算力集结丨云尖信息G7666V CX8+SP4+RTX PRO高性能iCluster解决方案发布
近日,DeepSeek-V4系列模型正式发布,其参数量已达到1.6万亿,上下文长度更是突破100万个token(词元),直观展现出大模型正朝着万亿级参数、百万上下文的方向加速演进,而这一演进也明确标志着下一代AI Infra的决胜关键——通信效率。要实现“更高吞吐、更低延迟“,除了高算力GPU,还需要低延迟、高带宽的网络互连,这是决定万亿参数模型能否高效运行的“生命线”。
为破解上述协同效率难题、筑牢模型运行“生命线”,云尖信息推出自研iCluster解决方案,可全面拆解核心需求、为大模型稳定高效运行提供精准支撑。

云尖信息
iCluster解决方案
云尖信息打造全自研iCluster解决方案,三大核心硬件深度适配NV核心技术,形成算力、网络、存储协同“组合拳”:G7666V X6 AI服务器(适配RTX PRO 600W GPU)+SD8891-128D交换机+高性能分布式并行存储。
关键优势:
1、全链路网络方案,网络平均时延降低38%;
2、CX8和SP4组合,保障GPU-to-GPU全400G带宽无损链路;
3、BF3和SP4协同发力,存储读写带宽和IOP提升10%,时延降低25%。
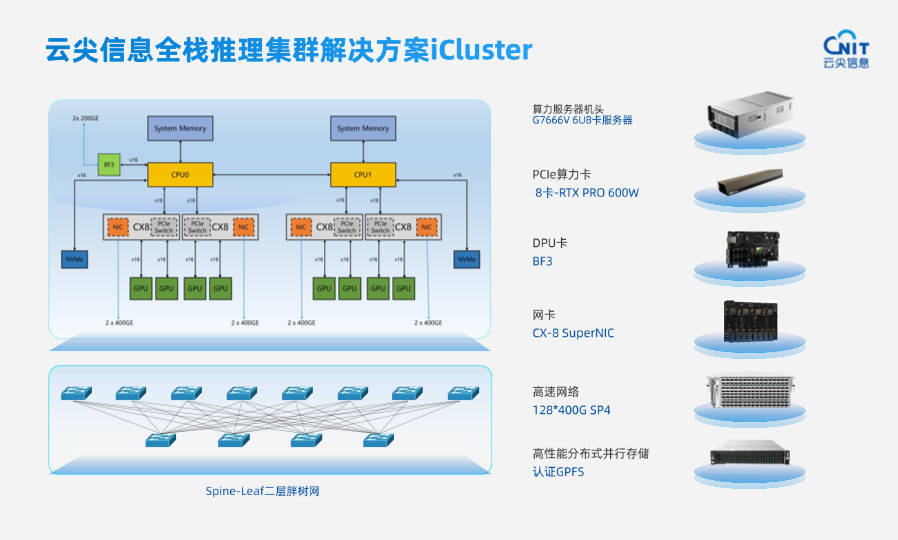
云尖信息 iCluster 解决方案
四大核心技术:算力与效率双跃升
1 FP4加速,算力倍增
-
G7666V X6高性能AI服务器与RTX PRO(单卡600W)GPU深度适配,支持8张600W双宽被动散热卡,依托Blackwell架构新引入的FP4精度算力硬件加速,直接提升2倍算力,仅损失1%精度。
2 智能通信调度,打破算力单元通信壁垒
-
实时流量感知与更优路径选择:AR技术能够实时监控网络链路状态,如同智能导航一般,为每个数据流动态计算并分配更优传输路径,有效规避拥塞节点。
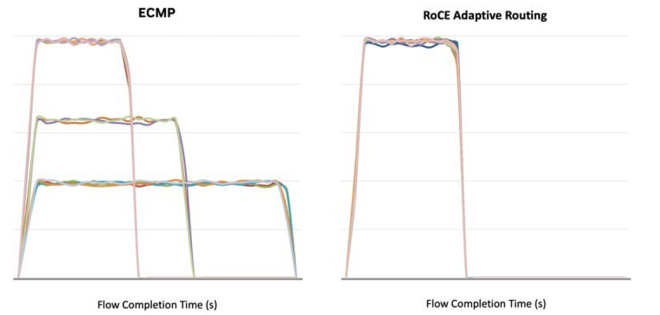
RoCE动态路由缩短了流完成时间,图源:网络
-
突破传统静态路由瓶颈:解决了传统ECMP路由在应对突发AI流量时的流量不均问题,大幅提升了网络在高负载场景下的稳定性与可靠性。
3 全链路稳控,保障关键业务稳定运行
-
微秒级高频硬件遥测: SP4+BF3组合具备实时、精准的全链路监控能力,能够捕捉网络中细微的性能指标波动。
-
动态拥塞预判与调整:结合智能算法,系统可在拥塞发生前主动介入,实现从被动响应到主动预防的跨越,有效解决多个数据发送端对单个数据接收端造成的拥塞问题。
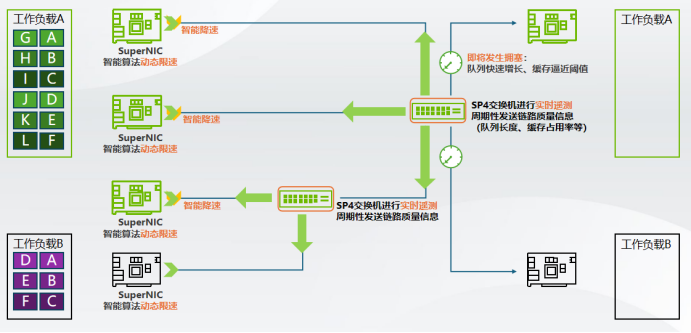
遥测与动态拥塞控制,图源:网络
4 全局缓冲隔离,高效吸收微突发流量
-
SP4通过全局共享缓冲区设计来助力性能隔离,为不同大小的流提供带宽公平性,保护工作负载免受“嘈杂邻居”流的影响,并在多个流具有相同目标端口的情况下实现更大的微突发吸收。
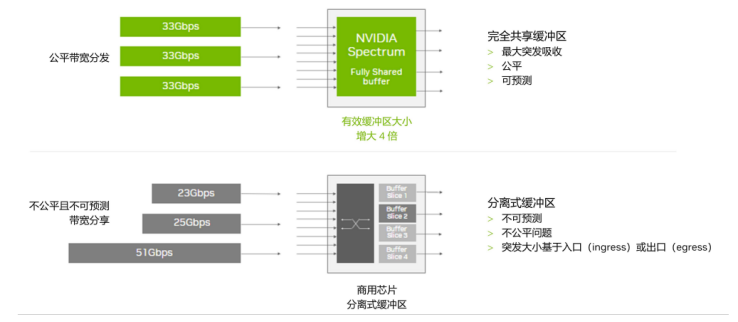
有无全局共享缓冲区的效果对比,图源:网络
三大场景实测:性能超越传统方案
场景一:PD分离
RTX PRO系列(单卡600W)GPU以高算力专注Prefill阶段,负责满足SLO TTFT;Decode阶段可选择高带宽GPU,负责满足SLO TPOT;CX8的互联优势配合SP4的无损网络,助力PD分离场景下,大规模的KV cache实现低延迟和高效传输,同时也将RTX PRO系列(单卡600W)预填充性能提升约1.4倍。
场景二:自动驾驶
RTX PRO系列(单卡600W)专司多模态传感器数据流的实时渲染,使用3DGS等技术将图像、激光雷达等数据实时渲染成逼真的场景。而CX8+SP4以其存储节点、计算节点间超低延迟与高带宽特性,有力地支撑了自动驾驶场景中TB~EB级别数据加载、VLA/世界模型的训练、仿真流程;同时,它也将仿真产生的巨量结果数据高速输出。根据实际业务场景测试,这种组合方式比H20的方案性能提升0.7~2倍。
场景三:金融量化
量化策略每日产生TB级实时行情等数据,通过高速网络注入分布式存储区,在做数据清洗等任务时,CX8+SP4网络确保数据无损,低延迟加载到RTX PRO系列(单卡600W)GPU中。根据实际业务场景测试,这种组合方式比A100的方案性能提升1.1~2.7倍。
无论是自动驾驶场景下所需要的高保真实时仿真,还是金融市场上追逐微秒优势的量化交易,亦或是现在主流推进的PD分离,该方案都提供了领先、坚实的技术支撑。
云尖信息iCluster解决方案并非一次简单的硬件迭代,而是一次面向未来的计算范式革新,不仅实现算力加速,更贯穿洞察、决策、创新全价值链,实现全流程能效提升

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)