卷积网络参数分析与优化:从维度陷阱到训练细节
前言
在掌握了卷积神经网络(CNN)的基本原理后,真正上手写代码时,最困扰我们的往往不是“卷积是什么”,而是“维度怎么对不上”。
今天的进阶笔记不聊概念,我们来聊点硬核的:如何精准控制卷积维度,以及在 PyTorch 工程实战中,那些让模型准确率从 97% 飞跃到 99% 的优化细节。
一、 维度设计的“精密计算”
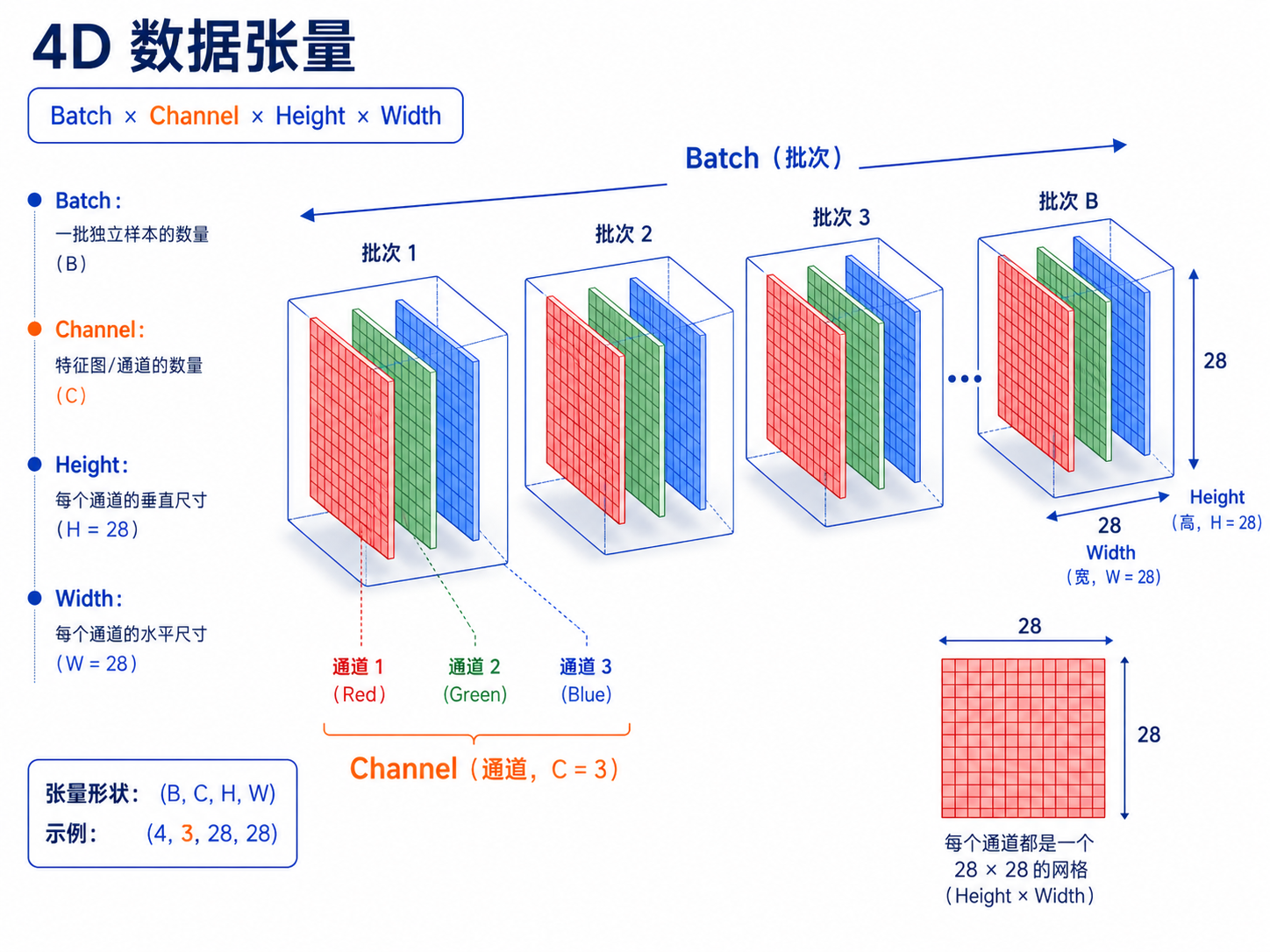
在 PyTorch 中构建 CNN,第一关就是处理 Channel First 的维度顺序:[Batch, Channel, Height, Width]。
1. 核心公式:掌控输出尺寸
卷积后的特征图尺寸不是随意的,它严格遵循以下公式:
注意:PyTorch 在除不尽时默认向下取整(Floor)。
2. 补齐“边缘遗憾”:Padding 的黄金搭档
为了不让图像在多层卷积后迅速萎缩,我们通常追求“输入输出等大”。这里有两组工程上的黄金搭档:
-
Kernel=5 时,设置 Padding=2(Stride=1)。
-
Kernel=3 时,设置 Padding=1(Stride=1)。
掌握了这两组搭档,你在设计 nn.Conv2d 时就能避免因为尺寸缩减过快而导致模型无法加深。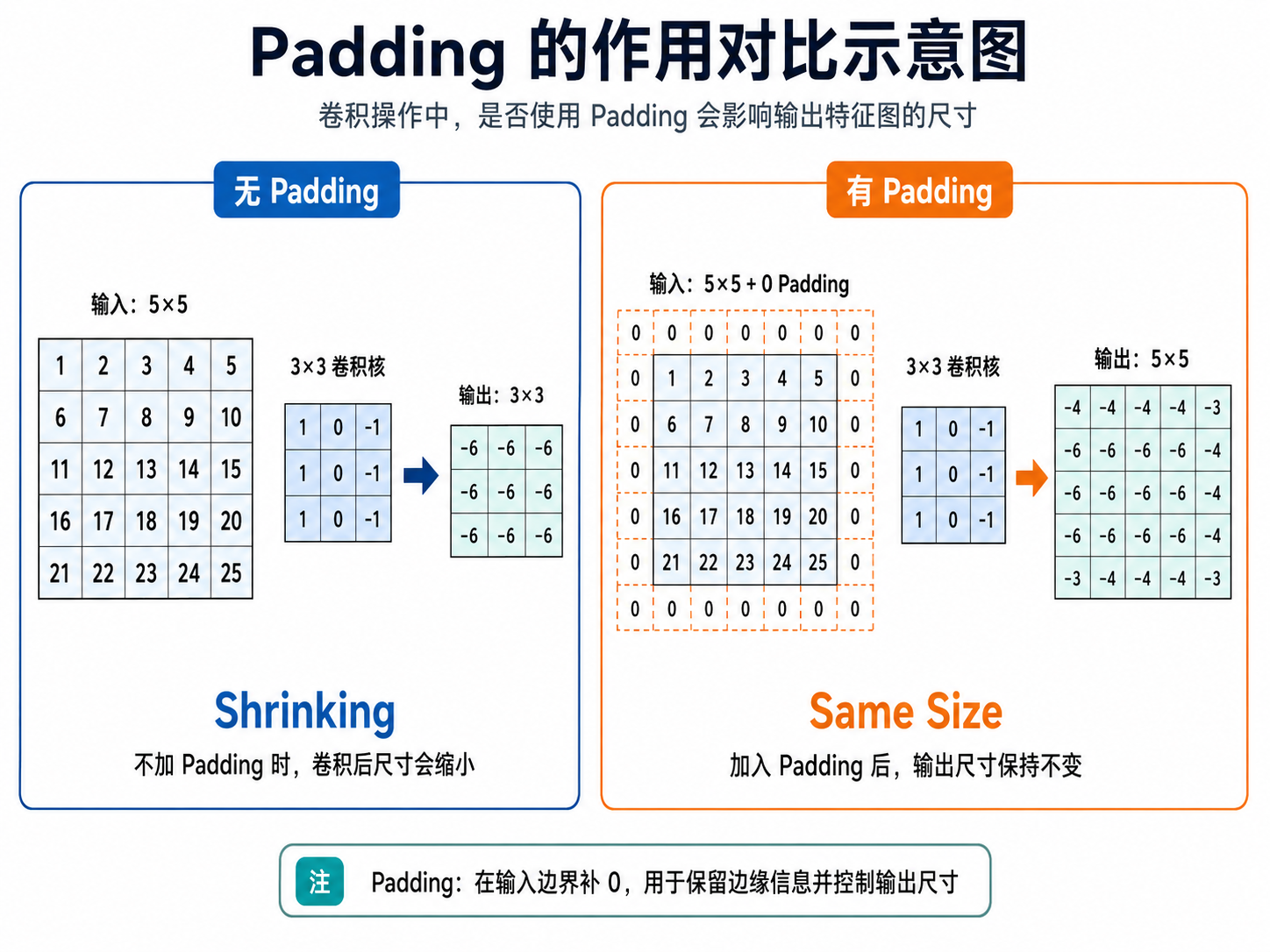
二、 关键跨越:从 3D 特征图到 1D 分类器
卷积层提取的是空间特征(3D 张量),但分类器(FC 层)只认识一维向量。这个“拉长”的过程是代码报错的高发区。
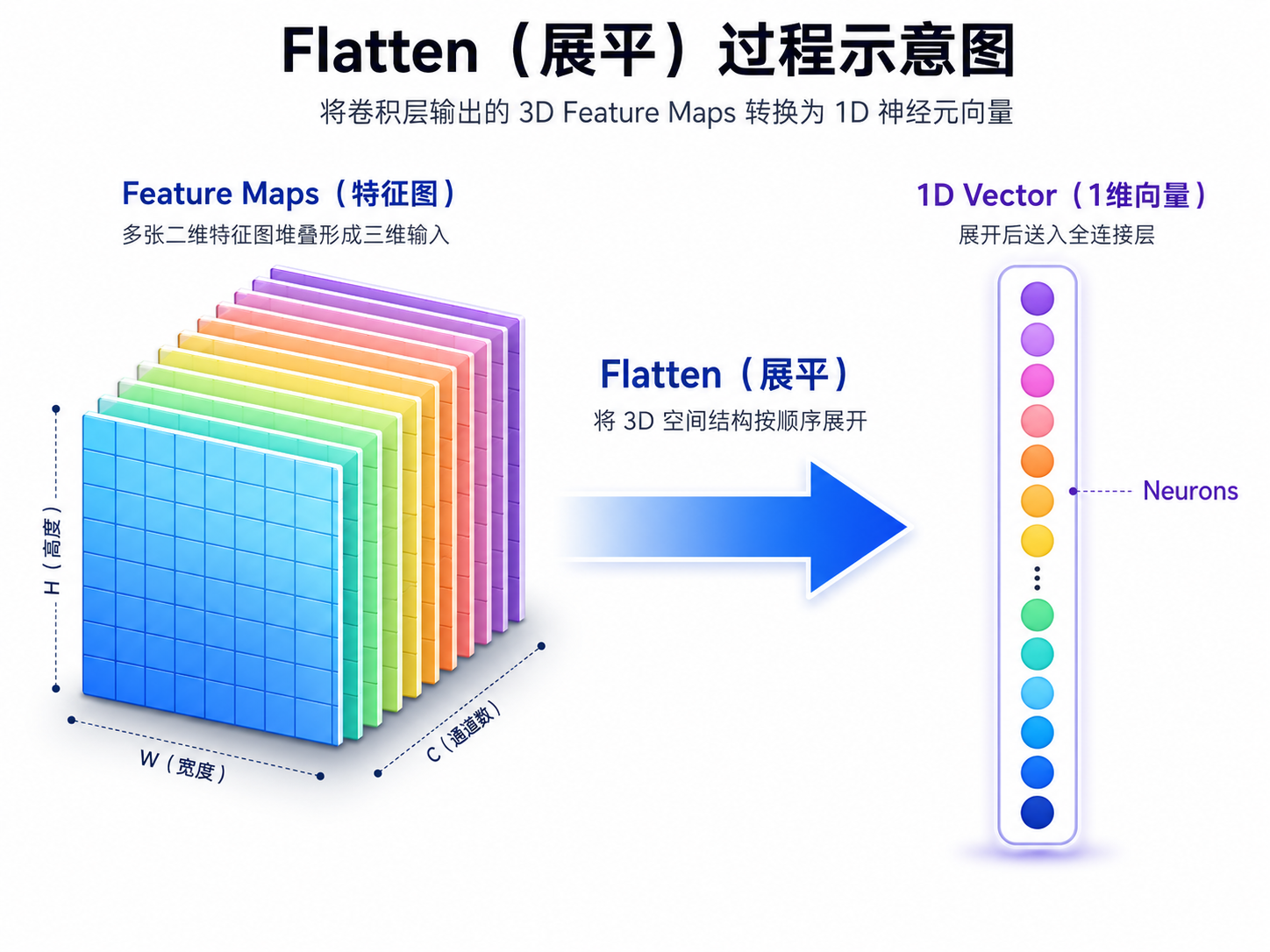
1. 展平逻辑:View 函数的妙用
假设最后一层卷积输出了 64 个 7×7 的特征图,总特征数就是 64×7×7=3136。
在送入全连接层前,必须执行:
x = x.view(x.size(0), -1) # size(0)保留Batch,-1自动计算 31362. 自动计算的“负一”技巧
代码中的 -1 相当于告诉系统:“我确定 Batch 维度不动,剩下的维度你自己乘起来。”这种写法增强了代码的鲁棒性,即使你修改了输入图像的大小,程序也不会轻易崩溃。
三、 训练策略的工程优化
同样的模型,为什么不同的人练出来效果不同?答案就在训练循环的细节里。
1. 训练模式与验证模式的切换
这是入门者最容易忽略的细节:
-
net.train():在训练集上开启权重更新。
-
net.eval():在验证集上关闭梯度计算和扰动。
不要每一轮迭代都跑验证集。推荐每隔 100 个迭代步(index % 100 == 0)运行一次验证,这样既能监控过拟合,又能节省宝贵的算力。
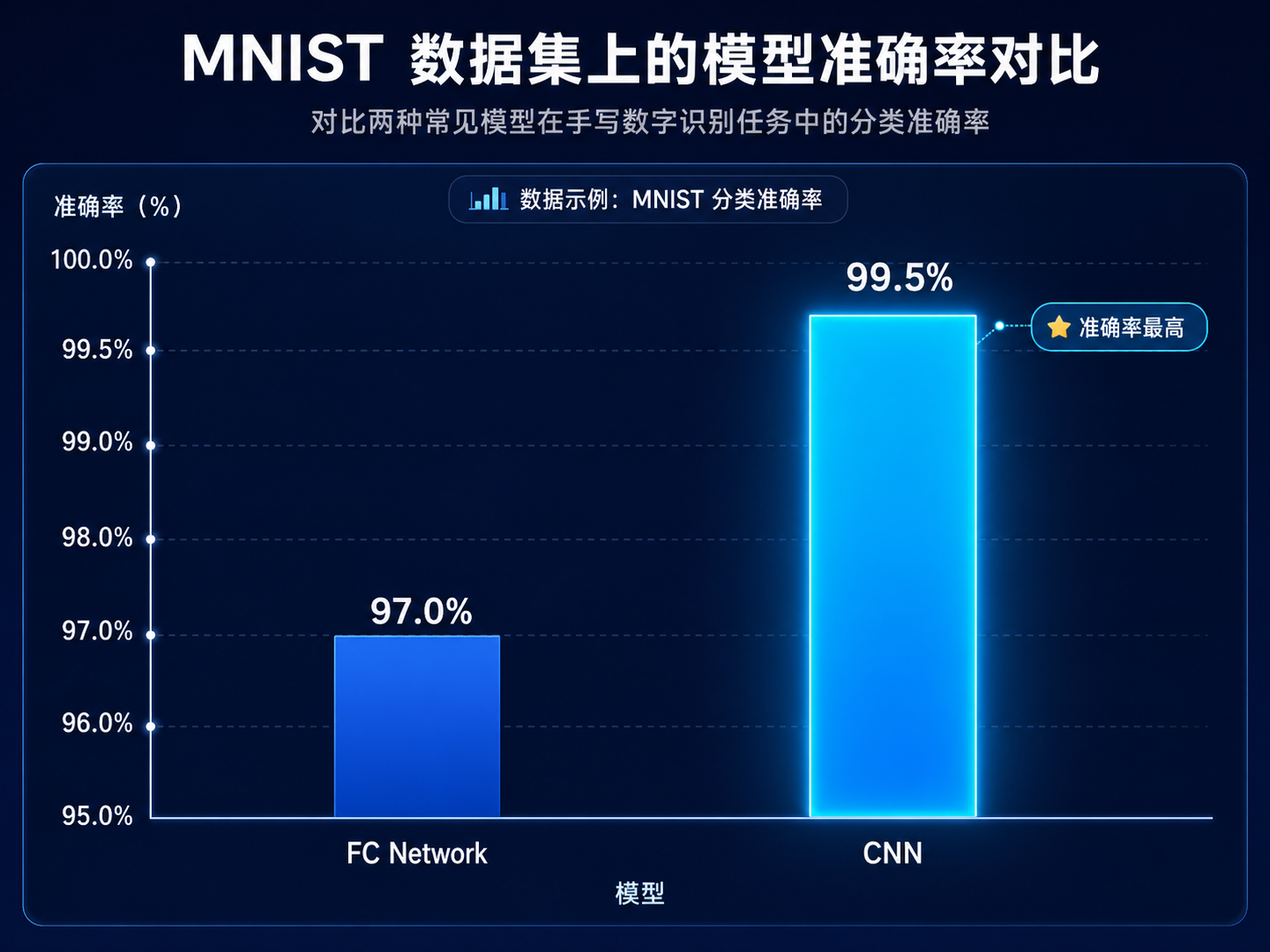
2. 性能降维打击
在 MNIST 数据集上,全连接网络(FC)由于将像素视为孤立点,准确率通常在 97% 左右;而经过参数优化后的 CNN 能够轻松突破 99%。这证明了:参数设计的核心在于利用像素间的空间相关性,而不是简单堆砌参数。
四、 进阶总结:如何设计你的模型?
-
输入输出对齐:通过调节 Padding,让卷积专注于提取特征,而不是改变尺寸。
-
逐步下采样:利用池化层(Pooling)将尺寸减半(如 28→14→7),同时通道数翻倍。
-
计算衔接:下一层的 in_channels 必须严丝合缝地对接上一层的 out_channels。
结语
参数分析是卷积网络的“筑基”过程。理解了维度是如何在网络中流动的,你才算真正拿到了深度学习的入场券。
下期预告:
当网络深度增加,普通的卷积堆叠会遇到“退化”瓶颈。下一篇,我们将聊聊那个让深度模型真正“深”下去的神器——ResNet 模型及其应用。
如果你在维度计算上踩过坑,欢迎在评论区分享你的经验!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)