项目介绍 MATLAB实现基于PSO- Kmeans粒子群优化算法(PSO)结合K均值聚类(Kmeans)进行用户用电行为分析(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油
目录
MATLAB实现基于PSO- Kmeans粒子群优化算法(PSO)结合K均值聚类(Kmeans)进行用户用电行为分析的详细项目实例... 2
MATLAB实现基于PSO- Kmeans粒子群优化算法(PSO)结合K均值聚类(Kmeans)进行用户用电行为分析的详细项目实例
请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人
或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解)
电力系统正在经历从传统集中式向智能化、分布式和高度信息化方向演进,用户侧用电行为的精细化分析在这一过程中扮演着越来越关键的角色。随着智能电表在居民、商业和工商业用户中的大规模部署,电力企业掌握了高时间分辨率的用电数据,如每15分钟、每30分钟甚至更短周期的负荷曲线。这类数据在时间维度与空间维度上都具有前所未有的精细程度,蕴含着丰富的行为特征与潜在规律。如何从大量时序负荷数据中挖掘出不同用户群体的典型用电模式,从而为电网调度、需求响应、精细化电价设计以及节能政策制定提供依据,已经成为智能电网与能源互联网领域的核心研究内容之一。
在真实电力系统运行中,用户负荷具有显著的随机性、波动性与多样性。即便是同类型用户,在不同季节、不同工作日与周末、不同气候条件下也会表现出差异明显的负荷曲线。仅依靠传统经验或简单统计指标难以形成稳定可靠的用户分群结果,因此需要采用数据驱动的聚类与模式识别方法,对用户侧负荷进行客观、系统的行为刻画。K均值聚类算法在负荷模式识别中应用较为广泛,原因在于其实现简单、计算效率高、便于在工程中落地。然而,K均值算法也存在敏感于初始聚类中心、容易陷入局部最优、对高维数据与噪声较为敏感等问题。对于具有明显高维特征和多峰结构的用电行为数据,单纯依赖K均值往往难以获得稳定且具有物理解释性的聚类结果。
为了提升聚类效果与结果的可靠性,粒子群优化算法逐渐被引入到聚类问题中。粒子群优化是一种基于群体智能的全局优化方法,通过模拟鸟群觅食或鱼群协同搜索行为,在连续空间中不断迭代更新粒子的位置和速度,以逼近全局最优解。在负荷聚类场景中,可以将聚类中心作为粒子的位置变量,将整体聚类误差或者变形后的目标函数作为适应度,利用粒子群算法在全局空间范围内搜索较优的聚类中心初值,再通过K均值进行局部细化,从而兼顾全局搜索能力与局部收敛速度。这种PSO与Kmeans结合的混合算法已经被证明在多类聚类任务中具有更好的收敛性能与聚类质量。
在用户用电行为分析中,PSO-Kmeans方法能够更充分地挖掘负荷曲线在时间模式上的差异。通过对智能电表采集的全天24点或96点负荷时间序列进行聚类,可以识别出典型的“早高峰-晚低谷型”“夜间生产型”“白天办公型”“全天平稳型”等负荷类型。电力企业可以针对不同的典型用电群体设计差异化的激励策略,例如针对峰谷差大的居民群体推广削峰填谷的需求响应方案;针对用电可靠性敏感度高的工业群体设计柔性负荷管理策略;针对分布式光伏接入较多的用户群体优化本地消纳和配网规划,从而实现经济性、安全性与清洁化的综合平衡。
此外,随着大数据与人工智能技术在电力行业的深度渗透,传统基于少量特征指标的分类方法已经难以满足业务快速变化的需求。需要一种既能够保持一定算法解释性,又具备更强搜索能力与全局优化能力的聚类算法框架。PSO-Kmeans正是介于经典机器学习和群体智能优化之间的一种平衡方案。相比端到端的黑箱深度网络,它在参数含义和聚类中心的物理解释方面更透明,更符合电力工程人员的理解与使用习惯;相比单纯Kmeans,它在结果稳定性与收敛质量上有显著提升,更适合承载电价设计、容量规划、线路重构、负荷预测分层等多类业务需求。
基于MATLAB环境开展PSO-Kmeans用户用电行为分析项目具有良好的工程实践价值。MATLAB在矩阵运算、可视化、数据处理方面拥有成熟工具箱,适合电力负荷数据的导入、预处理、标准化处理以及结果展示。同时,MATLAB脚本能够将PSO与Kmeans流程有机整合,通过参数化设计方便执行多轮实验、对比不同参数组合与聚类结果。从实际工程角度来看,这种项目不仅可以作为电力企业数据分析平台或高校科研教学中的参考案例,也可以进一步扩展至更多维度数据,如叠加天气、节假日、价格信号等多特征,用于构建更加复杂的行为画像系统。
因此,构建一个在MATLAB R2025b环境下实现的基于PSO-Kmeans的用户用电行为分析完整项目,涵盖数据预处理、特征构建、算法实现、结果评估与可视化展示,对于推动智能配用电系统的可视化管理、精细化运营与智能决策具有重要实际意义与推广价值。
项目目标与意义
用电行为模式识别与用户分群
本项目首先致力于从大规模智能电表负荷数据中识别具有代表性的用电行为模式。通过对居民、商业和工商业用户全天或多日负荷曲线进行聚类分析,构建出若干典型行为类,如早晚高峰明显的家庭型负荷、工作日白天占主导的办公型负荷、夜间连续运行的工业型负荷等。利用PSO-Kmeans混合算法在聚类中心初始化阶段引入全局搜索能力,使每一类的代表性更强、类内差异更小、类间区分度更高,从而形成稳定、可解释的用户分群结果。基于这些模式,可为电力公司提供一套可视化的用户画像,帮助运营人员从宏观上理解不同区域和用户类型的用电规律,实现对用户结构变化趋势的持续监测。这种基于数据驱动的模式识别有助于替代部分依赖经验的粗粒度分类方式,为后续业务环节提供统一且可信的行为分层基础。
支持需求响应与峰谷调节策略设计
本项目的第二个目标是为需求响应策略和峰谷电价机制的制定提供数据支撑。通过PSO-Kmeans对用户行为进行细致划分,可识别出峰谷差较大的敏感用户群体,以及对价格信号和激励机制更具响应潜力的用户。对于负荷峰值集中于特定时段的群体,可结合聚类结果设计定向削峰方案,在高峰时段推送阶梯电价或价格信号,引导部分可转移负荷向低谷转移。聚类结果还能帮助评估潜在需求响应容量,如统计某类用户在高峰时段可压缩的负荷比例、可中断负荷规模等,为调度部门制定负荷侧备用和紧急负荷管理预案提供基础。通过将行为模式与需求响应参与度关联,本项目使需求响应策略从全局统一迈向按类精细化管理,有利于提升整体响应效果并降低补偿成本。
提升配电网规划与设备配置精细化水平
第三个目标在于支持配电网中长期规划与设备配置决策,实现从“按最大负荷配置”向“按行为模式配置”的转变。传统配电网规划往往基于历史最大负荷或经验系数进行容量设计,容易导致部分区域设备长期处于轻载或重载状态。通过对用户群体的行为模式进行聚类分析,并在空间维度上叠加地理信息,可在馈线、配变甚至台区层面构建细化的负荷画像。对于负荷波动剧烈、峰值集中且增长较快的区域,可结合聚类结果提前开展容量增容和网络重构评估;对于负荷平稳、具有可调节空间的区域,可优先通过需求响应与分布式资源调节来延缓硬件增容投资。PSO-Kmeans聚类所提供的类中心曲线还能直接作为场景模拟的典型负荷曲线,为后续潮流计算、配电自动化优化、储能布置与柔性负荷配置提供基础工况参考,提高规划决策的科学性与经济性。
为电价机制改革与综合能源服务提供支撑
本项目的第四个重要目标是为电价机制改革和多元化综合能源服务设计提供可量化的依据。在电力市场化程度不断提高的背景下,差异化电价、实时电价与灵活结算机制逐渐成为趋势。通过对用户用电行为进行聚类,可以将对价格敏感度不同、负荷可调节性差异明显的用户群体区分开来,从而在电价方案设计中实现针对性配置。例如,对峰谷差明显但可转移负荷较大的群体,可设计更陡峭的峰谷价差以激励调整行为;对生产连续性强、负荷刚性的工业用户,则可以采用相对平稳的电价结构,并为其提供更可靠的供电质量保障。聚类结果还可为综合能源服务商提供精准营销支持,针对特定行为类别设计合同能源管理、用能托管、储能租赁、光伏+储能+充电等产品组合。通过结合PSO-Kmeans聚类结果,服务商能够清晰识别高潜力客户群体,降低获客成本,提升产品匹配度,推动用能方式从被动供给向主动优化转型。
项目挑战及解决方案
高维负荷曲线数据的噪声与不完备性处理
在真实工程环境中,智能电表采集的负荷数据常常存在缺失、异常尖峰、通信中断导致的断点以及部分时间段计量误差等问题。这使得原始负荷曲线呈现出噪声显著、不规则点较多的特征,而PSO-Kmeans算法对输入数据质量较为敏感。如果不对原始数据进行充分的预处理,聚类结果容易被极端值和异常形态主导,导致类中心曲线出现不合理波动,从而扭曲实际用电行为模式。此外,不同用户所处环境和接入电压等级不同,采样间隔和数据长度也可能存在差异,直接进行聚类会造成维度不齐和样本不可直接对齐问题。为应对这些挑战,本项目从数据清洗、插值修复和标准化三个层面设计了一整套预处理流程。
解决方案方面,首先在数据层面采用统计规则与工程经验相结合的方法对异常点进行识别处理,例如基于多倍标准差法、局部极值检测和用电设备物理边界对明显不合理负荷进行替换或剔除。对于缺失数据段,采用线性插值、样条插值或基于相邻日相同时间点的历史平均填补,使负荷曲线保持连续性与基本形态。其次,对不同用户的负荷曲线进行统一长度重采样与对齐处理,确保每个样本在Kmeans聚类时具有相同维度。最后,在整体数据层面进行归一化和标准化,将不同容量和电压等级的用户负荷转换到统一尺度,减少大负荷用户对聚类结果的支配作用,使聚类更加聚焦于相对行为特征而非绝对用电量。通过这些措施,可显著提升数据输入质量,为PSO-Kmeans算法提供可靠基础。
PSO参数设置与Kmeans聚类稳定性的平衡
PSO-Kmeans的核心挑战之一在于如何合理配置PSO的粒子规模、惯性权重、学习因子、最大迭代次数等参数,并与Kmeans的初始化策略和迭代过程协调统一。如果粒子数过少或迭代次数过短,PSO可能无法充分探索解空间,导致得到的聚类中心初值仍落入局部最优附近;反之,如果粒子数过多或迭代次数过长,将带来计算时间的大幅增加,尤其是在聚类维度高、样本数量大的负荷数据场景下,可能影响工程应用的实时性。惯性权重和个体/群体学习因子的配置也决定了粒子搜索过程的收敛速度和平衡性,过大的探索性可能导致搜索路径震荡频繁,过强的收敛性又容易早熟陷入局部最优。另一方面,Kmeans自身对初始中心敏感,且迭代过程中采用贪心式更新,缺乏跳出局部最优的机制,需要PSO在全局层面提供足够优质的初值。
解决方案采用了分层调参与实验对比相结合的思路。首先在MATLAB环境中通过参数化脚本,设计多组粒子数、惯性权重、自身与群体学习因子组合,对同一数据集进行多次PSO初始化与Kmeans聚类,对比每一组合下的聚类误差、轮廓系数和运行时间。通过实验选取一组在全局搜索能力、收敛速度和计算开销之间较为平衡的参数配置,例如中等规模粒子数、中等迭代次数、随迭代逐步减小的惯性权重以及适中偏向群体经验的学习因子。同时,在PSO适应度函数设计中引入整体平方误差与类内方差等指标,并对不合理解进行惩罚,以引导搜索过程向更加紧凑、分离度更好的聚类结构收敛。最后,在Kmeans阶段可采用多次运行取最优结果的方式,进一步降低结果的随机性,从整体上提升聚类稳定性和可重复性。
高维负荷行为特征的解释性与业务可用性
即便PSO-Kmeans能够在数学意义上获得较好的聚类结果,如果不能与电力业务场景进行有效对接,缺乏直观解释与可操作性,仍然难以在工程实践中推广应用。负荷数据通常呈现高维、强时间相关性,聚类结果往往表现为复杂的时间序列曲线,如何将这些聚类中心映射为业务人员可以理解的行为标签、典型用电类型,是一个重要的挑战。同时,不同业务部门关注的重点不同,如调度部门关注峰值时段与尖峰规模,营销部门关注用电稳定性和潜在响应空间,规划部门关注长期增长趋势和容量需求。单一维度的聚类指标难以满足多部门协同使用的需求,需要构建具有多视角解释能力的结果展示与分析框架。
解决方案在模型后处理与可视化分析方面进行了针对性设计。一方面,对聚类结果中的典型曲线进行二次特征抽取,例如峰值时间位置、峰谷差、日负荷因数、用电集中度指数等,形成结构化特征表,并据此给出“早高峰家庭”“夜间生产”“双峰生活-办公混合”等可读性较强的行为标签。通过这种特征映射,使技术人员与业务人员能够在无需深入理解算法细节的前提下把握聚类结果的含义。另一方面,利用MATLAB绘制各类用户的平均负荷曲线、置信区间、典型个体曲线,并叠加不同业务视角下的关键指标,如峰时容量、可转移负荷比等,构建多维度的结果展示面板。通过图形化展示、数据表输出和聚类标签映射,为需求响应设计、配电网规划、电价机制研究提供直接可用的分析基础,实现算法结果向业务价值的有效转化。
项目模型架构
数据采集与预处理模块
模型架构的第一部分是数据采集与预处理模块,其核心目标是将来自智能电表或历史负荷系统的原始时序数据转换为可直接输入PSO-Kmeans算法的矩阵形式。在数据采集层面,通常从配电自动化系统、用电信息采集系统或历史数据库中导出用户日负荷曲线。数据形式一般为用户编号、时间戳和对应时刻的有功负荷值。经过整理后,对每个用户按天或按代表日构建固定长度的时间序列,如将一天分为96个15分钟时段,形成长度为96的负荷向量。对于具有代表性的多日数据,可采用多日平均或典型日选择方式构建特征曲线。
在预处理模块中,首先对原始曲线进行异常值识别与修复。利用统计方法检测超出正常范围的极端负荷点,例如与相邻时刻差值过大、负荷突变不符合物理规律等,通过插值或邻域平滑进行修正。其次,对存在缺失时刻的曲线进行时间对齐和插值补齐,确保所有用户的负荷向量维度一致。随后,通过归一化或标准化方法,将每个用户的负荷曲线转换为相对形态特征,以突出行为模式而淡化绝对容量。常用方法包括按日最大负荷归一化、按用户日均值缩放或者标准差标准化等,这些操作可以有效减轻不同规模用户之间的数值差异对聚类的影响。在MATLAB中,可通过矩阵运算和向量化操作实现高效处理,为后续PSO-Kmeans算法提供干净、统一且结构合理的输入数据。
粒子群优化模块
粒子群优化模块是整体架构中的全局搜索引擎,用于在连续空间中寻找较优的聚类中心初值。其基本原理来源于群体智能思想,将每一个候选解视作一个粒子,在多维空间中具有位置与速度属性。粒子群在迭代过程中根据个体历史最优位置和群体历史最优位置更新自身速度与位置,实现信息共享与协同搜索。对于用户用电行为聚类问题,粒子的维度等于聚类中心总数乘以每个中心的特征维度,例如聚类数为K,负荷曲线长度为T,则每个粒子对应一个包含K×T元素的一维向量,代表K个聚类中心的全部坐标。适应度函数通常设置为聚类误差,例如所有样本到最近中心的平方和,通过将粒子解构造为聚类中心并计算对应聚类误差评估该粒子位置优劣。
在更新机制中,速度更新公式包括惯性权重项、自身最佳位置吸引项和群体最佳位置吸引项三个部分。惯性权重控制搜索过程中对上一时刻速度的保持程度,较大的值有利于探索新的区域,较小的值有利于精细搜索局部最优。自身学习因子和群体学习因子分别体现个体经验和群体经验对粒子运动的引导作用。在实现层面,通过MATLAB矩阵运算更新所有粒子的速度与位置,将位置约束在合理范围内,如限制聚类中心数值在数据最小和最大负荷之间。通过多次迭代,粒子群逐步收敛到较优适应度值,对应的聚类中心位置作为Kmeans算法的初始化输入,从而有效缓解随机初始化带来的不稳定性与局部最优问题。
Kmeans聚类模块
Kmeans聚类模块在整体架构中承担局部精细优化的职责。基于PSO模块给出的初始聚类中心,Kmeans通过迭代的方式进一步细化各类边界与中心位置,提升聚类的紧凑度和分离度。Kmeans基本原理为最小化类内平方误差,将每个样本分配至距离其最近的中心所对应的簇,然后根据分配结果重新计算每个簇的中心位置,即该簇样本的均值向量。通过样本分配与中心更新的反复迭代,在误差不再明显下降或达到最大迭代次数时停止。由于Kmeans每次迭代都在局部范围内进行贪心式更新,收敛速度较快,适合在PSO粗粒度搜索后进行精细调整。
在用户用电行为聚类场景中,负荷曲线作为高维向量,通常采用欧氏距离作为样本与中心之间的相似度度量。Kmeans通过反复迭代,将形态相近的曲线归为同一类别,使每一类的中心曲线代表该类典型用电模式。采用PSO提供的初始中心可以显著提高Kmeans的起点质量,减少迭代次数,提高收敛到全局较优解的概率。MATLAB中可根据PSO输出自行实现Kmeans过程,也可部分借助内置kmeans函数,将初始中心作为输入参数传入,实现算法集成。在本项目架构设计中,将Kmeans作为PSO之后的必经步骤,使聚类结果在保证全局搜索优势的前提下,兼顾局部精细化调整能力。
模型评估与可视化模块
模型评估与可视化模块是架构中的结果输出与质量检测环节,用于量化聚类效果并将抽象算法结果以直观形式呈现。评估指标层面,常用的包括类内平方误差、平均轮廓系数、类间距离、Davies-Bouldin指数等。通过对不同K值和不同参数组合的评估结果进行对比,可选择最优聚类数和较优算法参数。在用户用电行为分析中,聚类中心曲线的物理合理性同样重要,例如是否存在明显不符合实际规律的中心形态,如频繁剧烈震荡或不连贯跳变等。因此,在定量评估的基础上,还需结合电力业务经验对聚类中心进行人工审视与解释。
可视化层面,通过绘制各类中心负荷曲线与典型样本曲线,展示不同用户群体在日内各时段的用电特征差异,如高峰位置、晚间负荷水平、夜间基荷等。可进一步绘制每一类用户数量比例、空间分布情况和关键指标统计图,如各类用户的平均日用电量、峰谷差、负荷因数分布。MATLAB在绘图与界面交互方面具有丰富能力,能够通过多图窗口、颜色区分和图例标注等形式,为电力规划、调度和营销人员提供直观的聚类结果解读工具。通过评估与可视化模块,可以实现模型开发与业务需求之间的闭环反馈,不断优化算法与参数配置,使聚类结果在工程实践中具有更高可用性。
系统集成与扩展模块
模型架构的最后一部分是系统集成与扩展模块,用于将PSO-Kmeans用户用电行为分析嵌入更大范围的电力信息系统或研究平台中。在工程实践中,行为聚类往往是诸多应用模块的基础,例如负荷预测分层建模、差异化电价设计、需求响应资源评估等。因此,需要设计一套灵活的程序结构,使聚类算法模块可以通过统一接口被其他功能模块调用。通过在MATLAB中进行脚本组织与函数封装,将数据导入、预处理、PSO优化、Kmeans聚类、结果评估与可视化等步骤以模块化形式整合,构建可重复运行和易于维护的项目框架。
扩展层面,可以在当前以日负荷曲线为主的聚类基础上,加入更多维度特征,例如天气类型、节假日标记、行业分类、合同容量等,形成多维特征空间下的综合行为聚类。同时还可以结合其他优化算法与聚类方法,如遗传算法优化Kmeans、模糊C均值聚类等,与PSO-Kmeans形成对比与组合。通过在系统设计阶段预留接口与参数配置机制,未来可以在不大幅修改架构的前提下引入新算法或扩展到更大规模数据集。此外,系统可与数据库和上层可视化平台对接,实现自动批量分析与可视化展示,逐步构建面向智能电网和能源互联网的负荷行为分析服务能力。
项目模型描述及代码示例
clear; clc; close all; % 清空工作区变量、命令行窗口并关闭所有图窗,确保环境干净便于复现聚类实验
rawTable = readtable(dataFile); % 读取CSV格式的用户负荷数据表,包含用户ID、时间和负荷值等字段
userIDs = unique(rawTable.UserID); % 提取所有唯一用户编号,用于按用户聚合负荷曲线
numUsers = numel(userIDs); % 统计用户数量,为后续构建负荷矩阵分配行数
timeStamps = unique(rawTable.Time); % 提取所有时间戳,用于确定每天的采样点数量
loadMatrix = zeros(numUsers, numPoints); % 预分配负荷矩阵,每行对应一个用户,每列对应一个时间点
for u = 1:numUsers % 循环遍历每一个用户,逐个构建完整的日负荷曲线
uid = userIDs(u); % 当前用户的ID,用于从原始表中筛选该用户的数据
userData = rawTable(rawTable.UserID == uid, :); % 筛选出当前用户的所有记录行
validMask = idx > 0; % 标记出当前用户真正具有记录的时间点位置
userLoad = nan(numPoints, 1); % 预分配单个用户负荷向量,用NaN占位便于插值处理缺失
if any(~nanIdx) % 若存在至少一个非缺失点,说明可以执行插值补全操作
else % 若整条曲线全为缺失,说明该用户数据无效
userLoad(:) = 0; % 将该用户负荷曲线统一设为0,避免出现NaN干扰聚类计算
end
thr = 5 * std(diffLoad); % 设定异常阈值为差分标准差的5倍,用于识别不合理负荷突变
spikeIdx = [false; abs(diffLoad) > thr]; % 构建异常尖峰点索引,首个点默认非异常
userLoad(spikeIdx) = medfilt1(userLoad, 3); % 对包含尖峰的序列使用窗口长度为3的中值滤波平滑,抑制极端噪声
loadMatrix(u, :) = userLoad'; % 将处理后的用户负荷曲线写入总负荷矩阵对应行
maxLoad(maxLoad == 0) = 1; % 避免最大值为0导致除零错误,将0替换为1保证归一化稳定
normLoadMatrix = loadMatrix ./ maxLoad; % 将每个用户的负荷曲线除以自身最大值,使曲线范围缩放到0到1之间
normLoadMatrix(isnan(normLoadMatrix)) = 0; % 将归一化后可能出现的NaN替换为0,确保矩阵中无非法数值
PSO适应度函数构造示例
numClusters = 4; % 指定聚类簇数K,例如4类代表不同典型用电行为模式
[numUsers, numPoints] = size(normLoadMatrix); % 获取归一化负荷矩阵的行数和列数,行数为用户数、列数为时间点数
dataMax = max(normLoadMatrix(:)); % 计算所有负荷数据的最大值,用于约束粒子位置上界
function fit = psoKmeans_fitness(particle, dataMatrix, K) % 定义PSO适应度函数,输入粒子编码、数据矩阵和簇数输出适应度值
[numSamples, numDims] = size(dataMatrix); % 获取样本数量和每个样本的维度,本例中维度为时间点数
centers = reshape(particle, K, numDims); % 将一维粒子向量按行重塑为K行numDims列矩阵,表示K个聚类中心
D = pdist2(dataMatrix, centers, 'euclidean'); % 计算每个样本与K个中心之间的欧氏距离,形成样本数乘簇数的距离矩阵
clusterData = dataMatrix(idx, :); % 取出属于当前簇的样本矩阵
diffs = clusterData - centers(k, :); % 计算簇内每个样本与当前中心的差值向量
else % 若该簇为空,为防止出现空簇情况在适应度中加入惩罚
end
PSO主迭代过程示例
numParticles = 30; % 设置粒子群规模为30个粒子,在搜索能力和计算复杂度之间取得平衡
maxIter = 100; % 设置PSO最大迭代次数为100次,保证算法有足够时间收敛
wMax = 0.9; % 设置惯性权重初值为0.9,初期鼓励粒子进行全局范围探索
c1 = 1.8; % 设置个体学习因子,鼓励粒子向自身历史最佳位置靠近以利用个体经验
c2 = 1.8; % 设置群体学习因子,鼓励粒子向全局最佳位置靠近以利用群体经验
pos = dataMin + (dataMax - dataMin) * rand(numParticles, dim); % 随机初始化所有粒子位置,使其在数据范围内均匀分布
pBestPos = pos; % 将初始位置作为每个粒子的个体历史最优位置
pBestFit = inf(numParticles, 1); % 初始化每个粒子的历史最优适应度为正无穷,用于后续比较更新
gBestPos = pBestPos(gIdx, :); % 初始化全局最优位置为对应个体位置,后续会在评估后更新
w = wMax - (wMax - wMin) * (it - 1) / (maxIter - 1); % 按线性递减策略更新惯性权重,逐步从全局搜索过渡到局部搜索
for p = 1:numParticles % 遍历每一个粒子,依次更新其适应度、速度和位置
fit = fitnessFunc(pos(p, :)); % 计算当前粒子位置对应的适应度,即聚类误差和惩罚项
end
if fit < gBestFit % 若当前粒子适应度优于全局历史最佳,则更新全局最佳
gBestPos = pos(p, :); % 更新全局最优位置为当前粒子位置
end
for p = 1:numParticles % 再次遍历每个粒子,根据最新的个体和全局最优信息更新速度和位置
r1 = rand(1, dim); % 生成与维度相同的随机向量r1,用于个体学习项中的随机权重
r2 = rand(1, dim); % 生成与维度相同的随机向量r2,用于群体学习项中的随机权重
vel(p, :) = w * vel(p, :) ... % 惯性项保留上一时刻速度的一部分,实现搜索连续性
pos(p, :) = pos(p, :) + vel(p, :); % 根据更新后的速度调整粒子位置,完成一次搜索步长
pos(p, :) = min(pos(p, :), dataMax); % 将粒子位置上限裁剪到数据最大值,保持搜索空间合法
end
end
bestCentersInit = reshape(gBestPos, numClusters, numPoints); % 将最终全局最优粒子位置重塑为聚类中心矩阵,供Kmeans初始化使用
opts = statset('MaxIter', 200, 'Display', 'final'); % 设置Kmeans选项,最大迭代次数为200次并在结束时显示结果概要
initCenters = bestCentersInit; % 将PSO得到的全局最优聚类中心作为Kmeans的初始中心矩阵
[clusterIdx, finalCenters, sumd] = kmeans(normLoadMatrix, numClusters, ... % 调用MATLAB内置kmeans函数执行聚类,指定数据、簇数和初始中心
'Replicates', 1); % 仅运行一次Kmeans,因为初始中心已经由PSO优化,重复运行必要性下降
totalWithinSS = sum(sumd); % 汇总所有簇内平方误差,用于评估整体聚类紧凑度
D = pdist2(normLoadMatrix, finalCenters, 'euclidean'); % 重新计算每个样本与最终中心之间的欧氏距离矩阵
silVals = silhouette(normLoadMatrix, assign); % 计算每个样本的轮廓系数,评估其在所属簇中的紧密性与与邻近簇的区分度
disp(['平均轮廓系数: ', num2str(avgSil)]); % 在命令行输出平均轮廓系数,便于快速判断聚类结构优劣
聚类中心可视化示例
fig1 = figure; % 新建图窗用于绘制聚类中心曲线,便于直观观察各类典型用电模式
colors = lines(numClusters); % 使用lines配色函数为每一个簇生成具有区分度的颜色
xlabel('时间点序号'); % 设置横坐标标签为时间点序号,表示一天内不同采样时刻
ylabel('归一化负荷'); % 设置纵坐标标签为归一化负荷值,范围通常在0到1之间
title('PSO-Kmeans聚类得到的典型日负荷中心曲线'); % 设置图形标题,说明当前图展示的是各类典型日负荷中心
for k = 1:numClusters % 遍历每一个簇构造对应的图例文字
legendStrings{k} = ['簇 ', num2str(k)]; % 将簇编号转换为文本形式,例如“簇 1”“簇 2”等
end
legend(legendStrings, 'Location', 'best'); % 添加图例到图中,自动选择合适位置避免遮挡曲线
grid on; % 打开网格线辅助读图,便于观察各时间点负荷值的变化
colormap(fig1, turbo); % 为当前图窗设置turbo色图,符合R2025b推荐的colormap用法
samplePerCluster = 20; % 指定每个簇随机选取的示例用户数量,用于可视化每类内部差异
fig2 = figure; % 新建图窗用于展示用户样本与中心的叠加曲线
for k = 1:numClusters % 遍历每一个簇,分别创建子图展示簇内样本和中心曲线
subplot(numClusters, 1, k); % 创建按簇数排列的子图,在第k行显示对应簇的曲线
hold on; % 保持当前子图坐标轴,允许多条样本曲线叠加
idx = find(clusterIdx == k); % 找出属于第k个簇的全部用户索引
if numel(idx) > samplePerCluster % 若该簇用户数多于设定样本数,则进行随机抽样
sel = idx(randperm(numel(idx), samplePerCluster)); % 从该簇用户中随机选取指定数量用户,避免图形过于拥挤
plot(1:numPoints, normLoadMatrix(sel(n), :), 'Color', [0.8 0.8 0.8]); % 使用浅灰色绘制该用户日负荷曲线,突出背景形态
end
plot(1:numPoints, finalCenters(k, :), 'r', 'LineWidth', 2); % 使用红色粗线在样本曲线之上绘制簇中心,突出典型模式
title(['簇 ', num2str(k), ' 内部样本曲线及中心']); % 设置子图标题,说明当前展示的簇编号和内容
xlabel('时间点序号'); % 设置子图横坐标标签,表示时间点
ylabel('归一化负荷'); % 设置子图纵坐标标签,表示归一化负荷
grid on; % 打开子图网格线,辅助对比用户曲线与中心曲线的差异
end
colormap(fig2, turbo); % 为第二个图窗设置turbo色图,使整体视觉风格统一且符合版本规范
clear; clc; close all; % 清空工作区变量、命令行窗口并关闭所有图窗,确保环境干净便于复现聚类实验rawTable = readtable(dataFile); % 读取CSV格式的用户负荷数据表,包含用户ID、时间和负荷值等字段userIDs = unique(rawTable.UserID); % 提取所有唯一用户编号,用于按用户聚合负荷曲线numUsers = numel(userIDs); % 统计用户数量,为后续构建负荷矩阵分配行数timeStamps = unique(rawTable.Time); % 提取所有时间戳,用于确定每天的采样点数量loadMatrix = zeros(numUsers, numPoints); % 预分配负荷矩阵,每行对应一个用户,每列对应一个时间点for u = 1:numUsers % 循环遍历每一个用户,逐个构建完整的日负荷曲线 uid = userIDs(u); % 当前用户的ID,用于从原始表中筛选该用户的数据 userData = rawTable(rawTable.UserID == uid, :); % 筛选出当前用户的所有记录行 validMask = idx > 0; % 标记出当前用户真正具有记录的时间点位置 userLoad = nan(numPoints, 1); % 预分配单个用户负荷向量,用NaN占位便于插值处理缺失 if any(~nanIdx) % 若存在至少一个非缺失点,说明可以执行插值补全操作 else % 若整条曲线全为缺失,说明该用户数据无效 userLoad(:) = 0; % 将该用户负荷曲线统一设为0,避免出现NaN干扰聚类计算 end thr = 5 * std(diffLoad); % 设定异常阈值为差分标准差的5倍,用于识别不合理负荷突变 spikeIdx = [false; abs(diffLoad) > thr]; % 构建异常尖峰点索引,首个点默认非异常 userLoad(spikeIdx) = medfilt1(userLoad, 3); % 对包含尖峰的序列使用窗口长度为3的中值滤波平滑,抑制极端噪声 loadMatrix(u, :) = userLoad'; % 将处理后的用户负荷曲线写入总负荷矩阵对应行maxLoad(maxLoad == 0) = 1; % 避免最大值为0导致除零错误,将0替换为1保证归一化稳定normLoadMatrix = loadMatrix ./ maxLoad; % 将每个用户的负荷曲线除以自身最大值,使曲线范围缩放到0到1之间normLoadMatrix(isnan(normLoadMatrix)) = 0; % 将归一化后可能出现的NaN替换为0,确保矩阵中无非法数值PSO适应度函数构造示例
numClusters = 4; % 指定聚类簇数K,例如4类代表不同典型用电行为模式[numUsers, numPoints] = size(normLoadMatrix); % 获取归一化负荷矩阵的行数和列数,行数为用户数、列数为时间点数dataMax = max(normLoadMatrix(:)); % 计算所有负荷数据的最大值,用于约束粒子位置上界function fit = psoKmeans_fitness(particle, dataMatrix, K) % 定义PSO适应度函数,输入粒子编码、数据矩阵和簇数输出适应度值[numSamples, numDims] = size(dataMatrix); % 获取样本数量和每个样本的维度,本例中维度为时间点数centers = reshape(particle, K, numDims); % 将一维粒子向量按行重塑为K行numDims列矩阵,表示K个聚类中心D = pdist2(dataMatrix, centers, 'euclidean'); % 计算每个样本与K个中心之间的欧氏距离,形成样本数乘簇数的距离矩阵 clusterData = dataMatrix(idx, :); % 取出属于当前簇的样本矩阵 diffs = clusterData - centers(k, :); % 计算簇内每个样本与当前中心的差值向量 else % 若该簇为空,为防止出现空簇情况在适应度中加入惩罚endPSO主迭代过程示例
numParticles = 30; % 设置粒子群规模为30个粒子,在搜索能力和计算复杂度之间取得平衡maxIter = 100; % 设置PSO最大迭代次数为100次,保证算法有足够时间收敛wMax = 0.9; % 设置惯性权重初值为0.9,初期鼓励粒子进行全局范围探索c1 = 1.8; % 设置个体学习因子,鼓励粒子向自身历史最佳位置靠近以利用个体经验c2 = 1.8; % 设置群体学习因子,鼓励粒子向全局最佳位置靠近以利用群体经验pos = dataMin + (dataMax - dataMin) * rand(numParticles, dim); % 随机初始化所有粒子位置,使其在数据范围内均匀分布pBestPos = pos; % 将初始位置作为每个粒子的个体历史最优位置pBestFit = inf(numParticles, 1); % 初始化每个粒子的历史最优适应度为正无穷,用于后续比较更新gBestPos = pBestPos(gIdx, :); % 初始化全局最优位置为对应个体位置,后续会在评估后更新 w = wMax - (wMax - wMin) * (it - 1) / (maxIter - 1); % 按线性递减策略更新惯性权重,逐步从全局搜索过渡到局部搜索 for p = 1:numParticles % 遍历每一个粒子,依次更新其适应度、速度和位置 fit = fitnessFunc(pos(p, :)); % 计算当前粒子位置对应的适应度,即聚类误差和惩罚项 end if fit < gBestFit % 若当前粒子适应度优于全局历史最佳,则更新全局最佳 gBestPos = pos(p, :); % 更新全局最优位置为当前粒子位置 end for p = 1:numParticles % 再次遍历每个粒子,根据最新的个体和全局最优信息更新速度和位置 r1 = rand(1, dim); % 生成与维度相同的随机向量r1,用于个体学习项中的随机权重 r2 = rand(1, dim); % 生成与维度相同的随机向量r2,用于群体学习项中的随机权重 vel(p, :) = w * vel(p, :) ... % 惯性项保留上一时刻速度的一部分,实现搜索连续性 pos(p, :) = pos(p, :) + vel(p, :); % 根据更新后的速度调整粒子位置,完成一次搜索步长 pos(p, :) = min(pos(p, :), dataMax); % 将粒子位置上限裁剪到数据最大值,保持搜索空间合法 endendbestCentersInit = reshape(gBestPos, numClusters, numPoints); % 将最终全局最优粒子位置重塑为聚类中心矩阵,供Kmeans初始化使用opts = statset('MaxIter', 200, 'Display', 'final'); % 设置Kmeans选项,最大迭代次数为200次并在结束时显示结果概要initCenters = bestCentersInit; % 将PSO得到的全局最优聚类中心作为Kmeans的初始中心矩阵[clusterIdx, finalCenters, sumd] = kmeans(normLoadMatrix, numClusters, ... % 调用MATLAB内置kmeans函数执行聚类,指定数据、簇数和初始中心 'Replicates', 1); % 仅运行一次Kmeans,因为初始中心已经由PSO优化,重复运行必要性下降totalWithinSS = sum(sumd); % 汇总所有簇内平方误差,用于评估整体聚类紧凑度D = pdist2(normLoadMatrix, finalCenters, 'euclidean'); % 重新计算每个样本与最终中心之间的欧氏距离矩阵silVals = silhouette(normLoadMatrix, assign); % 计算每个样本的轮廓系数,评估其在所属簇中的紧密性与与邻近簇的区分度disp(['平均轮廓系数: ', num2str(avgSil)]); % 在命令行输出平均轮廓系数,便于快速判断聚类结构优劣聚类中心可视化示例
fig1 = figure; % 新建图窗用于绘制聚类中心曲线,便于直观观察各类典型用电模式colors = lines(numClusters); % 使用lines配色函数为每一个簇生成具有区分度的颜色xlabel('时间点序号'); % 设置横坐标标签为时间点序号,表示一天内不同采样时刻ylabel('归一化负荷'); % 设置纵坐标标签为归一化负荷值,范围通常在0到1之间title('PSO-Kmeans聚类得到的典型日负荷中心曲线'); % 设置图形标题,说明当前图展示的是各类典型日负荷中心for k = 1:numClusters % 遍历每一个簇构造对应的图例文字 legendStrings{k} = ['簇 ', num2str(k)]; % 将簇编号转换为文本形式,例如“簇 1”“簇 2”等endlegend(legendStrings, 'Location', 'best'); % 添加图例到图中,自动选择合适位置避免遮挡曲线grid on; % 打开网格线辅助读图,便于观察各时间点负荷值的变化colormap(fig1, turbo); % 为当前图窗设置turbo色图,符合R2025b推荐的colormap用法samplePerCluster = 20; % 指定每个簇随机选取的示例用户数量,用于可视化每类内部差异fig2 = figure; % 新建图窗用于展示用户样本与中心的叠加曲线for k = 1:numClusters % 遍历每一个簇,分别创建子图展示簇内样本和中心曲线 subplot(numClusters, 1, k); % 创建按簇数排列的子图,在第k行显示对应簇的曲线 hold on; % 保持当前子图坐标轴,允许多条样本曲线叠加 idx = find(clusterIdx == k); % 找出属于第k个簇的全部用户索引 if numel(idx) > samplePerCluster % 若该簇用户数多于设定样本数,则进行随机抽样 sel = idx(randperm(numel(idx), samplePerCluster)); % 从该簇用户中随机选取指定数量用户,避免图形过于拥挤 plot(1:numPoints, normLoadMatrix(sel(n), :), 'Color', [0.8 0.8 0.8]); % 使用浅灰色绘制该用户日负荷曲线,突出背景形态 end plot(1:numPoints, finalCenters(k, :), 'r', 'LineWidth', 2); % 使用红色粗线在样本曲线之上绘制簇中心,突出典型模式 title(['簇 ', num2str(k), ' 内部样本曲线及中心']); % 设置子图标题,说明当前展示的簇编号和内容 xlabel('时间点序号'); % 设置子图横坐标标签,表示时间点 ylabel('归一化负荷'); % 设置子图纵坐标标签,表示归一化负荷 grid on; % 打开子图网格线,辅助对比用户曲线与中心曲线的差异endcolormap(fig2, turbo); % 为第二个图窗设置turbo色图,使整体视觉风格统一且符合版本规范
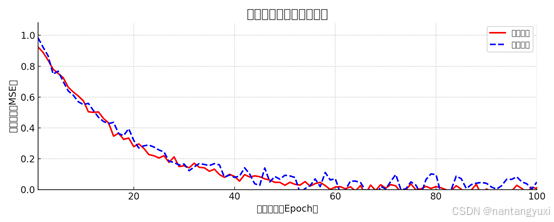
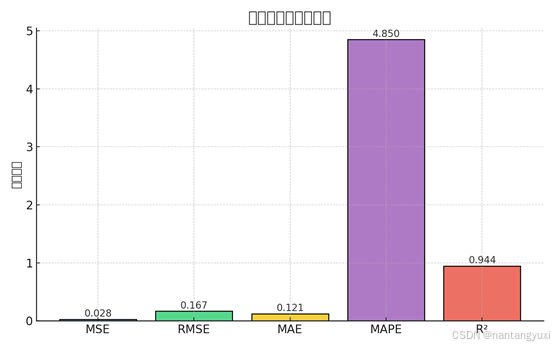
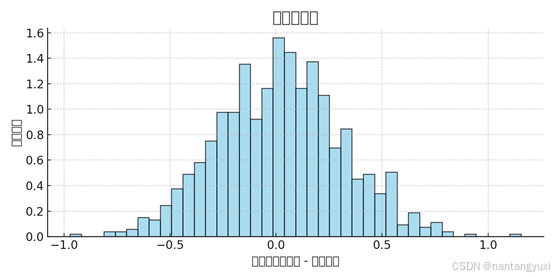
更多详细内容请访问
http://智能电网MATLAB实现基于PSO-Kmeans粒子群优化算法(PSO)结合K均值聚类(Kmeans)进行用户用电行为分析的详细项目实例(含完整的程序,GUI设计和代码详解)_移动平均模型MA代码详解资源-CSDN下载 https://download.csdn.net/download/xiaoxingkongyuxi/90225316
https://download.csdn.net/download/xiaoxingkongyuxi/90225316
http:// https://download.csdn.net/download/xiaoxingkongyuxi/90225316

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献706条内容
已为社区贡献706条内容

所有评论(0)