【干货】别只看数据表象,运营必懂的归因分析:5 大模型 + 完整计算实战
做运营的人都明白:用户数据就是公司的"体温计"!当你看到曲线一路向下,背后大概率是这几件事在作怪——拉新越来越费劲,甚至开始倒贴;打开 App 的人一天比一天少;好不容易拉来的用户,跑起来比兔子还快。
但我们必须意识到: “数据在掉” 只是表象,真正的挑战在于: 为什么在掉?从哪里开始掉?谁在掉? 这就需要我们进行一场结构化的用户数据归因分析。这篇文章从是什么→怎么办→实战应用→避坑指南,一步步拆解,保证看完能懂、能算、能落地分析。
一、归因分析是什么?
想象你追到了一个心仪的对象,别人问你:"谁帮的忙?"你说:"小红介绍的,小明出的主意,小刚借的车,小李帮忙订的餐厅……最后是我表的白。"
归因分析就是回答:这桩婚事,小红、小明、小刚、小李、你自己,各占多少功劳?
归因分析是指在一件事情发生之后,分析哪些因素导致它的发生,并确定各种因素对最终结果的贡献程度,以便做出相应的优化和改进。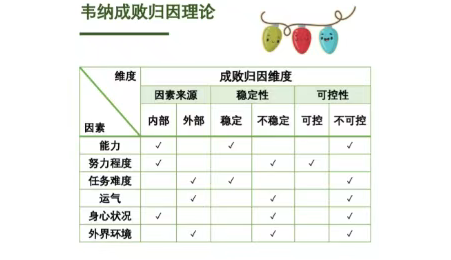
以广告投放为例,我们来具体说下归因分析具体想要解决的是设么问题。
广告投放的效果评估常常让人头疼:
-
到底是哪些营销渠道促成了销售?
-
各个渠道的贡献率又是如何分配的?
-
用户的消费路径是怎样的,背后隐藏着哪些行为模式?
-
该如何利用归因分析的结果,选择那些转化率更高的渠道组合?
归因分析(Attribution Analysis)正是为了解决这些难题而生,它帮助我们合理分配广告效果的“功劳”。不过,真相是,这些问题并没有统一的标准答案,因为业务往往错综复杂,精准分配贡献变得相当困难。
然而,归因分析的需求却十分迫切,时效性要求也很高,因此我们需要一些方法论来快速尝试、快速定位问题。
二、归因分析常见模型
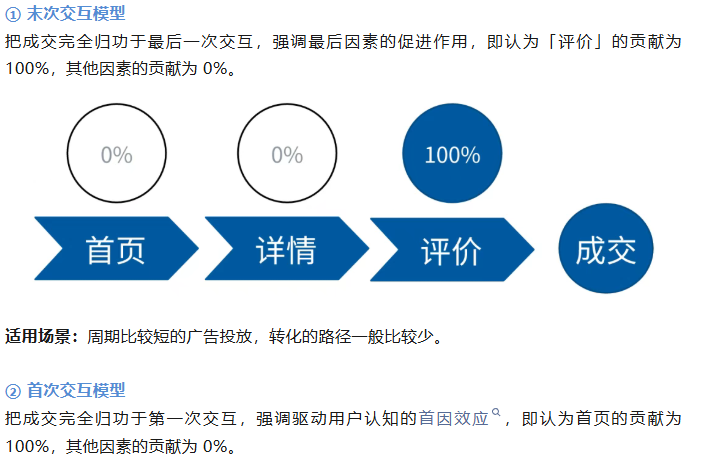
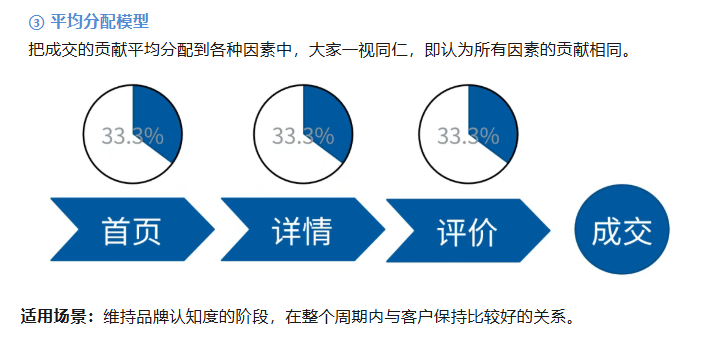
常见的归因分析模型有 5 种:末次交互模型、首次交互模型、平均分配模型、时间衰减模型、自定义模型。

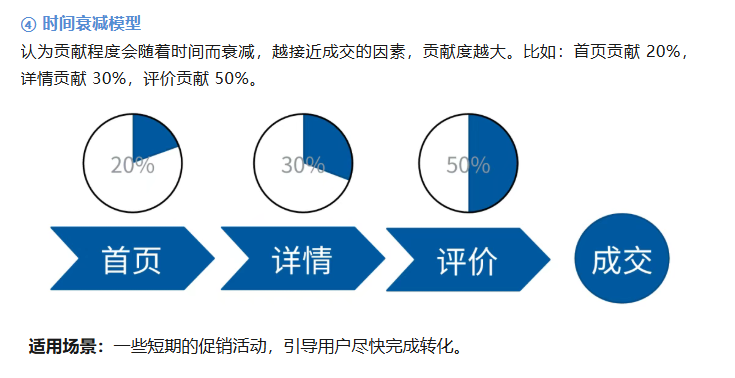
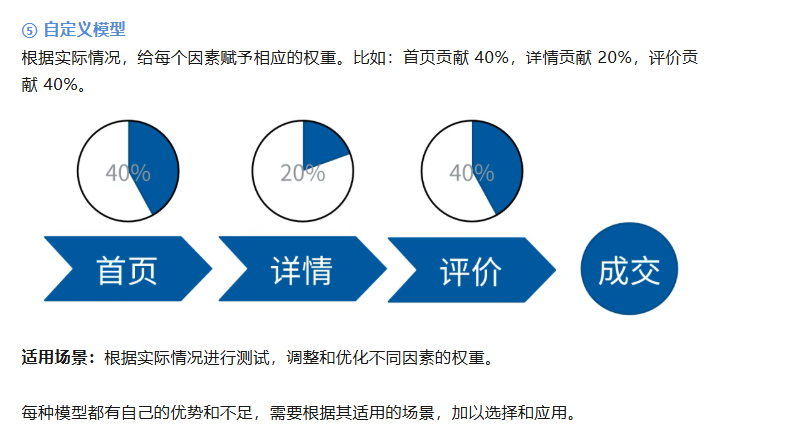
三、归因分析如何计算?
我们以较为简单的“平均分配模型”给大家展示具体的计算方式,只要理解这里的例子,其他的归因方式大同小异:
假设这是某用户在某电商app内的行为,对应数字是商品id,例如支付订单1,就是支付购买了商品1,浏览商详1就是浏览了商品1的商详页),我们想要知道:
Step 2:
在找到两笔订单对应的前向影响因素后,我们根据线性归因“平均分配”的原则对各因素打分:
(1)商品1订单:
(2)商品2订单:
Step 3:
对上述得分进行加和得到:
Step 4:
上述四个因素的得分占比,就是他们对这两笔订单的转化贡献:
总的来说,在这个场景中,点击广告位对于最终两笔订单支付转化的贡献度最大,占比达到50%。
-
促成该用户支付这两笔订单的因素是什么?
-
具体贡献有多少?

Step 1:
假设这边设定可能影响用户支付转化决策的因素有:搜索、点击推荐位、点击广告位、点击banner位。
我们从商品1的这笔订单往前追溯这些决策因素分别是:点击banner位A,点击推荐位A,点击广告B。然后到商品2 的订单,我们这边先定义一个向前追溯的“窗口期”为1天,也就是说从支付商品2的订单往前推1天内的行为才会纳入商品2订单的前向归因因素(图中的黑色竖线就是1天追溯期的界限)。
这样设置的原因是用户行为序列上过早的行为可能是很久之前的,对最终的转化其实没有什么作用。
我们从商品2的这笔订单往前追溯这些决策因素分别是:
-
点击广告位B
-
点击广告位C
-
搜索商品2
-
点击banner位A = 0.33
-
点击推荐位A = 0.33
-
点击广告位B = 0.33
-
点击广告位B = 0.33
-
点击广告位C = 0.33
-
搜索商品2 = 0.33
-
点击推荐位 = 0.33
-
点击广告位 = 0.33 + 0.33 + 0.33 = 1
-
点击banner位 = 0.33
-
搜索商品 = 0.33
-
总计 = 0.33 + 1 + 0.33 + 0.33 = 2
-
点击推荐位 = 0.33 / 2 = 16.67%
-
点击广告位 = 1 / 2 = 50%
-
点击banner位 = 0.33 / 2 = 16.67%
-
搜索商品 = 0.33 / 2 = 16.67%
四、需要注意的避坑事项
不同行业的业务逻辑不同,分析和优化周转率的重点也不同。归因分析重点需要注意以下问题:
(一)数据质量
归因分析依赖于高质量的数据,数据缺失或错误会导致不准确的结论。在进行归因分析时,需检查数据是否存在缺失、错误、异常值等问题,必要时进行数据清洗和预处理,以保证分析结果的可靠性。
(二)多重归因问题
一个结果可能受到多个因素的影响,识别这些因素的独立贡献度可能较为复杂。在进行归因分析时,要避免归因错误,不能以偏概全。
基本归因错误:避免将他人行为或结果过度归因于个人特质(如性格、能力),而忽视环境因素的影响。
(三)外部因素
外部环境(如市场变化、政策调整、竞争对手行为等)可能对结果产生影响,需在分析中纳入这些外部因素,避免忽略其作用。
(四)模型选择
选择合适的归因模型至关重要,不同模型可能会得出截然不同的结论。不同归因模型适用于不同场景(如线性归因、时间衰减归因、首次/末次归因等)。
需根据分析目标、数据特点和业务需求,选择最合适的模型,并理解模型的假设和局限性。
要想做好归因分析,只会套公式或者围着数字转远远不够!CDA 数据分析师认证,深耕电商、零售、制造业经营分析,教你拆解库存指标、定位滞销问题、制定优化方案。从理论到实战,练就专业数据分析能力,汇报有逻辑、决策有依据,职场晋升一路绿灯,在CDA认证小程序,开始学习。
-
自我服务偏差:在分析自身或团队结果时,避免将成功归因于自身努力,而将失败归因于外部因素。
-
确认偏误:避免只寻找支持自己假设的证据,而忽略相反的证据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)