从原理到工程实践:一文彻底讲透梯度下降 & SGD
导读:
如果你只允许用一个算法来解释整个深度学习世界,那一定是:
梯度下降(Gradient Descent)
想象一下,当我们在惊叹大语言模型的博学、自动驾驶的敏锐时,你是否好奇过:神经网络这些复杂的“黑盒”,究竟是如何一步步学习并不断纠错的?
在机器学习的浩瀚宇宙中,有一个被称为“AI引擎”的终极数学魔法——梯度下降(Gradient Descent)。今天,我们将剥开枯燥的公式外衣,从基础原理一路讲到现代前沿的 Adam 优化器,带你彻底看透让机器变聪明的核心法则!
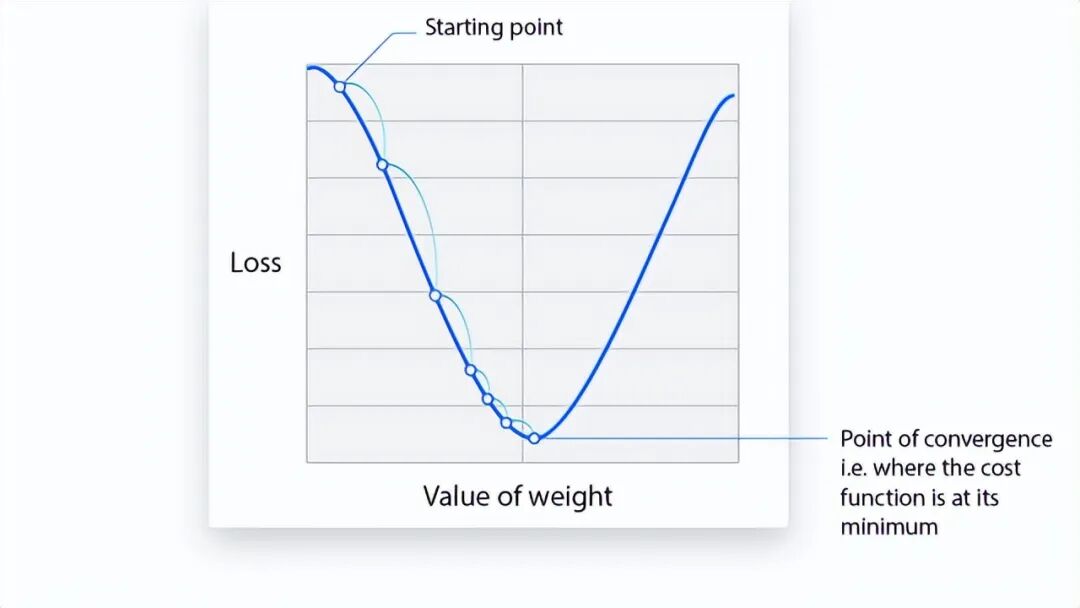
一、 什么是梯度下降?(底层逻辑)
梯度下降是一种迭代优化算法。它的唯一使命是:最大限度地减少“预测结果”和“实际结果”之间的误差。用于训练机器学习模型和神经网络。
它解决的核心问题是:
如何让模型的预测结果,尽可能接近真实结果?
答案就是:最小化误差(Loss / Cost Function)
模型会不断调整参数(权重和偏置),让误差越来越小,直到接近 0。
通俗类比:统计学中的线性回归
还记得初中数学里的直线方程y = mx + b吗?在统计学中,当我们面对一堆散点图时,目标是画出一条“最佳拟合直线”。
θ = θ - η · ∇J(θ)
θ:模型参数
η:学习率(步长)
∇J(θ):损失函数梯度
参数 = 原来的参数 - 一小步“下降方向”
为了找到这条线,我们需要计算所有点到直线的距离(误差),这就是均方误差。梯度下降算法的行为与此类似,只不过它处理的是高维的非线性模型,它始终在凸函数或非凸函数的“山谷”中寻找最低点。
目标是找到最优的 m 和 b,让直线尽可能贴合数据。
误差通过均方误差(MSE)衡量:
-
预测值:ŷ
-
真实值:y
梯度下降做的事情就是:
不断调整 m 和 b,让 (y - ŷ)² 最小
过程:
从随机参数开始
计算当前误差
求导(梯度)
更新参数
重复直到收敛
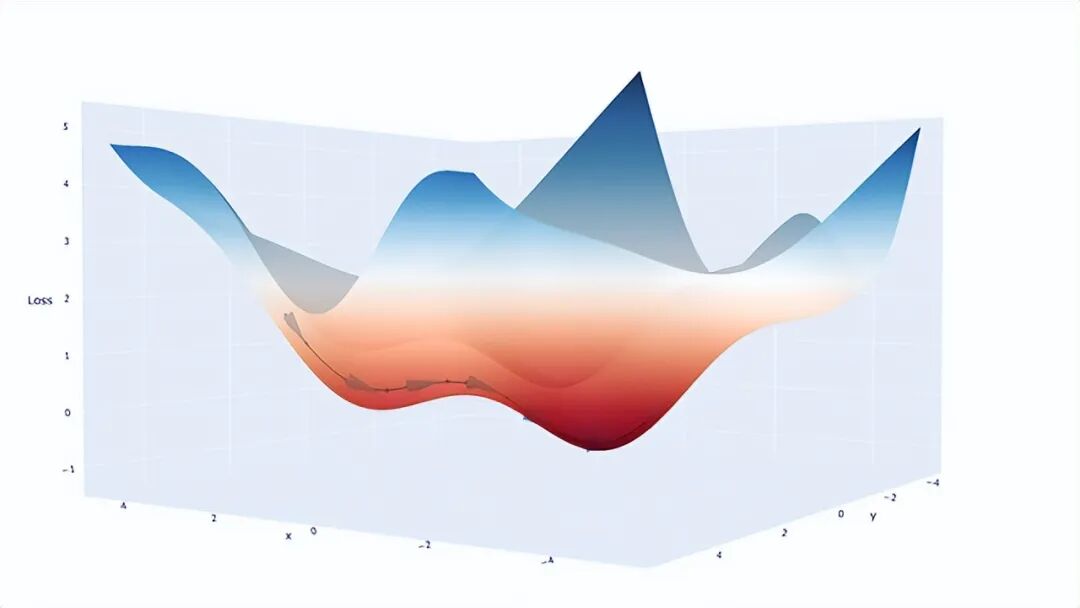
直观比喻:
想象你在一座山上:
-
山的高度 = 模型误差(损失函数)
-
你的位置 = 当前参数
-
目标 = 走到最低点(最优解)
你该怎么走?
每一步都沿着“最陡的下坡方向”走
这个“最陡方向”,就是:梯度(Gradient)
在这个过程中,我们需要深刻理解两个核心概念:
概念 1:成本函数 vs 损失函数
很多时候这两个词被混用,但它们有细微差别:
- 损失函数 (Loss Function):
针对单个训练样本,衡量当前预测值与真实值之间的误差距离。
- 成本函数 (Cost Function):
是整个训练集所有样本损失函数的平均值。它是衡量模型整体准确性的“标尺”。
模型优化的过程,就是不断调整参数(权重和偏差),沿着最陡的下降方向(负梯度)移动,直到成本函数接近或等于零(收敛)。
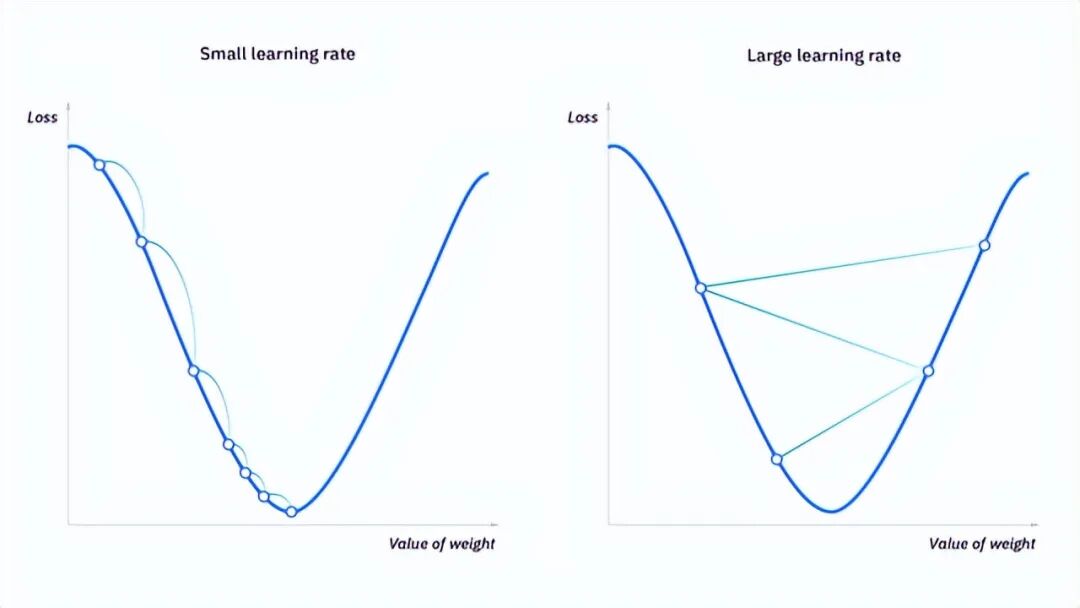
概念 2:学习率 (Learning Rate, α)
这是模型走向低谷的“步长”。
- 较小的学习率:
步子小,收敛缓慢但极其稳定,精度高。
- 较大的学习率:
步子迈得大,可能导致直接越过最低点(过冲),甚至在谷底两端来回震荡,导致系统不稳定。
二、 演化之路:三种经典的梯度下降类型
根据每次更新参数时“看多少数据”,梯度下降主要分为三大流派:
1. 批量梯度下降 (Batch GD)
它极其严谨。每次计算都要对训练集中的每一个点求误差总和,看完所有样本才更新一次参数。这被称为一个训练周期(Epoch)。
痛点:虽然路线稳定,但如果要训练包含数十亿图片的数据集,需要将全部数据塞入内存,不仅耗时极长,而且很容易陷入“局部最小值”出不来。
2. 随机梯度下降 (Stochastic GD, 简称 SGD)
为了解决速度问题,SGD 走向了另一个极端:每次只随机抽取“1个”训练样本来更新参数!
- 优点:
计算成本极低,速度极快。而且因为它只看单个数据,下降路线会产生剧烈的波动(噪音)。这种“跌跌撞撞”反而有助于它跳出浅层的“局部最小值”或“鞍点”。
- 缺点:
剧烈的锯齿状波动导致它很难在全局最低点彻底停稳。
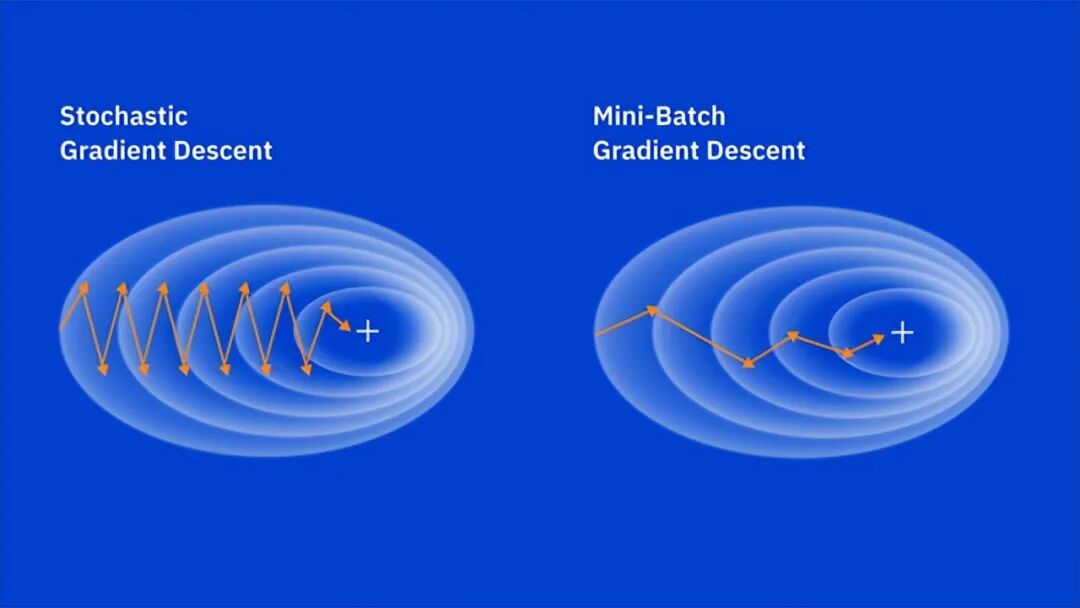
3. 小批量梯度下降 (Mini-batch SGD) —— 工业界黄金标准
既然看全集太慢,看单条太颠簸,那就取中间值!将数据集拆分成小批次(如 32、64、256 条)。它兼顾了 Batch GD 的稳定性和 SGD 的速度。由于现代 GPU 极其擅长并行处理小批量矩阵,这成为了深度学习的默认标配。
注意:在如今的 PyTorch 或 TensorFlow 等主流机器学习库中,当我们调用 SGD 优化器时,如果不特殊说明,默认指的其实就是“小批量梯度下降”。
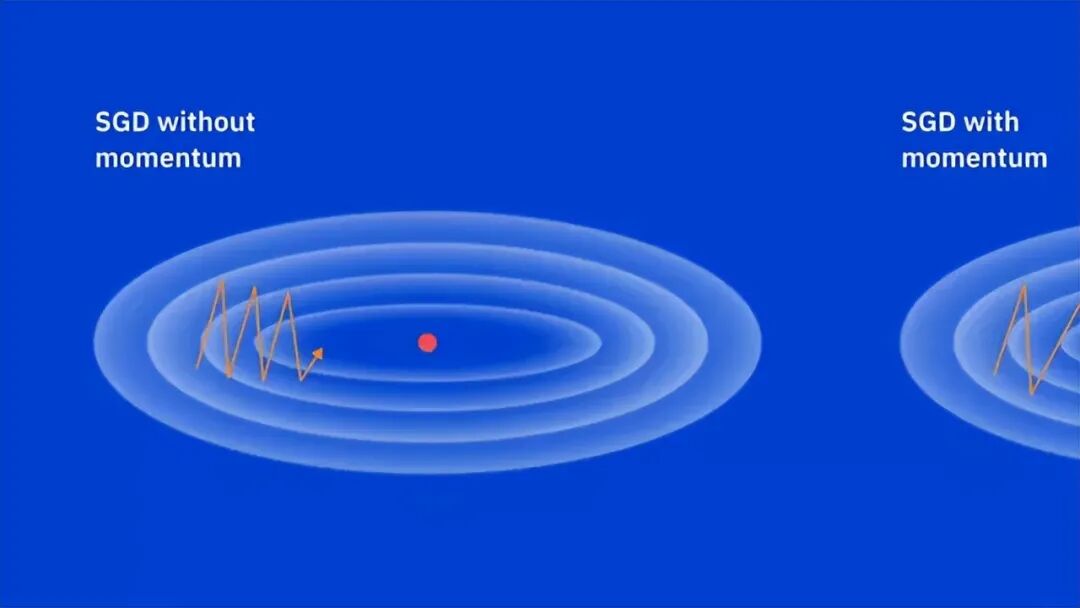
三、 现代黑科技:梯度下降的进阶变体
在复杂的神经网络中,普通的 SGD 有时仍显吃力。科学家们在此基础上增加了“动量”和“自适应”机制,诞生了现代 AI 框架中最常用的几大优化器:

专家提示:虽然 Adam 收敛极快,但对于超大规模数据集,精心调参的 带动量的 SGD 往往能获得更好的泛化能力(防止过拟合)。
四、 勇闯深水区:两大终极数学挑战
当我们把神经网络堆叠到几十层甚至上百层时,优化算法将面临可怕的地理陷阱:
1. 地形陷阱:局部最小值与鞍点
对于非凸优化问题,地形起伏不定。局部最小值就像半山腰的坑,算法掉进去发现四周都比自己高,误以为到了谷底。而鞍点更具欺骗性:它形状像马鞍,一个方向看是极小值,另一个方向看是极大值,导致梯度接近于 0,模型直接停滞。好在 SGD 带来的“嘈杂梯度”能帮模型震荡出这些陷阱。
2. 传播崩溃:梯度消失与梯度爆炸
在使用反向传播训练深层网络(特别是早期的 RNN)时:
- 梯度消失 (Vanishing Gradients):
误差信号向后传递时越来越小,到达前几层时直接变为 0。这意味着底层网络根本学不到任何东西,模型彻底罢工。
- 梯度爆炸 (Exploding Gradients):
误差信号在传递时呈指数级放大,导致权重更新过猛,数值直接崩溃(变成 NaN)。解决方法之一是利用降维技术降低模型复杂性,或者使用梯度裁剪。
总结
从最基础的寻找拟合直线,到极速狂飙的 SGD,再到集大成者的 Adam 优化器,梯度下降算法家族见证了 AI 算力与数学智慧的完美结合。
当训练时间成为瓶颈,当几十亿参数的大模型需要找到最聪明的状态时,正是这些隐秘的优化器在数据的高维空间里,日复一日地寻找着最优解。读懂了它们,你就真正触碰到了人工智能的脉搏!
梯度下降 = 找最优解的核心算法
SGD = 更快、更“随机”的版本
Mini-batch + Adam = 工业标准
最后一句话
机器学习,本质就是一场不断“下山”的过程 而梯度下降,是你唯一的指南针。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)