国产芯片优化1:如何构建三位一体软件栈,突破既定硬件的性能瓶颈?
当 DeepSeek-R1 & V3 在国产芯片上首次跑通,还实现了 SOTA 级性能表现,那一刻,我们知道游戏规则变了。
近年来,我们看到国产芯片厂商集体崛起,摩尔线程与沐曦相继上市,DeepSeek、Qwen、Kimi 等主流大模型适配国产芯片持续成为热点话题。然而,从理性视角来看,国产芯片在制造工艺和系统生态建设上,与国际先进水平相比仍存在一定差距。由 Air Street Capital 发布的 State of AI Report(《2025 年人工智能现状报告》)指出,NVIDIA 在芯片市场占据绝对“主导地位”,“市值突破 4 万亿美元,占据 90% AI 研究论文的芯片提及率”。对比 NVIDIA,国产 GPU 芯片存在一定物理限制,软件生态尚不完善,可用性和兼容性尚有不足。
对于拥有国产芯片的企业来说,在 AI 落地时常常感到力不从心:硬件性能似乎已经到了天花板,如何才能获得更强的算力支持?
这也是硅基流动一直在探索的命题,“解锁国产算力,释放全速 AI”。从推出服务的第一天起,硅基流动大模型服务平台的大部分算力就运行在国产芯片上,已完成对多款国产芯片的深度适配与优化,比如:
- 在华为昇腾 910B 及最新的超节点平台上实现了 SOTA 级性能表现,率先推出基于昇腾算力的 DeepSeek-R1 & V3 服务,实现了持平全球高端 GPU 部署模型的效果;
- 与沐曦合作,全球首发基于沐曦曦云 C550 集群的月之暗面 Kimi-K2 大模型商业化服务部署;
- 与摩尔线程合作,在 MTT S5000 上利用 FP8 低精度推理技术完成对 DeepSeek-V3 671B 满血版的深度适配与性能测试,单卡 Prefill 吞吐达到 4000 tokens/s 以上,Decode 吞吐超过 1000 tokens/s,树立国产推理性能新标杆。
以上突破性进展,验证了国产芯片完全有能力支撑主流大模型的高强度推理任务,硅基流动成为国内少数大规模使用国产算力卡(如华为昇腾、沐曦、摩尔线程等)对外提供稳定服务的公司。
接下来,我们将通过一系列文章,为你分享在芯片适配层、引擎层以及推理层,硅基流动在国产芯片适配与优化上的一些实践与心得。今天就和你分享我们如何在芯片适配层构建“算力、通信、生态”三位一体的软件护城河,为企业在多芯时代提供确定性的高性能 AI 推理能力。
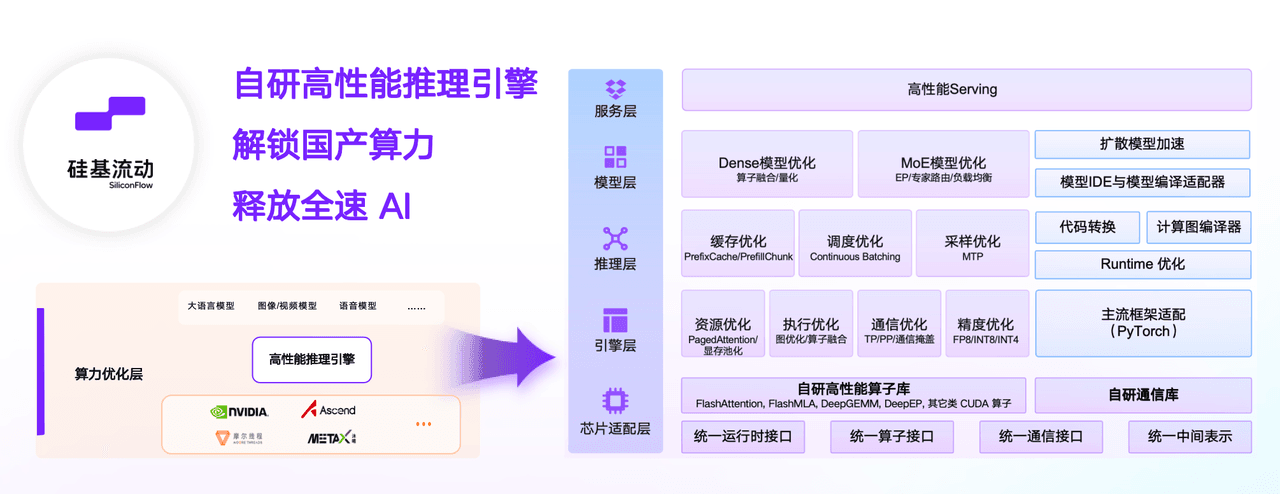
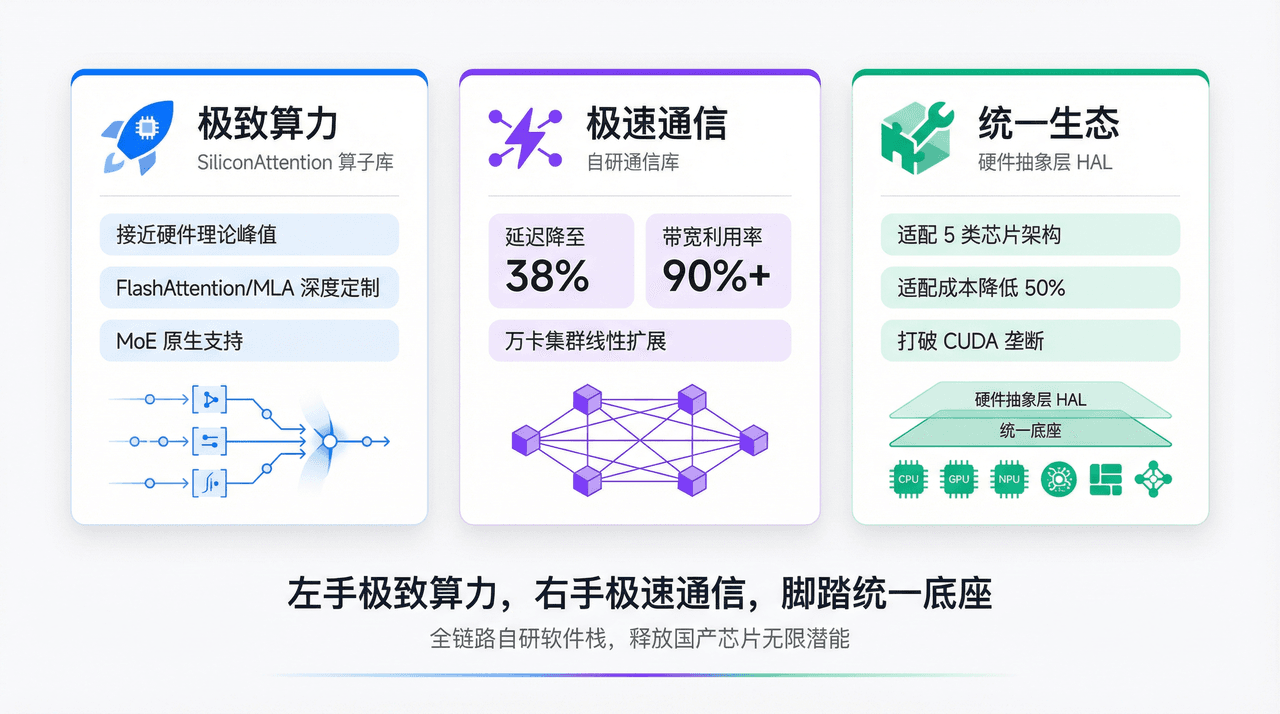
极致算力:自研高性能算子库 SiliconAttention
大模型的计算效率,决胜在毫秒之间。通用的开源算子库往往只能发挥硬件 60% 的性能,为了突破这一瓶颈,榨干硬件性能剩下的 40%,我们自研了 SiliconAttention 算子体系,显著降低了复杂算子的调度开销,实现无限接近硬件理论峰值的计算效率。
我们是如何做到的?
将 FlashAttention、MLA(Multi-Latent Attention)等复杂计算逻辑,与底层硬件指令深度融合,并基于硬件物理特性重构了矩阵运算(GEMM),大幅减少了数据在 HBM(High Bandwidth Memory)高带宽内存与计算单元之间的搬运,突破了长文本推理的带宽瓶颈。特别是在大热的 MoE(Mixture-of-Experts)混合专家模型场景下,我们重构了动态专家路由算法,有效消除了大量条件分支带来的性能开销。
核心技术突破
- SiliconAttention:深度定制 FlashAttention/MLA 内核,基于硬件指令集重构显存访问模式,显著减少数据搬运。
- MoE 算子:原生支持 MoE 专家路由机制,解决 DeepSeek 等模型中专家调度带来的计算碎片化问题,大幅降低推理延迟。
- 通用计算优化:基于硬件物理特性重构矩阵运算(GEMM),填补国产算子库在 Grouped GEMM 等新算子上的空白。
极速通信:自研超低延迟通信库
在分布式训练和推理中,最大的瓶颈往往是网络通信。我们没有满足于调用现成的通信库,比如 NVIDIA 的 NCCL 或 华为的 HCCL,而是深入到了 PTX 指令级(针对 NVIDIA)和汇编级(针对国产卡)进行微操优化。同时,通过引入 Hybrid-Topology(混合拓扑)算法,让系统能像智能导航一样,自动感知网络拥堵并选择最优路径。
基于以上这些技术,**我们打造了最硬核的技术突破——自研分布式通信库。**实现了:
- 端到端通信延迟降低至行业平均值的 38%
- 带宽利用率拉升至 90% 以上
- 支持万卡集群的线性扩展能力
核心技术突破
- 汇编级代码重写:实现指令级并行与内存访问优化,从最底层压榨性能。
- 多级流水线通信协议:消除计算“气泡”,减少显卡“干等数据”的时间,提升整体吞吐量。
- 动态网络拓扑感知:智能选择最优路由,避免“舍近求远”,最大化利用硬件带宽,显著降低通信延迟。
- 混合拓扑算法:自动感知网络拥堵,确保在网络抖动的情况下,模型推理依然丝般顺滑。
统一生态:通用硬件抽象层(HAL)
面对市面上五花八门的芯片架构,如何实现快速适配与平滑迁移?我们的答案是统一硬件抽象层(HAL,Hardware Abstraction Layer)。
我们设计了一套通用的中间表示(IR,Intermediate Representation),它就像 AI 界的“世界语”。无论底层是英伟达、AMD,还是国产芯片比如华为昇腾、海光、沐曦、摩尔线程等,我们的引擎只需通过这套“世界语”,说这一种语言,就能指挥所有芯片协同工作。
这一设计的商业价值是巨大的,为客户构建多元异构算力池提供了最坚实的保障:
- 已成功适配 5 类主流芯片架构
- 新硬件的迭代适配成本直接降低 50%
核心技术突破
- 架构分层抽象设计:建立标准设备运行时 → 内核适配器 → 硬件驱动调用栈,通过标准化的调用栈,屏蔽异构芯片的底层差异。
- 引入通用中间表示(IR):模型代码先翻译成 IR,再由 IR 自动翻译成各种芯片的指令集,打破 CUDA 的独家垄断。
- 标准化芯片接入接口:大幅缩短新硬件的适配周期。
总结:用软件定义算力,释放无限潜能
总结一下我们的破壁三策:左手极致算力,右手极速通信,脚踏统一底座。
这套全链路自研的软件栈,是我们在硬件充满不确定性的时代,为客户提供确定性、高性能推理的底气。我们的目标是极致释放每一款国产硬件的算力,打破碎片化困局,最终让国产异构芯片像英伟达一样好用,助力中国企业在 AI 时代乘风破浪。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)