【大模型-VA】Causal World Modeling for Robot Control
Website: https://technology.robbyant.com/lingbot-va
Github: https://github.com/robbyant/lingbot-va
Checkpoints: https://huggingface.co/robbyant/lingbot-va
摘要
这项工作强调,视频世界建模与视觉语言预训练相结合,为机器人学习建立了一个全新且独立的基础。直观地说,视频世界模型能够通过理解动作和视觉动态之间的因果关系来“想象”近期未来。受此启发,我们提出了 LingBot-VA,一个自回归扩散框架(an autoregressive diffusion framework),可以同时学习帧预测和策略执行。
我们的模型包含三个精心设计的结构:
(1)一个共享的潜在空间,整合了视觉和动作标记,由 Transformer 混合模型(MoT)驱动;
(2)一个闭环展开机制,允许持续获取环境反馈和真实观测数据;
(3)一个异步推理流水线,并行化动作预测和运动执行,以支持高效控制。
我们在仿真基准测试和真实场景中评估了我们的模型,结果表明,该模型在长时程操作、训练后数据效率以及对新配置的强大泛化能力方面都展现出显著优势。为了方便社区使用,代码和模型均已公开。
1 Introduction
视觉-语言-动作(VLA)模型已成为通用机器人操作领域极具前景的范式[7, 11, 12, 34],展现出将语言指令转化为视觉感知,并应用于各种物体和非结构化环境的强大能力。然而,在其表面的成功背后隐藏着一个重大挑战:表征纠缠representation entanglement。大多数现有的VLA模型采用前馈范式,将当前观测结果映射到动作序列[17, 91],这要求单个神经网络能够从统一的监督信号中同时学习视觉场景理解、物理动力学和运动控制。这种纠缠会造成瓶颈——模型必须将从高维视觉语义到低维运动指令等异构知识压缩到一个共享的表征空间中。这通常会导致样本效率低下和泛化能力欠佳。如果没有对环境演化进行显式建模[25, 26, 82],反应策略可能依赖于模式匹配,而非对物理动力学的原理性理解。
近期将世界建模引入机器人策略的尝试包括交互式神经模拟器(例如 UniSim [86])、基于块的视频动作扩散模型(例如 UVA [40] 和 UWM [97])以及用于子目标合成的离线视频生成器(例如 Gen2Act [4] 和 Act2Goal [95])。尽管这些方法在概念上很有吸引力,但它们在实现有效的闭环控制方面存在三个主要局限性。
- 首先是反应性差距:块/开环生成通常会生成较长的片段,而没有整合实时反馈,因此难以适应干扰。
- 其次是长期记忆有限:如果历史记录没有被持久缓存,块生成可能会在较长的时间范围内引入不一致性。
- 第三是因果关系:片段内的双向注意力允许未来的标记影响过去的预测,这与物理现实的因果性质相悖,在物理现实中,现在仅取决于过去。这些观察结果促使我们提出一种自回归模型来实现鲁棒的闭环推理。
Recent attempts to bring world modeling into robotic policies span interactive neural simulators (e.g., UniSim [86]), chunk-based video-action diffusion models (e.g., UVA [40] and UWM [97]), and offline video generators for subgoal synthesis (e.g. Gen2Act [4], Act2Goal [95]). While conceptually appealing, these approaches face three primary limitations for effective closed-loop control. First, the reactivity gap: chunk/open-loop generation often rolls out long segments without incorporating real-time feedback, making it hard to adapt to disturbances. Second, limited long-term memory: chunk-wise generation can introduce inconsistencies over long horizons when history is not persistently cached. Third, causality: bidirectional attention within a segment allows future tokens to influence past predictions, which diverges from the causal nature of physical reality where the present depends only on the past. These observations motivate an autoregressive formulation for robust closed-loop reasoning.
我们提出了 LingBot-VA,一种自回归扩散世界模型,它通过统一的视频-动作框架来解决这些局限性。与预测离散词元的自回归语言模型不同,我们的模型通过流匹配 [46, 50] 在连续的潜在空间中运行,并通过迭代去噪自回归地生成视频和动作表征片段。虽然我们的方法在概念上将视觉动态预测和动作解码 [22, 27] 分开,但其关键架构在于将视频和动作词元交错到一个自回归序列中。两种模态通过具有共享注意力机制的混合 Transformer (MoT) 架构 [43] 进行联合处理。在这个统一的自回归生成过程中,潜在想象和动作推断同时发生:在每个自回归步骤中,模型通过迭代去噪生成预测的未来视觉状态,同时解码相应的动作,从而使两个流能够相互影响。该集成方法基于大规模预训练视频扩散骨干网络[79],
具有以下几个优势:
- (i) 响应式AR循环:由于视频和动作标记构成统一序列,每个自回归步骤都允许系统基于最新的真实世界观测结果进行重新校准,从而能够及时调整预测的未来状态和运动指令;
- (ii) 通过KV缓存保持上下文持久性:缓存的键值对保留了交错的视频-动作轨迹,提供了丰富的上下文信息,有助于缓解时间漂移;
- (iii) 因果一致性:对统一序列进行因果注意力掩蔽,确保预测的视觉状态和动作指令都受先前状态的约束,符合物理动力学的时间方向。通过在每一步都融入真实世界观测结果,该方法有助于缓解常影响长时程任务中开环方法的分布漂移。
部署大规模自回归视频动作模型的主要挑战之一是推理延迟;通过迭代去噪生成高保真视频标记需要大量的计算资源。我们通过两种互补的策略来解决这个问题。
- 首先,我们引入了噪声历史增强(Noisy History Augmentation),这是一种能够在推理时进行部分去噪的训练方案。其关键在于,动作解码并不总是需要像素级的完美重建;相反,它可以依赖于鲁棒的语义结构。通过训练动作解码器从部分噪声的潜在表示中进行预测,我们显著降低了计算开销,同时保持了动作预测的精确性。
- 其次,我们设计了一个异步协调流水线,将计算与执行重叠:当机器人执行当前动作时,世界模型预测未来的视觉状态并规划后续序列。这种并行架构结合可变块大小的训练,能够在不影响预测质量的前提下实现高频闭环控制。
我们在模拟和真实环境中,针对各种操作任务对 LingBot-VA 进行了评估。我们的方法展现出与最先进的 VLA 策略相媲美的性能,尤其是在需要时间一致性的长时程任务中。我们的贡献总结如下:
• 自回归视频动作世界建模:我们引入了一种自回归扩散框架,该框架在架构上将视觉动态预测和动作推理统一到一个交错序列中,同时保持二者在概念上的区别。该框架通过键值缓存支持持久记忆,并通过注意力掩蔽支持因果一致性。
• 具有异步执行的混合Transformer架构:我们设计了一种具有非对称容量的双流MoT架构,并引入了一种结合异步协调的部分去噪策略,以实现高效的机器人控制。
• 卓越的长时域和高精度性能:大量的真实世界和仿真实验表明,我们的方法始终保持着最先进的性能,尤其是在长时域和高精度操作任务方面取得了显著的改进。我们的方法还显著提高了采样效率,并具有很强的泛化能力,能够适应新的场景和物体配置。
Related Work
Vision-Language-Action Policies
近年来,具身人工智能领域取得了显著进展,其范式已转向大规模视觉-语言-动作(VLA)策略。通过利用网络规模的知识和多样化的机器人演示,诸如π0.5 [29]、GR-3 [39] 和 GR00T-N1 [6] 等模型无需依赖手工设计的规则、模块化先验或受限的动作抽象,即可在各种操作任务中实现卓越的泛化能力,从而实现从感知到控制的更直接、更具表现力的端到端映射。这些策略通常采用预训练的视觉语言模型(VLM)作为基础骨干 [6, 7, 11, 29, 34, 39, 87, 93],与 ACT [91] 或扩散策略 [17] 等特定任务的模仿策略相比,它们能够提供更优异的跨模态理解和更具泛化性的动作分布。为了进一步提升部署能力,研究人员已投入大量精力,例如采用轻量级骨干网络[49, 62, 67]、高效分词[57]、实时推理[8, 10, 70]或微调方案[30, 32, 38]。然而,尽管这些模型在语义推理方面表现出色,但一个根本性的局限性依然存在:标准可变长度模型(VLM)的预训练目标和数据分布在很大程度上忽略了精细的系统动力学和底层轨迹,而这些对于精确操作至关重要。虽然在耗资巨大的机器人数据集上进行监督式微调可以使这些模型近似于边缘动作分布[3, 31, 53],但它们在捕捉底层转换动力学方面仍然存在不足——特别是环境的物理状态应该如何演变以及将会如何演变。此外,大多数当前的可变长度算法(VLA)将控制建模为从瞬时观测到动作的纯粹被动映射。这种方法本质上无法考虑解决非马尔可夫环境中歧义所需的历史背景。此外,视频逻辑模型(VLM)固有的静态图像-文本预训练无法灌输必要的时间先验信息。即使添加了记忆模块[37, 65, 68],这类模型仍然无法推断物理交互的因果关系和序列性。为了弥补这些不足,近期的研究转向了基于世界模型和生成式视频建模的通用机器人策略[1, 5, 40, 64, 97]。然而,这些方法通常使用双向注意力机制生成预测,这违背了物理动力学的因果结构,并且缺乏贯穿整个执行历史的持久长期记忆。我们的LingBot-VA将自回归视频预测与动作解码统一在一个严格的因果时间结构下,其中每个预测都完全基于过去的观察和动作。 LingBot-VA 通过维护整个交互历史的持久 KV 缓存,确保了长期的时间一致性,并允许策略将物理执行与环境的预测视觉演变同步。
World Models for Robotic Control.
受人类依靠直觉物理学来预测环境变化的启发,世界模型旨在通过预测未来动态来促进有效的规划。现有方法通常根据其状态表示分为三类。
- 第一类在潜在空间中运行[36, 41, 63, 80],将任务相关特征编码成紧凑的向量,并通过概率方法[36, 52, 83]或确定性方法[63, 85]预测演化。
- 第二类利用三维点云[66, 69, 77],并借助图神经网络(GNN)预测几何演化[88, 89],这对于操控可变形物体尤其有效[77, 89]。
- 第三类专注于二维像素空间,直接预测未来的关键帧或视频序列[21, 33, 95, 96]。
我们的工作属于第三类。在该领域,研究方法涵盖了从与视频生成协同训练以进行表征学习[14, 40, 97]到作为策略学习或评估的模拟器[71]等多种应用。我们的研究专门针对在执行过程中预测未来帧以指导动作生成的方法。然而,以往的视频条件方法主要依赖于开环生成[21, 95],这带来了两个重大挑战。首先,生成的视频与真实世界动态之间的不匹配,加上执行误差的累积漂移,通常会导致性能欠佳。其次,视频生成的计算密集型特性会造成高延迟,严重阻碍实时推理。我们的方法利用键值缓存和因果掩码,持续地用真实世界的观测数据更新模型的内存。这有效地将系统过渡到闭环控制机制,从而减轻了长时域任务中的误差累积。此外,我们引入了一种部分去噪策略,使得无需等待完全去噪的帧即可从中间表征生成动作。
2 Preliminary
这段内容主要介绍了流匹配(Flow Matching)这一生成式建模框架,以及它如何被应用于视频生成任务中。为了便于理解,可以将这两个部分拆解开来分析:
1. 流匹配 (Flow Matching) 的基础原理
流匹配是一种连续的生成建模方法,其核心思想是学习一个“流”的过程,将简单的噪声分布逐渐变形为复杂的目标数据分布。
- 起点与终点:生成过程始于一个简单的源分布(通常是高斯噪声 ϵ\epsilonϵ),终于真实的数据样本(x1x_1x1)。
- 定义路径:为了让噪声变成数据,模型定义了一个随时间 sss(从0到1)变化的插值路径 x(s)x^{(s)}x(s)。这里采用的是最简单的线性插值:x(s)=(1−s)ϵ+sx1x^{(s)} = (1-s)\epsilon + s x_1x(s)=(1−s)ϵ+sx1。这意味着在第 sss 时刻,样本处于噪声和真实数据之间的某个位置。
- 学习速度场:这是流匹配的关键。模型不学习样本本身,而是学习一个速度场 vsv_svs。这个速度场描述了在这个插值路径上,每个点应该以多快的速度、朝哪个方向移动。数学上表示为常微分方程 (ODE):dx(s)ds=vs(x(s))\frac{dx^{(s)}}{ds} = v_s(x^{(s)})dsdx(s)=vs(x(s))。
- 训练目标:模型(参数为 θ\thetaθ)的目标是预测出这个真实的速度场。训练时的损失函数是预测速度 vθv_\thetavθ 与真实速度 x˙(s)\dot{x}^{(s)}x˙(s) 之间的均方误差。根据定义的线性路径,真实速度其实就是数据点减去噪声(x˙(s)=x1−ϵ\dot{x}^{(s)} = x_1 - \epsilonx˙(s)=x1−ϵ),这是一个固定的已知值,非常有利于模型学习。
- 生成样本:训练完成后,要生成一张新图片,只需从随机噪声出发,利用学到的速度场 vθv_\thetavθ 沿着路径积分(即求解ODE),从 s=0s=0s=0 走到 s=1s=1s=1,噪声就会顺着流场“流动”成最终的图像 x1x_1x1。
2. 条件流匹配在视频生成中的应用
第二部分将上述原理扩展到复杂的视频生成领域,特别是引入了“条件控制”。
- 潜在空间操作:直接在像素层面处理视频数据量巨大。因此,模型通常在预训练的自编码器的**潜在空间(Latent Space)**中工作。视频帧被编码器压缩成低维的潜在表示 ztz_tzt,模型实际上是在生成这些潜在特征。
- 条件生成:视频生成通常不是凭空产生,而是基于某种条件 ccc(例如一段文字描述“一只猫在草地上跑”,或者一张初始图片)。
- 序列生成:模型的目标变为学习生成一个潜在视频帧序列 z={z1,…,zT}z = \{z_1, \dots, z_T\}z={z1,…,zT}。公式 (4) 表明,模型会根据当前的时间步 sss 和条件 ccc,预测潜在变量 z(s)z^{(s)}z(s) 的变化速度,从而构建出整个视频的演变轨迹。
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
# 1. 定义线性插值路径(在潜在空间中)
def linear_interpolation(z0, z1, t):
"""
z0: 噪声潜变量 [B, C, T, H, W]
z1: 真实数据潜变量 [B, C, T, H, W]
t: 时间步 [B, 1, 1, 1, 1] 或标量
返回: z_t = (1-t)*z0 + t*z1
"""
return (1 - t) * z0 + t * z1
# 2. 定义速度场模型(这里用3D U-Net示例)
class VelocityField3D(nn.Module):
def __init__(self, in_channels, condition_dim, hidden_dims=[64, 128, 256]):
super().__init__()
# 实际实现会更复杂,这里简化为多层卷积
self.conv1 = nn.Conv3d(in_channels + condition_dim, hidden_dims[0], 3, padding=1)
self.conv2 = nn.Conv3d(hidden_dims[0], hidden_dims[1], 3, padding=1)
self.conv3 = nn.Conv3d(hidden_dims[1], hidden_dims[2], 3, padding=1)
self.conv4 = nn.Conv3d(hidden_dims[2], in_channels, 3, padding=1)
def forward(self, z, t, condition):
"""
z: 当前潜变量 [B, C, T, H, W]
t: 时间步 [B, 1, 1, 1, 1]
condition: 条件(如文本嵌入)[B, D]
返回: 预测的速度场 [B, C, T, H, W]
"""
# 将时间步和条件广播到与z相同的空间维度
B, C, T, H, W = z.shape
condition_expanded = condition.view(B, -1, 1, 1, 1).expand(-1, -1, T, H, W)
t_expanded = t.expand(-1, -1, T, H, W)
# 拼接输入
x = torch.cat([z, condition_expanded, t_expanded], dim=1)
# 前向传播
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
v = self.conv4(x) # 预测的速度场
return v
# 3. 训练步骤
def train_step(model, z1, condition, optimizer):
"""
z1: 真实视频的潜变量 [B, C, T, H, W]
condition: 条件(如文本嵌入)[B, D]
"""
model.train()
optimizer.zero_grad()
B = z1.shape[0]
# 1. 随机采样噪声
z0 = torch.randn_like(z1) # 从标准高斯分布采样
# 2. 随机采样时间步
t = torch.rand(B, 1, 1, 1, 1, device=z1.device) # 均匀分布U[0,1]
# 3. 计算线性插值
z_t = linear_interpolation(z0, z1, t)
# 4. 计算真实速度(对于线性路径,真实速度是常数)
v_true = z1 - z0
# 5. 模型预测速度
v_pred = model(z_t, t, condition)
# 6. 计算损失:预测速度与真实速度的MSE
loss = F.mse_loss(v_pred, v_true)
# 7. 反向传播
loss.backward()
optimizer.step()
return loss.item()
# 4. 采样生成(使用ODE求解器)
def generate_video(model, condition, num_frames, latent_shape, device='cuda', steps=100):
"""
从噪声生成视频潜变量
condition: 条件 [1, D]
num_frames: 视频帧数
latent_shape: 单帧潜变量形状 [C, H, W]
steps: ODE求解步数
"""
model.eval()
# 初始化噪声
z = torch.randn(1, latent_shape[0], num_frames,
latent_shape[1], latent_shape[2]).to(device)
# 时间步从0到1
dt = 1.0 / steps
with torch.no_grad():
for i in tqdm(range(steps)):
t = torch.tensor([[i * dt]], device=device).view(1, 1, 1, 1, 1)
# 预测速度场
v = model(z, t, condition)
# 前向欧拉法(实际可用更高级的ODE求解器)
z = z + v * dt
return z # 生成的视频潜变量
# 5. 完整训练循环示例
def train_model(model, train_loader, condition_encoder, num_epochs=100):
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(num_epochs):
total_loss = 0
for batch in tqdm(train_loader):
# batch: 视频数据 [B, C, T, H, W]
videos = batch['video'].cuda()
conditions = batch['condition'] # 如文本描述
# 编码条件(这里简化为通过预训练模型)
with torch.no_grad():
condition_emb = condition_encoder(conditions).cuda()
# 视频编码到潜空间(这里简化为使用预训练的自编码器)
with torch.no_grad():
z1 = video_encoder(videos) # [B, C_latent, T, H_latent, W_latent]
# 训练步骤
loss = train_step(model, z1, condition_emb, optimizer)
total_loss += loss
print(f"Epoch {epoch}, Loss: {total_loss/len(train_loader):.4f}")
# 6. 使用示例
if __name__ == "__main__":
# 假设参数
latent_channels = 4
condition_dim = 512
num_frames = 16
latent_height = 32
latent_width = 32
# 初始化
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = VelocityField3D(latent_channels, condition_dim).to(device)
# 模拟条件(如CLIP文本嵌入)
condition = torch.randn(1, condition_dim).to(device)
# 生成视频
latent_shape = (latent_channels, latent_height, latent_width)
generated_latent = generate_video(
model, condition, num_frames, latent_shape, device, steps=50
)
print(f"生成潜变量形状: {generated_latent.shape}")
# 之后可以通过解码器将潜变量解码为视频帧
真实系统如Stable Video Diffusion的实现会更加复杂,包含多尺度训练、更精细的条件控制等。
3 Method
3.1 Problem Statement & Approach Overview
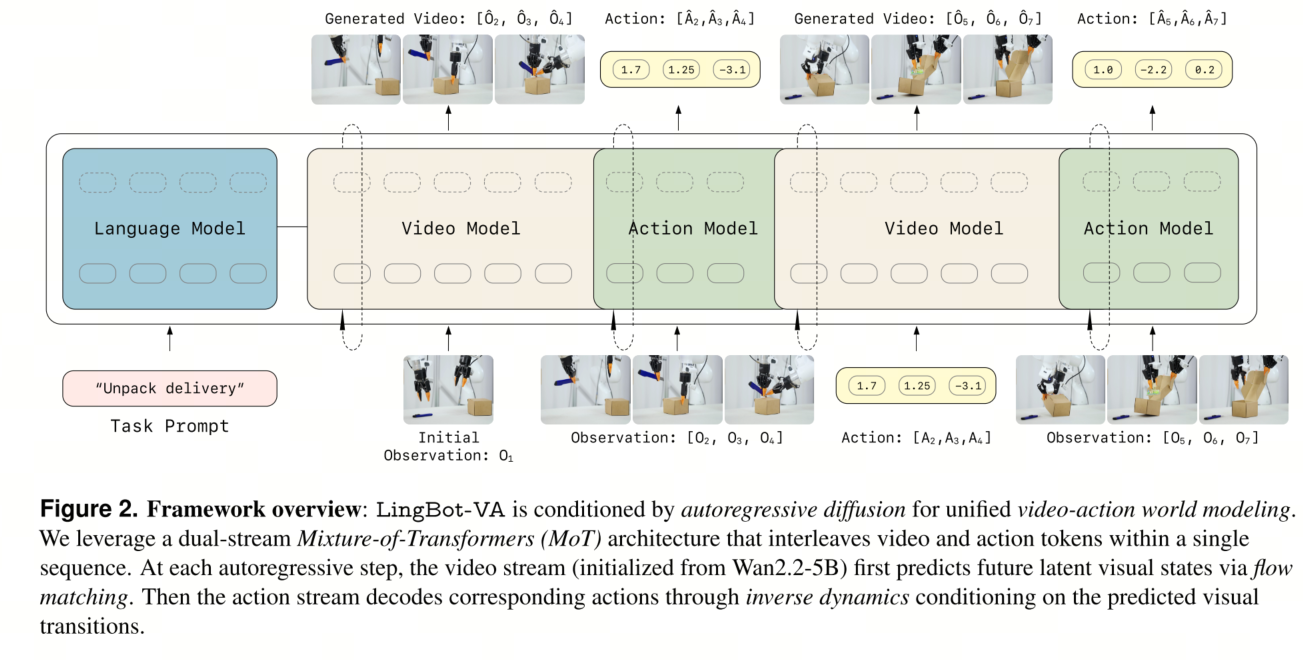
Vision-Language-Action (VLA) Policies.
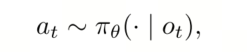
在每个时间步t,智能体接收到视觉观测值ot,并在at处执行一个动作,该动作会引起底层物理世界的转换,并产生下一个观测值ot+1。
本文方法
与直接学习动作分布的VLA策略[学习π(at | ot)]不同,我们采用世界建模的视角,预测视觉世界将如何演变,然后基于这些预测推断动作。我们的方法分两个阶段进行: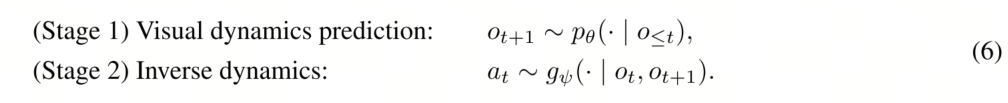
方法概述。图 2 展示了我们框架的细节。我们的方法包含三个关键组件,详见以下小节:
- (§3.2)自回归视频动作世界建模描述了我们如何在潜在空间中对视觉动态进行建模,并从预测的状态转换中解码动作——这是我们方法的核心公式;
- (§3.3)LingBot-VA:统一架构与训练介绍了我们用于视频动作预训练的统一模型,包括架构设计和训练目标——这是我们公式的具体实现;
- (§3.4)实时部署与异步推理介绍了我们的部署策略,该策略通过并行预测和执行实现实时控制——这是机器人控制的实际应用。
3.2 Autoregressive Video-Action World Modeling
以往的视频世界模型要么侧重于开放式的视频预测[54],要么学习动作条件化的交互环境[13, 56],主要用于游戏或模拟领域,但这些模型可能无法直接应用于精确的机器人操作。为了利用视频数据中丰富的视觉动态先验信息进行机器人操作,我们提出了一种统一的视频-动作世界建模框架,该框架在一个自回归过程中联合建模视觉观察和机器人动作。
- 以往将视频预测与动作推断分离(decouple video prediction from action inference)[16, 27]或依赖于片段内双向扩散(bidirectional diffusion within segments)[97]的方法。一次性生成完整长序列的开环方法计算成本过高,且无法整合实时反馈进行纠错。存在两个关键问题:
- (1) 由于每个分块都是独立生成的,无法访问完整的历史记录,因此缺乏跨分块的持久记忆,导致时间上的不一致性以及长期的漂移;
- (2) 每个分块内的双向注意力机制违反了因果关系,阻碍了与执行过程中实时观测的无缝集成。
- 我们的方法将视频和动作统一在一个因果自回归框架(single causal autoregressive framework)中,通过键值缓存实现持久记忆,并无缝集成实时观察结果。
World Dynamics with Autoregressive Modeling.
物理世界本质上是因果的和自回归的:当前状态仅取决于过去,我们无法在未来发生之前对其进行观测。这一基本特性促使我们提出自回归世界建模方法,该方法相比基于块的扩散方法在机器人控制方面具有三个关键优势:
- (1)持久记忆:通过因果注意力机制和KV缓存显式地对完整的观测历史进行条件化,该模型能够在整个轨迹中保持长期上下文和时间一致性,避免了基于块的方法的“失忆”问题;
- (2)因果一致性:单向依赖结构自然地与闭环执行相一致,新的观测数据可以无缝地融入其中;
- (3)效率:分块预测,并在每个块内进行并行生成,平衡了计算效率和自回归的灵活性,从而实现了高频控制和实时纠错。
我们将其形式化为一个自回归过程:在每个步骤中,世界模型使用条件流匹配来预测下一个包含 K 帧的视频块: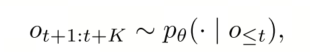
其中,每个视频块内的标记通过双向注意力机制并行生成,同时保持跨块的因果结构。这种分块式的构建方式兼顾了生成效率和自回归的灵活性,从而实现闭环校正。
Video-Action State Encoding.
通过压缩和令牌化,将高维冗余的视频流与机器人的动作指令统一到同一个低维、序列化的表示空间中,从而让模型能够进行高效的联合学习和预测。
具体可以从以下三个层面理解:
-
解决的核心问题:直接处理原始像素视频(
ot)数据量极大、计算成本过高,且包含大量冗余信息。因此需要一种高效的压缩表示方法。 -
关键技术方法:
- 视频压缩与表示:使用因果视频VAE,将每一时刻的视觉观测
ot编码成一组紧凑的潜在令牌zt。其关键特点是“因果性”——编码当前帧时会条件依赖于之前帧的潜在状态 (o<t),这确保了编码后的视频序列在时间上是连贯的,不会出现帧间跳跃或断裂,非常适合用于需要根据历史预测未来的自回归模型。 - 动作对齐:机器人的动作
at本身是向量。通过一个轻量级网络ϕ(·)将其投影到与视觉令牌zt维度相匹配的令牌嵌入。这样,动作和视觉信息就被“翻译”成了同一种“语言”。
- 视频压缩与表示:使用因果视频VAE,将每一时刻的视觉观测
-
最终目的与形式:将处理后的视觉令牌
zt和动作令牌嵌入ϕ(at)像拼积木一样交错拼接起来,形成一个统一的令牌序列:[z1, a1, z2, a2, ...]。这个序列可以直接输入给类似Transformer的自回归模型进行训练,让模型学习视觉观测与机器人动作之间的复杂因果关系,从而实现对世界动态的建模和预测。
Latent Video State Transition.
我们将自回归公式扩展到同时基于观测历史和动作历史的条件化,这使得世界模型能够将预测建立在实体状态之上,从而确保预测的观察结果反映机器人与场景的物理交互。
Inverse Dynamics for Action Decoding.
一旦世界模型预测出未来的视觉状态,我们就利用这些预测来规划行动。我们并非直接从当前观测结果预测行动,而是采用逆动力学模型。
然而,仅基于当前状态和下一状态 (zt, zt+1) 进行条件预测不足以准确预测动作。
动作历史 a<t 编码了身体的状态轨迹,用于确定可行动作,而观察历史 z<t 则为多步交互提供了时间上下文(例如,物体是否曾被抓取)。
因此,我们将逆动力学表述为:
IDM 是 Inverse Dynamics Model(逆动力学模型) 的缩写。
它是一种在机器人学和强化学习中常用的模型,其核心功能是:根据系统当前的状态和期望达到的下一状态,推断出需要执行的动作。
这与更常见的正向动力学模型正好相反:
- 正向模型:输入当前状态和当前动作,预测下一个状态会是什么。
- 逆动力学模型(IDM):输入当前状态和期望的下一个状态(即“未来目标”),推断出需要执行什么动作才能实现这个状态转变。
在你提供的语境中,IDM-based policies 指的是基于逆动力学的策略。这种策略的工作方式如下:
- 设定目标:首先设定一个想要达到的未来状态(例如,机器手移动到某个位置)。
- 逆向推断:IDM 模型根据机器人当前的状态(本体动态)和这个未来目标,反向计算出一个可行且符合物理规律的动作。
- 执行动作:机器人执行这个推断出的动作。
这种方法的优势在于:
- 目标驱动:策略直接由高级目标引导,更直观。
- 动态一致性:由于模型在推断时考虑了机器人的“本体动态”,生成的动作天然地符合机器人的物理约束,避免了不切实际或无法执行的动作。
- 在之前描述的世界建模框架中,模型学习了状态(视觉令牌
zt)和动作(动作令牌at)之间的序列关系。一个训练良好的IDM可以看作是这种关系的一个具体应用——当模型在序列中“看到”当前状态和下一个状态时,它就能准确地“补全”中间应该发生的动作。
因此,IDM 是实现智能体精准控制、特别是模仿学习和离线强化学习中的一种强大工具。
3.3 LingBot-VA: Unified Architecture & Training
架构。为了联合建模视频和动作生成,我们利用双流扩散变换器架构,该架构执行条件流匹配以实现自回归预测。
- 我们的模型由两个并行的变换器骨干组成:
- 一个视频流,其初始化基于 Wan2.2-5B(一个维度为 dv 的大规模预训练视频生成模型 [79]);
- 以及一个深度相同但宽度显著小于 dv 的动作流 da。
这种非对称设计源于以下观察:动作分布本质上比视觉数据更简单,因此只需更少的参数即可有效建模,同时保持对视觉动态的表达能力。
视频稀疏化。
视频帧存在显著的时间冗余,尤其是在场景逐渐演变的机器人操作中。我们通过将帧的时间下采样因子τ = 4来稀疏化视频序列,从而减少视觉标记并提高效率[5]。由于动作的演变频率高于视觉变化,我们将下采样后的视频标记与动作标记按时间顺序交错排列:对于每个视频帧ot,我们关联τ个连续动作{at,1, at,2, …, at,τ},形成一个统一的序列[zt, at,1, at,2, …, at,τ, zt+1, …]用于联合建模。这种设计意味着预测K个视频帧对应于生成τK个动作,从而在保持高效视频生成的同时实现高频控制。
混合Transformer模块
为了在保持模态特定特征空间的同时实现交互,我们采用了混合Transformer(MOT)架构[5, 19, 43]。在该架构中,视频和动作标记在每一层分别由独立的Transformer模块处理,然后通过跨模态注意力机制进行融合[5]。在每一层,视频流和动作流使用独立的QKV投影矩阵计算其查询矩阵、键矩阵和值矩阵,从而为每个模态保持不同的特征空间。为了对齐跨模态融合的维度,动作标记首先通过线性层投影到视频维度,参与联合自注意力机制,然后通过残差连接投影回其原始维度,从而保留动作的特定表示。这种MOT设计允许视频和动作通过注意力机制相互影响,同时保持各自的参数化,防止模态特定特征表示之间的干扰。对于动作解码,最终的动作流输出通过线性投影头映射到低维动作向量。
动作网络初始化。
动作流的正确初始化对于训练的稳定性和收敛性至关重要。我们发现,从头开始训练动作网络会导致优化不稳定和收敛速度缓慢,因为动作标记的输出分布最初与视频分布存在显著差异,从而破坏了联合注意力机制。为了解决这个问题,我们首先根据动作维度对预训练的视频权重进行插值,然后应用缩放因子 α = p dv/da 来保持输出方差,其中 dv 和 da 分别是视频和动作的维度。这种初始化策略确保动作标记的初始输出分布与视频标记的输出分布相当,从而稳定早期训练并加速收敛。
可变块大小训练。
为了实现灵活部署,我们在训练过程中从预定义的范围内随机抽取块大小 K。通过使用可变块大小(例如,K ∈ [1, 8])进行训练,模型可以学习在不同的时间范围内生成一致的预测。在推理阶段,这使得我们可以自由选择块大小,以平衡计算效率和规划范围——较大的块大小可以减少自回归步骤的数量,但需要更长的单步计算时间;而较小的块大小则可以实现更频繁的闭环校正。在我们的实验中,我们使用 K = 4 进行部署,这是一个比较实际的折衷方案。
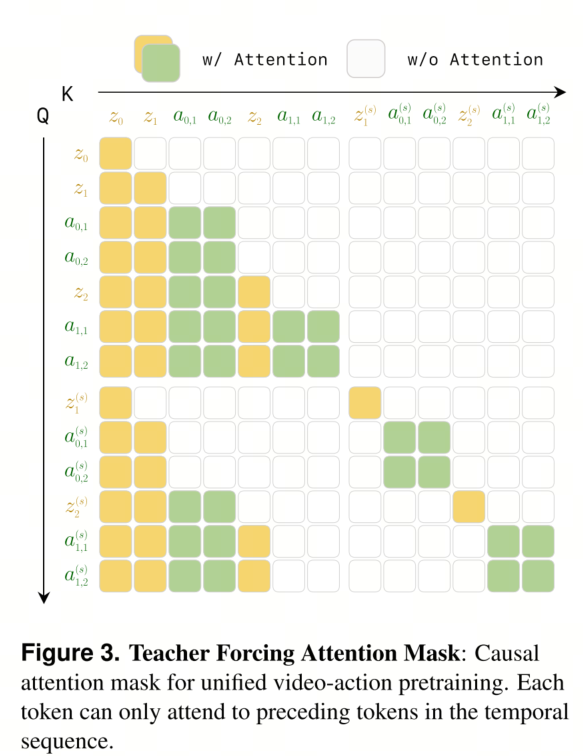
教师强制法用于统一的视频动作训练。
在 §3.2 中,我们将视觉动态预测(公式 7)和逆动态(公式 8)都建模为自回归模型问题,其中每个预测都基于观测和动作的历史。这种统一的自回归模型支持一种自然的训练策略:我们可以将交错的视频动作序列视为一个统一的序列,并使用标准的下一个标记预测来训练模型,类似于自然语言处理中的语言建模 [76]。
具体来说,给定一个包含交错标记的片段,我们训练模型以预测序列中每个标记,并使其基于序列中所有先前的标记。这是通过教师强制法实现的:在训练过程中,我们使用数据集中的真实标记作为预测后续标记的上下文,而不是模型生成的预测。因果依赖结构通过注意力掩蔽(图 3)来强制执行——每个标记只能关注在时间序列中更早出现的标记。
重要的是,教师强制方法尤其适用于机器人操作:与纯生成模型导致的训练集-测试集分布不匹配不同,机器人策略在部署过程中能够自然地获取真实世界的观测数据,从而与训练方案直接匹配。这种方法具有两个关键优势:
- (1)将视频和动作预测统一到一个训练目标下,实现了对世界动态和动作推理的端到端学习;
- (2)通过并行处理视频片段并结合因果注意力掩蔽,我们可以在一次前向传播中高效地优化所有时间步长的两个组件。
噪声历史数据增强。
推理过程中的主要瓶颈仍然是视频标记的生成——视频标记的数量远大于动作标记,并且每个视频标记都需要通过流匹配过程进行多次去噪。为了解决这个问题,我们引入了一种训练期间的噪声增强策略,从而能够在测试时进行部分去噪。关键在于,动作预测并不需要完全去噪的视频表示;逆动力学模型可以学习从部分噪声的视频状态中提取与动作相关的信息。具体来说,在训练期间,我们按照与流匹配相同的插值方案,随机地用噪声增强视频历史记录 z≤t: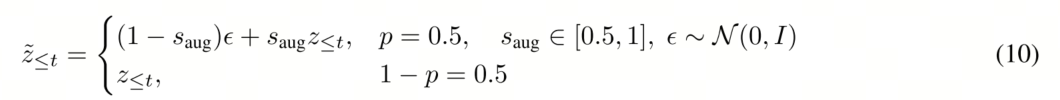
这种增强方法训练动作解码器,使其能够从部分噪声的视频表示中预测动作。
为了大幅提升推理(测试)速度,而对模型训练过程进行针对性优化的关键技术。其核心思想是:通过训练时主动给数据“加难度”(添加噪声),让模型学会从“不完美”的中间结果中做出正确决策,从而在测试时允许使用“未完成”的计算结果,实现加速。
具体可以从三个层面理解:
-
明确的瓶颈:在模型推理时,生成高质量的视频令牌(
zt)成本极高。原因有二:一是视频令牌数量远多于动作令牌;二是每个视频令牌都需要通过“流匹配”这种迭代去噪过程来生成(类似从噪声中一步步“画”出清晰图像),非常耗时。 -
关键的洞察:研究者发现,预测动作并不需要完全清晰、去噪完毕的视频表示。逆动力学模型(IDM)有能力从仍带有部分噪声的视频状态中,提取出与动作决策相关的足够信息。
-
创新的方法:
- 训练时(加噪声):在训练动作解码器(即IDM)时,不再只使用完全清晰的视频历史
z≤t,而是随机地按照流匹配的插值方案,为其添加不同程度的噪声,得到带噪版本z̃≤t。 - 目标:迫使动作解码器学会“抗干扰”,即从
z̃≤t中直接预测出正确的动作at。 - 测试时(减步骤):由于模型在训练中已见惯了各种噪声水平的视频,因此在推理时,无需将视频令牌完全去噪至清晰状态。只需进行部分次数的去噪步骤,得到一个“足够好”的、仍含些许噪声的表示,动作解码器就能基于此做出可靠的动作预测。这直接减少了迭代次数,突破了速度瓶颈。
- 训练时(加噪声):在训练动作解码器(即IDM)时,不再只使用完全清晰的视频历史
简单比喻:这好比训练一位指挥官。
- 传统方式:每次都必须等侦察兵把敌情照片完全修清晰、标注明白后,指挥官再下达命令。
- 本文方法:在平时训练中,就故意给指挥官看各种模糊、有噪点的照片,培养他“雾里看花”也能果断决策的能力。这样在真实战场上,侦察兵只需传回一张快速处理的、略有模糊的照片,指挥官就能立刻下令,从而赢得先机。
这种方法巧妙地将训练的计算负担转移,以换取推理时的极致效率,是模型部署优化中一种非常高级且有效的技术。
在推理时,这可以显著提高速度:我们只需要对 s = 0 到 s = 1 的视频标记进行去噪,而不是完全去噪到 s = 0.5,这样在保持动作预测质量的同时,将视频生成的去噪步骤减少了一半。
训练目标。我们使用上述带噪声历史增强的流匹配方法,联合优化视频和动作。
3.4 Real-time Deployment & Asynchronous Inference
用于高效自回归推理的键值缓存。我们的自回归模型自然地实现了推理过程中的键值缓存加速。由于每个预测步骤都依赖于观测和动作的历史信息,我们缓存了先前词元的键值对,以避免冗余计算。在每个自回归步骤中,只有新词元(当前观测和预测动作)需要完整的注意力计算,而缓存的历史词元则可以重用。算法 1 描述了使用键值缓存的完整推理过程。

异步预测与执行。尽管键值缓存和部分去噪提高了效率,但自回归预测仍然存在不可忽略的延迟,这可能会违反实时控制的要求。为了解决这个问题,我们引入了一种异步推理策略,该策略将动作预测与执行流水线化,有效地隐藏了预测延迟。图 4 展示了同步推理和异步推理之间的区别。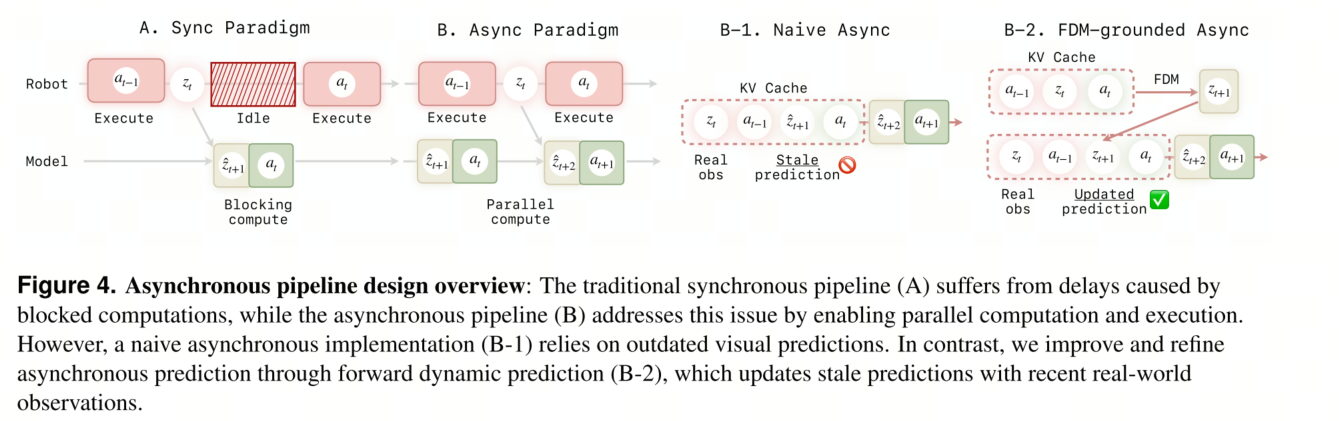
关键在于将计算与执行重叠(图 4B):当机器人执行当前动作块 at 时,模型会同时根据最新的真实观测值 zt−1(在执行 at−1 之后接收到)预测下一个动作块 at+1。为简便起见,本节中我们用 zt 表示潜在观测值(忽略视频 VAE 压缩),而不是 ot。我们丢弃时间戳 t − 1 之前的所有历史数据,并使用尖括号 ˆ 标记预测的视觉内容。因此,模型的活动上下文仅限于已执行的动作块 at−1、最近的真实观测值 zt−1、当前正在执行的动作 at 及其对应的视觉预测 ˆzt。一种简单的自回归实现(图 4B-1)是将这些标记存储到 KV 缓存中并预测 ˆzt+1。然而,我们观察到这种设计经常导致开环性能下降和轨迹漂移。由于视频生成模型本质上倾向于时间平滑性,它倾向于“延续”幻觉视频zˆt,而忽略真实观测zt−1提供的关键物理反馈,最终导致模型失去对环境做出反应的能力。
为了缓解这个问题,我们在推理流程中引入了一个基于前向动力学模型(FDM)的步骤(图 4B2)。我们不再依赖过时的预测,而是执行一次前向动力学过程:模型利用最近的反馈 zt−1,并“想象”在应用动作 at 后产生的视觉状态 zt。通过缓存这个基于反馈的预测,而不是过时的预测,我们强制模型在预测 zt+1 之前重新与环境反馈对齐。这种设计将我们的异步算法增强为一个鲁棒的闭环系统,使机器人能够有效地感知并响应现实世界的变化。
算法 2 将此异步流程形式化。在训练后阶段,我们还加入了前向动态预测损失: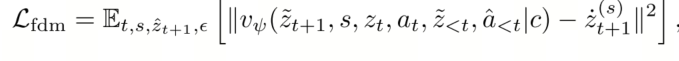

4 Experiments
预训练的 LingBot-VA 与 WAN 的比较。为了验证我们视频动作架构中的设计选择,我们进行了一项受控消融实验,将预训练的 LingBot-VA 模型与 WAN(Wan2.2-5B)模型进行比较,后者作为初始基线模型,用于在 RoboTwin 任务上进行微调。两个模型均使用相同的 RoboTwin 数据集,并采用相同的训练后处理流程(50 个特定任务的演示,学习率为 1 × 10⁻⁵,3000 步)进行微调。
我们从两个维度评估泛化能力:
-
新物体泛化——使用单个物体进行拾取放置训练,并在形状和纹理各异的物体上进行测试;
-
空间泛化——使用局部区域(记为分布内 (ID))内固定物体位置进行训练,并在随机放置(尤其是在分布外 (OOD) 区域)上进行测试。
如图 10 所示,我们的方法在新物体和分布外位置上都展现出更强的泛化能力。世界模型通过视频预测学习可迁移的视觉表征,捕捉与物体无关的物理先验信息,并将其迁移到新的场景。
6 结论
我们提出了 LingBot-VA,一个自回归扩散框架,它统一了用于机器人操作的视频动力学预测和动作推断。通过在 Mixture-of-Transformer 架构中交错视频和动作标记,我们的模型能够捕捉物理交互的因果结构,并通过持续整合真实世界的观测数据实现闭环控制。大量的评估表明,该模型在仿真基准测试(RoboTwin 2.0 上为 92.0%,LIBERO 上为 98.5%)和实际部署中均表现出色,在仅需 50 次演示即可适应的复杂任务中,其性能比 π0.5 提高了 20% 以上。这些结果表明,自回归视频-动作世界建模为学习可泛化的操作策略提供了一个原则性的基础,为反应式 VLA 范式提供了一种极具吸引力的替代方案。
未来工作。未来的研究方向包括开发更高效的视频压缩方案以降低计算开销,以及整合多模态传感器输入(触觉、力觉、音频),以在具有复杂接触动力学的任务中实现更稳健的操作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)