FaceFusion Windows 本地 .venv 部署实战教程
FaceFusion Windows 本地 .venv 部署实战教程
目录
FaceFusion Windows 本地 .venv 部署实战教程
六、强制安装 CUDA 13 线路的 ONNX Runtime
2. install.py 可能覆盖你手动安装的 ONNX Runtime
3. FaceFusion 报 choose an image for the source!
4. 看到 CUDAExecutionProvider 不代表 TensorRT 一定已启用
前言
这篇文章记录一次可复现的 FaceFusion 本地部署过程,特点是:
- 系统:Windows 11
- Python 环境:项目内
.venv - 不使用 Conda 环境管理
- GPU 加速:CUDA + ONNX Runtime + TensorRT
- 适合希望本地长期使用、并且不想依赖 Conda 的场景
本文基于一次实际跑通的环境整理,相关信息如下:
- FaceFusion 版本:
3.6.1 - Python 版本:
3.12.11 - 显卡:
NVIDIA GeForce RTX 3090 - 显卡驱动:
591.86 - ONNX Runtime:
1.25.1 - PyTorch:
2.10.0+cu130 - 系统 CUDA:
13.1 - cuDNN:
9.12.0
一、准备条件
部署前建议先确认以下条件:
- Windows 机器上已经安装 NVIDIA 显卡驱动
nvidia-smi可以正常执行- 已安装 Python
3.12 (推荐 EPGF 架构) - 已安装 Git
可先执行一次:
nvidia-smi
如果这里就报错,先解决显卡驱动问题,再继续后面的步骤。
EPGF 架构的使用提示:
EPGF 架构 环境配置规范(注释 + 代码格式)
# 确认当前 Python 版本 python -V # 切换到指定 Python 版本环境(conda) conda activate py312 # 创建项目本地虚拟环境(--copies 禁用符号链接,用于可能移动/拷贝的项目) python -m venv --copies .venv # 激活本地虚拟环境(Windows PowerShell) .\.venv\Scripts\Activate.ps1 # 退出父级 conda 环境,避免包冲突 conda deactivate # 升级 pip 到最新版,保证依赖安装稳定 python.exe -m pip install --upgrade pip
二、创建项目内 .venv
# 克隆项目
git clone https://github.com/facefusion/facefusion.git进入项目根目录后,创建虚拟环境:
python -m venv --copies .venv
这里使用 --copies,目的是避免虚拟环境大量使用符号链接。对于可能被移动、拷贝或打包迁移的项目,这个参数更稳。
创建完成后激活环境:
.\.venv\Scripts\Activate.ps1
升级 pip:
python.exe -m pip install --upgrade pip
建议顺手确认当前解释器确实来自项目内 .venv:
python -c "import sys; print(sys.executable)"
输出路径应类似:
K:\PythonProjects5\facefusion\.venv\Scripts\python.exe
三、安装 PyTorch CUDA 版本
这一步建议优先单独安装 PyTorch GPU 版,用它来验证显卡、CUDA 和 cuDNN 是否正常。
安装命令:
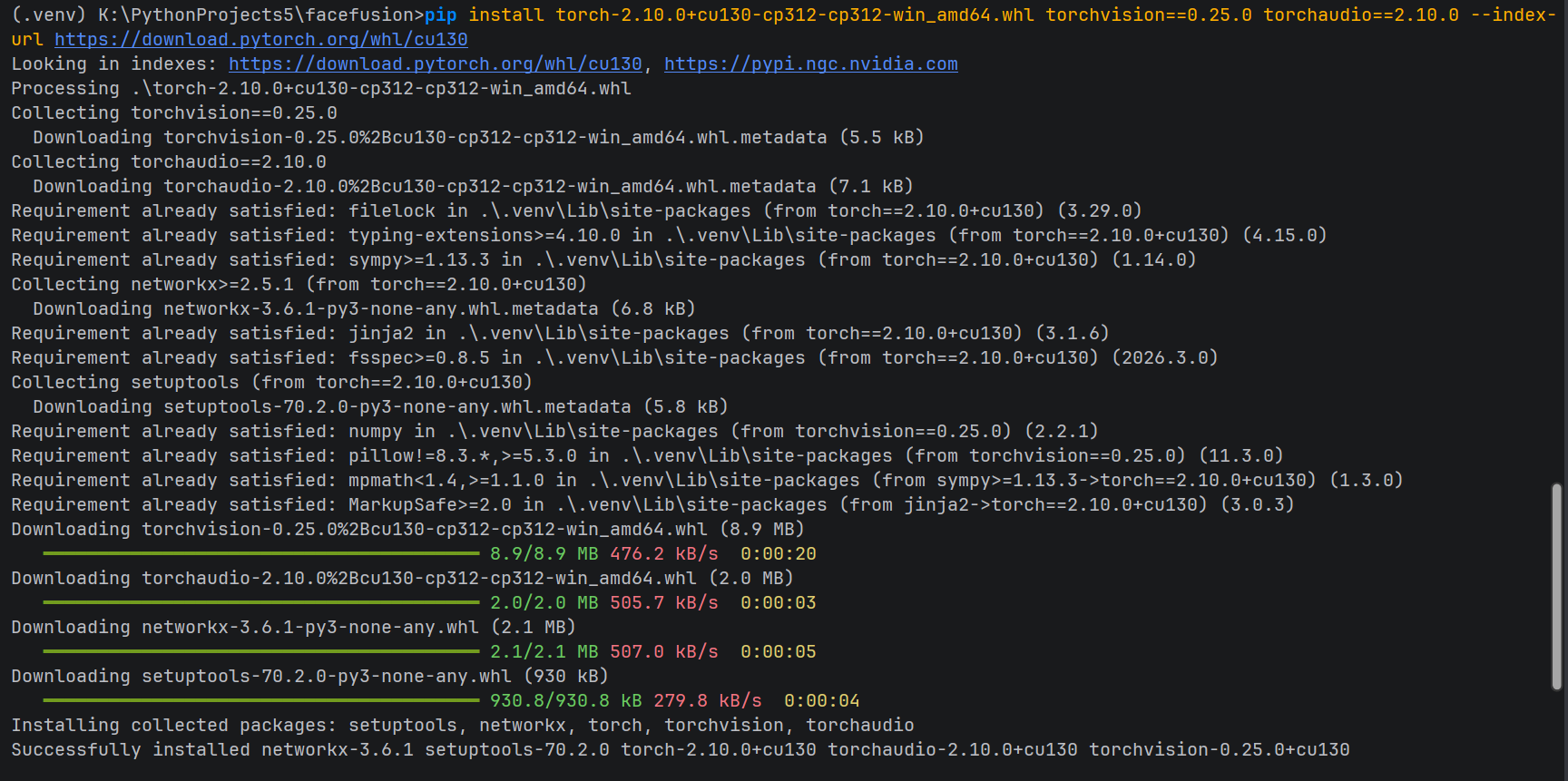
pip install torch==2.10.0 torchvision==0.25.0 torchaudio==2.10.0 --index-url https://download.pytorch.org/whl/cu130
实际验证通过的版本如下:
torch 2.10.0+cu130torchvision 0.25.0torchaudio 2.10.0
四、验证 PyTorch 是否成功启用 GPU
进入 Python:
python
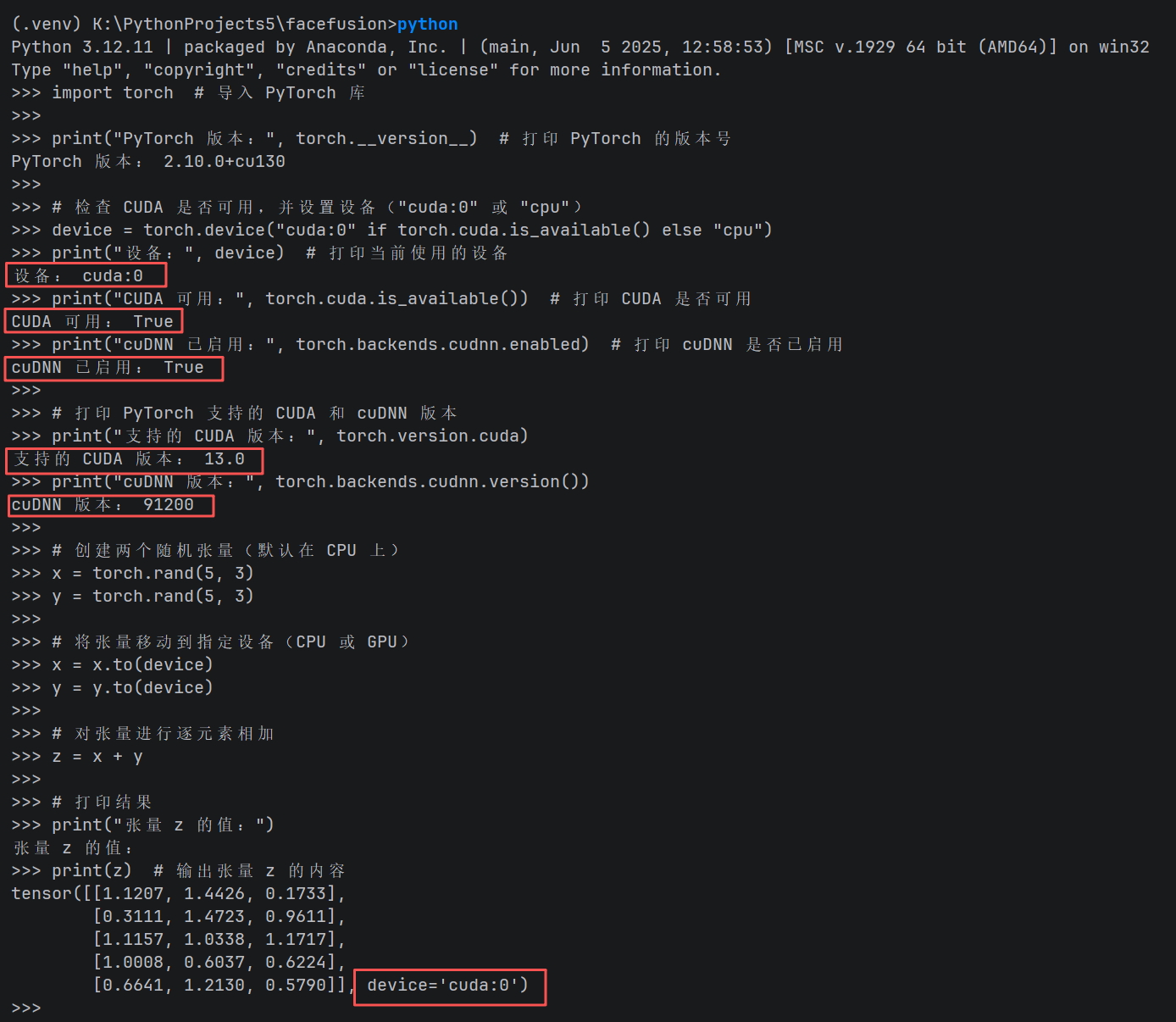
执行下面这段代码:
# 验证
import torch # 导入 PyTorch 库
print("PyTorch 版本:", torch.__version__) # 打印 PyTorch 的版本号
# 检查 CUDA 是否可用,并设置设备("cuda:0" 或 "cpu")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 打印当前使用的设备
print("CUDA 可用:", torch.cuda.is_available()) # 打印 CUDA 是否可用
print("cuDNN 已启用:", torch.backends.cudnn.enabled) # 打印 cuDNN 是否已启用
# 打印 PyTorch 支持的 CUDA 和 cuDNN 版本
print("支持的 CUDA 版本:", torch.version.cuda)
print("cuDNN 版本:", torch.backends.cudnn.version())
# 创建两个随机张量(默认在 CPU 上)
x = torch.rand(5, 3)
y = torch.rand(5, 3)
# 将张量移动到指定设备(CPU 或 GPU)
x = x.to(device)
y = y.to(device)
# 对张量进行逐元素相加
z = x + y
# 打印结果
print("张量 z 的值:")
print(z) # 输出张量 z 的内容
如果输出中满足这些条件,说明 PyTorch GPU 路线已经通了:
设备: cuda:0CUDA 可用: TruecuDNN 已启用: True
五、安装 FaceFusion 基础依赖
FaceFusion 自带了安装脚本。由于本文走的是本地 .venv,不是 Conda,所以使用:
python install.py --onnxruntime cuda --skip-conda
这一步会安装项目的大部分 Python 依赖。
需要注意的是:项目默认安装的 onnxruntime-gpu 版本不一定是最适合当前 CUDA 路线的版本,所以后面还要手动覆盖一次。
六、强制安装 CUDA 13 线路的 ONNX Runtime
如果你的环境和本文一样,是实际跑通了 PyTorch cu130,那么建议把 onnxruntime-gpu 强制切到 CUDA 13 对应源:
pip install --force-reinstall --no-cache-dir onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-13/pypi/simple/
安装完成后验证:
python -c "import onnxruntime as ort; print(ort.__version__); print(ort.get_available_providers())"
本次验证通过的输出是:
1.25.1
['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']

如果你至少看到了:
CUDAExecutionProvider
就说明 ONNX Runtime 已经可以使用 CUDA。
七、安装 TensorRT
为了让 FaceFusion 支持更高优先级的推理后端,可以继续安装 TensorRT:
pip install tensorrt --extra-index-url https://pypi.nvidia.com
安装完成后再验证一次:
python -c "from facefusion.execution import get_available_execution_providers; print(get_available_execution_providers())"

本次环境中的输出为:
['cuda', 'tensorrt', 'cpu']
这说明 FaceFusion 这一层已经能识别:
cudatensorrtcpu
到这里,核心 GPU 加速链路就已经通了。
八、模型共享,减少磁盘占用
基于 EPGF 架构的环境迁移复现部署 及 基于符号链接的模型共享解决方案——FaceFusion 3.3.2与3.4.1 模型共享方案:100GB 空间节省实践
如果你在别的盘里已经有一份 FaceFusion 模型目录,可以通过目录符号链接复用,避免重复下载和占用空间。
例如,把:
F:\PythonProjects1\facefusion\.assets\models
共享给当前项目:
New-Item -ItemType SymbolicLink -Path ".assets\models" -Target "F:\PythonProjects1\facefusion\.assets\models"
如果 .assets 目录还不存在,可以先创建:
New-Item -ItemType Directory -Path ".assets"
验证方式:
Get-Item ".assets\models" | Format-List FullName,LinkType,Target
如果看到 LinkType : SymbolicLink,说明链接创建成功。
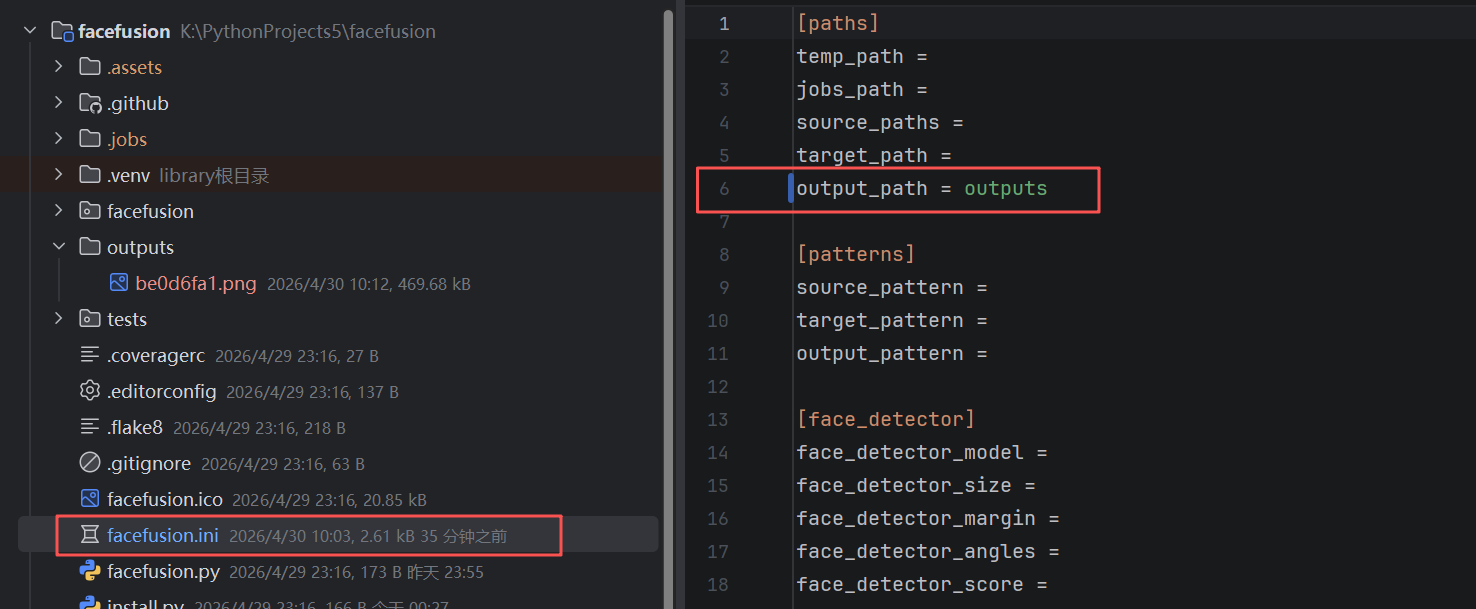
九、配置默认输出目录
建议在项目根目录下创建一个 outputs 文件夹,用于统一保存导出结果。
先创建目录:
New-Item -ItemType Directory -Path "outputs"
然后编辑项目根目录下的 facefusion.ini,把:
[paths]
output_path =
改成:
[paths]
output_path = outputs
这样后续默认输出会落到项目内的 outputs 目录,便于管理。
十、启动 FaceFusion
浏览器模式启动:
python facefusion.py run --open-browser
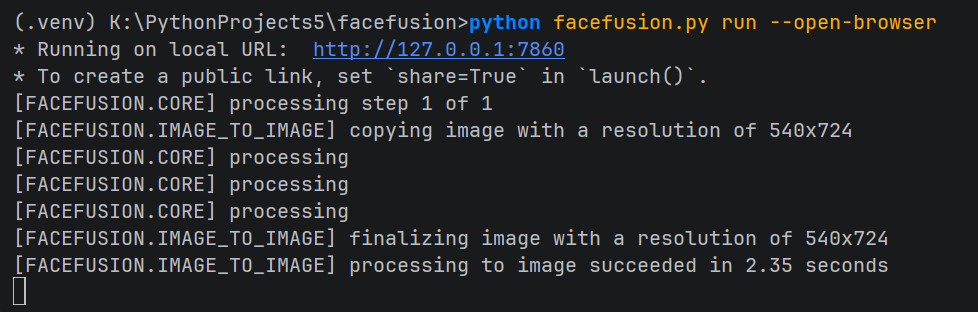
启动后,上传源图和目标图,执行一次实际处理,能得到正常结果就说明部署成功。
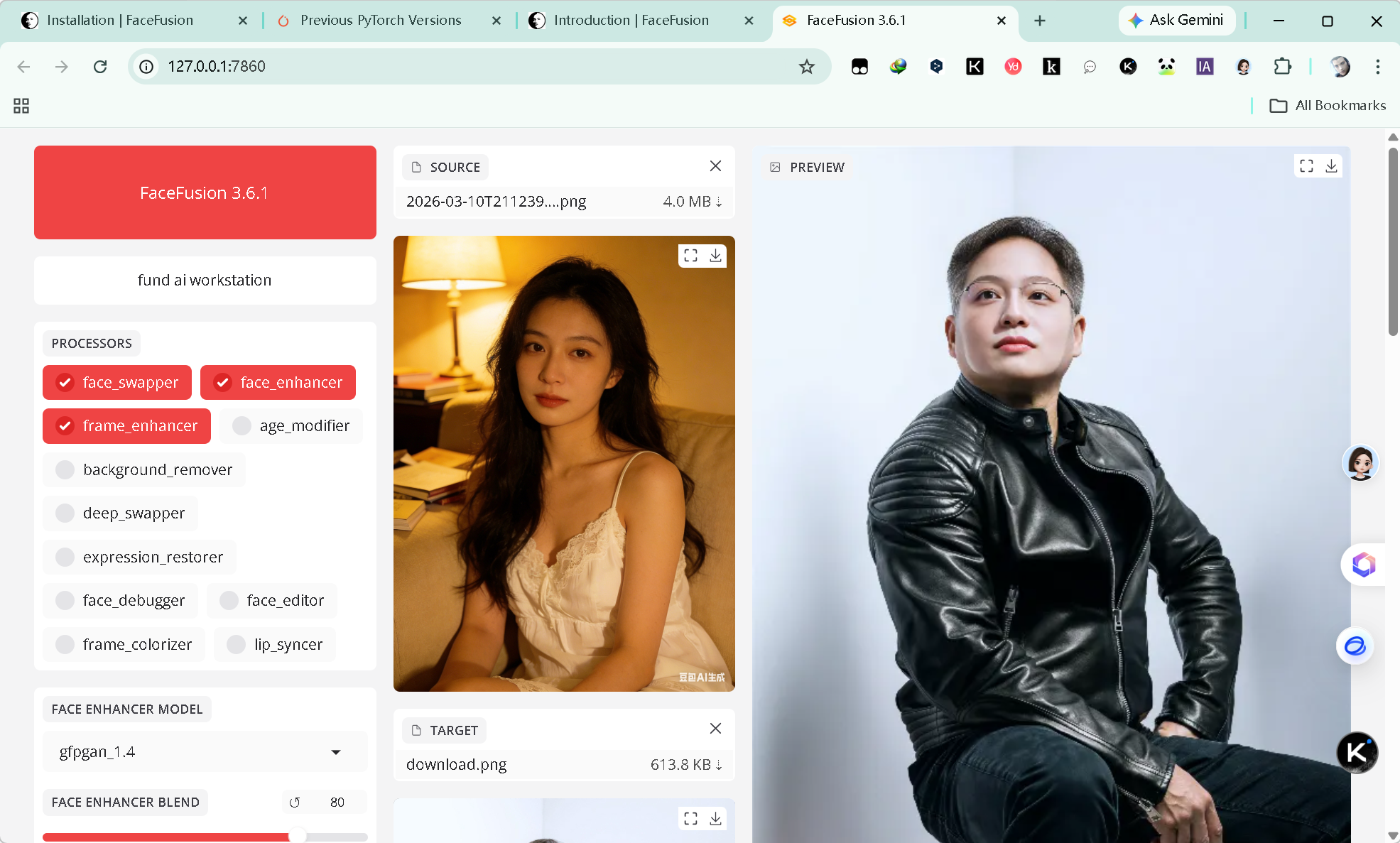
十一、命令行测试示例
如果你想先用命令行验证,而不是直接打开 UI,需要注意 face_swapper 默认必须同时提供源图和目标图。
示例:
python facefusion.py headless-run --execution-providers tensorrt cuda -s source.jpg -t target.jpg -o outputs\result.jpg
说明:
tensorrt放前面,表示优先尝试 TensorRTcuda放后面,表示 TensorRT 不适用时回退到 CUDA
十二、常见坑
1. 没有激活 .venv
如果你没有激活项目内 .venv,可能会误用系统或其他环境里的 Python,导致:
numpy导入失败onnxruntime版本不一致torch和onnxruntime不在同一个环境里
每次操作前建议先确认:
python -c "import sys; print(sys.executable)"
2. install.py 可能覆盖你手动安装的 ONNX Runtime
本文为了适配 CUDA 13,执行过一次:
pip install --force-reinstall --no-cache-dir onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-13/pypi/simple/
如果后面再次运行项目原始安装脚本,有可能把它换回默认版本。遇到这种情况,重新执行上面的强制安装命令即可。
3. FaceFusion 报 choose an image for the source!
这通常不是 CUDA 问题,而是你运行 headless-run 时只传了目标图,没有传源图。
正确示例:
python facefusion.py headless-run --execution-providers cuda -s source.jpg -t target.jpg -o outputs\result.jpg
4. 看到 CUDAExecutionProvider 不代表 TensorRT 一定已启用
要确认 FaceFusion 是否识别到 TensorRT,请执行:
python -c "from facefusion.execution import get_available_execution_providers; print(get_available_execution_providers())"
如果输出中有 tensorrt,才表示 FaceFusion 这一层也看到了 TensorRT。
十三、最终验证清单
部署完成后,至少确认以下几点:
.venv已激活python -c "import torch; print(torch.cuda.is_available())"输出Truepython -c "import onnxruntime as ort; print(ort.get_available_providers())"中有CUDAExecutionProviderpython -c "from facefusion.execution import get_available_execution_providers; print(get_available_execution_providers())"中有cuda- 如需 TensorRT,加上确认输出里有
tensorrt python facefusion.py run --open-browser可以正常打开页面并完成一次处理
结论
如果你的目标是在 Windows 上,以本地 .venv 的方式部署 FaceFusion,而不是依赖 Conda,那么这套流程是可以跑通的:
- 用
python -m venv --copies .venv创建独立环境 - 先验证
PyTorch + CUDA - 再安装 FaceFusion
- 手动切换到可用的
onnxruntime-gpu CUDA 13源 - 补装 TensorRT
- 最后通过 UI 或命令行做一次实测
部署成功后,这套环境已经具备:
- PyTorch GPU 加速
- ONNX Runtime CUDA 加速
- TensorRT 可选加速
- 模型目录跨项目共享
- 项目内统一输出目录
对于需要长期维护、希望项目目录结构清晰、并且不想引入 Conda 的用户,这是一条比较稳的 Windows 本地部署路线。
参考资料
基于 EPGF 架构的环境迁移复现部署 及 基于符号链接的模型共享解决方案——FaceFusion 3.3.2与3.4.1 模型共享方案:100GB 空间节省实践
FaceFusion 3.4.1 版本:[FACEFUSION.CORE] Copying image failed 大分辨率图像处理失败的解决方案与 Bug 探究
基于 EPGF 架构理念的 FaceFusion 3.4.1 本地 .venv 部署教程(非 Conda 环境部署优化版)
怎么使用嵌套虚拟环境实现项目部署之virtualenv嵌套conda绕开安装环境检测实现.venv部署facefusion

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)