【智能制造】-工业AI成功4大关键要素,超越大模型本身
·
在智能制造转型的浪潮中,多数企业将注意力集中于大模型的参数规模与算力投入,却忽视了决定工业AI成败的真正基础。本文基于多年服务多行业企业数字化转型的实践经验,拆解工业AI项目成功的关键要素。
一、自动化工程经验的沉淀深度
所谓“自动化项目年”,并非简单的时间累积,而是指工程经验的厚度与可复用性。

一位拥有十年以上自动化项目经验的工程师,其价值不仅体现在PID参数整定、阀门响应滞后补偿等具体技能上,更体现在对产线关键数据甄别、异常模式识别等隐性知识的掌握。这类现场经验,是大模型即便精读大量技术文献也难以直接获得的。
实施建议:
- 系统盘点企业内部拥有长期现场经验的工程师资源,将其作为AI项目的核心知识源
- 推动将资深工程师的经验转化为结构化规则库与知识库,使其参与问题定义与特征工程环节
- 参考实践经验,已有企业将现场经验封装为可复用的知识库,以模块化方式支持AI应用快速定制
二、数据质量与治理能力
工业界有“垃圾进,垃圾出”的基本共识,但在实际生产环境中,数据质量的评价维度远不止于“干净与否”,更应关注其信息密度与业务相关性。
以一条温度曲线为例:
- 初级视角:仅关注数值大小
- 工程视角:关注曲线形态、拐点位置、滞后特性
- 价值视角:理解“该拐点对应的物理过程及其对产品质量的影响”
实施建议:
- 组织资深工艺工程师对典型工况数据进行标注,建立高质量样本集
- 基于工程经验设计数据清洗与特征提取规则,建立规范的数据治理体系
- 研究显示,高质量数据集是支撑大模型精准学习规律的基石,原始数据必须经过规范化的处理流程
- 实践中,数据分散、质量参差、跨主体共享难,仍是制约工业AI落地的三大瓶颈
三、完整的建设路径
大量企业在实践中跳过底层能力建设,直接追逐上层AI应用,导致典型问题:数据无法有效采集,或采集后无法使用,或可用数据缺乏业务解读能力。
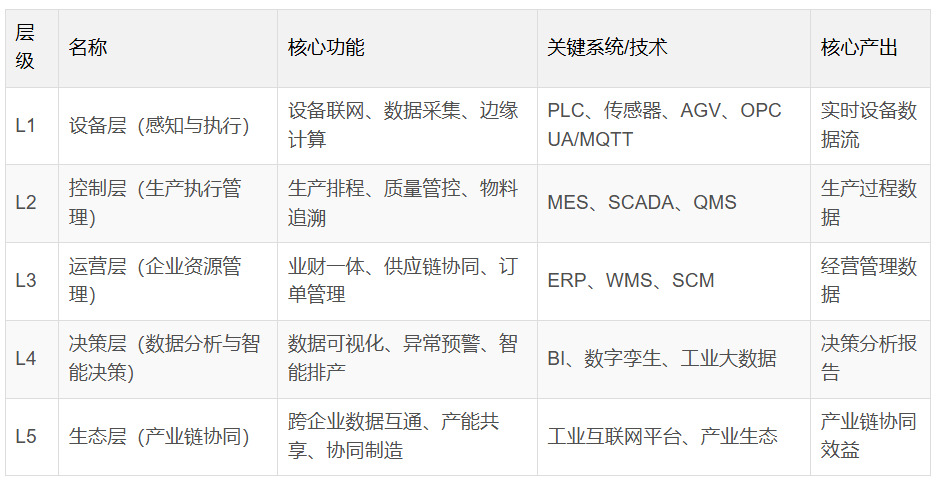
可行的技术路径应遵循分层递进的建设逻辑:
| 层级 | 名称 | 核心任务 |
|---|---|---|
| L1 | 物理层 | 设备接入与实时数据采集 |
| L2 | 边缘层 | 协议解析、边缘计算与数据预处理 |
| L3 | 业务层 | 规则引擎、专家知识库与工艺模型 |
| L4 | 应用层 | AI模型训练、智能决策与闭环优化 |
实施建议:
- 每一层级均需通过实际项目积累系统能力,不存在绕过底层直接到达上层的技术捷径
- 边缘计算是实现智能制造的核心技术支撑之一,可有效解决数据实时性、安全性需求与云端算力的平衡难题
- 设备预测性维护等应用场景对数据采集的深度与质量有更高要求,不应作为初期目标
- 某制造业500强企业在智能工厂建设中,依托跨区域边缘计算专网,数据采集实时时延达微秒级,成功实现AI创新应用矩阵覆盖全生产环节
四、组织文化与人才体系
这是最易被忽视、却最具决定性的因素。实践中常见的组织阻力包括:
- 设备管理部门:将数据视为部门私有资源,不愿共享
- IT部门:对AI项目实行统一管控,限制业务部门自主探索
- 一线资深员工:因经验被技术系统“替代”而产生抵触情绪
若企业内部缺乏数据开放、跨部门协同的组织文化,再先进的模型与算力也难以转化为实际效益。
结语
工业AI的真正竞争力,不取决于所采用的大模型版本、所购置的GPU数量或所聘任的AI博士数量。它根植于:
- 企业积累的自动化工程经验厚度
- 工业数据的真实质量与信息密度
- 从物理层到应用层的系统化建设路径
- 开放、协同、人机互信的组织文化

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)