一个模型干掉五个模块!UAF 用单个 LLM 统一全双工语音前端
Speech AI · FRONTIER — 第 2 期精读
一个模型干掉五个模块!UAF 用单个 LLM 统一全双工语音前端
📄 原文:UAF: A Unified Audio Front-end LLM for Full-Duplex Speech Interaction
👥 作者:Yadong Li, Guoxin Wu, Haiping Hou, Biye Li
📅 日期:2026-04-21 | 🏷️ 来源:arXiv 2604.19221 (cs.AI / eess.AS)
📌 一句话总结
把 VAD、说话人识别、ASR、轮次检测、问答五个前端任务统一为一个自回归序列预测问题,用单个 LLM 在流式场景下同时输出语音状态和语义内容。
🤔 这篇论文要解决什么问题?
全双工语音交互(Full-Duplex Speech Interaction)要求系统在"听"的同时能"说",像人类对话一样自然。但传统方案是多个独立模块级联——VAD → 说话人识别 → ASR → 轮次检测 → 对话管理,存在严重痛点:
痛点一:错误级联传播。 前一模块的错误会不可逆地传递到下游。比如 VAD 误判导致 ASR 收到错误的音频段,ASR 错误又影响轮次检测,整条链路的可靠性由最弱环节决定。
痛点二:跨任务信息浪费。 各模块独立训练,无法利用任务间的依赖关系。例如说话人身份信息本可以帮助 ASR 在噪声中聚焦目标说话者,但级联架构无法做到这种联合优化。
痛点三:延迟累积。 每个模块都引入处理延迟,累加后很难达到人类感知舒适度(200-500ms)。全双工场景对延迟极其敏感——你不会接受一个反应迟钝半秒以上的"对话伙伴"。
UAF 的切入点:不再级联,而是用一个统一的 LLM 同时完成所有前端感知任务,将多任务重构为一个序列预测问题。
🏗️ 核心方法
整体架构
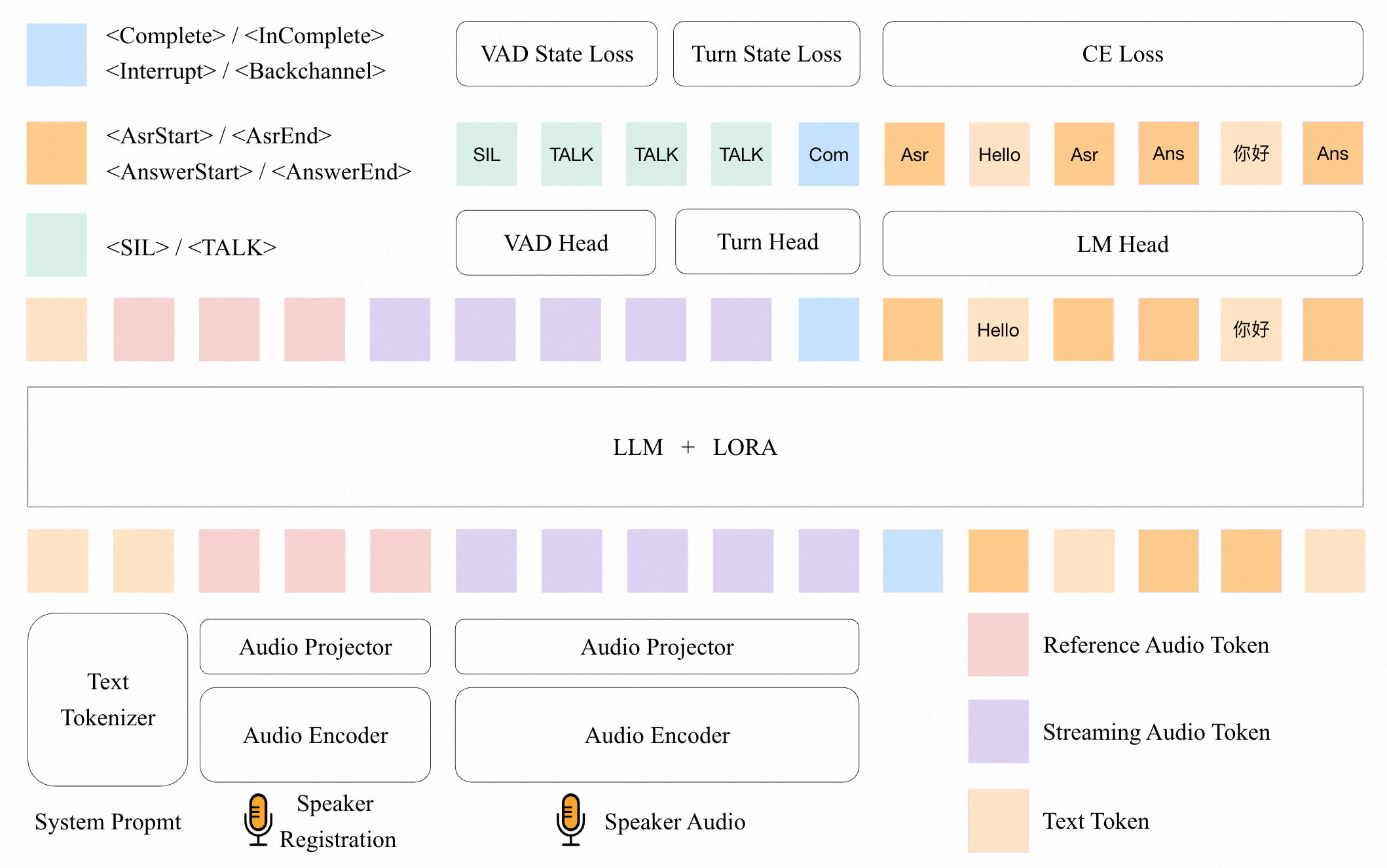
▲ 架构图详解:
UAF 采用 Encoder-Projector-LLM 三段式架构,基于 Qwen3-Omni-30B-A3B 改编。
① 音频编码器(Audio Encoder):接收原始波形,将其转换为高维声学特征表示。论文采用流式处理方式,每次输入固定 600ms 音频块,适配全双工场景的实时性要求。
② 音频投影器(Audio Projector):将编码器输出的声学特征映射到 LLM 的语义嵌入空间。这是跨模态对齐的关键桥梁,使得 LLM 能够"理解"音频信号。
③ 参考音频提示(Reference Audio Prompt):输入 3-5 秒目标说话者的参考音频,作为说话者锚定。这使模型在多人说话 + 噪声的复杂场景下,能聚焦目标说话者并抑制干扰。
④ LLM 骨干 + 扩展词表:基于 Qwen3-Omni-30B-A3B(MoE 架构,30B 总参数,3B 激活参数),扩展词表加入两类特殊 token:VAD 状态 token [<SIL>, <TALK>] 和轮次状态 token [<Complete>, <InComplete>, <Interrupt>, <Backchannel>]。通过 LoRA 微调,避免灾难性遗忘。
⑤ 多头输出设计:VAD Head 从 LM Head 初始化,独立输出 VAD 状态;Turn Head 输出轮次检测结果;LM Head 输出 ASR 转录和 QA 回答。三个 Head 共享 LLM 的隐状态,实现信息共享。
⑥ 数据流路径:流式音频块(600ms)→ Audio Encoder → Audio Projector → [与参考音频嵌入拼接] → LLM → 同时输出 VAD 状态 + 轮次状态 + ASR/QA 文本 token。
关键技术点
技术点一:多任务统一为序列预测
传统做法是每个任务一个模型。UAF 将 5 个任务(VAD、Speaker Recognition、ASR、Turn-taking Detection、QA)重构为统一的自回归序列预测:模型对每个 600ms 音频块,依次预测 VAD token → 轮次 token → 语义 token。
为什么有效:所有任务共享同一个 LLM 的上下文表征,天然实现了跨任务信息流动。例如,说话人识别的信息直接帮助 ASR 在噪声中聚焦目标说话者。
与已有方法的区别:Qwen3-Omni 等模型虽然也是多模态 LLM,但它们并未专门设计前端感知能力(VAD、轮次检测),在全双工场景下表现不佳。
技术点二:三阶段渐进式训练
| 阶段 | 任务 | 数据量 | 策略 |
|---|---|---|---|
| Stage I | VAD + SR + ASR | 6000 小时 | LoRA 微调,学习率 1e-4,VAD Head 从 LM Head 初始化 |
| Stage II | 新增 TD + QA | 1000 小时新 + 1000 小时保留 | 冻结 LLM 和编码器,仅训练 Turn Head + LoRA |
| Stage III | 全任务联合 | 多轮对话数据 | 联合微调所有可训练模块 |
为什么分三阶段:Stage I 先建立基础感知能力;Stage II 在不破坏已有能力的前提下新增轮次检测和 QA;Stage III 用真实对话场景做联合对齐。冻结策略有效防止了灾难性遗忘。
技术点三:全双工交互数据合成
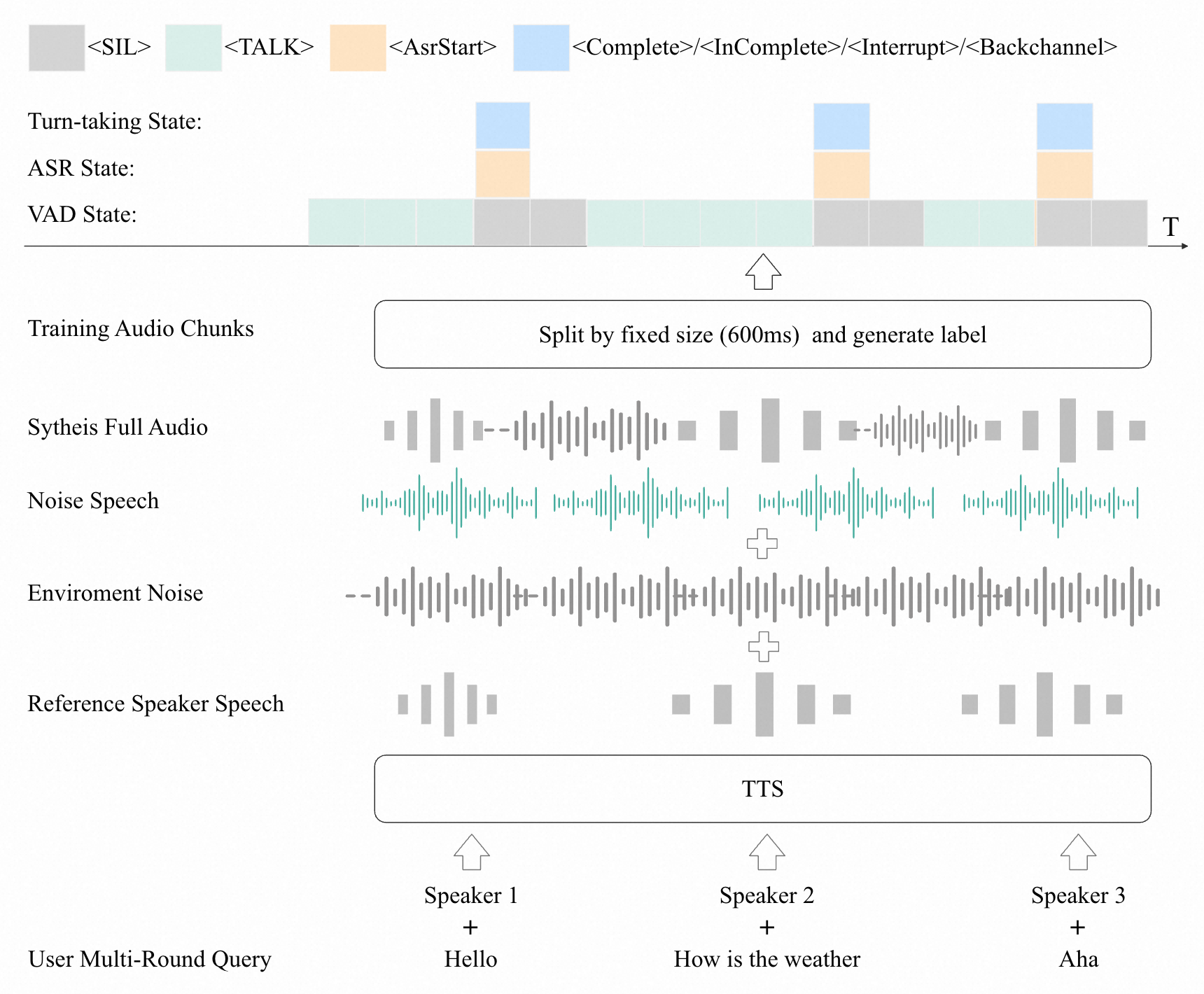
▲ 数据合成管道详解:
论文构建了一套完整的合成数据管道来模拟真实全双工交互场景:
合成数据规模:合计 7000 小时 VAD 训练样本、1000 小时带轮次状态标注数据、50k+ QA 训练样本。
噪声模拟:在 0-20dB SNR 范围内添加随机噪声,模拟真实嘈杂环境。还加入系统回放音(system playback),模拟全双工场景下"自己的声音"对麦克风的干扰——这是全双工特有的挑战。
多说话者合成:将多个说话者的音频混合,配合参考音频提示训练模型的说话者分离能力。
📊 实验结果
VAD 性能对比
| 模型 | F1 | 召回率 | 准确率 |
|---|---|---|---|
| Silero-VAD | 97.48% | 96.81% | — |
| TEN-VAD | 97.09% | — | — |
| UAF-30B-A3B | 97.57% | 97.99% | 92.31% |
📌 关键数据:UAF 在 F1 指标上达到 97.57%,超越专用 VAD 模型 Silero-VAD 和 TEN-VAD。
说话者感知 ASR(噪声鲁棒性)
| SNR 条件 | UAF | Qwen3-Omni-30B-A3B | 相对改进 |
|---|---|---|---|
| 2dB | 5.34 WER | 38.6 WER | 7.2x |
| 随机 0-10dB | 3.09 WER | 68.01 WER | 22x |
| 干净 | 1.41 WER | 1.34 WER | 持平 |
📌 关键数据:在极端噪声条件(2dB SNR)下,UAF 的 WER 仅 5.34%,而基线 Qwen3-Omni 高达 38.6%——参考音频提示 + 统一建模带来 7 倍性能提升。
轮次检测准确率
| 轮次类型 | UAF | Qwen3-Omni |
|---|---|---|
| Complete(说完了) | 96.48% | 75% |
| Interrupt(被打断) | 100% | 99% |
| Backchannel(嗯、哦) | 95.7% | 28% |
📌 关键数据:Backchannel 检测从 Qwen3-Omni 的 28% 提升到 95.7%,这对全双工自然交互至关重要——系统不再把"嗯、哦"误判为发言结束。
消融实验亮点
模型规模消融:30B-A3B 在 2dB SNR 下 WER 5.34,7B 为 15.03,3B 为 38.24。规模对噪声鲁棒性影响显著。
LoRA vs 全参数微调:在 AISHELL-1 上差异仅 < 0.1 WER,低 SNR 条件下差异 0.08 WER。LoRA 几乎无损,同时保留了原始模型能力。
💡 个人点评
优势:
- 首次将全双工前端的所有感知任务统一到一个 LLM 中,思路优雅。跨任务信息共享是最大价值——尤其是说话者锚定 + ASR 联合,在噪声场景下效果惊人(7 倍提升)。
局限:
- 30B-A3B 的模型规模对端侧部署仍然偏大。消融实验显示 3B 模型在噪声下性能急剧退化,说明这种方法对模型容量依赖很强。600ms 的音频块大小也意味着最少 600ms 的初始延迟。
工程价值:
- 三阶段训练 + LoRA 的策略非常实用,可以直接复用到其他多任务语音 LLM 场景。数据合成管道(噪声混合 + 系统回放模拟)对全双工产品开发有直接参考价值。
未来方向:
- 模型蒸馏到更小规模(7B 以下)、音频块大小自适应(低延迟场景用更短块)、多语言扩展。
🔗 资源链接
- 📄 论文链接:arxiv.org/abs/2604.19221
- 🎯 相关论文推荐:
- Qwen3-Omni — 多模态大模型(arxiv.org/abs/2503.20215)
- VITA — 实时交互视觉语言模型(arxiv.org/abs/2408.05211)
- FunASR — 工业级语音识别工具包(github.com/modelscope/FunASR)
Speech AI · FRONTIER · 论文精读系列
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文解读与技术点评由作者完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)