大数据实战!基于消费行为特征工程的贫困生精准识别与分层资助体系模型实践
目录
1. 项目背景
在传统的校园资助工作中,我们通常面临两大痛点:一是"边缘学生漏检"——有些学生虽然总体消费金额不低,但为了省钱常年不吃早餐,这种隐性贫困容易被忽视;二是"资助手段单一"——通常是统一发放固定金额,难以满足不同学生的具体困难。
传统方法依赖学生主动申报或班主任经验判断,存在遗漏或主观偏差。本项目的核心逻辑在于非入侵式识别:利用Python对校园卡后台流水进行高维度的行为建模,从"金额导向"迈入"行为建模"。我们通过分析消费结构与稳定性,最大程度保护学生隐私与自尊,精准区分"主动节俭"与"被动拮据"。
2. 任务目标与技术栈
-
任务目标:
-
基于消费数据,构建多维度贫困识别模型,精准锁定困难学生;
-
对困难群体进行生活画像分析,发现其具体的省钱模式;
-
提供个性化的分层补贴建议,实现精准滴灌。
-
-
技术栈与环境:
-
语言:Python(Pandas、NumPy、Matplotlib、Seaborn、Scikit-learn)
-
算法:Min-Max标准化、孤立森林(Isolation Forest)
-
开发环境:Jupyter Notebook / VS Code
-
-
数据来源:
-
7_consumption.csv:本学年消费记录,共463,904条(含消费时间、金额、学生ID) -
2_student_info.csv:学生基本信息,共1,765条(含性别、籍贯、班级等)
-
3. 整体分析流程
本项目采用"漏斗式"分析流程,如下图所示:
数据加载与清洗 → 特征工程(11项指标) → 第一层:金额初筛(15%分位线)
→ 第二层:困难指数精选(5指标等权加权) → 孤立森林交叉验证
→ 困难群体画像分析 → 三层资助体系设计 → 结果导出
核心步骤说明:
-
特征工程:从46万条消费记录中,按学生聚合出日均消费、三餐规律、经济稳定性、校园依赖度四大维度的11项特征;
-
双层筛选:第一层用15%分位线进行金额初筛(260人入池),第二层用生活困难指数精选核心群体(130人锁定);
-
交叉验证:用孤立森林对全体学生进行异常检测,验证分层识别的稳健性;
-
画像分析:深度剖析困难学生的省钱部位、营养规律、经济稳定性、校园依赖度;
-
方案设计:基于画像结果,设计基础补贴+早餐专项+月末应急的三层托底体系。
4. 特征工程
识别逻辑的优劣取决于特征设计的精细度。我们不仅关注消费总量,更关注消费的结构与稳定性。从消费明细中按学生聚合,提取了以下11项特征:
| 特征 | 含义 | 与贫困的关系 |
|---|---|---|
| avg_daily_cost | 日均消费金额 | 越低越可能贫困 |
| breakfast_rate | 早餐就餐频率 | 越低越节省 |
| miss_breakfast_rate | 缺早餐率(=1-早餐频率) | 越高越节省 |
| lunch_avg | 午餐平均消费 | 越低越拮据 |
| dinner_avg | 晚餐平均消费 | 越低越拮据 |
| cost_std | 消费标准差 | 反映波动性 |
| cv_cost | 消费变异系数(=标准差/均值) | 越高越不稳定 |
| weekend_ratio | 周末消费占比 | 反映校园依赖度 |
| month_end_ratio | 月底消费占比 | 异常可能反映资金紧张 |
| max_low_days | 最长连续低消费天数 | 越高反映持续性经济压力 |
| total_days | 有消费记录的总天数 | 反映在校时长 |
4.1 消费数据处理
这里有一个关键的技术细节:如果不先按学生+日期汇总每日总消费,直接对所有消费记录取平均,会导致"一天刷多次卡的学生"日均消费被高估。因此我们做了如下处理:
# 第一步:按学生+日期计算每日总消费
daily_cost = df_consumption.groupby(['bf_StudentID', 'date'])['cost'].sum().reset_index(name='daily_cost')
# 第二步:基于每日总消费计算日均值和标准差
student_cost = daily_cost.groupby('bf_StudentID').agg(
total_cost=('daily_cost', 'sum'),
total_days=('date', 'nunique'),
avg_daily_cost=('daily_cost', 'mean'),
cost_std=('daily_cost', 'std'),
).reset_index()4.2 时段特征与就餐规律
通过提取三餐就餐率和各时段平均消费,我们发现困难群体存在严重的"早餐缺失"现象:
extra_features = df_consumption.groupby('bf_StudentID').agg(
breakfast_rate=('hour', lambda x: ((x>=6) & (x<8)).sum() / len(x)),
lunch_avg=('cost', lambda x: x[(df_consumption.loc[x.index, 'hour']>=11) &
(df_consumption.loc[x.index, 'hour']<13)].mean()),
dinner_avg=('cost', lambda x: x[(df_consumption.loc[x.index, 'hour']>=17) &
(df_consumption.loc[x.index, 'hour']<19)].mean()),
weekend_ratio=('weekday', lambda x: (x>=5).sum() / len(x)),
month_end_ratio=('is_month_end', 'mean')
).reset_index()
# 衍生特征
student_cost['miss_breakfast_rate'] = 1 - student_cost['breakfast_rate']
student_cost['cv_cost'] = student_cost['cost_std'] / (student_cost['avg_daily_cost'] + 0.01)4.3 经济稳定性特征
引入最长连续低消费天数这一关键指标,捕捉持续性的生存压力:
def max_consecutive_low(grp):
grp = grp.sort_values('date')
low = (grp['daily_cost'] < poverty_line_simple).astype(int)
max_len, cur = 0, 0
for v in low:
if v == 1:
cur += 1
max_len = max(max_len, cur)
else:
cur = 0
return max_len
stu_max_low = daily_cost.groupby('bf_StudentID').apply(max_consecutive_low).reset_index(name='max_low_days')5. 核心方案:双层筛选模型与算法优势
为了确保资助的公平性与覆盖度,我们采用双层筛选模型——这比传统的单指标一刀切或单一算法检测更加精准。
第一层:放宽金额初筛
采用全校日均消费的15%分位线(约16.30元/天)作为入池门槛,而非传统的10%。这一设计极具人文关怀,有效降低了"早饭省下、午饭正常"这类边缘学生的漏检率。最终筛出260人进入待选池。
第二层:生活困难指数精选
在低消费池内,选取日均消费、晚餐均价、消费变异系数、月底消费占比、最长连续低消费天数五项指标。经Min-Max标准化后等权加权,构建"生活困难指数",取中位数以上者为核心困难学生,最终锁定130人(占全校7.5%)。
# %% 分层识别:先金额筛选,再生活困难指数排序
# 第一层:消费金额筛选(使用15%分位线,比10%稍宽,避免漏掉边缘学生)
money_line = student_cost['avg_daily_cost'].quantile(0.15)
print(f"第一层筛选线(15%分位):{money_line:.2f} 元/天")
low_consumption = student_cost[student_cost['avg_daily_cost'] < money_line].copy()
print(f"第一层筛选出消费较低学生:{len(low_consumption)} 人")
# 第二层:在低消费群体中构建生活困难指数
# 选取更能反映“拮据程度”的指标(去掉缺失率,因为在这个群体内不缺分度)
features_v2 = ['avg_daily_cost', 'dinner_avg', 'cv_cost', 'month_end_ratio', 'max_low_days']
X_v2 = low_consumption[features_v2].copy()
scaler_v2 = MinMaxScaler()
X_scaled_v2 = pd.DataFrame(scaler_v2.fit_transform(X_v2), columns=features_v2, index=X_v2.index)
# 方向处理:avg_daily_cost, dinner_avg 越低越困难
for col in ['avg_daily_cost', 'dinner_avg']:
X_scaled_v2[col] = 1 - X_scaled_v2[col]
# 等权
low_consumption['hardship_score'] = X_scaled_v2.mean(axis=1)
# 取前50%作为“核心困难群体”(可根据学校预算调整)
threshold = low_consumption['hardship_score'].median()
low_consumption['is_hardship'] = (low_consumption['hardship_score'] >= threshold).astype(int)
hardship_students = low_consumption[low_consumption['is_hardship'] == 1].copy()
hardship_ids = hardship_students['bf_StudentID'].tolist()
# 给全体 student_cost 打标签
student_cost['is_hardship'] = student_cost['bf_StudentID'].isin(hardship_ids).astype(int)
student_cost['hardship_score'] = 0
student_cost.loc[student_cost['bf_StudentID'].isin(low_consumption['bf_StudentID']), 'hardship_score'] = low_consumption['hardship_score']
print(f"第二层筛选出核心困难学生:{len(hardship_students)} 人")
print(f"占总人数比例:{len(hardship_students)/len(student_cost):.1%}")
双层筛选可视化
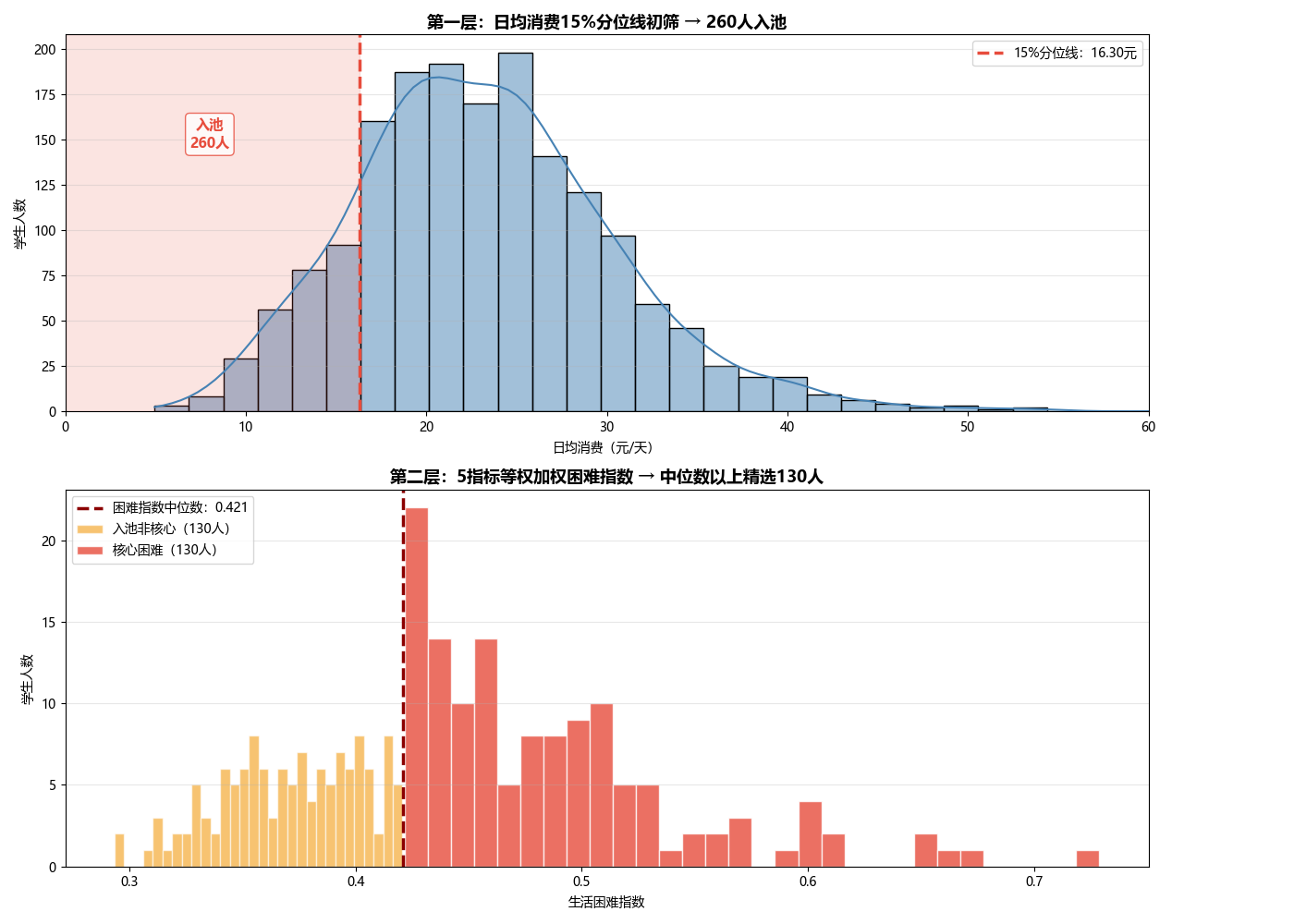
解读要点:
-
上层:15%分位线(红线左侧)划出低消费池260人——这一步是"粗筛",不漏掉边缘学生;
-
下层:生活困难指数中位数(红线右侧130人)锁定核心困难群体——这一步是"精选",多维度确认贫困程度。
5.1 全貌对比:单一指标 vs 多维画像
在做分层识别之前,我们先看看全校的消费分布,以及"仅用单一金额指标"会有怎样的局限:
# %% 全体学生消费分布概览(简单贫困线对比)
plt.figure(figsize=(10,5))
sns.histplot(student_cost['avg_daily_cost'], bins=50, kde=True, color='skyblue') # bins从50加到80,柱子更细
plt.axvline(poverty_line_simple, color='red', linestyle='--', linewidth=2,
label=f'10%分位线 {poverty_line_simple:.2f} 元')
plt.title('全体学生日均消费分布')
plt.xlabel('日均消费 (元)')
plt.xlim(0, 70)
plt.xticks(range(0, 71, 5))
plt.legend()
plt.show()
# 简单金额线人数
simple_poor_count = (student_cost['avg_daily_cost'] < poverty_line_simple).sum()
print(f"若只用日均消费<10%分位线,贫困生人数:{simple_poor_count}")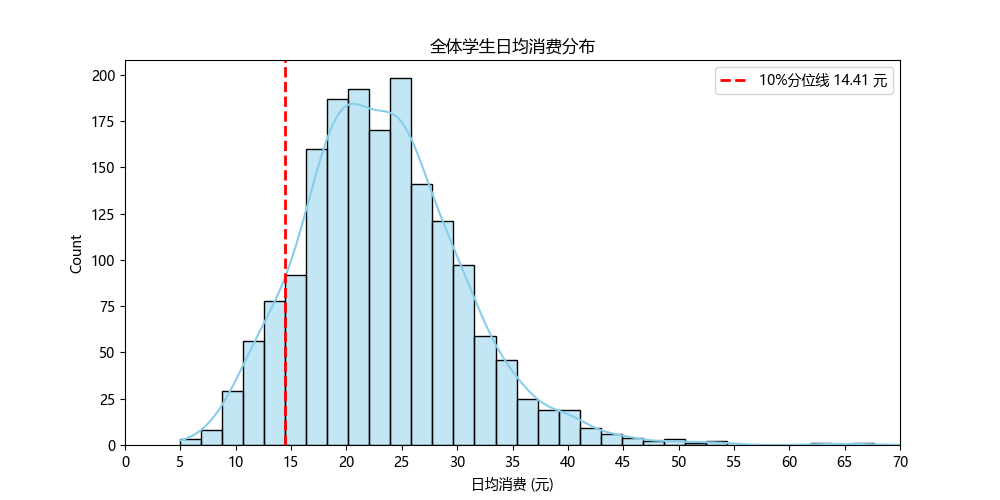
解读要点:
-
全校日均消费呈近似正态分布,均值约23元;
-
若仅以10%分位线(14.58元)一刀切,可识别173人——但单一金额指标无法反映消费稳定性、营养规律等生活质量维度。
5.2 多维度特征对比
下图将"10%分位线以下学生"和"其他学生"在四个核心维度上进行对比:
打简单标签
student_cost['simple_poor'] = (student_cost['avg_daily_cost'] < poverty_line_10).astype(int)
compare_features = ['avg_daily_cost', 'miss_breakfast_rate', 'cv_cost', 'max_low_days']
compare_labels = ['日均消费(元)', '缺早餐率', '消费变异系数', '最长连续低消天数']
compare_colors = ['#3498db', '#e74c3c']
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
for ax, feat, label in zip(axes.flatten(), compare_features, compare_labels):
data_poor = student_cost[student_cost['simple_poor'] == 1][feat]
data_other = student_cost[student_cost['simple_poor'] == 0][feat]
# 用中位数+四分位距做简化箱线
stats = [
[data_other.median(), data_other.quantile(0.25), data_other.quantile(0.75)],
[data_poor.median(), data_poor.quantile(0.25), data_poor.quantile(0.75)]
]
x = [0, 1]
for i, (med, q1, q3) in enumerate(stats):
ax.bar(i, med, 0.5, color=compare_colors[i], alpha=0.8, zorder=3)
ax.plot([i, i], [q1, q3], 'k-', linewidth=2, zorder=4)
ax.plot([i - 0.1, i + 0.1], [q1, q1], 'k-', linewidth=1.5)
ax.plot([i - 0.1, i + 0.1], [q3, q3], 'k-', linewidth=1.5)
ax.set_xticks([0, 1])
ax.set_xticklabels(['其他学生', '10%线以下'])
ax.set_title(label, fontsize=12, fontweight='bold')
ax.grid(axis='y', alpha=0.3)
plt.suptitle('单一金额线 vs 多维度特征:同一群学生的不同面貌', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()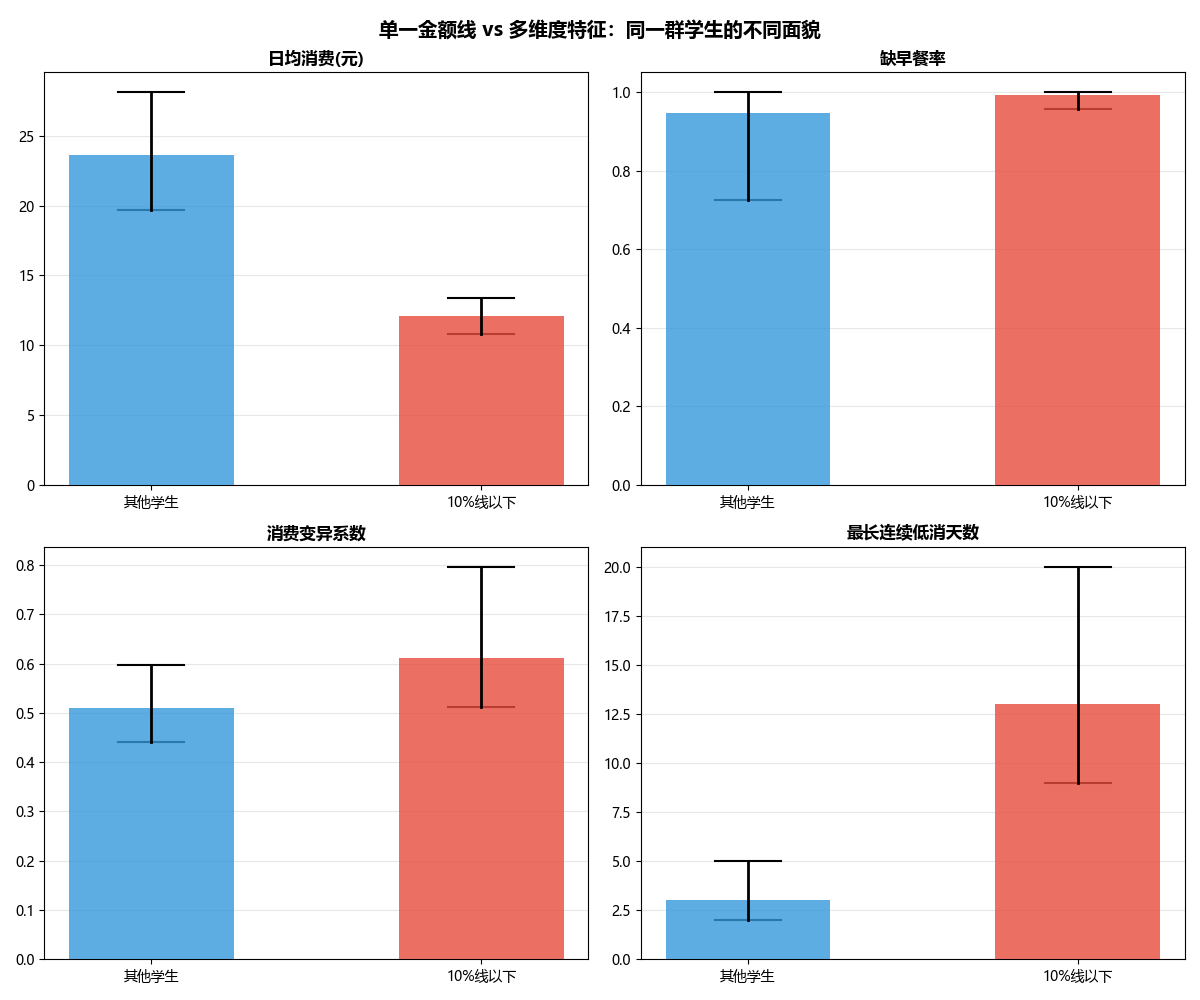
解读要点:
-
日均消费:两组差距显著(定义使然),但这只是冰山一角;
-
缺早餐率:低消费组显著更高,说明"不吃早餐"是省钱的核心手段;
-
消费变异系数:低消费组波动更大,暗示经济来源不稳定;
-
最长连续低消天数:低消费组远超其他学生,存在持续性拮据。
5.3 模型验证:孤立森林交叉验证
我们将分层识别名单与孤立森林(污染率5%)的异常检测结果进行交叉比对,重叠率高达43.08%(远超随机概率5%)。这表明:分层法聚焦"经济拮据",孤立森林捕获"模式异常",两者互为补充,大幅提升了识别的可信度。
iso = IsolationForest(contamination=0.05, random_state=42)
features_iso = ['avg_daily_cost', 'dinner_avg', 'cv_cost', 'weekend_ratio', 'max_low_days']
X_iso_scaled = pd.DataFrame(MinMaxScaler().fit_transform(X_iso), columns=features_iso)
student_cost['iso_anomaly'] = iso.fit_predict(X_iso_scaled)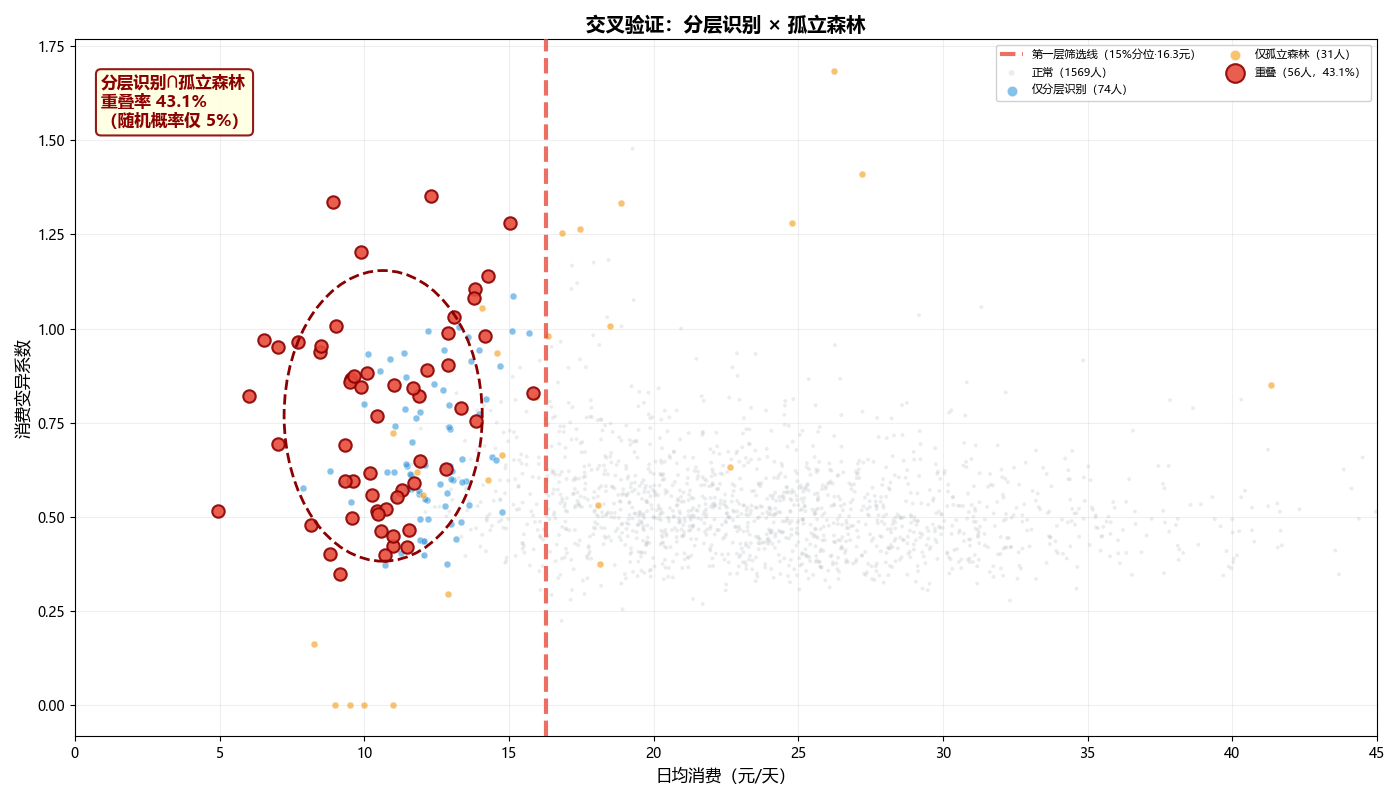
解读要点——四类学生着色:
-
红色重叠区(核心确认):分层识别+孤立森林双重认定的困难学生,位于左上方(低消费+高波动),置信度最高;
-
蓝色仅分层识别:日均消费低但消费模式不够"异常",可能是习惯性节俭;
-
橙色仅孤立森林:消费金额不低但模式异常,可能是消费习惯特殊;
-
15%分位线(红色虚线):第一层筛选门槛,左侧全部进入待选池。
6. 困难学生深度画像与可视化解读
6.1 三餐省在哪里?——省钱部位定位
我们对困难学生和其他学生在各时段的消费进行对比,发现三餐全方位节省,但午餐和晚餐是省钱的主要来源:
def time_slot(h):
if 6<=h<8: return '早餐'
elif 11<=h<13: return '午餐'
elif 17<=h<19: return '晚餐'
else: return '其他'
slot_compare = pd.DataFrame({
'困难学生': poor_consume.groupby('slot')['cost'].mean(),
'其他学生': non_poor_consume.groupby('slot')['cost'].mean()
}).drop('其他', errors='ignore')为进一步拆解"省钱"行为,我们同时对就餐率和单次消费金额进行了对比:
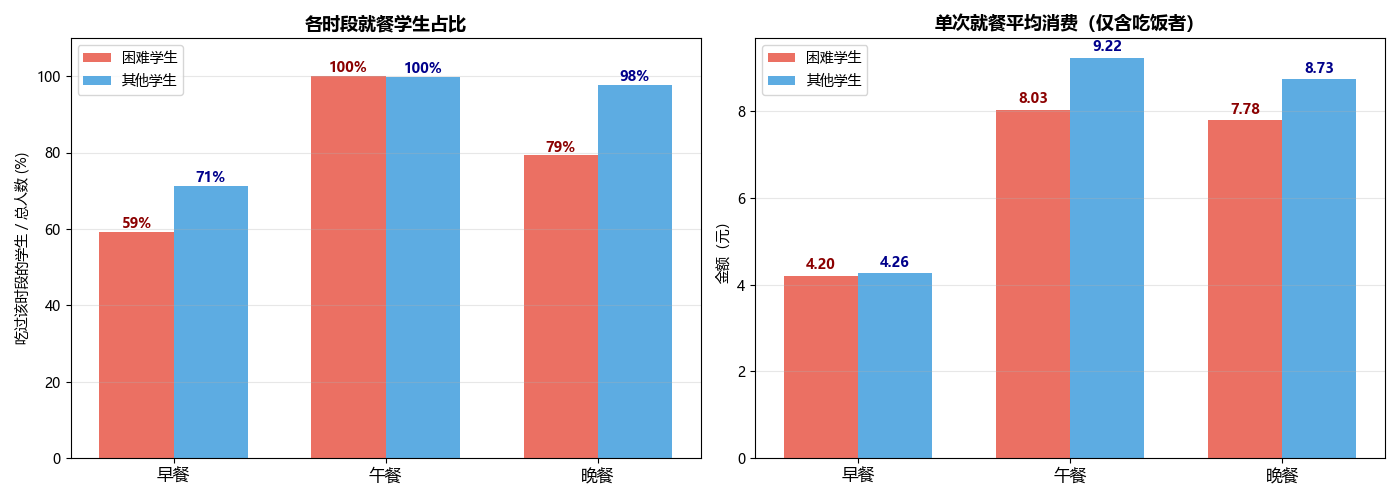
解读要点:
-
左图(就餐率):困难学生早餐就餐率明显低于其他学生,说明他们倾向"省掉早餐"——这是一种主动压抑消费的行为;
-
右图(单次消费金额):即便是就同一餐次而言,困难学生的人均消费也全面偏低,印证了"每一餐都在省钱";
-
综合来看,午餐和晚餐的人均消费差异最大(合计少花约2.14元/天),是省钱的主要部位。
6.2 营养规律性:缺早餐率分析
困难学生中几乎不吃早餐(缺早餐率>80%)的比例高达95.4%,显著高于其他学生的65.3%。"不吃早餐"虽然在该校是普遍现象,但在困难学生中更为严重。
no_bf_poor = (hardship_students['miss_breakfast_rate'] > 0.8).mean()
no_bf_other = (student_cost[student_cost['is_hardship']==0]['miss_breakfast_rate'] > 0.8).mean()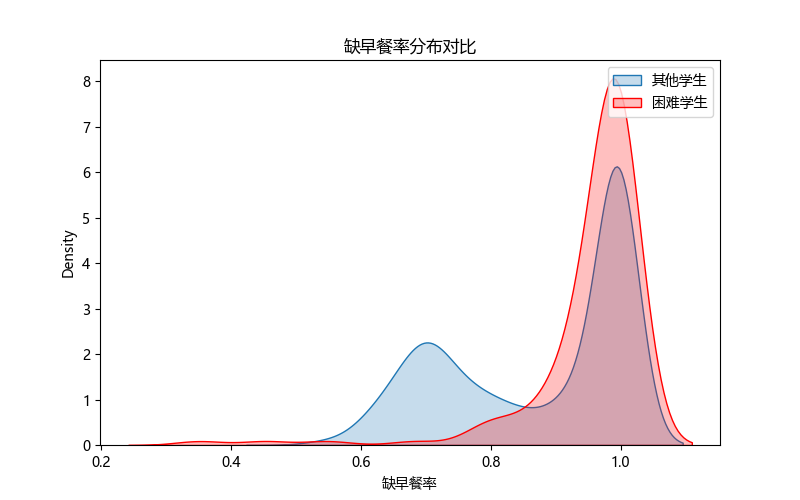
解读要点:
-
困难学生(红色)的缺早餐率分布明显右偏,集中在高缺失区间;
-
95.4%的困难学生几乎不吃早餐——资助重点应放在早餐补贴,直接解决"不吃早餐"的经济动因。
6.3 经济稳定性:消费波动与持续低消
困难学生的日消费波动更大、持续低消时间更长,存在明显的"断粮"风险:
python
# 左侧:消费变异系数散点分布 + 均值标记
# 右侧:最长连续低消费天数 KDE + 均值线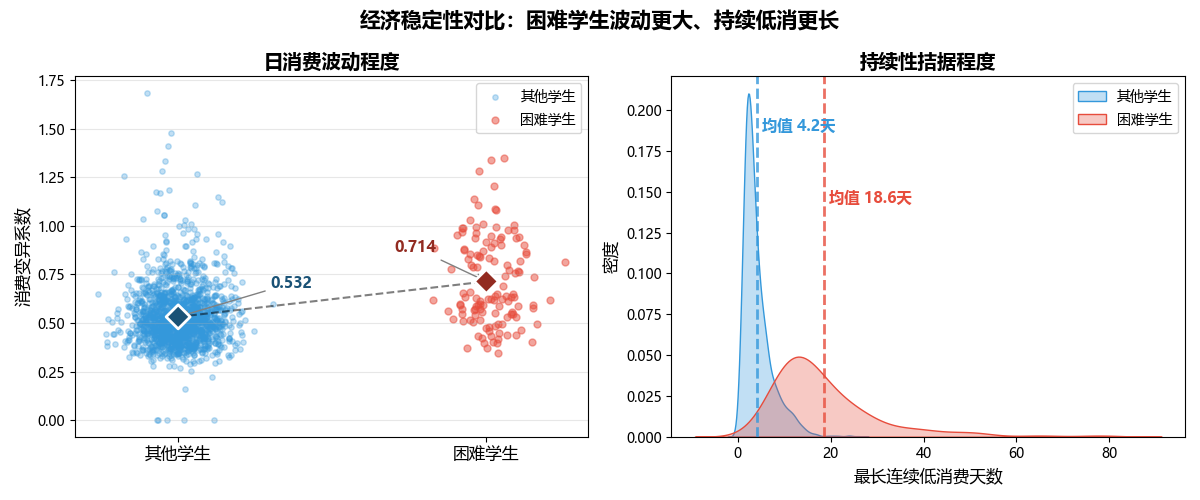
解读要点:
-
左图(消费变异系数):困难学生(红色)CV系数均值显著更高,菱形标记清晰展示了两组均值的差距,说明其日消费波动更大,经济来源可能不稳定;
-
右图(连续低消费天数):困难学生(红色)分布明显右移,均值高达18.6天——意味着他们曾连续超过半个月处于极度节省状态,远超其他学生。
6.4 月度消费趋势:压力敏感窗口识别
从各月人均日总消费趋势来看,困难学生全年各月消费均低于其他学生:
monthly_trend = daily_cost_full.groupby(['month', 'is_hardship'])['daily_cost'].mean().unstack()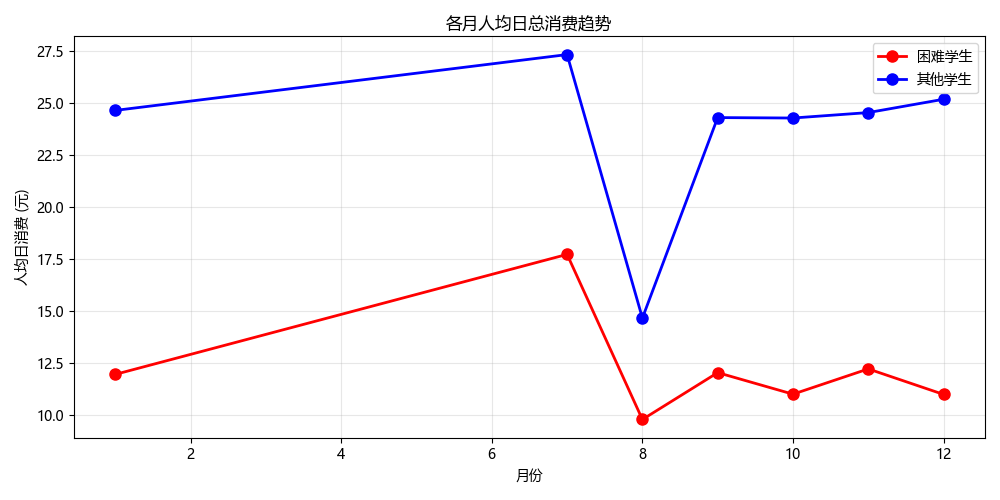
解读要点:
-
开学季与长假前后是困难学生经济压力的敏感窗口——9月开学初学生自带物资较多,10月国庆长假离校,消费出现低谷;
-
这一趋势提示学校,应在开学季与长假前后加强困难学生的生活保障。
7. 精准资助:三层托底体系
精准识别最终服务于精准资助。基于困难学生群体的画像特征(95.4%几乎不吃早餐、日均缺口约4.46元),我们设计了互补的三层方案。
7.1 补贴金额测算
以全校日均消费第15百分位(约16.30元/天)作为"体面生活线",困难学生当前日均消费中位数为11.84元,每日存在约4.46元的缺口:
living_line = student_cost['avg_daily_cost'].quantile(0.15)
hardship_students['subsidy_daily'] = np.maximum(living_line - hardship_students['current_avg'], 0)7.2 三层资助体系可视化
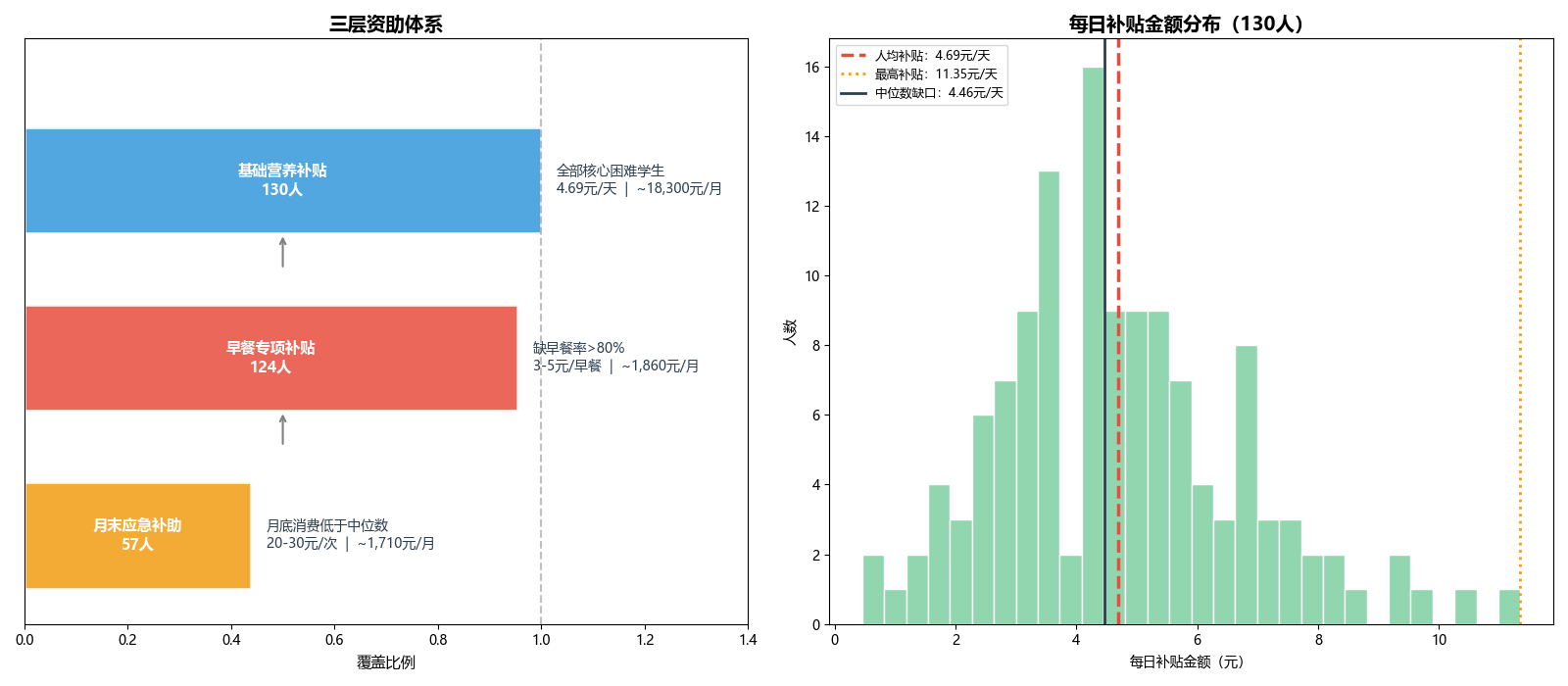
解读要点:
-
左图(三层资助体系):从上到下逐层精准——
-
第一层基础营养补贴覆盖全部130人,补足体面生活线缺口;
-
第二层早餐专项补贴聚焦124名缺早餐率>80%的学生,在早餐时段自动充值3-5元;
-
第三层月末应急补助针对57名月底消费明显下降的学生,每月25日后发放20-30元。
-
-
右图(补贴分布):展示了130名困难学生每日补贴金额的分布,三条参考线分别标注人均补贴、最高补贴和中位数缺口。
| 方案层级 | 覆盖人群 | 核心逻辑 | 预期目标 | 月度成本 |
|---|---|---|---|---|
| 基础营养补贴 | 全部130名困难生 | 补足体面生活线(16.3元)缺口 | 实现生活底线兜底 | 约18,300元 |
| 早餐专项补助 | 缺早餐率>80%者(124人) | 早餐时段自动发放定向补贴 | 解决因贫困导致的"跳餐" | 约1,860元 |
| 月末应急资助 | 月底消费低于中位者(57人) | 每月25日后发放应急额度 | 对冲月末资金短缺风险 | 约1,710元 |
三项合计月均仅需约21,900元,即可实现对130名困难学生的精准生活托底,人均月补约168元。相较于该校全寄宿制的运营成本,这一投入负担极轻。
8. 结果总结
本研究基于某校全寄宿制高中46万余条消费记录,采用"双层筛选模型"从1,730名学生中精准识别出130名核心困难学生(占全校7.5%),并通过孤立森林交叉验证(重叠率43.08%),验证了识别结果的稳健性。主要结论如下:
8.1 贫困识别结论
-
消费水平严重偏低:困难学生日均总消费中位数为11.84元,与全校体面生活线(16.30元/天)之间存在约4.46元的每日缺口;
-
三餐全方位节省:困难学生在早餐、午餐、晚餐各时段的消费均低于其他学生,其中午餐和晚餐是省钱的主要来源(合计每日少花约2.14元);
-
早餐缺失极其严重:95.4%的困难学生几乎不吃早餐(缺早餐率>80%),远超其他学生的65.3%,早餐补贴是最迫切的干预切入点;
-
经济持续性不稳定:困难学生平均最长连续低消费天数高达18.6天,意味着他们曾连续超过半个月处于极度节省状态,存在明显的"断粮"风险;
-
校园依赖度更高:困难学生周末消费占比为9.93%,明显高于其他学生的6.78%,校园是其主要生活空间;
-
生源地呈现地域特征:困难生比例最高的地区为宁海(18.18%)、奉化(16.67%)、余姚(15.38%),呈现"周边区县高于中心城区"的特征。
8.2 资助方案结论
-
三层托底体系:基础营养补贴(全覆盖)+ 早餐专项补助(缺早餐率>80%者)+ 月末应急资助(月底消费低于中位者),三项合计月均约21,900元,人均月补约168元;
-
成本效益显著:相较于全校全寄宿制的运营成本,这一投入负担极轻,却能实现困难学生群体的生活底线保障。
9. 结语
从"经验判断"到"数据驱动",从"统一发放"到"分层滴灌",教育大数据正在让校园资助工作变得更精准、更有温度。本文构建的双层筛选模型和三层资助体系,仅是一个起点。
我们相信,每一份助学金都应当精准抵达最需要它的学生手中,每一顿早餐都不应因贫困而被迫省去。未来,随着更多维数据的接入(如家庭经济状况、学业表现、心理健康等),精准资助的画像将更加立体,教育的公平与温度也将更进一步。
让数据说话,让温暖落地。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 57
57 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)