SE、CBAM和CA模块:深度学习中的注意力机制解析
一、SE(Squeeze-and-Excitation)模块
SE模块是一种通道注意力机制,最早由论文 Squeeze-and-Excitation Networks 提出,核心思想是:让网络自动学习每个通道的重要性,并对特征进行重标定(re-weighting)
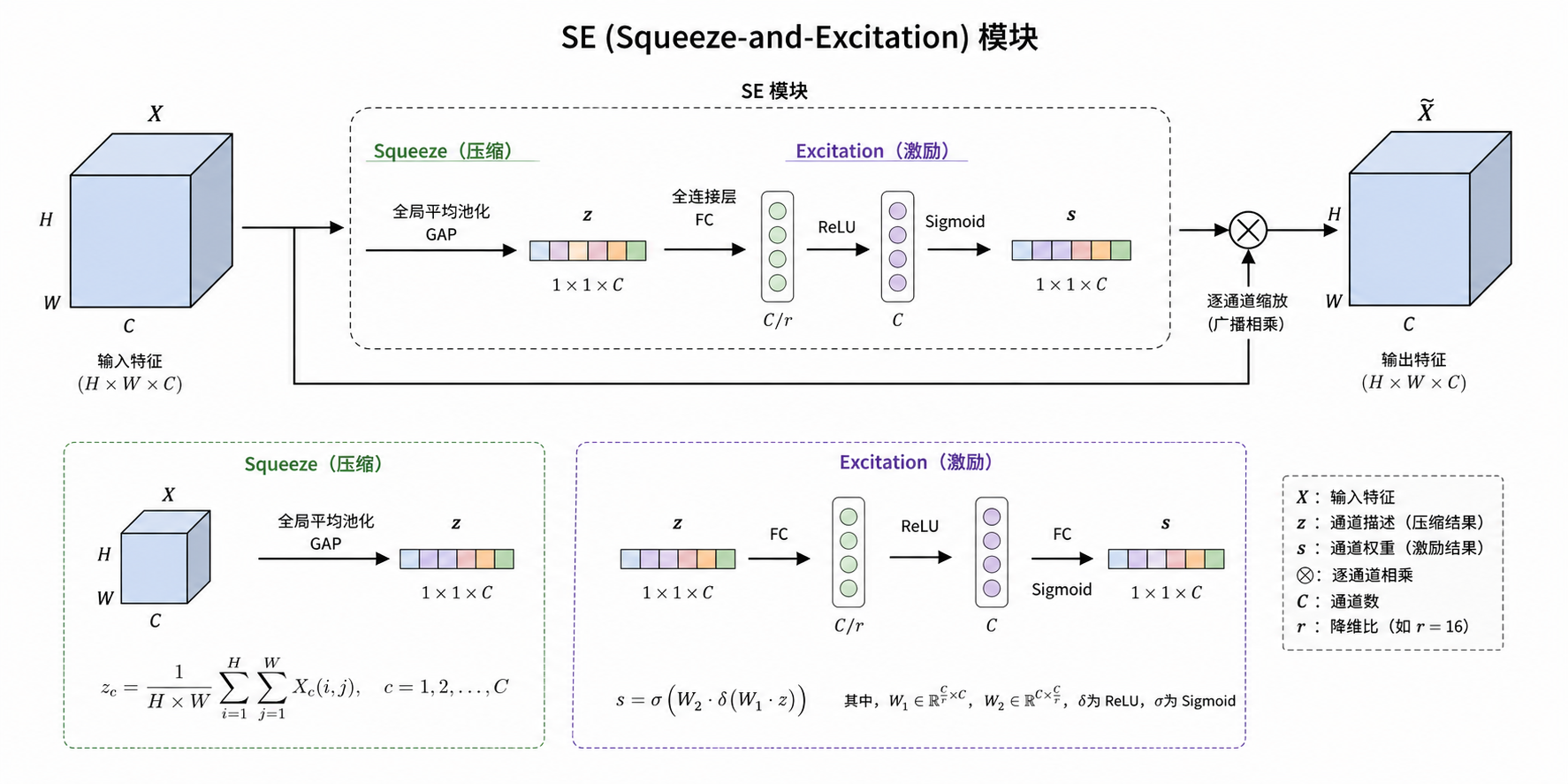
输入特征:
SE模块做三件事:
1.Squeeze(压缩空间信息)
为了应对利用通道依赖性的问题,首先考虑输出特征中每个通道的信号。将全局空间信息压缩到通道描述符中。通过使用全局平均池化生成通道级统计信息实现这一点。形式上,通过在空间维度 H × W 上收缩 X,生成一个统计量 ,使得 z 的第 c 个元素计算方式为:
结果:从 H×W×C变成 1×1×C
直观理解:每个通道变成一个数,表示这个通道“整体有多重要”
2.Excitation(学习通道权重)
为了利用在 squeeze 操作中汇总的信息,其后进行第二个操作,旨在充分捕捉通道间的依赖关系。
为了实现这一目标,该函数必须满足两个标准:
首先,它必须具有灵活性(特别是,它必须能够学习通道之间的非线性交互);
其次,它必须学习非互斥关系,因为我们希望确保可以强调多个通道(而不是强制单一激活)。
为了满足这些标准,作者采用了两层全连接构成的门机制,第一个全连接层把C个通道压缩成了C/r个通道来降低计算量,再通过一个RELU非线性激活层,第二个全连接层将通道数恢复回为C个通道,再通过Sigmoid激活得到权重s,最后得到的这个s的维度是1×1×C,它是用来刻画特征图X中C个feature map的权重。r是指压缩的比例。
作用:学习每个通道的权重
结构:两层全连接(FC)+ 非线性
其中:
W1:C→C/r(降维)
W2:C/r→C(升维)
为什么要降维?一是为了减少计算量,二是为了增强非线性表达
输出:
每个通道一个权重(0~1之间)
3.Scale(加权原特征)
作用:将前面得到的注意力权重加权到每个通道的特征上
本质就是放大重要通道,抑制不重要通道
4.代码实现
class SELayer(nn.Module):
def __init__(self, c1, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
c_ = max(8, c // reduction)
self.fc = nn.Sequential(
nn.Linear(c1, c_, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c_, c1, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)二、CBAM(Convolutional Block Attention Module)模块
CBAM: Convolutional Block Attention Module 是由 Sanghyun Woo、Jongchan Park、Joon-Young Lee 与 In So Kweon 提出的计算机视觉论文,发表于 2018 年欧洲计算机视觉会议(ECCV 2018)。论文提出了一种可嵌入任意卷积神经网络(CNN)的轻量级注意力机制模块,用于改进特征表达能力。
CBAM结合了通道注意力(CA)和空间注意力(SA),通过分别对通道和空间的注意力进行建模,动态调整特征图中各部分的重要性。
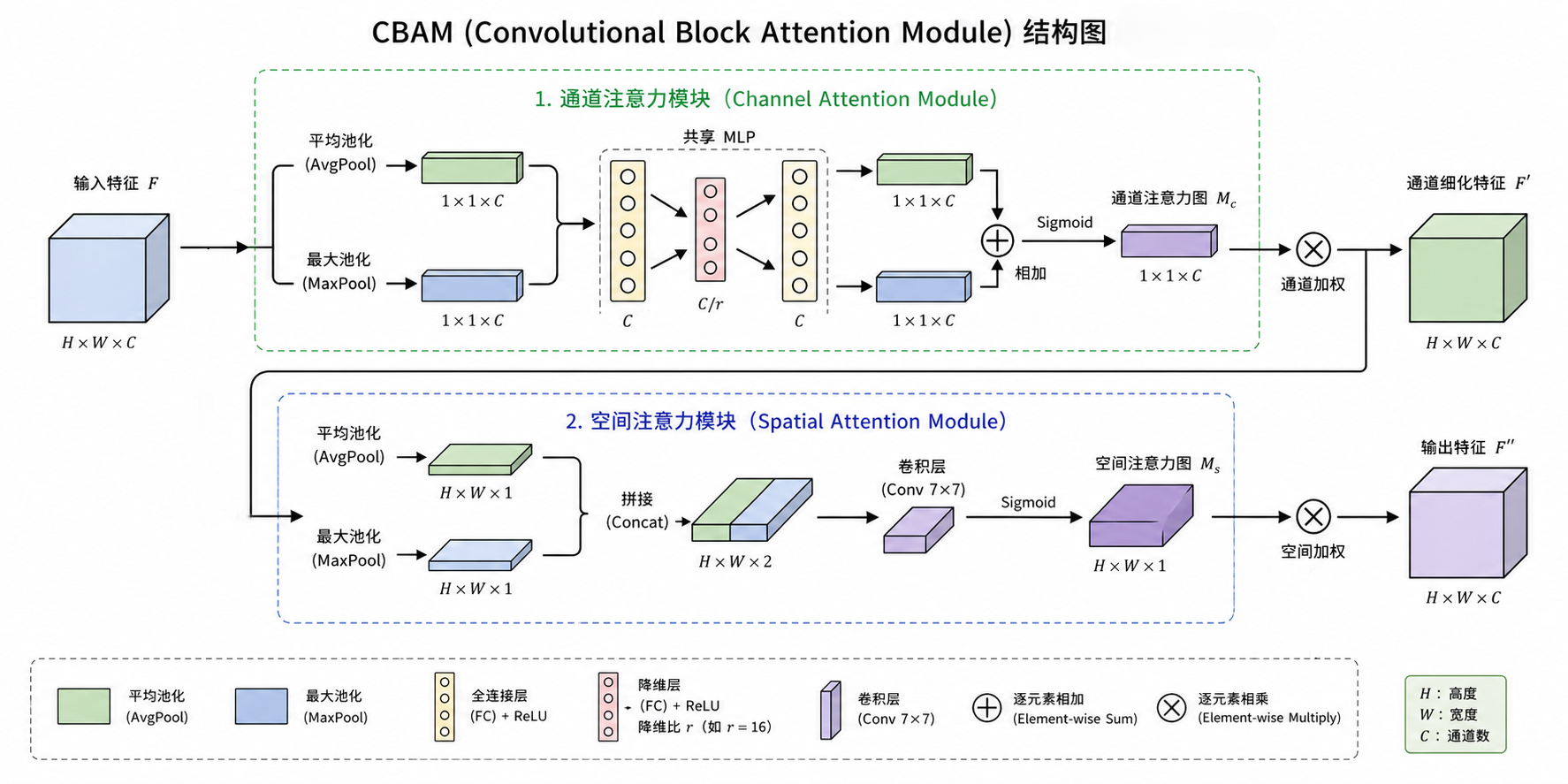
给定一个中间特征图 作为输入,CBAM 依次推断一个 1D 通道注意力图
和一个 2D 空间注意力图
,如上图所示。
整体注意力过程可以总结如下:
其中 ⊗ 表示元素级乘法。在乘法过程中,注意力值会相应地广播(复制):通道注意力值沿空间维度广播,反之亦然。F 是最终的精炼输出。
1.通道子模块
通道子模块利用最大池化输出和平均池化输出,并通过共享网络进行处理;空间子模块利用沿通道轴池化的两个类似输出,并将其传递到卷积层。我们首先通过平均池化和最大池化操作聚合特征图的空间信息,生成两个不同的空间上下文描述符:和
,分别表示平均池化特征和最大池化特征。
然后,将这两个描述符传递到共享网络以生成我们的通道注意力图 。共享网络由一个具有一个隐藏层的多层感知机(MLP)组成。为了减少参数开销,隐藏层的激活尺寸设置为
,其中 r 为缩减比率。在共享网络应用于每个描述符之后,我们使用逐元素求和合并输出特征向量。
简而言之,通道注意力的计算方式为
其中 σ 表示 sigmoid 函数,,
。注意,MLP 权重 W0 和 W1 对两个输入都是共享的,并且在 W0 后面使用了 ReLU 激活函数
2.空间子模块
不同于通道注意力,空间注意力关注“哪里”是信息丰富的部分,具有对通道注意力的互补性。为了计算空间注意力,首先沿通道轴应用平均池化和最大池化操作,并将它们连接以生成有效的特征描述符。应用卷积层来生成空间注意力图 ,它编码了强调或抑制的位置。
通过使用两种池化操作聚合特征图的通道信息,生成两个二维图: 和
,分别表示通道上的平均池化特征和最大池化特征。然后将它们连接并通过标准卷积层卷积,生成我们的二维空间注意力图。简而言之,空间注意力计算公式为:
其中 σ 表示 sigmoid 函数,表示滤波器尺寸为 7×7 的卷积操作。
给定输入图像,两个注意力模块,通道和空间,会计算互补注意力,分别关注“是什么”和“在哪里”。考虑到这一点,这两个模块可以以并行或顺序方式放置。论文作者发现顺序排列比并行排列效果更好。对于顺序过程的排列,实验结果显示通道优先顺序略优于空间优先顺序。
3.代码实现
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享 MLP
self.mlp = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, kernel_size=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels // reduction, in_channels, kernel_size=1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.mlp(self.avg_pool(x))
max_out = self.mlp(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_channels, reduction=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_channels, reduction)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
# Channel Attention
out = self.ca(x) * x
# Spatial Attention
out = self.sa(out) * out
return out三、CA (Coordinate attention) 模块·
Coordinate attention是在Coordinate Attention for Efficient Mobile Network Design论文中被提出,作为一种新的移动网络注意力机制,通过将位置信息嵌入通道注意力中,称之为“坐标注意力”。
与通过二维全局池化将特征张量转换为单一特征向量的通道注意力不同,坐标注意力将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向聚合特征。通过这种方式,可以沿一个空间方向捕获长距离依赖,同时沿另一个空间方向保留精确的位置信息。生成的特征图随后被分别编码为一对方向感知且位置敏感的注意力图,这些注意力图可以互补地应用于输入特征图,以增强感兴趣对象的表示。
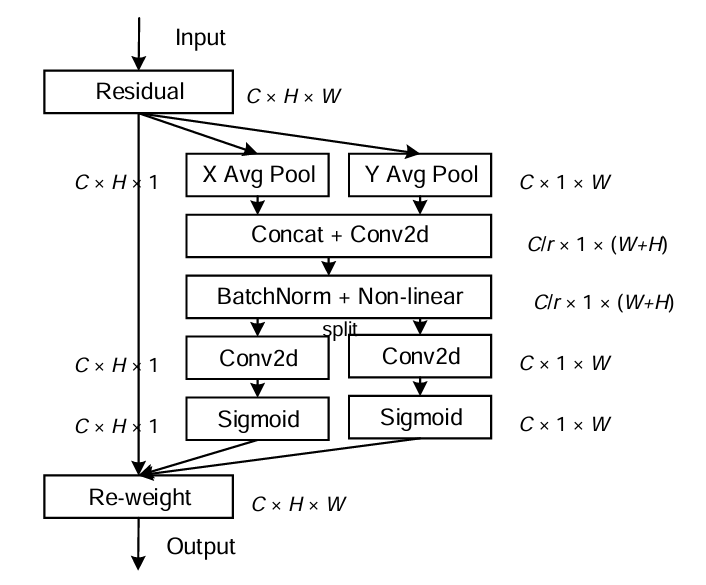
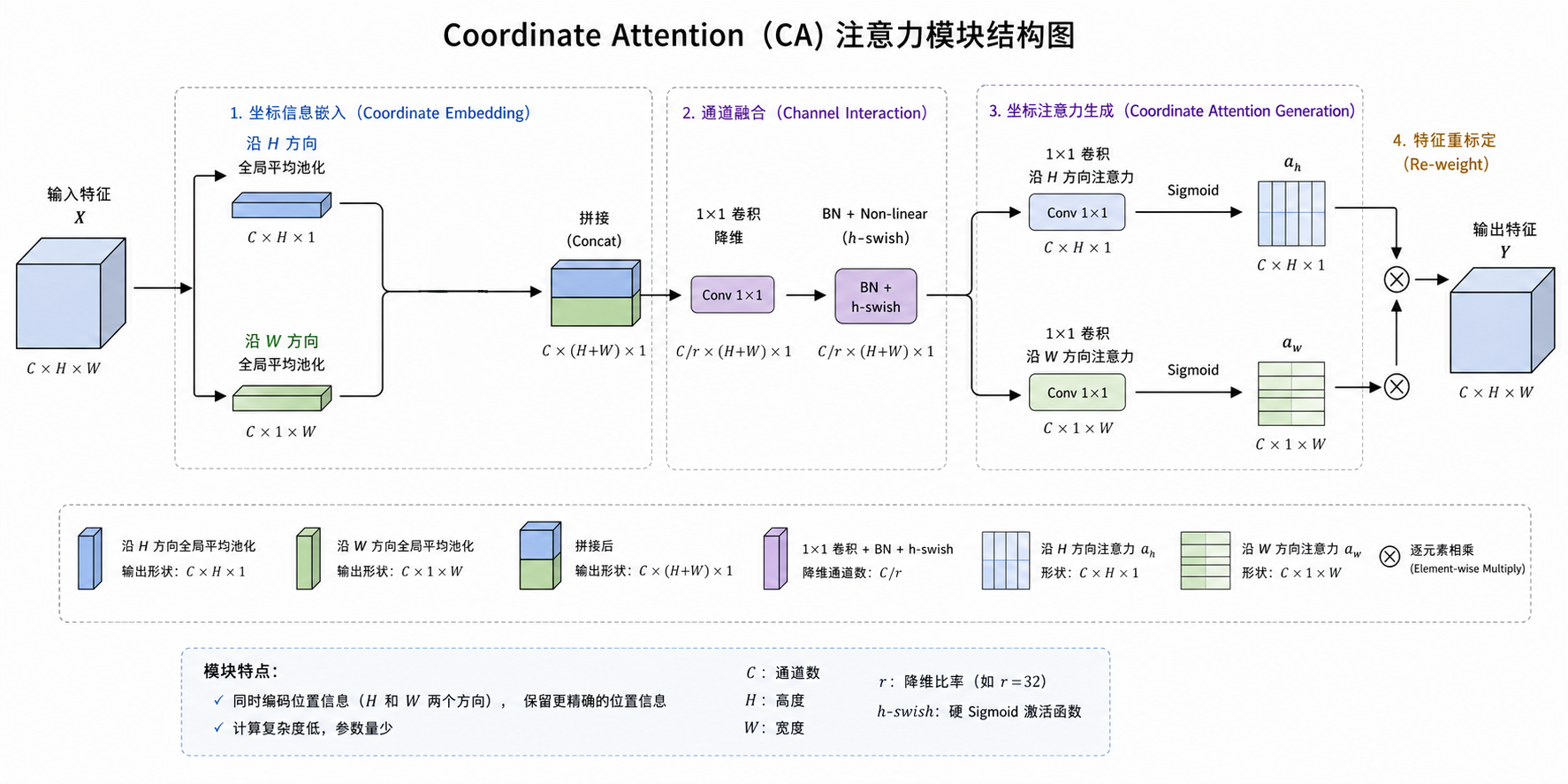
1.Coordinate Embedding(坐标信息编码)
通道注意力中经常使用全局池化来全局编码空间信息,但它将全局空间信息压缩到通道描述符中,因此难以保留位置信息,而位置信息对于捕捉视觉任务中的空间结构至关重要。
为了使注意力块能够以精确的位置信息捕获长距离的空间交互,将公式
中提出的全局池化分解为一对1D特征编码操作。具体来说,给定输入 X,我们使用两个空间范围的池化核 (H,1) 或 (1,W) 分别沿水平坐标和垂直坐标对每个通道进行编码。
因此,高度 h 上第 c 个通道的输出可以表示为
类似地,宽度 w 上第 c 个通道的输出可以写成
上述两种变换分别沿两个空间方向聚合特征,从而生成一对方向感知的特征图。这与通道注意力方法中的压缩操作生成单个特征向量的方式有很大不同。这两种变换还允许我们的注意力块沿一个空间方向捕获长距离依赖,并在另一个空间方向保留精确的位置信息,这有助于网络更准确地定位感兴趣的对象。
如上所述,这两个公式实现了全局感受野并编码了精确的位置信息。为了利用由此产生的富有表现力的表示,我们提出了第二种变换,称为坐标注意力生成。我们的设计参考了以下三个标准。首先,新的变换在移动环境中的应用应尽可能简单且成本低。其次,它可以充分利用捕获的位置信息,以便精确地突出感兴趣区域。
2.特征拼接 + 降维
具体而言,给定由公式 (8) 和公式 (9) 生成的聚合特征图,首先将它们拼接,然后送入共享的 1 × 1 卷积变换函数 F1,得到
其中 [·,·] 表示沿空间维度的拼接操作,δ 是非线性激活函数, 是同时在水平方向和垂直方向编码空间信息的中间特征图。这里的r表示下采样比例,和SE模块一样用来控制模块的大小。
接着,沿着空间维度将f切分为两个单独的张量 和
,再利用两个1x1卷积
和
将特征图
和
变换到和输入X同样的通道数,得到下式的结果
然后对和
进行拓展,作为注意力权重,CA模块的最终输出可以表述如下式。
3.代码实现
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out四、总结
SE、CBAM和CA三种注意力模块本质上体现了卷积神经网络中注意力机制从“通道建模”向“空间感知再到坐标感知”的逐步演进。
SE模块通过全局平均池化压缩空间信息,仅从通道维度学习全局重要性,结构简单但会丢失位置信息;
CBAM在此基础上引入空间注意力,将通道与空间建模串联起来,使网络不仅能够关注“哪些特征重要”,还能关注“哪些位置重要”,但其空间建模仍然较为粗粒度;
而CA模块进一步改进,通过沿水平和垂直方向分别编码空间信息,将位置信息嵌入到通道注意力之中,在保持轻量计算开销的同时,实现了对长程依赖和精细空间结构的更有效建模。
总体来看,三者在表达能力与复杂度之间形成递进关系:SE最轻量但表达有限,CBAM在性能与复杂度之间取得平衡,而CA则在轻量前提下提供更强的空间建模能力,尤其适用于对位置信息敏感的视觉任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)