从 Demo 到生产:NVIDIA RAG 部署课程学习与 Mirror 实践启发(THS)
前言
本文基于 NVIDIA Deep Learning Institute 的《在生产环境大规模部署 RAG 工作流》课程,围绕 NIM、RAG、K8s/Helm/Operator、监控弹性、多模态与 Agentic AI 等主线,从工程实践角度总结课程内容,并结合 Mirror 平台的实际场景提供启发。
当我们谈论"把 AI 能力集成到产品"时,大多数讨论停留在"选什么模型"、"Prompt 怎么写"。但 NVIDIA 这门课程的核心不在于此,而是回答了一个更本质的问题:
如何把 AI 能力从 Demo 变成可交付、可运营、可治理的系统能力?
作为 Mirror 平台的工程团队成员,我们面临的挑战不是缺少模型,而是如何把多模型、多 Agent、上下文资产、在线 IDE 沙盒等能力整合成稳定、可观测、可扩展的工程系统。这门课程提供了一套完整的工程化思路:从容器化部署、Kubernetes 编排、监控弹性,到多模态 RAG 与 Agentic 工作流。
本文将按以下结构展开:
- 课程五大主线总结(工具应用 vs 技术原理)
- 讲解两个核心工具应用(NIM Operator + K8s 交付;监控 + 弹性闭环)
- 结合 Mirror 平台的四点启发
一. 课程五大主线总结
主线 1:NIM & API Catalog ——把模型变成"可部署服务"
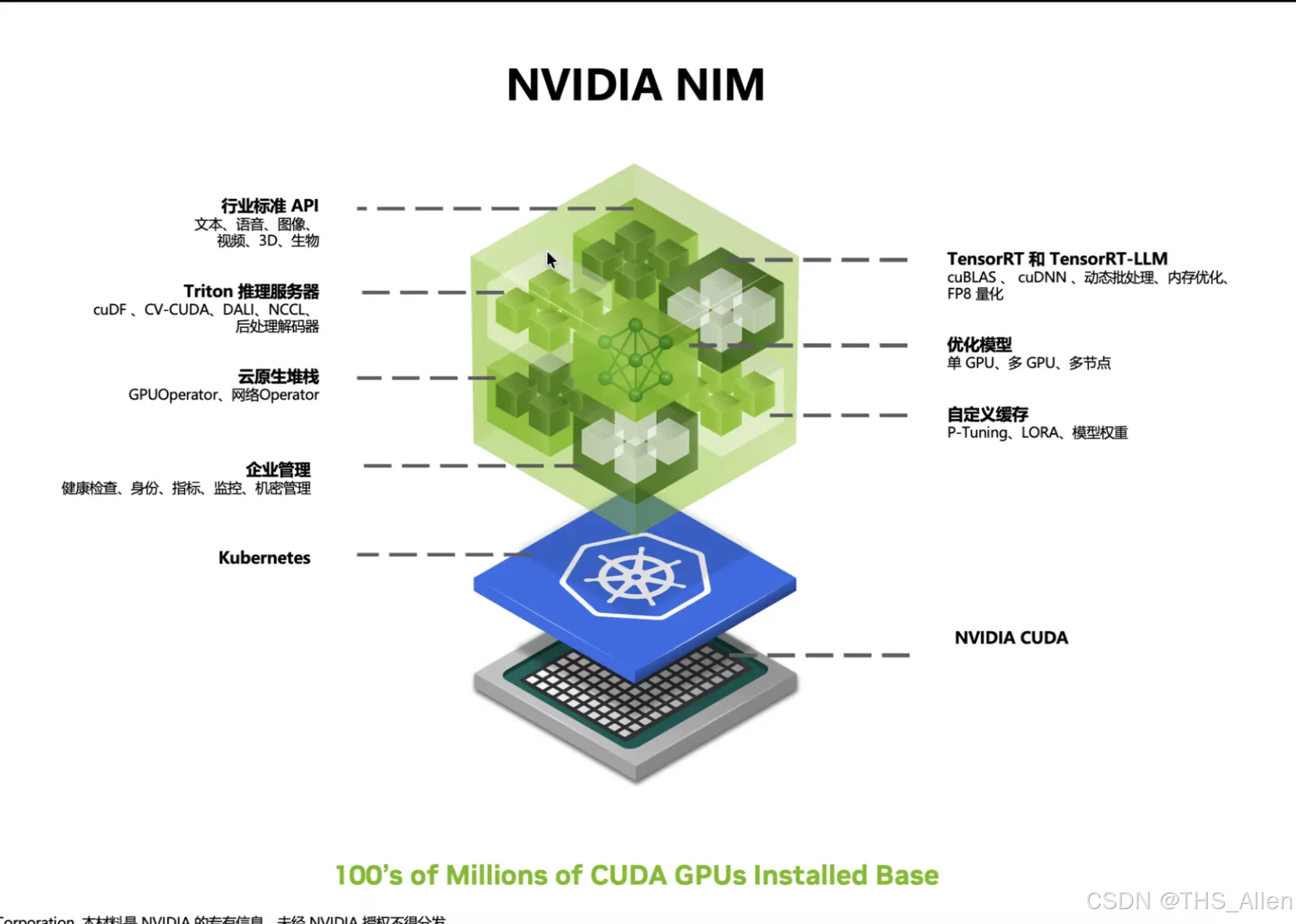
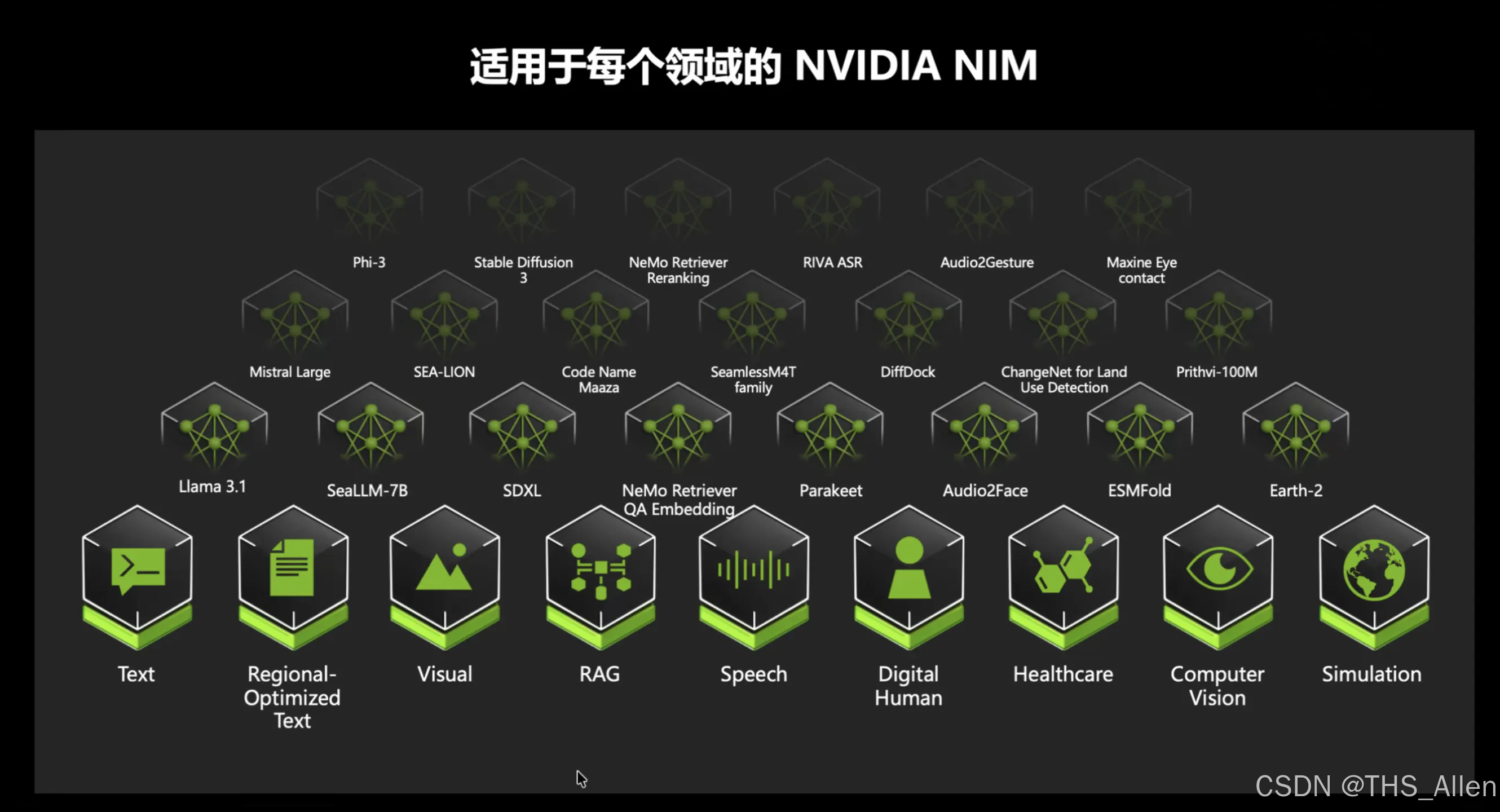
课程讲什么?
NVIDIA 提供的 NIM(NVIDIA Inference Microservices)是一套专业级的企业部署方案,核心思路是:
- 通过 API Catalog(模型市场)快速试用各种 NIM 能力(推理、Embedding、Rerank 等)
- 验证方案可行性后,一键打包部署到私有环境
- 形成可工程化交付的"模型服务层"
工具应用:
- API Catalog:选型与试用入口,降低模型验证成本
- NIM:容器化的模型推理服务,支持 LLM、Embedding、Rerank、多模态等多种能力
技术原理:
推理服务为何受显存/吞吐/延迟约束,需要 KV Cache、并行等优化,但重点不在原理推导,而在工程交付路径。
主线 2:RAG 工程拆解 ——从"问答"到"可运营流水线"
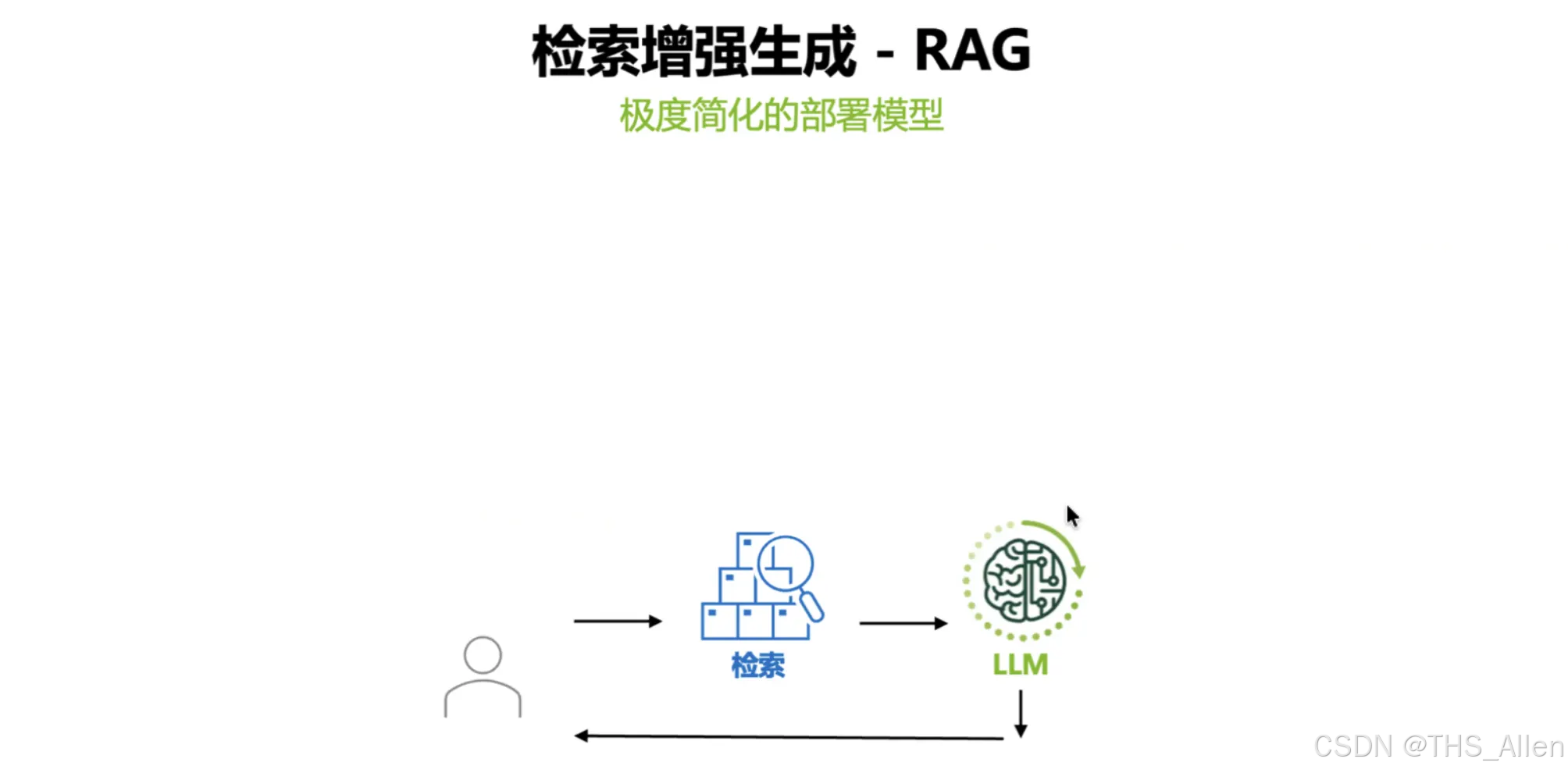
课程讲什么?
RAG 不是"喂文档 + 问问题"这么简单。课程以工程视角拆解了完整链路:
文档处理 → Embedding → 向量库 → 检索/重排 → Prompt 构建 → LLM 生成
强调"可组合、可替换"的部署思路:每个环节(Embedding、Rerank、向量库)都可以独立升级,不影响整体架构。
工具应用:
- 向量库:课程展示了多种可选方案(如 Milvus、Faiss 等)
- 应用层编排:chain-server、rag-frontend 等服务化组件
技术原理:

主线 3:DevOps 上生产 ——容器 / K8s / Helm / Operator
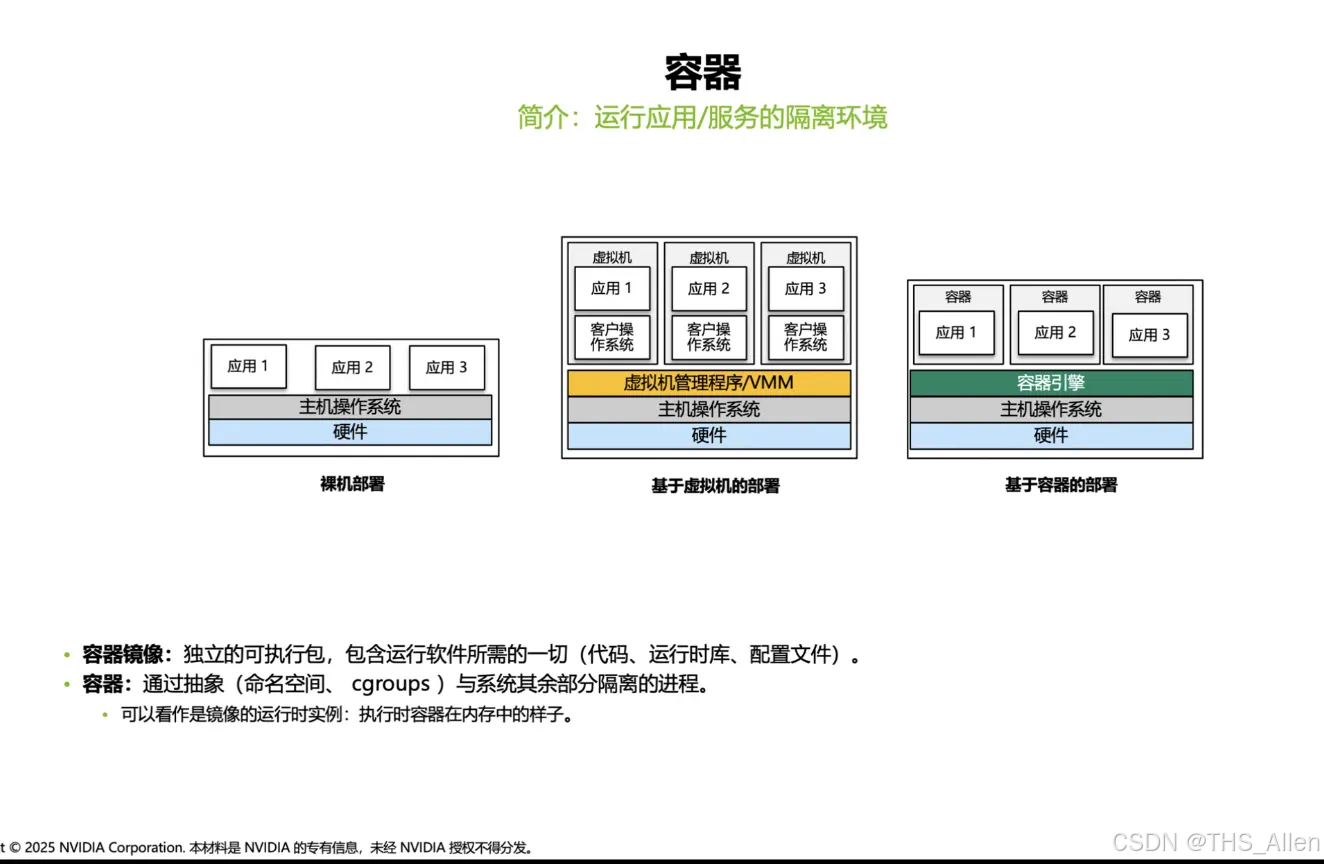
课程讲什么?
把 RAG 从"能跑"变成"可交付"的关键路径:
- 容器镜像化:Docker 封装环境依赖
- Kubernetes 运行:资源隔离、调度、健康检查
- Helm 参数化部署:通过 Chart + values.yaml 管理多环境差异
- Operator 管理生命周期:声明式管理 NIM 服务

工具应用:
- Docker / docker-compose:容器化基础
- Kubernetes:Pod、Namespace、调度与隔离
- Helm:Chart + values.yaml 参数化部署
- NIM Operator:声明式管理 NIM 服务的生命周期
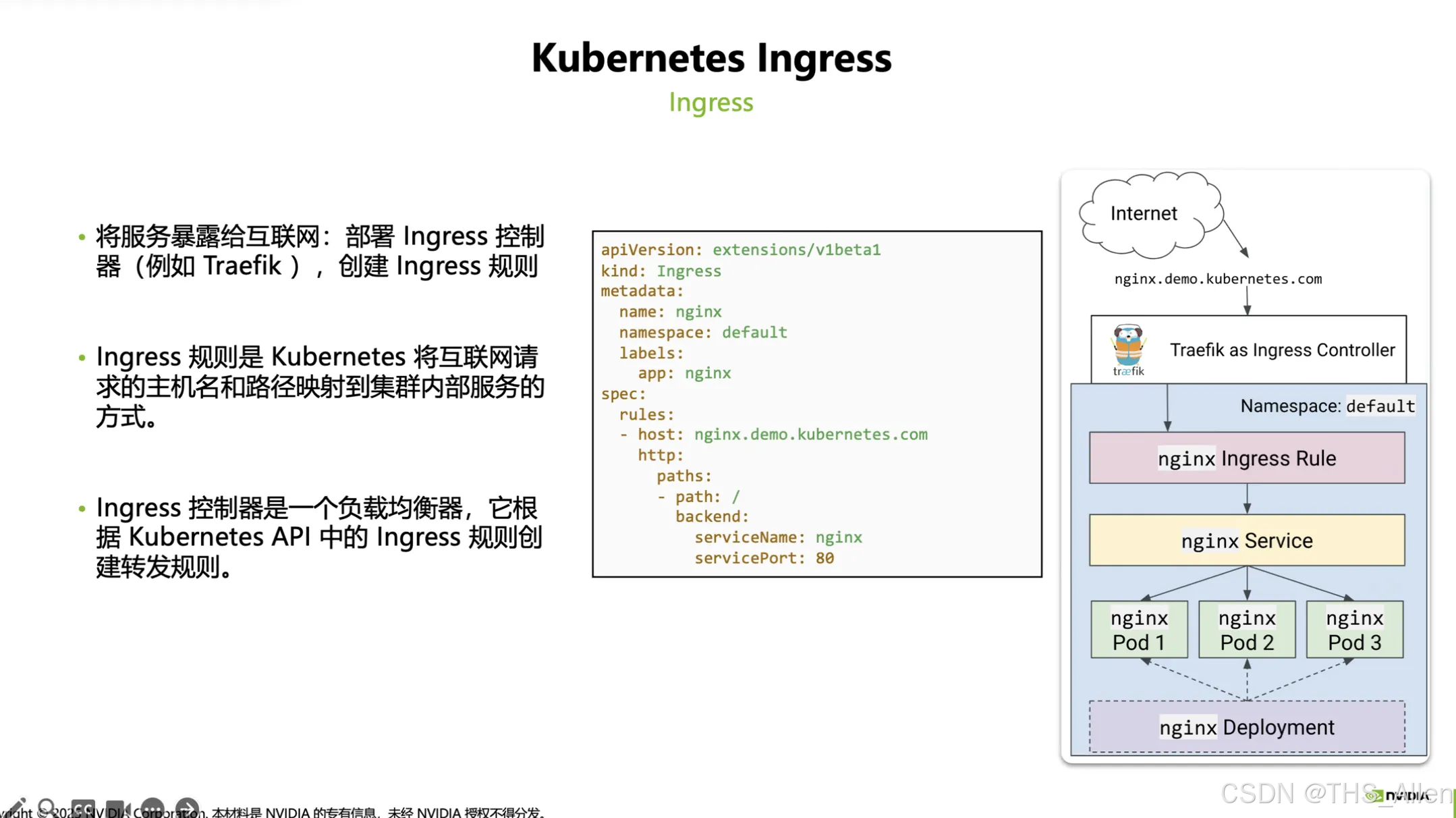
- Ingress、PV/PVC:网络暴露与持久化存储

技术原理:
推理性能与成本优化手段(量化、KV Cache、分布式并行)主要作为"为何要治理"的背景介绍。
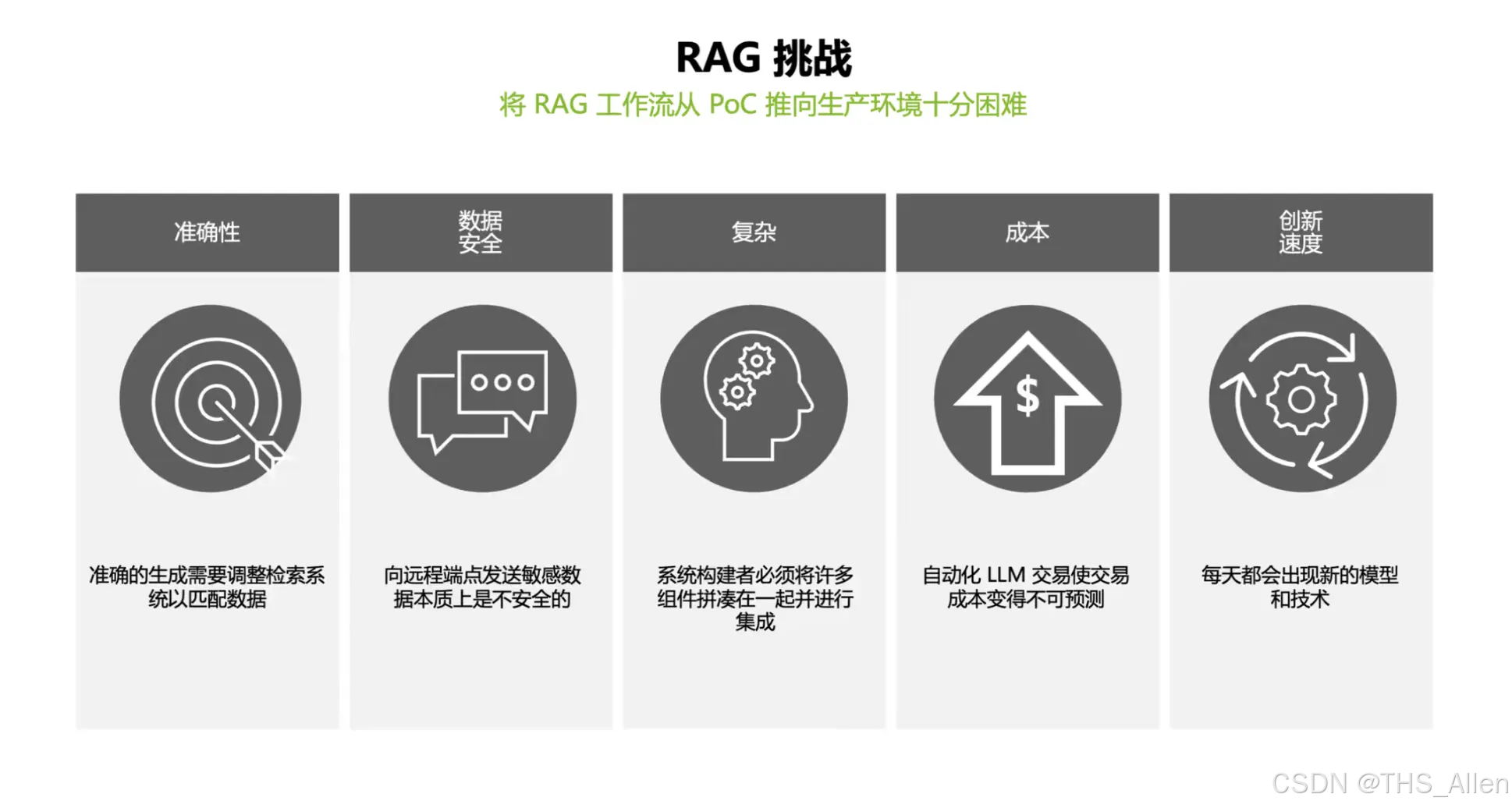
主线 4:可观测性与弹性 ——监控闭环 + 自动扩缩容 + 压测验证
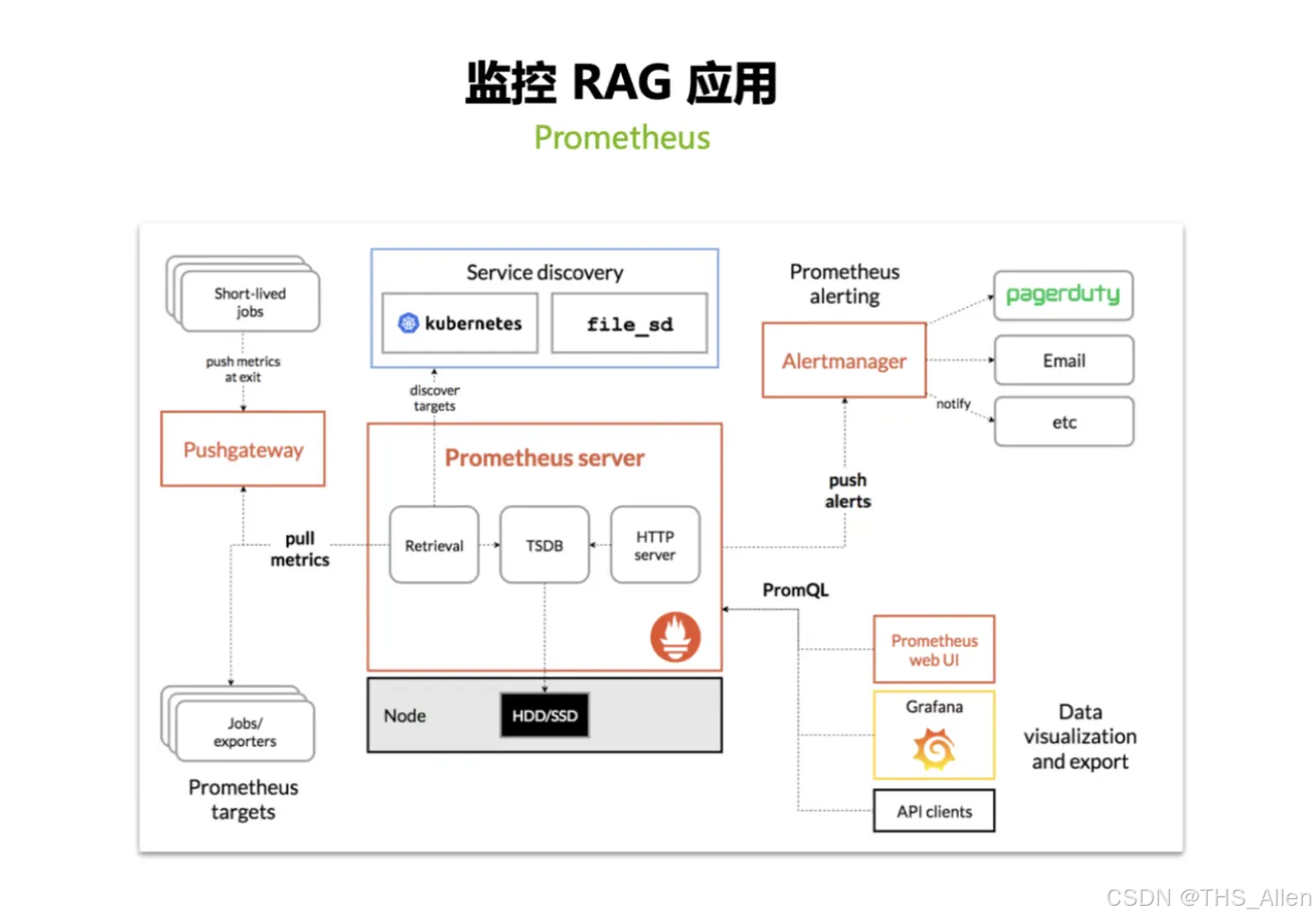
课程讲什么?
"能部署"不等于"能服务"。课程构建了完整的可观测性与弹性治理闭环:
- 监控栈:Prometheus + DCGM Exporter + Grafana
- 弹性策略:HPA 使用自定义 Prometheus 指标触发扩缩容
- 验证手段:Locust 生成负载,验证扩缩容是否按预期工作
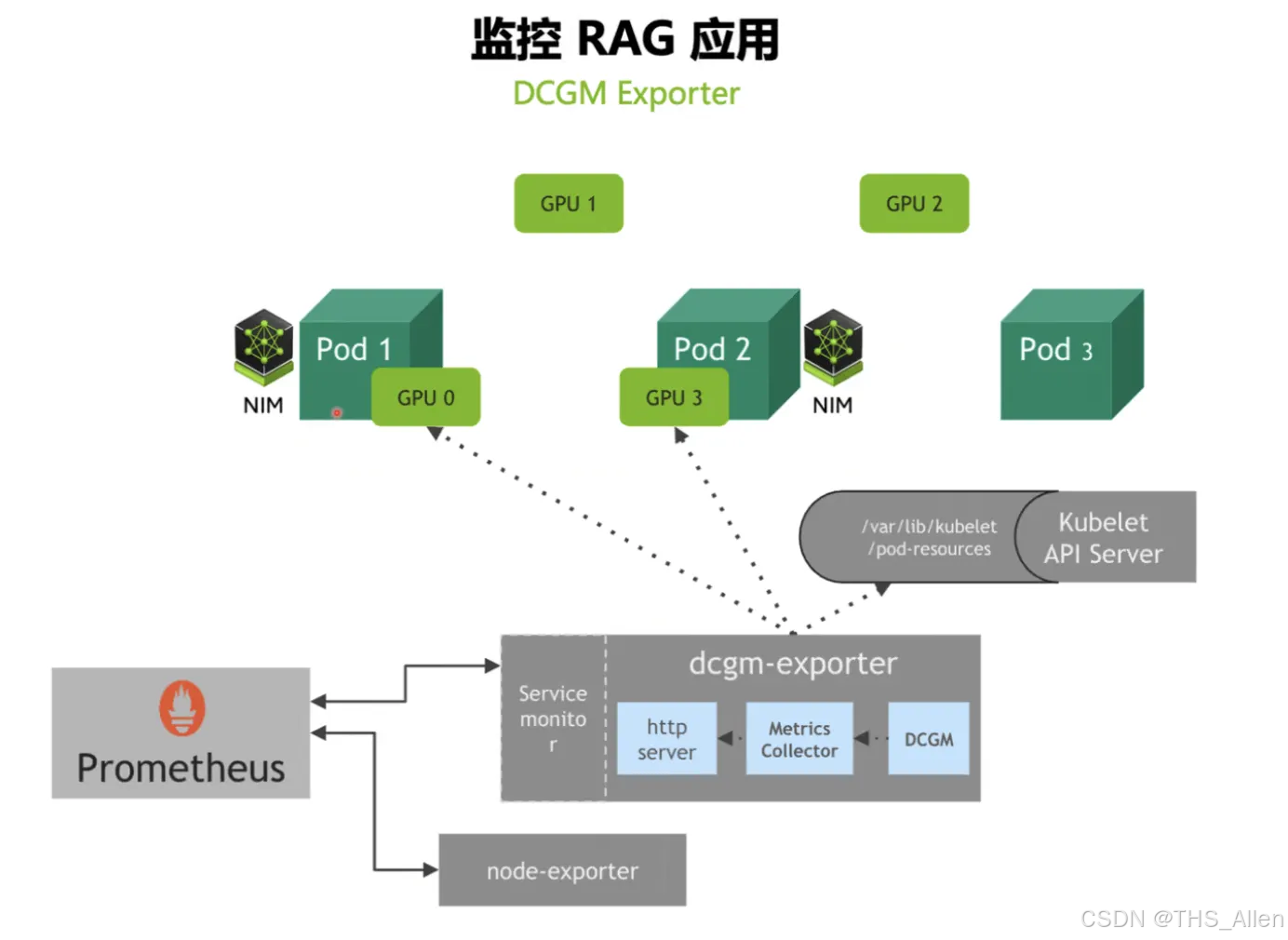
工具应用:
- Prometheus:采集服务指标(QPS、延迟、错误率、队列)
- DCGM Exporter:采集 GPU 指标(利用率、显存、温度、功耗)
- Grafana:可视化运营与排障仪表盘
- HPA:基于自定义指标的自动扩缩容
- Locust:压测工具
技术原理:
为什么模型服务必须纳入 SRE:容量规划、失败率、延迟 SLA、GPU 资源利用率等,否则无法稳定服务化。
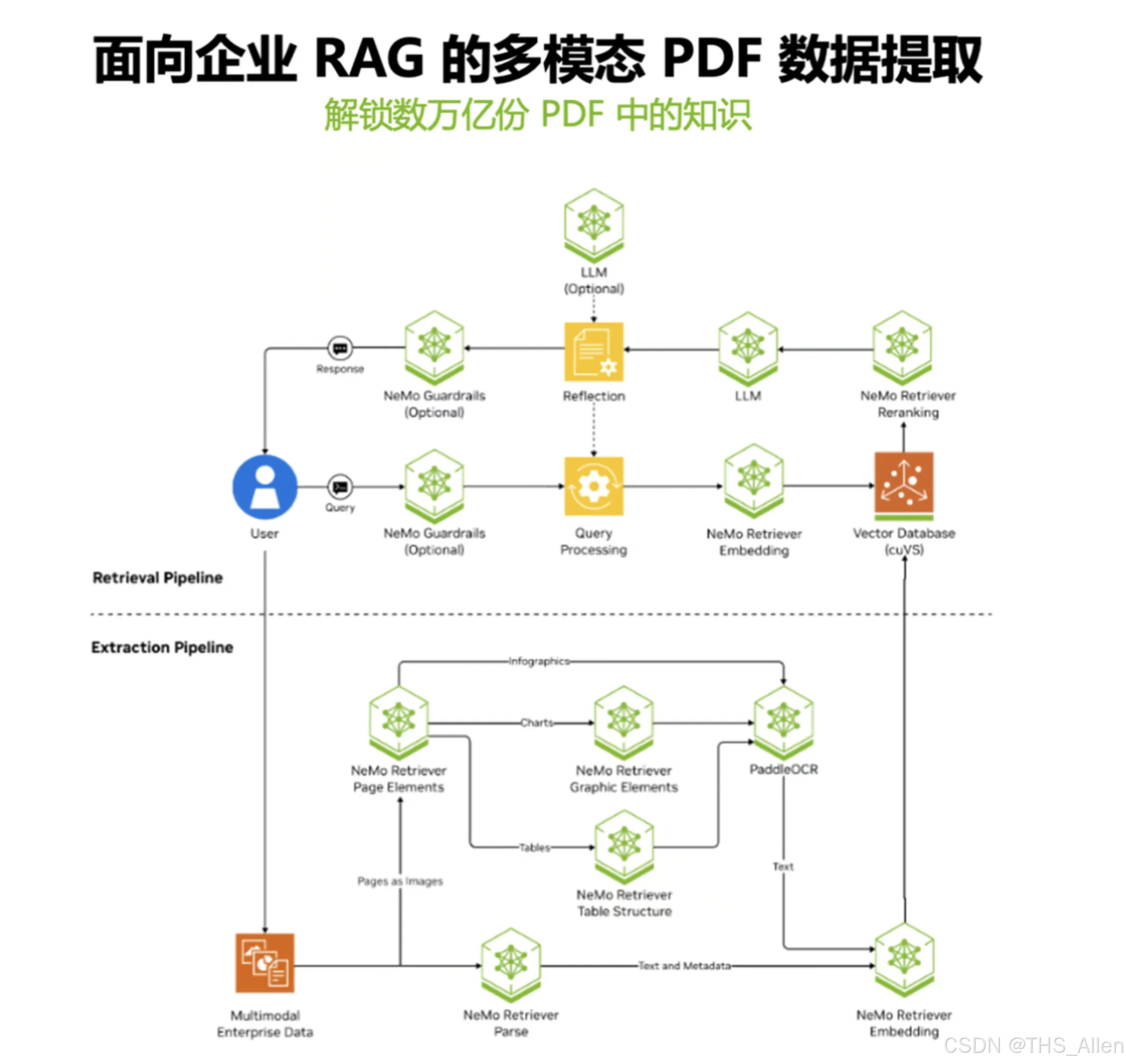
主线 5:多模态 RAG + Agentic AI ——从文本到 PDF/图表/表格,再到路由编排

课程讲什么?
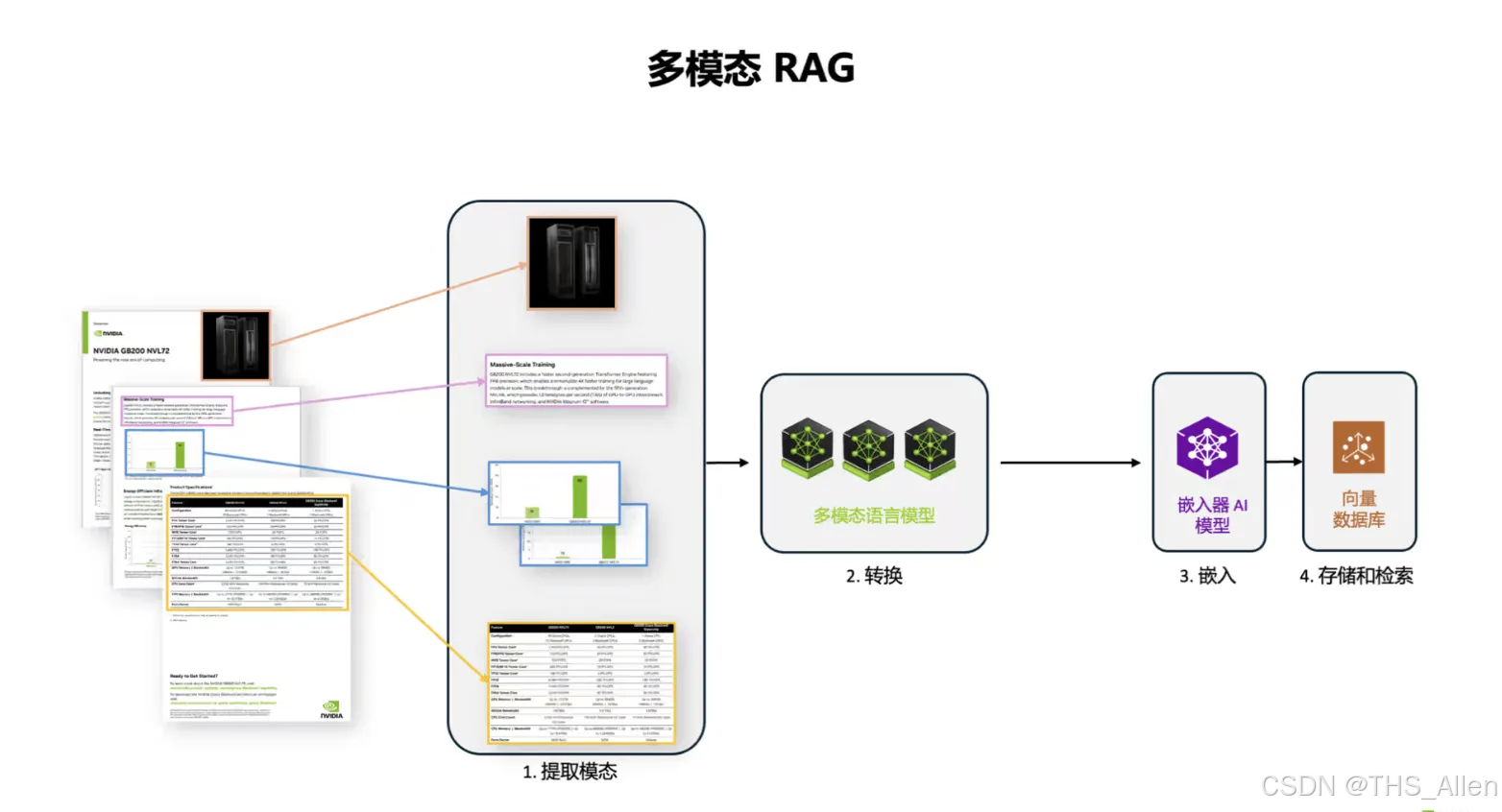
多模态 RAG 四步流程:
- 提取模态:从 PDF 中提取文本、表格、图像(图表、绘图)
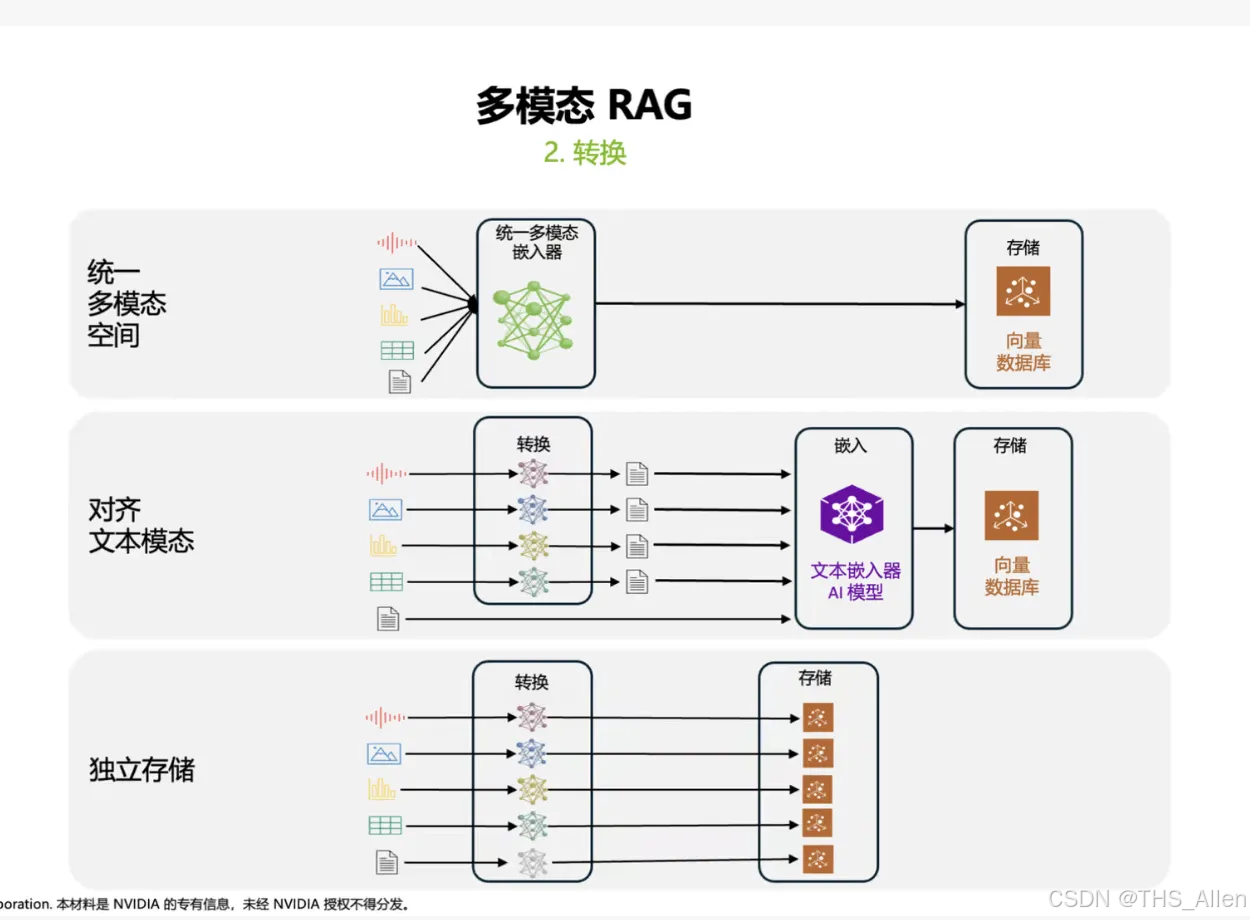
- 转换:将不同模态转为统一表示
- 嵌入:多模态向量化
- 存储与检索:向量库存储与语义检索
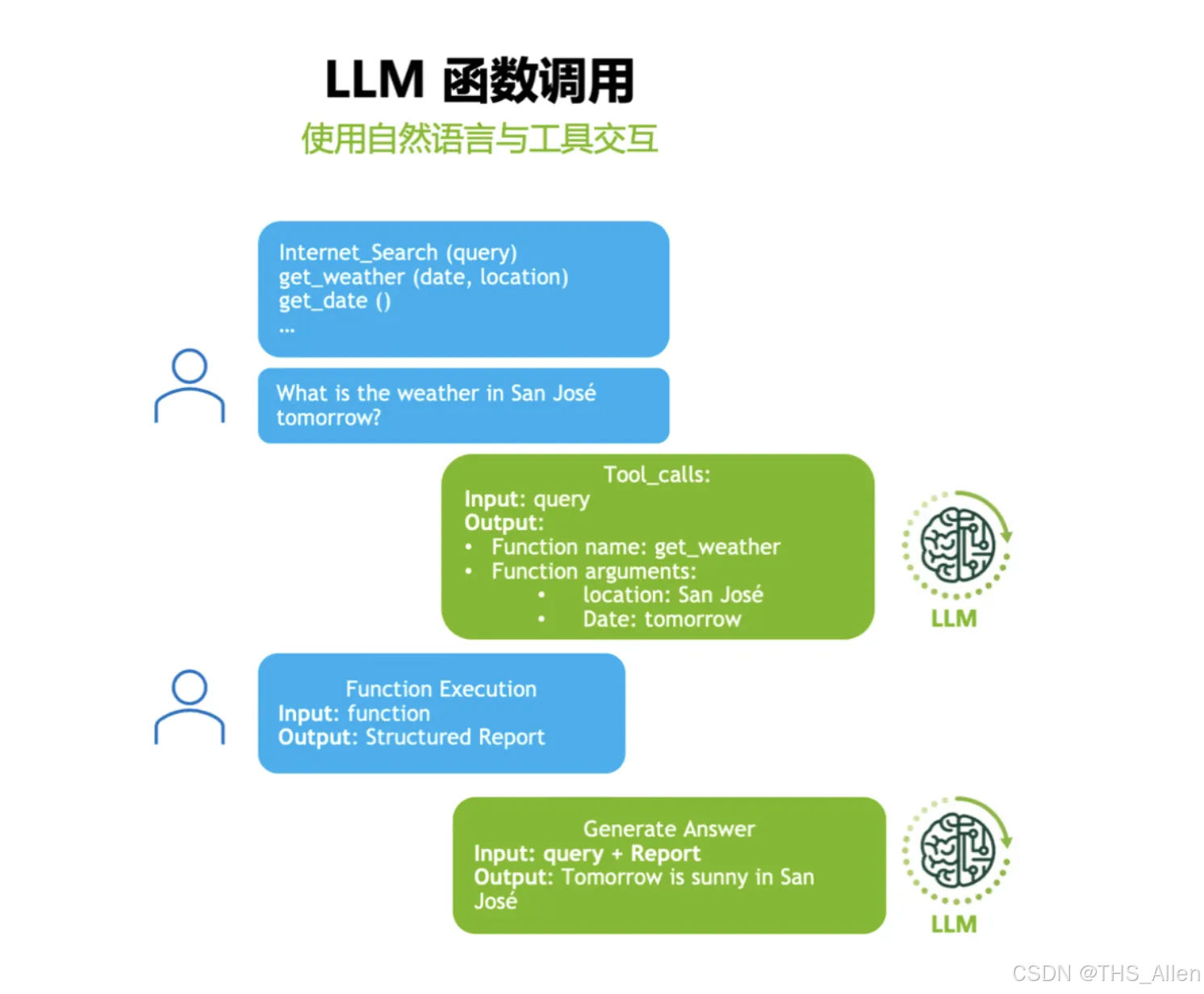
Agentic AI:函数调用/工具交互,用图结构(如 LangGraph)做查询路由与工作流编排。
工具应用:
- 多模态提取/转换组件:OCR(OCDRNet、PaddleOCR)、物体检测(nv-yolox-page-elements-v1)、VLM(DePlot、Chached、llama3.2-90b-vision-instruct)、CLIP
- LangChain / Unstructured:构建摄取与 RAG 流水线
- LangGraph:查询路由与工作流编排
技术原理:
- 多模态对齐(图文同空间)的概念
- "先摄取再检索"的分层方法
第一节总结:工具应用 vs 技术原理
|
维度 |
内容 |
|
工具应用 |
NIM/API Catalog、K8s/Helm/Operator、Prometheus/Grafana/DCGM、HPA/Locust、多模态组件、LangGraph |
|
技术原理 |
推理性能与成本(量化/KV Cache/并行)、RAG 质量因素、多模态对齐与摄取分层 |
二. 深入讲解两个核心工具应用
2.1 工具深讲 1:NIM Operator + K8s 交付(把模型服务纳入"标准发布体系")
讲解目标:
这一节重点展开课程中最实用的两个工程化主题:如何让模型服务可交付,以及如何让 RAG 系统可运营。

- NIM:作为 K8s 中的推理服务运行单元(容器化服务)
- Operator:用声明式资源来管理 NIM 的生命周期(创建/更新/健康/资源)
为什么需要 Operator?
直接用 Deployment/StatefulSet 管理推理服务会遇到很多问题:
- 模型加载时间长,需要特殊的健康检查策略
- GPU 资源分配与隔离需要精细控制
- 配置(模型路径、API Key、缓存策略)需要统一管理
NIM Operator 封装了这些最佳实践,让开发者只需关注"要什么模型、要多少副本、要什么规格"。
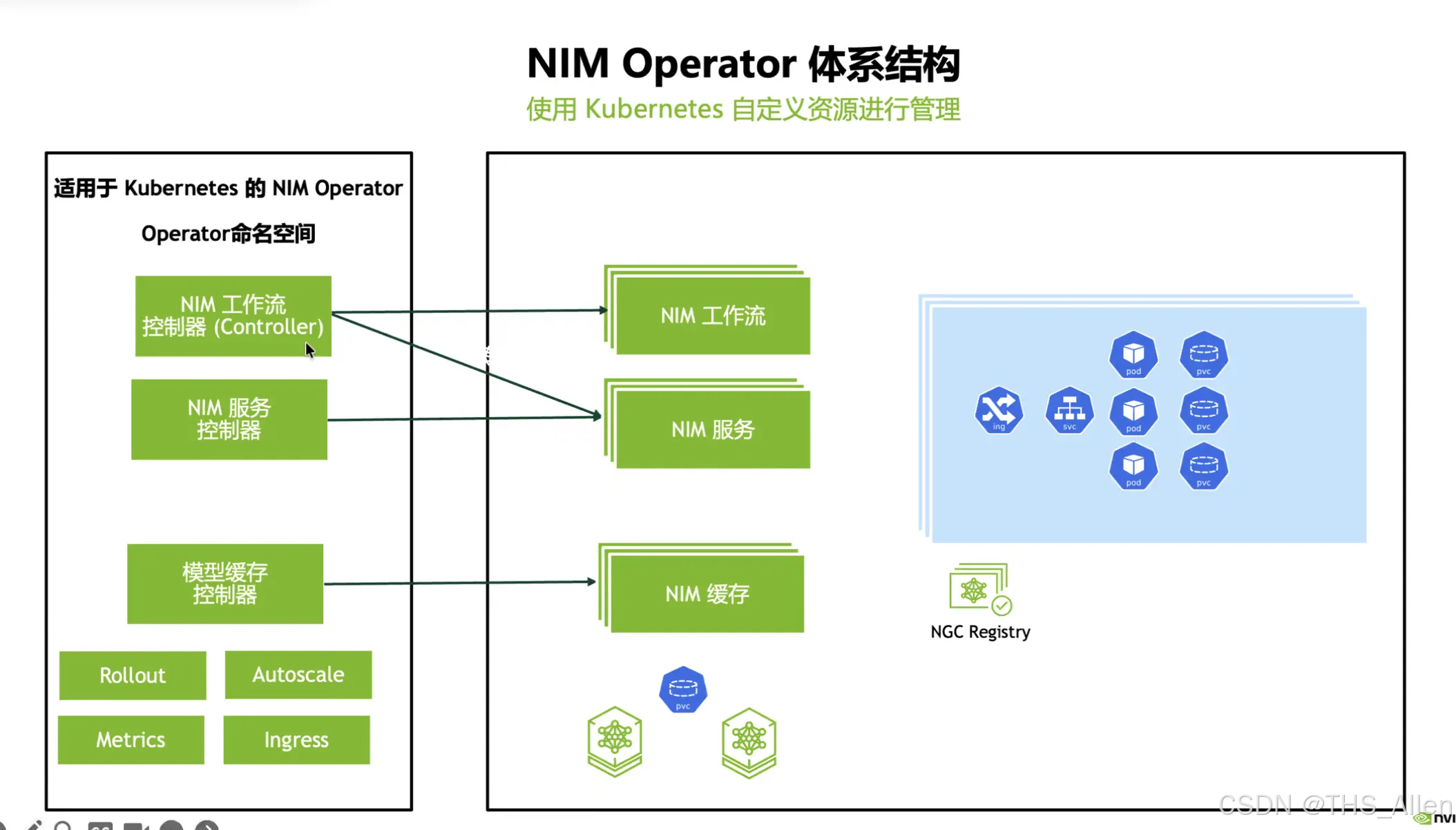
怎么用它搭建 RAG 系统?
一个完整的 RAG 系统通常分为三层:
- 模型服务层:LLM、Embedding、Rerank 等 NIM 服务
- 应用编排层:负责调用模型、组装 Prompt、处理用户请求
- 数据存储层:向量数据库、文档库等
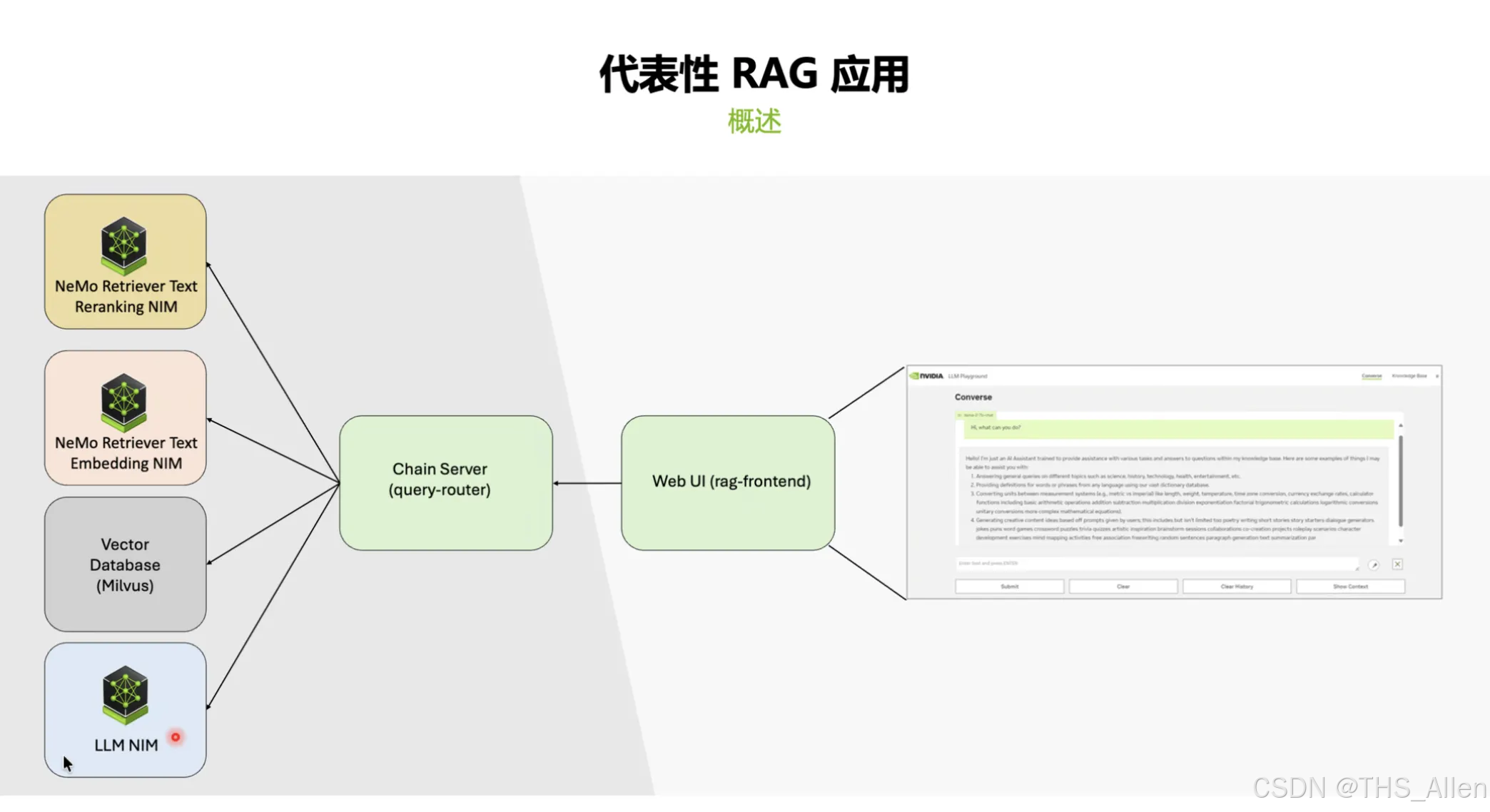
用 Helm 这样的工具可以把不同环境(开发/测试/生产)的配置参数化管理,再配合 Kubernetes 的 Ingress(网络入口)、持久化存储等基础设施,就能把整套系统稳定地跑起来。

一句话总结: NIM Operator 把部署 AI 模型这件事变得像部署普通微服务一样标准化,让 AI 能力可以真正进入企业的持续交付流程。
2.2 监控与弹性:让 RAG 系统能扛住真实流量
讲解目标:
"如何把 RAG 从 demo 变成可运营服务"。光把系统部署上线还不够,你得知道它跑得怎么样、能不能扛住流量高峰、出问题怎么快速定位。这就是可观测性与弹性要解决的问题。
课程构建了一套完整的监控体系:
- Prometheus:采集服务层面的指标——请求量、响应延迟、错误率、队列长度
- DCGM Exporter:采集 GPU 层面的指标——利用率、显存占用、温度、功耗
- Grafana:把这些数据可视化,做成运营仪表盘
- 有了这些指标,你就能回答系统现在健康吗、成本多少、瓶颈在哪这些关键问题。
怎么自动扩缩容?
AI 推理服务的瓶颈通常不是 CPU,而是 GPU 利用率或者请求队列长度。课程展示了如何用 HPA(Horizontal Pod Autoscaler)配合 Prometheus 自定义指标,让系统根据实际负载自动增减副本数。
比如:当队列积压超过阈值动扩容,流量回落后自动缩容以节省成本。
怎么验证有效?
用 Locust 这样的压测工具模拟真实流量,观察监控指标和扩缩容行为是否符合预期。这是上线前的安全演练。
一句话总结:
"能部署"不等于"能服务":监控 + 弹性 + 压测验证,才让 RAG 进入可运营阶段。
三. 对 Mirror 平台的四点启发
对应Mirror工程2026目标
- 开发 AgentSDK,提供 Agent 统一交互协议,实现 Agent 全生命周期管理与在线调试能力;
- 工作台建设,覆盖更多技术栈,支持二开,支持IDE、桌面应用等更多维度形态的接入;
- 全链路埋点与告警体系建设,打造更多维度数据看板,提供更精准的监控告警能力;
- 围绕 AgentSDK 建设开放平台,形成可对外输出的能力包。
3.1 AgentSDK 建设:像 NIM 一样标准化 Agent 接入与管理
- NIM Operator 的价值在于把模型服务标准化管理:统一接入、声明式配置、生命周期管理。AgentSDK 要做的本质上是同一件事,只不过管理对象从模型变成了 Agent。
-
具体对照:
- NIM 的注册/配置中心 → AgentSDK 的配置中心与动态注册能力
- NIM 的健康检查/资源管理 → AgentSDK 的鉴权/拦截/观测能力
- Operator 的声明式管理 → AgentSDK 的全生命周期管理(发布/回滚)
- Helm 的参数化部署 → AgentSDK 的统一交互协议(状态/流式/A2A)
-
课程中 Operator + Helm 的组合思路可以直接应用到 AgentSDK 设计上:用配置中心管理 Agent 元数据,用统一协议隔离实现细节,让新 Agent 接入成本降低 ≥70%。
3.2 监控与可观测性:像 Prometheus + Grafana 一样建设 Mirror 指标看板
课程展示的监控体系非常完整:Prometheus 采集指标 → Grafana 可视化 → HPA 自动扩缩容 → Locust 压测验证。这是一个闭环。Mirror 的监控建设可以直接复用这套思路:
应用层指标(类比 Prometheus 服务指标)
- Agent 调用量、响应时延(P50/P95/P99)、错误率
- 各环节耗时分布(需求澄清 → 设计转码 → 代码生成)
- 用户操作路径与转化率
资源层指标(类比 DCGM GPU 指标)
- 沙盒资源占用(CPU、内存、启动时间)
- 模型推理资源消耗(如果有自建推理服务)
- 存储与网络 I/O
可视化与告警(类比 Grafana + HPA)
- 核心业务仪表盘(健康度、成功率、性能分布)
- 基于指标的自动告警与故障定位
- 支持回放与根因分析
- 课程中 Prometheus + DCGM + Grafana 的分层监控思路,正好对应 Mirror 的全链路埋点需求。
3.3 多技术栈接入与工作台升级:像 Helm Chart 一样参数化管理差异
Helm Chart + values.yaml 的设计哲学是:把不变的逻辑抽象成 Chart,把会变的配置放到 values.yaml。不同环境(开发/测试/生产)只需要修改 values.yaml,Chart 本身保持不变。Mirror 的多技术栈接入也应该遵循同样的思路:
不变的部分(平台能力)
- Agent 调度与编排逻辑
- 文件系统与 Git 工作流
- 上下文资产管理
- 监控埋点与告警
可变的部分(技术栈差异)
- 脚手架模板与依赖配置
- 构建工具与编译参数
- 代码规范与 Lint 规则
- 组件库与设计系统
用类似 Helm values.yaml 的方式管理技术栈配置(比如 mirror.config.ts),让新技术栈接入只需要提供配置文件,而不需要修改平台核心代码。这样才能支撑 20+ 技术栈的快速接入目标。
3.4 能力开放与商业化:像 API Catalog 一样低门槛试用 + 私有化部署
NVIDIA 的商业化路径很清晰:
- API Catalog(云端试用):用户可以快速试用各种 NIM 能力,验证方案可行性
- 私有化部署:验证通过后,一键打包部署到客户自己的环境
以下是Mirror商业化路径畅想(非实际):
阶段 1:能力市场(类比 API Catalog)
- 提供在线 Playground,让用户快速试用 Mirror 的各种 Agent 能力
- 降低试用门槛,用 API Key 接入而不是复杂的环境搭建
- 提供示例与文档,展示典型场景的效果
阶段 2:私有化部署(类比 NIM 容器化交付)
- 基于 AgentSDK 的标准化能力,打包成可独立部署的服务
- 提供 Helm Chart 或 Docker Compose,让客户一键部署
- 配套计费/配额/权限/审计等企业级能力
阶段 3:生态开放(类比 Operator 扩展)
- 开放 Agent 注册协议,让第三方开发者可以贡献 Agent
- 建立 Agent 市场,形成生态闭环
课程中"从试用到部署"的产品化路径,为 Mirror 的商业化提供了可参考的范式
四. 总结与展望
NVIDIA 这门课程的价值不在于教你用什么模型,而在于提供了一套完整的 AI 工程化方法论:把 AI 能力从 Demo 变成可交付、可运营、可治理的系统能力。
课程最核心的四个工程化思路:
- 标准化管理(NIM Operator):用声明式配置 + 生命周期管理让 AI 服务可复制、可回滚
- 可观测闭环(Prometheus + Grafana + HPA):监控 + 弹性 + 压测验证,让系统能扛住真实流量
- 参数化隔离(Helm Chart + values.yaml):把不变的逻辑和可变的配置分离,支持快速扩展
- 低门槛试用 + 私有化部署(API Catalog):从试用到交付的完整产品化路径
这四个思路不仅适用于 RAG 系统,对任何想要把 AI 能力工程化的团队都有参考价值。
工程化的本质:
课程中反复强调的一个观点让我印象深刻:"能部署"不等于"能服务","能服务"不等于"能运营"。
从 Demo 到生产的跨越,需要在三个维度持续投入:
- 标准化:让能力可复制、可替换、可回滚
- 可观测:让系统可监控、可调试、可追溯
- 可扩展:让架构能应对流量增长、功能演进、技术迭代
NVIDIA 的工程化实践为这三个维度都提供了清晰的参考路径。对于 Mirror 这样的 AI 工程平台来说,这些方法论可以直接借鉴到 Agent 管理、多技术栈接入、监控体系建设、能力开放等各个方向。
写在最后:
AI 工程化不是一蹴而就的,而是一个持续迭代的过程。从标准化接入、到监控闭环、再到弹性治理,每一步都需要扎实的工程积累。
希望这篇课程总结能为正在做 AI 工程化的团队提供一些启发。让我们一起把 AI 能力从实验室带到生产环境,从 Demo 变成真正可以服务用户的系统。
参考文献与官方资料
课程来源:NVIDIA Deep Learning Institute -《在生产环境大规模部署 RAG 工作流》
NVIDIA / NIM
GPU 监控(DCGM)
K8s 弹性(HPA)与 Prometheus 自定义指标
压测(Locust)
RAG / 工作流与路由(LangChain / Unstructured / LangGraph)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)