山东大学软件学院创新实训(三)
前言
上周我们完成了 Python AI 微服务的基础架构搭建,打通了 Java 业务层与 Python AI 层之间的 RabbitMQ 消息通道。截至目前,我重点推进了 RAG(检索增强生成) 和 视觉题目识别 两大核心功能的落地,让错题本从"简单的聊天机器人"进化为真正的"智能学习助手"。
一、RAG 检索增强生成
1.1 为什么需要 RAG?
单纯的对话式 AI 存在两个问题:
- 知识滞后:大模型的训练数据是固定的,无法了解我们教材的最新内容。
- 幻觉问题:AI 可能会编造不存在的知识点或解题方法.
RAG 技术的引入完美解决了这些问题:先从本地知识库检索相关知识,再让 AI 基于这些知识回答问题,确保答案的准确性和专业性。
1.2 向量数据库选型与实现
我们选择了 FAISS(Facebook AI Similarity Search)作为向量数据库,配合 sentence-transformers 实现文本向量化。
核心封装类:FAISSStore:
"""
FAISS向量数据库封装
用于存储和检索知识向量
"""
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
from typing import List, Dict
class FAISSStore:
"""FAISS向量存储"""
def __init__(self, embedding_model: str = "paraphrase-multilingual-MiniLM-L12-v2",
dimension: int = 384):
self.dimension = dimension
self.documents = [] # 存储原始文本
self.metadatas = [] # 存储元数据
# 初始化嵌入模型(支持多语言)
self.embedding_model = SentenceTransformer(embedding_model)
# 初始化FAISS索引(使用L2距离)
self.index = faiss.IndexFlatL2(dimension)
def add_documents(self, texts: List[str], metadatas: List[Dict] = None) -> List[int]:
"""添加文档到向量库"""
if not texts:
return []
# 生成嵌入向量
embeddings = self.embedding_model.encode(texts, convert_to_numpy=True)
embeddings = np.array(embeddings).astype('float32')
# 添加到FAISS索引
ids = list(range(len(self.documents), len(self.documents) + len(texts)))
self.index.add(embeddings)
# 存储文档和元数据
self.documents.extend(texts)
if metadatas:
self.metadatas.extend(metadatas)
else:
self.metadatas.extend([{}] * len(texts))
return ids
def similarity_search(self, query: str, k: int = 5) -> List[Dict]:
"""相似度搜索"""
if len(self.documents) == 0:
return []
# 生成查询向量
query_embedding = self.embedding_model.encode([query], convert_to_numpy=True)
query_embedding = np.array(query_embedding).astype('float32')
# 搜索最相似的向量
k = min(k, len(self.documents))
distances, indices = self.index.search(query_embedding, k)
# 构建结果
results = []
for idx, distance in zip(indices[0], distances[0]):
if idx != -1:
results.append({
'content': self.documents[idx],
'metadata': self.metadatas[idx],
'distance': float(distance)
})
return results
def save(self, path: str = "./data/faiss_index"):
"""保存向量库到磁盘"""
os.makedirs(os.path.dirname(path), exist_ok=True)
faiss.write_index(self.index, f"{path}.index")
with open(f"{path}.docs.json", 'w', encoding='utf-8') as f:
json.dump({
'documents': self.documents,
'metadatas': self.metadatas
}, f, ensure_ascii=False, indent=2)
def load(self, path: str = "./data/faiss_index"):
"""从磁盘加载向量库"""
self.index = faiss.read_index(f"{path}.index")
with open(f"{path}.docs.json", 'r', encoding='utf-8') as f:
data = json.load(f)
self.documents = data['documents']
self.metadatas = data['metadatas']
关键技术点:
- 使用 paraphrase-multilingual-MiniLM-L12-v2 模型,支持中英文混合检索。
- 向量维度为 384,平衡了精度和性能。
- 支持持久化存储,服务重启后可快速加载。
1.3 RAG 服务层封装
"""
RAG (Retrieval-Augmented Generation) 检索增强生成服务
结合向量数据库和大模型,实现精准的知识问答
"""
from vector_store.faiss_store import FAISSStore
from core.ai_service import ai_service
class RAGService:
"""RAG服务 - 检索增强生成"""
def __init__(self):
self.vector_store = FAISSStore()
self.ai_service = ai_service
# RAG系统提示词
self.rag_system_prompt = """你是一个基于知识库的智能学习助手。
你会收到相关的知识片段和用户的问题。
请基于提供的知识片段来回答问题,如果知识片段中没有相关信息,请诚实地告诉用户。
回答时要准确、清晰,并适当引用知识库中的内容。"""
def rag_query(self, query: str, user_id: str = "system",
top_k: int = 3) -> str:
"""
RAG检索查询
Args:
query: 用户查询
user_id: 用户ID
top_k: 检索最相关的K个知识片段
Returns:
AI生成的答案
"""
try:
# 1. 从向量库检索最相关的知识片段
docs = self.vector_store.similarity_search(query, k=top_k)
if not docs:
# 如果没有检索到知识,直接使用普通对话
return self.ai_service.chat(user_id, query)
# 2. 构建上下文
context_parts = []
for i, doc in enumerate(docs, 1):
content = doc.get('content', '')
source = doc.get('metadata', {}).get('source', '未知来源')
context_parts.append(f"[知识片段 {i}] (来源: {source})\n{content}\n")
context = "\n".join(context_parts)
# 3. 构建增强提示词
enhanced_prompt = f"""【相关知识库内容】
{context}
【用户问题】
{query}
请基于上述知识库内容回答用户的问题。如果知识库中的信息不足以完整回答问题,请结合你的知识进行补充,但要明确标注哪些是来自知识库,哪些是你的补充。"""
# 4. 调用AI生成答案
messages = [
{"role": "system", "content": self.rag_system_prompt},
{"role": "user", "content": enhanced_prompt}
]
response = self.ai_service.client.chat.completions.create(
model=settings.ai.model,
messages=messages,
temperature=0.7,
max_tokens=settings.ai.max_tokens
)
answer = response.choices[0].message.content
return answer
except Exception as e:
raise Exception(f"RAG查询异常: {str(e)}")
# 全局RAG服务实例
rag_service = RAGService()
RAG 工作流程:
1.检索阶段:将用户问题向量化,在 FAISS 中检索最相关的 K 个知识片段。
2.增强阶段:将检索到的知识片段作为上下文,构建增强提示词。
3.生成阶段:调用通义千问 API,基于知识库内容生成准确答案。
1.4知识库构建脚本
为了让 RAG 系统有知识可查,我编写了知识库构建脚本,从 MySQL 数据库中提取错题数据并向量化:
"""
从MySQL导入历史错题到向量库(用于错因分析和RAG问答)
"""
from core.rag_service import rag_service
from database.mysql_client import mysql_client
class KnowledgeBaseBuilder:
"""知识库构建器"""
def __init__(self):
self.rag_service = rag_service
def import_from_mysql(self, limit=500):
"""从MySQL导入错题到向量库"""
sql = """
SELECT id, stem, analysis, wrong_reason, tags
FROM topic
WHERE deleted = 0
AND stem IS NOT NULL
AND analysis IS NOT NULL
LIMIT %s
"""
topics = mysql_client.execute_query(sql, (limit,))
texts = []
metadatas = []
for topic in topics:
# 构建知识文本:题目 + 解析 + 错因
content = f"题目:{topic['stem']}\n解析:{topic['analysis']}"
if topic.get('wrong_reason'):
content += f"\n常见错误:{topic['wrong_reason']}"
metadata = {
"topic_id": topic['id'],
"tags": topic.get('tags', '').split(',') if topic.get('tags') else [],
"source": "mysql",
"type": "error_note"
}
texts.append(content)
metadatas.append(metadata)
if texts:
ids = self.rag_service.add_knowledge(texts, metadatas)
return len(texts)
def build(self):
"""构建知识库"""
total = self.import_from_mysql(limit=1000)
# 保存到 ./data/kb_error_notebook
project_root = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
save_path = os.path.join(project_root, "data", "kb_error_notebook")
self.rag_service.save_vector_store(save_path)
def main():
builder = KnowledgeBaseBuilder()
builder.build()
执行后会在data/文件夹生成:data/kb_error_notebook.index - FAISS 索引文件、data/kb_error_notebook.docs.json - 文档和元数据。
1.5运行结果
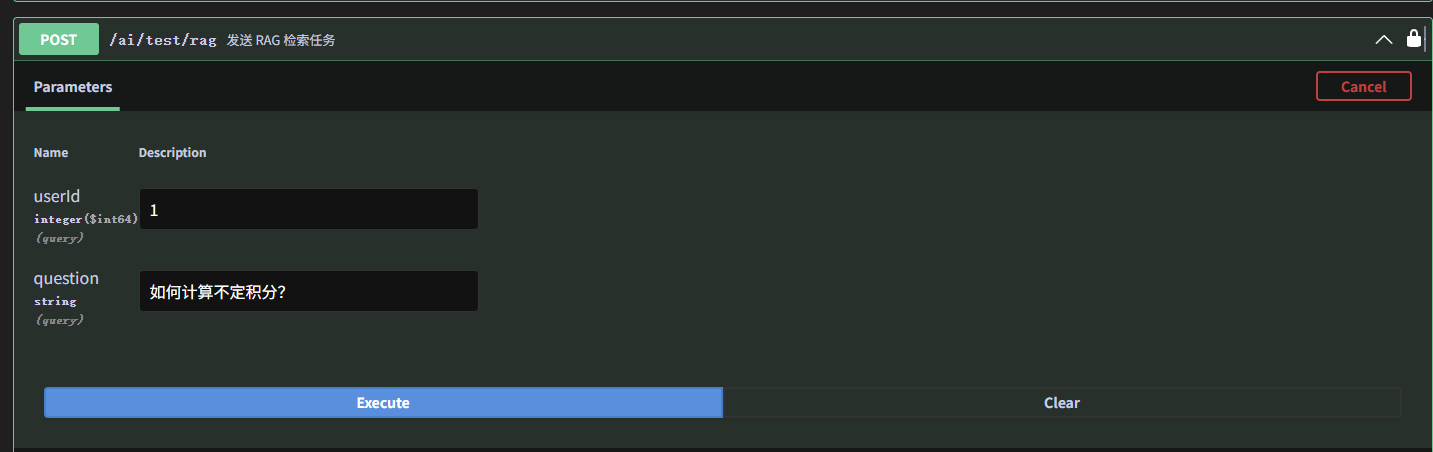
在Swagger UI的接口中我们输入问题:如何计算不定积分?此时分别观察java端和python端的日志,得到:
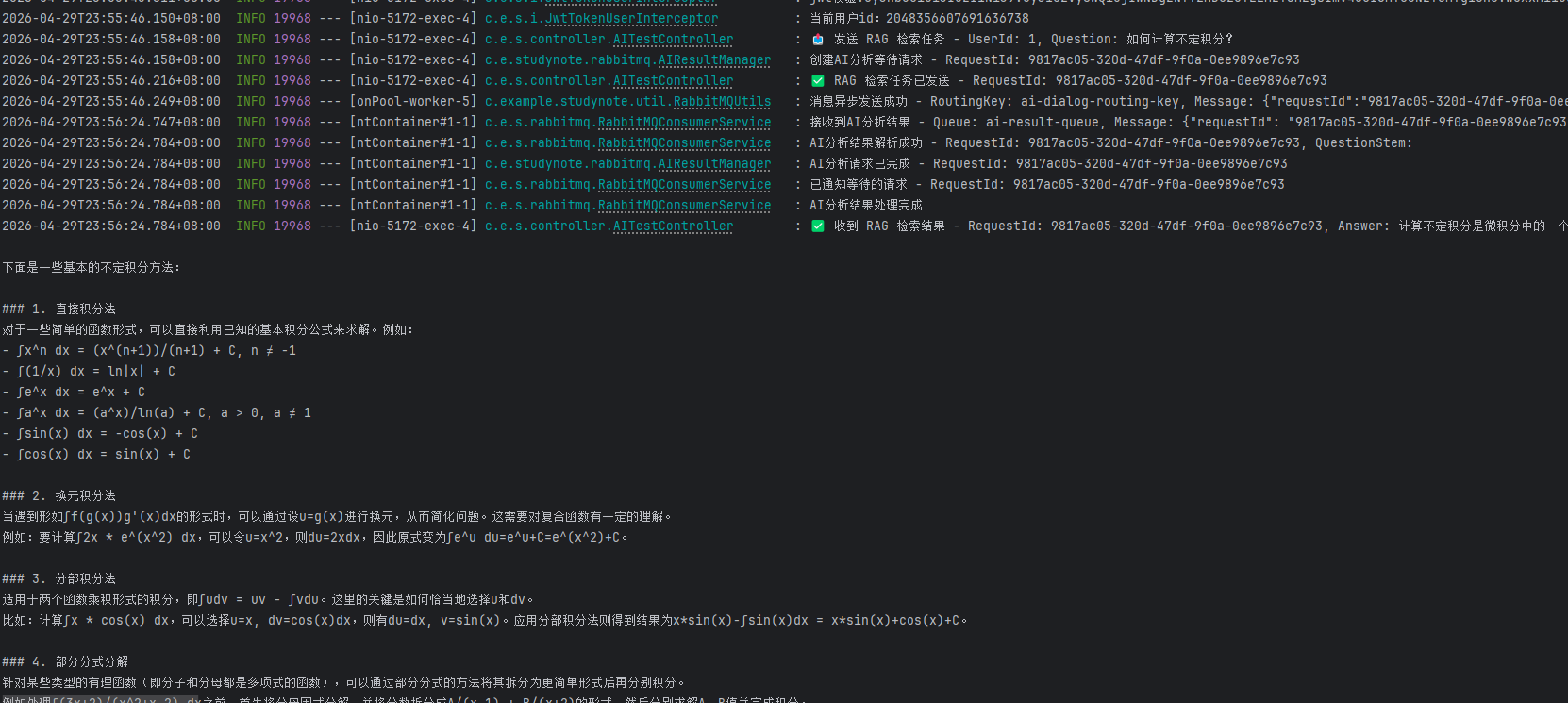


可以看出已经得到了相应的结果,与此同时,在RabbitMQ Management中观察到ai-dialog-queue中的unlocked和total的值均为1:
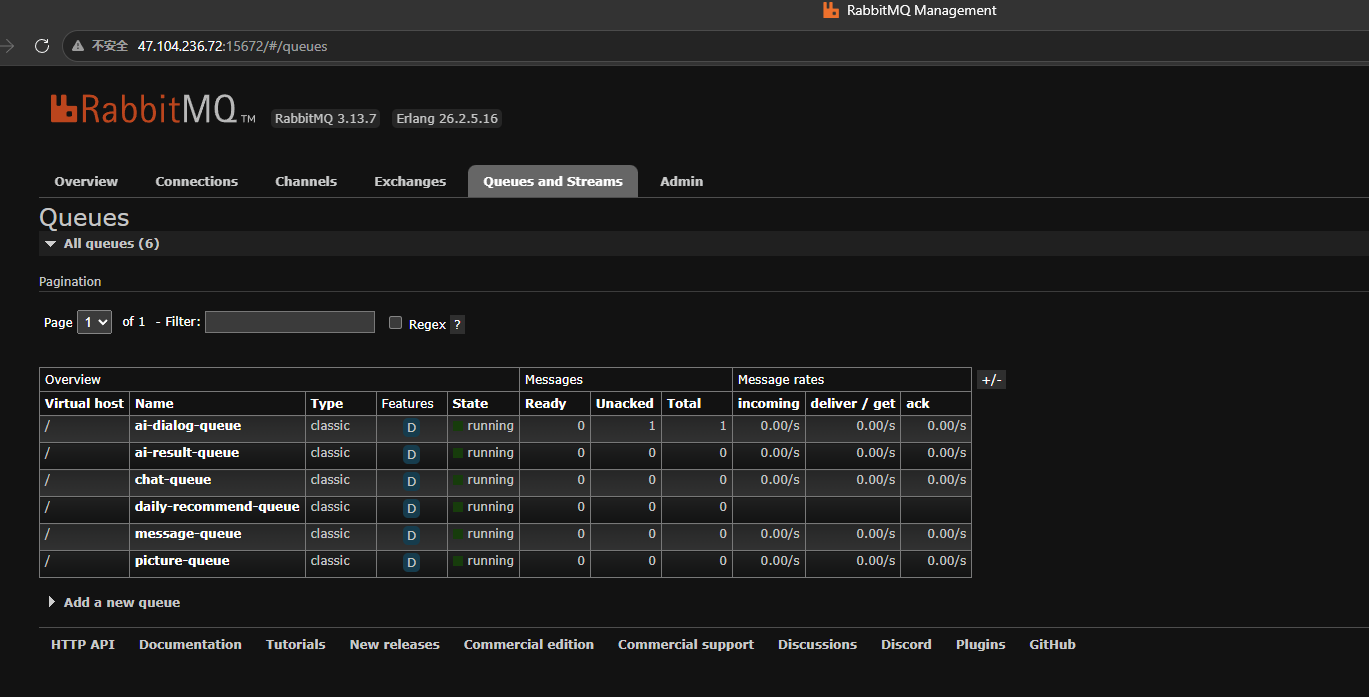
检索成功后,两者的值重新变为0,这意味着java和python两端成功完成了消息队列的通信。
二、视觉题目识别:拍照即可录入错题
2.1 功能需求
传统的错题录入需要手动输入题干、选项、答案,体验极差。我们引入了视觉识别功能:用户只需拍照上传,AI 自动识别题目内容、提取关键信息。
2.2 通义千问视觉模型接入
阿里云通义千问提供了强大的视觉理解能力(qwen-vl-max),我们通过 OpenAI 兼容模式接入:
def analyze_image(self, image_url: str) -> Dict:
"""
分析图片中的题目
Args:
image_url: 图片 URL
Returns:
分析结果字典,包含:
- question_stem: 识别出的题干
- user_answer: 用户手写答案
- correct_answer: 正确答案
- analysis: 题目解析
- tags: 知识点标签
"""
try:
import requests
import base64
from io import BytesIO
from PIL import Image
from urllib.parse import unquote, parse_qs, urlparse
# 处理百度图片链接:自动提取真实图片 URL
if 'image.baidu.com' in image_url:
parsed_url = urlparse(image_url)
query_params = parse_qs(parsed_url.query)
if 'objurl' in query_params:
real_url = unquote(unquote(query_params['objurl'][0]))
image_url = real_url
# 下载图片
response = requests.get(image_url, timeout=15, headers={
'User-Agent': 'Mozilla/5.0 ...',
'Referer': 'https://www.baidu.com/'
})
response.raise_for_status()
# 验证图片格式
img = Image.open(BytesIO(response.content))
if img.format not in ['JPEG', 'PNG', 'WEBP', 'BMP']:
raise ValueError(f"不支持的图片格式: {img.format}")
# 转换为 base64
buffered = BytesIO()
img.save(buffered, format=img.format)
img_base64 = base64.b64encode(buffered.getvalue()).decode('utf-8')
# 构建消息内容(多模态输入)
content = [
{
"type": "image_url",
"image_url": {
"url": f"data:image/{img.format.lower()};base64,{img_base64}"
}
},
{
"type": "text",
"text": """请识别图片中的数学/物理/化学/英语题目内容,并按以下 JSON 格式返回结果:
{
"question_stem": "识别出的完整题干内容(公式用 LaTeX 格式)",
"user_answer": "用户手写的答案(如果有)",
"correct_answer": "正确答案(如果有)",
"analysis": "题目解析和解题步骤",
"tags": ["知识点1", "知识点2", "知识点3"]
}
要求:
1. 公式用 LaTeX 格式
2. 如果图片中没有题目,返回空字符串
"""
}
]
messages = [
{"role": "system", "content": "你是一个专业的题目识别和分析助手。"},
{"role": "user", "content": content}
]
# 调用视觉模型
response = self.client.chat.completions.create(
model=settings.ai.vision_model, # qwen-vl-max
messages=messages,
temperature=settings.ai.vision_temperature # 0.1(低温度保证稳定性)
)
result_text = response.choices[0].message.content
# 解析 JSON 结果
result = json.loads(result_text)
return result
except Exception as e:
raise Exception(f"图片分析异常: {str(e)}")
关键技术点:
- 图片预处理:自动处理百度图片等特殊链接,提取真实 URL。
- Base64 编码:将图片转换为 base64 格式,符合 API 要求。
- 结构化输出:强制 AI 返回 JSON 格式,便于后续程序处理。
- LaTeX 公式支持:数学公式自动转换为 LaTeX 格式。
2.3 图片分析任务的消息队列集成
视觉识别是耗时操作,我们通过 RabbitMQ 异步处理:
def on_picture_message(self, ch, method, properties, body):
"""
处理图片分析任务(来自 picture-queue)
"""
try:
task = json.loads(body)
request_id = task.get("requestId")
user_id = str(task.get("userId"))
url = task.get("url")
# 1. 调用视觉模型识别图片
result = ai_service.analyze_image(url)
question_stem = result.get("question_stem", "")
user_answer = result.get("user_answer", "")
correct_answer = result.get("correct_answer", "")
# 2. RAG 检索错因分析
error_cause_context = ""
if user_answer and correct_answer:
error_cause_query = f"错误答案 {user_answer} 正确答案 {correct_answer}"
error_cause_results = rag_service.vector_store.similarity_search(
error_cause_query, k=3
)
if error_cause_results:
error_cause_context = "\n".join([
f"- {doc['content'][:200]}..."
for doc in error_cause_results
])
# 3. 构建响应
response = {
"requestId": request_id,
"questionStem": question_stem,
"analyseQuestion": result.get("analysis", ""),
"analyseWrong": error_cause_context,
"suggestLabels": result.get("tags", [])
}
# 4. 发送结果回 Java 端
self._send_result(settings.rabbitmq.ai_result_queue,
settings.rabbitmq.ai_result_routing_key,
response)
ch.basic_ack(delivery_tag=method.delivery_tag)
except Exception as e:
logger.error(f"处理图片任务失败:{str(e)}", exc_info=True)
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
处理流程:
1.接收 Java 端发送的图片 URL。
2.调用视觉模型识别题目内容。
3.基于识别结果,RAG 检索错因分析。
4.将完整结果返回给 Java 端。
2.4 运行结果
首先我从百度找了一道高数题的图片,图片的url是:https://img2.baidu.com/it/u=257672646,1143862643&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=1160
同样,在Swagger UI的analyze-image接口中输入该图片的url并execute,观察到两端的页面结果:
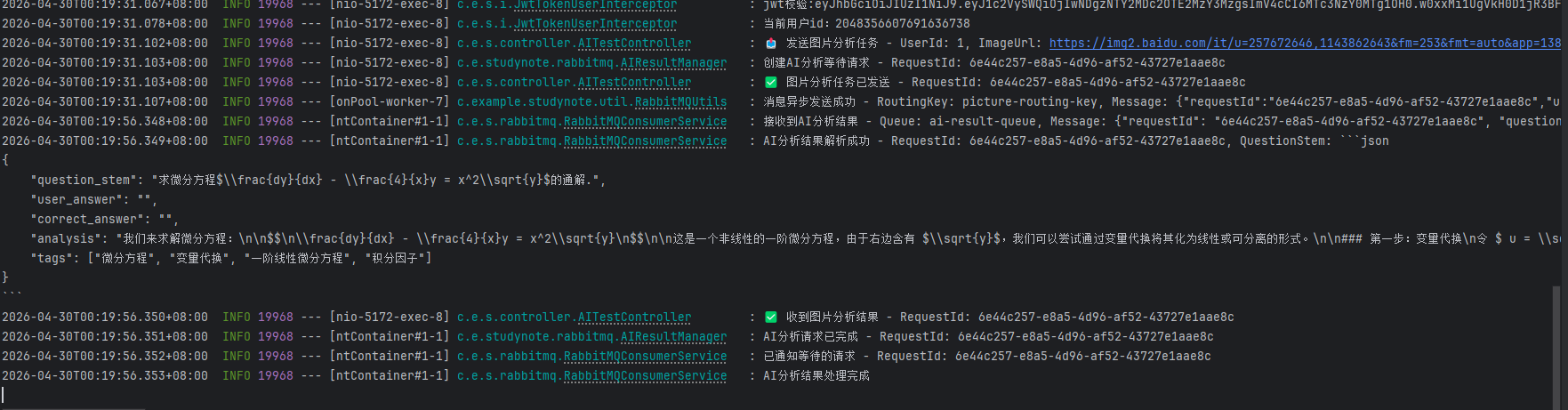


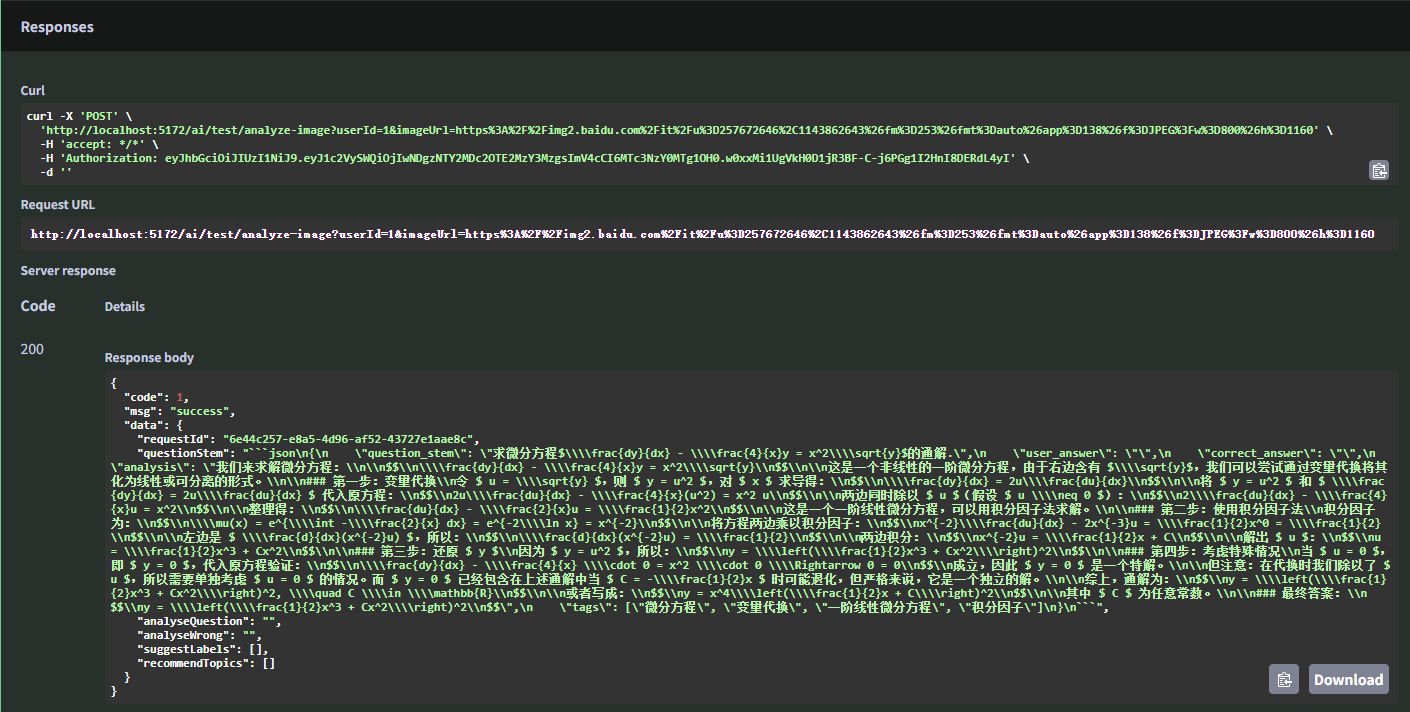
RabbitMQ Management中的过程就不再赘述,可以看到java和python两端已经成功完成了消息队列的通信,而Swagger UI也返回了我们需要的该题的答案。不过需要注意的是,由于目前知识库的数据仍然很少,所以ython端并没有检索到类似的题目并推送。
三、服务启动优化
在 main.py 中,我优化了服务启动流程,确保知识库在服务启动时就加载完成:
class AIServiceApp:
"""AI服务应用"""
def start(self):
"""启动服务"""
try:
logger.info("=" * 60)
logger.info("🚀 Python AI服务启动中...")
logger.info(f"📡 RabbitMQ Host: {settings.rabbitmq.host}")
logger.info(f"🤖 AI Model: {settings.ai.model}")
logger.info(f"👁️ Vision Model: {settings.ai.vision_model}")
logger.info("=" * 60)
# 【关键修改】1. 先加载知识库(阻塞等待完成)
try:
from core.rag_service import rag_service
# 加载错题本知识库
knowledge_path = "./data/kb_error_notebook"
if os.path.exists(f"{knowledge_path}.index"):
logger.info("📚 正在加载错题本知识库...")
rag_service.load_vector_store(knowledge_path)
stats = rag_service.vector_store.get_stats()
logger.info(
f"✅ 知识库加载成功 - 文档数: {stats['total_documents']}, "
f"索引大小: {stats['index_size']}")
else:
logger.warning("⚠️ 未找到知识库文件,请先运行 scripts/build_knowledge_base.py")
except Exception as e:
logger.error(f"❌ 加载知识库失败: {str(e)}")
# 【关键修改】2. 知识库加载完成后,再创建消费者
logger.info("✅ 知识库准备就绪,正在初始化消息队列消费者...")
self.consumer = MQConsumer()
self.running = True
logger.info("🎉 服务启动成功,开始处理任务...")
# 3. 开始消费消息(这会阻塞)
self.consumer.start_consuming()
except Exception as e:
logger.error(f"❌ 服务启动失败: {str(e)}", exc_info=True)
sys.exit(1)
启动日志示例:
============================================================
🚀 Python AI服务启动中...
📡 RabbitMQ Host: 47.104.236.72
🤖 AI Model: qwen-max
👁️ Vision Model: qwen-vl-max
============================================================
📚 正在加载错题本知识库...
✅ 知识库加载成功 - 文档数: 856, 索引大小: 856
✅ 知识库准备就绪,正在初始化消息队列消费者...
🎉 服务启动成功,开始处理任务...
Python AI 服务已启动,正在监听队列...
正在监听队列:picture-queue
正在监听队列:ai-dialog-queue
四、总结与规划
本周我们完成了 RAG 检索增强生成 和 视觉题目识别 两大核心功能的落地,让 AI 错题本具备了真正的"智能":
1.RAG 检索:让 AI 回答有据可依,避免幻觉。
2.视觉识别:拍照即可录入错题,大幅提升用户体验。
3.异步架构:RabbitMQ 解耦,保证系统高并发和低延迟。
目前的架构已经具备了极强的扩展性,下周我们将重点推进个性化推题功能的实现,例如基于用户薄弱知识点实现精准的题目推荐,结合 RAG 检索的错因知识生成精准的错因分析报告等等。让错题本真正做到"懂你所需,推你所缺"。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)