【晓天衡宇·评测社区】复杂指令遵循榜单正式发布,国产模型输在哪里?
【榜单简介】
该榜单评测大模型复杂指令遵循能力,包含202道多约束指令题,覆盖文本处理、文本生成、角色扮演、语言理解、逻辑推理和问答六大任务类型。采用约束通过率和严格通过率ILA两种评测指标,并通过人机一致性验证确保评测可靠性。
【参评模型】
【评测集解读】
评测维度
任务类型涉及文本处理、文本生成、角色扮演、语言理解、逻辑推理和问答六大类。主要设计了非知识类考察的任务类型,本次测试完全排除需要外部知识检索的事实性问答,规则理解也是指令自包含可验证形式。任务聚焦客观可评估的任务类型,没有过多选择纯粹文本生成类的任务。但在设计挑选上还是有部分要求细致,客观程度较高的主观性问答、创意写作任务包含其中。
数据标准
自建复杂多约束指令202题。我们构建了包含“指令结构(L1)、约束功能(L2)、约束类型(L3)”的三级分类体系,设计了全面的任务类型和任务约束拓扑关联图,可以用来评价多约束指令的客观难度,并引导合成高质量评估数据。指令通过设计教学约束、操作约束、边界范围约束、数量篇幅约束、格式输出约束、素材约束六大类限制约束之间的复杂逻辑推理关系,提升题目评估难度。
数据采取合成+人工优化的策略, 或者纯人工构建。并且我们通过自定义的方式设计了不同约束类型对题目难度贡献的权重计算公式,以此检测检测评估题目的难易程度,并且将模型难度通过百分制转换区分为S, A, B, C,D 五个级别的难度,以此区分模型在不同难度数据上的遵循表现。
每道题都经过多人标注评分考点,考点设计逻辑严格依据约束对结果影响的程度来进行细化拆分,减少或合并部分低区分度的考点实现动态权重。
【评分标准】
一、约束通过率
简单计算每个考点的通过率作为每个模型每道题的得分,百分制。由于考点设计是人工根据不同难度、实现细节和对模型回复影响的程度动态拆分,因此回复评估就是简单计算考点通过率作为约束得分。
二、严格通过率ILA
所有数据中每个题的每个考点都完全通过的比率,即但凡有一个考点不通过就是0,可以理解成约束完全遵循的比率。
【榜单速览】
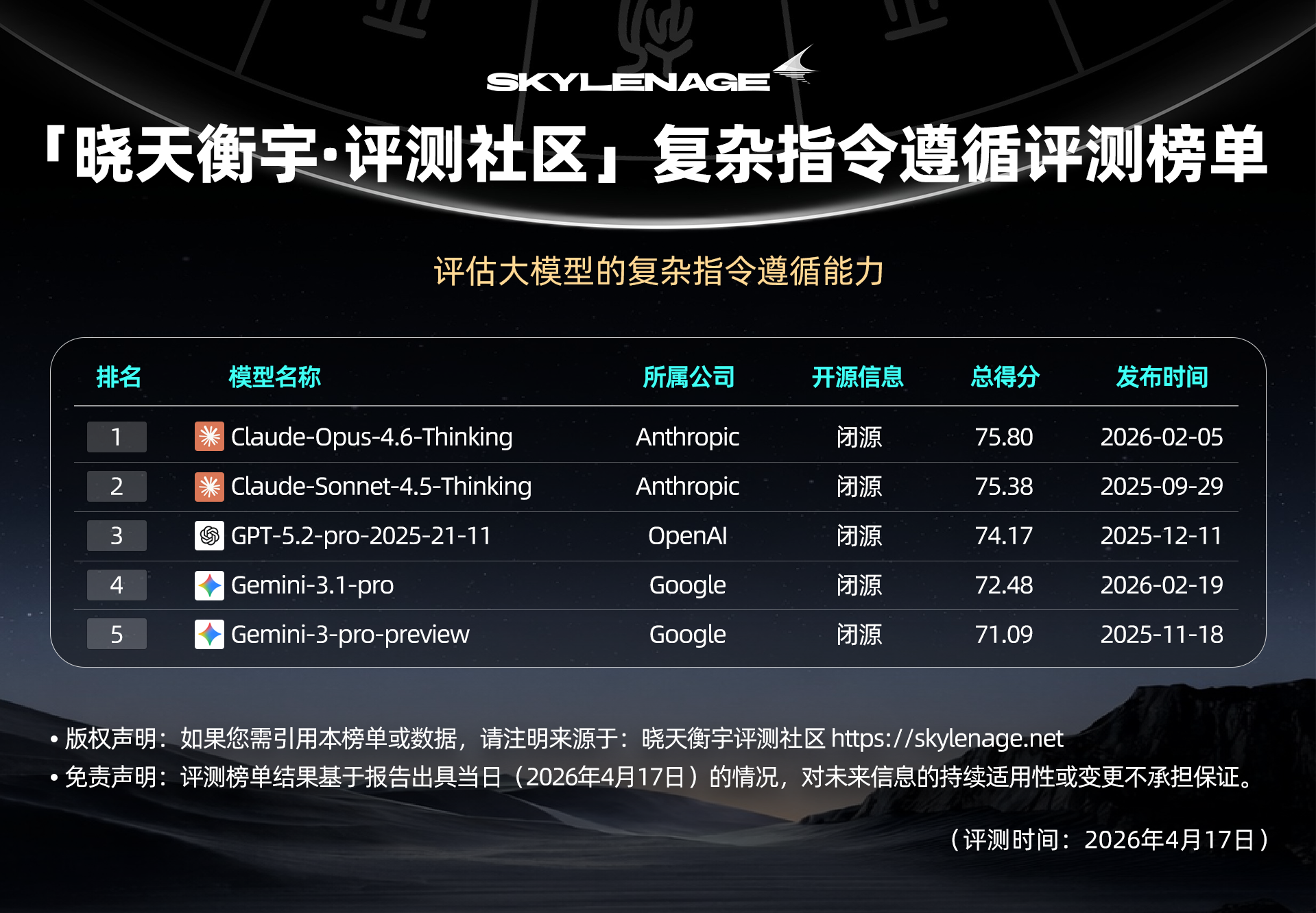
【榜单结论】
人工专家盲测了49个题,覆盖32个模型,评测了1125道题,整体纯粹的人机打分一致性是0.788,属于可靠性较高的水平。
整体测验的一致性较高。
相关性强(0.79-0.80)→ 模型评分趋势与人工高度一致;
一致性好(ICC=0.792)→ 标注员间打分稳定可靠;
误差可控(12.8%) → 绝对分值有偏差但在合理范围内。
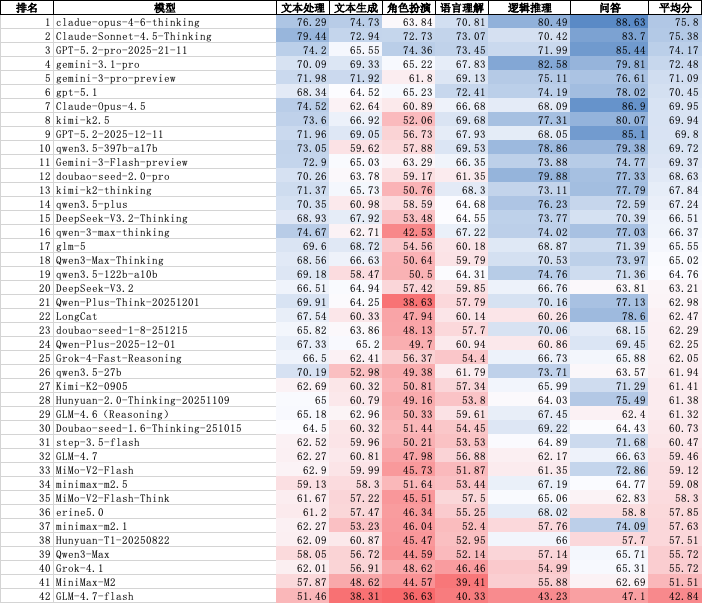
结合八大数据类型的综合平均分,以及在最高难度自建人工集(H / HM)上的抗压表现,本次参评的 40 个模型呈现出极具阶级感的能力梯队:
第一梯队(国际断层 SOTA,均分 > 73,自建高难不崩盘)
-
入围代表:
Claude 4.5 Sonnet Thinking、Gemini 3 Pro Preview、Claude 4.6 Opus Thinking、Gemini 3.1 Pro。 -
能力画像:真正的顶级梯队被 Anthropic (Claude) 和 Google (Gemini) 的最新前沿模型包揽。它们的恐怖之处在于:面对极端复杂的 HM(人机协作组合约束)数据,依然能稳住 60-70 分的盘面(如 Claude 4.5 Sonnet 在 HM 上 斩获全场最高的 70.17 分),展现出绝对领先的复杂逻辑拓扑解析能力与指令遵循稳定性。
第二梯队(国产准 SOTA 与国际强模型,均分 70 - 73 分)
-
入围代表:
GPT-5.2 Pro(72.66分)、Kimi k2.5(72.35分)、Doubao Seed 2.0 Pro(72.19分)、DeepSeek V3.2 Thinking(70.89分)、GLM-5。 -
能力画像:令人惊喜的是,Kimi、字节大模型 (Doubao)、深度求索 (DeepSeek) 和智谱 (GLM) 的最新大杯模型已成功跻身这一梯队,综合表现与 GPT-5.2 Pro 及 Claude 4.5 Opus 旗鼓相当。在自建纯人工数据 (H / HM) 上开始出现轻微疲软(跌至 50-60 分区间),在超长距多重条件嵌套上偶发幻觉。
第三梯队(主流实战梯队,均分 66 - 70 分)
-
入围代表:
Qwen 3 Max/Plus 系列、GPT-5.2 基础版、GLM-4.7、Grok 4 Fast Reasoning。 -
能力画像:这一梯队以阿里 Qwen 系列及智谱上一代主力模型为主。能力特点是“偏科严重”——在单一任务或基础文本处理上表现优异,但一旦叠加“格式约束 + 流程约束 + 边界否定”的三维约束,得分直接腰斩。例如 Qwen 3 Max (0123版) 在 HM 数据上仅得 38.49 分,证明其对隐含业务逻辑的理解依然停留在表面字面量匹配。
第四梯队(基础可用及边缘梯队,均分 < 66 分)
入围代表:ERNIE 5.0 (文心)、Hunyuan (混元)、MiniMax (海螺)、MiMo、LongCat。
能力画像:面对本评测的高压复杂指令基本“全线溃败”。这些模型在自建复杂集(H/HM)上的得分普遍在 40 分左右徘徊,部分甚至下探至 20-30 分区间。暴露出的核心问题是对 L1 层级(如条件、嵌套关系)的逻辑拓扑完全无法解析,极易陷入“忽略核心任务,只输出个空壳 JSON”的形式主义错误。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)