FLUX.1架构的理解8——模型、工具、架构图解
一、前言
仅供参考,未经实验验证。参考资料:
Demystifying Flux Architecture
论文地址:https://arxiv.org/pdf/2507.09595
3 模型与工具
3.1 文本到图像
FLUX.1 系列文本到图像模型包含三个变体,它们共享相同的 12B 参数架构,在可访问性和模型能力之间取得了平衡 [18]。
FLUX.1[pro] 这是 FLUX.1 系列中性能最高的变体,在提示词对齐、视觉细节和输出多样性方面均表现出色。它专为商业用途而设计,仅可通过 Replicate 或 Fal.ai 等授权的 API 端点访问。模型权重未公开,因此它是一个仅托管的解决方案。此版本非常适合对图像生成质量有最高要求且商业许可可行的生产环境。
FLUX.1[dev] 提供了一个开放权重版本,该版本通过指导蒸馏 [26] 自 Pro 版本而来。它仅限于非商业用途,使得研究人员、开发者和爱好者能够进行实验和学术研究。与 Pro 版本不同,Dev 版本可以本地下载和运行,为非商业应用提供了完全的控制和灵活性。FLUX.1 [dev] 模型可通过 huggingface 获取,也可直接在 Replicate 或 fal.ai 上试用。需要注意的是,Dev 版本可能需要比 Pro 版本更多的采样步数才能达到高级性能。
• FLUX.1[schnell] 是 FLUX.1 Pro 的一个速度优化、蒸馏版本,旨在显著减少推理时间同时保持合理的图像质量。它共享相同的 12B 架构,但通过时间步蒸馏 [27] 从 Pro 模型进行训练,这意味着它通过优化速度和效率,学习在更少的采样步数(最多一步)内模仿 Pro 的输出。这以牺牲部分提示保真度和精细细节为代价,实现了更快的生成速度。Schnell 在宽松的 Apache 2.0 许可下发布,允许无限制的商业用途,使其成为实时、低延迟应用和轻量级部署的理想选择,在这些场景下速度和开放许可比最高视觉保真度更重要。
• FLUX1.1[pro]是FLUX.1[pro]模型的增强版本,能够更快地生成图像,同时提高图像质量、提示遵循度和多样性。该模型引入了新模式——Ultra,可在不影响速度的情况下实现4倍分辨率;Raw模式则能生成超写实、抓拍风格的图像。此外,提示上采样功能利用大型语言模型(LLMs)扩展和丰富用户提示,增强创意输出。虽然本报告未涵盖,但FLUX 1.1 Pro可通过Replicate和Fal.ai等平台的API访问,但需要商业许可。
3.2 工具
FLUX.1 最初是为文本到图像生成而开发的,此后 Black Forest Labs 公司对其进行了扩展,提供了一套支持多种用例的工具,超出了其最初的用途。本报告并未像对 FLUX.1 模型本身那样深入探讨每一个工具。
• FLUX-Fill 是一种图像修复和图像外延模型,它能够根据文本描述和二值掩码对真实图像和生成图像进行编辑和扩展。
• FLUX-Canny 能够基于从输入图像和文本提示中提取的 Canny 边缘来实现结构化引导。
• FLUX-Depth 依据从输入图像提取的深度图和文本提示来实现结构化引导。
• FLUX-Redux 是一个适配器,它将 SigLIP 图像编码器 [28] 提取的密集(每 token)图像嵌入与 T5 文本嵌入空间对齐,以便使用预训练的 FLUX.1 基础模型进行图像条件生成。虽然在开发版本中对图像变化有限制,但它集成了更复杂的工作流程,在结合使用 FLUX1.1 [pro] Ultra 模型时,通过提示实现图像重塑,从而能够组合输入图像和文本提示。
•FLUX-Kontext 将基础 FLUX 模型文本到图像的能力扩展到强大的上下文生成和编辑工作流,通过实现多模态条件控制——允许用户使用文本和参考图像来指导生成。虽然 FLUX-Redux 已经为图像变体和提示驱动的风格重塑引入了基本的多模态条件控制,但 FLUX-Kontext 实现了更高级的功能,例如局部编辑、风格迁移以及跨图像的角色或场景一致性。通过 Kontext [pro] 和 [max] 等模型,重点转向了快速、迭代的生成和高精度编辑。
FLUX.1高层架构解析(图4):
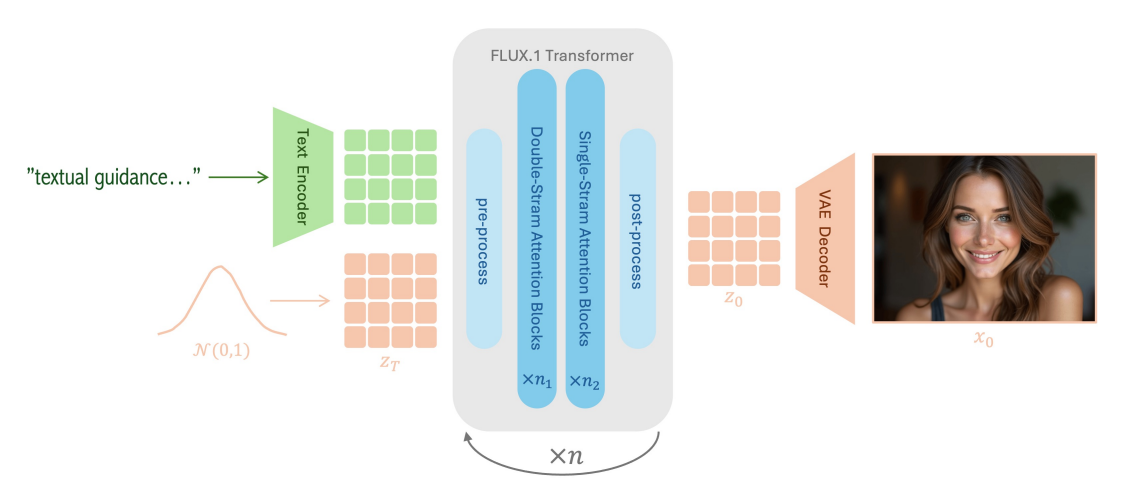
这张图(图 4)为我们清晰地展示了 FLUX.1 模型进行文本到图像生成的高层架构。它的核心目的是将用户提供的文本描述(“textual guidance…”)转化为高质量、与文本高度对齐的图像( X 0 X_0 X0)。
整个生成过程可以理解为一个迭代精炼的流程,其中文本信息和图像的初始噪声表示在潜在空间中不断相互作用,最终生成清晰的图像。
接下来,我们按照图中的流程,从左到右、从上到下详细解析每个关键模块的功能和它们之间的协作关系:
1. 输入阶段
FLUX.1 模型接收两种主要输入:
-
文本指导 (“textual guidance…”):
- 这代表了用户输入的文本提示(prompt),它描述了期望生成的图像内容和风格。
- 例如:“一只穿着宇航服的猫在月球上”。
-
初始噪声 ( N ( 0 , 1 ) N(0,1) N(0,1)):
- 这通常是一个从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1) 中采样的纯高斯噪声。
- 在扩散模型和整流流(Rectified Flow)框架中,图像生成过程通常从随机噪声开始,然后逐步将其“去噪”或“转换”成有意义的图像。
2. 编码器与潜在表示
-
文本编码器 (Text Encoder):
- 接收用户的文本指导,并将其转换为高维的文本嵌入 (Text Embeddings)。
- 这些嵌入捕捉了文本的语义信息,是模型理解用户意图的关键。
- 根据论文,FLUX.1 使用了 CLIP Text Encoder 和 T5 Text Encoder 两种预训练编码器。CLIP 编码器提供全局的池化嵌入,T5 编码器提供更细粒度的、基于 token 的密集嵌入,两者共同为 Transformer 提供丰富的文本上下文信息。
-
潜在图像嵌入 ( Z t Z_t Zt):
- 初始高斯噪声 N ( 0 , 1 ) N(0,1) N(0,1) 被转化为潜在图像嵌入 Z t Z_t Zt。
- FLUX.1 类似于 Stable Diffusion (LDM) 的设计,在潜在空间 (latent space) 中进行大部分计算,而不是直接在像素空间操作。这样做可以显著提高计算效率,同时保持图像质量。初始的噪声 N ( 0 , 1 ) N(0,1) N(0,1) 实际上是作为噪声的潜在表示。
3. FLUX.1 Transformer (核心迭代精炼模块)
这是整个架构的心脏,负责将文本嵌入和潜在图像嵌入进行迭代处理,逐步将噪声转化为有意义的图像特征。
-
预处理 (pre-process):
- 在每次迭代开始之前,Transformer 会对输入进行预处理。这包括将文本嵌入和潜在图像嵌入调整到统一的维度,并生成引导嵌入 (Guiding Embeds / temb) 和位置嵌入 (Pos Embeds)。
- 引导嵌入 (
temb):结合了当前迭代的时间步(timestep)信息和 CLIP 模型的池化提示嵌入。这使得模型能够理解当前处于去噪过程的哪个阶段,并根据文本提示调整生成方向。 - 位置嵌入 (
Pos Embeds):从img_ids和text_ids中提取,使用旋转位置嵌入(RoPE)方法,为图像和文本 token 提供空间和序列位置信息。
-
注意力块序列 (Series of Attention Blocks):
- FLUX.1 Transformer 内部包含一系列双流注意力块 (Double-Stream Attention Blocks) 和单流注意力块 (Single-Stream Attention Blocks)。
- 双流注意力块 (Double-Stream Attention Blocks):
- 这些块对图像 token 和文本 token 使用独立的权重进行处理。
- 它们通过多模态注意力机制(在拼接后的 token 上执行注意力)实现图像和文本之间的双向交互,但内部的归一化和前馈层是顺序应用的,并且对不同模态使用不同的参数。这允许模型针对不同模态进行专业化处理,提供更强的表达能力。
- 图中标记为 “ × 19 \times 19 ×19”,表示有 19 个这样的块。
- 单流注意力块 (Single-Stream Attention Blocks):
- 这些块对图像 token 和文本 token 使用共享的权重进行处理。
- 与双流块不同,单流块中的注意力层和前馈层是并行计算的。这种设计更注重效率和参数共享,有助于模型在不同模态之间建立更紧密的联系,提高泛化能力。
- 图中标记为 “ × 38 \times 38 ×38”,表示有 38 个这样的块。
- 多模态注意力:这两种注意力块都采用了多模态注意力机制,能够同时处理拼接后的图像和文本 token,捕捉它们之间的复杂关系。
- 迭代处理 (Iteratively Processed):图中的循环箭头 “ X N X_N XN” 表示这些注意力块对潜在图像嵌入和文本嵌入进行多次迭代处理。在每次迭代中,模型会根据当前的潜在状态 ( Z t Z_t Zt)、时间步和文本指导,预测一个“速度向量”(在整流流中),然后更新潜在图像嵌入,使其更接近最终的清晰图像。
-
后处理 (post-process):
- 在 Transformer 完成所有迭代和注意力块的处理后,输出的潜在表示会经过最终的后处理步骤,得到精炼后的干净潜在表示 Z 0 Z_0 Z0。
4. 解码与最终输出
-
VAE 解码器 (VAE Decoder):
- 接收 Transformer 输出的精炼潜在表示 Z 0 Z_0 Z0。
- 这是一个预训练的变分自编码器(VAE)的解码器部分,其作用是将低维的潜在空间表示解码回高维的像素空间。
- 这一步将抽象的图像特征转化为我们能看到的具体像素图像。
-
最终图像 ( X 0 X_0 X0):
- 经过 VAE 解码器后,最终得到与文本描述相符的高质量像素图像 X 0 X_0 X0。
总结与核心设计理念
FLUX.1 的高层架构体现了以下几个关键设计理念:
- 潜在空间操作 (Latent Space Operation):通过在压缩的潜在空间中进行大部分计算,显著提高了图像生成的速度和效率,同时保持了视觉质量。
- Transformer 作为核心骨干 (Transformer Backbone):放弃了传统的 U-Net 结构,转而采用全 Transformer 架构进行去噪过程,这提升了模型的扩展性和上下文建模能力,尤其在处理长距离依赖方面表现更优。
- 整流流训练范式 (Rectified Flow Training Paradigm):虽然图中未直接显示训练细节,但论文明确指出 FLUX.1 是基于整流流训练的。这意味着它通过学习一个确定性的速度向量来将噪声直接映射到数据,简化了传统的随机扩散过程,实现了更快、更稳定的图像合成。
- 多模态深度融合 (Deep Multi-modal Fusion):通过结合双流和单流两种注意力块,模型能够在不同的抽象层次上对文本和图像信息进行深度融合。双流块允许模态间的专业化处理,而单流块则促进了更紧密的模态间集成和效率。
- 迭代精炼 (Iterative Refinement):图像生成不是一步到位的,而是通过 Transformer 的多次迭代,逐步将初始噪声精炼为与文本高度一致的清晰图像。
通过这些精心设计的模块和流程,FLUX.1 实现了在文本到图像生成任务中的最先进性能,尤其在图像质量、文本对齐、风格多样性和场景复杂度方面表现突出。
Flux.1 采样流程解析(图5):
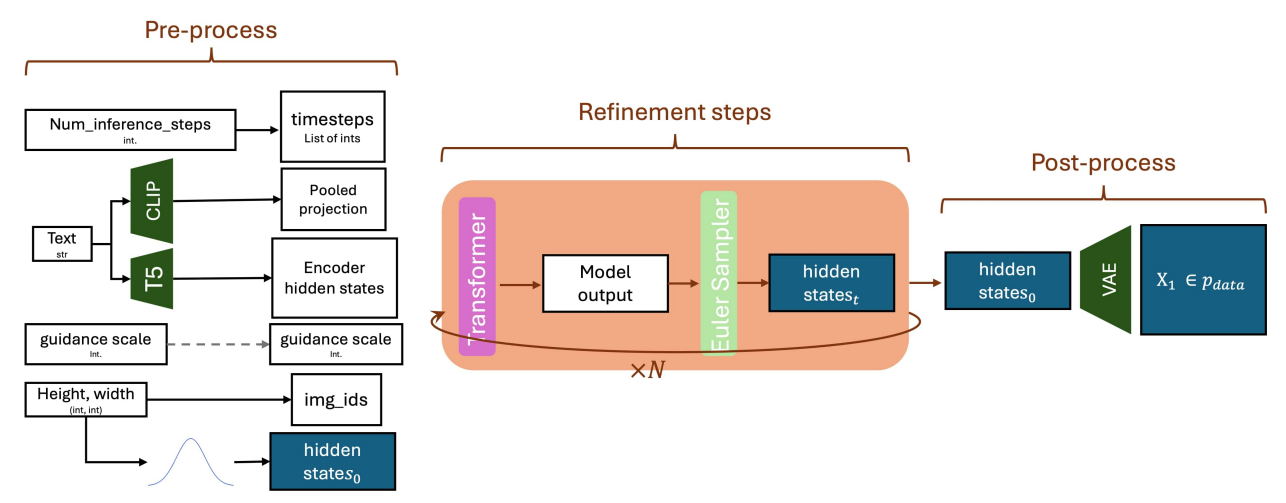
总体目的:
图 5 详尽地展示了 FLUX.1 模型从用户输入(文本提示、生成参数)到最终输出(高质量图像)的完整生成流程,这被称为“采样流程”。它清晰地分为三个主要阶段:预处理 (Pre-process)、迭代精炼 (Refinement steps) 和 后处理 (Post-process)。其核心思想与扩散模型类似,即在潜在空间中对初始的随机噪声进行迭代精炼,最终通过解码器生成清晰的图像。
流程分步拆解:
1. 预处理阶段 (Pre-process)
此阶段的目标是接收用户输入的各种参数和文本提示,并将其转化为 Transformer 模型所需的标准化潜在表示和控制信号。
-
输入项及其转化:
num_inference_steps(整数):这是用户指定总共进行多少次迭代采样步骤。它被转化为一个timesteps(时间步列表),这个列表定义了在迭代精炼过程中,模型将关注的特定时间点。Text(字符串):用户输入的文本提示,是生成图像的语义指导。- 它被送入两个预训练的文本编码器:
- CLIP:产生
Pooled projection(池化投影),这是一个单一的、全局的文本嵌入,捕捉整个提示的整体语义。 - T5:产生
Encoder hidden states(编码器隐藏状态),这是基于每个词元(token)的密集嵌入,提供了更细粒度的文本语义信息。
- CLIP:产生
- 它被送入两个预训练的文本编码器:
guidance_scale(浮点数):控制文本提示对图像生成的影响强度。它直接作为guidance_scale信号传递。Height, width(整数对):指定期望生成图像的空间分辨率(高度和宽度)。- 它被用于生成
img_ids(图像 ID),这是一个表示潜在图像空间中每个位置的标识符,包含了位置信息,以便 Transformer 理解图像的空间结构。
- 它被用于生成
- 初始噪声源 (蓝色波浪线,代表 N ( 0 , 1 ) N(0,1) N(0,1)):代表从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1) 采样的纯高斯噪声。
- 这个噪声被转化为
hidden_state_0(隐藏状态 z 0 z_0 z0),这是在潜在空间中表示的初始随机图像,作为迭代精炼的起点。
- 这个噪声被转化为
-
预处理阶段输出汇总:
经过预处理后,模型准备好了以下输入,供后续的 Transformer 使用:timestepsPooled projectionEncoder hidden statesguidance_scaleimg_idshidden_state_0(初始噪声的潜在表示,在迭代中通常写作 z t z_t zt)
2. 迭代精炼阶段 (Refinement steps)
这是 FLUX.1 采样的核心,通过一个 Transformer 模型的多次迭代,将初始噪声潜在表示逐步转化为清晰的图像潜在表示。
-
核心组件:
- Transformer (紫色方块):这是 FLUX.1 的主要生成模型,它是一个基于 Transformer 的架构(如论文 2.3 节所述,包含双流和单流注意力块)。
- 输入:在每次迭代中,Transformer 接收当前的潜在图像表示 ( z t z_t zt,图中用
hidden_state_t表示),以及预处理阶段得到的各种文本和控制信号(如timesteps、Pooled projection、Encoder hidden states、guidance_scale、img_ids等)。 - 功能:Transformer 模型预测一个“速度向量” v θ ( z t , t , Φ ) v_\theta(z_t, t, \Phi) vθ(zt,t,Φ),其中 z t z_t zt 是当前带噪的潜在表示, t t t 是当前时间步, Φ \Phi Φ 是所有文本和控制嵌入的集合。这个速度向量指示了如何将 z t z_t zt 推向一个更清晰的图像。
Model output(模型输出):Transformer 的输出就是这个预测的速度向量。
- 输入:在每次迭代中,Transformer 接收当前的潜在图像表示 ( z t z_t zt,图中用
- Euler Sampler (绿色方块):这是一个采样器,根据 Transformer 预测的速度向量,更新当前的潜在图像表示。
- 功能:它使用欧拉方法(Flow-Matching Euler Discrete sampler)来更新潜在状态,从 z t z_t zt 计算出下一个时间步的潜在状态 z t + Δ t z_{t+\Delta t} zt+Δt。
- 更新公式为: z t + Δ t = Samp ( v θ ( z t , t , Φ ) ) z_{t+\Delta t} = \text{Samp}(v_\theta(z_t, t, \Phi)) zt+Δt=Samp(vθ(zt,t,Φ)),其中 Samp ( ⋅ ) \text{Samp}(\cdot) Samp(⋅) 表示采样操作。
hidden_state_t(隐藏状态 z t z_t zt):代表当前迭代的潜在图像表示。- 在每次迭代开始时,它是一个带噪的图像潜在表示。
- Transformer 接收它,并预测如何去噪。
- Euler Sampler 根据预测结果更新它,生成下一个时间步的更清晰的
hidden_state_t。
- Transformer (紫色方块):这是 FLUX.1 的主要生成模型,它是一个基于 Transformer 的架构(如论文 2.3 节所述,包含双流和单流注意力块)。
-
迭代循环 (
×N):- 图中的循环箭头和
×N标记表明,Transformer 和 Euler Sampler 的组合会重复执行N次(N由num_inference_steps决定)。 - 在每次循环中,
hidden_state_t都会被逐步去噪和精炼。这个过程从初始的纯噪声 z 0 z_0 z0 开始,逐步向最终的干净图像 z 1 z_1 z1 演进。
- 图中的循环箭头和
-
迭代精炼阶段输出:
经过N次迭代后,hidden_state_t会演变为最终的精炼潜在表示hidden_state_0(通常表示为 z 1 z_1 z1),它代表了一个接近于目标图像的干净潜在编码。
3. 后处理阶段 (Post-process)
此阶段将精炼后的潜在表示转换回人眼可识别的像素图像。
- 核心组件:
hidden_state_0( z 1 z_1 z1):这是迭代精炼阶段的最终输出,一个高度精炼的潜在图像表示。- VAE Decoder (绿色梯形):这是一个预训练的变分自编码器(VAE)的解码器部分。
- 功能:它接收来自 Transformer 的最终潜在表示
hidden_state_0,并将其解码(上采样)回高维的像素空间。
- 功能:它接收来自 Transformer 的最终潜在表示
- X 1 ∈ P d a t a X_1 \in P_{data} X1∈Pdata (最终图像 x 1 x_1 x1):VAE 解码器的输出就是最终生成的 RGB 图像 x 1 x_1 x1,它属于原始数据分布 P d a t a P_{data} Pdata。
关键信息与设计原理:
- 潜在空间优势:FLUX.1 沿用了潜在扩散模型(LDM)的思路,在低维度的潜在空间进行大部分计算。这大大降低了计算成本,尤其是在生成高分辨率图像时,同时通过 VAE 保持了视觉细节。
- Transformer 骨干:模型的核心去噪网络是一个全 Transformer 架构,而非传统的 U-Net。这使得模型能更好地捕捉图像和文本之间的长距离依赖关系,增强了上下文理解和生成质量。
- 多编码器文本指导:同时使用 CLIP 和 T5 文本编码器,FLUX.1 能够从文本提示中提取不同粒度的语义信息(全局概念与局部词元细节),从而实现更精确的文本-图像对齐和对复杂提示的理解。
- 整流流范式:虽然图中未直接体现训练过程,但论文指出 FLUX.1 采用整流流(Rectified Flow)进行训练。这意味着模型学习一个确定性的“速度向量”,直接将噪声潜在表示转换为数据潜在表示,相比传统扩散模型中的随机去噪过程,通常能实现更快、更稳定的采样。
- 迭代精炼:通过多次迭代循环,模型逐步“雕刻”出图像。每次迭代都会根据文本指导和时间步信息,对潜在表示进行微调,使其离最终目标图像更近。
guidance_scale的作用:这个参数在预处理阶段就被提取出来,并在Transformer的内部预处理中(通过引导嵌入temb)影响模型的行为,它允许用户在生成质量和对提示的遵循度之间进行权衡。较高的guidance_scale会使生成图像更严格地遵循文本提示,但可能牺牲一些多样性和自然度。
这个采样流程展示了 FLUX.1 如何将复杂的文本描述转化为视觉内容,其模块化的设计和多模态信息的深度融合是其实现最先进性能的关键。
Flux Transformer 架构概览解析(图6):
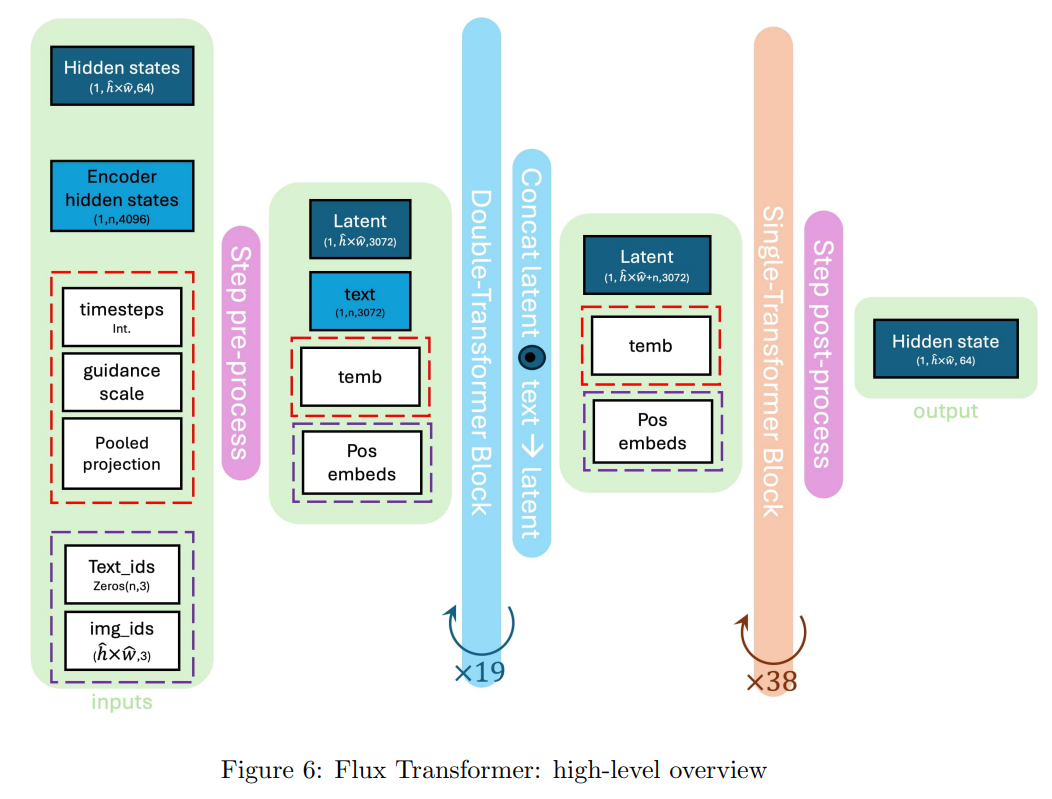
总体目的:
图 6 提供的是 FLUX.1 模型核心组件——Transformer 在每次采样迭代中的高层工作流程概览。它展示了文本嵌入和潜在图像嵌入是如何通过一系列注意力块(Transformer Blocks)进行迭代处理,最终生成文本条件下的图像的。这与图 5 所示的整个采样流程中的“迭代精炼阶段”紧密相关,图 6 聚焦于该阶段内部 Transformer 的具体操作。
流程分步拆解:
整个 Transformer 流程可以分解为三个主要阶段:迭代预处理 (Step pre-process)、双流 Transformer 块 (Double-Stream Transformer Block)、单流 Transformer 块 (Single-Stream Transformer Block) 和 迭代后处理 (Step post-process)。
1. 输入与迭代预处理阶段 (Inputs & Step pre-process)
此阶段的目标是将来自外部和上一次迭代的各种输入,转化为 Transformer 块所需的统一格式和特征表示。
-
核心输入项:
Hidden states (1, hxw, 64)(深蓝色方块):这代表了当前迭代的潜在图像表示(即 z t z_t zt),它是一个经过噪声处理或部分去噪的图像编码。其维度(1, hxw, 64)表示批次大小为 1,空间维度为h乘w,每个位置有 64 个特征。Encoder hidden states (1, n, 4096)(蓝色方块):这代表了从 T5 文本编码器获得的密集(per-token)文本嵌入。n是文本词元(token)的数量,每个词元有 4096 个特征。timesteps (Int.)(红色虚线框内):当前采样的时间步,一个整数值。guidance scale(红色虚线框内):控制文本引导强度的标量参数。Pooled projection(红色虚线框内):从 CLIP 文本编码器获得的池化(全局)文本嵌入,代表整个文本提示的整体语义。Text_ids (Zeros(n,3))(紫色虚线框内):用于文本词元的位置编码。img_ids (hxw,3)(紫色虚线框内):用于潜在图像空间中每个位置的标识符,包含了空间位置信息。
-
迭代预处理 (Step pre-process) 的功能:
这个紫色方块代表了 Transformer 内部的预处理步骤(对应论文 2.3.1 节和图 7)。它将上述原始输入转化为 Transformer 块可以直接使用的标准化嵌入:- 维度统一:
Hidden states和Encoder hidden states会通过各自的线性层被投影到共享的特征维度3072。Hidden states (1, hxw, 64)→ \rightarrow →Latent (1, hxw, 3072)Encoder hidden states (1, n, 4096)→ \rightarrow →text (1, n, 3072)
- 引导嵌入 (
temb) 的生成:timesteps、guidance scale和Pooled projection会被组合并投影,生成一个统一的引导嵌入temb (1, 3072)。这个temb包含了时间信息和全局文本引导信息,用于调节 Transformer 块的行为。 - 位置嵌入 (
Pos embeds) 的生成:Text_ids和img_ids会被用于生成位置嵌入Pos embeds (hxw+n, 128)。这些嵌入结合了文本和图像的空间/序列位置信息,并通过旋转位置编码(RoPE)注入到注意力机制中。
- 维度统一:
2. 双流 Transformer 块 (Double-Stream Transformer Block)
- 输入:
Latent (1, hxw, 3072)、text (1, n, 3072)、temb (1, 3072)、Pos embeds (hxw+n, 128)。 - 功能和设计原理 (蓝色块,循环 19 次):
- 多模态处理:这个阶段由 19 个连续的“双流 Transformer 块”组成。这些块采用分离的权重来处理图像(
Latent)和文本(text)词元。 - 信息交互:尽管是“双流”,但它通过多模态注意力机制实现文本和图像之间的双向信息交互。这意味着在注意力计算中,图像查询可以关注文本键值,文本查询也可以关注图像键值,从而实现跨模态的理解和对齐。
- 计算风格:双流块采用顺序计算风格。注意力层和前馈网络 (MLP) 是依次应用的,注意力层的输出作为 MLP 的输入。这使得每一层都能在前一层的基础上进行更深度的信息处理,有利于捕获复杂的依赖关系和表达能力。
- AdaLN (Adaptive Layer Normalization):每个流内部(图像和文本)都使用 AdaLN 层来标准化和调制中间激活。AdaLN 能够根据外部的
temb引导嵌入动态生成缩放和平移参数,从而让模型行为适应当前的时间步和文本引导。 - RoPE (Rotary Positional Embeddings):位置嵌入
Pos embeds在此阶段被用于旋转查询(Q)和键(K)向量,以注入位置信息,帮助模型理解空间和序列关系。
- 多模态处理:这个阶段由 19 个连续的“双流 Transformer 块”组成。这些块采用分离的权重来处理图像(
- 输出: 经过 19 个双流块后,
Latent和text嵌入被精炼,并准备好进入下一个阶段。
3. 潜在-文本拼接与单流 Transformer 块 (Concat latent + text -> latent & Single-Transformer Block)
- 拼接 (
Concat latent + text -> latent):- 在进入单流块之前,精炼后的潜在图像嵌入 (
Latent) 和文本嵌入 (text) 会被拼接 (concatenate) 起来,形成一个统一的张量。 - 拼接后的张量维度变为
(1, hxw+n, 3072),其中hxw是图像词元数,n是文本词元数。
- 在进入单流块之前,精炼后的潜在图像嵌入 (
- 单流 Transformer 块 (橙色块,循环 38 次):
- 输入: 拼接后的潜在-文本张量、
temb (1, 3072)、Pos embeds (hxw+n, 128)。 - 功能和设计原理:
- 共享权重:这个阶段由 38 个连续的“单流 Transformer 块”组成。与双流块不同,单流块对拼接后的图像和文本词元使用单一的、共享的权重集。这提高了参数效率,并促进了模态之间更紧密的集成。
- 计算风格:单流块采用并行计算风格。注意力层和前馈网络 (MLP) 是同时从相同的输入中计算的,它们的输出随后被合并。这提高了计算效率和每个块的表示容量,但可能限制了层间交互的深度。
- AdaLN 与 RoPE:同样,
temb通过 AdaLN 调节共享层的行为,Pos embeds通过 RoPE 注入位置信息。
- 输入: 拼接后的潜在-文本张量、
- 输出: 经过 38 个单流块后,拼接的潜在-文本张量被进一步精炼。
4. 迭代后处理与输出 (Step post-process & Output)
- 迭代后处理 (Step post-process):
- 这个紫色方块代表了 Transformer 内部的最终处理步骤。
- 它将经过单流 Transformer 块精炼后的拼接张量,再次分离为图像和文本的潜在表示。
- 然后,它会从图像部分提取出最终的去噪预测。
- 输出 (
Hidden state (1, hxw, 64)):- Transformer 的最终输出是一个维度为
(1, hxw, 64)的Hidden state。这代表了在当前迭代中,模型对潜在图像的去噪预测或速度向量(在整流流中)。 - 这个输出随后会被送回 Euler Sampler(如图 5 所示),用于更新 z t z_t zt 到 z t + Δ t z_{t+\Delta t} zt+Δt,从而在下一个迭代中继续精炼。
- Transformer 的最终输出是一个维度为
关键信息与设计原理总结:
- 分阶段多模态融合:FLUX.1 采用“双流”和“单流”两种 Transformer 块的组合。
- 双流块(19 个):侧重于专业化和表达力,使用独立权重处理图像和文本,并进行顺序计算,允许更深度的层间交互,以捕捉复杂的跨模态关系。
- 单流块(38 个):侧重于效率和集成,使用共享权重和并行计算,减少参数量并加速处理,同时促进模态间的紧密融合。
- 这种组合可能旨在平衡模型在处理复杂语义和保持计算效率方面的需求。
- Transformer 作为核心:FLUX.1 摒弃了传统的 U-Net,完全采用 Transformer 架构作为去噪骨干网络。这使得模型能够更好地处理长距离依赖,增强了对图像和文本之间复杂关系的理解能力。
- 多维度条件注入:通过
temb(时间步、引导尺度、全局文本)和Pos embeds(文本和图像位置),模型能够全面地接收和整合各种条件信息,精确控制图像生成过程。 - AdaLN 的作用:通过自适应层归一化,模型能够动态地调整其内部行为,以响应不同的时间步和文本引导强度,从而提高生成质量和稳定性。
- RoPE 的引入:旋转位置嵌入使得模型能够更好地理解和泛化不同序列长度下的空间和序列关系,尤其是在将文本位置概念“重用”于图像块时。
这张图清晰地揭示了 FLUX.1 Transformer 如何在潜在空间中,通过精巧设计的多模态注意力机制和分阶段处理,将文本指导高效地转化为图像的潜在表示,从而实现高质量的文本到图像生成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0


 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)