pthread亲和性继承的一个坑:main绑核让整个进程退化到单核
现象
C++ 多线程进程 qfactor(19 万行/分钟的高频股票因子计算),配 work_thread_nums=8,应该用 8 个
build 线程并行处理 8 个 partition 的数据。但实测 CPU 只跑满 1 个核(101%),per-factor cycle
耗时 23 秒;同一份代码在另一个分支上 CPU 用满 8.3 核(832%),cycle 只要 2 秒。12倍速度差,但代码逻辑、编译选项、ylfeature 子模块全部完全相同。
排查过程
按嫌疑度走过的死胡同:
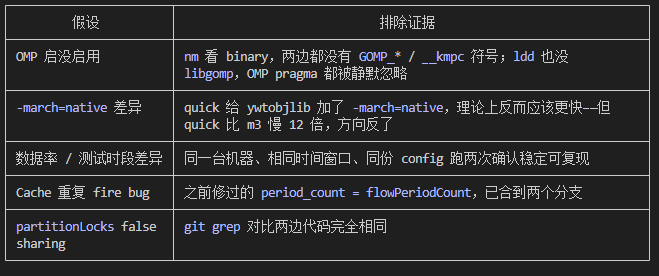
根因
// apps/qfactor/main.cc:147(quick 上有)
if (config->getOtherCpuID() >= 0) {
utility::bindCurrentThreadToCpu(config->getOtherCpuID(), "main");
} else {
utility::bindCurrentThreadToCpu(0, "main"); // ← 默认 fallback 到 CPU 0
}
m3 分支没这段。
Linux pthread_create 默认继承父线程的 CPU 亲和性(man pthread_create)。一旦 main 被
pthread_setaffinity_np 绑到单核,所有从 main 派生的子线程出生时都自动只能跑那个核:
- ✅ 显式 bindThreadToCpu 重绑的:buildThreads[i]、sendThread、checkMasterThread——pthread_create
后立刻被重绑到 config 指定核(如果 config 有),可以救回
- ❌ 没有显式重绑机制的:librdkafka 的 rdk:main / rdk:bro+ / 每个 broker 的 worker、ZMQ context
内部 epoll 线程、Boost.Log async sink 后台线程、Redis hiredis subscriber、OceanView
心跳——全部继承 main 的单核亲和性,再也回不来
如果 config 没配 other_cpu_id(很多场景默认不配),fallback 把 main 绑到 CPU0,整个进程的所有线程被锁在 CPU 0 上 time-slice 共享。12 个线程挤一核,每个线程拿到 ~7%CPU,总和 100%。
验证数据
修 main.cc,把那 5 行删掉,重编译重跑:
CPU build 线程 cycle 耗时
quick 修复前 101% 7-13% × 12 23.4s
quick 修复后 832% 87-99% × 11 2.0s ← 12× 提速
m3 对照 893% 99-100% × 11 2.0s
每只线程的 affinity mask:
- 修复前:0x1(仅 CPU 0)
- 修复后:0xffffffff...(所有核)
直接 taskset -p $tid 就能看出来。
教训
1. pthread_setaffinity_np 是有传染性的——绑了父线程,后续 spawn出来的所有线程都被传染,包括你看不见的第三方库内部线程。
2. 如果一定要绑 main,要么在所有子线程创建之后再绑,要么用 pthread_attr_setaffinity_np
给每个具体线程显式设亲和性。前者有种顺序依赖、后者要求你能控制每个线程的创建——第三方库做不到。
3. 绑核默认值不要用 0。CPU 0 是最容易被系统中断(IRQ 处理、softirq、内核 worker)打扰的核。"找不到配置就绑 0" 是双重坑:第一坑是上面的传染性,第二坑是绑了一个最忙的核。
4. 观测手段:top -H 看每个线程的 CPU% 和 R/D/S 状态,加上 taskset -p 查 affinitymask,是最快定位类似问题的组合。top 总 CPU 看着只有 100%、但有 12 个线程都活着——这种"线程多但
CPU 上不去"的反直觉模式就是亲和性继承在作祟。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)