AI-从底层逻辑看为什么土豆和马铃薯相似
很多人好奇,AI 为什么能知道土豆就是马铃薯、能分辨词语语义相似、能做智能检索和智能匹配?核心底层逻辑只有一句话:AI 把所有文字、语义,全部转换成高维空间里的向量,靠计算两个向量的夹角,来判断语义相似度。
今天我们就刨根问底,从普通人能看懂的直角三角形开始,一步步讲透:为什么看夹角不看长度、二维到高维向量余弦值怎么算、公式从哪来;再讲清 AI 的 1024 维向量到底从何而来,最后用土豆和马铃薯做真实向量演算,彻底搞懂 AI 向量计算的本质。
一、核心疑问:为什么判断相似度,只看向量夹角,不怎么关心向量长度?
我们先建立一个基础认知:在 AI 的向量世界里,每一个词语、一句话,都是空间里从原点出发的一根箭头,这根箭头就是向量。
两根箭头有两个关键属性:方向和长度。
- 方向:代表词语的核心本义
- 长度:代表词语的修饰程度、语气强弱、语义丰富度
举个很直观的例子:土豆、超大的土豆、迷你的土豆、很漂亮的土豆。这几个词,核心都是指向 “土豆” 本身,在空间里几乎朝着同一个方向;只是有的描述更夸张、有的修饰更简单,造成向量长短不一样。
由此得出关键结论:语义相不相似,由向量之间的 方向(夹角)大小 决定;向量长短只代表修饰、强弱与补充描述,不改变核心本义。所以我们判断语义相似度,只看夹角大小,不用纠结向量长度。
夹角越小,方向越接近,语义就越相近;夹角越大,方向越偏离,语义就越无关。而我们用来精准量化夹角的工具,就是余弦值 cosθ。当然还有其他算法比如:欧式距离、曼哈顿距离等,我们今天重点讨论的是余弦相似度(cosθ)。
二、先搞懂:AI 的 1024 维向量到底是什么?数值从哪来?
主流语义嵌入模型,默认输出固定1024 维向量。普通人很难想象上千维空间,我们可以用通俗逻辑理解:
把每一个维度,看作一个独立的语义特征打分项。1024 维,就等于模型给每一个词语,拆成 1024 个隐藏特征逐一打分。
这其中,有少部分维度是我们能通俗解释的:比如是不是食物、是不是长在土里、能不能做主食、口感如何、属于哪一类物种;而剩下绝大部分维度,不是人为手动定义的,是模型通过海量文本自学、自动归纳出来的隐藏语义特征,人类没法逐条解释,但机器能精准用来刻画语义差异。
为了方便大家看懂演算,我们不用复杂的 1024 维,只截取可理解的前 5 个维度来模拟,原理和 1024 维完全一致。
我们先人为设定 5 个可理解特征维度:维度 1:是否属于食物维度 2:是否生长在土里维度 3:是否可做主食维度 4:口感是否粉糯维度 5:是否属于蔬菜
每个维度都会给出一个 0~1 之间的分值,分值越高,越贴合这个特征。
基于这 5 个维度打分:土豆向量(前五维):[0.8,0.7,0.2,0.6,0.5]马铃薯向量(前五维):[0.78,0.72,0.19,0.58,0.51]
很直观就能发现:两个词语每一个维度的打分都高度接近。我们不能只靠 “感觉相近” 就判定语义相似,必须用数学方法给出严谨结论,这个数学方法,就是计算余弦相似度。
三、从二维到三维,再到 AI 千维向量:余弦计算公式通用规律
普通人只熟悉平面直角坐标系、直角三角形,我们从最简单的二维入手,再延伸三维,最后直接套用到 AI 的高维向量。
1.二维平面向量 A(x1,y1)、B(x2,y2)
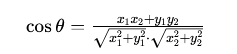
2.三维空间向量 A(x1,y1,z1)、B(x2,y2,z2)
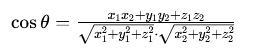
3.套用拉马努金的口头禅“我们可以观察到”:
n 维向量1:A=(x1,y1,z1,…,an1)、向量 2:B=(x2,y2,z2,…,an2)
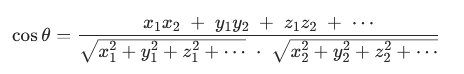
通用规律(4 维、5 维、1024 维全部适用):
- 分子:两个向量对应每一维数字相乘,再累加求和
- 分母:第一个向量自身长度 × 第二个向量自身长度
维度再多,计算规则完全不变,只是特征数量变多而已。
四、刨根问底:余弦相似度公式,从直角三角形怎么推导来的?
余弦定理:c²=a²+b²−2abcosθ,也就是cosθ=(a²+b²-c²)/2ab
怎么来的?数学都快忘记完了,好在还记得小学的三角形直角边的平方和等于斜边的平方,推导一下吧:

最后化简后:
五、实战演算:用前五维向量计算土豆与马铃薯的余弦相似度
1. 计算分子:对应维度相乘再求和
0.8×0.78=0.6240.7×0.72=0.5040.2×0.19=0.0380.6×0.58=0.3480.5×0.51=0.255累加分子合计:1.769
2. 计算两个向量自身长度
土豆向量模长:0.82+0.72+0.22+0.62+0.52≈1.334马铃薯向量模长:0.782+0.722+0.192+0.582+0.512≈1.326
3. 计算分母与最终余弦值
分母:1.334×1.326≈1.769
cosθ≈1.7691.769≈0.9996
余弦值无限接近 1,说明两个向量夹角极小、方向几乎完全重合。从数学角度严谨证明:土豆和马铃薯语义高度同源,绝非主观感觉判断。
六、总结
1.AI 把词语转化为固定 1024 维高维向量,每一维对应一个语义特征;少部分特征可人为解释,其余是模型海量训练后自动学到的隐藏特征,用来精细刻画语义。
2.向量有方向和长度,方向决定核心语义,长度只代表修饰强弱,所以相似度只看向量夹角。
3.用余弦值量化夹角,公式源自平面直角三角形余弦定理,二维、三维到 1024 维通用。
4.语义相近的词语,每一维特征打分都高度接近;不能靠主观感觉判定相似,必须通过余弦相似度(或者欧式距离、曼哈顿距离等算法)做数学严谨计算。
5.余弦值越接近1,夹角越小,语义相似度越高,这就是 AI 理解语义、识别同义、智能匹配的底层核心本质。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)