,支持100+种语言;上下文长度 32k;嵌入维度最
高 4096,支持用户定义的输出维度,范围从 32 到 4096。推理需要一定的GPU计算资源(例如, 至少需要16GB以上显存的GPU才能高效运行)。
gemini-embedding-001 (Google) :支持100+种语言;默认维度 3072,可选降维版本:1536维
或 768维;令牌长度支持为2048
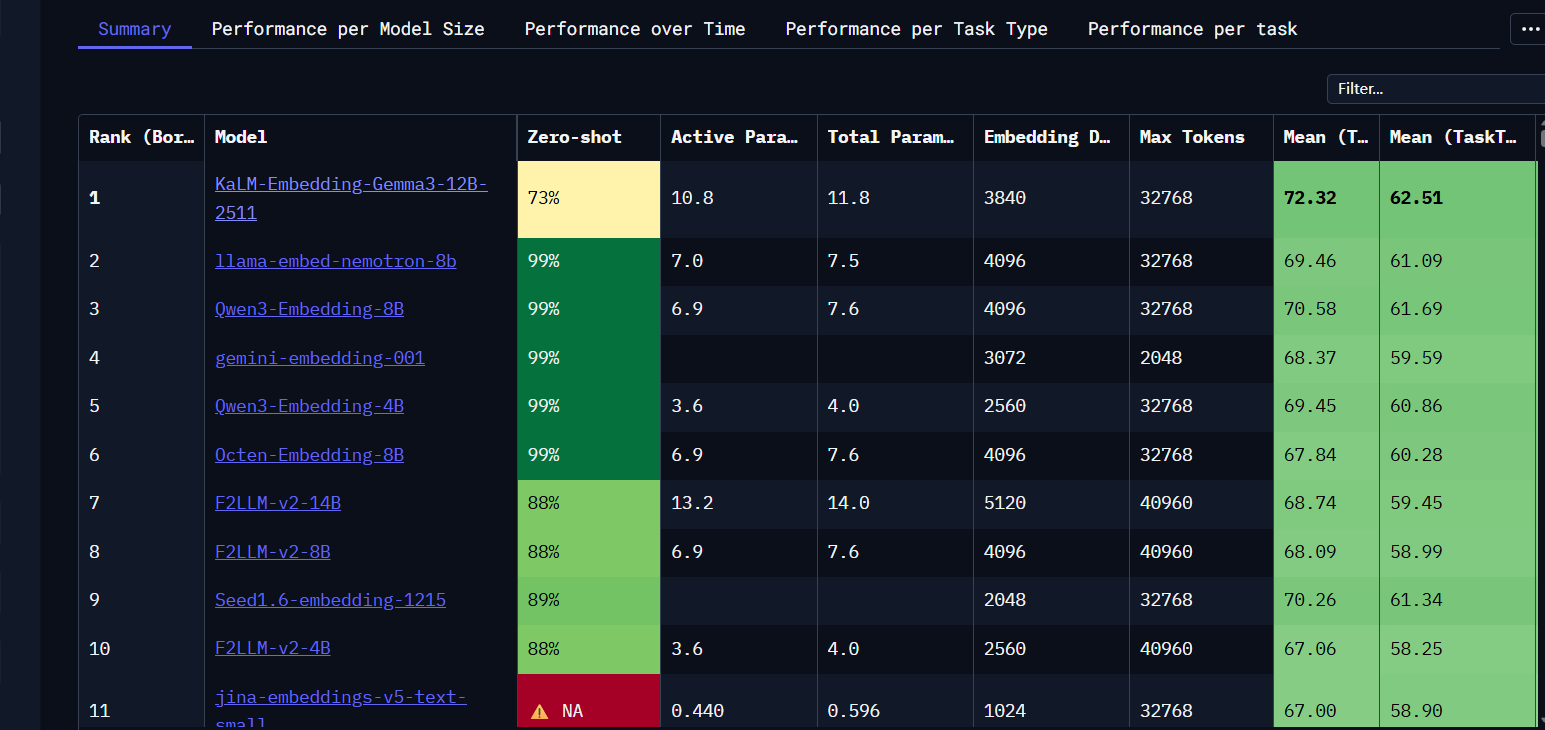
Huggingface 的 MTEB 评测: https://huggingface.co/spaces/mteb/leaderboard
嵌入模型接入方式
嵌入模型接入和使用方式根据模型类型(开源或闭源)有根本性的不同。下图清晰地展示了两种典型的接入流程:
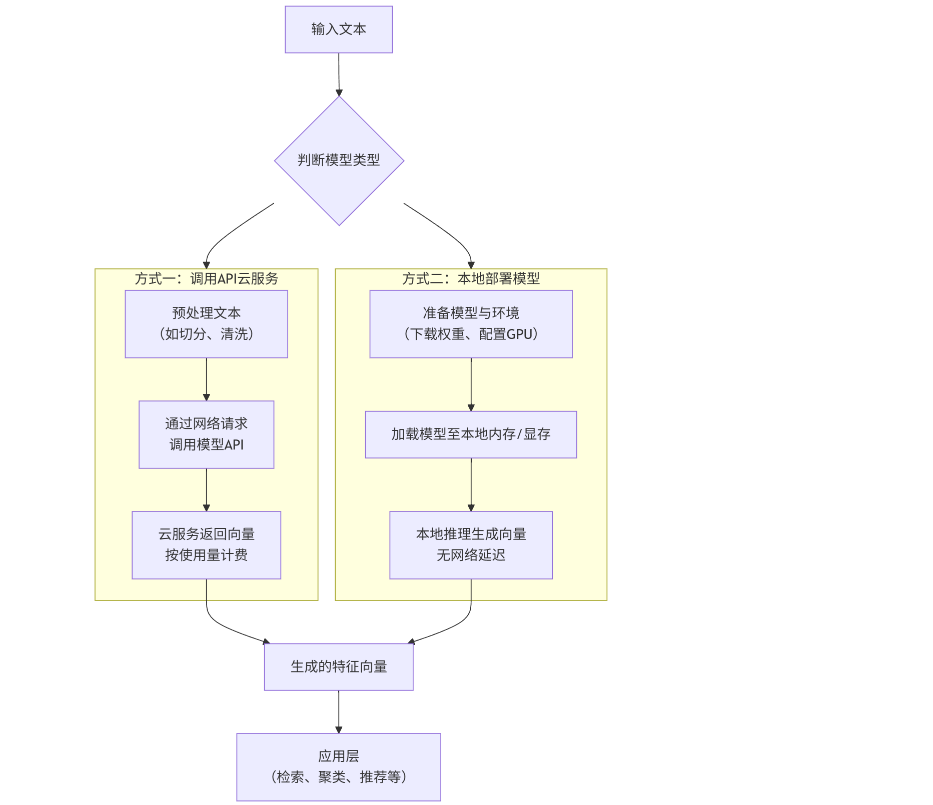
API 接入(闭源)
这是最快速、最简单的方式,无需管理任何基础设施。只需要向模型提供商的服务端发送一个 HTTP 请求即可。
适用模型: text-embedding-3-large , gemini-embedding-001 等。
通用步骤:
1. 注册账号并获取API Key:在对应的云服务平台(如OpenAI Platform, Google AI Studio/Vertex
AI)上注册账号,获取用于身份验证的API Key。
2. 安装 SDK 或构造 HTTP请求:使用官方提供的SDK(如 openai , google-generativeai )
或直接构造HTTP请求。
3. 调用API并处理响应:发送文本,接收返回的JSON格式的向量数据。
示例1:发起 HTTP 请求
curl https://api.openai.com/v1/embeddings
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}
响应包含嵌入向量(浮点数列表)以及一些其他元数据:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
示例2:接入 SDK
# 使⽤ OpenAI Python SDK
from openai import OpenAI
import os
# 1. 设置 API Key
client = OpenAI(api_key="your-api-key")
# 2. 准备输⼊⽂本
text = "这是⼀段需要转换为向量的⽂本。"
# 3. 调⽤ API
response = client.embeddings.create(
model="text-embedding-3-large", # 指定模型
input=text,
dimensions=1024 # 可选:指定输出维度,例如从3072降维到1024
)
# 4. 获取向量
embedding = response.data[0].embedding
print(f"向量维度:{len(embedding)}")
print(embedding)本地部署(开源)
这种方式需要自行准备计算资源(通常是带有GPU的机器)来运行模型,适合对数据隐私、成本和控制权有更高要求的场景。
适用模型: Qwen3-Embedding-8B 等。
通用步骤:
1. 环境准备:准备一台有足够 GPU 显存的服务器(对于Qwen3-Embedding-8B,需要至少16GB以 上显存)。
2. 模型下载:从 Hugging Face 等模型仓库下载模型权重文件和配置文件。
3. 代码集成:使用像 transformers 这样的库来加载模型并进行推理。
对于大多数初创项目或原型验证,从API方式开始是最佳选 择。当应用规模化或面临严格的数据合规要求时,再考虑迁移到本地部署开源模型。
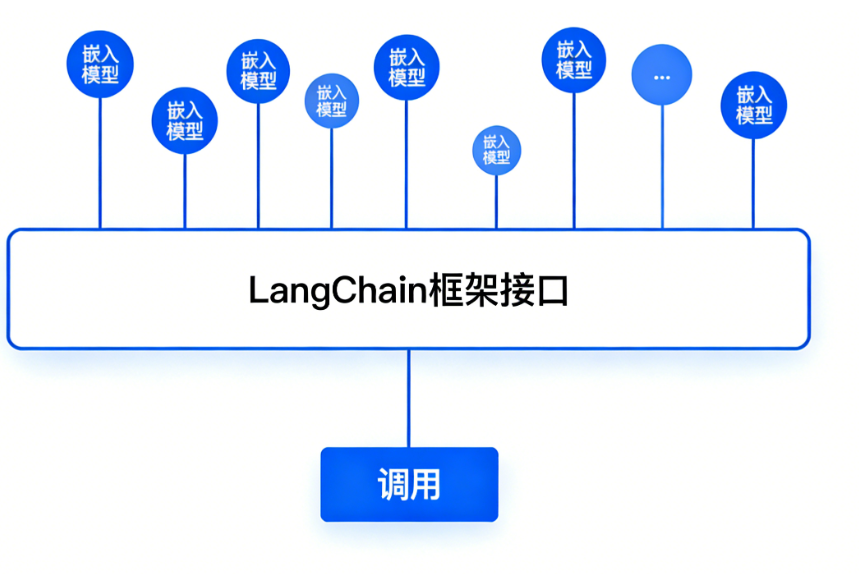
在实际应用中,直接调用嵌入模型获取结果,与直接调用原生LLM 存在相似的问题:无论是通过 API 还是本地部署获得向量,下一步通常都是将它们存入向量数据库(如Chroma, Milvus, Pinecone等)以供后续检索。为了便于切换不同的嵌入模型,很多项目会使用像 LangChain 这样的框架,它提供了统一的嵌入模型接口。
向量数据库是什么?(Embedding 必搭配)
Embedding 输出的向量必须存在向量数据库:
- Chroma(轻量,学习首选)
- Milvus(企业级)
- Pinecone(云服务)
- FAISS(脸书开源,轻量快)
LangChain 全部内置支持。
本篇总结(面向 LangChain 开发者)
- Embedding 是 RAG 的核心,没有它就没有私有知识库
- 它把文本变成向量,实现语义搜索
- 分为闭源 API / 开源本地两种方式
- 中文优先选 Qwen / BGE / GTE
- LangChain 提供统一封装,一行切换模型
- 向量数据库是向量的 “家”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 37
37 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)