AI系统的“正确性”到底怎么定义?

很多团队第一次做 AI 应用测试时,都会遇到一个很尴尬的问题:
传统系统测对错,通常有明确答案。
接口返回状态码是不是 200? 金额计算是不是 99.99? 权限校验是不是拦住了非法用户? 数据库字段是不是落对了?
这些问题大多可以写成断言。
但是到了 AI 系统里,问题突然变复杂了。
同一个问题,模型可能给出不同表达; 同一个任务,不同上下文下答案可能都“看起来合理”; 同一个输出,业务觉得能用,测试觉得不可控,法务觉得有风险,产品觉得体验还行。
于是很多团队会卡在第一步:
AI 系统到底怎么算“正确”?
如果这个问题没有定义清楚,后面的测试用例、评估指标、验收标准、质量门禁,基本都会变成拍脑袋。
阅读目录
-
传统软件里的“正确性”为什么更容易定义
-
AI 系统的正确性为什么变复杂了
-
AI 系统正确性的核心定义
-
不能只看答案,要看任务、证据、约束和风险
-
AI 系统正确性的 8 个评估维度
-
RAG、Agent、多模态系统的正确性差异
-
测试团队如何把“正确性”落到工程里
-
一个可落地的 AI 正确性评估框架
一、传统软件里的“正确性”,本质上是“规格符合”
在传统软件测试里,我们判断一个系统是否正确,核心依据通常是:
需求规格 + 输入条件 + 预期输出。
比如一个优惠券系统:
输入:
商品金额 = 200
优惠券规则 = 满100减20
预期输出:
最终金额 = 180
这个场景的正确性很清楚。
只要输出不是 180,那就是错误。
传统软件的正确性,大多建立在几个前提上:
|
维度 |
传统软件特点 |
|---|---|
|
输入 |
相对结构化 |
|
规则 |
明确写在需求里 |
|
输出 |
可预测、可枚举 |
|
判断方式 |
可以断言 |
|
失败原因 |
大多可追踪到代码逻辑 |
所以传统测试最常见的方法是:
assert actual_result == expected_result
这也是很多测试工程师熟悉的工作方式。
但 AI 系统不是这样。
二、AI 系统的正确性,为什么不能只靠“标准答案”?
AI 系统最大的问题不是“它没有答案”,而是:
它经常有多个看似合理的答案。
比如用户问:
请帮我总结这份会议纪要里的核心风险。
模型可能输出:
版本 A:
核心风险包括需求边界不清、交付时间紧、跨团队协作成本高。
版本 B:
主要风险集中在排期压缩、责任人不明确以及验收标准缺失。
这两个答案谁更正确?
如果会议纪要里确实都提到了这些内容,那两个答案可能都不算错。
但如果模型凭空补了一条“预算不足”,而原文没有出现,那就属于错误。
所以 AI 系统的正确性不能简单定义成:
输出是否等于某个标准答案
更准确地说,AI 系统的正确性应该定义为:
“在给定任务目标、上下文、约束条件、证据来源和风险等级下,AI 系统输出是否满足可验证目标,并且没有突破业务、安全、事实和格式边界。
这句话比较长,但非常关键。
AI 的正确性不是一个单点判断,而是一组约束共同成立。
三、AI 系统正确性的核心,不是“像不像人话”
很多团队做 AI 测试时,容易把注意力放在这些表面问题上:
-
回答是不是流畅?
-
语气是不是自然?
-
内容是不是看起来合理?
-
有没有把话说完整?
这些当然重要,但它们更多属于体验质量,不等于正确性。
一个回答可以非常流畅,但事实完全错误。
比如:
某个内部接口支持 /api/v3/user/export,并且默认返回 CSV。
这句话看起来很像真的。
但如果系统里根本没有这个接口,它就是错误。
AI 系统最危险的地方就在这里:
它可以用非常确定的语气,说出完全不存在的内容。
所以 AI 系统的正确性,一定要从“语言表达”往下拆:

真正的正确性,不是“说得像不像”,而是:
有没有把该做的事做对。
四、AI 系统的正确性,要先区分三类问题
做 AI 测试时,建议先把问题分成三类:
-
答案型任务
-
生成型任务
-
行动型任务
这三类任务的正确性标准完全不同。
1. 答案型任务:重点看事实和证据
典型场景:
-
智能客服问答
-
企业知识库问答
-
政策制度查询
-
技术文档问答
-
代码解释
-
数据分析问答
用户问:
公司的报销发票要求是什么?
这类任务的正确性重点不是文采,而是:
-
答案是否来自知识库
-
是否引用了正确文档
-
是否遗漏关键限制
-
是否编造不存在的规则
-
是否把旧制度当成新制度
-
是否能拒答知识库里没有的信息
对于答案型 AI 系统,正确性可以简单理解为:
回答内容 = 用户问题 + 检索证据 + 业务规则 的一致结果
如果没有证据支撑,就不能随便回答。
2. 生成型任务:重点看目标、约束和可用性
典型场景:
-
写文章
-
写邮件
-
生成测试用例
-
生成代码
-
生成 SQL
-
生成方案
-
生成海报文案
比如让 AI 生成测试用例:
根据登录需求,生成边界值和异常场景测试用例。
这类任务通常没有唯一标准答案。
正确性不能只看“是不是和标准答案一模一样”,而要看:
-
是否覆盖核心业务路径
-
是否包含异常场景
-
是否符合测试设计方法
-
是否没有引入不存在的需求
-
是否输出结构可直接使用
-
是否符合团队模板规范
生成型任务的正确性更像是:
满足任务目标 + 覆盖关键场景 + 遵守输出约束 + 具备实际可用性
3. 行动型任务:重点看执行链路是否安全可靠
典型场景:
-
Agent 调用工具
-
自动创建工单
-
自动操作浏览器
-
自动执行 SQL
-
自动发邮件
-
自动调用接口
-
自动修改代码仓库
比如用户说:
帮我查一下最近 7 天支付失败的订单,并生成分析报告。
一个 Agent 可能会执行:
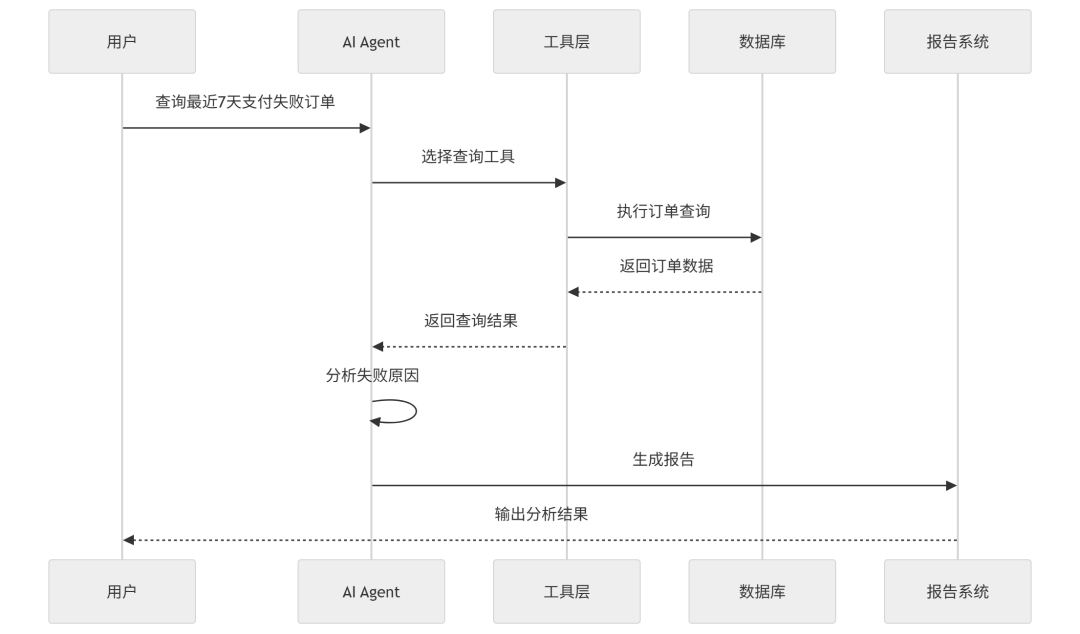
这里的正确性不只是最后报告写得好不好,还包括:
-
工具选得对不对
-
查询条件对不对
-
时间范围有没有错
-
SQL 有没有越权
-
是否访问了不该访问的数据
-
是否正确处理空结果
-
是否对异常做了降级
-
是否保留执行日志
行动型 AI 系统的正确性,本质上是:
意图理解正确 + 工具选择正确 + 参数构造正确 + 执行结果正确 + 权限边界正确
只看最终输出,很容易漏掉中间链路的问题。
五、AI系统正确性的 8 个核心维度
如果要把 AI 正确性落到测试标准里,不能只写一句“回答正确”。
建议至少拆成 8 个维度。
维度一:任务理解是否正确
AI 首先要理解用户到底想干什么。
比如用户说:
帮我看一下这段代码有没有性能问题。
它要识别出这是一个代码评审任务,重点应该放在:
-
时间复杂度
-
空间复杂度
-
IO 调用
-
数据库访问
-
循环嵌套
-
缓存使用
-
并发风险
如果模型跑去解释代码语法,方向就偏了。
测试关注点:
|
检查项 |
示例 |
|---|---|
|
是否识别用户意图 |
用户要评审,不是翻译 |
|
是否识别任务类型 |
问答、生成、分析、执行 |
|
是否识别关键对象 |
代码、接口、日志、文档 |
|
是否识别隐含目标 |
找风险、给建议、输出结论 |
维度二:事实是否正确
这是 AI 系统最基础的正确性。
比如:
-
技术概念有没有说错
-
API 参数有没有编造
-
法规政策有没有过期
-
公司制度有没有引用错误
-
数据统计有没有算错
-
文档内容有没有歪曲
AI 系统常见的事实错误包括:
1. 编造不存在的信息
2. 把旧信息当成新信息
3. 把相似概念混在一起
4. 用不确定内容给出确定结论
5. 对数字、时间、版本号产生错误
尤其是企业知识库场景,事实正确性非常重要。
因为用户不是在跟 AI 聊天,而是在把 AI 当成一个业务系统使用。
维度三:证据是否一致
对于 RAG 系统来说,正确性不能只看回答,还要看回答和检索证据是否一致。
一个回答如果看似正确,但不是基于检索材料得出的,也存在质量风险。
典型错误包括:
|
错误类型 |
说明 |
|---|---|
|
无证据回答 |
知识库没有内容,模型自己补充 |
|
证据错配 |
检索到了 A 文档,却回答 B 文档内容 |
|
证据过期 |
引用了旧制度、旧接口、旧版本 |
|
证据断章取义 |
只引用局部信息,忽略限制条件 |
|
证据冲突未处理 |
多份文档说法不同,模型直接选一个 |
RAG 系统的正确性可以拆成两层:
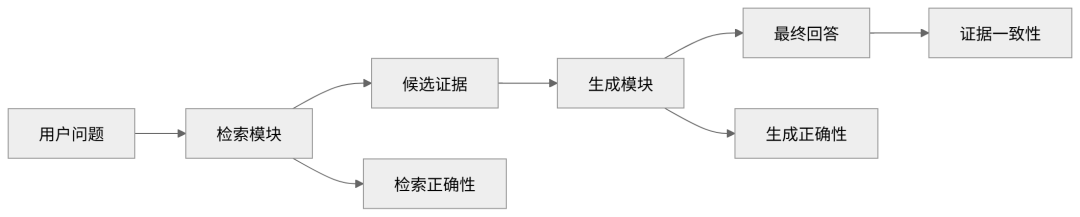
如果检索错了,生成再好也没用。 如果检索对了,生成乱编也不行。
维度四:约束是否遵守
AI 系统通常会有很多约束。
比如:
只能基于知识库回答
不能输出敏感字段
必须使用 JSON 格式
不能给出医疗诊断
不能执行删除类操作
必须先确认再发邮件
这些约束往往比答案本身更重要。
比如让 AI 输出接口测试用例,要求是:
{
"case_name": "",
"precondition": "",
"steps": [],
"expected_result": ""
}
如果模型内容写得不错,但格式不符合平台要求,系统就无法解析。
这类错误在 AI 工程里非常常见。
所以格式正确性也是正确性的一部分。
维度五:推理过程是否可靠
有些 AI 系统不是直接回答,而是需要多步分析。
比如:
根据这份日志,判断支付失败的主要原因。
正确的分析链路可能是:
先识别错误码
再聚合出现频次
再结合时间窗口
再判断是否集中在某个渠道
最后给出根因假设
如果模型直接跳到结论:
应该是第三方支付通道异常。
但没有任何依据,这个结论就不可靠。
AI 的推理正确性,不是要求它展示复杂过程,而是要求:
-
结论能被输入支撑
-
中间判断没有明显跳步
-
不把猜测包装成事实
-
能区分确定结论和可能原因
-
能在证据不足时降低置信度
维度六:工具调用是否正确
Agent 系统尤其要关注工具调用。
因为一旦 AI 能调用工具,它就不只是“说错”,还可能“做错”。
比如:
用户想查询订单,Agent 却调用了退款接口。
这就不是普通回答错误,而是执行风险。
Agent 工具调用正确性至少包括:
|
维度 |
检查点 |
|---|---|
|
工具选择 |
是否选择了正确工具 |
|
参数构造 |
参数是否完整、准确 |
|
权限控制 |
是否越权访问 |
|
执行顺序 |
多工具调用顺序是否合理 |
|
异常处理 |
工具失败后是否重试或降级 |
|
高风险动作 |
是否需要二次确认 |
Agent 系统的正确性,可以理解为:
不仅要答对,还要做对;不仅要做对,还要在边界内做对。
维度七:稳定性和一致性是否可接受
AI 输出存在随机性。
同一个问题问三次,模型可能给出三种表达。
这不是天然错误,但要看业务是否允许。
比如写营销文案,适度变化可以接受。 但查公司制度、生成 SQL、审批建议,就不能随意变化。
因此 AI 正确性里还要考虑一致性:
同一输入、多次执行,核心结论是否稳定?
相似输入、轻微改写,输出是否保持一致?
不同模型版本,关键任务是否出现质量回退?
这就是 AI 系统里的回归测试问题。
传统系统升级后,我们跑自动化用例。 AI 系统升级模型、Prompt、知识库、检索策略后,也必须跑评估集。
维度八:风险边界是否守住
AI 系统不是所有错误都一样严重。
比如:
把文章标题写得不够好
和:
错误地生成了一条删除数据库数据的 SQL
完全不是一个风险等级。
所以 AI 正确性一定要引入风险分级。
|
风险等级 |
示例 |
测试策略 |
|---|---|---|
|
低风险 |
文案表达不够自然 |
人工抽检 |
|
中风险 |
测试用例遗漏场景 |
评估集 + 人工复核 |
|
高风险 |
错误业务建议 |
证据校验 + 专家审核 |
|
极高风险 |
自动执行付款、删除、审批 |
强权限 + 二次确认 + 全链路审计 |
AI 系统的正确性不是平均分越高越好。
真正关键的是:
高风险场景不能错。
六、不同 AI 系统,正确性的定义不一样
AI 系统不是一种系统,而是一组系统形态。
不同形态下,正确性的重点完全不同。
1. 大模型问答系统
关注重点:
-
回答是否准确
-
是否理解问题
-
是否拒绝无法回答的问题
-
是否避免编造
-
是否遵守角色设定
-
是否能给出清晰解释
适合指标:
准确率、拒答正确率、幻觉率、相关性、完整性
2. RAG 知识库系统
关注重点:
-
是否检索到正确文档
-
是否引用正确片段
-
是否基于证据回答
-
是否处理文档冲突
-
是否避免知识库外编造
适合指标:
检索召回率、Top-K 命中率、上下文相关性、答案忠实度、引用准确率
3. AI Agent 系统
关注重点:
-
是否正确拆解任务
-
是否选择正确工具
-
是否构造正确参数
-
是否处理异常
-
是否遵守权限和审批流程
-
是否留下可审计记录
适合指标:
任务成功率、工具调用准确率、参数正确率、执行失败率、人工接管率
4. 代码生成系统
关注重点:
-
代码是否能运行
-
是否满足需求
-
是否通过测试
-
是否存在安全问题
-
是否符合工程规范
-
是否容易维护
适合指标:
编译通过率、单测通过率、漏洞数量、代码规范评分、需求覆盖率
5. 测试用例生成系统
关注重点:
-
是否覆盖主流程
-
是否覆盖异常流
-
是否覆盖边界值
-
是否贴合需求
-
是否没有编造需求
-
是否能直接进入测试管理平台
适合指标:
需求覆盖率、场景完整度、无效用例率、可执行率、重复率
七、AI 正确性不能只靠人工感觉,要工程化评估
很多团队上线 AI 功能时,评估方式是:
找几个人试一下,感觉还不错,就上线。
这种方式在 Demo 阶段可以,在生产环境不够。
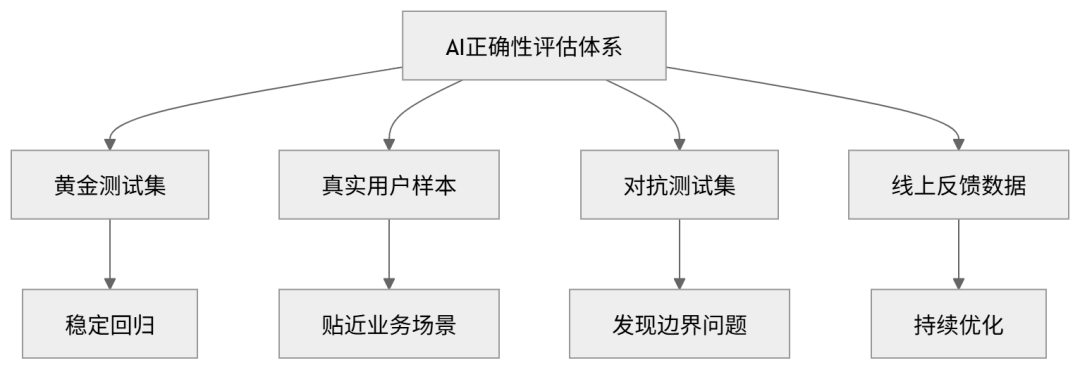
AI 系统的正确性要工程化,至少需要四类数据:
八、黄金测试集:AI 测试的基本盘
黄金测试集可以理解为 AI 系统的“核心回归用例”。
它不是随便凑一批问题,而是从业务高频场景、风险场景、历史问题中整理出来的标准评估集。
一条黄金测试样本至少应该包含:
{
"question": "员工报销发票抬头有什么要求?",
"context": "报销制度文档片段",
"expected_points": [
"必须使用公司全称",
"发票内容需与实际业务一致",
"电子发票需上传原始文件"
],
"forbidden_points": [
"不能编造税号规则",
"不能引用旧版制度"
],
"risk_level": "medium"
}
注意,这里的 expected_points 不一定是完整标准答案,而是关键判断点。
因为 AI 输出可能有不同表达,但关键事实不能错。
九、AI 正确性评估,建议用“打点式”而不是“全文匹配”
传统断言喜欢这样写:
assert actual == expected
但 AI 输出不适合全文匹配。
更适合使用“关键点检查”。
比如:
def evaluate_answer(answer: str) -> dict:
checks = {
"mentions_company_full_name": "公司全称"in answer,
"mentions_invoice_consistency": "实际业务"in answer or"业务一致"in answer,
"no_fake_tax_rule": "税号必须"notin answer,
"no_old_policy": "旧版制度"notin answer
}
passed = all(checks.values())
return {
"passed": passed,
"checks": checks
}
这只是一个简化示例。
真实工程里,可以结合:
-
规则校验
-
关键词校验
-
结构化字段校验
-
LLM-as-Judge
-
人工抽检
-
业务专家复核
-
线上反馈闭环
重点是:
不要只问“这段回答好不好”,而要拆成可检查的判断点。
十、LLM-as-Judge 可以用,但不能迷信
现在很多团队会用大模型来评估大模型。
比如让评估模型判断:
回答是否忠实于参考文档?
回答是否遗漏关键点?
回答是否出现幻觉?
回答是否满足格式要求?
这种方式很有价值,尤其适合大规模评估。
但它也有明显风险:
-
评估模型本身也可能误判
-
评分标准不稳定
-
Prompt 改动会影响评分
-
对细粒度业务规则不一定敏感
-
对高风险场景不能完全替代人工
比较稳妥的做法是:
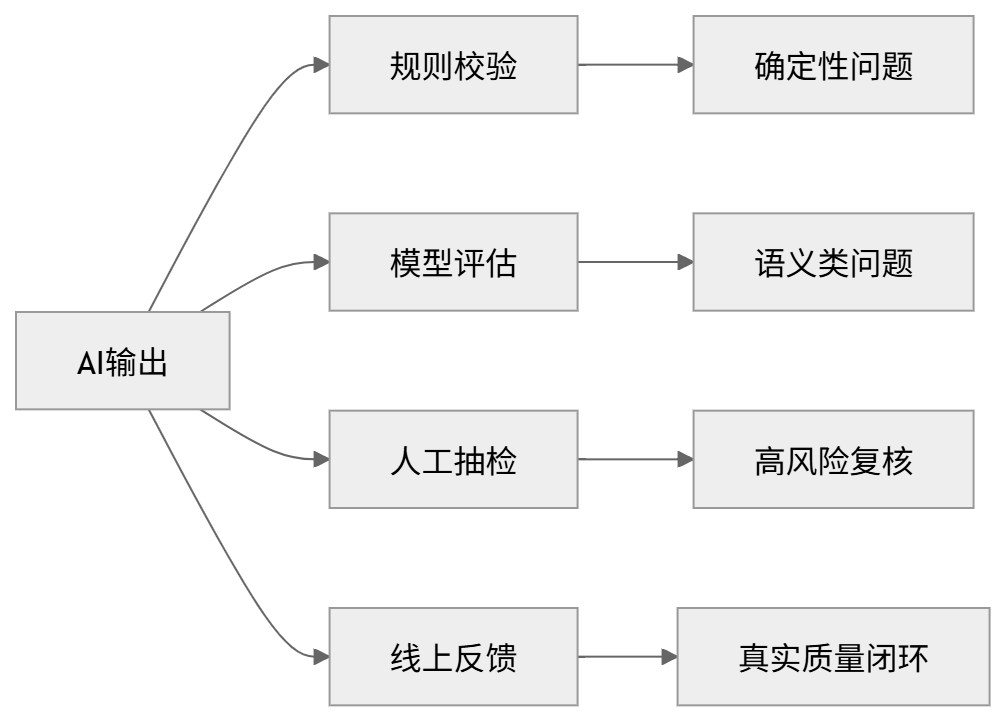
也就是说:
能用规则判断的,不要全交给模型;规则判断不了的,再让模型辅助评估。
十一、AI 系统正确性,必须引入“可观测性”
AI 系统出错时,不能只看到最后一句回答。
要能追踪它为什么这么回答。
尤其是 RAG 和 Agent 系统,至少要记录:
|
日志对象 |
作用 |
|---|---|
|
用户原始输入 |
判断任务意图 |
|
Prompt 版本 |
定位提示词变更影响 |
|
模型版本 |
定位模型升级影响 |
|
检索 Query |
判断检索是否跑偏 |
|
召回文档 |
判断证据是否正确 |
|
Rerank 分数 |
判断排序是否合理 |
|
工具调用记录 |
判断执行链路是否正确 |
|
最终输出 |
判断结果质量 |
|
用户反馈 |
形成优化闭环 |
没有可观测性,AI 测试会变成玄学。
你只能看到“这次回答错了”,却不知道:
-
是问题理解错了?
-
是知识库没召回?
-
是召回了但排序错了?
-
是 Prompt 没约束住?
-
是模型编造了?
-
是工具参数传错了?
-
是用户问题本身有歧义?
AI 系统正确性的评估,必须和链路追踪绑定。
十二、一个更实用的定义:AI 正确性 = 契约正确性
如果要用一句话来总结,可以这样定义:
“AI 系统的正确性,不是输出一个唯一标准答案,而是在特定任务契约下,满足事实、证据、约束、格式、行动和风险边界。
这里的关键词是:任务契约。
每个 AI 能力上线前,都应该定义清楚它的任务契约。
比如一个“AI 生成测试用例”的能力,任务契约可以写成:
输入:
需求文档、接口文档、业务规则
输出:
结构化测试用例列表
必须满足:
1. 覆盖主流程、异常流、边界值
2. 不编造需求文档中不存在的功能
3. 输出字段符合测试管理平台格式
4. 高风险业务规则必须生成对应用例
5. 不输出无法执行的空泛描述
不可接受:
1. 把技术方案当成需求
2. 生成重复用例
3. 遗漏权限、幂等、异常处理场景
4. 输出无法导入平台的格式
一旦契约清楚,测试就能落地。
否则只能靠感觉判断。
十三、测试团队可以怎么做?
如果你是测试团队,要评估一个 AI 系统的正确性,可以按这个流程走:
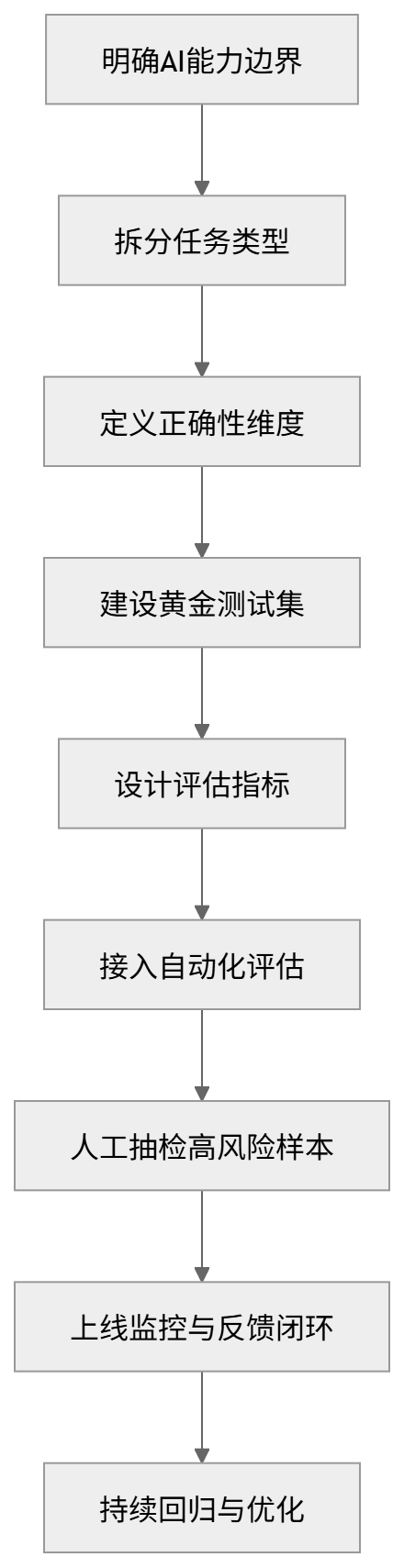
具体动作可以拆成 7 步:
第一步:先定义 AI 能做什么、不能做什么
不要一上来就测。
先问清楚:
这个 AI 能力的边界是什么?
哪些问题必须回答?
哪些问题必须拒答?
哪些动作可以自动执行?
哪些动作必须人工确认?
边界不清,正确性就无从谈起。
第二步:把任务类型拆清楚
同一个 AI 系统里可能同时包含:
-
问答
-
摘要
-
生成
-
推荐
-
分类
-
工具调用
-
多轮对话
不同任务要用不同标准。
不要用一套指标评估所有能力。
第三步:定义每类任务的正确性指标
比如 RAG 问答:
|
指标 |
含义 |
|---|---|
|
答案相关性 |
是否回答了用户问题 |
|
事实准确性 |
内容是否正确 |
|
证据忠实度 |
是否基于召回文档 |
|
引用准确率 |
引用文档是否匹配 |
|
拒答正确率 |
无答案时是否拒答 |
|
幻觉率 |
是否编造不存在内容 |
比如 Agent:
|
指标 |
含义 |
|---|---|
|
任务成功率 |
是否完成用户目标 |
|
工具选择准确率 |
是否选对工具 |
|
参数正确率 |
是否传对参数 |
|
越权调用率 |
是否触碰权限边界 |
|
异常恢复率 |
工具失败后是否处理 |
|
人工接管率 |
需要人工介入的比例 |
第四步:建设黄金测试集
测试集不要只放简单问题。
要覆盖:
-
高频问题
-
边界问题
-
易混淆问题
-
无答案问题
-
冲突文档问题
-
权限限制问题
-
历史线上问题
-
高风险业务问题
AI 系统的很多问题,不会出现在正常样本里,而会出现在边界样本里。
第五步:评估不能只看平均分
AI 系统很容易出现一种情况:
整体评分 90 分,但关键问题错了。
比如客服系统 100 个问题里答对 90 个,但把退款规则答错了。
这比普通闲聊错一句严重得多。
所以评估时要看:
-
总体分
-
分场景分
-
高风险场景通过率
-
幻觉率
-
拒答能力
-
线上负反馈样本
高风险场景建议单独设置准入门槛。
第六步:把评估接入发布流程
AI 系统每次变更都可能影响质量:
-
换模型
-
改 Prompt
-
改知识库
-
改检索参数
-
改切分策略
-
改工具描述
-
改权限策略
所以 AI 系统也需要回归测试。
发布前至少跑一轮核心评估集。

第七步:线上反馈要能回流到测试集
AI 系统上线后,用户反馈非常重要。
但不能只停留在“用户点了踩”。
要进一步分析:
用户为什么点踩?
是答非所问?
是事实错误?
是缺少证据?
是格式不对?
是没有解决问题?
是触发了风险边界?
然后把典型问题沉淀到测试集中。
这样 AI 系统才会越测越稳,而不是每次都从头排查。
十四、AI系统正确性的最终判断标准
AI 系统的正确性,不应该再用一句“答案对不对”来概括。
更合理的判断方式是:
1. 它是否理解了用户任务?
2. 它是否基于正确证据?
3. 它是否遵守系统约束?
4. 它是否输出了可用结果?
5. 它是否避免了编造和越界?
6. 它是否在高风险场景下足够保守?
7. 它的结果是否可以被追踪和复现?
8. 它在版本迭代后是否保持稳定?
如果这几个问题答不清楚,AI 系统的质量就很难被真正控制。
AI 测试的难点,不是没有标准,而是标准要重新设计
传统软件测试的核心是:
给定输入,验证输出是否符合预期。
AI 系统测试的核心变成了:
给定任务、上下文、证据和约束,验证系统是否在边界内完成目标。
这就是 AI 正确性和传统正确性的最大区别。
AI 系统不是不能测,也不是只能靠人工感觉测。
它需要把“正确性”从一个模糊判断,拆成一组可验证的工程契约:
任务契约
事实契约
证据契约
格式契约
工具契约
权限契约
风险契约
回归契约
未来 AI 应用越深入业务,测试团队越不能只盯着“模型回答得像不像”。
真正要盯的是:
它有没有在正确的边界里,完成正确的事情。
本文部分内容参考了霍格沃兹测试开发学社整理的相关技术资料,主要涉及软件测试、自动化测试、测试开发及 AI 测试等内容,侧重测试实践、工具应用与工程经验整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)